
IBM Cloud Pak for Data constituye una solución avanzada para la gestión de datos empresariales, diseñada para abordar los desafíos de integración y análisis en entornos complejos. Basada en una arquitectura de microservicios y operando sobre Red Hat OpenShift, esta plataforma modular ofrece escalabilidad y flexibilidad, adaptándose a las necesidades específicas de cada organización.
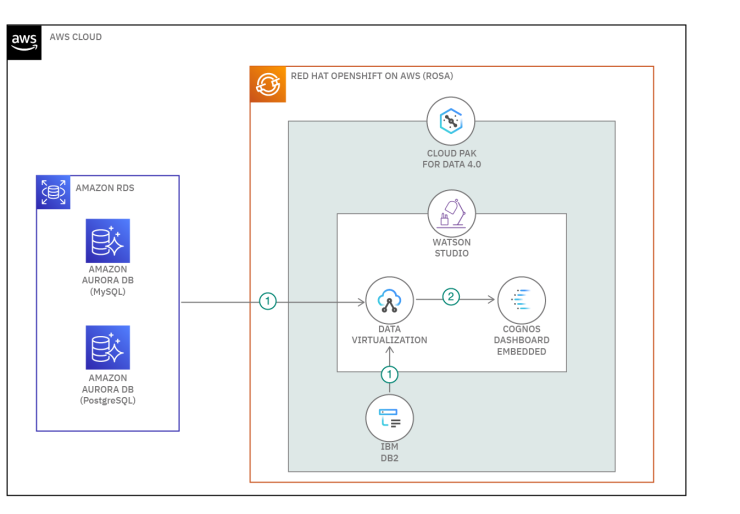
La virtualización de datos es uno de los pilares fundamentales de esta herramienta. Al eliminar la necesidad de procesos ETL tradicionales, permite acceder a más de 60 fuentes de datos heterogéneas, incluyendo bases de datos relacionales, sistemas NoSQL y servicios en la nube. Esto no solo reduce la latencia, sino que también simplifica la consolidación de datos para proyectos analíticos y de inteligencia empresarial.
En el ámbito de análisis, IBM Cloud Pak for Data integra herramientas como Watson Studio y Watson Machine Learning, que facilitan el desarrollo y despliegue de modelos de aprendizaje automático. Estas capacidades se complementan con la compatibilidad con frameworks de código abierto como TensorFlow y PyTorch, ofreciendo flexibilidad para proyectos de inteligencia artificial.
La gobernanza de datos es otro aspecto destacado. Con IBM Watson Knowledge Catalog, las organizaciones pueden catalogar, rastrear y gestionar metadatos de manera centralizada, asegurando el cumplimiento de normativas internacionales como GDPR y CCPA. Además, la plataforma incluye herramientas avanzadas de auditoría y trazabilidad, garantizando la transparencia en el uso de los datos.
Principales funcionalidades
-
Virtualización de datos: Permite acceder a múltiples fuentes de datos distribuidas sin necesidad de moverlos físicamente. Gracias a su compatibilidad con más de 60 conectores nativos, la plataforma integra datos de fuentes heterogéneas como bases de datos relacionales (PostgreSQL, Oracle, MySQL), sistemas NoSQL (MongoDB, Cassandra) y servicios en la nube (AWS, Azure, Google Cloud Platform). Esto reduce los tiempos de implementación y simplifica los procesos de integración, permitiendo una consolidación y acceso a datos en tiempo real.
-
Automatización de gobernanza de datos: IBM Watson Knowledge Catalog es una herramienta integrada que automatiza la creación de catálogos de datos. Utiliza metadatos activos para rastrear y organizar información, asegurando que los datos sean confiables, seguros y estén alineados con normativas como GDPR y CCPA. Las políticas de acceso y uso se gestionan de manera centralizada, lo que garantiza un control exhaustivo y una trazabilidad completa del ciclo de vida de los datos.
-
Análisis e inteligencia artificial (IA): La plataforma incorpora IBM Watson Studio y Watson Machine Learning para facilitar el desarrollo de modelos de aprendizaje automático y su implementación. Los frameworks de código abierto como TensorFlow, PyTorch y Scikit-learn están completamente integrados, permitiendo a los científicos de datos trabajar con herramientas familiares. La función de AutoAI automatiza tareas complejas, como la selección de características, la creación de modelos y la optimización de hiperparámetros, reduciendo significativamente el tiempo necesario para poner los modelos en producción.
-
Integración avanzada: IBM Cloud Pak for Data ofrece capacidades avanzadas de integración mediante su módulo IBM DataStage, que permite realizar operaciones de ETL (Extract, Transform, Load) de manera eficiente. Esta funcionalidad se combina con la virtualización para eliminar redundancias y mejorar el rendimiento en el acceso a datos. Además, soporta flujos de trabajo basados en orquestación para integraciones complejas, lo que resulta clave en entornos corporativos de gran escala.
-
Escalabilidad y personalización: La arquitectura modular de microservicios permite a las organizaciones personalizar la implementación de la plataforma según sus necesidades específicas. Este diseño ofrece flexibilidad para escalar vertical u horizontalmente, adaptándose a volúmenes crecientes de datos o requerimientos adicionales. Las empresas pueden implementar únicamente los servicios que necesiten, como analítica avanzada, integración de datos o visualización, optimizando los costos.
-
Compatibilidad multinube e híbrida: IBM Cloud Pak for Data está diseñada para operar en entornos híbridos y multinube, lo que la hace ideal para empresas que utilizan tanto infraestructuras locales como servicios en la nube. La capacidad de distribuir cargas de trabajo de manera estratégica garantiza un rendimiento óptimo y una mejor utilización de los recursos disponibles.
-
Rendimiento optimizado: Las capacidades de optimización de consultas de la plataforma mejoran el rendimiento en el acceso y análisis de datos. Técnicas avanzadas de compresión y optimización reducen significativamente los tiempos de respuesta, lo que es esencial para análisis en tiempo real o procesamiento de grandes volúmenes de datos.
Características principales
| Característica | Descripción |
|---|---|
| Arquitectura modular | Basada en microservicios para escalabilidad y flexibilidad. |
| Virtualización de datos | Acceso a datos distribuidos sin replicación. |
| Automatización | Reducción de tareas manuales mediante políticas automáticas. |
| Compatibilidad | Soporte para más de 60 fuentes de datos. |
| Análisis e IA | Capacidades avanzadas para análisis y aprendizaje automático. |
| Cumplimiento normativo | Cumple con estándares como GDPR y CCPA. |
Referencias
-
Página oficial de IBM Cloud Pak for Data
- Printer-friendly version
- Log in to post comments
