
SAS, SPSS y R: Ejemplos de componentes para tratamiento de datos. Equivalencias entre herramientas
 Existen en el Mercado numerosas herramientas para tratamiento de datos. En este post, nos vamos a centrar en algunas de las más utilizadas: SAS, SPSS y R. Sin entrar a valorar la mejor o peor adecuación de cada una de ellas al tipo de proyecto en el que trabajemos, sus ventajas o sus inconvenientes, lo que es evidente es que son tres herramientas muy extendidas.
Existen en el Mercado numerosas herramientas para tratamiento de datos. En este post, nos vamos a centrar en algunas de las más utilizadas: SAS, SPSS y R. Sin entrar a valorar la mejor o peor adecuación de cada una de ellas al tipo de proyecto en el que trabajemos, sus ventajas o sus inconvenientes, lo que es evidente es que son tres herramientas muy extendidas.
 En este post vamos a realizar un ejemplo de segmentación de datos de clientes, empleando un proceso de clusterización, concretamente el procedimiento proc fastclus de SAS.
En este post vamos a realizar un ejemplo de segmentación de datos de clientes, empleando un proceso de clusterización, concretamente el procedimiento proc fastclus de SAS.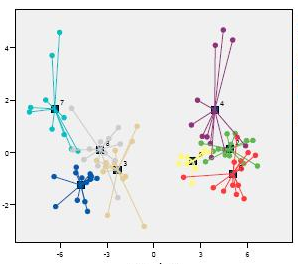 En el presente post mostramos un sencillo ejemplo de análisis discriminante en SAS que puede servir para analizar relaciones entre variables en un conjunto de datos. En el caso que vamos a estudiar, este análisis permite discriminar qué variable de las que caracteriza a un conjunto de clientes tiene más peso en la tasa de bajas
En el presente post mostramos un sencillo ejemplo de análisis discriminante en SAS que puede servir para analizar relaciones entre variables en un conjunto de datos. En el caso que vamos a estudiar, este análisis permite discriminar qué variable de las que caracteriza a un conjunto de clientes tiene más peso en la tasa de bajas La gestión de los datos no estructurados se ha convertido en uno de los principales retos a los que hacen frente las compañías en lo relativo a gestión de información y Big Data. En este post damos una breve introducción al tratamiento de los mismos y las problemáticas más comunes en su gestión..
La gestión de los datos no estructurados se ha convertido en uno de los principales retos a los que hacen frente las compañías en lo relativo a gestión de información y Big Data. En este post damos una breve introducción al tratamiento de los mismos y las problemáticas más comunes en su gestión...jpg) Dentro de las actividades habituales en minería de datos, se encuentra el estudio de correlaciones entre variables. En este post vamos a realizar un ejemplo sencillo de estudio de correlación entre variables realizado con la herramienta SAS.
Dentro de las actividades habituales en minería de datos, se encuentra el estudio de correlaciones entre variables. En este post vamos a realizar un ejemplo sencillo de estudio de correlación entre variables realizado con la herramienta SAS. En el siguiente post mostramos con ejemplos los diferentes métodos de agregación de los que disponemos en el módulo BASE de SAS. Se incluye un script con ejemplos utilizando el procedimiento generalista ‘proc sql’ o bien procedimientos propios de agregación como ‘proc means’ o ‘proc summary’.
En el siguiente post mostramos con ejemplos los diferentes métodos de agregación de los que disponemos en el módulo BASE de SAS. Se incluye un script con ejemplos utilizando el procedimiento generalista ‘proc sql’ o bien procedimientos propios de agregación como ‘proc means’ o ‘proc summary’.