
Introducción
Los outliers son los valores extremos que tiene una variable, dependiendo del modelo o requerimiento, puede ser necesario tratarlos ya sea transformando o eliminandolos.
Distribución variable “Income”
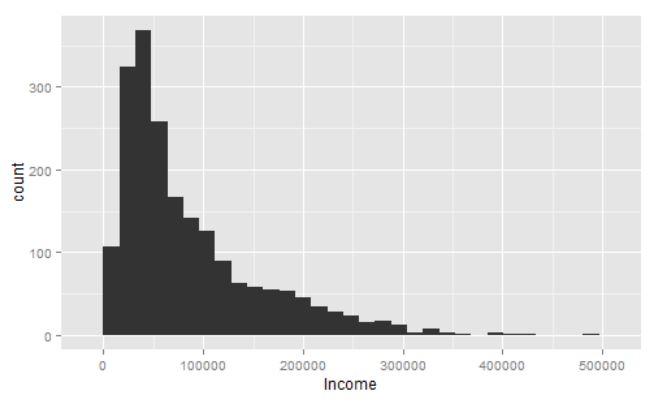
Ésta será la variable ejemplo, la cual representa los ingresos en $ de clientes de una empresa. Observamos como hay pocos casos con valores altos, y muchos con valores bajos.
Si elegimos eliminarlos…
Una pregunta común es ¿cuántos casos excluir? podemos elegir dejar afuera el 1% de los valores mas altos, con lo cual tendríamos:
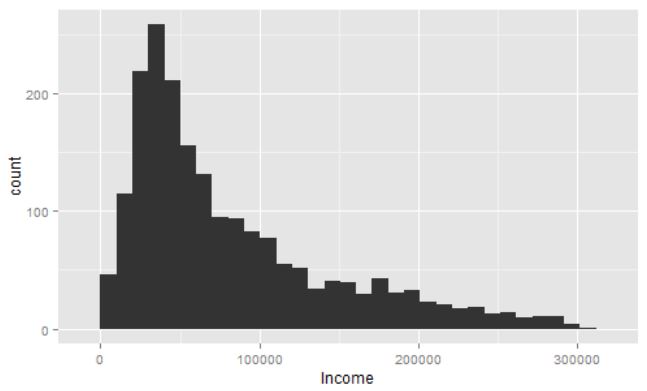
La distribución se ve muy similar, ahora llega hasta 300.000 en vez de 500.000.
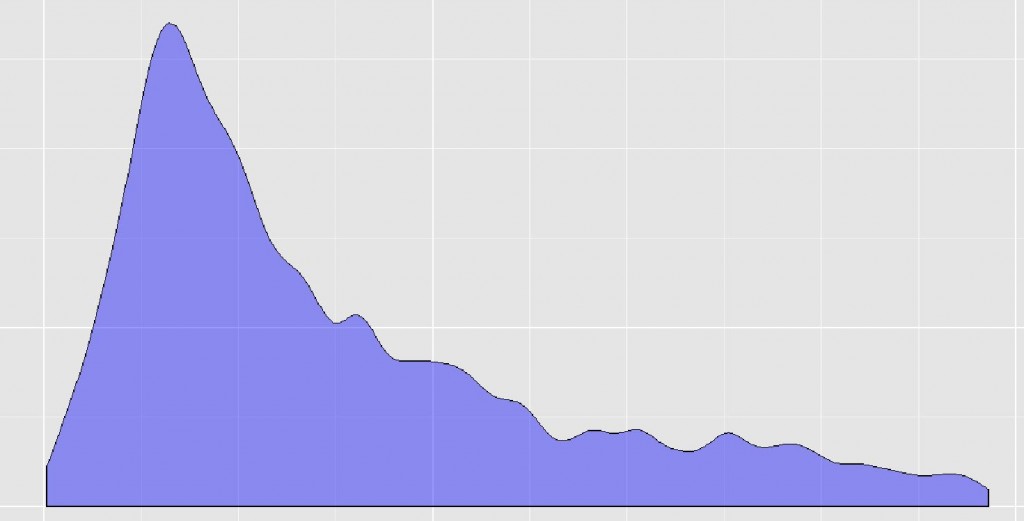
Si hacemos este proceso iterativamente -sacando el 1% mas grande, y a ese resultado se le vuelve a sacar el 1%, y asi sucesivamente por un total de 10 veces- estaremos analizando distintos valores del punto de corte. Sucede algo curioso con el resultado, la silutea se mantiene siempre parecida a:
Animando el ejemplo
La siguente animación muestra en acción el proceso iterativo de eliminación: como a medida que se va dejando afuera el 1% mas grande, la silueta mantiene un aspecto similar:
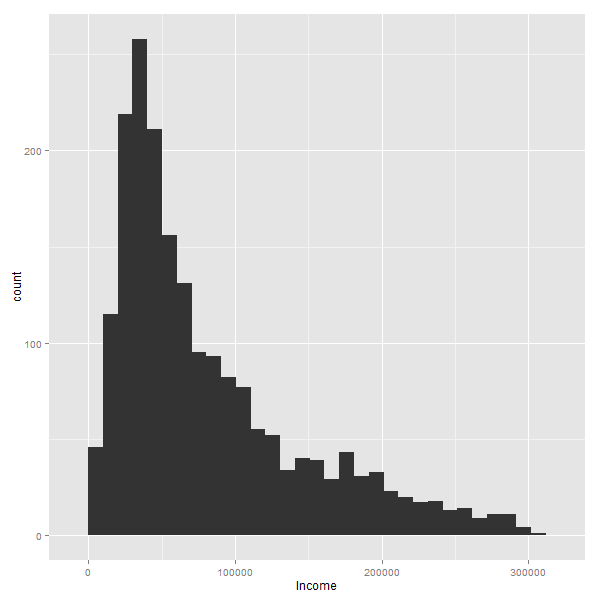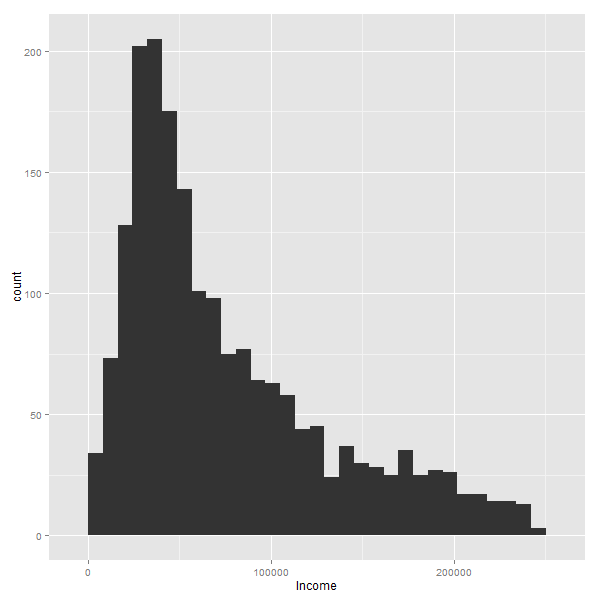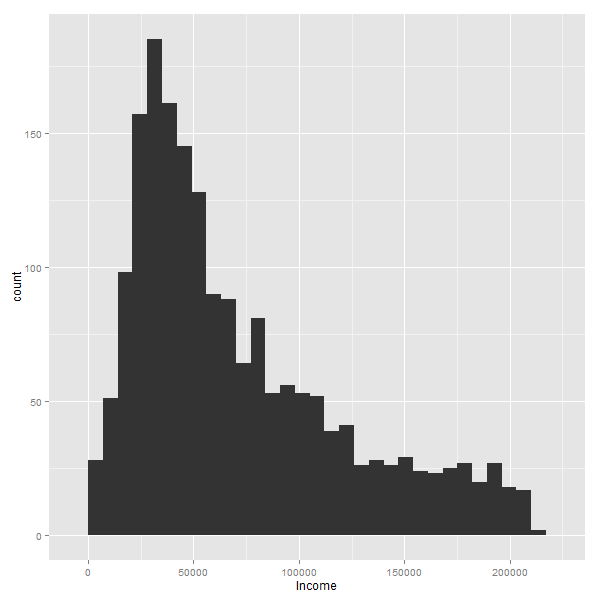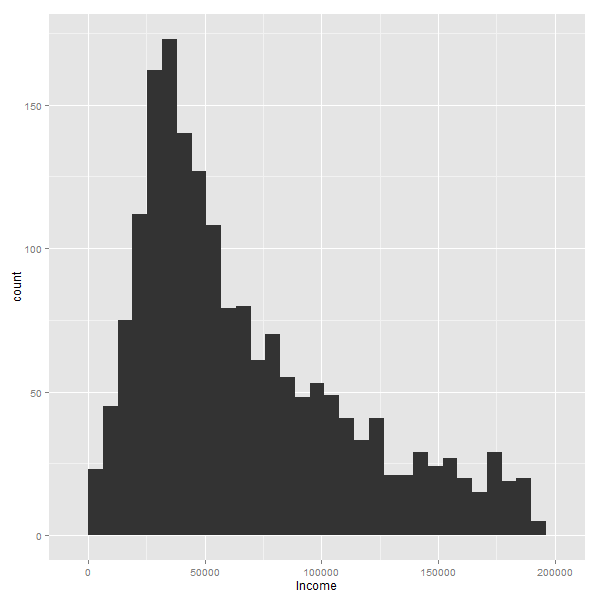
Es decir, siempre habran muchas personas con ingresos bajos/medios, y pocos con ingresos altos. Lo que naturalmente cambian, son los valores de los ejes.
Si cambiamos el gráfico histograma por uno de densidad, el efecto que aparece es mas parecido a un zoom hacia la parte izquierda de los datos:
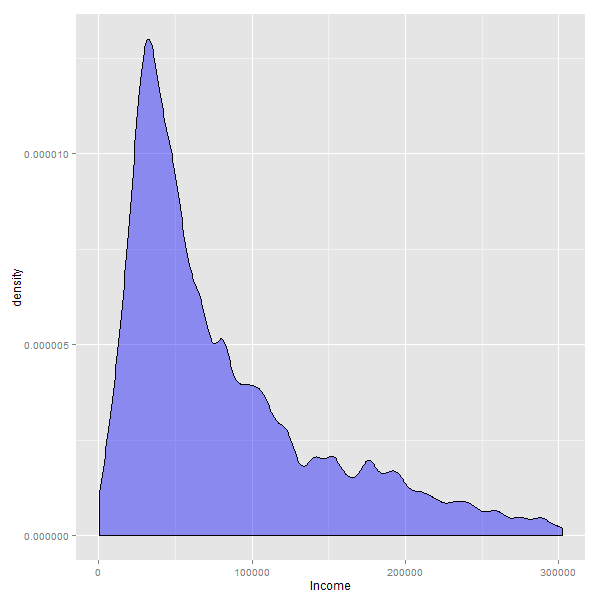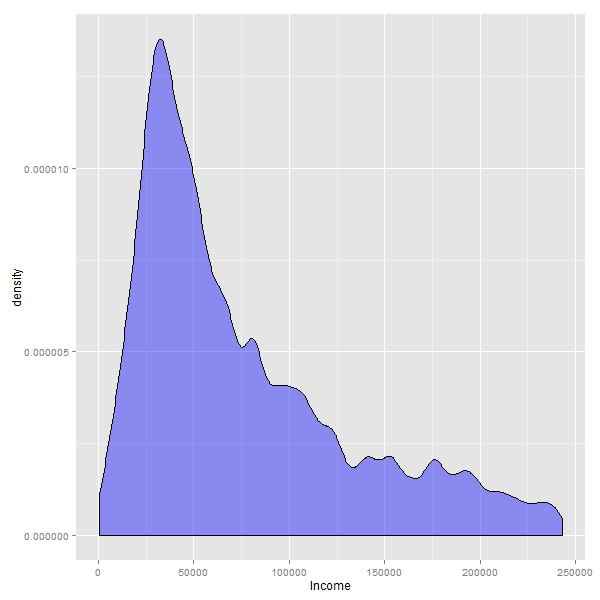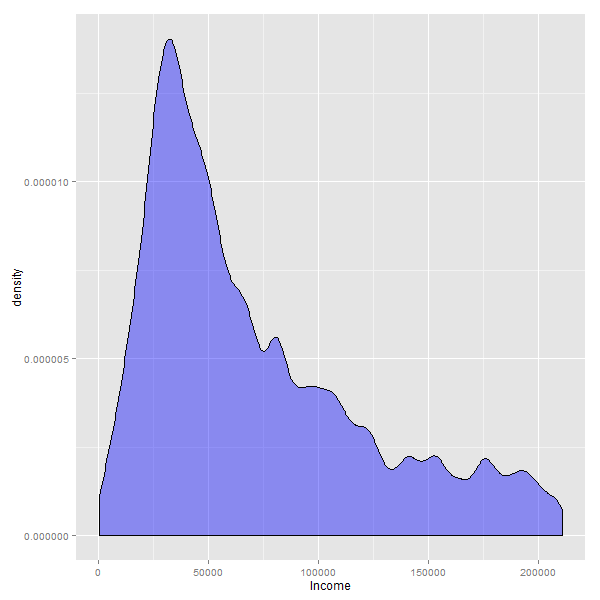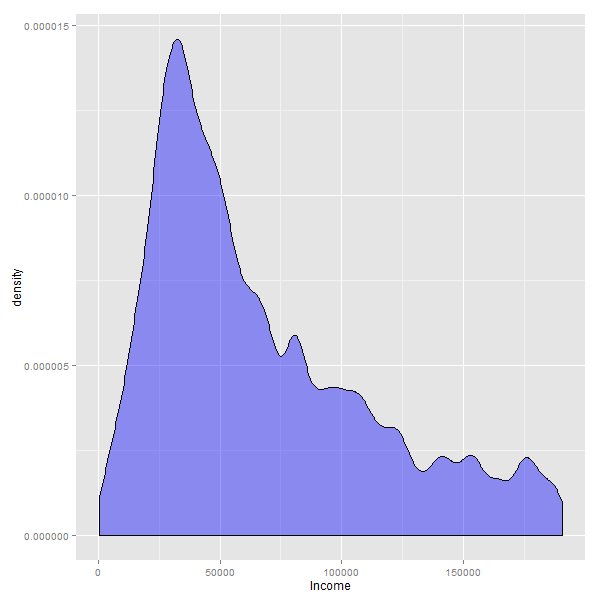
Cuando se eliminan los valores mas bajos, o mas altos de una variable, lo que se consigue es hacer un acercamiento -ó “zoom”- hacia donde se encuentra la mayor cantidad de casos.
Reflexión final
En este caso en particular se podría dejar afuera el 0.5 o 1% de los datos. Aunque no siempre es recomendable eliminar outliers, a veces pueden representar fraudes, un desperfecto en una máquina, u otro evento que merece una inspección mayor.
Contacto
Hecho por Pablo C. de Data Science Heroes.
Código en R y datos disponible en github
Temas de outliers y tratamiento de datos se ven en el curso e-learning: Data Science with R (Demo gratuita disponible)
-
¿Preguntas acerca data science? Escribirlas en nuestro grupo de Linkedin

Muy buena referencia, sería
Subido por JUAN ANDRADE ARMAS (no verificado) el 17 Octubre, 2016 - 16:09
Muy buena referencia, sería bueno complementarlo con un ejemplo para entender de mejor manera.