

La Inteligencia Artificial ha dejado de ser una capa funcional superpuesta a los sistemas tradicionales para convertirse en un principio estructural que redefine cómo deben diseñarse, gobernarse y operar las arquitecturas de datos modernas. Durante décadas, las plataformas empresariales se han construido alrededor de patrones estables: bases de datos relacionales, almacenes centralizados, ETLs recurrentes y modelos de gobernanza que asumían que el dato era fundamentalmente un activo estático. Sin embargo, la irrupción de modelos de machine learning —y, más recientemente, los modelos generativos y LLMs— ha provocado un cambio profundo: ahora el dato es dinámico, contextual, tiempo-dependiente y semánticamente rico.
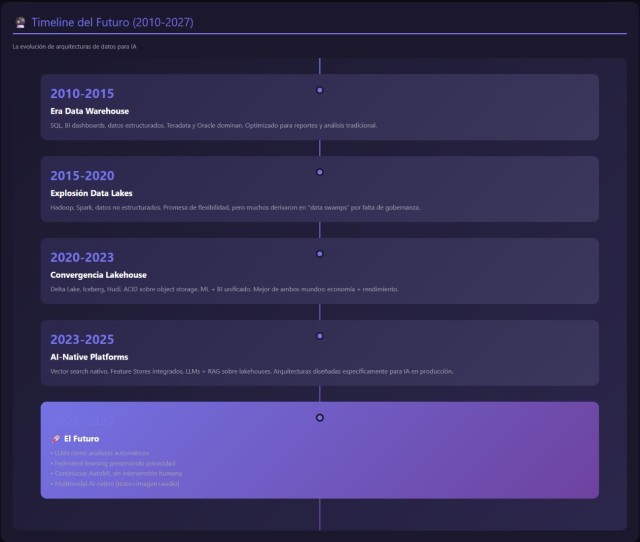
Durante tres décadas, las arquitecturas de datos empresariales se optimizaron para un objetivo claro: ejecutar consultas SQL rápidas sobre datos estructurados. Los data warehouses de Teradata, Oracle y posteriormente Snowflake se diseñaron pensando en analistas de negocio generando informes financieros, dashboards de ventas y métricas operacionales. Pero en 2023 todo cambió..
La explosión de modelos de lenguaje grandes (LLMs), sistemas de recomendación personalizados, detección de fraude en tiempo real y aplicaciones de visión computacional ha transformado radicalmente los requisitos arquitectónicos. Los patrones de acceso a datos de una aplicación moderna de IA tienen poco que ver con una consulta SQL tradicional:
- Búsquedas vectoriales sobre embeddings de 1536 dimensiones para sistemas RAG (Retrieval-Augmented Generation)
- Entrenamiento distribuido de redes neuronales sobre petabytes de datos históricos
- Inferencia en milisegundos sobre streams continuos de eventos
- Feature stores que sincronizan datos batch y streaming para garantizar consistencia entre entrenamiento y producción
- Procesamiento multimodal que combina texto, imágenes, audio y series temporales en un único pipeline
Abordaremos precisamente esta transición. No desde la perspectiva de una moda tecnológica, sino desde el impacto real que tiene en el diseño de una plataforma corporativa que aspire a ser AI-native. La IA ya no es una funcionalidad adicional, sino un condicionante técnico de primer orden: desde la necesidad de infrastructures GPU, la adopción de bases vectoriales, la creación de feature stores y pipelines híbridos, hasta la observabilidad avanzada para modelos y la gestión del model drift como capacidad operativa obligatoria.
Las arquitecturas clásicas —data lakes, data warehouses, pipelines ETL, motores OLAP— continúan siendo pilares fundamentales, pero su valor se redefine al integrarse con componentes que hasta hace muy poco pertenecían al ámbito exclusivo de laboratorios de investigación. Hoy son esenciales para cualquier organización que desee competir: modelos de embeddings, motores de búsqueda semántica, gateways de inferencia, stores de metadatos enriquecidos, o catálogos de datasets versionados preparados para entrenamiento y evaluación continua.
El CIO y los arquitectos de datos se encuentran, por tanto, ante un nuevo escenario. La IA exige tomar decisiones que afectan no solo al plano técnico, sino al económico, al organizativo y al regulatorio. Adoptar un enfoque AI-native implica aceptar nuevos riesgos —aumento potencial del coste, dependencia de proveedores, opacidad de modelos, exposición a fugas de información— y también nuevas oportunidades: automatización avanzada, productos de datos inteligentes, optimización operativa y experiencias de usuario radicalmente más ricas.
Este capítulo explica ese cambio de paradigma con detalle técnico, visión estratégica y enfoque práctico. No se trata simplemente de añadir IA a la arquitectura existente, sino de diseñar la plataforma que hará posible que la IA se convierta en un motor de valor sostenido para la organización.
La irrupción de la IA en las arquitecturas modernas
La conversación sobre arquitectura de datos ha cambiado más en los últimos tres años que en las dos décadas anteriores. Hasta hace poco, cualquier discusión técnica entre CIOs y arquitectos solía moverse dentro de coordenadas conocidas: elección entre data lake y data warehouse, decisiones sobre particionado y modelos estrella, patrones de ingestión por lotes o streaming, grados de normalización o estrategias de gobernanza. Pero la aparición de la IA generativa ha introducido una tensión estructural que reconfigura todos estos ejes. No se trata simplemente de añadir modelos a un pipeline existente, sino de comprender que la propia naturaleza de los datos —cómo se recogen, cómo se procesan, cómo se almacenan y cómo se consumen— se transforma radicalmente.
La IA, especialmente en su vertiente generativa, impone una lógica distinta. En lugar de depender únicamente de datos transaccionales o analíticos tradicionales, los sistemas modernos necesitan datos contextuales, ricos en semántica, con relaciones explícitas, embeddings que capturen significados, historiales temporales completos y, cada vez más, información multimodal (texto, audio, imagen, eventos, logs). El resultado es que la arquitectura basada únicamente en estructuras tabulares deja de ser suficiente. En su lugar emerge un ecosistema más complejo: bases de datos vectoriales, catálogos de features versionadas, motores de grafos, pipelines híbridos y almacenes que combinan columnas clásicas con índices semánticos.
La primera consecuencia práctica de este cambio es que los límites tradicionales entre OLTP, OLAP y machine learning empiezan a difuminarse. Los modelos ya no se entrenan únicamente de forma batch en ciclos largos; ahora necesitan retraining continuo, datos frescos, feedback en tiempo real y monitorización constante del comportamiento. Esto afecta directamente al diseño de pipelines: lo que antes podía resolverse con un ETL diario, ahora requiere una arquitectura que combine ingestión por CDC, microbatch, eventos y sincronización online/offline. A nivel operativo, los equipos pasan de pensar en “procesos nocturnos” a flujos permanentes que mantienen la coherencia de las features en producción.
Otra transición significativa tiene que ver con la naturaleza del consumo. El BI siempre ha sido la forma canónica de explotar el dato: dashboards, informes, consultas ad hoc. Pero los modelos modernos cambian la ecuación. Ahora se consume información a través de modelos conversacionales, motores de recomendación, sistemas de generación automática de contenido o asistentes internos que dependen de RAG (Retrieval-Augmented Generation). En este paradigma, la fuente de verdad ya no es únicamente una tabla o una vista materializada; también lo es un índice vectorial, un embedding store o un grafo empresarial. La arquitectura debe integrar ambas realidades sin comprometer ni el rendimiento ni la gobernanza.
La adopción de LLMs dentro de la empresa acelera el fenómeno. Estos modelos exigen decisiones totalmente nuevas: ¿se utiliza un modelo base externo?, ¿se aloja un modelo propio?, ¿se hace fine-tuning?, ¿se usa LoRA para adaptarlo?, ¿se opta por RAG para evitar sensibilidades regulatorias? Y cada decisión técnica tiene un impacto directo en la arquitectura. Por ejemplo, un RAG bien implementado requiere una integración íntima entre catálogos de datos, bases vectoriales, pipelines de embeddings, sistemas de chunking, job schedulers para el refresco semántico y un gateway de inferencia que gestione la autenticación y el contexto. Muy lejos de lo que tradicionalmente se pedía a un data warehouse.
Además, aparece otro desafío estructural: el coste. Las arquitecturas AI-native son significativamente más costosas si se adoptan de manera improvisada. Un cluster GPU mal configurado puede generar runaway costs en pocos días; un vector store sin políticas de retención puede crecer de forma exponencial; un pipeline mal diseñado puede duplicar innecesariamente embeddings o recalcular features sin necesidad. Por eso la arquitectura deja de ser un ejercicio puramente técnico y se convierte en una disciplina que combina ingeniería, economía del dato (FinOps), seguridad y gestión del riesgo. El CIO no solo debe decidir qué construir, sino también cuánto cuesta operar cada decisión durante años.
En paralelo, la irrupción de la IA ha introducido nuevas responsabilidades en gobernanza. Si antes la prioridad era asegurar que los datos eran completos, consistentes y gobernados, ahora también lo es garantizar que los modelos que dependen de ellos sean auditables, que exista trazabilidad sobre datasets de entrenamiento, que los prompts puedan monitorizarse, que las inferencias no expongan datos sensibles y que el sistema pueda detectar y mitigar fenómenos como el model drift, el data drift o las alucinaciones generativas. Por eso, en las arquitecturas modernas emergen componentes que hace solo tres años no aparecían en ningún diagrama: registries de modelos, sistemas de auditoría de prompts, pipelines de evaluación continua, contenedores seguros para inferencia o reglas de aislamiento contextuales para prevenir fugas de datos.
Este nuevo escenario también reconfigura la relación entre los equipos. En un modelo clásico, el CIO supervisaba la estrategia de datos, el arquitecto definía los patrones, los ingenieros construían pipelines y el equipo de BI explotaba la información. Con IA, surge un ecosistema más interdependiente: los equipos de MLOps necesitan a los ingenieros de datos para mantener features fiables; los equipos de seguridad necesitan entender cómo los modelos pueden filtrar información; el equipo jurídico participa activamente en decisiones sobre RAG, fine-tuning y retención de embeddings. El dato pasa de ser un activo técnico a un activo estratégico cuya explotación está sometida a expectativas regulatorias, riesgos operativos y presiones de negocio inéditas.
Finalmente, quizá el cambio más profundo es cultural. Las organizaciones que realmente adoptan IA entienden que no se trata de “instalar un modelo” sino de “construir una fábrica de modelos”, capaz de mantener una línea continua de entrenamiento, validación, puesta en producción y observabilidad. Esto exige una arquitectura flexible, modular, gobernada por metadatos y preparada para operar a escala. No basta con añadir IA a una plataforma existente; hay que reimaginar la plataforma para que la IA sea una capacidad orgánica.
La conclusión es clara: la irrupción de la IA no es una evolución incremental de la arquitectura de datos, sino una nueva dimensión que obliga a repensar decisiones de diseño que parecían estables. Quien aplique este cambio con visión estratégica podrá construir plataformas más inteligentes, más automatizadas y más capaces de generar valor. Quien lo ignore, corre el riesgo de quedarse atrapado en arquitecturas obsoletas incapaces de soportar la próxima década.
Los Nuevos Requisitos: Qué Necesita la IA que el BI Tradicional Nunca Pidió
Latencias en Múltiples Órdenes de Magnitud
El BI tradicional opera cómodamente en el rango de segundos. Una consulta que devuelve resultados en 2-5 segundos se considera rápida. Los usuarios están habituados a esperar mientras el dashboard se refresca.
La IA en producción opera en rangos completamente diferentes:
Entrenamiento de modelos:
- Escaneos completos de datasets (cientos de TBs): horas o días
- Aceptable porque es batch y programado
- Prioridad: throughput sobre latencia
Inferencia batch (scoring masivo):
- Predicciones sobre millones de registros: minutos a horas
- Típico en campañas de marketing, análisis de riesgo crediticio
- Similar a BI tradicional pero con mayor volumetría
Inferencia real-time (producción):
- Autorización de pago con detección de fraude: <100 milisegundos
- Recomendación de producto en página web: <50 milisegundos
- Moderación de contenido en redes sociales: <200 milisegundos
Feature lookup para inferencia:
- Consulta a Feature Store online: <10 milisegundos
- Cualquier latencia superior rompe el SLA de la aplicación
Un data warehouse tradicional como Snowflake o BigQuery tiene latencias típicas de 500ms a 2 segundos sólo en la ejecución de la query, sin contar la conexión de red y el procesamiento de resultados. Para aplicaciones de IA en producción, esto es de 20 a 100 veces demasiado lento.
Formatos de Datos No Estructurados y Multimodales
El BI tradicional asume datos tabulares: filas y columnas, tipos de datos conocidos (entero, string, fecha), esquemas estables.
Los workloads de IA modernos requieren:
Texto sin procesar:
- Logs de aplicaciones (JSON semiestructurado)
- Documentos corporativos (PDFs, Word, emails)
- Transcripciones de call center
- Posts de redes sociales
Imágenes:
- Fotos de productos (e-commerce)
- Imágenes médicas DICOM (radiografías, tomografías)
- Capturas de cámaras de seguridad
- Documentos escaneados (OCR)
Audio:
- Grabaciones de atención al cliente
- Podcasts y contenido multimedia
- Comandos de voz para asistentes virtuales
Video:
- Contenido de streaming (Netflix, YouTube)
- Vigilancia y seguridad
- Análisis de comportamiento en retail físico
Series temporales:
- Telemetría de sensores IoT (millones de eventos/segundo)
- Logs de aplicaciones con timestamps precisos
- Datos financieros tick-by-tick
Embeddings (vectores densos):
- Representaciones numéricas de texto, imágenes, audio
- 384, 768, 1536, o 4096 dimensiones
- Requieren búsquedas de similitud especializadas
Un data warehouse puede almacenar un link a una imagen en S3, pero no puede procesarla nativamente. No puede ejecutar modelos de visión computacional, no puede extraer features de audio, no puede realizar búsquedas semánticas sobre texto.
Acceso Aleatorio vs Secuencial
Las consultas SQL tradicionales son scan-heavy: leer grandes bloques de datos secuencialmente, aplicar filtros, agregaciones y joins.
Los data warehouses optimizan para esto mediante:
- Almacenamiento columnar (solo leer columnas necesarias)
- Compresión agresiva
- Particionado y pruning
- Procesamiento paralelo masivo
Los workloads de IA tienen patrones diferentes:
Entrenamiento: Similar a BI, escaneos secuenciales masivos. Compatible con data warehouses.
Inferencia: Lookups aleatorios de features individuales por key (user_id, product_id). Un modelo de recomendación necesita:
Ejecutar 50+ queries individuales con latencias de 500ms cada una = 25 segundos. Completamente inviable en un DWH.
Solución: Feature Store online con base de datos key-value (Redis, DynamoDB) optimizada para lookups individuales en <10ms.
1.4 Versionado y Reproducibilidad
En Business Intelligence, si un dashboard muestra datos ligeramente diferentes mañana porque la tabla se actualizó, generalmente no es crítico. Los usuarios comprenden que los datos evolucionan.
En ML, la reproducibilidad es obligatoria:
Auditoría regulatoria:
- Banca: "¿Por qué rechazaste este préstamo a este cliente el 15 de marzo de 2023?"
- Respuesta requerida: "Modelo v2.3.1 entrenado con datos hasta 2023-03-01, features X, Y, Z con estos valores exactos"
Debugging de modelos:
- "El modelo degradó su accuracy del 92% al 85% en producción"
- Necesitas: datos exactos en el momento de entrenamiento, features exactas, versión exacta del modelo
Regulación (AI Act europeo, leyes de transparencia algorítmica):
- Obligación de explicar decisiones automatizadas
- Requiere trazabilidad completa: datos → features → modelo → predicción
Los data warehouses tradicionales tienen capacidades limitadas de versionado:
- Snowflake Time Travel: 90 días máximo (extensible a 1 año con coste adicional)
- BigQuery: 7 días de time travel
- No versiona automáticamente transformaciones de features
Los lakehouses con Delta Lake/Iceberg ofrecen:
- Time travel indefinido (limitado solo por retención de archivos en S3)
- Versionado de tablas con metadatos de quién modificó qué y cuándo
- Linaje de datos desde raw hasta features agregadas
- Model registry que vincula versiones de modelos con snapshots de datos
Arquitectura técnica: la anatomía de una plataforma AI-native
Cuando una empresa decide avanzar hacia un modelo AI-native, la arquitectura deja de ser un simple ensamblaje de tecnologías y se convierte en un organismo vivo. Cada decisión —desde cómo se ingesta un dato hasta cómo se sirve una inferencia— determina la eficiencia, seguridad y escalabilidad del sistema. Una plataforma capaz de soportar IA generativa, ML clásico, analítica avanzada y BI necesita articular componentes que antes vivían separados. La arquitectura moderna es híbrida, orchestral y profundamente dependiente de metadatos. A continuación, desmenuzamos sus elementos fundamentales.
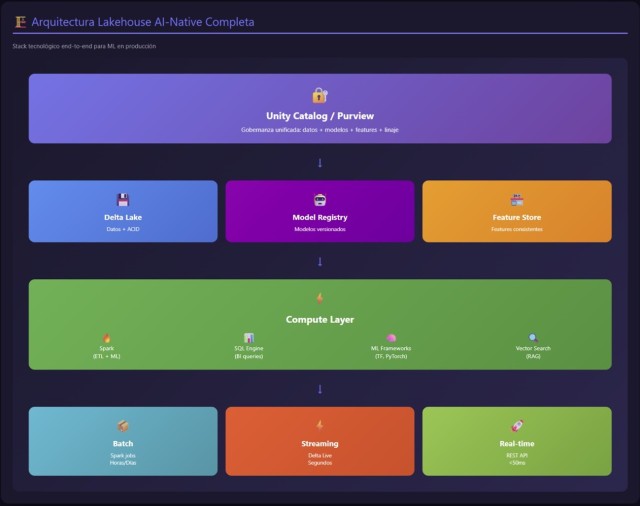
Capa de datos: del lakehouse al AI Lakehouse
El punto de partida es la capa de almacenamiento. Tradicionalmente, la arquitectura combinaba un data lake para datos crudos y un data warehouse para analítica estructurada. En un entorno AI-native, esta dualidad evoluciona hacia un AI Lakehouse, un repositorio que combina formatos tabulares clásicos (Parquet, Delta, Iceberg) con estructuras especializadas necesarias para el mundo de los modelos:
-
Embeddings: vectores de alta dimensión que representan significado semántico de documentos, registros, logs o eventos.
-
Índices vectoriales: estructuras como HNSW, IVF, PQ o Flat Index, esenciales para búsquedas aproximadas de vecinos cercanos en miles de millones de vectores.
-
Metadatos enriquecidos: descripciones de datasets, anotaciones de calidad, relaciones semánticas e incluso descripciones generadas por IA.
-
Ontologías y grafos empresariales: estructuras que permiten que los modelos comprendan relaciones explícitas entre entidades (cliente–producto–transacción–riesgo).
Esta capa habilita capacidades que antes no existían: búsqueda semántica, RAG, descubrimiento inteligente de datos y clasificación automática de documentos. Pero también trae nuevos retos: el versionado de embeddings, la consistencia entre índices y documentos, y la gobernanza del contenido semántico.
Las organizaciones más avanzadas integran tecnologías como LakeFS o DVC para versionado completo de datasets; motores de grafos como Neo4j o Neptune para modelar conocimiento; y bases vectoriales como Pinecone, Weaviate, Chroma o las integraciones de FAISS en plataformas cloud.
Este no es un cambio estético, sino operativo: si la IA depende de los datos y los datos dependen de la semántica, la arquitectura debe capturar esa semántica desde el origen.
Pipelines híbridos: batch, streaming y near-real-time
En las arquitecturas tradicionales, el pipeline de datos era mayoritariamente batch. Con IA, la gestión de datos se acelera: los modelos necesitan entrenamiento continuo, validación permanente y señales frescas.
Por ejemplo, un modelo de recomendación necesita:
-
Datos batch de histórico (compras, navegación, catálogos).
-
Eventos en streaming para detectar señales recientes (clics, búsquedas, sesiones).
-
Procesamiento near-real-time para features que caducan en minutos (por ejemplo, “últimos 5 productos vistos”).
Este triple flujo requiere arquitecturas híbridas donde conviven:
-
CDC (Change Data Capture) para extraer cambios de sistemas operacionales.
-
Streams con Kafka, Pulsar o Kinesis.
-
Microbatches con Spark o Flink.
-
Orquestación con Airflow, Dagster o Prefect.
La clave está en la consistencia online/offline, uno de los problemas más delicados del ML moderno. Un modelo entrenado con features generadas en batch puede comportarse de manera impredecible si, en producción, esas mismas features se calculan en tiempo real de forma ligeramente diferente. De aquí nace la necesidad del componente central de toda plataforma AI-native: la feature store.
Feature store: el corazón del machine learning moderno
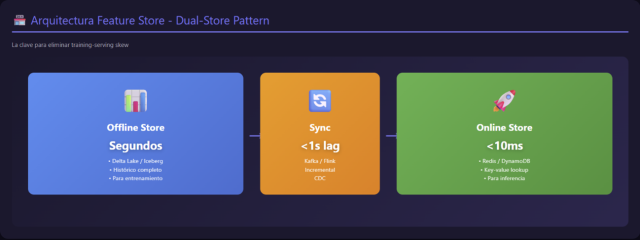
Una feature store es mucho más que un repositorio de columnas. Es un sistema de coherencia. Permite:
-
Definir features como código, incluyendo sus transformaciones.
-
Versionarlas y controlarlas como artefactos.
-
Garantizar consistencia entre entrenamiento e inferencia.
-
Proveer un catálogo para que los equipos reutilicen definiciones sin duplicarlas.
-
Mantener historiales para experimentación.
Su adopción reduce drásticamente el tiempo de desarrollo de modelos y evita errores comunes como la deriva de definición (feature drift) o los cálculos inconsistentes entre entornos.
Una feature store moderna integra tres capas:
-
Offline store: generalmente sobre un lakehouse (Parquet/Delta).
-
Online store: KV stores de baja latencia (Redis, DynamoDB, AlloyDB).
-
Registry de definiciones versionadas.
Caso práctico: en una fintech, una feature "ratio de gasto en las últimas 24 horas" debe calcularse igual en batch para entrenamiento y en un microservicio de scoring en 50 ms. Sin una feature store, esto suele dar lugar a drift, bugs y degradación del modelo.
Vector databases y motores semánticos
Los vector stores son el equivalente moderno de los índices invertidos que hicieron posibles los grandes buscadores de Internet. Su relevancia es enorme: permiten búsquedas semánticas, RAG, clasificación por similitud, clustering avanzado y análisis basado en significado.
Las arquitecturas AI-native deben integrar bases vectoriales en un patrón claro:
-
Pipeline de generación de embeddings
-
Ingesta
-
Limpieza
-
Chunking
-
Transformación mediante un modelo embedding (normalmente un modelo pequeño, rápido y estable)
-
Inserción en el vector store
-
-
Indexación y refresco
-
Reindexado parcial
-
Compresión PQ
-
Agrupación por espacios semánticos
-
-
Query semántica + re-ranking
-
Búsqueda aproximada
-
Re-ranking con LLM
-
Evaluación de calidad de resultados
-
-
Gobernanza de vectores
-
Retención
-
Versionado
-
Eliminación segura de información sensible
-
El reto no está solo en almacenar vectores, sino en mantener la coherencia entre el índice y los datos originales, un problema que las plataformas deben resolver con estrategias de refresco incremental, detección de desincronización y políticas de versionado.
Infraestructura de cómputación: GPU, escalabilidad y gateways de inferencia
La infraestructura es probablemente la parte que ha evolucionado más rápido. Los modelos modernos exigen:
-
GPU clusters, muchas veces con arquitecturas de alto ancho de banda (NVLink).
-
Autoscaling híbrido: nodos on-demand y nodos spot para reducir costes.
-
Containers optimizados: CUDA, TensorRT, Triton o servidores como vLLM o SGLang.
-
Inference gateways que gestionan autenticación, rate limiting, logging y aislamiento de contexto.
Una diferencia clave respecto a infraestructura tradicional es el comportamiento económico. Mientras que un cluster de datos puede dimensionarse de forma previsible, una plataforma de inferencia puede tener picos impredecibles. El CIO debe adoptar estrategias de FinOps para evitar escaladas de coste, como:
-
Autoscaling controlado
-
Cuotas por equipo
-
Cacheo de embeddings
-
Reutilización de resultados (semantic caching)
-
Limitación de prompts
-
Políticas de expiración de contextos
La infraestructura AI-native se acerca mucho a los modelos SRE que se utilizan en grandes servicios de Internet. No se trata solo de cómputo, sino de fiabilidad, latencia y gobernanza del gasto.
Observabilidad para IA: más allá del logging y las métricas
La observabilidad clásica monitoriza pipelines, latencias, colas o fallos. Pero la IA introduce nuevas preguntas:
-
¿Se está degradando el comportamiento del modelo?
-
¿Han cambiado las distribuciones de los datos?
-
¿El modelo está generando respuestas inestables?
-
¿Qué prompts generan mayores desviaciones?
-
¿Hay riesgo de filtración de datos sensibles?
Los sistemas modernos deben monitorizar:
-
Drift de datos
-
Drift de modelo
-
Calidad de inferencias
-
Hallucination rate
-
Toxicidad y sesgo
-
Embeddings fuera de dominio
-
Costo por inferencia
De aquí la necesidad de herramientas de ML observability como Arize, WhyLabs, Fiddler u opciones cloud. Un componente que antes era opcional ahora es imprescindible.
Seguridad, privacidad y confianza
Las arquitecturas AI-native deben reforzar la seguridad en múltiples niveles:
Seguridad del dato
-
Cifrado en reposo y movimiento
-
Controles de acceso por política (ABAC, PBAC)
-
Clasificación automática de datos sensibles con modelos LLM
-
Red-teaming de prompts para detectar vulnerabilidades
Seguridad de los modelos
-
Prevención de prompt injection
-
Aislamiento de contextos
-
Auditoría de logs de inferencia
-
Reglas de filtrado semántico (RASP para IA)
Seguridad operativa
-
Validación permanente del contenido generado
-
Análisis continuo de riesgos regulatorios
-
Trazabilidad completa sobre datasets y modelos
La confianza no es un componente opcional, especialmente en sectores regulados: finanzas, salud, administración pública o seguros. Sin una capa de seguridad sólida, cualquier iniciativa de IA corre riesgo jurídico, reputacional y operacional.
Componentes Arquitectónicos Específicos para IA
Un análisis detallado de los componentes básicos, con ejemplos de cómo se implementan en las soluciones de referencia.
Feature Store: El Componente Crítico que los Data Warehouses No Ofrecen
Un Feature Store es un repositorio centralizado de features (variables/atributos) para machine learning, con capacidades duales:
Offline Store (para entrenamiento):
- Almacena histórico completo de features
- Acceso batch sobre grandes volúmenes
- Típicamente: Delta Lake, Iceberg, o incluso un data warehouse
- Latencias: segundos/minutos (aceptable para entrenamiento)
Online Store (para inferencia en producción):
- Almacena solo valores actuales de features
- Acceso individual por key con latencias <10ms
- Típicamente: Redis, DynamoDB, Cassandra, Feast
- Sincronización continua desde Offline Store
¿Por qué es crítico?
El problema número uno en ML en producción es el training-serving skew: las features se calculan de una forma durante entrenamiento (Python/Pandas en notebook) y de otra forma durante inferencia (Java/Scala en aplicación). Pequeñas diferencias en lógica de transformación causan que el modelo funcione brillantemente en desarrollo pero degrada en producción.

Ejemplo real de training-serving skew:
Sutil diferencia: el código Python usa ventana móvil de 7 filas, el Java usa 7 días calendario. Si un cliente tiene 20 transacciones en 7 días, el resultado diverge dramáticamente.
Solución con Feature Store:
La transformación se define una vez, se ejecuta consistentemente en ambos contextos, eliminando el skew.
Bases de datos Vectoriales: Búsqueda Semántica a Escala
Los sistemas RAG (Retrieval-Augmented Generation) han explotado en 2023-2024. La arquitectura típica:
- Documentos corporativos → Embeddings (vectores de 1536 dimensiones con OpenAI)
- Vectores almacenados en base de datos vectorial
- Query del usuario → Embedding → Búsqueda de similitud coseno → Top-K documentos relevantes
- Documentos + query → LLM → Respuesta contextualizada

¿Por qué no usar un data warehouse para esto?
Una búsqueda de similitud coseno sobre 10 millones de vectores requiere:
- Comparar el vector query contra 10M vectores almacenados
- Para vectores de 1536 dimensiones: 15.36 billones de multiplicaciones
En SQL puro sobre Snowflake:
Latencia: 10-30 segundos para 10M documentos. Inviable para una aplicación interactiva.
Con índice HNSW (Hierarchical Navigable Small World) en Pinecone/Weaviate:
Índice especializado que organiza vectores en grafos navegables. Búsqueda aproximada (ANN - Approximate Nearest Neighbors) con garantías de recall >95%.
Latencia: 10-50 milisegundos para 100M+ vectores.
Integración en lakehouses modernos:
Databricks Unity Catalog creo Vector Search nativo (2024):
Ventaja: Embeddings y datos estructurados en el mismo lakehouse, gobernanza unificada, sin sincronización entre sistemas.
Model Registry: Versionado y Linaje de Modelos
Los data warehouses versionan datos. Los Model Registries versionan modelos ML:
Funcionalidades clave:
- Versionado automático: Cada entrenamiento genera una nueva versión
- Metadata rica:
- Hiperparámetros usados
- Métricas de evaluación (accuracy, precision, recall, AUC)
- Datos de entrenamiento (snapshot exacto)
- Features utilizadas
- Framework y librerías (Python 3.9, TensorFlow 2.13)
- Stages de lifecycle:
Development: ExperimentaciónStaging: Pre-producción, validaciónProduction: Sirviendo tráfico realArchived: Modelos antiguos, retención para auditoría
- Linaje completo: Desde datos raw → features → modelo → predicciones
MLflow (open-source) integrado en lakehouses:
Consulta posterior para auditoría:
¿Por qué un data warehouse no puede hacer esto?
Snowflake puede almacenar la metadata (en tablas), pero:
- No se integra con frameworks ML (TensorFlow, PyTorch)
- No versiona archivos binarios de modelos eficientemente
- No provee APIs para desplegar modelos (endpoints de inferencia)
- No gestiona el ciclo de vida (dev → staging → production)
MLflow + Lakehouse es el estándar de facto.
Streaming Compute: Flink, Spark Structured Streaming, Kafka Streams
El BI tradicional es batch: ETL nocturna, dashboards que se refrescan cada hora o cada día.
La IA en producción es streaming: decisiones en milisegundos sobre datos que llegan continuamente.
Casos de uso streaming ML:
Detección de fraude en pagos:
- Transacción llega → Kafka
- Flink calcula features en ventanas temporales (últimos 5 min, última hora, últimas 24h)
- Modelo evalúa probabilidad de fraude
- Si >80%: bloquear, si 50-80%: verificación adicional, si <50%: aprobar
- Latencia total: <100ms
Recomendaciones en tiempo real:
- Usuario navega sitio web → eventos de clickstream a Kafka
- Spark Structured Streaming actualiza perfil de intereses
- Cada pageview: recomendaciones personalizadas basadas en sesión actual + histórico
- Feature Store se actualiza incrementalmente
Mantenimiento predictivo en manufactura:
- 10,000 sensores IoT → MQTT → Kafka (50k eventos/segundo)
- Flink detecta patrones anómalos (temperatura, vibración, presión)
- LSTM predice probabilidad de fallo en próximas 24h
- Si >75%: alerta a mantenimiento, programar intervención
Arquitectura típica:
¿Por qué el data warehouse no encaja?
- Snowflake/BigQuery no se integran nativamente con Kafka
- Micro-batch cada segundo generaría millones de queries, costes prohibitivos
- Latencias de escritura demasiado altas (bulk loading optimizado para grandes batches)
- No hay concepto de "ventanas temporales" o "watermarks" para eventos desordenados
Lakehouse + Delta Lake es ideal:
Delta Lake garantiza ACID incluso con escrituras streaming concurrentes.
Arquitecturas de Referencia para IA: Tres Patrones Dominantes
Lakehouse AI-Native (Databricks/Fabric)
Cuándo elegir:
- Workloads mixtos: ML + BI
- Petabytes de datos históricos
- Feature engineering complejo
- Necesidad de gobernanza estricta
Stack tecnológico:
Ventajas:
- Todo en una plataforma: menos complejidad operacional
- Gobernanza unificada (no sincronizar permisos entre sistemas)
- Costes de almacenamiento bajos (S3/ADLS)
- Escalado elástico de computación
Desventajas:
- Curva de aprendizaje (requiere expertise en Spark)
- Vendor lock-in (aunque Delta es open-source)
- No tan rápido como warehouse puro para queries SQL simples
Caso de uso ideal: Fintech con 500TB de transacciones históricas, necesita entrenar modelos de fraude sobre ventanas de 2 años, servir predicciones en tiempo real (<100ms), y también proveer dashboards de BI para analistas de negocio.
Data Warehouse + Vector DB + Feature Store (Híbrido)
Cuándo elegir:
- Fuerte inversión existente en data warehouse
- BI es la carga de trabajo principal, ML es complementario
- Volumetría moderada (<50TB)
- No requiere ML sobre datos raw no estructurados
Stack tecnológico:
Ventajas:
- Aprovechar inversión existente en warehouse
- BI sigue siendo óptimo (usuarios no necesitan reentrenarse)
- Agregar capacidades ML sin gran disrupción
Desventajas:
- Complejidad: sincronización entre 3-4 sistemas
- Costes: pagar data warehouse + vector DB + feature store
- Latencias: múltiples hops para obtener features + embeddings
- Gobernanza fragmentada (permisos en cada sistema)
Caso de uso ideal: Empresa de seguros con Snowflake establecido para actuarial y finanzas. Quieren agregar chatbot RAG sobre documentación de pólizas y modelos de recomendación de productos. Volumen de datos moderado, no justifica migración completa a lakehouse.
Especializado por Dominio (Polyglot Architecture)
Cuándo elegir:
- Organización grande con múltiples equipos independientes
- Cada dominio tiene necesidades muy específicas
- Budget y expertise para gestionar múltiples plataformas
Stack tecnológico:
Ventajas:
- Best-of-breed para cada caso de uso
- Equipos autónomos, eligen sus herramientas
- Evita "one size fits all"
Desventajas:
- Altísima complejidad operacional
- Costes de integración y sincronización
- Talento especializado para cada plataforma
- Gobernanza federada difícil de implementar
Caso de uso ideal: Multinacional con 10,000+ empleados, múltiples business units. Finanzas usa Snowflake (gobernanza estricta, auditoría). Data science usa Databricks (petabytes de datos de clientes). DevOps usa Elasticsearch (logs de aplicaciones). IoT usa TimescaleDB (millones de sensores).
Decisiones Críticas: Matriz de Evaluación para IA
Volumetría y Tasa de Crecimiento
| Volumen Datos | Tasa Crecimiento | Recomendación |
|---|---|---|
| <10 TB | <1 TB/año | Data Warehouse (Snowflake/BigQuery) suficiente |
| 10-100 TB | 5-20 TB/año | Lakehouse si ML intensivo, Warehouse si solo BI |
| 100TB-1PB | 50-100 TB/año | Lakehouse mandatorio (costes warehouse prohibitivos) |
| >1 PB | >100 TB/año | Lakehouse + tiering agresivo (S3 Glacier para cold data) |
Cálculo de costes comparativo (ejemplo 200TB):

Snowflake:
- Almacenamiento: 200 TB × $40/TB/mes = $8,000/mes
- Compute (estimado uso moderado): $15,000/mes
- Total: ~$23,000/mes
Lakehouse (Databricks + S3):
- Almacenamiento S3: 200 TB × $23/TB/año ÷ 12 = $383/mes
- Databricks compute (similar workload): $12,000/mes
- Total: ~$12,400/mes (reducción de 46%)
Con 1PB de datos, la diferencia sería $115k/mes (warehouse) vs $25k/mes (lakehouse).
Tipo de Workload Predominante
Usa este flujo de decisión:
Latencia Requerida
Matriz de decisión por latencia:
| Latencia Requerida | Componente Necesario | Arquitectura |
|---|---|---|
| Segundos-minutos | Data Warehouse | Snowflake/BigQuery OK |
| Cientos de ms | Lakehouse | Databricks SQL, BigQuery |
| <100ms | Feature Store + cache | Lakehouse + Redis/DynamoDB |
| <10ms | In-memory KV store | Redis Cluster, DynamoDB DAX |
| <1ms | Local cache | Application-level cache (Caffeine, Guava) |
Implicación: Si tu aplicación ML requiere latencias <100ms, un data warehouse tradicional NO es viable como componente principal.
Madurez del Equipo
Evaluación realista de skills:
| Perfil del Equipo | Arquitectura Recomendada | Justificación |
|---|---|---|
| Analistas SQL, sin ingenieros de datos | Data Warehouse | Mínima curva de aprendizaje |
| Ingenieros de datos con Spark | Lakehouse | Aprovecha expertise existente |
| Data scientists con Python, sin ingeniería | Warehouse + SageMaker | Abstrae complejidad infraestructura |
| Equipo mixto (BI + DS + ingeniería) | Lakehouse | Plataforma unificada reduce fricción |
| Startup sin equipo técnico dedicado | Servicios gestionados | BigQuery ML, Vertex AI AutoML |
Error común: Subestimar la complejidad operacional del lakehouse. Requiere:
- Expertise en Spark (configuración clusters, tuning de rendimiento)
- Gestión de formatos transaccionales (Delta Lake compaction, Z-ordering)
- Monitorización de pipelines streaming
- Debugging de jobs distribuidos
Si tu equipo son 2 analistas de datos, un lakehouse es over-engineering. BigQuery + BigQuery ML es más pragmático.
Requisitos de Gobernanza
Evaluación por industria:
| Industria | Regulación | Requisitos Clave | Arquitectura |
|---|---|---|---|
| Banca/Finanzas | Basel III, GDPR, SOX | Auditoría forense, inmutabilidad, explicabilidad decisiones | Lakehouse con Unity Catalog o Warehouse con retención extendida |
| Healthcare | HIPAA, GDPR | Encriptación end-to-end, control acceso nivel celda, pseudonimización | Lakehouse con HIPAA compliance (Databricks Healthcare) |
| Retail/E-commerce | GDPR, CCPA | Right to be forgotten, consentimiento granular | Lakehouse con hard deletes (Delta Lake GDPR tools) |
| Telecomunicaciones | GDPR, regulación local | Residencia de datos por país, retención limitada | Multi-region lakehouse con data sovereignty |
Funcionalidades críticas:
Control de acceso nivel columna:
Auditoría completa:
Data warehouses tradicionales tienen limitaciones:
- Snowflake: Dynamic Data Masking (sí), column-level security (limitado)
- BigQuery: Column-level security (desde 2023), auditoría (sí pero menos granular)
- Redshift: Limitado, requiere vistas complejas para enmascaramiento
Casos de Uso Detallados: Arquitectura por Industria
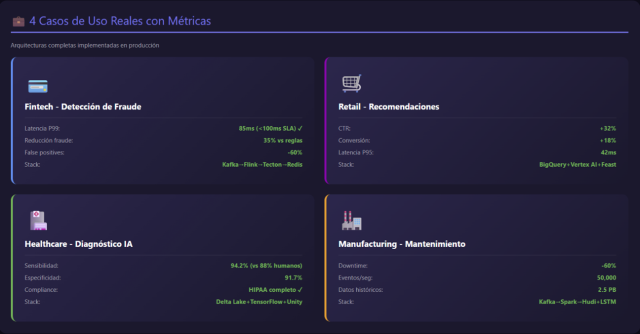
Fintech: Detección de Fraude en Tiempo Real
Contexto: Fintech procesa 10,000 transacciones/segundo. Cada autorización de pago debe evaluarse en <100ms para decidir: aprobar, rechazar, o solicitar verificación adicional.
Requisitos técnicos:
- Latencia inferencia: <100ms (P99)
- Features: combinación de batch (histórico 90 días) y streaming (últimos 5 minutos)
- Modelo: XGBoost con 150 features
- Reentrenamiento: semanal con ground truth (transacciones reportadas como fraude)
- Auditoría: capacidad de explicar por qué se rechazó una transacción específica
Arquitectura implementada:
Métricas de negocio alcanzadas:
- Reducción fraude: 35% (vs sistema basado en reglas)
- Falsos positivos: reducción de 60% (menos rechazos legítimos)
- Latencia P99: 85ms (cumple SLA <100ms)
- Coste infraestructura: $18k/mes (vs $45k/mes en arquitectura anterior con Redshift)
¿Por qué lakehouse fue crítico?
- Redshift no podía sostener writes streaming a la tasa necesaria
- Costes de almacenar 500TB histórico en Redshift: $20k/mes sólo en almacenamiento
- Iceberg permite time travel: auditoría "¿qué features vio el modelo en esta transacción específica?"
Retail: Recomendaciones Personalizadas
Contexto: E-commerce con 5M de usuarios activos, 100k productos. Cada pageview debe mostrar 6 recomendaciones personalizadas.
Requisitos técnicos:
- Latencia: <50ms para no degradar experiencia usuario
- Personalización: basada en sesión actual + histórico de navegación/compras
- Cold start: recomendaciones para usuarios nuevos
- Freshness: productos recientemente añadidos deben aparecer rápido
Arquitectura implementada:
Métricas de negocio:
- CTR (click-through rate): +32% vs recomendaciones basadas en popularidad
- Conversión: +18%
- Average order value: +12%
- Latencia P95: 42ms
Decisión arquitectónica clave: BigQuery para datos históricos (BI + feature engineering) + Vertex AI para ML + Feast para feature store. No migraron a lakehouse completo porque:
- Equipo ya experto en BigQuery
- Volumetría (250TB total) manejable en BigQuery
- BigQuery ML permitió prototipado rápido inicial
- Vertex AI integración nativa con GCP
Aprendizajes:
- Inicialmente intentaron servir recomendaciones directamente desde BigQuery: latencias de 800ms, inviable
- Vertex AI Matching Engine redujo latencia 40x (800ms → 20ms)
- Reranking con LightGBM fue crítico: vector search solo da "similares", el ranking pondera objetivos de negocio
Healthcare: Diagnóstico Asistido por IA
Contexto: Red hospitalaria con 50 centros. Sistema de diagnóstico asistido para radiología: detectar anomalías en radiografías de tórax.
Requisitos técnicos:
- Datos multimodales: imágenes DICOM + historial clínico estructurado
- Compliance: HIPAA, rastrear quién accedió a qué imagen
- Reproducibilidad: versión exacta de modelo + datos para cada diagnóstico
- Explicabilidad: heatmaps de qué regiones de la imagen el modelo considera sospechosas
Arquitectura implementada:
Métricas clínicas:
- Sensibilidad (recall): 94.2% (vs 88% radiólogos junior)
- Especificidad: 91.7%
- Tiempo diagnóstico: reducción de 40% (modelo pre-filtra casos normales)
- False negatives: 5.8% (aceptable como herramienta de asistencia, no reemplazo)
¿Por qué lakehouse fue mandatorio?
- Imágenes DICOM (no estructuradas) no encajan en data warehouse
- Necesidad de combinar imágenes + historial clínico estructurado en un pipeline
- Unity Catalog crítico para HIPAA: auditoría forense de cada acceso
- Time travel en Delta Lake: reproducir exactamente qué vio el modelo en un diagnóstico específico (requisito regulatorio)
Aprendizaje crítico: Inicialmente almacenaron imágenes en S3 y metadata en RDS (PostgreSQL). Sincronización manual generó inconsistencias: metadata existía pero imagen había sido eliminada (violación de política de retención). Migrar todo a Delta Lake (incluyendo referencias a imágenes) con transacciones ACID resolvió el problema.
Manufacturing: Mantenimiento Predictivo IoT
Contexto: Planta de manufactura con 10,000 sensores en 500 máquinas críticas. Objetivo: predecir fallos con 24-48h de anticipación para programar mantenimiento preventivo.
Requisitos técnicos:
- Volumetría: 50,000 eventos/segundo (temperatura, vibración, presión, consumo eléctrico)
- Retención: 7 años (regulación industrial)
- Modelos: LSTM para series temporales (detectar patrones anómalos)
- Latencia inferencia: no crítica (batch diario es suficiente)
Arquitectura implementada:
Métricas operacionales:
- Downtime no planeado: reducción de 60%
- Coste mantenimiento: reducción de 25% (menos intervenciones reactivas)
- Precision@48h: 78% (de las alertas, 78% resultaron en fallo real)
- Recall: 85% (detecta 85% de fallos con anticipación)
Decisión arquitectónica: ¿Por qué Hudi?
- Delta Lake y Iceberg también eran opciones válidas
- Hudi elegido por upserts incrementales eficientes: cada máquina tiene registro de "estado actual" que se actualiza cada minuto
- Con Delta/Iceberg, actualizar 500 registros cada minuto requeriría merge full table scan (lento con 2.5PB)
- Hudi con índice Bloom filter: updates en tiempo casi constante
Coste total:
- Almacenamiento S3:
- Hot (últimos 6 meses): 180TB × $23/TB/año = $345/mes
- Cold (7 años histórico): 2.3PB × $1/TB/año = $192/mes
- Spark clusters (batch + streaming): $8,000/mes
- Total: ~$8,500/mes
Alternativa descartada (data warehouse):
- Redshift: 2.5PB × $85/TB/mes = $212k/mes (solo almacenamiento)
- 25x más caro, inviable
Feature Engineering a Escala: El Desafío Operacional
El Problema de las Ventanas Temporales
El Feature engineering para ML a menudo requiere agregaciones sobre ventanas temporales:
Ejemplo: credit scoring
Problema durante la fase de entrenamiento: Para cada sample del dataset, necesitas calcular estas ventanas. Con 10M de customers y 3 años de histórico:
- Ventana de 7 días: escanear últimos 7 días de transacciones por cada cliente en cada fecha de entrenamiento
- Con 10M clientes × 1,000 fechas de entrenamiento = 10B operaciones de ventana
- En SQL puro: horas o días de procesamiento
Solución: materializar features incrementalmente
Beneficios:
- Materialización incremental: solo procesa datos nuevos
- Training:
SELECT * FROM customer_features_7d WHERE date = training_date→ instantáneo - Inference: lookup directo por customer_id + current_date
- Coste: procesar una vez, leer N veces
Exactitud Point-in-Time: Evitar Data Leakage
Error clásico de data leakage:
Ejemplo concreto:
- Transacción T1 ocurre el 2024-01-15 a las 10:00
- Feature "txn_count_7d" se calcula diariamente a las 23:00
- Si usas el valor del 2024-01-15 calculado a las 23:00, incluye transacciones que ocurrieron DESPUÉS de T1
- El modelo aprende con información del futuro → precisión artificial alta en entrenamiento, desastre en producción
Solución: point-in-time correct join
Implementación manual si no usas Feature Store:
Feature Skew: Training vs Serving
Problema: Features calculadas de manera diferente en entrenamiento y producción producen inconsistencias.
Caso real:
Durante entrenamiento (Jupyter notebook):
Durante serving (Java microservice):
Diferencias sutiles que causan skew:
pd.to_datetime('now')usa timezone local del servidor de entrenamientoLocalDate.now()en producción puede estar en timezone diferente- Si el servidor de entrenamiento está en UTC-8 y producción en UTC+0, hay 8 horas de diferencia
- Para compras cercanas al cambio de día,
days_since_last_purchasedifiere en 1 día
Solución: Feature Store con transformación unificada
Ahora la lógica está centralizada. Cambios se propagan automáticamente a training y serving.
El Futuro: Tendencias 2025-2027
LLMs como Analistas sobre tu Lakehouse
Visión: En lugar de que los analistas de negocio escriban SQL, interactúan con un LLM que:
- Comprende el esquema del lakehouse (gracias a Unity Catalog)
- Genera SQL optimizado basado en preguntas en lenguaje natural
- Ejecuta las queries
- Interpreta resultados y genera insights
Arquitectura emergente:
Tecnologías habilitadoras:
- Langchain SQL Agent: Framework que conecta LLMs con bases de datos
- Unity Catalog metadata: Descriptions de tablas/columnas que alimentan el contexto del LLM
- dbt semantic layer: Define métricas de negocio que el LLM puede referenciar ("revenue" = SUM(price × quantity))
Databricks está desarrollando esta funcionalidad activamente (preview en 2024):
Federated Learning sobre Lakehouses
Problema: Organizaciones con datos sensibles (hospitales, bancos) no pueden centralizar datos por regulación o privacidad.
Solución tradicional: Cada organización entrena modelos localmente, no hay colaboración.
Federated Learning: Entrenar colaborativamente sin compartir datos.
Arquitectura:
Proceso:
- Cada hospital inicia con mismo modelo global (pesos aleatorios)
- Ronda 1:
- Hospital A entrena localmente en sus 100k pacientes → calcula gradientes
- Hospital B entrena localmente en sus 150k pacientes → calcula gradientes
- Hospital C entrena localmente en sus 80k pacientes → calcula gradientes
- Hospitales envían solo gradientes al agregador (no datos raw)
- Agregador promedia gradientes (peso ajustado por tamaño de dataset)
- Agregador actualiza modelo global y lo distribuye
- Ronda 2: Repetir proceso con nuevo modelo global
Después de 50-100 rondas: Modelo global alcanza precisión comparable a entrenar centralizadamente, pero sin compartir datos sensibles.
Implementación con Flower (framework federated learning):
python
Ventajas:
- Privacidad preservada: Datos nunca salen del lakehouse local
- Cumplimiento: Cumple GDPR, HIPAA (datos no se transfieren)
- Modelo más robusto: Entrenado en 330k pacientes (A+B+C), pero sin centralizar
Desafíos:
- Heterogeneidad: Si Hospital A tiene población mayormente >65 años y Hospital C <40 años, gradientes pueden divergir
- Comunicación: Las múltiples rondas requieren coordinación (aunque solo de gradientes, no GB de datos)
- Privacidad diferencial: Agregar ruido a gradientes para que no se pueda inferir información de pacientes individuales
Proyección 2027: Lakehouses nativamente soportarán federated learning. Unity Catalog coordinará federación entre múltiples organizaciones con políticas de governanza automáticas.
AutoML Nativo en Plataformas de Datos
Evolución:
2020: AutoML requería plataformas separadas (H2O.ai, DataRobot)
2024: BigQuery ML, Databricks AutoML integrado
2027: AutoML será "invisible", ejecutándose automáticamente
BigQuery ML hoy:
sql
BigQuery prueba automáticamente:
- Gradient Boosted Trees
- Deep Neural Networks
- Linear/Logistic Regression
- Ensemble methods
Devuelve el mejor según validation set.
Databricks AutoML:
python
Tendencia para 2027: "Continuous AutoML"
En lugar de entrenar una vez, el lakehouse lo hace continuamente:
- Monitoriza drift de datos (distribución cambia)
- Detecta degradación de modelo (accuracy cae)
- Automáticamente lanza AutoML para reentrenar
- A/B test nuevo modelo vs actual
- Si nuevo modelo mejora métricas de negocio → promote a producción
- Todo sin intervención humana
Ejemplo conceptual:
python
El Sistema monitoriza continuamente. Si la precisión cae a 0.88, lanza AutoML, entrena un nuevo modelo, lo testea con el 10% del tráfico durante 7 días, y si reduce los falsos positivos en un 5%, lo despliega automáticamente.
Multimodal AI: Texto + Imágenes + Audio en un Pipeline
Contexto: Aplicaciones modernas que procesan múltiples modalidades simultáneamente.
Ejemplo: Plataforma de e-commerce
Búsqueda multimodal:
- El usuario sube una foto de un producto que vio en la calle
- El sistema busca productos similares basándose en:
- Imagen: similitud visual (color, forma, estilo)
- Texto: descripción del producto
- Metadata: precio, marca, categoría
Arquitectura multimodal:
Implementación de embeddings multimodales:
python
Query multimodal:
python
Ventaja del lakehouse:
- Imágenes raw + embeddings + metadata en un repositorio unificado
- Procesamiento batch (Spark) + indexación (Vector Search) integrados
- Versionado: si cambias modelo de embeddings, regeneras todo con time travel para comparar
Proyección para 2027: Modelos multimodales de base (GPT-4V, Gemini Ultra) nativamente integrados en lakehouses. No necesitarás generar embeddings manualmente, el lakehouse lo hará automáticamente.
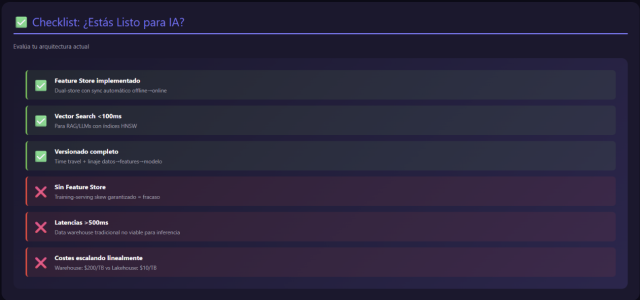
Checklist de Evaluación: ¿Tu Arquitectura está Lista para IA?
8.1 Preparación Básica
Acceso a Datos:
- ¿Puedes acceder a datos raw sin múltiples copias/transformaciones?
- ¿Los científicos de datos pueden explorar datos abrir sin tickets a IT?
- ¿La latencia de acceso a datasets históricos es <5 minutos?
Metadatos y Catálogo:
- ¿Tienes el catálogo de datos actualizado automáticamente?
- ¿Los esquemas, descripciones, owners están documentados?
- ¿El Linaje de datos es rastreable (raw → features → modelo)?
Versionado:
- ¿Puedes reproducir el estado de una tabla a hace 30 días?
- ¿Los modelos ML están versionados con metadata (hiperparámetros, métricas)?
- ¿Las features están versionadas junto con los modelos?
Costes:
- ¿El almacenamiento permite retener años de histórico sin costes prohibitivos?
- ¿Los costes de computación son predecibles y controlables?
- ¿Dispones de tiering automático para datos fríos?
Capacidades ML Específicas
Entrenamiento:
- ¿Puedes escanear TBs de datos para entrenamiento sin timeouts?
- ¿Soportas entrenamiento distribuido (multi-GPU, multi-node)?
- ¿Tienes frameworks populares (TensorFlow, PyTorch, XGBoost) integrados?
Feature Store:
- ¿Tienes Feature Store o un plan para implementar alguno?
- ¿Las Features están compartidas entre equipos (no silos)?
- ¿La sincronización offline-online está automatizada?
- ¿Tienes exactitud de Point-in-time garantizada?
Inferencia:
- ¿Las latencias de inferencia cumplen con los SLAs de aplicación?
- ¿Los Endpoints de inferencia son escalables automáticamente?
- ¿Tienes monitorización de drift y de la degradación de modelos?
Vector Search (para RAG/LLMs):
- ¿Soportas búsqueda vectorial con latencias <100ms?
- ¿Tienes Índices especializados (HNSW, IVF) disponibles?
- ¿Dispones de integración con LLMs para RAG?
Gobernanza y Cumplimiento
Seguridad:
- ¿Tienes control de acceso granular (nivel columna/fila)?
- ¿Realizas enmascaramiento dinámico de datos sensibles?
- ¿Dispones de encriptación at-rest y in-transit?
Auditoría:
- ¿Está cada acceso a datos sensibles logeado?
- ¿Tus Logs son inmutables y retenidos según regulación?
- ¿Puedes responder a la pregunta "quién accedió a qué dato cuándo"?
Explicabilidad:
- ¿Tus modelos ML tienen explicabilidad (SHAP, LIME)?
- ¿Las decisiones automatizadas son auditables?
- ¿Puedes seguir el linaje completo: datos → features → modelo → predicción?
Operaciones y Escalabilidad
Monitorización:
- ¿Dispones de métricas de calidad de datos automatizadas?
- ¿Recibes alertas cuando los datos o los modelos se degradan?
- ¿Dispones de cuadros de mando de costes en tiempo real?
Escalabilidad:
- ¿Tu arquitectura escala horizontalmente sin rediseño?
- ¿Dispones de eutoescalado de computación basado en demanda?
- ¿Tienes los cuellos de botella identificados y documentados?
Disaster Recovery:
- ¿Dispones de backups automáticos y testados?
- ¿Tienes RPO/RTO definidos y alcanzables?
- ¿Existe un plan de recuperación documentado y ensayado?
Conclusiones y Recomendaciones
Principios Fundamentales
1. La IA ha cambiado los requisitos arquitectónicos
No es una evolución del BI tradicional, es un paradigma diferente. Latencias 100x menores, formatos de datos radicalmente distintos, necesidad de reproducibilidad absoluta. Tu arquitectura de 2020 (optimizada para SQL) probablemente no está lista para IA de producción de 2025.
2. El Lakehouse es la arquitectura dominante para flujos de trabajo AI-native
No es una moda, existen razones económicas y técnicas sólidas:
- Economía: 10-40x más barato que data warehouse para almacenamiento a escala
- Flexibilidad: Soporta datos estructurados + no estructurados + vectores
- Integración: ML frameworks, Feature Stores, Vector Search nativos
- Gobernanza: Unity Catalog iguala (o supera) las capacidades de data warehouses
3. Los Feature Stores son críticos, no opcionales
El 80% de fracasos de ML en producción son por training-serving skew. El Feature Store no es un "nice to have", es básico para cualquier modelo en producción que requiera features calculadas.
4. Data Warehouses siguen siendo válidos para casos específicos
Si tu organización:
- Tiene <50TB de datos estructurados
- Workload es 95% BI tradicional, 5% ML experimental
- Equipo es experto en SQL, tiene menos conocimiento de Spark/Python
- No requiere latencias <500ms
Entonces Snowflake/BigQuery u otros son perfectamente válidos. No migres por migrar.
5. Arquitecturas híbridas son la realidad
Muchas empresas maduras operan:
- Data warehouse para BI crítico y cumplimiento
- Lakehouse para ML y big data
- Bases operacionales (PostgreSQL, MongoDB)
- Caches (Redis) para latencias ultra-bajas
La complejidad está en la orquestación y gobernanza unificada, no en cada componente individual.
Propuesta de Hoja de Ruta de Migración, si has de migrar
Adoptar una arquitectura AI-native no es una decisión técnica aislada: implica un replanteamiento estratégico, organizativo y económico de la plataforma de datos. Desde la perspectiva del CIO y del arquitecto principal, la transición debe abordarse como un diagnóstico progresivo que combine ambición e incrementalismo. Antes de construir, es necesario evaluar el “estado de salud” de la organización.
El primer paso consiste en validar la madurez del dato. No hay IA sostenible sin datos limpios, catalogados y accesibles. La organización debe evaluar si sus pipelines actuales soportan sincronización online/offline, si el lakehouse cuenta con versionado real y si los metadatos permiten auditar datasets completos. Muchas iniciativas fracasan no por la IA, sino por la falta de cimientos.
A continuación, conviene analizar la infraestructura disponible. No se trata solo de decidir entre GPU on-premise o cloud, sino de garantizar que el sistema de cómputo está preparado para autoscaling, aislamiento, control de gasto y latencias estables. La pregunta clave es si la plataforma puede absorber modelos sin sacrificar resiliencia. En este punto es común descubrir que la arquitectura es robusta para SQL, pero frágil para inferencias.
También debes evaluar la gobernanza aplicable. La empresa debe saber qué datos pueden utilizarse para entrenamiento, qué restricciones regulatorias aplican, cómo se gestionará el versionado de modelos y qué mecanismos existen para auditar inferencias. La gobernanza tradicional debe complementarse con políticas específicas de IA: retención de embeddings, clasificación semántica, trazabilidad de prompts y métricas de drift.
No olvides el análisis de coste y sostenibilidad. El CIO debe estimar el coste operativo de cada modelo —por request, por dataset, por ciclo de entrenamiento— y establecer límites claros. Sin un control del TCO, cualquier éxito inicial quedará eclipsado por un crecimiento descontrolado de la factura.
Es necesario construir un roadmap evolutivo, dividido por trimestres, que combine quick wins (asistentes internos, automatizaciones operativas) con pilares arquitectónicos (feature store, vector store, observabilidad). La clave no es avanzar rápido, sino avanzar bien: con fundamentos sólidos que preparen a la organización para escalar la IA de forma segura, eficiente y gobernada.
Fase 1: Evaluación (1-2 meses)
- Inventariar volumetría, crecimiento proyectado, tipos de datos
- Mapear patrones de acceso: quién usa qué, con qué frecuencia
- Identificar los puntos de dolor: costes, rendimiento, limitaciones actuales
- Evaluar la madurez del equipo: skills, capacidad de absorber nuevas tecnologías
- Calcular TCO actual y proyectado con alternativas
Fase 2: PoC (2-3 meses)
- Seleccionar 2-3 casos de uso representativos
- Implementar en la arquitectura objetivo (lakehouse o híbrida)
- Comparar rendimiento, costes y complejidad operacional
- Identificar gaps de skills y necesidades de formación
- Documentar aprendizaje y decisión go/no-go
Fase 3: Implementación de un Piloto (3-6 meses)
- Diseñar la arquitectura objetivo detallada
- Migrar primero datasets no críticos
- Implementar Feature Store para 1-2 modelos
- Capacitar al equipo con cursos/certificaciones
- Operación dual: sistema legacy + nuevo en paralelo
Fase 4: Migración Gradual (6-18 meses)
- Migrar workloads por oleadas (priorizar por ROI)
- Validar cada oleada antes de abordar la siguiente
- Monitorizar los costes semanalmente
- Ajustar la arquitectura basándote en aprendizajes
- Mantener legacy hasta la validación completa
Fase 5: Optimización Continua (ongoing)
- Compactación regular de Delta/Iceberg tables
- Z-ordering en columnas de filtrado frecuente
- Tiering agresivo (hot → warm → cold storage)
- Revisar costes y rendimiento trimestralmente
- Adoptar nuevas features de plataforma cuando estén maduras
Riesgos, anti-patrones y decisiones erróneas habituales
La entrada de la IA en la arquitectura de datos trae oportunidades inmensas, pero también una colección de riesgos y anti-patrones que se van repitiendo en empresas de todos los sectores. Algunos se deben al entusiasmo tecnológico, otros a la presión del negocio y muchos a una interpretación incompleta de cómo cambia la ingeniería cuando intervienen modelos. El CIO y los arquitectos necesitan reconocer estas señales desde el principio para evitar bloqueos, sobrecostes o fallos operativos.

Anti-patrón 1: Querer “añadir IA” sin rediseñar la arquitectura
Uno de los errores más frecuentes es concebir la IA como una pieza modular que puede instalarse sobre la arquitectura actual sin modificaciones profundas. Esto suele traducirse en:
-
Pipelines incompatibles con batch/streaming híbrido.
-
Falta de features consistentes entre entrenamiento e inferencia.
-
Data lakes sin versionado.
-
Catálogos incompletos o inexistentes.
-
Infraestructura insuficiente para cargas GPU.
El resultado es que el modelo puede funcionar bien en pruebas, pero fracasa al llegar a producción. La IA exige datos más frescos, semántica más rica y pipelines más orquestados que cualquier plataforma de analítica tradicional. No rediseñar la arquitectura es, casi siempre, un camino directo a la frustración.
Anti-patrón 2: Usar RAG como martillo para todos los clavos
El auge del Retrieval-Augmented Generation ha llevado a muchas organizaciones a adoptarlo como solución universal. Aunque el RAG es potentísimo —especialmente para construir asistentes internos y motores de búsqueda semántica— no es válido para todo:
-
No soluciona cálculos operacionales complejos.
-
No reemplaza a modelos transaccionales o de scoring.
-
Puede ofrecer respuestas inconsistentes si los embeddings no están bien gestionados.
-
Requiere pipelines de chunking, limpieza y refresh que muchas organizaciones subestiman.
El anti-patrón más grave es creer que RAG elimina la necesidad de gobernanza del dato: ocurre justo lo contrario. Un RAG mal alimentado amplifica errores, inconsistencias o datos obsoletos, generando una falsa sensación de fiabilidad.
Anti-patrón 3: Subestimar los costes operativos de la IA
En múltiples empresas vemos el mismo fenómeno: se adopta IA generativa sin tener un modelo financiero realista. Las consecuencias incluyen:
-
Facturas sorpresa por inferencias masivas.
-
Clusters GPU ocioso-costosos sin autoscaling.
-
Pipelines redundantes recalculando embeddings.
-
Almacenamiento de vectores duplicados.
-
Trabajo manual excesivo en experimentación por falta de MLOps.
La IA introduce una dinámica económica nueva: cada inferencia cuesta dinero. Y cada refresh de embeddings también. Y cada reentrenamiento más. Sin prácticas de FinOps —cache semántica, autoscaling, cuotas, análisis de coste por modelo— el TCO puede dispararse un orden de magnitud por encima del previsto.
Anti-patrón 4: Ignorar la importancia del metadato
El metadato es la savia principal de una arquitectura AI-native. Sin metadatos:
-
No hay discovery fiable
-
No existe versionado de datasets
-
No es posible reproducir experimentos
-
No hay auditoría para reguladores
-
El RAG pierde trazabilidad
-
La feature store no puede validar consistencia
Muchos proyectos se hunden no por falta de modelos, sino por falta de metadatos. La paradoja es evidente: cuanto más inteligente se vuelve una arquitectura, más dependiente es de información “sobre la información”. Las empresas que no invierten en metadatos acaban atrapadas en un caos operativo silencioso.
Anti-patrón 5: Construir modelos sin un ciclo MLOps completo
Un modelo entrenado sin MLOps es como una aplicación sin CI/CD: una bomba de relojería. En numerosas compañías, los modelos pasan de experimentación a producción sin:
-
Pruebas sistemáticas
-
Control de versiones
-
Validación de datos de entrada
-
Monitoreo de drift
-
Registros de inferencias
-
Entrenamientos reproducibles
Sin estos cimientos, el modelo empieza “a vivir su propia vida”: se degrada, se desvía, ofrece resultados inconsistentes o se adapta de forma errática a datos nuevos. Este anti-patrón hace que el éxito inicial de un piloto se convierta en fracaso operativo al cabo de meses.
Anti-patrón 6: Subestimar el componente jurídico y regulatorio
El impacto regulatorio de la IA es enorme. En sectores como banca, salud, administración pública o seguros, el riesgo de incumplimiento es tan alto que un simple error en la arquitectura puede desencadenar consecuencias graves.
Errores habituales:
-
Almacenar embeddings que contienen datos sensibles.
-
Usar modelos externos sin aislar contextos.
-
Delegar prompts “crudos” a proveedores externos.
-
No trazar datasets de entrenamiento.
-
No evaluar sesgo y fairness.
-
No controlar la exposición de información en sistemas conversacionales internos.
La solución no es frenar la IA, sino dotarla de una arquitectura que permita auditarla, gobernarla y justificarla.
Errores Críticos a Evitar
❌ Error 1: Big Bang Migration No migres todo de golpe. Las migraciones graduales con validación en cada fase reducen el riesgo drásticamente.
❌ Error 2: Subestimar la Complejidad Operacional Un Lakehouse requiere expertise real en Spark, formatos transaccionales y orquestación. No es sólo "instalar Databricks y listo".
❌ Error 3: No Formar al Equipo Tecnología nueva requiere skills nuevos. Presupuesta un 10-20% del proyecto en formación.
❌ Error 4: Ignorar los Costes de Computación El almacenamiento barato en lakehouse puede engañar. La computación mal optimizada dispara los costes. Monitoriza desde el día uno.
❌ Error 5: La Gobernanza como Afterthought Implementar el catálogo, linaje y control de acceso DESDE EL INICIO. Hacerlo después es 10 veces más difícil.
❌ Error 6: No Testear con Datos/Queries Reales Los benchmarks sintéticos (TPC-H) son sólo una referencia. Tu query específica puede tener un rendimiento radicalmente diferente.
❌ Error 7: Vendor Lock-in sin Evaluarlo Delta Lake es open-source pero Databricks platform es propietaria. Evalúa los costes de un cambio a futuro.
En conjunto, estos riesgos no deben interpretarse como barreras, sino como señales de madurez. La IA no fracasa por falta de potencia, sino por falta de arquitectura. Una plataforma bien diseñada es el mejor antídoto contra todos estos anti-patrones.
Métricas de Éxito
Cómo sabes si va todo bien? Has de medir y evaluar. Define las métricas que te van a permitir responder a esta pregunta.
Técnicas:
- Latencia P95 de inferencia ML: <SLA definido
- Throughput de entrenamiento: >X modelos/semana
- Disponibilidad Feature Store: >99.9%
- Time-to-production nuevos modelos: <Y semanas
Económicas:
- TCO mensual: reducción >X% vs arquitectura anterior
- Coste por TB almacenado: <$Z/mes
- Coste por predicción ML: <$W
- ROI del proyecto: positivo en <18 meses
Operacionales:
- Incidentes de calidad de datos: <N/mes
- Feature skew en producción: 0 ocurrencias
- Data drift detectado: <T horas hasta acción
- Tiempo promedio de recovery: <H horas
Organizacionales:
- Adopción por data scientists: >80%
- Satisfacción usuarios BI: >4/5
- Time-to-insight para analistas: -X%
- Modelos ML en producción: +Y% vs año anterior
Reflexiones Finales
La inteligencia artificial no es el futuro, es el presente. Las organizaciones que no adapten sus arquitecturas de datos para soportar workloads de IA quedarán relegadas competitivamente.
Pero la adaptación no significa necesariamente "tirar todo y empezar de cero". Muchas organizaciones prosperan con arquitecturas híbridas que combinan sus inversiones existentes (data warehouses) con nuevas capacidades (lakehouses, feature stores).
Lo crítico es:
- Evaluar honestamente tus necesidades actuales y proyectadas
- Calcular TCO realista incluyendo costes ocultos (operaciones y formación)
- Implementar gradualmente con validación en cada fase
- Monitorizar continuamente costes, rendimiento y calidad
La arquitectura de datos correcta no es la más moderna, ni la más barata, ni la más compleja. Es la que habilita a tu organización para entregar valor de negocio predeciblemente, a costes sostenibles, y con riesgos gestionables.
En 2025, el sweet spot para cargas de trabajo de IA está en el lakehouse para la mayoría de organizaciones medianas-grandes. Pero cada contexto es único. Usa este artículo como guía, no como dogma.
Recursos Adicionales
La adopción de arquitecturas AI-native exige una combinación de fundamentos sólidos y actualización continua. Para CIOs, arquitectos y equipos de datos, estas referencias ofrecen profundidad técnica, visión estratégica y guías prácticas contrastadas en entornos reales.
Uno de los recursos más valiosos es la documentación técnica sobre paradigmas de lakehouse y sistemas de versionado de datos. Los whitepapers de Delta Lake o Apache Iceberg permiten entender por qué el versionado transaccional se ha convertido en la base operativa para el entrenamiento y reentrenamiento de modelos. Complementan esta visión los análisis de vendors cloud sobre almacenamiento jerarquizado, cuotas por request y arquitecturas costo-eficientes para cargas de inferencia.
Para quienes deban integrar IA generativa, destacan las guías de RAG (Retrieval-Augmented Generation). Explican paso a paso cómo combinar vector stores, pipelines de embeddings y gateways de inferencia, así como patrones de caché semántica y mecanismos de evaluación automáticos. La mayoría incorpora ejemplos prácticos aplicables a casi cualquier sector.
En gobernanza y regulación, los informes especializados sobre auditoría de modelos, retención de metadatos y metodologías de explicabilidad ofrecen un marco indispensable, especialmente para sectores como banca, salud o seguros. Proveen criterios para medir drift, asegurar la trazabilidad del entrenamiento y estructurar procesos de revisión periódica.
En el plano metodológico, las mejores prácticas de MLOps —desde testing de features hasta despliegues canary— son un recurso operativo que permite anticipar problemas antes de que escalen. A esto se suman las guías de observabilidad de datos y modelos, que ayudan a diseñar un sistema de alertas que combine métricas clásicas con señales semánticas.
Finalmente, para completar una visión estratégica, los análisis de consultoras tecnológicas sobre adopción de IA ofrecen perspectivas comparativas sobre madurez, casos de uso prioritarios y riesgos habituales que pueden afectar la hoja de ruta de cualquier organización.
Documentación Técnica:
- Databricks Lakehouse Platform
- Delta Lake Documentation
- MLflow Documentation
- Chroma Documentation
- Apache Iceberg
- Feast Feature Store
Papers Académicos:
- "Lakehouse: A New Generation of Open Platforms" (CIDR 2021)
- "Delta Lake: High-Performance ACID Table Storage" (VLDB 2020)
- "Feature Store for ML" (Google Research 2017)
Cursos Recomendados:
- Databricks Certified Data Engineer Professional
- AWS Certified Machine Learning - Specialty
- Stanford CS329S: Machine Learning Systems Design
Comunidades:
| Attachment | Size |
|---|---|
| Documento resumen del artículo IA y Arquitecturas de Datos | 165.02 KB |
