Una revolución silenciosa en el mundo de las bases de datos empresariales
Cuando Google publicó en 2012 el célebre paper académico que describía Spanner, la comunidad tecnológica contempló algo que parecía imposible: una base de datos relacional capaz de operar a escala planetaria manteniendo consistencia fuerte en todas las transacciones. Aquella promesa, que desafiaba directamente el teorema CAP que durante décadas había condicionado el diseño de sistemas distribuidos, se materializó primero como infraestructura interna de Google —potenciando servicios como Gmail, Google Photos y el sistema publicitario Google Ads— antes de llegar al mercado cloud público en 2017 bajo el nombre de Google Cloud Spanner.
Hoy, Cloud Spanner procesa más de 3.000 millones de consultas por segundo en sus instancias internas y gestiona más de 12 exabytes de datos, cifras que eclipsan incluso a competidores directos como Amazon DynamoDB. Esta solución representa la convergencia de dos mundos tradicionalmente incompatibles: la semántica transaccional ACID propia de las bases de datos relacionales y la escalabilidad horizontal ilimitada característica de los sistemas NoSQL. El resultado constituye una plataforma que permite a las organizaciones construir aplicaciones de misión crítica sin sacrificar consistencia por disponibilidad ni rendimiento por integridad de datos.
La evolución experimentada durante 2024 ha transformado Spanner de una base de datos distribuida puramente relacional a una plataforma multi-modelo con capacidades inteligentes e interoperables. La incorporación de Spanner Graph, búsqueda vectorial y búsqueda de texto completo posiciona a esta solución como un ecosistema unificado donde convergen cargas de trabajo relacionales, clave-valor, grafos y búsqueda semántica, todo ello sin necesidad de mover datos entre sistemas especializados ni implementar complejos pipelines ETL.
Google Cloud Spanner se posiciona como una plataforma que impulsa operaciones transaccionales de alcance mundial, garantizando consistencia externa, sincronización precisa y una arquitectura capaz de afrontar volúmenes masivos sin interrupciones.
Arquitectura y fundamentos tecnológicos
La arquitectura de Google Cloud Spanner destaca por un diseño distribuido global que permite manejar datos transaccionales en distintos continentes sin pérdida de coherencia. El sistema se construye sobre una infraestructura que combina automatización profunda, replicación inteligente y un enfoque en la minimización de la latencia. En vez de apoyarse en máquinas estáticas, Spanner distribuye automáticamente los datos en fragmentos (splits) que se reubican y reajustan según el volumen de lecturas o escrituras, manteniendo un flujo de trabajo equilibrado incluso bajo presiones elevadas.
Una pieza clave de esta arquitectura aparece en la separación entre plano de control y plano de datos. El plano de control gestiona asignaciones, planificación, distribución del almacenamiento y monitorización continua. El plano de datos ejecuta las transacciones, procesa consultas SQL y mantiene la replicación entre nodos. Esta separación permite que mejoras internas, actualizaciones o redistribuciones se desplieguen sin interrupciones para el usuario final. La plataforma funciona como un organismo autónomo que reconfigura recursos según fluctuaciones del entorno, eliminando la necesidad de ajustes manuales frecuentes.
La sincronización temporal como piedra angular
El mecanismo que sostiene su consistencia global se fundamenta en TrueTime, la tecnología que Google desarrolló a partir de relojes atómicos y GPS de alta precisión. TrueTime proporciona un intervalo de tiempo garantizado y extremadamente estrecho, lo que evita conflictos entre transacciones ubicadas en regiones distintas. Cada operación se valida dentro de un margen temporal controlado, lo que permite transacciones distribuidas con consistencia externa, un logro que muchos motores de bases de datos distribuidas solo pueden aproximar mediante técnicas más costosas o menos precisas. Esta sincronización impulsa escenarios OLTP globales con una estabilidad que resulta crítica en multinacionales que manejan pedidos, pagos o inventario en tiempo real.
El modelo relacional extendido que utiliza Cloud Spanner ofrece una estructura basada en tablas, columnas, relaciones y claves primarias, pero incorpora un sistema interno de intercalado jerárquico (interleaving) que facilita la agrupación física de tablas relacionadas. Esto ayuda a minimizar latencias y reduce el número de saltos al procesar transacciones comunes entre entidades vinculadas. En entornos con alta actividad transaccional, esta estrategia multiplica la eficiencia al mantener los datos que “viajan juntos” dentro de los mismos fragmentos o nodos cercanos.
Otro elemento diferenciador radica en la forma en que el motor gestiona la concurrencia. Spanner aplica un esquema de control que usa multiversión y bloqueos optimizados, de modo que múltiples transacciones pueden avanzar sin generar esperas prolongadas. La plataforma aplica validaciones de forma distribuida, apoyándose en TrueTime para eliminar ambigüedades. Esto impulsa un uso altamente eficiente del hardware subyacente y permite que cargas de lectura/escritura se mantengan fluidas incluso cuando alcanzan picos pronunciados.
Comparada con bases de datos tradicionales que dependen de escalado vertical, Spanner adopta un enfoque centrado en el crecimiento horizontal. La plataforma añade nodos sin alterar el esquema ni provocar redistribuciones manuales, de modo que las aplicaciones continúan funcionando mientras el sistema incrementa su capacidad. Este comportamiento encaja con patrones modernos de microservicios y arquitecturas nativas en la nube, donde los sistemas necesitan absorber crecimientos repentinos sin rediseños estructurales.
En términos conceptuales, Cloud Spanner ocupa un espacio intermedio entre motores SQL clásicos y almacenes NoSQL altamente distribuidos. Ofrece transacciones ACID reales, consultas SQL y estructuras relacionales, al tiempo que mantiene escalado automático, replicación multirregional y distribución global típicas del universo NoSQL. Esa combinación resulta valiosa para organizaciones que necesitan capacidades analíticas y transaccionales sin sacrificar consistencia ni latencia. Sus capacidades permiten afrontar desafíos que, en entornos tradicionales, demandarían múltiples sistemas o arquitecturas híbridas más complejas.
El sistema de replicación Paxos y la consistencia externa
Spanner implementa un esquema de replicación síncrona basada en Paxos, donde cada grupo de réplicas (denominado Paxos group) alcanza consenso sobre cada operación de escritura. Una transacción se considera confirmada cuando una mayoría de réplicas —el quórum— acuerda registrarla. El mecanismo Paxos constituye un componente crítico de la arquitectura de Spanner, operando sobre el principio del consenso distribuido. Garantiza que un grupo de réplicas acuerde un valor único, como la confirmación de una transacción o qué líder gestiona las actualizaciones. Una réplica en cada grupo Paxos actúa como líder, manejando todas las operaciones de escritura para su partición, mientras las demás réplicas procesan solicitudes de lectura para mejorar el rendimiento.
Este diseño proporciona consistencia externa, el nivel más estricto de garantías de concurrencia. El sistema se comporta como si todas las transacciones se ejecutaran secuencialmente, aunque Spanner las procese en paralelo a través de múltiples servidores y centros de datos. Si una transacción completa antes de que otra inicie su confirmación, Spanner garantiza que ningún cliente observará jamás un estado que incluya los efectos de la segunda pero no de la primera.
Arquitectura de almacenamiento: Colossus y la separación compute-storage
Los datos de Spanner residen en Colossus, el sistema de archivos distribuido y replicado de Google, heredero del legendario Google File System. Esta separación entre cómputo y almacenamiento proporciona ventajas significativas en la redistribución de carga, ya que los datos no quedan vinculados a nodos individuales. Si un nodo o zona falla, la base de datos permanece disponible sin intervención manual, servida por los nodos restantes.
Cada tabla se almacena ordenada por clave primaria y se divide en rangos contiguos denominados splits. Estos splits se gestionan de forma completamente independiente por diferentes nodos de Spanner, y su número varía dinámicamente según el volumen de datos y la carga de trabajo. Este resharding dinámico automático elimina la necesidad de particionar manualmente las bases de datos, una tarea operativamente costosa en sistemas tradicionales como MySQL fragmentado.
La inversión técnica detrás de Spanner coloca a esta base de datos dentro de un segmento muy particular: plataformas capaces de manejar millones de transacciones por segundo distribuidas en continentes múltiples sin que el consumidor final perciba discrepancias. Desde la perspectiva de infraestructura, cada capa del sistema —almacenamiento, comunicaciones, reloj distribuido, protocolos de replicación y optimizadores SQL— coopera para mantener desempeño, coherencia y estabilidad, algo que normalmente requiere grandes equipos dedicados cuando se utilizan tecnologías tradicionales.
Rendimiento, escalabilidad y disponibilidad
El rendimiento constituye uno de los elementos más analizados al evaluar Google Cloud Spanner, especialmente en organizaciones donde cada milisegundo impacta directamente en ingresos o experiencia de usuario. Spanner gestiona el rendimiento mediante una combinación de fragmentación dinámica, replicación inteligente y optimización interna del plano de ejecución SQL. La plataforma redistribuye fragmentos de forma continua según el patrón de carga, lo que permite que lecturas y escrituras fluyan sin cuellos de botella prolongados. Esta lógica evita saturaciones localizadas y mantiene la capacidad de respuesta durante picos repentinos, un comportamiento que marcas globales valoran cuando afrontan eventos de tráfico impredecible.
El sistema de fragmentación no funciona como un simple particionamiento estático; utiliza métricas en tiempo real sobre accesos, latencias y volumen de transacciones para reajustar automáticamente la colocación de los datos. Cuando un fragmento recibe más operaciones de las previstas, la plataforma divide su contenido y redistribuye la carga en nodos adicionales. Esto facilita un crecimiento continuo sin fricciones y evita que los equipos técnicos tengan que planificar ampliaciones manuales, operación que suele consumir mucho tiempo en motores tradicionales.
En cuanto al escalado horizontal, Spanner aprovecha su diseño multirregión para aumentar potencia sin interrupciones. Añadir nodos incrementa la capacidad de procesamiento y almacenamiento, mientras la plataforma ajusta internamente los fragmentos hacia la nueva arquitectura. Esta capacidad resulta especialmente útil en organizaciones que avanzan hacia modelos multinube híbridos o arquitecturas event-driven, donde el volumen de datos fluctúa constantemente. La ampliación transparente permite ciclos de vida más ágiles, con menos dependencia de operaciones manuales y menos riesgo de configuraciones erróneas.
La disponibilidad constituye otro pilar clave. Configuraciones multirregión permiten que la plataforma mantenga operaciones incluso durante fallos completos de zonas o centros de datos. Cada réplica interviene en un protocolo de consenso que valida las transacciones, lo que garantiza continuidad operativa sin depender de un único punto crítico. En entornos donde una interrupción de minutos puede traducirse en pérdidas significativas —por ejemplo, plataformas de pagos, marketplaces globales o juegos online multijugador—, esta distribución geográfica aporta una ventaja notable.
La sincronización proporcionada por TrueTime también influye directamente en la disponibilidad. Al gestionar ventanas temporales con precisión, el sistema evita condiciones de carrera, inconsistencias y reintentos innecesarios. Esto reduce la probabilidad de bloqueos prolongados y mantiene la fluidez del tráfico en regiones separadas por miles de kilómetros. Además, la replicación síncrona consigue que las lecturas devuelvan datos completamente actualizados sin depender de mecanismos de consistencia eventual, algo que en otros motores puede multiplicar los errores en aplicaciones transaccionales.
Otro aspecto relevante del rendimiento aparece en el manejo de transacciones de larga duración. Spanner incluye optimizaciones para limitar los bloqueos y liberar recursos cuando detecta operaciones que podrían afectar a múltiples fragmentos. Esto contribuye a un comportamiento más estable en situaciones complejas, como cálculos financieros, procesos de facturación o actualizaciones masivas de inventario. La plataforma incorpora algoritmos que monitorizan continuamente los planes de ejecución y ajustan rutas internas para evitar saturaciones.
En escenarios de latencia, Spanner ofrece un comportamiento predecible gracias a su distribución equilibrada y a la ubicación estratégica de réplicas. Las consultas locales mantienen tiempos de respuesta competitivos, mientras las transacciones globales aprovechan el control temporal de TrueTime para entregar coherencia sin tiempos de espera excesivos. Para aplicaciones con usuarios distribuidos, esta combinación evita la penalización típica de sistemas que dependen de una única región o que utilizan replicación con retrasos apreciables.
La plataforma también incluye mecanismos de autosupervisión que detectan anomalías en el rendimiento y actúan antes de que la degradación afecte a la experiencia de usuario. Esta inteligencia operativa incorpora métricas avanzadas sobre saturación de CPU, latencia en discos, cuellos en la red interna y ralentizaciones en replicación. Cuando algo supera los umbrales previstos, el sistema reequilibra fragmentos, reajusta réplicas o activa recursos adicionales de forma automática.
Finalmente, la combinación de escalabilidad instantánea, replicación multirregión y una estrategia sólida de sincronización temporal aporta una arquitectura capaz de soportar cargas extremas con un nivel alto de estabilidad. Para empresas que necesitan ejecutar servicios globales y mantener coherencia absoluta, Spanner ofrece un equilibrio difícil de alcanzar con alternativas tradicionales.
Capacidades Multi-Modelo: Un Ecosistema Unificado
Spanner Graph: Consultas de grafos sobre datos relacionales
Anunciado durante la conferencia Cloud Next en Tokio, Spanner Graph representa una funcionalidad gestionada que integra capacidades de grafos, relacionales, búsqueda e inteligencia artificial dentro de Spanner. Esta nueva base de datos soporta una interfaz de consultas de grafos compatible con el estándar ISO GQL (Graph Query Language), evitando la necesidad de mantener una base de datos de grafos independiente.
La verdadera potencia de Spanner Graph reside en su interoperabilidad completa con SQL. Las tablas pueden mapearse declarativamente a grafos sin migrar los datos, habilitando consultas que combinan GQL para recorrer relaciones y SQL para operaciones tradicionales. Esto permite casos de uso como detección de fraude, motores de recomendación, seguridad de redes, grafos de conocimiento, planificación de rutas y trazabilidad de linaje de datos.
Búsqueda vectorial para aplicaciones de IA
Spanner ahora soporta búsqueda de embeddings vectoriales a escala prácticamente ilimitada, con soporte tanto para búsqueda de vecinos más cercanos exacta (KNN) como aproximada (ANN). Con soporte vectorial para Spanner, los desarrolladores pueden realizar búsquedas de similitud sobre embeddings almacenados en la base de datos. La búsqueda vectorial de Spanner proporciona flexibilidad para diferentes cargas de trabajo mediante el algoritmo ScaNN (Scalable Nearest Neighbors) de Google.
Esta capacidad elimina la necesidad de soluciones de bases de datos vectoriales especializadas, proporcionando garantías transaccionales sobre los datos operacionales, resultados de búsqueda frescos y consistentes, y una arquitectura serverless escalable sin sobrecarga de gestión. Spanner soporta actualmente búsquedas vectoriales escalando a más de 10.000 millones de vectores, habilitando aplicaciones de GraphRAG y agentes de IA conectados a datos empresariales actualizados.
Búsqueda de texto completo integrada
La funcionalidad de full-text search incorporada aprovecha los aprendizajes de Google Search para proporcionar búsqueda de alto rendimiento transaccionalmente consistente. Las capacidades incluyen búsqueda fonética, coincidencia basada en N-gramas para variaciones ortográficas, y resultados que reflejan el estado actual de los datos sin los retrasos típicos de sincronización con sistemas de búsqueda externos.
Ediciones y Modelo de Precios: Flexibilidad para Cada Necesidad
Estructura de ediciones desde septiembre 2024
Spanner editions constituye un modelo de precios basado en niveles que proporciona diferentes capacidades a distintos puntos de precio. Spanner ofrece las siguientes ediciones:
- Standard edition proporciona un conjunto completo de capacidades establecidas incluyendo todas las funcionalidades GA anteriores a septiembre de 2024, junto con capacidades adicionales selectas como reverse ETL desde BigQuery y backups programados en configuraciones regionales. Representa la opción más económica para equipos que no requieren funcionalidades multi-modelo ni distribución multi-regional.
- Enterprise edition amplía la edición Standard y ofrece capacidades multi-modelo incluyendo Spanner Graph, búsqueda de texto completo y búsqueda vectorial, además de autoescalado gestionado y backups incrementales.
- Enterprise Plus edition atiende las cargas de trabajo más exigentes que requieren disponibilidad del 99.999% con configuraciones multi-región y soporte de geo-particionamiento.
Esta estructura permite a las organizaciones seleccionar el nivel apropiado según sus requisitos específicos:
Componentes del coste
El precio de Spanner se compone de varios elementos: capacidad de cómputo (medida en processing units o nodos, donde 1 nodo equivale a 1000 processing units), almacenamiento de base de datos (con opciones SSD para baja latencia y HDD para datos de acceso menos frecuente), almacenamiento de backups, replicación inter-regional y uso de red.
Google anunció mejoras significativas de precio-rendimiento para Cloud Spanner, proporcionando hasta un 50% de incremento en throughput y 2.5 veces más almacenamiento por nodo sin cambio en el precio. La alta capacidad de Spanner, escalado virtualmente ilimitado, latencia de milisegundos de un solo dígito, SLA de disponibilidad de cinco nueves y semántica de consistencia externa fuerte están ahora disponibles a la mitad del coste de Amazon DynamoDB para la mayoría de cargas de trabajo.
Los descuentos por compromiso de uso (CUDs) ofrecen reducciones adicionales: un 20% para compromisos de un año y un 40% para compromisos de tres años, aplicables a todos los proyectos, regiones y multi-regiones asociados a una cuenta de facturación.
Modelo de desarrollo y características para equipos técnicos
El modelo de desarrollo que propone Google Cloud Spanner introduce un enfoque que combina expresividad SQL con mecanismos avanzados de distribución y replicación. Esta combinación permite que los equipos técnicos trabajen con estructuras relacionales familiares mientras aprovechan un entorno altamente automatizado. El lenguaje SQL de Spanner conserva la mayoría de instrucciones clásicas, aunque incorpora extensiones y limitaciones específicas que optimizan las operaciones distribuidas. Las consultas utilizan un optimizador interno que analiza fragmentos, réplicas y estadísticas para decidir la ruta más adecuada en cada operación, lo que garantiza que las peticiones circulen con eficiencia entre regiones y nodos.
Dentro de su conjunto de funcionalidades, Spanner ofrece DDL online, lo que facilita cambios de esquema sin detener servicios ni bloquear tablas durante períodos prolongados. Equipos que gestionan sistemas vivos con grandes volúmenes de datos pueden ajustar estructuras, añadir columnas o introducir índices mientras la plataforma continúa procesando transacciones. Esta capacidad elimina ciclos de mantenimiento nocturnos y reduce la presión operativa que suelen sufrir bases de datos más convencionales. Al mismo tiempo, el motor analiza automáticamente el impacto del cambio, reorganiza fragmentos afectados y mantiene la coherencia durante todo el proceso.
En el ámbito del desarrollo, la plataforma incorpora un conjunto de bibliotecas cliente en Java, Go, Node.js, Python, C++ y otros lenguajes utilizados por equipos corporativos. Estas bibliotecas incluyen capacidades de conexión, administración de sesiones y ejecución de consultas optimizadas para entornos distribuidos. La lógica interna gestiona reintentos, enrutamiento y métricas avanzadas, por lo que el desarrollador mantiene un enfoque en la funcionalidad del negocio sin tener que preocuparse por otros detalles.
La integración con el ecosistema de Google Cloud destaca como uno de los pilares que impulsan la adopción de Spanner. La plataforma utiliza IAM para gestionar permisos mediante roles granulares, lo que permite controlar el acceso a tablas, instancias o proyectos completos. Además, Spanner se conecta de forma fluida con Cloud Dataflow, Pub/Sub, Cloud Functions, BigQuery y otros servicios que intervienen en arquitecturas de datos modernas.
En entornos donde múltiples servicios interactúan con Spanner, la red privada VPC distribuye el tráfico de manera segura y rápida. Los desarrolladores pueden desplegar microservicios en GKE, Cloud Run o Compute Engine mientras mantienen un acceso consistente hacia la base de datos, sin exposición directa hacia redes públicas. Esta arquitectura elimina puntos vulnerables y facilita auditorías internas basadas en políticas de organización, etiquetas de proyectos y monitoreo unificado.
Otro componente relevante es el sistema de monitorización y observabilidad, una pieza crítica para cualquier operación de datos a gran escala. Spanner se integra con Cloud Monitoring y Cloud Logging, lo que permite visualizar métricas como latencia por región, saturación de CPU, tamaño de fragmentos, tiempos de commit, número de lecturas y patrones de acceso. Los equipos pueden configurar alertas dinámicas que reaccionan a anomalías, activar planes de optimización o diagnosticar cuellos de botella antes de que afecten a la experiencia del usuario.
El proceso de gestión de backups también juega un papel importante en Spanner. La plataforma crea copias de seguridad sin interrumpir las operaciones de producción y permite restauraciones en instancias nuevas, lo que facilita pruebas, controles de integridad o simulaciones de recuperación ante desastres. Los equipos pueden programar ciclos automatizados y conservar copias durante períodos prolongados según normativas o requisitos legales del sector. La restauración utiliza una lógica que aprovecha fragmentación y replicación interna para reconstruir la base de forma eficiente y sin pérdida de consistencia.
A nivel de diseño de datos, Spanner introduce conceptos que ayudan a obtener el máximo rendimiento en arquitecturas distribuidas. La selección de la clave primaria resulta fundamental, ya que impacta directamente en la forma en que los datos se fragmentan. Una mala elección puede obligar al sistema a reubicar fragmentos de forma continua, mientras que una planificación adecuada mejora latencias y equilibrio de carga. Además, el mecanismo de interleaving permite agrupar físicamente tablas vinculadas mediante jerarquías, lo que reduce accesos remotos y mejora notablemente el rendimiento de transacciones frecuentes entre entidades asociadas.
Otro punto relevante para los equipos técnicos es la compatibilidad con transacciones ACID distribuidas. Spanner admite transacciones de lectura-escritura que utilizan un protocolo multiversión y control temporal para garantizar que cada operación se complete sin conflictos. Las transacciones de solo lectura pueden ejecutarse con timestamps consistentes en réplicas locales, lo que minimiza la latencia en consultas históricas o analíticas ligeras. Esta dualidad permite una operación equilibrada en sistemas con alto volumen de consultas mixtas.
Finalmente, el modelo de desarrollo en Spanner se apoya en la automatización. Ajustes internos como reorganización de fragmentos, reconstrucción de índices, redistribución entre regiones o ampliación de nodos ocurren sin intervención explícita. Esto reduce la carga operativa y libera a los equipos para enfocarse en lógica empresarial, seguridad o evolución de productos. La plataforma, al mantener un ecosistema coherente y una API limpia, ofrece una experiencia de trabajo sólida para arquitectos, desarrolladores y operadores que buscan estabilidad a largo plazo.
Casos de Uso y Sectores de Aplicación
Servicios financieros y fintech
Las instituciones financieras requieren garantías absolutas de consistencia, auditoría completa y cumplimiento normativo estricto. Spanner satisface estos requisitos proporcionando transacciones ACID globales, replicación síncrona entre regiones y certificaciones de cumplimiento para PCI DSS, SOC 1/2/3 e HIPAA. Plataformas de trading, sistemas bancarios y procesadores de pagos como Vodeno aprovechan estas capacidades para manejar millones de transacciones financieras manteniendo consistencia perfecta.
Gaming y entretenimiento interactivo
Ninguna industria pone a prueba la escalabilidad de una base de datos tanto como la de videojuegos. Un nuevo título exitoso puede atraer millones de jugadores el día del lanzamiento, y todos representan un potencial significativo de ingresos desde gameplay en tiempo real y compras dentro del juego. Esta audiencia no tolerará frustración ni tiempo de inactividad.
Spanner proporciona escalabilidad horizontal ilimitada tanto regional como globalmente, permitiendo escalar para acomodar picos súbitos de tráfico con un simple clic. El carácter auto-gestionado de Spanner elimina pausas para parches, backups, failover o incluso actualizaciones de esquema. Estudios como Lucille Games han migrado a Spanner para garantizar experiencias de juego consistentes globalmente sin interrupciones.
Retail y gestión de inventario
Cada rotura de stock envía tu venta y tu cliente a la competencia. Además, debes planificar para picos estacionales de negocio. En el pasado, la solución predeterminada consistía en sobreprovisionar hardware anticipando la demanda estacional. Este costoso enfoque para manejar picos de uso ahora ya no es necesario.
Spanner ofrece escalado elástico para satisfacer aumentos de demanda, facturando únicamente por ese incremento de escala durante el tiempo que resulte necesario. Empresas como L.L.Bean y Walmart han modernizado sus plataformas de gestión de datos con Spanner, proporcionando una fuente única de verdad para inventario y pedidos a través de canales online, tiendas físicas, centros de distribución y envíos.
Telecomunicaciones y tecnología
Compañías como Optiva utilizan Spanner para sistemas de facturación y gestión de clientes que demandan alta disponibilidad, consistencia fuerte y capacidad de escalar globalmente. La industria de telecomunicaciones requiere bases de datos capaces de manejar millones de registros de llamadas, sesiones de datos y eventos de facturación sin perder un solo registro.
Salud y ciencias de la vida
Organizaciones como Maxwell Plus confían en Spanner para cargas de trabajo de datos de salud que requieren cumplimiento HIPAA, encriptación rigurosa y control de acceso granular. La capacidad de Spanner para proporcionar consistencia fuerte resulta crítica cuando la integridad de datos médicos impacta directamente en decisiones clínicas.
Integración con el Ecosistema Google Cloud
BigQuery y analítica sin fricción
La integración bidireccional entre Spanner y BigQuery proporciona un flujo de datos sin interrupciones entre cargas de trabajo transaccionales y analíticas. Data Boost permite ejecutar consultas analíticas, trabajos de procesamiento por lotes u operaciones de exportación sin afectar las cargas transaccionales existentes, utilizando recursos de cómputo independientes siempre disponibles y sin necesidad de planificación de capacidad.
La funcionalidad reverse ETL desde BigQuery permite transformaciones SQL y la operacionalización de insights analíticos directamente en Spanner, habilitando casos de uso como servir analíticas complejas con alta QPS y baja latencia computadas en BigQuery y servidas desde Spanner.
Vertex AI y aplicaciones de inteligencia artificial
La integración nativa con Vertex AI facilita la construcción de aplicaciones de IA generativa más precisas, transparentes y fiables. Los desarrolladores pueden aprovechar la función ML.PREDICT de GoogleSQL para convertir texto de consulta en lenguaje natural a embeddings y realizar búsqueda vectorial ANN, todo dentro de la misma transacción que accede a datos relacionales.
Database Center: Gestión unificada
Database Center representa una solución de gestión de bases de datos unificada potenciada por IA para monitorizar y administrar servicios de bases de datos diversos. Durante 2024, los clientes comenzaron a utilizar Database Center para gestionar sus bases de datos Spanner, con soporte añadido para trazado end-to-end y trazado de cliente para facilitar la resolución de problemas de rendimiento.
Migración y Compatibilidad
Interfaz PostgreSQL: Familiaridad sin compromiso
Utilizar PostgreSQL a través de tu portfolio de bases de datos significa menos variaciones entre productos específicos y un conjunto común de mejores prácticas. La interfaz PostgreSQL proporciona todas las ventajas de disponibilidad, consistencia y precio-rendimiento existentes de Spanner sin comprometer ninguna de las capacidades disponibles en el ecosistema GoogleSQL complementario.
La interfaz PostgreSQL compila consultas PostgreSQL a las primitivas de procesamiento de consultas distribuidas y almacenamiento existentes de Spanner, soportando también el protocolo wire de PostgreSQL para conectividad de clientes. PGAdapter, un proxy ligero que se ejecuta junto a la aplicación, traduce el protocolo wire de PostgreSQL a las APIs gRPC de bajo nivel de Spanner sin añadir latencia perceptible.
Resulta importante comprender que la interfaz PostgreSQL no soporta todas las funcionalidades de PostgreSQL nativo. La migración de una aplicación PostgreSQL existente a Spanner, incluso utilizando la interfaz PostgreSQL, probablemente requiere cierta reelaboración para acomodar capacidades PostgreSQL no soportadas o diferencias de comportamiento, como optimización de consultas o diseño de claves primarias.
Herramientas de migración
La Spanner Migration Tool (SMT) automatiza la conversión de esquemas y migración de datos desde MySQL y PostgreSQL, manejando automáticamente muchos problemas de compatibilidad. Para migración continua de datos, Cloud Dataflow ofrece capacidades tanto batch como streaming a través del conector SpannerIO.
El proceso de migración con mínimo tiempo de inactividad aprovecha Datastream y Dataflow para migrar datos existentes y transmitir cambios realizados en la base de datos origen durante la migración. La Data Validation Tool (DVT) proporciona un método estandarizado de validación de datos soportado por la comunidad open source e integrable con productos Google Cloud existentes.
Interfaz compatible con Cassandra
Spanner ofrece una interfaz compatible con Cassandra que soporta cambios de código de aplicación cercanos a cero cuando se migra desde Cassandra. Esta funcionalidad, actualmente en preview, permite a organizaciones que han invertido en aplicaciones Cassandra beneficiarse de las garantías de Spanner sin reescrituras extensivas.
Seguridad y Cumplimiento Normativo
Encriptación multicapa
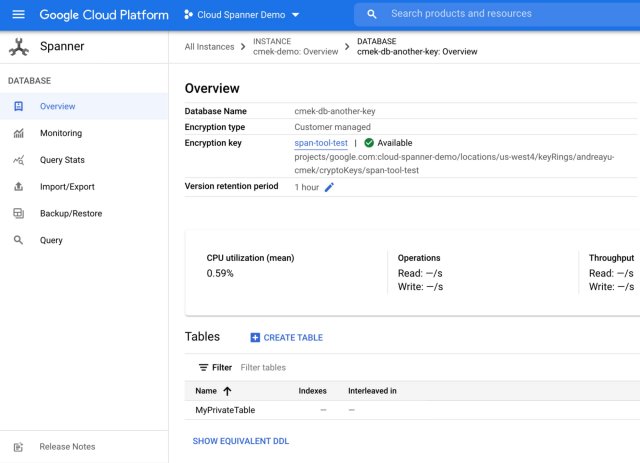
Desde una perspectiva de seguridad, Spanner ya ofrece por defecto encriptación para datos en tránsito a través de sus bibliotecas cliente y para datos en reposo utilizando claves de encriptación gestionadas por Google. Para organizaciones con requisitos más estrictos, Customer-Managed Encryption Keys (CMEK) proporciona control completo sobre las claves de encriptación.
La integración con Cloud KMS permite generar, usar, rotar y destruir claves criptográficas. Los clientes que necesitan un nivel de seguridad incrementado pueden elegir claves de encriptación protegidas por hardware, alojando claves y realizando operaciones criptográficas en Hardware Security Modules (HSMs) validados FIPS 140-2 Level 3.
Certificaciones y cumplimiento
Spanner proporciona soporte de VPC Service Controls y tiene certificaciones de cumplimiento y aprobaciones necesarias para cargas de trabajo que requieren ISO 27001, 27017, 27018, PCI DSS, SOC1/2/3, HIPAA y FedRAMP.
Estas certificaciones resultan críticas para organizaciones en industrias reguladas. Los servicios financieros requieren PCI DSS para procesamiento de tarjetas, las organizaciones de salud necesitan cumplimiento HIPAA para datos de pacientes, y las agencias gubernamentales demandan FedRAMP para información federal sensible.
Controles de acceso y auditoría
El sistema Identity and Access Management (IAM) de Google Cloud proporciona gestión de acceso granular, permitiendo definir permisos específicos a nivel de instancia, base de datos o incluso tabla. Access Transparency proporciona logs en tiempo casi real donde el personal de soporte e ingeniería de Google registra justificaciones de negocio para cualquier acceso a datos del cliente.
VPC Service Controls previene la exfiltración no autorizada de datos aplicando límites de seguridad de red, mientras que Access Approval permite a los clientes aprobar explícitamente accesos de personal de Google antes de que ocurran.
Rendimiento y Optimización
Métricas de capacidad
Benchmarks recientes revelan las impresionantes capacidades de Spanner: las instancias regionales soportan hasta 15.000 lecturas por segundo y 2.700 escrituras por segundo por nodo. Alcanzar estos números requiere orquestación ETL cuidadosa, ordenando datos por clave primaria antes de inserción, manteniendo tamaños de transacción dentro de rangos óptimos y manteniendo utilización de CPU por debajo del 65% para cargas de trabajo de producción.
Estrategias de optimización de esquema
El diseño de claves primarias impacta significativamente en el rendimiento de Spanner. Las tablas con escrituras frecuentes deben evitar claves que incrementan o decrementan monótonamente, ya que crean hotspots que degradan el rendimiento. Las estrategias recomendadas incluyen:
- UUIDs versión 4 generados mediante la función GENERATE_UUID()
- Secuencias bit-reversed positivas que distribuyen valores uniformemente
- Prefijado de hash para claves secuenciales existentes que deban preservarse
Las tablas intercaladas permiten definir relaciones padre-hijo de uno a muchos, almacenando filas hijas junto a sus padres para optimizar consultas que acceden a datos relacionados. Spanner soporta hasta 6 niveles de relaciones padre-hijo intercaladas.
Autoescalado gestionado
El autoescalador gestionado disponible en Enterprise Edition y superiores ajusta automáticamente la capacidad de cómputo basándose en la demanda de la carga de trabajo. Esto elimina la necesidad de monitorizar continuamente la utilización y ajustar manualmente el número de nodos, aunque resulta importante entender que el escalado implica mover splits entre servidores, lo que puede incrementar temporalmente las latencias de cola.
Puntos Fuertes y Consideraciones
Ventajas competitivas distintivas
Consistencia global sin compromisos: Spanner permanece como la única base de datos comercial que proporciona transacciones ACID con consistencia externa a escala planetaria. Google Cloud utiliza relojes atómicos, mientras otras bases de datos como CockroachDB y YugabyteDB usan software como el algoritmo de consenso Raft para garantizar consistencia.
Disponibilidad cinco nueves: El SLA del 99.999% para configuraciones multi-región significa menos de 5.26 minutos de tiempo de inactividad anual. Esta garantía incluye cero tiempo de inactividad para mantenimiento planificado y cambios de esquema.
Experiencia multi-modelo verdadera: A diferencia de otras bases de datos multi-modelo que requieren movimiento de datos o presentan inconsistencias entre modelos, Spanner ofrece interoperabilidad completa donde relacional, grafos, clave-valor y búsqueda vectorial operan sobre los mismos datos consistentes.
Cero mantenimiento operacional: No existen ventanas de mantenimiento, actualizaciones de software ni optimizaciones de instancia que requieran intervención manual o tiempo de inactividad.
Aspectos a considerar
Curva de aprendizaje inicial: Aunque Spanner soporta SQL, sus características únicas —como el diseño de claves primarias anti-hotspot, tablas intercaladas y comportamiento transaccional específico— requieren formación para desarrolladores acostumbrados a bases de datos relacionales tradicionales.
Representa vendor lock-in y el precio resulta elevado en algunos casos. La dependencia exclusiva del ecosistema Google Cloud significa que migrar fuera de Spanner requiere un esfuerzo significativo, aunque la interfaz PostgreSQL mitiga parcialmente esta preocupación.
Coste de entrada: Aunque Spanner ahora ofrece instancias de prueba gratuitas durante 90 días y configuraciones mínimas desde aproximadamente 40 dólares mensuales, las cargas de trabajo de producción con requisitos de alta disponibilidad pueden representar inversiones significativas. Cloud Spanner constituye un producto bastante caro de Google Cloud. Su rango de precios varía desde 2.70 a 28 dólares por hora para una instancia de producción mínima de tres nodos, excluyendo el coste de almacenamiento.
Emulador con limitaciones: Los usuarios encuentran complicado ejecutar Spanner localmente debido a las limitaciones del emulador. El emulador oficial, aunque disponible GA desde julio 2020, no replica completamente el comportamiento del producto real, complicando ciertos escenarios de desarrollo y pruebas locales.
Google Cloud Spanner: Fortalezas y Debilidades
Análisis comparativo completo para la toma de decisiones empresariales
¿Merece la pena Google Cloud Spanner?
Google Cloud Spanner destaca como la única base de datos relacional del mercado capaz de ofrecer escalabilidad horizontal ilimitada junto con transacciones ACID globales y consistencia externa. Sin embargo, esta potencia conlleva un coste elevado y dependencia exclusiva del ecosistema Google Cloud. La decisión de adopción debe evaluar si los requisitos de la aplicación justifican la inversión frente a alternativas más económicas o portables.
Tabla Comparativa: Fortalezas vs Debilidades
| Categoría | ✅ Fortalezas | ❌ Debilidades |
|---|---|---|
| Escalabilidad | Escalado horizontal ilimitado sin reingeniería. Crece de gigabytes a petabytes automáticamente | Requiere rediseño de claves primarias para evitar hotspots en cargas de escritura intensiva |
| Consistencia | Consistencia externa global mediante TrueTime. Garantías ACID en transacciones multi-región | La sincronización TrueTime añade latencia en escrituras geográficamente dispersas |
| Disponibilidad | SLA 99.999% (cinco nueves) en configuraciones multi-región. Menos de 5 minutos de downtime anual | Las configuraciones de alta disponibilidad requieren Enterprise Plus Edition con coste significativamente mayor |
| Rendimiento | 15.000 lecturas/segundo y 2.700 escrituras/segundo por nodo. Latencia de milisegundos | El escalado de nodos no resulta instantáneo; puede generar latencias temporales durante redistribución |
| Modelo de datos | Soporte multi-modelo: relacional, grafos (GQL), clave-valor y vectorial en una única plataforma | La interfaz PostgreSQL no soporta todas las funcionalidades nativas; requiere adaptación de código |
| Operaciones | Completamente gestionado. Cero mantenimiento, parches automáticos, backups sin downtime | Emulador local limitado dificulta desarrollo y testing con comportamiento idéntico a producción |
| Integraciones | Integración nativa con BigQuery, Vertex AI, Dataflow y todo el ecosistema Google Cloud | Vendor lock-in exclusivo con Google Cloud. Migración de salida compleja y costosa |
| Seguridad | Certificaciones HIPAA, PCI DSS, SOC 1/2/3, FedRAMP, ISO 27001. Encriptación por defecto | Las opciones de CMEK y HSM incrementan costes y complejidad de gestión de claves |
| Costes | Descuentos CUD hasta 40% con compromisos de 3 años. Data Boost para analytics sin impacto | Precio de entrada elevado: instancias de producción desde 2.000-20.000 USD/mes |
| IA y Analytics | Búsqueda vectorial escalando a 10.000M+ vectores. Integración ML.PREDICT con Vertex AI | Las capacidades multi-modelo avanzadas requieren Enterprise Edition o superior |
Comparativa con Alternativas del Mercado
Frente a Amazon Aurora
Google Cloud Spanner proporciona escalabilidad horizontal sin sacrificar consistencia ni rendimiento. Spanner puede escalar sin problemas para manejar millones de solicitudes por segundo distribuyendo datos a través de múltiples regiones y gestionando automáticamente sharding y replicación. Amazon Aurora, aunque ofrece rendimiento similar y compatibilidad MySQL/PostgreSQL, carece de replicación global con consistencia fuerte —sus réplicas de lectura proporcionan consistencia eventual.
Aurora destaca en escenarios donde la compatibilidad MySQL/PostgreSQL nativa resulta prioritaria y la distribución multi-región con consistencia fuerte no constituye un requisito. Su modelo serverless ofrece escalado automático basado en demanda, aunque limitado a una única región primaria.
Frente a CockroachDB
A pesar de las similitudes arquitectónicas con Google Spanner, solo CockroachDB proporciona la libertad de desplegar tu base de datos en cualquier lugar y en cualquier cloud. CockroachDB representa la principal alternativa open source inspirada en Spanner, ofreciendo portabilidad multi-cloud y evitando vendor lock-in.
CockroachDB proporciona capacidades como commits paralelos y pipelining para optimizar transacciones globalmente distribuidas, además de DDL simple que permite definir dónde residirán los datos a través de múltiples regiones. Sin embargo, Spanner mantiene ventajas en rendimiento bruto, integración con el ecosistema Google Cloud y madurez del producto tras más de una década de operación interna en Google.
Frente a Amazon DynamoDB
DynamoDB excela en cargas de trabajo clave-valor puras con latencias de milisegundos de un solo dígito, pero no ofrece el mismo modelo relacional ni soporte SQL que Spanner. Spanner ofrece ahora hasta 2x mejor throughput de lectura por dólar comparado con Amazon DynamoDB para cargas de trabajo similares.
Para equipos que requieren semántica relacional y transacciones complejas, Spanner presenta ventajas significativas. DynamoDB resulta más apropiado para patrones de acceso clave-valor simples donde la flexibilidad de esquema y el precio por operación individual constituyen prioridades.
Matriz de Decisión: ¿Cuándo elegir Spanner?
| Requisito | Recomendación |
|---|---|
| Necesito transacciones ACID globales con consistencia fuerte | ✅ Spanner ideal |
| Mi aplicación debe escalar a millones de transacciones/segundo | ✅ Spanner ideal |
| Requiero 99.999% de disponibilidad garantizada por SLA | ✅ Spanner ideal |
| Mi presupuesto mensual para base de datos supera 5.000 USD | ✅ Spanner viable |
| Necesito portabilidad multi-cloud o despliegue on-premise | ❌ Considerar CockroachDB |
| Mi carga de trabajo cabe en menos de 10TB sin distribución global | ❌ Considerar Cloud SQL |
| Requiero compatibilidad 100% PostgreSQL sin adaptaciones | ❌ Considerar Cloud SQL PostgreSQL |
| Mi presupuesto mensual permanece por debajo de 500 USD | ❌ Considerar alternativas |
Conclusiones y Recomendaciones
Perfil de organización ideal
Google Cloud Spanner representa la elección óptima para organizaciones que cumplen varios de estos criterios:
- Requisitos de consistencia global: Aplicaciones que demandan garantías transaccionales ACID a través de múltiples regiones geográficas sin compromisos de consistencia eventual.
- Escala masiva sin límites predefinidos: Cargas de trabajo que necesitan crecer desde gigabytes hasta petabytes sin reingeniería de la capa de datos ni migraciones dolorosas.
- Disponibilidad de misión crítica: Sistemas donde cinco nueves de disponibilidad resultan un requisito de negocio, no una aspiración.
- Inversión existente en Google Cloud: Organizaciones que ya aprovechan BigQuery, Vertex AI u otros servicios de Google Cloud y buscan maximizar sinergias.
- Simplificación de arquitectura de datos: Equipos que desean consolidar bases de datos relacionales, de grafos, clave-valor y búsqueda en una plataforma unificada.
Escenarios donde otras opciones podrían encajar mejor
- Presupuesto muy limitado para desarrollo/pruebas: Cloud SQL para PostgreSQL o MySQL ofrece puntos de entrada más económicos para cargas de trabajo no críticas.
- Máxima compatibilidad PostgreSQL u otras: Si la portabilidad total y compatibilidad al 100% con PostgreSQL constituyen requisitos inamovibles, Cloud SQL o instalaciones PostgreSQL gestionadas resultan más apropiadas.
- Multi-cloud como requisito estratégico: Organizaciones comprometidas con estrategias multi-cloud deberían evaluar CockroachDB u otras alternativas portables.
Idoneidad de Spanner por perfil de empresa
✅ Spanner resulta excelente para:
- Empresas financieras que procesan transacciones globales
- Plataformas de gaming con millones de usuarios concurrentes
- Retailers omnicanal con inventario distribuido globalmente
- Aplicaciones de IA que requieren datos operacionales + vectoriales
- Organizaciones ya comprometidas con Google Cloud
❌ Spanner probablemente no encaja para:
- Startups en etapas tempranas con presupuesto ajustado
- Aplicaciones regionales sin requisitos de distribución global
- Equipos que priorizan portabilidad y evitan vendor lock-in
- Proyectos que requieren compatibilidad PostgreSQL/MySQL exacta
- Cargas de trabajo puramente analíticas (mejor BigQuery)
En definitiva
Google Cloud Spanner materializa una propuesta tecnológica sin equivalente directo en el mercado: una base de datos relacional que escala horizontalmente sin sacrificar las garantías transaccionales que han definido a los sistemas de gestión de bases de datos durante décadas. La innovación de TrueTime —esa combinación de relojes atómicos y GPS que parecía ciencia ficción cuando Google la describió por primera vez— proporciona los fundamentos para algo que el teorema CAP sugería imposible: consistencia fuerte, disponibilidad y tolerancia a particiones, todo simultáneamente.
La evolución durante 2024 hacia una plataforma multi-modelo amplifica significativamente su propuesta de valor. Spanner Graph, búsqueda vectorial y full-text search transforman lo que anteriormente constituía una excelente base de datos relacional distribuida en un ecosistema unificado capaz de atender prácticamente cualquier carga de trabajo moderna. La capacidad de ejecutar consultas GQL sobre grafos, búsquedas semánticas con embeddings vectoriales y operaciones SQL tradicionales —todo dentro de la misma transacción ACID— elimina la complejidad arquitectónica de mantener múltiples sistemas especializados sincronizados.
El modelo de precios basado en ediciones introducido en septiembre de 2024 democratiza el acceso a Spanner, permitiendo que organizaciones con diferentes niveles de requisitos encuentren un punto de entrada apropiado. La Standard Edition ofrece las capacidades fundamentales a un coste reducido, mientras que Enterprise y Enterprise Plus desbloquean progresivamente funcionalidades multi-modelo, autoescalado gestionado y los SLAs más exigentes del mercado.
Para arquitectos de datos y responsables de tecnología que evalúan la siguiente generación de su infraestructura de datos, Spanner merece consideración seria. No constituye la opción más económica, ni la más portable. Sin embargo, representa la única opción que combina escalabilidad prácticamente ilimitada, consistencia global garantizada, disponibilidad cinco nueves y capacidades multi-modelo unificadas en un servicio completamente gestionado.
Las organizaciones que procesan transacciones financieras globales, operan plataformas de gaming con millones de usuarios concurrentes, gestionan inventarios de retail omnicanal o construyen aplicaciones de IA generativa sobre datos operacionales encontrarán en Spanner una plataforma que elimina las limitaciones tradicionales de las bases de datos. El coste de entrada se justifica cuando el coste del tiempo de inactividad, la inconsistencia de datos o la incapacidad de escalar superan ampliamente la inversión en infraestructura.
La pregunta fundamental no debería centrarse en si Spanner resulta "mejor" que las alternativas, sino en si los requisitos específicos de la organización demandan las capacidades únicas que Spanner proporciona. Para quienes la respuesta resulte afirmativa, pocas inversiones tecnológicas ofrecerán un retorno comparable en términos de simplicidad operacional, garantías de datos y libertad para escalar sin límites artificiales.
Recursos Adicionales y Siguientes Pasos
Documentación y formación
- Documentación oficial de Spanner: cloud.google.com/spanner/docs proporciona guías completas de arquitectura, mejores prácticas y referencia de APIs.
- Qwiklabs y Google Cloud Skills Boost: Laboratorios prácticos guiados que permiten experimentar con Spanner sin configuración inicial.
- Spanner Ecosystem: El repositorio github.com/cloudspannerecosystem contiene herramientas de la comunidad, ejemplos de código y extensiones.
Opciones de prueba gratuita
Google Cloud ofrece una prueba gratuita de 90 días para instancias de Spanner, proporcionando capacidad suficiente para evaluar funcionalidades y realizar pruebas de concepto. Adicionalmente, el emulador de Spanner permite desarrollo local sin costes de cloud, aunque con las limitaciones previamente mencionadas respecto a la fidelidad del comportamiento.
✅Google Cloud Spanner: Preguntas Frecuentes (FAQs)
Guía completa con respuestas a las dudas más buscadas sobre la base de datos distribuida de Google
Conceptos Básicos y Definición
¿Qué es Google Cloud Spanner y para qué sirve?
Google Cloud Spanner constituye una base de datos relacional completamente gestionada que combina la consistencia transaccional de las bases de datos SQL tradicionales con la escalabilidad horizontal ilimitada típica de los sistemas NoSQL. Desarrollada originalmente por Google para potenciar servicios internos como Gmail, Google Photos y Google Ads, esta plataforma llegó al mercado público en 2017 y actualmente procesa más de 3.000 millones de consultas por segundo en las infraestructuras internas del gigante tecnológico.
La plataforma permite construir aplicaciones de misión crítica que requieren disponibilidad global, consistencia fuerte en todas las transacciones y capacidad de escalar desde gigabytes hasta petabytes sin reingeniería. Sectores como servicios financieros, gaming, retail y telecomunicaciones utilizan Spanner para cargas de trabajo que demandan cero tolerancia a inconsistencias de datos.
¿Cómo funciona la tecnología TrueTime de Google Spanner?
TrueTime representa el componente más innovador de la arquitectura de Spanner: una API propietaria que proporciona sincronización temporal global con precisión de milisegundos. Esta tecnología combina relojes atómicos y receptores GPS redundantes instalados en todos los centros de datos de Google, mitigando las debilidades inherentes a cada sistema de forma complementaria.
A diferencia de los relojes convencionales, TrueTime reconoce explícitamente la incertidumbre temporal y devuelve intervalos con límites acotados —típicamente entre 0 y 6 milisegundos— en lugar de timestamps puntuales. Spanner utiliza estos intervalos para garantizar que las transacciones reciban timestamps únicos y ordenados globalmente, asegurando que los efectos de cualquier transacción completada resulten visibles para todas las lecturas posteriores en cualquier ubicación geográfica del planeta.
¿Qué significa que Spanner ofrece consistencia externa?
La consistencia externa representa el nivel más estricto de garantías de concurrencia disponible en sistemas distribuidos. Con esta propiedad, Spanner se comporta como si todas las transacciones se ejecutaran secuencialmente, aunque el sistema las procese en paralelo a través de múltiples servidores y centros de datos dispersos geográficamente.
En términos prácticos, esto significa que si una transacción A completa antes de que otra transacción B inicie su confirmación, ningún cliente observará jamás un estado que incluya los efectos de B pero no de A. Esta garantía elimina las anomalías de consistencia eventual que afectan a otras bases de datos distribuidas, donde diferentes usuarios pueden observar versiones distintas de los datos dependiendo de qué réplica consulten.
Comparativas y Alternativas
¿Cuál es la diferencia entre Google Cloud Spanner y Cloud SQL?
La diferencia fundamental radica en la escala y arquitectura de cada solución. Cloud SQL ofrece instancias gestionadas de MySQL, PostgreSQL y SQL Server con un límite máximo de 10TB de almacenamiento y sin escalabilidad horizontal verdadera. Spanner, por su parte, proporciona escalabilidad prácticamente ilimitada distribuyendo datos automáticamente a través de múltiples regiones.
Cloud SQL resulta apropiado para aplicaciones web tradicionales, sistemas CRM/ERP y cargas de trabajo que no superarán unos pocos terabytes. Spanner destaca cuando la aplicación requiere miles de escrituras por segundo a escala global, disponibilidad del 99.999% y transacciones ACID distribuidas. El coste también difiere significativamente: Cloud SQL arranca desde pocos dólares mensuales, mientras que Spanner requiere inversiones considerablemente mayores para configuraciones de producción.
¿Qué diferencias existen entre Spanner y PostgreSQL o MySQL?
PostgreSQL y MySQL funcionan como bases de datos monolíticas tradicionales diseñadas para ejecutarse en un único servidor o con replicación limitada. Spanner opera como un sistema nativo distribuido que fragmenta automáticamente los datos y los distribuye globalmente manteniendo consistencia fuerte.
Las diferencias clave incluyen:
- Escalabilidad: PostgreSQL/MySQL requieren sharding manual complejo para escalar horizontalmente; Spanner gestiona esto automáticamente
- Disponibilidad: Spanner garantiza hasta 99.999% de uptime en configuraciones multi-región; las bases de datos tradicionales típicamente ofrecen 99.95%
- Distribución global: PostgreSQL ofrece replicación asíncrona con consistencia eventual; Spanner proporciona replicación síncrona con consistencia fuerte
- Compatibilidad: PostgreSQL/MySQL ofrecen ecosistemas maduros con décadas de herramientas; Spanner tiene un ecosistema más limitado aunque creciente
- Coste: PostgreSQL tiene licencia open source gratuita; Spanner implica costes significativos de cloud
¿Cómo se compara Spanner con Amazon DynamoDB?
DynamoDB destaca como base de datos clave-valor optimizada para patrones de acceso simples con latencias de milisegundos de un solo dígito. Spanner ofrece un modelo relacional completo con SQL, joins, transacciones multi-tabla y consistencia externa global.
Spanner proporciona hasta 2x mejor throughput de lectura por dólar comparado con DynamoDB para cargas de trabajo similares, según benchmarks de Google. Sin embargo, DynamoDB resulta más apropiado para aplicaciones que no requieren semántica relacional, donde la flexibilidad de esquema y el precio por operación individual constituyen prioridades. La elección depende fundamentalmente de si la aplicación necesita transacciones complejas y relaciones entre entidades (favoreciendo Spanner) o acceso clave-valor simple y ultra-rápido (favoreciendo DynamoDB).
¿Spanner o CockroachDB? ¿Cuál elegir?
CockroachDB representa la principal alternativa open source inspirada en Spanner, ofreciendo portabilidad multi-cloud y evitando el vendor lock-in inherente a Google Cloud. Ambos sistemas comparten fundamentos arquitectónicos similares, incluyendo distribución automática de datos y transacciones ACID distribuidas.
Las diferencias principales incluyen:
- Sincronización temporal: Spanner utiliza TrueTime con relojes atómicos; CockroachDB emplea algoritmos de consenso Raft basados en software
- Rendimiento: Spanner mantiene ventajas en throughput bruto gracias a su infraestructura de hardware especializada
- Portabilidad: CockroachDB permite despliegues on-premise, multi-cloud o híbridos; Spanner requiere exclusivamente Google Cloud
- Madurez: Spanner lleva más de una década operando internamente en Google; CockroachDB tiene menos años de operación en producción a escala masiva
- Coste de salida: Migrar desde CockroachDB resulta más sencillo gracias a su compatibilidad PostgreSQL nativa
Funcionalidades y Capacidades
¿Spanner soporta PostgreSQL? ¿Puedo usar sintaxis PostgreSQL?
Sí, Spanner ofrece una interfaz PostgreSQL que permite utilizar sintaxis SQL familiar y el protocolo wire de PostgreSQL para conectividad de clientes. Esta interfaz compila consultas PostgreSQL a las primitivas de procesamiento distribuido de Spanner, manteniendo todas las ventajas de disponibilidad, consistencia y escalabilidad de la plataforma.
PGAdapter, un proxy ligero que se ejecuta junto a la aplicación, traduce el protocolo wire de PostgreSQL a las APIs gRPC de Spanner sin añadir latencia perceptible. Sin embargo, resulta importante comprender que la interfaz PostgreSQL no soporta todas las funcionalidades de PostgreSQL nativo. La migración de aplicaciones existentes probablemente requiere cierta reelaboración para acomodar capacidades no soportadas o diferencias de comportamiento en optimización de consultas y diseño de claves primarias.
¿Qué es Spanner Graph y cómo funciona?
Spanner Graph representa una funcionalidad que integra capacidades de grafos directamente sobre datos relacionales existentes. Anunciado durante Cloud Next en Tokio, este componente soporta el estándar ISO GQL (Graph Query Language) y permite mapear tablas relacionales a grafos sin migrar físicamente los datos.
La potencia de Spanner Graph reside en su interoperabilidad completa con SQL: las consultas pueden combinar GQL para recorrer relaciones complejas y SQL para operaciones tradicionales, todo dentro de la misma transacción ACID. Los casos de uso incluyen detección de fraude, motores de recomendación, seguridad de redes, grafos de conocimiento, planificación de rutas y trazabilidad de linaje de datos. Esta capacidad elimina la necesidad de mantener bases de datos de grafos separadas como Neo4j o Amazon Neptune.
¿Spanner tiene búsqueda vectorial para IA?
Sí, Spanner incorpora búsqueda de embeddings vectoriales a escala prácticamente ilimitada, soportando tanto búsqueda de vecinos más cercanos exacta (KNN) como aproximada (ANN) mediante el algoritmo ScaNN (Scalable Nearest Neighbors) de Google.
Esta funcionalidad permite almacenar y consultar vectores de embeddings directamente en Spanner, escalando a más de 10.000 millones de vectores con garantías transaccionales completas. Las aplicaciones de IA generativa, GraphRAG y agentes inteligentes pueden conectarse a datos empresariales actualizados sin necesidad de sistemas vectoriales especializados externos como Pinecone o Weaviate. La integración nativa con Vertex AI facilita convertir texto en embeddings y realizar búsquedas semánticas dentro de la misma transacción que accede a datos relacionales.
¿Spanner escala automáticamente?
Spanner ofrece escalado horizontal automático de los datos a través de su mecanismo de splits dinámicos: las tablas se dividen automáticamente en rangos que se distribuyen entre diferentes nodos según el volumen y la carga. Sin embargo, el escalado de la capacidad de cómputo (número de nodos o processing units) requiere configuración.
Para automatizar el escalado de cómputo, existen varias opciones:
- Autoescalador gestionado: Disponible en Enterprise Edition y superiores, ajusta automáticamente la capacidad basándose en métricas de utilización
- Autoscaler open source: Una herramienta de código abierto que monitoriza instancias y añade o elimina nodos según parámetros configurables
- Cloud Monitoring con Cloud Functions: Configuración personalizada mediante alertas y funciones que responden a umbrales de CPU
Precios y Costes
¿Cuánto cuesta Google Cloud Spanner al mes?
El coste de Spanner depende de múltiples factores: capacidad de cómputo, almacenamiento, replicación inter-regional y uso de red. Las instancias de producción mínimas con tres nodos oscilan entre 2.70 y 28 dólares por hora dependiendo de la configuración regional o multi-regional, lo que puede traducirse en 2.000-20.000 dólares mensuales para cargas de trabajo básicas.
Los componentes del coste incluyen:
- Processing units/nodos: Unidad básica de cómputo (1 nodo = 1000 processing units)
- Almacenamiento SSD: Para datos de acceso frecuente con baja latencia
- Almacenamiento HDD: Opción más económica para datos de acceso infrecuente
- Backups: Almacenamiento de copias de seguridad
- Replicación: Transferencia de datos entre regiones
Los descuentos por compromiso de uso (CUDs) ofrecen reducciones significativas: 20% para compromisos de un año y 40% para compromisos de tres años.
¿Spanner tiene capa gratuita o período de prueba?
Google Cloud ofrece una prueba gratuita de 90 días para instancias de Spanner, proporcionando capacidad suficiente para evaluar funcionalidades y realizar pruebas de concepto. Esta prueba permite experimentar con configuraciones regionales sin inversión inicial.
Adicionalmente, el emulador de Spanner permite desarrollo local completamente gratuito. Disponible como imagen Docker o instalación directa, el emulador simula el comportamiento de Spanner para desarrollo y testing, aunque presenta limitaciones respecto a la fidelidad del comportamiento en producción —especialmente en aspectos de rendimiento y comportamiento transaccional avanzado.
Para desarrollo con costes mínimos, Spanner ofrece configuraciones que arrancan desde aproximadamente 40 dólares mensuales utilizando processing units en lugar de nodos completos.
¿Spanner tiene mejor precio que DynamoDB?
Según benchmarks publicados por Google, Spanner ofrece hasta un 50% de incremento en throughput y 2.5 veces más almacenamiento por nodo sin cambio en precio, resultando en hasta 2x mejor throughput de lectura por dólar comparado con Amazon DynamoDB para cargas de trabajo similares.
Sin embargo, la comparación directa de precios resulta compleja porque ambos servicios utilizan modelos de facturación diferentes:
- DynamoDB: Cobra por capacidad provisionada (RCU/WCU) o por solicitud individual en modo on-demand
- Spanner: Cobra por capacidad de cómputo (nodos/processing units) más almacenamiento
Para cargas de trabajo de alto volumen con patrones de acceso predecibles, Spanner puede resultar más económico. Para cargas de trabajo esporádicas o con picos impredecibles, el modelo on-demand de DynamoDB puede ofrecer ventajas. El análisis debe considerar el patrón específico de la aplicación para determinar la opción más económica.
Casos de Uso y Sectores
¿Para qué tipo de aplicaciones se recomienda Spanner?
Spanner resulta óptimo para aplicaciones que cumplen varios de estos criterios:
- Transacciones globales consistentes: Aplicaciones financieras, sistemas de pagos y plataformas de trading que requieren garantías ACID a través de múltiples regiones geográficas
- Escala masiva impredecible: Videojuegos con millones de usuarios concurrentes, plataformas virales o aplicaciones con crecimiento exponencial
- Alta disponibilidad crítica: Sistemas donde cinco nueves de uptime representan un requisito de negocio, no una aspiración
- Gestión de inventario multi-canal: Retail omnicanal que necesita una fuente única de verdad para stock, pedidos y logística
- Cargas de trabajo multi-modelo: Aplicaciones que combinan datos relacionales, grafos, clave-valor y búsqueda vectorial
¿Qué empresas utilizan Google Cloud Spanner?
Múltiples organizaciones de diversos sectores han adoptado Spanner para cargas de trabajo críticas:
- Gaming: Lucille Games, Square Enix (Dragon Quest Walk) para gestión de perfiles de millones de jugadores
- Retail: L.L.Bean, Walmart para inventario y gestión de pedidos omnicanal
- Fintech: Vodeno para procesamiento de transacciones financieras con consistencia perfecta
- Telecomunicaciones: Optiva para sistemas de facturación y gestión de clientes
- Salud: Maxwell Plus para cargas de trabajo que requieren cumplimiento HIPAA
Internamente, Google utiliza Spanner para potenciar servicios como Gmail, Google Photos, Google Play y el sistema publicitario Google Ads, procesando más de 3.000 millones de consultas por segundo.
¿Spanner sirve para desarrollo de videojuegos?
Absolutamente. La industria de gaming representa uno de los casos de uso más demandantes para Spanner. Los videojuegos modernos pueden atraer millones de jugadores el día del lanzamiento, todos generando transacciones en tiempo real desde gameplay y compras dentro del juego.
Spanner proporciona:
- Escalabilidad horizontal ilimitada para acomodar picos súbitos de tráfico sin planificación previa
- Latencia de milisegundos para experiencias de juego responsivas
- Cero tiempo de inactividad para parches, backups, failover o actualizaciones de esquema
- Consistencia global para que jugadores en diferentes continentes compartan el mismo estado de juego
Estudios han utilizado Spanner para gestionar perfiles de usuario, inventarios de objetos virtuales, matchmaking, tablas de clasificación globales y economías virtuales que requieren integridad transaccional perfecta.
Migración e Implementación
¿Cómo migrar de MySQL o PostgreSQL a Spanner?
La migración a Spanner involucra varias herramientas y consideraciones:
Spanner Migration Tool (SMT) automatiza la conversión de esquemas y migración de datos desde MySQL y PostgreSQL, manejando automáticamente muchos problemas de compatibilidad. Para migraciones con mínimo tiempo de inactividad, la combinación de Datastream y Dataflow permite migrar datos existentes mientras transmite cambios realizados en la base de datos origen durante el proceso.
La Data Validation Tool (DVT) proporciona validación estandarizada de datos para verificar la integridad post-migración. Sin embargo, resulta importante comprender que la migración probablemente requiere reelaboración de código para acomodar:
- Diseño de claves primarias que eviten hotspots
- Diferencias en funcionalidades SQL soportadas
- Adaptación de patrones de acceso a datos para optimizar rendimiento en Spanner
¿Puedo ejecutar Spanner localmente para desarrollo?
Sí, Google proporciona un emulador oficial de Spanner disponible como imagen Docker o instalación directa. Este emulador simula el comportamiento de Spanner para desarrollo y testing sin costes de cloud.
Para instalarlo mediante Docker:
Sin embargo, los desarrolladores deben comprender las limitaciones del emulador:
- No replica completamente el comportamiento de rendimiento de producción
- Algunas características avanzadas pueden comportarse de forma diferente
- No simula latencias de red ni comportamiento multi-región
- Las pruebas de carga no reflejarán el rendimiento real de Spanner
Para testing de integración riguroso, Google recomienda utilizar instancias de Spanner reales con configuraciones mínimas de coste.
¿Qué consideraciones de diseño de esquema debo tener en cuenta?
El diseño de esquema en Spanner difiere significativamente de bases de datos tradicionales:
Claves primarias: Evitar valores que incrementan o decrementan monótonamente (timestamps secuenciales, auto-incrementos) como primera parte de la clave, ya que crean hotspots que degradan el rendimiento. Las estrategias recomendadas incluyen:
- UUIDs versión 4 generados mediante
GENERATE_UUID() - Secuencias bit-reversed que distribuyen valores uniformemente
- Prefijado con hash para claves secuenciales existentes
Tablas intercaladas: Permiten definir relaciones padre-hijo almacenando filas relacionadas físicamente juntas, optimizando consultas que acceden a datos jerárquicos. Spanner soporta hasta 6 niveles de intercalación.
Índices secundarios: A diferencia de otras bases de datos, Spanner no elige automáticamente índices secundarios en la mayoría de casos —las consultas deben incluir hints explícitos para utilizar índices específicos.
Seguridad y Cumplimiento
¿Qué certificaciones de cumplimiento tiene Spanner?
Spanner cumple con un amplio conjunto de estándares y regulaciones para cargas de trabajo empresariales y reguladas:
- ISO 27001, 27017, 27018: Estándares internacionales de seguridad de la información
- PCI DSS: Para procesamiento de datos de tarjetas de pago
- SOC 1, SOC 2, SOC 3: Controles de seguridad y disponibilidad
- HIPAA: Para datos de salud protegidos
- FedRAMP: Para agencias gubernamentales estadounidenses
Estas certificaciones resultan críticas para organizaciones en industrias reguladas como servicios financieros, salud y sector público.
¿Cómo gestiona Spanner la encriptación de datos?
Spanner implementa encriptación multicapa por defecto:
- Datos en tránsito: Encriptación automática mediante TLS para todas las comunicaciones
- Datos en reposo: Encriptación AES-256 utilizando claves gestionadas por Google
Para organizaciones con requisitos más estrictos, Customer-Managed Encryption Keys (CMEK) proporciona control completo sobre las claves de encriptación mediante integración con Cloud KMS. Los clientes que necesitan seguridad incrementada pueden utilizar Hardware Security Modules (HSMs) validados FIPS 140-2 Level 3 para alojar claves y realizar operaciones criptográficas.
VPC Service Controls previene la exfiltración no autorizada de datos aplicando límites de seguridad de red, mientras que Access Approval permite aprobar explícitamente accesos de personal de Google antes de que ocurran.
Rendimiento y Disponibilidad
¿Qué SLA de disponibilidad ofrece Spanner?
Spanner ofrece diferentes niveles de SLA (Service Level Agreement) según la configuración:
- Configuraciones regionales: 99.99% de disponibilidad mensual
- Configuraciones multi-región: 99.999% de disponibilidad mensual (cinco nueves)
El SLA de cinco nueves significa menos de 5.26 minutos de tiempo de inactividad anual, incluyendo cero downtime para mantenimiento planificado y cambios de esquema. Esta garantía supera significativamente a la mayoría de bases de datos tradicionales gestionadas, que típicamente ofrecen 99.95% (hasta 4.38 horas de downtime anual).
El failover automático y la replicación síncrona garantizan que las aplicaciones permanezcan disponibles incluso si zonas o regiones completas experimentan fallos.
¿Cuántas lecturas y escrituras por segundo soporta Spanner?
Las instancias regionales de Spanner soportan aproximadamente:
- 15.000 lecturas por segundo por nodo
- 2.700 escrituras por segundo por nodo
Estos números representan benchmarks bajo condiciones óptimas. Para alcanzar el máximo rendimiento, las aplicaciones deben:
- Ordenar datos por clave primaria antes de inserciones masivas
- Mantener tamaños de transacción dentro de rangos óptimos
- Mantener utilización de CPU por debajo del 65% para cargas de producción
- Diseñar claves primarias que eviten hotspots
La escalabilidad horizontal significa que añadir nodos incrementa proporcionalmente la capacidad de throughput, sin límite teórico superior.
Integración y Herramientas
¿Spanner se integra con BigQuery?
Sí, Spanner ofrece integración bidireccional profunda con BigQuery:
- Consultas federadas: BigQuery puede consultar datos de Spanner directamente sin copiar datos
- Data Boost: Permite ejecutar consultas analíticas, trabajos batch u operaciones de exportación sin afectar cargas transaccionales, utilizando recursos de cómputo independientes
- Reverse ETL: Permite operacionalizar insights analíticos computados en BigQuery directamente en Spanner para servir con alta QPS y baja latencia
Esta integración permite arquitecturas donde Spanner gestiona cargas transaccionales mientras BigQuery proporciona analytics avanzados, sin pipelines ETL complejos ni duplicación de datos.
¿Qué lenguajes de programación y frameworks soporta Spanner?
Spanner proporciona bibliotecas cliente oficiales para:
- Java
- Python
- Go
- Node.js
- C#
- PHP
- Ruby
- C++
Adicionalmente, el driver JDBC permite conectar cualquier aplicación Java que utilice JDBC estándar. La interfaz PostgreSQL amplía la compatibilidad a cualquier herramienta o framework que soporte el protocolo wire de PostgreSQL.
Para frameworks de ORM, existen adaptadores para:
- Hibernate (con spanner-hibernate-dialect)
- SQLAlchemy (con python-spanner-sqlalchemy)
- Django (con django-spanner)
La compatibilidad con Spring Boot permite integrar Spanner en aplicaciones Java empresariales mediante Spring Data.
Artículo actualizado con información de 2024-2025. Los precios, características y disponibilidad pueden variar según región y configuración específica. Consulta la documentación oficial de Google Cloud para información actualizada.
- Printer-friendly version
- Log in to post comments
 Looker, Google's main Business Intelligence tool, integrates a flexible semantic layer based on LookML to model data directly in the database. It allows connection to multiple sources, facilitating…
Looker, Google's main Business Intelligence tool, integrates a flexible semantic layer based on LookML to model data directly in the database. It allows connection to multiple sources, facilitating…