
La escena se repite en innumerables salas de reuniones corporativas: un equipo técnico presenta con entusiasmo los resultados de su prueba de concepto en datos. Los dashboards muestran insights prometedores, el modelo de machine learning alcanza métricas impresionantes en el conjunto de prueba, y la demo transcurre sin contratiempos. La dirección aprueba con la cabeza, impresionada. Y entonces llega la pregunta inevitable: "Excelente, ¿cuándo podemos tenerlo en producción para toda la empresa?" El entusiasmo inicial se transforma en una mezcla de nerviosismo y realidad. Porque entre esa POC brillante ejecutándose en el portátil de un ingeniero y una plataforma robusta sirviendo a miles de usuarios en producción existe un abismo que muchas organizaciones subestiman peligrosamente.

Este salto del concepto a la producción representa uno de los momentos más críticos en la maduración de cualquier iniciativa de datos. Es donde las buenas intenciones chocan con la realidad operativa, donde las arquitecturas de datos elegantes en papel se encuentran con las restricciones del mundo real, y donde muchos proyectos prometedores naufragan silenciosamente. Según diversos estudios de analistas como Gartner y Forrester, entre el 60% y el 80% de los proyectos de datos nunca llegan a producción o fracasan durante su primer año operativo. No por falta de talento técnico o visión estratégica, sino por subestimar sistemáticamente la complejidad de este proceso de industrialización.
La diferencia fundamental radica en comprender que una POC (Proof Of Concept) y una plataforma productiva no son simplemente versiones a distinta escala del mismo sistema, sino entidades cualitativamente diferentes con requisitos, arquitecturas y dinámicas operativas completamente distintas. Una POC exitosa demuestra que algo es técnicamente posible bajo condiciones controladas. Una plataforma en producción debe demostrar que ese algo es operativamente sostenible bajo condiciones impredecibles, durante años, con equipos que evolucionan y requisitos que cambian constantemente.
La Anatomía de la Brecha: Qué Separa Realmente una POC de un entorno de Producción
Cuando analizamos fracasos en la transición a producción, identificamos patrones recurrentes que trascienden industrias y tecnologías específicas. El primer error conceptual consiste en pensar que producción es simplemente POC más recursos. Esta mentalidad lleva a equipos a intentar "escalar hacia arriba" su prototipo, añadiendo máquinas más potentes, bases de datos más grandes o frameworks más complejos, esperando que la magia de la POC se replique automáticamente. La realidad es que producción requiere un cambio arquitectónico fundamental en múltiples dimensiones simultáneas.
La dimensión de volumen y escala representa el aspecto más evidente pero frecuentemente mal interpretado. Una POC típica trabaja con conjuntos de datos cuidadosamente seleccionados, quizás unos gigabytes de información histórica limpia y representativa. En producción, ese volumen puede multiplicarse por mil o diez mil, pero el verdadero desafío no está en la cantidad sino en las características del flujo continuo de datos. La información llega a todas horas desde fuentes heterogéneas con calidad variable, formatos inconsistentes y patrones de uso impredecibles. Los picos de tráfico no siguen calendarios convenientes, las integraciones se rompen en momentos críticos, y los casos extremos que parecían estadísticamente insignificantes se convierten en problemas diarios cuando multiplicas por millones de transacciones.
La dimensión de resiliencia y disponibilidad introduce requisitos que simplemente no existen en el mundo de la POC. En desarrollo, si algo falla, reinicias el proceso, ajustas el código y vuelves a intentarlo. En producción, cada fallo tiene consecuencias en cascada que afectan a usuarios reales, decisiones de negocio y frecuentemente la reputación de la empresa. Un sistema productivo debe anticipar fallos, diseñarse para degradarse elegantemente, recuperarse automáticamente cuando sea posible y alertar inteligentemente cuando requiera intervención humana. Esto implica implementar monitorización exhaustiva, logging estructurado, tracing distribuido, circuit breakers, políticas de reintento inteligentes, y toda una infraestructura de observabilidad que típicamente representa más código y complejidad que la lógica de negocio original de la POC.
La dimensión de seguridad y cumplimiento emerge como una realidad ineludible. Durante una POC, trabajamos con datos anonimizados o sintéticos, ejecutamos código en entornos aislados y raramente nos preocupamos por aspectos como auditoría de accesos o trazabilidad completa de transformaciones. En producción, manejamos información sensible real, debemos cumplir regulaciones estrictas como GDPR, implementar controles de acceso granulares, cifrar datos en tránsito y reposo, mantener logs de auditoría inmutables y demostrar compliance continuo ante auditorías internas y externas. Esta capa de requisitos no es opcional ni puede añadirse superficialmente, debe integrarse en el diseño arquitectónico.
La dimensión de mantenibilidad y evolución representa quizás el aspecto más subestimado. Una POC es un artefacto estático que demuestra un punto específico en el tiempo. Una plataforma productiva es un organismo vivo que debe evolucionar constantemente, integrarse con sistemas cambiantes, adaptarse a nuevos requisitos de negocio y mantenerse operativa mientras se actualiza. Esto requiere diseño modular, interfaces estables, versionado riguroso, estrategias de deployment sin tiempo de inactividad, capacidad de rollback rápido y documentación exhaustiva que sobreviva a la rotación de personal. La deuda técnica que es perfectamente aceptable en una POC se convierte en una carga paralizante en producción.
Arquitectura para la Realidad: Principios de Diseño Productivo
Transformar una POC en plataforma productiva exige repensar la arquitectura de datos desde fundamentos completamente diferentes. El primer principio arquitectónico crítico es la separación de responsabilidades en capas claramente definidas. Donde la POC mezclaba ingesta, transformación, almacenamiento y presentación en scripts monolíticos ejecutados secuencialmente, la plataforma productiva debe descomponer estas funciones en servicios independientes con interfaces bien definidas. Esta modularidad no es academicismo arquitectónico, sino necesidad operativa: permite desplegar, escalar, monitorizar y actualizar cada componente independientemente sin afectar al sistema completo.
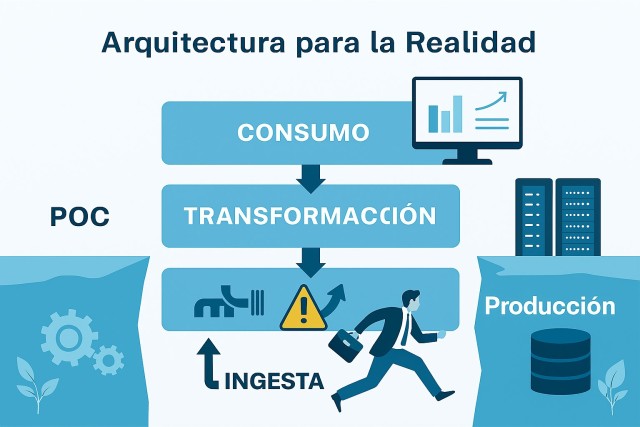
La capa de ingesta en producción debe diseñarse asumiendo que las fuentes de datos son inherentemente poco confiables. Los sistemas externos fallarán, los esquemas cambiarán sin aviso, los datos llegarán duplicados o fuera de orden, y las ventanas de extracción se reducirán inesperadamente. Una arquitectura robusta implementa patrones como idempotencia para permitir reintentos seguros, checkpointing para reanudar desde puntos conocidos tras fallos, validación temprana para rechazar datos malformados antes de contaminar el sistema, y circuitos de protección que aíslan automáticamente fuentes problemáticas sin derribar todo el pipeline. En sectores como retail o finanzas, donde múltiples sistemas legacy generan eventos críticos, esta capa de ingesta defensiva marca la diferencia entre una plataforma fiable y un sistema que requiere intervención manual constante.
La capa de almacenamiento debe evolucionar desde un único datastore conveniente hacia una arquitectura políglota que utiliza tecnologías especializadas según patrones de acceso reales. La POC quizás utilizaba una sola base de datos PostgreSQL porque era familiar y suficientemente rápida para el volumen de prueba. La plataforma productiva reconoce que datos transaccionales, analíticos, de series temporales y de eventos tienen requisitos fundamentalmente diferentes. Los datos crudos ingresan típicamente a un data lake basado en object storage como S3 o Azure Blob, proporcionando durabilidad extrema y coste optimizado para volúmenes masivos. Los datos transformados y modelados residen comunmente en un data warehouse columnar como Snowflake, BigQuery o Redshift, optimizado para consultas analíticas complejas. Cachés como Redis aceleran accesos frecuentes, mientras bases especializadas como ClickHouse o TimescaleDB manejan series temporales de alta cardinalidad. Esta diversidad no busca complejidad sino optimización: cada tecnología resuelve brillantemente problemas específicos que se convierten en cuellos de botella en producción.
La capa de transformación debe industrializarse mediante herramientas de orquestación como Apache Airflow, Prefect o Dagster que convierten scripts individuales en pipelines observables y mantenibles. En la POC, transformábamos datos ejecutando notebooks Jupyter secuencialmente, quizás con algunos scripts Python coordinados manualmente. En producción, necesitamos DAGs que expresen claramente dependencias, implementen retry logic inteligente, permitan ejecuciones paralelas donde sea seguro, registren métricas detalladas de cada paso y faciliten debugging cuando algo inevitablemente falle. La adopción de frameworks modernos como dbt para transformaciones SQL declarativas representa un salto cualitativo: permite expresar lógica de negocio de forma legible, genera automáticamente documentación y lineage, facilita testing mediante assertions, y posibilita despliegue incremental mediante materialización selectiva de modelos. En empresas de telecomunicaciones o energía con cientos de transformaciones interdependientes, esta organización estructurada es la única forma de mantener coherencia y agilidad simultáneamente.
El principio de observabilidad debe elevarse de ocurrencia posterior a requisito arquitectónico fundamental. Un sistema productivo sin observabilidad profunda es como hacer volar un avión sin instrumentos: quizás funcione mientras todo va bien, pero cuando surgen problemas no tenemos forma de diagnosticar qué está fallando ni por qué. Esto implica implementar logging estructurado en todos los componentes utilizando formatos parseables como JSON, instrumentar código con métricas que expongan no solo tasas de error sino latencias percentiles y características de distribución, implementar tracing distribuido que permita seguir requests individuales a través de múltiples servicios, y configurar monitorización y alertas inteligentes que notifiquen anomalías reales sin generar fatiga de alarmas. Herramientas como Prometheus, Grafana, ELK stack o soluciones managed como Datadog proporcionan esta capacidad, pero su valor depende completamente de instrumentar proactivamente los puntos críticos del sistema.
El Checklist de Transición: Pasos Concretos de la POC a Producción
Convertir estos principios arquitectónicos en realidad operativa requiere un proceso estructurado que equilibre velocidad de entrega con solidez técnica.
El primer paso crítico consiste en realizar una auditoría técnica honesta de la POC actual, identificando exactamente qué componentes son reutilizables y cuáles deben reconstruirse desde cero. Esta evaluación debe examinar código, arquitectura de datos, dependencias externas, asunciones implícitas y atajos tomados durante el desarrollo acelerado del prototipo. Frecuentemente descubrimos que la lógica de negocio central es sólida y aprovechable, pero toda la infraestructura circundante requiere un rediseño completo.
El segundo paso implica definir requisitos no funcionales específicos y mesurables que el sistema productivo debe cumplir. Estos SLOs van mucho más allá de declaraciones vagas como "debe ser rápido y fiable" hacia compromisos cuantificables del tipo: pipelines de ingesta deben completarse en menos de dos horas con disponibilidad del 99,5%, consultas analíticas interactivas deben responder en menos de cinco segundos para el percentil 95, la plataforma debe soportar crecimiento del 200% anual sin rediseño arquitectónico, el tiempo de recuperación ante fallos (RTO) no debe exceder quince minutos, y nuevos datasets deben integrarse en menos de una semana. Estos requisitos guían todas las decisiones técnicas posteriores y proporcionan criterios objetivos de éxito.
El tercer paso requiere diseñar la arquitectura objetivo considerando explícitamente los vectores de crecimiento esperados. Una plataforma de datos puede escalar principalmente en volumen de datos, frecuencia de actualización, cantidad de fuentes, número de usuarios, complejidad de transformaciones o diversidad de casos de uso. Cada vector impone restricciones arquitectónicas diferentes. Si anticipamos crecer principalmente en volumen, priorizamos tecnologías distribuidas inherentemente escalables horizontalmente. Si esperamos multiplicar fuentes de datos, invertimos en abstracciones de ingesta que faciliten integración rápida de nuevos conectores. Si preveemos centenares de usuarios concurrentes, diseñamos capas de cache y agregación que protejan los sistemas de backend. Esta anticipación estratégica evita reescrituras completas cuando el crecimiento inevitable se materializa.
El cuarto paso implica implementar la infraestructura fundamental de observabilidad y operaciones antes de migrar lógica de negocio. Esta secuencia contradice el instinto de muchos equipos que quieren ver funcionalidad visible cuanto antes, pero es absolutamente crítica. Instrumentar sistemas retroactivamente es exponencialmente más difícil que hacerlo desde el inicio, y operar sin visibilidad profunda desde el primer día productivo genera crisis innecesarias. Esto incluye configurar logging centralizado, definir métricas clave y dashboards de monitorización, implementar alertas basado en umbrales adaptados al comportamiento real del sistema, establecer runbooks para incidentes comunes, y realizar simulacros de fallos para validar que realmente podemos detectar y responder a problemas.
El quinto paso consiste en migrar funcionalidad incrementalmente mediante una estrategia de strangler pattern o implementación paralela. Raramente es prudente hacer un big bang cutover donde el sistema viejo desaparece y el nuevo lo reemplaza completamente en un momento específico. Los riesgos son excesivos y la capacidad de rollback es limitada. En cambio, construimos el nuevo sistema paralelamente al viejo, migramos cargas de trabajo selectivamente comenzando por casos menos críticos, operamos ambos sistemas simultáneamente durante un período de validación, y finalmente redirigimos tráfico completamente al nuevo sistema solo cuando confiamos plenamente en su estabilidad. En organizaciones financieras, donde la precisión es absolutamente crítica, hemos visto períodos de validación paralela de tres a seis meses donde cada resultado del sistema nuevo se compara automáticamente contra el legacy para identificar discrepancias antes de confiar decisiones en la nueva plataforma.
El sexto paso aborda la preparación organizacional que frecuentemente se ignora hasta que es demasiado tarde. Un sistema productivo requiere no solo código diferente sino procesos operativos, documentación, entrenamiento y roles claramente definidos. Esto incluye documentar arquitectura y decisiones de diseño de forma que nuevos miembros del equipo puedan onboardearse efectivamente, crear runbooks detallados para operación y troubleshooting, establecer procesos de on-call y escalado para incidentes, definir políticas de despliegue y rollback, implementar code review riguroso y testing automatizado, y entrenar a usuarios finales en capacidades y limitaciones del nuevo sistema. En empresas de salud o fabricación, donde múltiples stakeholders dependen de la plataforma, esta inversión en gestión del cambio determina si la adopción es exitosa o conflictiva.
Métricas de Éxito: Cómo Medir una Transición Exitosa
Definir éxito en la transición a producción requiere métricas que capturen no solo capacidades técnicas sino también valor de negocio entregado y sostenibilidad operativa a largo plazo.
Las métricas técnicas fundamentales incluyen disponibilidad medida como uptime del sistema, típicamente expresada como número de “nueves”. Una plataforma con disponibilidad del 99% permite aproximadamente 87 horas de inactividad anual, insuficiente para casos críticos. El 99.9% reduce esto a 8 horas anuales, un target razonable para muchas plataformas empresariales. Alcanzar niveles superiores requiere inversión exponencialmente mayor en redundancia y automatización.

La latencia de pipelines mide cuánto tiempo transcurre desde que datos nuevos están disponibles en fuentes hasta que se reflejan en sistemas consumidores. Esta métrica debe medirse en percentiles, no promedios, porque los casos extremos frecuentemente revelan problemas arquitectónicos importantes. Si el percentil 50 de latencia es 30 minutos pero el percentil 95 es 6 horas, indica que el sistema funciona bien bajo condiciones normales pero colapsa ante variaciones. En retail durante eventos promocionales o en medios durante noticias virales, estas variaciones son la norma, no la excepción.
La tasa de error de datos cuantifica qué porcentaje de registros procesados fallan en las validaciones o generan resultados inconsistentes. Una tasa del 1% puede parecer aceptable estadísticamente, pero si procesas mil millones de registros diarios, estás generando diez millones de registros erróneos que requieren investigación y solución. Plataformas maduras aspiran a tasas de error por debajo del 0.01% para datos críticos, implementando validaciones exhaustivas en múltiples capas del pipeline.
El tiempo de integración de nuevas fuentes mide la agilidad arquitectónica del sistema. Si añadir un nuevo dataset o fuente de datos requiere semanas de desarrollo personalizado, la plataforma se convertirá en un cuello de botella que frena iniciativas de negocio. Arquitecturas maduras con abstracciones sólidas y conectores reutilizables pueden integrar fuentes estándar en días. En organizaciones que crecen por adquisiciones, esta capacidad de absorber rápidamente datos de empresas adquiridas representa una ventaja competitiva directa.
Las métricas de negocio vinculan capacidades técnicas con resultados organizacionales. El time-to-insight mide cuánto tarda una pregunta de negocio en obtener respuesta basada en datos. Si los analistas deben esperar días o semanas para acceder a información necesaria, las decisiones se toman sin datos o la oportunidad se pierde. Plataformas efectivas reducen este tiempo a horas o incluso minutos mediante modelado semántico sólido y herramientas de autoservicio bien gobernadas.
El porcentaje de decisiones data-driven cuantifica adopción real versus declarada. Muchas organizaciones afirman ser data-driven pero cuando auditamos procesos decisorios descubrimos que la mayoría de resoluciones importantes se basan en intuición o política, consultando datos solo para racionalizar decisiones ya tomadas. Las Plataformas verdaderamente exitosas muestran adopción orgánica donde stakeholders consultan datos proactivamente, confían en los insights generados, y ajustan estrategias basándose en evidencia.
Las métricas operativas evalúan sostenibilidad a largo plazo. El Mean Time to Recovery (MTTR) mide cuánto tarda el equipo en resolver incidentes productivos. Plataformas inmaduras frecuentemente sufren outages prolongados porque los equipos no entienden el sistema completamente o carecen de herramientas de diagnóstico adecuadas. Sistemas maduros con observabilidad sólida y runbooks exhaustivos típicamente resuelven incidentes en minutos o decenas de minutos.
El ratio de tiempo reactivo vs proactivo del equipo de datos revela si están constantemente apagando incendios o pueden enfocarse en mejorar el sistema. Si los ingenieros dedican más del 50% de su tiempo a troubleshooting y soporte, algo fundamental está mal en la arquitectura o en los procesos operativos. Los Equipos efectivos operan con la mayoría de tiempo dedicado a desarrollo de nuevas capacidades, optimización y eliminación proactiva de deuda técnica.
Riesgos Frecuentes y Cómo Mitigarlos
La experiencia en múltiples transiciones de POC a producción revela patrones de fracaso recurrentes que pueden anticiparse y mitigarse.
El primer riesgo crítico es la subestimación sistemática de la complejidad operativa. Equipos técnicos brillantes diseñan arquitecturas elegantes en pizarras pero descubren en producción que la complejidad real no reside en la lógica de negocio, sino en manejar casos extremos, integraciones inconsistentes, requisitos de seguridad y cumplimiento, y operación continua 24/7. Mitigar esto requiere involucrar equipos de operaciones y seguridad desde el diseño inicial, realizar threat modeling y failure mode analysis antes de implementar, y simular condiciones productivas en ambientes de staging que repliquen fielmente la complejidad real.
El segundo riesgo es la falta de gobernanza clara de datos, que se manifiesta dramáticamente cuando escalamos. Durante la POC, un equipo pequeño mantenía comprensión compartida implícita de qué significan los datos, cómo se transforman y quién puede acceder a qué. En producción, con múltiples equipos produciendo y consumiendo datos, esta informalidad colapsa en conflictos sobre definiciones, duplicación de esfuerzos, inconsistencias entre reportes y violaciones inadvertidas de políticas de acceso. La mitigación efectiva requiere establecer formalmente roles de data ownership, donde stakeholders específicos son responsables de la calidad y definición de dominios de datos particulares, implementar un catálogo de datos que documente exhaustivamente esquemas, transformaciones y lineage, y crear procesos claros para solicitar accesos, reportar problemas de calidad y proponer cambios a estructuras existentes.
El tercer riesgo emerge de priorizar características funcionales sobre fundamentos operacionales. La presión por demostrar valor rápidamente lleva a equipos a implementar dashboards vistosos y modelos predictivos impresionantes mientras posponen inversión en testing automatizado, disaster recovery, documentación técnica y optimización de performance. Esta deuda técnica eventualmente se cobra con intereses cuando incidentes productivos impactan en los usuarios, el rendimiento se degrada bajo carga real, o el equipo original abandona llevándose conocimiento crítico no documentado. Contrarrestar este riesgo requiere disciplina para invertir un mínimo del 20–30% del tiempo de desarrollo en fundamentos operacionales desde el inicio, establecer quality gates que impidan despliegue de código sin tests adecuados y documentación, y medir equipos no solo por funcionalidades entregadas sino por métricas de calidad y confiabilidad.
El cuarto riesgo involucra dependencias externas que funcionaban en la POC pero que fallan impredeciblemente en producción. APIs de terceros que respondían instantáneamente durante pruebas comienzan a throttlear requests o fallar intermitentemente bajo carga productiva. Fuentes de datos que proporcionaban información consistente durante el piloto cambian formatos sin aviso o sufren degradaciones de calidad. Servicios cloud que parecían infinitamente escalables encuentran límites de cuota o experimentan outages regionales. La mitigación requiere diseñar asumiendo que todas las dependencias fallarán eventualmente, implementando circuit breakers que aíslen automáticamente servicios problemáticos, manteniendo fallbacks y estrategias de degradación elegante, negociando SLAs explícitos con proveedores críticos, y monitorizando proactivamente la salud de dependencias externas.
| Riesgo | Síntoma / alerta | Mitigación / respuesta |
|---|---|---|
| Sobrecarga inesperada | Latencias crecen rápidamente bajo carga real | Pruebas de carga anticipadas, escalado automático, throttling |
| Deuda técnica oculta | Componentes rígidos, difícil cambio | Refactorizar antes de producción, modularidad, revisiones de arquitectura |
| Falsos positivos / degradación de calidad de datos | Alertas erróneas frecuentes, aumenta retrabajo | Validaciones, contratos de datos, monitoreo de comportamiento estadístico |
| Eventos fuera de esquema / datos nuevos no previstos | Fallo del pipeline ante nuevos atributos | Validación flexible, versiones de esquema, mecanismos de fallback |
| Fallas operativas / falta de runbooks | Incapacidad para reaccionar ante fallos | Documentación, simulacros, playbooks de incidentes |
| Seguridad y cumplimiento incumplidos | Brechas de datos, sanciones normativas | Auditoría desde inicio, controles de acceso, encriptación, revisión legal |
| Conflictos políticos y silos | Equipos reclaman “propiedad exclusiva” del dato | Gobernanza clara, comités, acuerdo de SLA interno |
| Versionado y migration quebrados | Consumidores rotos tras cambios | Compatibilidad hacia atrás, migraciones progresivas, validaciones pre-lanzamiento |
| Subdimensionamiento por economía | Infra infrautilizada o incapaz de escalar | Proyección de crecimiento, pruebas bajo estrés, margen de sobredimensionado |
| Falta de mantenimiento continuo | La plataforma se deteriora con el tiempo | Plan técnico de mejoras, sprints de refactorización, revisión constante |
Caso Práctico: Transición en una Empresa de Logística
Ilustremos estos principios mediante un caso real de una empresa europea de logística y transporte con aproximadamente mil vehículos en flota y operaciones en quince países. El equipo de innovación había desarrollado una POC impresionante de optimización de rutas utilizando machine learning que reducía los costes estimados de combustible en un 15% y mejoraba la puntualidad de entregas significativamente. El prototipo procesaba datos históricos de seis meses de una región específica, ejecutándose en el laptop de un data scientist con resultados generados overnight que se presentaban en Jupyter notebooks.
La transición a producción reveló inmediatamente múltiples brechas arquitectónicas. Primero, el volumen de datos en producción excedía por factor de cincuenta lo procesado en la POC: en lugar de seis meses históricos de una región, necesitaban procesar telemetría en tiempo real de toda la flota generando millones de eventos diarios sobre ubicación, velocidad, consumo, estado de vehículos y condiciones de tráfico. El portátil del data scientist obviamente no podía manejar este volumen.
Segundo, los requisitos de latencia cambiaban fundamentalmente la arquitectura. El Piloto generaba rutas optimizadas con varias horas de anticipación. En producción, necesitaban reoptimizar dinámicamente cuando surgían cambios: nuevos pedidos urgentes, vehículos con averías, cierres inesperados de carreteras o condiciones climáticas adversas. Esto requería generar rutas alternativas en minutos, no horas.
Tercero, la integración con sistemas legacy presentaba complejidad subestimada. La POC utilizaba datasets curados manualmente. En producción, debían integrarse con el sistema de gestión de flotas en AS400, el ERP de pedidos en SAP, múltiples APIs de terceros para información de tráfico y meteorología, y aplicaciones móviles de conductores con conectividad intermitente. Cada integración tenía peculiaridades técnicas y esquemas inconsistentes.
El equipo adoptó una estrategia de transición escalonada a tres meses. Durante el primer mes, construyeron infraestructura fundamental: migraron el procesamiento a Kubernetes en cloud con autoscaling, implementaron la ingesta basada en Kafka para manejar streams de telemetría, establecieron un data lake en S3 con particionado eficiente por fecha y región, configuraron Airflow para orquestar pipelines batch de entrenamiento de modelos, y desplegaron un stack de observabilidad completo con Prometheus, Grafana y ELK.
Durante el segundo mes, reimplementaron el algoritmo de optimización como servicio REST escalable, añadieron cacheado inteligente de resultados para reducir el recómputo innecesario, implementaron un feature store para garantizar la consistencia entre entrenamiento e inferencia, crearon simuladores de carga para testeo de rendimiento, y desarrollaron dashboards operacionales para monitorizar la salud del sistema en tiempo real.
El tercer mes se dedicó a rollout controlado: comenzaron optimizando rutas en una región piloto mientras el sistema legacy continuaba sirviendo al resto, operaron ambos sistemas en paralelo comparando resultados diariamente, iteraron rápidamente sobre discrepancias y casos extremos descubiertos, entrenaron equipos de operaciones y conductores en el nuevo sistema, y finalmente expandieron gradualmente a regiones adicionales solo después de validar la estabilidad.
Los resultados medibles después de seis meses en producción completa incluían disponibilidad del sistema del 99.7%, tiempo promedio de generación de rutas de 3 minutos con percentil 95 de 7 minutos, reducción real de costes de combustible del 12% (ligeramente inferior al estimado de la POC debido a la fricción operativa real), mejora del 18% en puntualidad de entregas, y satisfacción de conductores del 75% según encuestas. Igualmente importante, el equipo de desarrollo podía desplegar mejoras del modelo semanalmente sin afectar las operaciones, y el tiempo de incorporación de nuevas telemetrías o fuentes de datos se redujo a aproximadamente una semana.
Las lecciones aprendidas de esta transición incluyen la importancia crítica de invertir en observabilidad antes que en funcionalidad, el valor de rollouts incrementales para validar asunciones sin riesgo excesivo, la necesidad de involucrar equipos operacionales y usuarios finales desde el diseño, no solo para recolectar requisitos, y la sorpresa consistente de que la complejidad real reside en detalles de integración y casos extremos que nunca aparecen en POCs controladas.
Otro Caso de Estudio: Plataforma de Datos en Fintech
Para profundizar en las complejidades prácticas de esta transición, examinemos el caso de una fintech europea especializada en préstamos peer-to-peer que evolucionó su POC de credit scoring a una plataforma de decisión de riesgo en tiempo real. La empresa operaba en ocho mercados europeos, procesaba aproximadamente cincuenta mil solicitudes de préstamo mensuales, en un entorno de regulación financiera estricta que requerí explicabilidad completa de decisiones crediticias.

La POC inicial, desarrollada por dos data scientists durante tres meses, utilizaba datos históricos de veinte mil préstamos para entrenar un modelo gradient boosting que predecía probabilidad de incumplimiento con precisión superior al modelo legacy basado en reglas. El prototipo procesaba datos en formato CSV exportado manualmente, ejecutaba en una instancia EC2 compartida, y generaba scores mediante un script Python invocado ad-hoc. Los resultados impresionaron a la dirección: el modelo capturaba patrones sutiles ignorados por reglas heurísticas, podía rechazar más solicitudes de riesgo sin impactar en el volumen de préstamos aprobados, y estimaba reducir la tasa de incumplimiento del 4% al 2,8%.
Sin embargo, la brecha entre esta POC y una plataforma productiva resultó inmensa. Los requisitos regulatorios exigían explicabilidad individual de cada decisión con auditoría completa, imposible con el enfoque de script ad-hoc. La latencia requerida era diferente: en lugar de scoring batch nocturno, necesitaban responder a solicitudes en menos de dos segundos para no degradar la experiencia de usuario en la aplicación móvil. El volumen de features creció dramáticamente: la POC utilizaba treinta variables básicas, pero producción requería integrar el historial crediticio de bureaus externos, análisis de transacciones bancarias mediante open banking APIs, datos de comportamiento en la aplicación, verificaciones de identidad en tiempo real y scoring de dispositivo para detectar fraude.
La arquitectura en producción reflejaba estos requisitos. La capa de ingesta implementó microservicios especializados: integración con bureaus de crédito con circuit breakers y fallbacks, un servicio de open banking cumpliendo PSD2, un servicio de device fingerprinting y un servicio de feature engineering. Estos publicaban datos a un feature store centralizado en Redis para baja latencia y DynamoDB para persistencia.
El servicio de scoring consumía features del feature store, invocaba el modelo versionado y generaba explicaciones con SHAP values. Cada predicción se registraba en un log de auditoria con timestamp, versión del modelo, features de entrada y explicación, cumpliendo con la trazabilidad regulatoria. Un servicio de orquestación coordinaba la secuencia: solicitud, enriquecimiento, cálculo de features, scoring, reglas de negocio y devolución de decisión con explicación.
La capa de entrenamiento operaba en batch. Airflow orquestaba un DAG que extraía préstamos con outcomes conocidos, calculaba features, entrenaba modelos con hyperparameter tuning, evaluaba fairness metrics, generaba reportes de explicabilidad y promovía el modelo ganador a staging. Este pipeline generaba documentación automática de cada versión para auditorías.
El rollout adoptó shadow mode extendido. Durante seis semanas, el nuevo sistema generaba decisiones en paralelo con el legacy. Se comparaban resultados y se investigaban discrepancias. Tras validar un 98% de concordancia, comenzó un rollout graduado con feature flags por país. España fue piloto con un 20% del tráfico, monitorizando latencias, errores y métricas de negocio como ratio de conversión.
Los resultados tras seis meses en producción: reducción del incumplimiento al 2,3%, latencia promedio de 1,8 segundos cumpliendo el SLO, disponibilidad del 99,84% y tres incidentes significativos (conexiones de base de datos, librería de ML, throttling de API externa). Los costes operativos rondaban los 20.000 € mensuales, justificados por el valor generado y un ROI superior al 500% anualizado.
Las lecciones críticas incluyeron: la importancia del feature store para consistencia entre training y serving, el valor del shadow mode para validar sin riesgo, la necesidad de circuit breakers y degradación elegante ante fallos externos, la criticidad de observabilidad granular con tracing distribuido, y que la explicabilidad regulatoria requirió más esfuerzo de ingeniería que el propio modelo predictivo.
De Transición a Evolución Continua
Una vez superada exitosamente la transición inicial a producción, el desafío cambia de construcción a evolución continua. Las plataformas de datos más exitosas no son aquellas con arquitectura perfecta desde el día uno, sino las diseñadas para cambiar ágilmente conforme evolucionan requisitos, tecnologías y comprensión del dominio. Esto requiere establecer prácticas de ingeniería que faciliten el cambio seguro: testing automatizado exhaustivo incluyendo tests unitarios de transformaciones, tests de integración de pipelines completos y tests de contratos entre servicios; despliegue continuo mediante CI/CD que permite desplegar cambios múltiples veces al día con confianza; feature flags que separan deployment técnico de activación de funcionalidad permitiendo rollouts graduales y rollback instantáneo sin redeploy; y versionado semántico de datasets y APIs que permite evolución backward-compatible sin dejar de dar servicio a los consumidores existentes.
La documentación viva se convierte en activo crítico conforme el sistema crece en complejidad y el equipo evoluciona. Herramientas como dbt, Great Expectations o Amundsen generan automáticamente documentación desde código, tests y metadata, asegurando que la documentación permanece sincronizada con la implementación real. Runbooks detallados para escenarios operacionales comunes empoderan a equipos on-call para resolver incidentes efectivamente. Architecture Decision Records documentan el razonamiento detrás de elecciones significativas, ayudando a futuros mantenedores a comprender no solo qué se construyó sino por qué.
La cultura de postmortems sin culpa convierte incidentes inevitables en oportunidades de aprendizaje organizacional. Cuando algo falla en producción, el objetivo no es identificar culpables sino comprender sistémicamente qué permitió el fallo y qué cambios estructurales previenen recurrencias similares. Los mejores postmortems resultan en mejoras concretas: mejor observabilidad que hubiera detectado el problema antes, tests automatizados que previenen regresiones específicas, documentación que acelera troubleshooting futuro, o cambios arquitectónicos que eliminan clases enteras de fallos potenciales.
Finalmente, mantener la alineación con la evolución de negocio requiere mecanismos explícitos de gobernanza y priorización. Un comité de steering con representación de IT y líneas de negocio se reúne regularmente para evaluar roadmap de la plataforma, priorizar nuevas capacidades versus deuda técnica, aprobar cambios arquitectónicos significativos y resolver conflictos de recursos. Métricas de uso y valor generado informan objetivamente estas discusiones, evitando que las decisiones se basen puramente en opinión o política. Product managers especializados en datos traducen necesidades de negocio en requisitos técnicos y comunican capacidades técnicas en términos de valor empresarial, cerrando el gap comunicacional que frecuentemente frustra las iniciativas de datos.
En resumen
La transición de prueba de concepto a plataforma productiva representa el momento más crítico en la maduración de iniciativas de datos, donde la mayoría de proyectos prometedores fracasan por subestimar la brecha cualitativa entre ambos estados. Una POC demuestra posibilidad técnica bajo condiciones controladas; una plataforma productiva garantiza sostenibilidad operativa bajo condiciones impredecibles durante años.
El éxito requiere reconocer dimensiones fundamentales que diferencian producción: volumen y patrones de datos reales continuos, requisitos estrictos de resiliencia y disponibilidad, obligaciones de seguridad y cumplimiento regulatorio, y necesidad de mantenibilidad y evolución continua. Arquitectónicamente, esto implica modularidad rigurosa con separación de responsabilidades, ingesta defensiva que asume fuentes poco confiables, almacenamiento políglota optimizado por patrones de acceso, transformaciones industrializadas mediante orquestación observable, y observabilidad profunda como requisito fundamental no opcional.
El proceso de transición requiere pasos estructurados: auditoría honesta de la POC identificando qué es reutilizable, definición de SLOs específicos y medibles, diseño arquitectónico considerando vectores de crecimiento anticipados, implementación de infraestructura operacional antes que funcionalidad, migración incremental mediante estrategias de strangler pattern, y preparación organizacional incluyendo documentación, procesos y entrenamiento.
Las métricas de éxito deben capturar capacidades técnicas, valor de negocio y sostenibilidad operativa: disponibilidad del sistema medida en nueves, latencia de pipelines en percentiles, no promedios, tasas de error de datos ambiciosas, tiempo de integración de nuevas fuentes como proxy de agilidad arquitectónica, time-to-insight para decisiones de negocio, adopción real versus declarada de datos en procesos decisorios, mean time to recovery de incidentes, y balance de tiempo reactivo versus proactivo del equipo técnico.
Los riesgos más frecuentes incluyen subestimación de la complejidad operativa mitigable mediante threat modeling anticipado, falta de gobernanza clara solucionable con roles formales y catálogo de datos, priorización de características sobre fundamentos contrarrestable con disciplina de inversión operacional, y dependencias externas frágiles manejables mediante diseño defensivo con circuit breakers y fallbacks.
La transición exitosa no termina con el primer deployment productivo sino que evoluciona hacia operación continua facilitada por testing automatizado exhaustivo, CI/CD que permite cambios frecuentes seguros, feature flags para rollouts graduales, versionado semántico para evolución compatible, documentación viva generada automáticamente, postmortems sin culpa que convierten fallos en aprendizaje, y gobernanza explícita que mantiene alineación con negocio.
Checklist Operativo de la Transición
Proporcionamos este checklist operativo como propuesta de guia por fases para una eventual transición de una Prueba de Concepto a un sistema productivo
Fase 1: Evaluación y Planificación
-
Realizar auditoría técnica completa de la POC identificando componentes reutilizables versus reconstruibles
-
Documentar todas las asunciones implícitas de la POC que no se mantienen en producción
-
Definir SLOs específicos para disponibilidad, latencia, throughput y tasas de error
-
Identificar stakeholders críticos y establecer canales de comunicación regulares
-
Estimar vectores de crecimiento a doce y veinticuatro meses
-
Evaluar opciones tecnológicas para cada capa arquitectónica
-
Crear arquitectura objetivo documentando componentes, interfaces y flujos de datos
-
Establecer presupuesto realista con contingencia del treinta por ciento
-
Definir criterios de éxito medibles tanto técnicos como de negocio
-
Obtener aprobación formal de dirección con compromisos de recursos
Fase 2: Infraestructura Fundamental
-
Aprovisionar ambientes de desarrollo, staging y producción con paridad arquitectónica
-
Implementar infraestructura como código para reproducibilidad
-
Configurar networking incluyendo VPCs, subnets y security groups
-
Establecer gestión de secretos para credenciales y claves
-
Desplegar stack de observabilidad: logging, métricas, tracing y dashboards
-
Configurar alertas con umbrales conservadores iniciales
-
Implementar backup automatizado y disaster recovery
-
Establecer procesos de deployment con CI/CD básico
-
Configurar herramienta de orquestación con monitorización
-
Documentar arquitectura y procedimientos de troubleshooting
Fase 3: Capa de Ingesta y Almacenamiento
-
Implementar conectores de ingesta con manejo robusto de errores
-
Configurar validación temprana de esquemas y calidad
-
Establecer estrategia de particionado optimizada
-
Implementar idempotencia en pipelines de ingesta
-
Configurar checkpointing para reinicio tras fallos
-
Establecer políticas de retención y lifecycle management
-
Implementar versionado de datasets críticos
-
Configurar permisos granulares y auditoría de accesos
-
Realizar pruebas de carga con volúmenes realistas
-
Documentar esquemas, formatos y SLAs
Fase 4: Transformaciones y Modelado
-
Migrar lógica de transformación a framework estructurado
-
Implementar tests automatizados para transformaciones críticas
-
Establecer DAGs expresando dependencias y retry logic
-
Crear capas de modelado dimensional o vault
-
Implementar slowly changing dimensions
-
Configurar materialización incremental
-
Establecer data quality checks automatizados
-
Documentar lógica de negocio en catálogo de datos
-
Implementar lineage tracking automático
-
Realizar pruebas de reconciliación contra legacy
Fase 5: Capa de Consumo
-
Implementar semantic layer o data marts
-
Configurar herramienta BI con conexiones seguras
-
Establecer APIs con autenticación y rate limiting
-
Implementar cacheado para consultas frecuentes
-
Configurar permisos basados en roles
-
Crear dashboards operacionales para métricas críticas
-
Documentar catálogo de métricas
-
Establecer procesos de solicitud de acceso
-
Realizar UAT con usuarios piloto
-
Preparar material de entrenamiento
Fase 6: Seguridad y Cumplimiento
-
Implementar cifrado en tránsito y reposo
-
Configurar auditoría exhaustiva de accesos
-
Realizar security assessment
-
Implementar data masking para ambientes no productivos
-
Establecer gestión de identidades con menor privilegio
-
Configurar detección de anomalías
-
Documentar controles para auditorías
-
Realizar penetration testings
-
Establecer procedimientos de respuesta a incidentes
-
Validar cumplimiento regulatorio
Fase 7: Rollout Controlado
-
Seleccionar región piloto o caso de uso limitado
-
Operar nuevo sistema en paralelo con legacy
-
Establecer métricas de comparación cuantitativas
-
Investigar y documentar discrepancias
-
Monitorizar intensivamente rendimiento y errores
-
Realizar ajustes iterativos basados en aprendizajes
-
Expandir gradualmente a casos adicionales
-
Mantener capacidad de rollback rápido
-
Recolectar métricas de adopción y satisfacción
-
Documentar lecciones aprendidas
Fase 8: Operación y Mejora Continua
-
Transicionar a equipo de operaciones con shadowing
-
Establecer rotación on-call con runbooks detallados
-
Implementar procesos de postmortem sin culpa
-
Configurar revisiones regulares de rendimiento
-
Establecer comité de gobernanza de datos
-
Implementar mecanismo de roadmap priorizando
-
Realizar retrospectivas técnicas trimestrales
-
Mantener actualización de documentación
-
Monitorizar evolución de costes
-
Celebrar éxitos comunicando valor generado
Recursos y Lecturas Recomendadas
-
Artículos y guías técnicas fundamentales
"Designing Data-Intensive Applications" de Martin Kleppmann - Libro sobre arquitectura de sistemas de datos modernos cubriendo profundamente consistencia distribuida, replicación, particionado, streaming y batch processing. Esencial para arquitectos diseñando plataformas escalables. Especialmente relevantes capítulos sobre reliability, scalability y maintainability. Disponible en: https://dataintensive.net/
"The Data Engineering Cookbook" - Guía práctica mantenida por Andreas Kretz cubriendo stack tecnológico completo de data engineering, patrones arquitectónicos comunes, y career path para ingenieros de datos. Particularmente útil la sección sobre transición de prototipos a producción. Disponible en: https://github.com/andkret/Cookbook
Frameworks y mejores prácticas operacionales
"Google SRE Book" - Colección de prácticas de Site Reliability Engineering de Google cubriendo SLOs/SLIs, incident management, postmortems, capacity planning y automation. Aunque enfocado en servicios web, principios son directamente aplicables a plataformas de datos. Especialmente útil para establecer cultura operacional madura. Disponible gratuitamente en: https://sre.google/books/
"MLOps: Continuous Delivery and Automation Pipelines in Machine Learning" - Paper de Google Cloud describiendo niveles de madurez MLOps desde modelos manuales hasta sistemas completamente automatizados con CI/CD. Proporciona roadmap claro para industrialización de ML. Disponible en: https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
Recursos específicos de Dataprix
Dataprix Marketplace - Directorio de plataformas y herramientas organizadas por categoría (bases de datos, ETL, BI, ML, gobernanza) con comparativas objetivas, casos de uso y guías de selección. Útil para decisiones de stack tecnológico durante diseño arquitectónico. Disponible en: https://dataprix.com
Este capítulo forma parte del libro online "Arquitectura de Datos Empresarial: Guía Práctica de Implementación" publicado en Dataprix.com. La serie completa recorre sistemáticamente estrategia, fundamentos técnicos, plataformas, integración, consumo, AI y gobernanza de datos empresariales con enfoque práctico y accionable para CIOs, arquitectos e ingenieros de datos.
