
Como hemos comentado, aunque ambos modelos pueden derivar el uno en el otro, en función de aplicar técnicas de normalización o desnormalización, el resultado final sí tiene su importancia. Hoy por hoy casi todas las herramientas de explotación pueden "atacar" a cualquier modelo, pero solamente algunas son capaces de aprovechar al máximo las capacidades de los modelos copo de nieve, en general, todas se mueven por el mundo de las estrellas.
Tradicionalmente los fabricantes de herramientas, basadas en modelos estrellas, han sido especialmente críticos con su competencia, pues se posicionaba con otro tipo de modelo. Ello provocó y todavía se nota, mensajes muy erróneos lanzados al mercado. Del mismo modo, actualmente nos quieren vender ideas como: hacer un DW en 10 minutos, todo ello sin técnicos, o de la vital importancia de disponer de análisis en un iPad, etc., cuando la mayoría de los sistemas funcionan por los pelos y no son adecuadamente explotados. En general, las necesidades de los usuarios finales no están alineadas con las estrategias comerciales de algunos fabricantes, mal que les pese.
En función de sus necesidades, conocimientos, herramientas y estrategias pueden optar por un tipo de modelo u otro. La figura 2 visualiza un modelo en estrella, en el centro la tabla de hechos donde se encuentran los indicadores numéricos a analizar, a su alrededor una tabla por dimensión o visión del negocio. Dentro de cada una se encuentran todos los conceptos asociados a dicha dimensión.
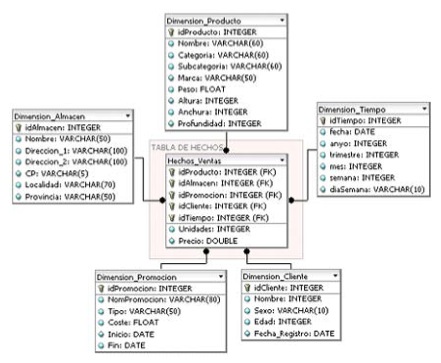
Figura 2. Modelo en estrella para un Data Warehouse
No soy enemigo de los modelos en estrella, pues mi maestro y casi padrino en BI fue Ralph Kimball. También es cierto que por aquellos años, aquella forma de diseñar fue una revolución en sí misma y tampoco había muchas más alternativas.
Puntualizar que en un proyecto de BI, no existe una sola estrella, de hecho, algunos hablan de constelaciones... En una base de datos de DW, podríamos encontrar decenas de tablas fact y sus dimensiones asociadas, comunes y no comunes entre diversas tablas fact. Pues en caso contrario, si piensan que con una estrella lo tienen todo resuelto, permítanme dos comentarios:
- No malgaste su tiempo y dinero, pues algo no he sabido explicarle o para usted un fichero texto ya sirve para tomar decisiones.
- Hágalo usted mismo, con una tabla dinámica de Excel.
Queda claro que de cara a intentar explicar temas de modelos, nos apoyamos con la expresión mínima (una sola tabla de hechos y sus dimensiones), las cuales son ilustradas en las figuras, pero la realidad no es tan simple.
La otra opción es el modelo copo de nieve, el cual tiene más o menos la apariencia que muestra la figura 3.
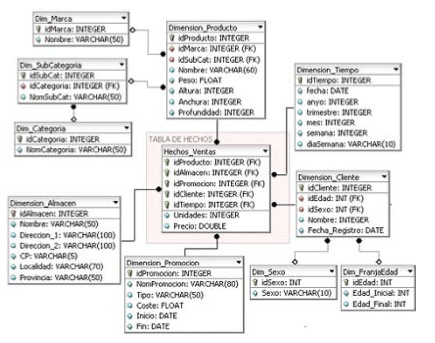
Figura 3. Modelo copo de nieve para un Data Warehouse
Los defensores de los modelos en estrella, modelos completamente desnormalizados, han basado su defensa en algunas afirmaciones que vamos a repasar, aunque el tiempo ha demostrado que "no es oro todo lo que reluce":
- Fácilmente entendible, consultas sencillas (por usar pocas tablas). Lo comparto, pues casi cualquiera puede entender a simple vista este modelo, digamos que no asusta al verlo. Supongo que su expansión se encuentra relacionada con su relativa sencillez al diseñarlo, pues deja todo el "marrón" a la herramienta, sobre la cual se debe definir la lógica de navegación. Como ya he indicado lo considero un error potencialmente alto. Las estrellas simples sobre BBDD relacionales son lo más parecido conceptualmente a las BBDD multidimensionales, a los castigados cubos, e incluso a las tablas dinámicas del Excel, etc. Supongo que por ello, algunos defienden el Excel como una herramienta de BI, sin más comentarios.
- Son más rápidos (por usar pocas tablas, pocos joins). Directamente, es una verdad a medias. Solamente podría ser así con poco volumen de información. Además, las políticas de claves, bajo este tipo de estructuras, no favorecen las búsquedas, aparte de ser francamente difícil planificar a priori la clave o claves más adecuadas, pues nunca podemos saber por dónde nos vendrá la consulta.
Otro problema más serio, y que solamente por ello debería hacernos replantear toda la solución, es que no es posible implementar integridad referencial. Por ello nuestro gestor nunca será capaz de garantizar la consistencia y la calidad del dato. Obligando a desarrollar unos procesos ETL muy estudiados y minuciosos.
En resumen, por ahorrar tiempo en el análisis, en el diseño y no complicarse la vida, algunas veces "te entregan unas estrellitas muy monas". Nadie te explicará y te pondrá sobre aviso de que:
- Ese tipo de diseño puede implicar perder calidad y consistencia en los datos, pues no puedes definir integridad referencial entre campos de una misma tabla.
- Ello ocasiona pasar el control de la consistencia a los procesos ETL, lo cual implica un esfuerzo extra y un coste elevado.
- Dicha forma de diseñar delega la lógica de la navegación a la herramienta final y no está implícita en el modelo, esto es igual a problemas tarde o temprano.
- Dificultad para determinar índices para mejorar respuesta.
- Relaciones padres e hijos no identificados.
- La velocidad que supuestamente ganamos por no hacer joins por diversas tablas, la podemos perder por el gran volumen de la dimensión (en única tabla) y por la posible ausencia de índices adecuados, etc.
Creo que ello, unido a otros puntos difíciles de explicar sobre papel nos debería por lo menos cuestionar qué modelo establecer y avisarnos sobre todo lo que leemos por Internet. Lo más sensato: Haga una prueba con el escenario más parecido posible a la realidad, también respecto al volumen de información.
