
La orientación de Microstrategy 9 con el Data Mining es integrarlo totalmente en su plataforma de Business Intelligence y que no sea un producto aparte como en muchos otros fabricantes (lo que nos obliga a realizar los análisis en un sistema paralelo). Esta integración se realiza a traves de las métricas predictivas, que estaran disponibles en el sistema como un elemento mas del sistema de BI.
Ademas, soporta el estandar de la industria PMML (Predictive Model Markup Language), lo que nos permite importar modelos de data mining desde otras plataformas y crear de forma automatica en el repositorio de metadatos las metricas predictivas. Recordemos que PMML es un estandar de la industria en XML desarrollado por el Data Mining Group(DMG) para describir los modelos predictivos. En su desarrollo han participado los principales fabricantes de software de datamining, incluyendo Microstrategy. Este estandar soporta un gran numero de algoritmos de data mining, como son las Redes Neuronales, Clustering, Regresion, Arboles de Decision y Asociacion. PMML se puede generar en las principales aplicaciones de DM como son SAS®, SPSS®, Microsoft®, Oracle®, IBM®, KXEN™, ANGOSS y otros. Microstrategy es la primera plataforma BI que soporta el estandar, y su plataforma incluye, de forma integrada con el resto de elementos, la creación de modelos y la distribución de los resultados a los usuarios a traves del visor de modelos previsibles, que presenta unas características e información gráfica diferente según el tipo de análisis que estemos realizando. Los resultados de los estudios se pueden incluir como un elemento mas en los Dashboards de analisis.
Los tipos de algoritmos soportados por Microstrategy 9 son los siguientes: Regresión lineal , Regresión Exponencial, Regresión Logistica, Agrupación (Clustering), Arbol de Decisiones, Series Temporales y Asociacion.
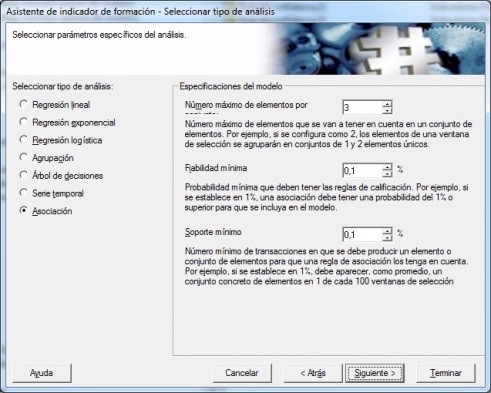
Tipos de analisis de Datamining soportados por Microstrategy 9
Ademas de estas características DataMining puras, Microstategy va mas alla y enumera otros elementos de la plataforma BI que también son utiles y necesarios para un analisis avanzado (como parte incluida dentro de la preparación del modelado de DataMining o como analisis previos o especificos). Estas caracteristicas las hemos visto en diferentes entradas del Blog cuando hemos analizado las principales componentes de la Suite ( Reporting en Microstrategy 9 I y II, Navegación Dimensional y cubos OLAP en Microstrategy 9). Resumiendo, serían las siguientes:
Funcionalidad de Reporting Guiada por Parámetros.
Partiendo de los informes construidos, y mediante el uso de parametros, podemos construir analisis de una forma variable y sencilla. Esos parametros podrán interactuar contra los valores de los indicadores para hacer analisis interactivos, permitiendons crear informes sofisticados. Por ejemplo, podemos pedir un valor en tiempo de ejecución que se utilizara dinamicamente en la formula de calculo de un indicador, pudiendo realizar analisis de suposiciones y predictivos utilizando diferentes variables, algunas de las funciones proporcionadas por la suite y los valores de indicadores de nuestro modelo. Mediante las selecciones dinamicas de valor y la utilización de estos valores en las formulas de los indicadores dispondremos de una forma sencilla de esta funcionalidad.
Capacidades de Navegación Drill-Anywhere.
Mediante estas capacidades de navegación, los usuarios pueden visualizar tanto información sumarizada como detallada y tienen acceso a la totalidad de los datos contenidos en el data warehouse en cualquier lugar de estos. Esta navegación nos permite navegar en los detalles tal como aparecen en el modelo de negocio y detectar tendencias, desviaciones o aspectos que sera interesante analizar mas a fondo. No es necesario que los usuarios comprendan en profundidad la base de datos, las estructuras de las tablas, ni el lenguaje de las consultas. Simplemente deben saber dónde posicionarse y cómo hacer clic.
Análisis de Conjuntos y Segmentación de Datos
Los usuarios pueden potenciar los análisis de conjuntos que trae MicroStrategy para realizar una fácil segmentación de los datos. Los usuarios pueden manipular y combinar los sets de datos definidos para obtener un set de datos más refinado para llevar adelante análisis más profundos. Para ello podemos utilizar los filtros, las selecciones dinámicas, los filtros de visualización, los filtros sobre los indicadores, la navegación a través de grupos de atributos, etc. Las herramientas de reporting pueden ser el punto de partida para los analísis mas profundos utilizando todas las posibilidades que nos proporciona.
Grupos de Datos Definidos por Usuarios
Cuando construimos el data warehouse, definimos en el una estructura que refleja el modelo de negocio de la empresa, pero dicha estructura no siempre refleja los requerimientos de negocio de los departamentos individuales, ni de los equipos de trabajo ni de los decisores. Con los Grupos Personalizados y Consolidaciones, podemos cambiar el enfoque del modelo de negocio y construir nuevos atributos o agrupaciones mas acordes con el tipo de analisis que queremos realizar. No pueden ayudar a realizar analisis previos antes de la realización de estudios de data mining. Con ellos podemos perfeccionar el modelo de negocios hasta alcanzar los requerimientos departamentales o individuales, sin impactar en la estructura del modelo de datos de la empresa. Podemos realizar simulaciones de segmentación que luego analizaremos en profundidad utilizando las técnicas de Data Mining.
Tratamiento Analítico de los Datos
MicroStrategy nos proporciona un amplio conjunto de funciones analíticas para interactuar sobre los datos. MicroStrategy contiene una libreria de mas de 270 funciones, incluyendo las básicas, funciones Olap, funciones matematicas, financieras, estadísticas y de data mining, que pueden ser utilizadas para crear metricas e indicadores de rendimiento (pki).
Microstrategy - Funciones estadísticas
Las funciones disponibles, de forma resumida, son las siguientes:
- Funciones básicas: suma, promedio, media aritmetica, contadores, minimo, maximo, varianza, media geometrica, moda, desviación estandar, etc.
- Funciones de cadena: concatenacion, longitud de cadenas, tratamiento de subcadenas, paso a mayusculas o minusculas, eliminación espacios, etc.
- Funciones de fecha y hora: operaciones sobre fechas; hora, minuto, segundo, dia, mes, año, dia de la semana, dia del mes, dia del año de una fecha, etc.
- Funciones de orden y NTile: funciones ntile, percetiles o rankings.
- Funciones Olap: funciones relacionadas con el procesamiento Olap.
- Funciones de extraccion de datos: funciones para data mining como modelo asociacion, modelo regresion, arbol de decision, clustering, etc.
- Funciones estadisticas: distribucion beta, distribucion binomial, confianza, correlacion, covarianza, distribucion chi cuadrado, distribucion gamma, permutaciones, distribución de poisson, etc.
- Funciones financieras: funciones financieras para el calculo de interes, rentabilidad, prestamos, etc.
- Funciones matematicas: valor absoluto, seno, coseno, tangente, redondeo, truncate, logaritmos, raiz cuadrada, etc.
Ademas, como características avanzadas, y en las que no habiamos entrado todavia, podemos destacar las siguientes:
Plug-ins para Funciones a Medida
Microstrategy permite incorporar a la plataforma de BI nuestras propias funciones, desarrolladas mediante DLL´s. Por medio de un asistente plug-in para funciones a medida, los usuarios de MicroStrategy pueden incorporar dichas funciones para usarlas en la creación de informes. Una vez importadas, se ponen a disposición de todos los usuarios de manera automática para que se definan las métricas y las medidas.
Creación de Datamarts utilizando informes de Microstrategy.
Esta es una funcionalidad muy interesante, que nos puede servir tanto para la preparación de los datos sobre los que luego aplicar nuestros analisis de Data Mining o como para la construcción de Datamarts departamentales o de un area especifica (que incluyen solo un conjunto de datos de todos los que disponemos en nuestro sistema). Los datos extraidos son almacenados en una tabla de base de datos en el lugar que nosotros indiquemos. Los datos estaran en ese momento disponibles para analizarlos en el mismo Microstrategy o para utilizarlos con otras aplicaciones externas.
La idea es muy sencilla. Construimos un informe donde incluimos la información necesaria (el conjunto de atributos e indicadores que queremos “extraer” de nuestro sistema), con los correspondientes filtros o selecciones dinámicas para restringir o calificar el proceso de extracción a nuestras necesidades. Una vez definido el informe, en la seccion Datos –> Configurar Datamart indicamos el destino donde se guardarán los datos (tal y como vemos en la imagen):
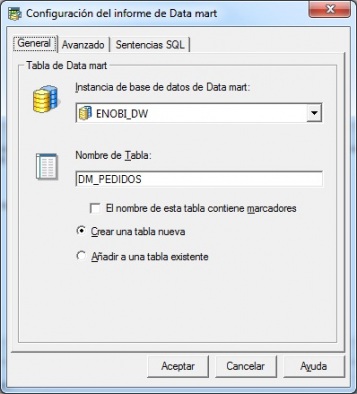
Microstrategy - Creación de Datamart
Indicaremos la instancia de la base de datos donde queremos guardar los datos (que podrá ser cualquier base de datos de las soportadas), la tabla, pudiendo además indicar una serie de opciones avanzadas, como número máximo de filas, sentencia sql a ejecutar antes y despues de crear la tabla o sentencia a ejecutar antes de insertar los datos. Además, en el nombre de la tabla podemos insertar calificadores que pueden ser utiles para crear tablas diferentes según algún criterio (usuario, fecha, nombre de informe). Para ello, marcamos la opción “El nombre de esta tabla contine marcadores” e indicamos alguno de los siguientes valores:
- !U – Nombre de usuario.
- !D – Fecha.
- !O – Nombre de informe.
Una vez indicados los parametros correctos en la sección, ejecutaremos el informe, momento en el cual se creara la tabla en el destino indicado y se llenara con los datos recuperados por el informe. La ejecución del informe no devuelve ningún resultado. Igualmente, podremos configurar la ejecución automatica de este tipo de informes para que se llene el Datamart de una forma desasistida (al igual que cuando vimos los cubos inteligentes).
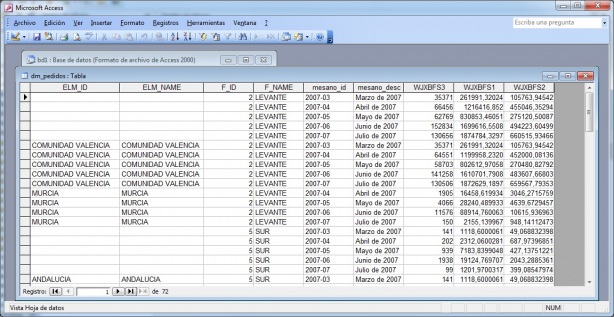
Microstrategy - Ejemplo de Datamart
En la imagen podeis ver la vinculación desde Access a una tabla del tipo Datamart creada con un informe. En el informe utilizamos los grupos personalizados de zonas geografícas (que agrupan los valores de varias regiones, por ejemplo, Zona Levante agrupa Murcia, Valencia y Cataluña) para extraer los datos de ingresos, unidades y margen por mes para cada zona geográfica. Podemos ver como, aunque los grupos personalizados no son algo que exista en nuestro modelo, al realizar la exportación de datos al Datamart si se ha creado su correspondiente columna en la tabla creada (campos F_ID y F_NAME en el ejemplo ). Los primeros registros del ejemplo tienen los datos totales de la zona geográfica LEVANTE por mes y los 9 registros siguiente el desglose de la zona por cada una de las regiones).
Con esta funcionalidad, junto con el uso de las multiples funciones que proporciona Microstrategy, podremos realizar la extracción de datos adaptada a nuestras necesidades para realizar los analisis de data mining sobre los datos o cualquier otro tipo de operativa.
Construcción de Analisis de DataMining en Microstrategy.
Para llevar a cabo la construcción del análisis, tendremos que determinar primero un objetivo. Es objetivo incluira los resultados deseados para mejorar un aspecto determinado en una organización. Por ejemplo, objetivos pueden ser mejorar la respuesta en una campaña de marketing, evitar la perdida de clientes, previsión de tendencias o segmentación de clientes. Este objetivo ha de ser especifico, pues a a ver determinar que analisis se puede utilizar y que datos nos haran falta.
Una vez definido el objetivo, comenzaremos a explorar en los datos para conocer mas de ellos y preparar el camino para el análisis. En nuestro caso, en Microstrategy, construiremos unos reports de ejemplo que nos permitiran ir observando los datos. Con el conjunto de datos que nos va a hacer falta para el analisis (dependeran del tipo de este), podemos construir un Datamart de la forma vista anteriormente (al que podremos atacar incluyendolo la definición de atributos e indicadores en el metadata) y a partir de el comenzar el análisis o continuar trabajando directamente con los datos mediante los informes. De ese conjunto de datos podremos ir eliminando componentes mediante filtrados (materiales que no son relevantes, clientes que no consideramos en el análisis, lineas de producto o zonas geograficas fuera del ambito, periodos de tiempo fuera de campaña, etc). Podremos igualmente ir navegando en los datos para observar comportamientos, variaciones, peculiaridades, patrones. Podremos crear nuevos indicadores que nos faciliten este analisis utilizando las funciones analiticas de Microstrategy (por ejemplo, funciones estadisticas, de ranking, de orden, etc). Todo este analisis previo nos permitira ir haciendo la depuración de datos y concretando los aspectos del análisis. Igualmente, podremos ir preparando para que solo se seleccione un conjunto determinado de los datos (un muestreo), utilizando igualmente funciones de las que disponemos en Microstrategy.
Una vez tenemos disponible el conjunto de datos, podremos seguir explorandolo para descubrir patrones o definir transformaciones que habra que realizar sobre ellos, con el objetivo final de identificar las variables con las que construiremos el modelo de análisis.
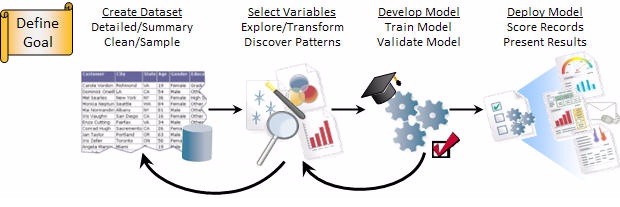
Pasos en un analisis de Datamining con Microstrategy
Con esas variables identificadas, construiremos el modelo previsible a traves de lo que en Microstrategy se llaman indicadores de formación. El indicador de formación es un tipo de indicador especial que va a contener información sobre el tipo de analisis que queremos realizar, que variables intervienen en el análisis y parametros concretos que determinaran la forma de realizar el analisis (que dependen del tipo de modelo a utilizar). Microstrategy dispone de un asistente de creación de indicadores de formación. En el caso de que vayamos a desarrollar un modelo que incluya el analisis de atributos (como por ejemplo número de pedido, material o datos de clientes), habrá que crear indicadores para estos atributos, pues en el indicador de formación solo se pueden utilizar indicadores. Los indicadores que se utilizan en la creación del indicador de formación se llaman indicadores de entrada previsibles.
Al crear el indicador de formación, seleccionamos en primer lugar el tipo de analisis, de los posibles en Microstrategy, que son, como ya vimos: Regresión lineal , Regresión Exponencial, Regresión Logistica, Agrupación (Clustering), Arbol de Decisiones, Series Temporales y Asociacion.
A continuación, el asistente nos pedira las variables implicadas en el análisis, según el tipo de este. Por ejemplo, para una analisis de asociación, las variables serán el indicador de transacción (el número de pedido, por ejemplo, que es el elemento para agrupar los elementos) y el indicador de elemento (los elementos que se van a analizar, en este caso, el material o producto). Ademas se nos pediran diferentes valores según el tipo de analisis a construir, valores que concretaran la forma en realizar en analisis.
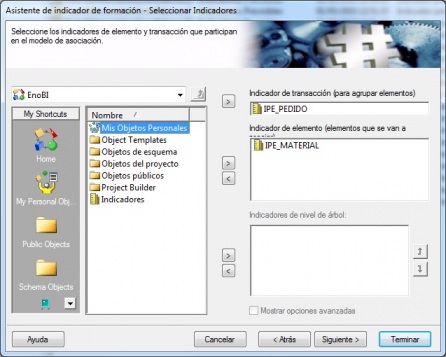
Microstrategy - Definición de indicador de formación
El indicador de formación tiene el objetivo de construir los indicadores previsibles y de realizar al generación del modelo de análisis. Una vez definido el indicador de formación, crearemos un informe de Microstrategy donde tendremos las variables (atributos o indicadores) necesarias para el tipo de analisis y donde ademas incluiremos el indicador de formación. Al incluir este, cuando ejecutemos el informe, se crearan los indicadores previsibles. Los indicadores previsibles guardan los resultados del análisis y pueden ser analizados mediante el visor que proporciona Microstrategy.
El visor de modelos previsibles (según vemos en la imagen siguiente), tiene un aspecto diferente según el tipo de analisis que estemos realizando. Basicamente, nos proporciona información sobre el modelo ( incluyendo información grafica en algunos casos y los datos para exportar el modelo en el estandar PMML), las variables que intervienen en el, una pestaña de simulación donde podemos analizar como cambia el modelo si cambiamos el valor de las variables de entrada y la herramienta de verificación del modelo (una lista de registros de verificación del modelo con su puntuación).
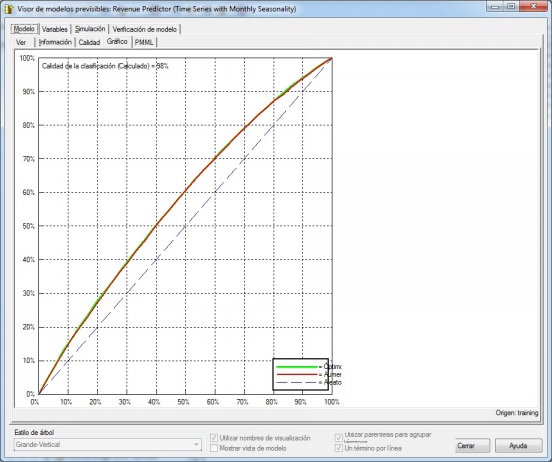
Microstrategy - Visor Modelos Previsibles en Analisis Serie Temporal
Podriamos ir modificando la muestra de datos sobre la que aplicamos el indicador de formación, y con los indicadores previsibles generados y el visor, ir validando y ajustando el modelo de análisis o ir realizando cambio en las variables, parametros del indicador de formación o en el conjunto de datos. Estos pasos los repetiremos hasta obtener los resultados deseados y concretar y validar el modelo de análisis.
Los indicadores previsibles se pueden, ademas de visualizar, utilizar como resultado en cualquier informe de Microstrategy. Esto puede ser util para validar los resultados, para analizar tendencias o para presentar los resultados del analisis.
Una vez concluido el análisis, podremos seguir utilizandolo para validar resultados a futuro o exportarlo en formato PMML para utilizarlo en otras herramientas de Data Mining que incluyan el trabajo con dichol estandar.
Para ver mas en detalle todos estos pasos seguidos, vamos a realizar un ejemplo práctico de analisis de Reglas de Asociación.
Ejemplo 1. Analisis de cesta de la compra (Asociacion).
Vamos a ver los pasos seguidos para la construcción de un modelo de analisis de la cesta de la compra, utilizando reglas de Asociación. Utilizamos para ello el proyecto Tutorial que se incluye en la instalación de Microstrategy (que muestra ejemplos de todas las funcionalidades incluidas en la suite, incluyendo el Data Mining).
Vamos a analizar una tabla que incluye los datos de ventas de peliculas de DVD. En primer lugar, construimos un informe para realizar un primer vistazo a los datos. En este informe podremos ir incluyendo restricciones sobre los datos, como excluir determinados materiales (o solo incluir una familia de producto determinada, como en este caso, las peliculas de DVD), seleccionar un periodo de tiempo o una zona geográfica concreta o realizar un muestreo aleatorio de datos utilizando indicadores de orden, para reducir el tamaño del conjunto de datos..
Como el tipo de analisis a realizar es el de asociación, que trata de ver como estan relacionadas las ventas de productos diferentes entre si en las mismas transacciones, nos vamos a centrar en los atributos Pedido y Articulo.
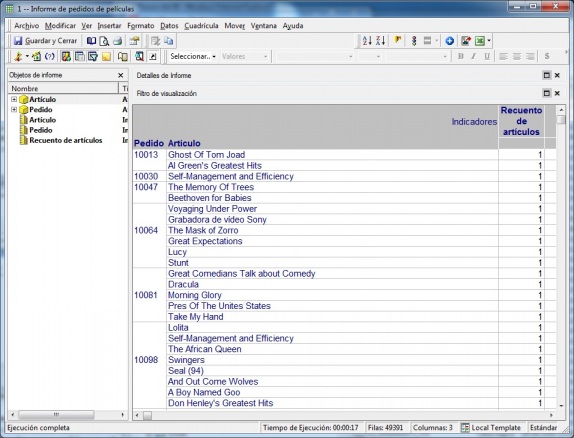
Informe inicial en analisis de asociacion
Una vez delimitado y acotado el conjunto de datos sobre el que realizaremos el analisis, realizamos la definición de los indicadores para los atributos Pedido y Articulo (aunque son indicadores normales, los llamamos Indicadores de Entrada Previsibles). Ellos nos van a permitir construir el indicador de formación, base del analisis. Veamos como definimos los indicadores para los atributos
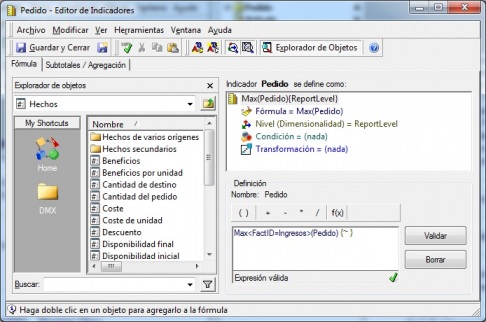
Definicion de indicador de entrada previsible para atributo
A continuación, realizamos la creación del indicador de formación, seleccionando el tipo de analisis Asociación. Al crear un indicador de formación de este tipo, las especificaciones del modelo son las siguientes:
- Numero maximo de elementos por conjunto: este parametro determina el número máximo de artículos que pueden aparecer en el conjunto de elementos anterior o posterior. Por ejemplo, si se establece en tres, los articulos se agruparán en conjuntos de elementos que contendrán uno, dos o tres artículos. En nuestro ejemplo, indicamos 3.
- Confianza minima: probabilidad mínima que deben tener las reglas de calificación. Por ejemplo, si se establece en 10%, una regla de asociación debe tener una confianza del 10% o superior para que se incluya en el modelo. El valor por defecto es 10% y aumentar su valor puede llevar a generar menos reglas. En nuestro ejemplo indicamos un 0,1%.
- Soporte minimo: el número mínimo de transacciones en las que se debe producir un conjunto de elementos para que una regla de asociación lo tenga en cuenta. Por ejemplo, si se establece en 1%, los conjuntos de elementos deben aparecer, en promedio, en una transacción cada 100. En nuestro ejemplo indicamos un 0,1%.
A continuación indicamos las variables que intervienen en el análisis, por una lado el indicador de transacción (el indicador para los numeros de pedido que hemos definido) y el indicador de elemento (el indicador para el material). Finalmente, indicamos las opciones de los diferentes indicadores previsibles que se generaran cuando ejecutemos el indicador de formación dentro de un informe. En este caso, indicaremos que reglas de asociación se van a devolver en los indicadores previsibles que se creen. En nuestro ejemplo, devolveremos dos indicadores, la regla de asociación (la tupla grupo peliculas anterior –> grupo peliculas posterior) y la recomendación (grupo peliculas posterior). Y cada indicador lo devolveremos 3 veces, por cada una de las 3 reglas que mas porcentaje de confianza tenga:
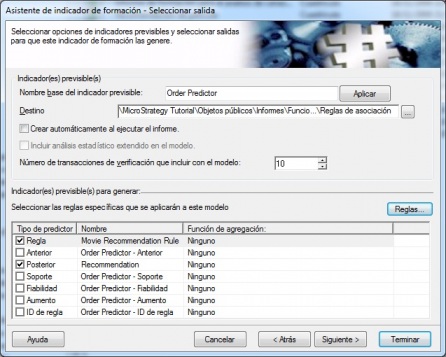
Opciones de indicadores previsibles a generar
El modelo ya esta preparado para empezar a trabajar con el. A continuación, incluimos el indicador de formación en un informe, junto con los atributos necesarios para el analisis (cada fila será un pedido, material y el indicador). El informe sería algo asi:
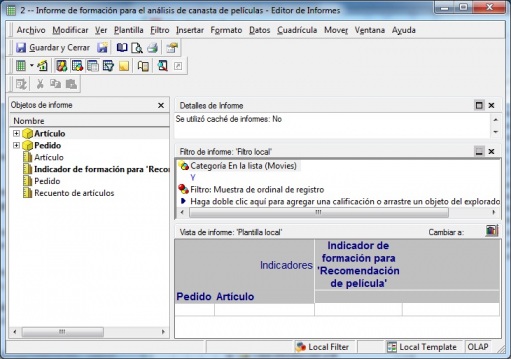
Asociacion - Informe Creacion Indicadores Previsibles
Podeis observar como hemos incluido en las filas los atributos pedido y articulo (al fin y al cabo, los indicadores se construyen sobre dichos atributos) y en las columnas el indicador de formación creado anteriormente. Cuando ejecutamos el informe, se realiza el proceso de analisis y se crean en el lugar indicado los indicadores previsibles (uno o varios según como hayamos definido el indicador de formación). En cada indicador previsible de los creados podremos visualizar el modelo que se ha creado con el visor de modelos previsibles (aunque hay varios indicadores previsibles, hay un unico modelo). El hecho de que haya varios indicadores previsibles es para tener información diferente que luego poder utilizar en un informe para presentar los resultados del análisis. Podremos ir realizando ajustes al modelo, cambiando el volumen del muestreo o las condiciones indicadas para la obtención de datos, o modificando los porcentajes de confianza y soporte del indicador de formación y generando diferentes indicadores previsibles que analizaremos con el visor correspondiente (tal y como vemos a continuación). También podremos validar el modelo aplicandolo sobre un conjunto de datos o muestreo diferente para confirmar los resultados que hemos obtenido en las diferentes tandas.
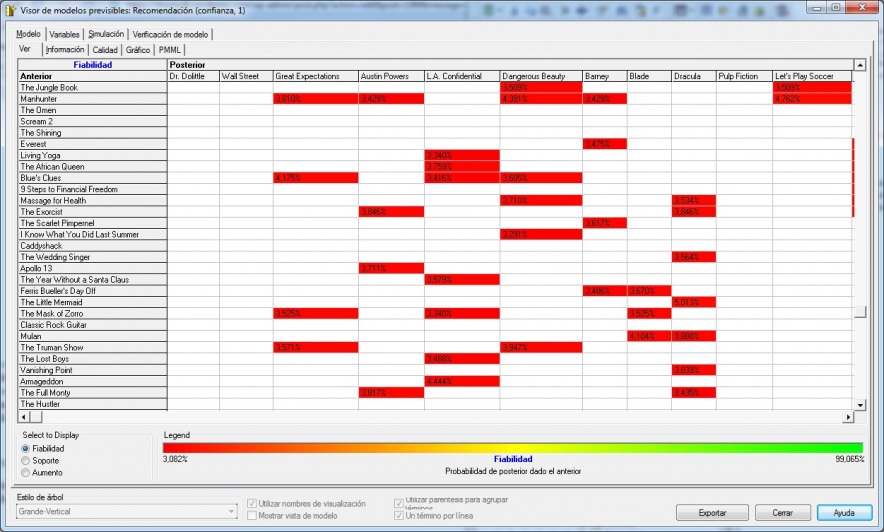
Visor de indicadores previsibles
En la imagen, podeis ver el visor de indicadores previsibles, donde tenemos la información del análisis realizado. Podemos ver la tabla de resultados (en otro tipo de analisis, la información que aparecerá será diferente). Podemos ver que Microstrategy ha construido la tabla de conjuntos, estando en las filas las reglas que representan a los grupos anteriores y en las columnas los grupos posteriores. El valor que aparece en cada casilla varia según el tipo de elemento elegido para visualizar ( casilla selección en la parte inferior izquierda):
- Confidence (confianza o fiabilidad): un estimacion de la probabilidad de que una transacción tenga el elemento posterior en el caso de que contenga el antecesor. La formula sería la siguiente:
- Confianza = Soporte (Anterior + Posterior en la misma transac ) / Soporte (Anterior)
- Support (soporte): frecuencia relativa de que una transaccion contenga el anterior y el posterior.
- Lift (aumento): Una relación que describe si la regla es más o menos significativa que el azar. Valores lift superiores a 1,0 indican que las transacciones con el anterior tienden a contener el posterior más a menudo que las transacciones que no contienen el antecedente.
La leyenda en la parte inferior de la tabla muestra el minimo y el maximo valor de la estadistica seleccionada para visualizar (con la correspondiente graduación de colores según los valores).
Despues de ajustar el modelo, realizar la verificación y las reejecuciones que se estime necesario, podemos comprobar los resultados incluyendo los indicadores previsibles en un informe estandar de Microstrategy. Para nuestro ejemplo, el informe final con los resultados podría ser algo así:
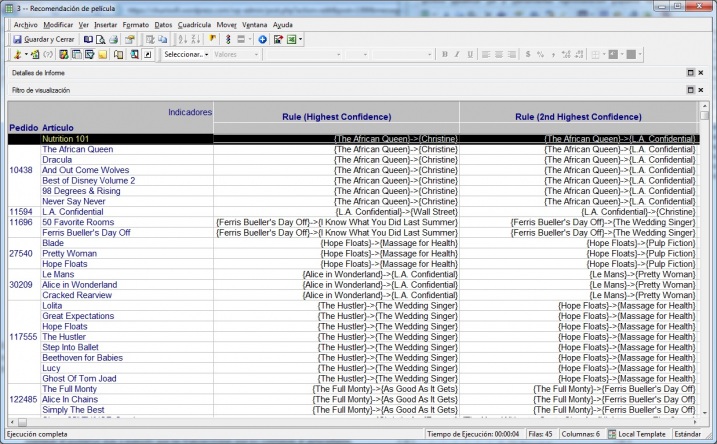
Modelo asociacion - Informe resultados con Indicadores Previsibles
A partir de los resultados, se podrían completar otro tipo de analisis que nos llevasen a establecer determinadas promociones con las peliculas, como colocarlas conjuntamente en los lugares de venta o en las zonas de paso, realizar packs que incluyan las dos, promociones de segunda unidad a un menor precio, etc. Las posibles acciones a realizar se podrian verificar a posteriori utilizando los grupos personalizados, de forma que podamos ver el historico de ventas anteriores de los materiales por separado y como han evolucionado las ventas despues de realizar las correspondientes acciones y venderlos conjuntamente. Incluso podriamos utilizar el indicador de formación que utilizamos en el estudio para verificar que los porcentajes de confianza han aumentado.
En la siguiente entrada del blog realizaremos el diseño completo de 2 ejemplos más de Data Mining con Microstrategy 9.

Hola amigos : Por favor,
Submitted by Omar Daniel (not verified) on 21 September, 2016 - 20:29
Hola amigos : Por favor, necesito que me ayuden, tengo que generar un Data Mart en MicroStrategy pero el nombre de Tabla tiene que tener el formato similar al siguiente : "CLIENTES_YYYY_MM.txt" dónde YYYY_MM es año y mes actual -1, ¿ esto se puede hacer ? Gracias por la respuesta. Saludos.
Hola Omar A nivel de base de
Submitted by Carlos on 22 September, 2016 - 09:51
In reply to Hola amigos : Por favor, by Omar Daniel (not verified)
Hola Omar
A nivel de base de datos obviamente tu puedes denominar a las tablas como quieras, por lo que entiendo que estás preguntando si MicroStrategy puede utilizar como origen cada mes una tabla con nombre diferente.
Si es eso, directamente no, a menos que cada mes cambies el nombre en el modelo, pero lo que sí puedes hacer es utilizar el particionamiento de MicroStrategy, particionando por mes. En la ETL irías creando una tabla para cada mes, y en MicroStrategy creas un particionamiento para Clientes configurándolo por meses.
Espero haberte ayudado,
Nota: Este tema no tiene mucho que ver con el Datamining de MicroStrategy, para próximas consultas de este tipo mejor utiliza el foro de Dataprix sobre MicroStrategy.