Building Hadoop Clusters [Video] - Review (en español)
Estimad@s,
una vez más se trata de una review de un video curso publicado por Packt Publishing. En este caso les haré un comentario sobre "Building Hadoop Clusters" cuyo autor es Sean Mikha.

Estimad@s,
una vez más se trata de una review de un video curso publicado por Packt Publishing. En este caso les haré un comentario sobre "Building Hadoop Clusters" cuyo autor es Sean Mikha.
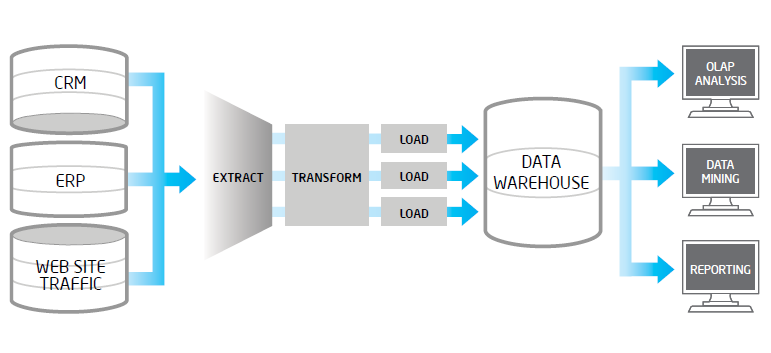 En el presente post pretendemos mostrar la problemática que con frecuencia encontramos en los procesos de extracción, validación y carga de datos en los entornos Big Data. Un proceso ETL tradicional, extrae datos desde múltiples fuentes origen, después los valida, normaliza, realiza determinadas transformaciones y vuelca los mismos en un entorno datawarehouse para su posterior análisis. Cuando en los datos fuentes, tenemos volúmenes altos, una frecuencia de actualización alta en origen o bien son datos no estructurados, estos procesos ETL suelen tener problemas..
En el presente post pretendemos mostrar la problemática que con frecuencia encontramos en los procesos de extracción, validación y carga de datos en los entornos Big Data. Un proceso ETL tradicional, extrae datos desde múltiples fuentes origen, después los valida, normaliza, realiza determinadas transformaciones y vuelca los mismos en un entorno datawarehouse para su posterior análisis. Cuando en los datos fuentes, tenemos volúmenes altos, una frecuencia de actualización alta en origen o bien son datos no estructurados, estos procesos ETL suelen tener problemas..
.png) Una de las herramientas más maduras en el mundo Big Data es el framework de licencia libre Apache Hadoop. En este post exponemos de forma resumida la integración entre Hadoop y uno de los fabricantes líder en analítica de negocio: SAS.
Una de las herramientas más maduras en el mundo Big Data es el framework de licencia libre Apache Hadoop. En este post exponemos de forma resumida la integración entre Hadoop y uno de los fabricantes líder en analítica de negocio: SAS.
En primer lugar resumimos los principales componentes de la arquitectura Hadoop..

 Estos días he estado leyendo el libro Big Data Analytics with R and Hadoop, de Vignesh Prajapati, un libro que explica cómo integrar el paquete de análisis estadístico R y la plataforma de Big Data Apache Hadoop, para romper la barrera de la mayor limitación de R, que es la limitada cantidad de datos que acepta como juegos de datos para procesar.
Estos días he estado leyendo el libro Big Data Analytics with R and Hadoop, de Vignesh Prajapati, un libro que explica cómo integrar el paquete de análisis estadístico R y la plataforma de Big Data Apache Hadoop, para romper la barrera de la mayor limitación de R, que es la limitada cantidad de datos que acepta como juegos de datos para procesar.
Combinando estas dos herramientas open source se obtiene una potente plataforma de analítica, con la que se pueden aplicar operaciones de estadística e inteligencia artificial sobre grandes conjuntos de datos..
 Si miramos alrededor nuestro, vemos que cualquier dispositivo que usamos genera datos, estos pueden ser analizados actualmente. De esta gran cantidad de datos que tenemos a nuestro alcance, sólo el 20% se trata de información estructura y el 80% son datos no estructurados. Estos últimos añaden complejidad en la forma que se tienen que almacenar y analizar.
Si miramos alrededor nuestro, vemos que cualquier dispositivo que usamos genera datos, estos pueden ser analizados actualmente. De esta gran cantidad de datos que tenemos a nuestro alcance, sólo el 20% se trata de información estructura y el 80% son datos no estructurados. Estos últimos añaden complejidad en la forma que se tienen que almacenar y analizar.
Hadoop aparece en el mercado Big Data como una solución para estos problemas, dando una forma de almacenar y procesar estos datos..
Como sabéis Apache Hadoop está revolucionando la forma en que se accede a la información. GigaOM nos proporciona 4 buenos enlaces para conocer la evolución de Hadoop

Luca Zurlo es Director para el Sur de Europa de Jaspersoft, la compañia que ofrece la extendida suite de Business Intelligence open source.
Con motivo de la presentación en el evento Big data 2012 de novedades en la suite para trabajar con Big Data, y del acuerdo firmado por la compañia con el grupo tecnológico GMV, que convierte a esta compañia en el primer partner de Jaspersoft en España, Luca Zurlo nos concedió esta entrevista.
 Uno de los puntos que han cambiado la forma en que se hace y hará Business Intelligence es la eclosión de una gran cantidad de datos que anteriormente no se analizaban. Ahora es posible combinar y analizar de forma conjunta, tanto datos estructurados (relacionales, legacy, dbcolumn, etc...) con no estructurados (Hadoop, MapReduce, NoSQL), permitiendo alcanzar cantidades enormes de datos.
Uno de los puntos que han cambiado la forma en que se hace y hará Business Intelligence es la eclosión de una gran cantidad de datos que anteriormente no se analizaban. Ahora es posible combinar y analizar de forma conjunta, tanto datos estructurados (relacionales, legacy, dbcolumn, etc...) con no estructurados (Hadoop, MapReduce, NoSQL), permitiendo alcanzar cantidades enormes de datos.
 Durante décadas, las organizaciones se han esforzado por gestionar sus datos con eficacia. Sin embargo, para guardarlos utilizaban almacenes de datos muy frágiles, que se deterioraban con demasiada facilidad. Como resultado, no conseguían extraer la información que necesitaban para tomar decisiones estratégicas sobre la dirección del negocio. Este ha sido el eterno problema de muchas empresas en todo el mundo.
Durante décadas, las organizaciones se han esforzado por gestionar sus datos con eficacia. Sin embargo, para guardarlos utilizaban almacenes de datos muy frágiles, que se deterioraban con demasiada facilidad. Como resultado, no conseguían extraer la información que necesitaban para tomar decisiones estratégicas sobre la dirección del negocio. Este ha sido el eterno problema de muchas empresas en todo el mundo.
Cloudera, uno de los grandes especialistas en Big Data desvela en esta presentación sus 12 predicciones para el 2012 sobre Apache Hadoop y Big Data, uno de los temas candentes de este año en BI.
 Esta obra está bajo una licencia de Creative Commons Reconocimiento-CompartirIgual | Presentacion | Aviso legal
Esta obra está bajo una licencia de Creative Commons Reconocimiento-CompartirIgual | Presentacion | Aviso legal