
Observabilidad en bases de datos: métricas clave, distributed tracing y alerting para la capa de datos


La observabilidad en la capa de datos es la disciplina que convierte el comportamiento interno de bases de datos, pipelines y motores de almacenamiento en información accionable para los equipos de ingeniería. A diferencia de la simple monitorización —que alerta cuando algo ya ha roto—, la observabilidad permite anticipar degradaciones, diagnosticar causas raíz y comprender el estado del sistema en tiempo real.
En este capítulo se analizan en profundidad las métricas esenciales por tipo de base de datos, los patrones de distributed tracing aplicados a la capa de datos, las estrategias de alerting que van más allá de los umbrales estáticos, las herramientas del ecosistema actual y los riesgos que pueden convertir un proyecto de observabilidad en un grave problema de señal-ruido..


 El rendimiento de una web es un factor muy importante, tanto para proporcionar una buena experiencia de navegación al visitante como para que el algoritmo de Google te tenga mejor considerado en sus resultados de búsqueda, así que merece la pena invertir un poco de esfuerzo y a veces de dinero en que tu web responda rápido a las interacciones con los visitantes y usuarios..
El rendimiento de una web es un factor muy importante, tanto para proporcionar una buena experiencia de navegación al visitante como para que el algoritmo de Google te tenga mejor considerado en sus resultados de búsqueda, así que merece la pena invertir un poco de esfuerzo y a veces de dinero en que tu web responda rápido a las interacciones con los visitantes y usuarios..
 Casi siempre nos enteramos de que alguna query va lenta por alguna queja de usuario. Ahora se queja que hace tiempo aquella cosa que hacía tardaba tanto y hoy cuando lo ha hecho un par de veces la cosa ha sido más lenta de normal.
Casi siempre nos enteramos de que alguna query va lenta por alguna queja de usuario. Ahora se queja que hace tiempo aquella cosa que hacía tardaba tanto y hoy cuando lo ha hecho un par de veces la cosa ha sido más lenta de normal.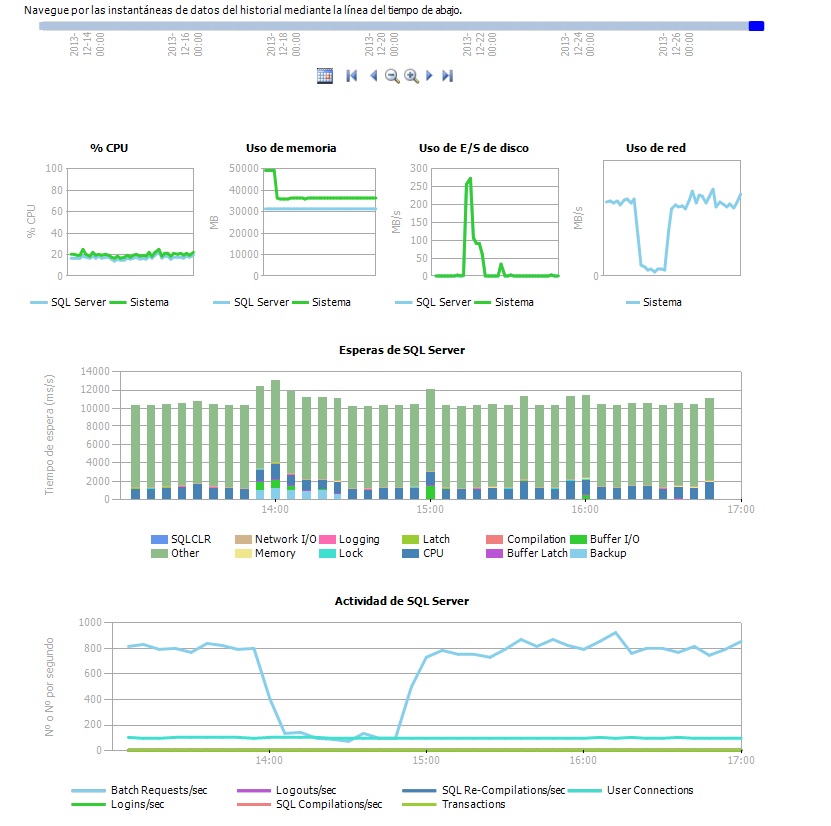 El recopilador de datos es una parte de MS Sql Server que permite recopilar diferentes tipos de datos y métricas sobre el rendimiento y desempeño de la base de datos. Se incluye desde la versión 2008 de SqlServer hasta la 2014 y esta formado por un conjunto de trabajos que se ejecutan mediante el agente de Sql Server periódicamente o de forma continua. Su configuración esta formada por dos sencillos pasos mediante asistente. Una vez finalizados ya podemos explotar su información mediante los informes incluidos.
El recopilador de datos es una parte de MS Sql Server que permite recopilar diferentes tipos de datos y métricas sobre el rendimiento y desempeño de la base de datos. Se incluye desde la versión 2008 de SqlServer hasta la 2014 y esta formado por un conjunto de trabajos que se ejecutan mediante el agente de Sql Server periódicamente o de forma continua. Su configuración esta formada por dos sencillos pasos mediante asistente. Una vez finalizados ya podemos explotar su información mediante los informes incluidos. Una de las tareas básicas en la administración de bases de datos es la monitorización de nuestro servidor y nuestra base de datos. Para servidores Windows con SQL Server una de las maneras más básicas (y gratuitas) es hacerlo mediante los contadores de rendimiento del sistema.
Una de las tareas básicas en la administración de bases de datos es la monitorización de nuestro servidor y nuestra base de datos. Para servidores Windows con SQL Server una de las maneras más básicas (y gratuitas) es hacerlo mediante los contadores de rendimiento del sistema.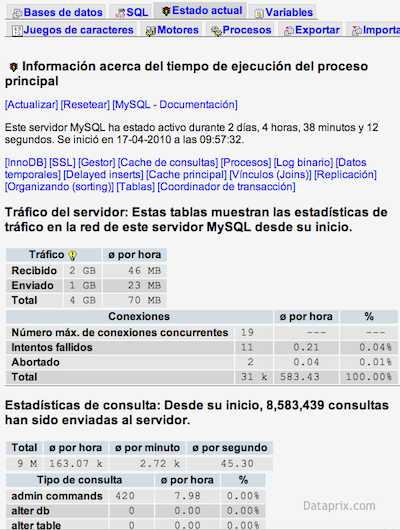 MySQL, al igual que la mayoría de gestores de bases de datos, permite modificar fácilmente sus parámetros que controlan tamaños de memoria dedicados a determinadas tareas, utilización de recursos, límites de concurrencia, etc.
MySQL, al igual que la mayoría de gestores de bases de datos, permite modificar fácilmente sus parámetros que controlan tamaños de memoria dedicados a determinadas tareas, utilización de recursos, límites de concurrencia, etc.