Artículos de Integración de Datos de Dataprix
Artículos de Integración de Datos de Dataprix Dataprix 26 Diciembre, 2009 - 17:11Arquitectura del Data Warehouse: áreas de datos de nuestro Almacén Corporativo
Arquitectura del Data Warehouse: áreas de datos de nuestro Almacén Corporativo Carlos 22 Julio, 2009 - 14:16Cuando diseñamos la arquitectura de un sistema de Data Warehouse nos hemos de plantear los diferentes entornos por los que han de pasar los datos en su camino hacia su Data mart o cubo de destino. Dada la cantidad de transformaciones que se han de realizar, y que normalmente el DWH, además de cumplir su función de soporte a los requerimientos analíticos, realiza una función de integración de datos que van a conformar el Almacén Corporativo y que van a tener que ser consultados también de la manera tradicional por los sistemas operacionales, es muy recomendable crear diferentes áreas de datos en el camino entre los sistemas origen y las herramientas OLAP.
Cada una de estas áreas se distinguirá por las funciones que realiza, de qué manera se organizan los datos en la misma, y a qué tipo de necesidad puede dar servicio. El área que se encuentra 'al final del camino' es importante, pero no va a ser la única que almacene los datos que van a explotar las herramientas de reporting.
Tampoco hay una convención estandar sobre lo que abarca exactamente cada área, y la obligatoriedad de utilizar cada una de ellas. Cada proyecto es un mundo, e influyen muchos factores como la complejidad, el volumen de información del mismo, si realmente se quiere utilizar el Data Warehouse como almacén corporativo o Sistema Maestro de Datos, o si existen necesidades reales de soporte al reporting operacional.
Visto esto, comentaré a continuación las áreas de datos que se suelen utilizar, e iré perfilando una propuesta de arquitectura que cada uno ha de adaptar a sus necesidades o simplemente a su gusto en función de su experiencia.
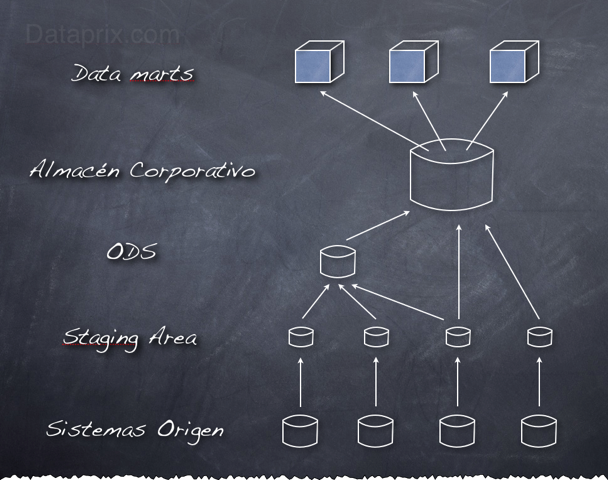
Staging Area
Es un área temporal donde se recogen los datos que se necesitan de los sistemas origen. Se recogen los datos estrictamente necesarios para las cargas, y se aplica el mínimo de transformaciones a los mismos. No se aplican restricciones de integridad ni se utilizan claves, los datos se tratan como si las tablas fueran ficheros planos. De esta manera se minimiza la afectación a los sistemas origen, la carga es lo más rápida posible para minimizar la ventana horaria necesaria, y se reduce también al mínimo la posibilidad de error. Una vez que los datos están traspasados, el DWH se independiza de los sistemas origen hasta la siguiente carga. Lo único que se suele añadir es algún campo que almacene la fecha de la carga.
Obviamente estos datos no van a dar servicio a ninguna aplicación de reporting, son datos temporales que una vez hayan cumplido su función serán eliminados, de hecho en el esquema lógico de la arquitectura muchas veces no aparece, ya que su función es meramente operativa.
Hay quien considera que la Staging Area abarca más de lo que he comentado, o incluso que este area engloba todo el entorno donde se realizan los procesos de ETL, yo me decanto por su utilización sólo como área temporal.
ODS (Operational Data Store)
Como su nombre indica, este area es la que va a dar soporte a los sistemas operacionales. El modelo de datos del Almacén de Datos Operacional sigue una estructura relacional y normalizada, para que cualquier herramienta de reporting o sistema operacional pueda consultar sus datos. Está dentro del Data Warehouse porque se aprovecha el esfuerzo de integración que supone la creación del Almacén de Datos Corporativo para poder atender también a necesidades operacionales, pero no es obligatorio, y ni siquiera es algo específico del Business Intelligence, los ODS ya existían antes de que empezáramos a hablar de BI y de DWH.
No almacena datos históricos, muestra la imagen del momento actual, aunque eso no significa que no se puedan registrar los cambios.
Los datos del ODS se recogen de la Stage Area, y aquí sí que se realizan transformaciones, limpieza de datos y controles de integridad referencial para que los datos estén perfectamente integrados en el modelo relacional normalizado.
Hay que tener en cuenta que la actualización de los datos del ODS no va a ser instantánea, los cambios en los datos de los sistemas origen no se verán reflejados hasta que finalice la carga correspondiente. Es decir, que se irán actualizando los datos cada cierto tiempo, cosa que hay que explicar a los usuarios, porque los informes que se lancen contra el ODS casi nunca podrán estar tan 'al minuto' como los que existan en el sistema origen. Lo que sí se puede hacer es definir una mayor frecuencia de carga para el ODS que para el Almacén Corporativo. Si es necesario, se puede refrescar el ODS cada 15 minutos, y el resto cada día, por ejemplo.
Almacén de Datos Corporativo
El Almacén de Datos Corporativo sí que contiene datos históricos, y está orientado a la explotación analítica de la información que recoge. Las herramientas DSS o de reporting analítico atacarán principalmente a los Data marts, pero también se pueden realizar consultas directamente contra el Almacén de Datos Corporativo, sobretodo cuando sea necesario mostrar a la vez información que se encuentre en diferentes Datamarts.
En él se almacenan datos que pueden provenir tanto de la Staging Area como del ODS. Si ya hemos realizado procesos de transformación e integración en el ODS no los vamos a repetir para pasar los mismos datos al Almacén Corporativo. Lo que no se pueda recoger desde el ODS sí que habrá que ir a buscarlo a la Staging Area.
El esquema se parece al de un modelo relacional normalizado, pero en él ya se aplican técnicas de desnormalización. No debería contener un número excesivo de tablas ni de relaciones ya que, por ejemplo, muchas relaciones jerárquicas que en un modelo normalizado se implementarían con tablas separadas aquí ya deberían crearse en una misma tabla, que después representará una dimensión. Otra particularidad es que la mayoría de las tablas han de incorporar campos de fecha para controlar la fecha de carga, la fecha en que se produce un hecho, o el periodo de validez del registro.
Si el Data Warehouse no es demasiado grande, o el nivel de exigencia no es muy elevado en cuanto a los requerimientos 'operacionales', para simplificar la estructura se puede optar por prescindir del ODS, y si es necesario adecuar el Almacén de Datos Corporativo para servir a los dos tipos de reporting. En este caso, el área resultante sería el DWH Corporativo, pero a veces también se le llama ODS.
Data marts
Y por fin llegamos a la última área de datos, que es el lugar donde se crean los Data marts. Éstos se obtienen a partir de la información recopilada en el área del Almacén Corporativo. Cada Data Mart es como un subconjunto de este almacén, pero orientado a un tema de análisis, normalmente asociado a un departamento de la empresa.
Los Data marts se diseñan con estructura multidimensional, cada objeto de análisis es una tabla de hechos enlazada con diversas tablas de dimensiones. Si se diseñan siguiendo el Modelo en Estrella habrá prácticamente una tabla para cada dimensión, es la versión más desnormalizada. Si se sigue un modelo de Copo de Nieve las tablas de dimensiones estarán menos desnormalizadas y para cada dimensión se podrán utilizar varias tablas enlazadas jerárquicamente.
Este área puede residir en la misma base de datos que las demás si la herramienta de explotación es de tipo ROLAP, o también puede crearse ya fuera de la BD, en la estructura de datos propia que generan las aplicaciones de tipo MOLAP, más conocida como los cubos multidimensionales.
El paso del anterior área de datos a esta ha de ser bastante simple, cosa que además proporciona una cierta independencia sobre el software que se utiliza para el reporting analítico. Si por cualquier razón es necesario cambiar la herramienta de OLAP habría que hacer poco más que redefinir los metadatos y regenerar los cubos, y si el cambio es entre dos de tipo ROLAP ni siquiera esto último sería necesario. En cualquier caso, las áreas anteriores no tienen porqué modificarse.
Data profiling con SQL Server 2008
Data profiling con SQL Server 2008 Carlos 17 Agosto, 2009 - 19:47Una de las múltiples mejoras que aporta SQL Server 2008 en la parte de ETL con Integration Services es su capacidad para realizar perfilado de datos con su nueva Data Profile Task.
El data profiling es una de las primeras tareas que se suelen abordar en procesos Calidad de Datos, y consiste en realizar un primer análisis sobre los datos de origen, normalmente sobre tablas, con el objetivo de empezar a conocer su estructura, formato y nivel de calidad. Se hacen consultas a nivel de tabla, columna, relaciones entre columnas, e incluso relaciones entre tablas.
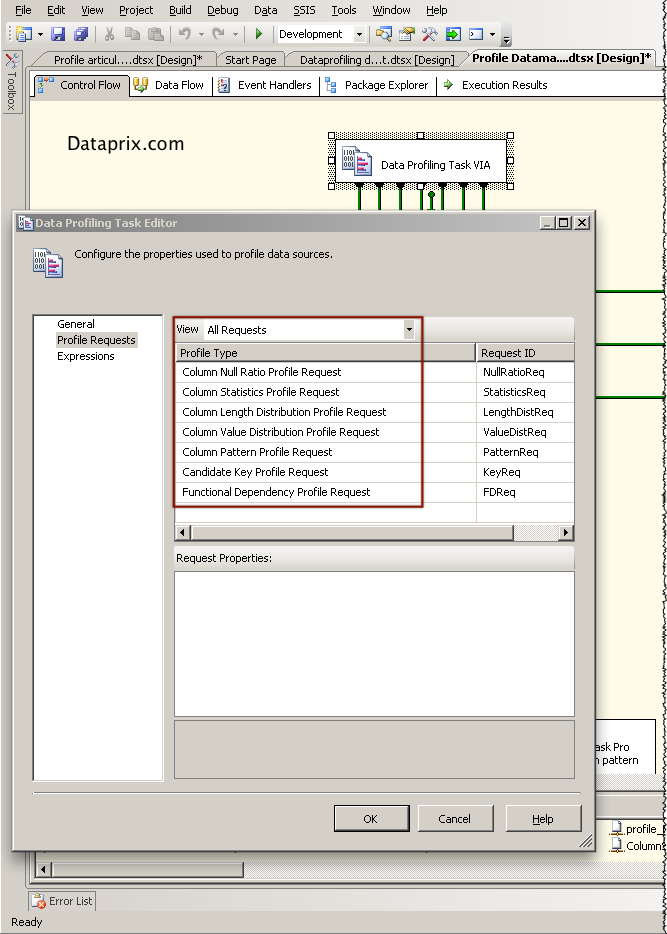
La Data Profile Task de SSIS funciona seleccionando una tabla de una base de datos SQLServer 2000 o superior (no sirven otras bases de datos), las opciones de perfilado que se quiera realizar sobre los datos de la tabla, y un fichero XML donde se almacenarán los resultados cuando se ejecute la misma. Es realmente sencillo.
Se pueden seleccionar hasta 8 tipos de perfilado, 5 a nivel de columna y 3 a nivel de varias columnas.
Perfilados a nivel de columna:
- Distribución de la longitud de los valores
- Porcentaje de valores nulos
- Patrones, expresados mediante expresiones regulares
- Estadísticas de columna: mínimo, máximo, media o desviación standard
- Distribución de los valores, valores diferentes y porcentaje de aparición de cada uno sobre el total de filas
Perfilados a nivel multicolumna:
- Claves candidatas, qué columnas podrían ser clave primaria de la tabla
- Dependencia funcional, los valores de una columna pueden depender de los de otra
- Inclusión de valores, que columnas podrían ser claves foráneas de otras
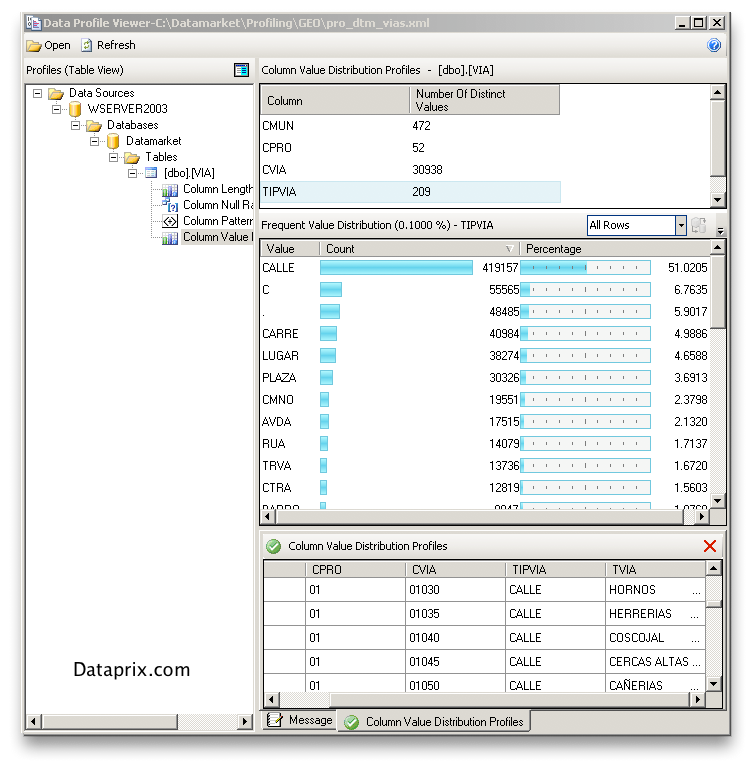
Tras ejecutar la tarea se genera un fichero XML en la ubicación elegida donde se almacena toda la información resultado del análisis. Para poder examinar estos resultados SQL Server proporciona la aplicación Data Profile Viewer que en una instalación normal sobre la unidad C debería encontrarse en este directorio:
C:\Archivos de programa\Microsoft SQL Server\100\DTS\Binn\DataProfileViewer.exe
Sólo hay que seleccionar el XML generado por la tarea de SSIS y comenzar a explorar los resultados:
Para obtener información más detallada se puede consultar el apartado Tarea de generación de perfiles de datos de la documentación en linea de Microsoft Technet.
También está muy bien comentada esta tarea en los artículos de SQLServer Performance SSIS New Features in SQL Server 2008 - Part 3 y Using The Data Profiler Task and FTP Task in SQL Server 2008 Integration Services
Data profiles de SQL Server IS almacenados en tablas
Data profiles de SQL Server IS almacenados en tablas Carlos 19 Agosto, 2009 - 14:24La tarea de Data Profile de SQL Server Information Services almacena los resultados del perfilado en un documento XML que se puede examinar con el Data Profile Viewer. En el artículo Dataprofiling con SQL Server 2008 explico cómo se utiliza esta nueva Task de SSIS.
Aunque este método sea muy sencillo, a veces puede no resultar suficiente. Si se aborda un proyecto de calidad de datos puede interesar, por ejemplo, almacenar un histórico de los perfilados para poder evaluar cómo ha ido mejorando la calidad de los datos tratados.
La mejor manera de trabajar con datos históricos es utilizando una base de datos y almacenando estos datos en tablas, sobre las que se podrán hacer las consultas, informes y comparativas que haga falta. Para conseguirlo lo único que haría falta es pasar a tablas los metadatos que la tarea de perfilado ha almacenado en el fichero XML.
Pues alguien ya se ha dedicado a buscar una manera sencilla de hacerlo. Thomas Frisendal, desde su web Information quality solutions explica cómo ha creado un archivo XSLT para cada tipo de perfilado que sirve para extraer del XML que genera la Data Profile Task de SSIS uno o más ficheros XML en un formato que puede ser directamente importado a tablas.
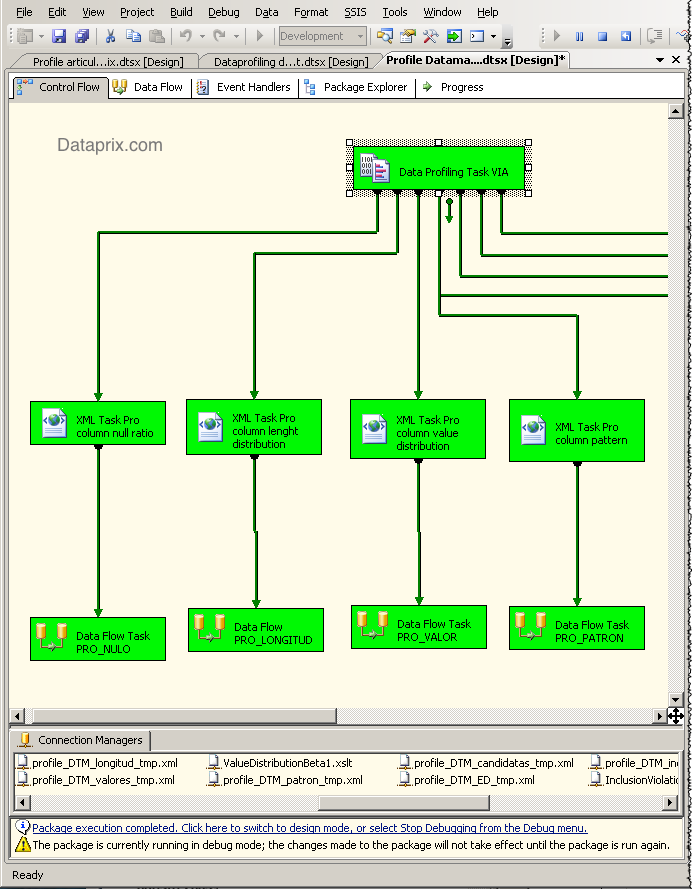
Así, con sólo crear un proceso que aplique un XSLT por cada tipo de perfilado, y después cargue cada fichero XML resultante en una tabla ya se pueden almacenar los datos de perfilado en tablas. Como además en todos los ficheros se incluye un campo que informa del nombre de la tabla origen, con una sola tabla para cada tipo de perfilado ya se pueden almacenar los profiles de todas las tablas que se traten.
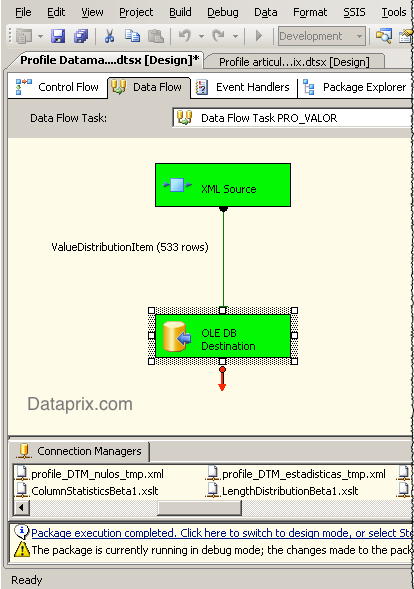
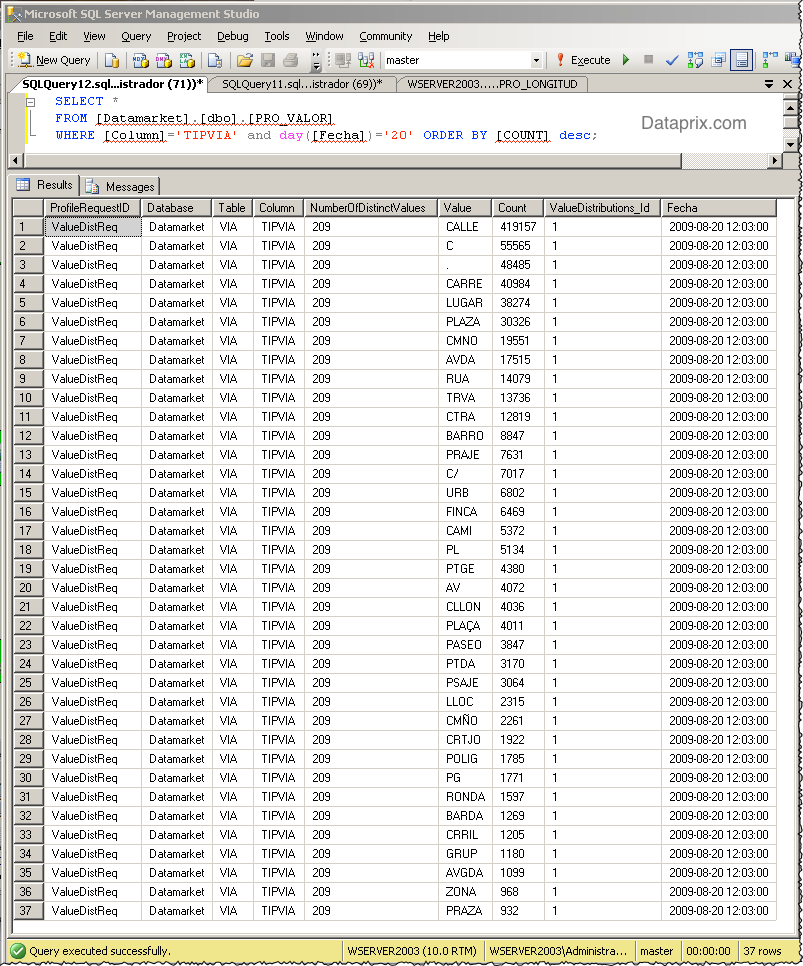
Yo he añadido además a la tabla un campo de fecha que almacena la fecha en que se realiza el proceso, y de momento el resultado ha sido bueno.
En el gráfico podemos ver la distribución de tipos de vía diferentes para el callejero español según datos del INE y darnos cuenta, por ejemplo, de que los identificadores no están demasiado bien tipificados, ya que podemos encontrar cosas como más de un identificador para el mismo tipo de vía (CALLE, C, C/), o bastantes vías con un punto como identificador.
En Free tool for automation of SQL Server el autor comenta cómo funciona esta solución y cómo obtener las hojas de estilo, y en Usage recommandations for the ProfileToSQL stylesheets explica más en detalle cómo utilizar los XSLT, e incluye un disclaimer dejando claro que este software es una versión de test.
En qué consiste el data cleansing
En qué consiste el data cleansing Carlos 18 Julio, 2006 - 15:33En el artículo del archivo adjunto los autores realizan una exposición bastante completa sobre en qué consiste el data cleansing, o limpieza de datos, las principales maneras en que se suele abordar, e incluso qué técnicas utilizan las principales compañías comerciales que ofrecen este servicio. (Bueno, las que lo ofrecían el año 2000, pero las técnicas principales no han variado mucho desde entonces).
Herramientas de ETL
Herramientas de ETL Carlos 25 Abril, 2007 - 23:36Las herramientas de ETL sirven para facilitar los procesos de Extracción, Transformación y Carga de cualquier sistema, y son especialmente útiles para el Data Warehousing, cuando se construyen sistemas de Data Warehouse en proyectos de Business Intelligence.
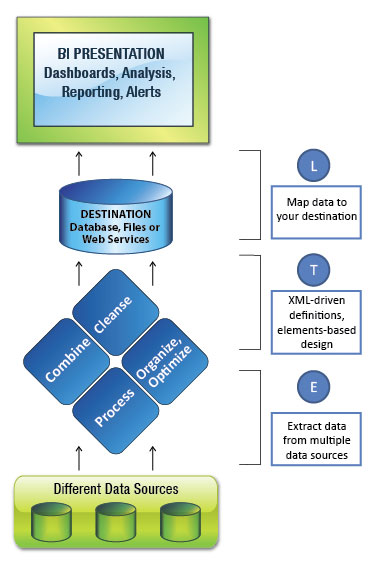
Esquema Tipico de Herramienta ETL
Los grandes fabricantes suelen disponer de una herramienta ETL principal, para procesos de integración que se ejecutan cada cierto tiempo, que es la manera en que se han ido alimentando tradicionalmente los sistemas de Data Warehouse, y una herramienta que permite gestionar procesos de integración en tiempo real, que es la última tendencia en software de ETL, y también suelen ser herramientas de ETL de nueva creación, software relativamente nuevo, que en muchas ocasiones era de fabricantes independientes y que ha sido adquirido por los grandes fabricantes de SW empresarial para completar su portfolio con estas soluciones de ETL en Real Time, que normalmente llevan también asociadas capacidades de CDC, o Change Data Capture.
Listo a continuación las principales herramientas de ETL (Extraction, Transformation and Load) que ofrecen diversos fabricantes de software ETL para la empresa. Puede faltar alguna, o puede pasar que con el tiempo el software ETL de un proveedor 'cambie de manos', e incluso de nombre. Intentaremos ir completando y actualizando la lista con estos cambios, y agradecemos que nos aviséis de cualquier novedad para poder mantener actualizada nuestra lista de principales herramientas ETL para la empresa:
- IBM InfoSphere DataStage
SW ETL de IBM para plataformas distribuidas y mainframes - IBM Cognos DecisionStream
Software ETL de IBM para la construcción de Data Warehouses y Data Marts para reporting y análisis - IBM InfoSphere Change Data Capture (CDC)
Software de IBM para la integración de información en tiempo real a través de almacenes de datos heterogeneos.
- Informatica Powercenter
Software de Integracion de datos empresariales de Informatica
- Oracle Data Integrator (ODI)
Plataforma de integración de datos de Oracle Fusion Middleware - Oracle GoldenGate (CDC)
Sofware de integración de datos de Oracle Fusion Middleware, que permite la replicación de datos en tiempo real en entornos de datos heterogéneos
- SAP BusinessObjects Data Integrator
Software ETL de SAP BO, plataforma de Business Intelligence de SAP - SAS Enterprise Data Integration Server
Software de ETL y ELT de SAS, que permite transformar datos directamente en las bases de datos origen
- Microsoft SQL Server Integration Services (SSIS)
Software ETL de Microsoft, incluído en la base de datos SQL Server, y que reemplaza a Data Transformation Services (DTS)
- iWay DataMigrator
Herramienta ETL de iWay Software para Data Warehousing. - iWay Enterprise Information (EII)
Herramienta ETL de iWay Software para integración en tiempo real entre almacenes de datos heterogéneos.
- Pentaho Data Integration (PDI)
Software ETL Open Source de la suite de BI de Pentaho. La versión Community (PDI CE) es tembién conocida como Kettle, que es el nombre del proyecto open source original.
- Talend Open Studio for Data Integration
Software ETL Open Source para integración de datos de Talend.
Informatica World 2008 en Las Vegas
Informatica World 2008 en Las Vegas Carlos 11 Junio, 2008 - 00:20Finalmente he podido asistir al Informatica World 2008 y qué menos que explicar un poco lo que me encontré por allí. La conferencia se celebró del 3 al 5 de junio bajo el lema 'Gain the Edge', una expresión con mucha fuerza en inglés pero difícil de traducir al castellano, a ver si alguien se anima y nos da una traducción válida.

El día 3 comenzó, después del desayuno, con una sesión general que llevaba por título Vision. Strategy. Technology Announcements. Industry leadership. En la misma, tanto Sohaib Abbasi, CEO y Presidente de Informática, como Chris Boorman, Ivan Chong y Girish Pancha, Vicepresidentes en las àreas de Márqueting, Calidad de Datos e Integración de Datos, respectivamente, nos mostraron su visión actual del mercado, cómo están evolucionando la tecnología y los negocios, y qué papel juegan en este marco los datos y las aplicaciones que los gestionan.
Mucho de lo que comentaron ya había podido escucharlo en las presentaciones del Powerday 2008 de Barcelona, cosa que muestra que la compañia mantiene una estrategia bien definida, y la comparte con sus partners.
Se hizo especial hincapié, cada ponente bajo la perspectiva de su àrea, del valor que representan los datos, y lo importante que es la habilidad de cada organización para gestionarlos, mantener su coherencia y calidad, garantizar su accesibilidad en el momento oportuno, protegerlos, sincronizarlos y poder intercambiarlos con otras organizaciones.
Nos hicieron notar que ahora ya no sólo se trata de crear un almacén de datos corporativo que nos porporcione información actualizada cada cierto intervalo de tiempo. La evolución tecnológica y de Internet, la globalización y la competencia nos hacen plantearnos que con el Data Warehouse no es suficiente. Se oyeron mucho los términos SaaS, Real Time y Data Quality, cosa que nos da pistas sobre hacia donde van encaminadas las nuevas funcionalidades de las herramientas de la compañia.
También realizaron una interesante demo sobre cómo una aplicación como Salesforce.com puede sincronizarse en tiempo real, y a través de Internet, con una hoja de cálculo de Google Docs. Este ejemplo de cloud to cloud computing lo prepararon mostrando en la pantalla de la izquierda Salesforce.com y en la de la derecha una spreadsheet de Google Docs, cada aplicación 'controlada' desde un portatil. En el portatil de Salesforce realizaron un cambio, y pudimos ver cómo se actualizaba al momento la hoja de cálculo. Después hicieron otra modificación en la hoja de cálculo, y la aplicación de Salesforce también se actualizó, todo a través de Internet. Para poner la guindilla después hicieron lo mismo, pero con un iPod touch, no hay que olvidar las posibilidades que nos brindan los nuevos dispositivos móviles cuando se conectan a la web.
También pudimos asistir a una animada presentación de Royce Bell, CEO de Accenture Information Management Services, que supo cómo mantener la atención de todo el mundo.

La sesión general de este Informatica World 2008 daba paso a las Breakout Sessions, cada una de ellas clasificada en una de las siguientes categorías:
- Productos y Tecnología
- Arquitectura
- Gestión de Datos Empresarial
- Soluciones
- Presentación Técnica
- Impacto sobre el negocio
Además se catalogaban según nivel de experiencia y rol del público al que iban dirigidas.
Los niveles eran Beginner, Intermediate y Advanced, y los roles Architect, Business and IT Influencer y Practitioner.
Así cada uno podía seleccionar las sesiones que más le interesaran y mejor se adaptaran a su perfil profesional.

En total había 56 sesiones, de las cuales había que elegir como mucho 8. Como son tantas, listaré a continuación sólo el título de cada una, dentro de cada categoría, todo en el idioma original, y subrayo las que yo seleccioné:
Products and Technology
- What’s New in PowerCenter
- Data Quality with Identity Resolution: A Leap Forward for Data Quality in the Enterprise
- How to Get More from Informatica Metadata Manager
- The Informatica Roadmap: Vision for V9
- Informatica B2B Data Exchange: Building a Data Exchange
- What’s New in Informatica Data Explorer and Informatica Data Quality 8.6
- Protecting Private Data Using PowerCenter Data Masking
- Real-Time Data Integration
Architecture
- Customer Panel: Real-Time Integration Architectures for Right-Time Business Value
- Informatica Architecture: Where to Start?
- A Practical Approach to Building Data Services with PowerCenter 8.5
- Informatica Orchestration and Human Workflow: Process-Enabled Data Integration and Data
- Maximizing Operational Uptime: Real-Time Data Integration with Informatica
- On Demand Data Integration: Overview and Demonstration
- Deploying PowerCenter on Grid Computing Architectures
- PowerCenter Data Federation Option: A Unified Platform for Data Integration Flexibility
Enterprise Data Management
- Data Quality, The First Step on the Path to Master Data Management
- Where Real-Time Data Integration Meets Real-Time Data Warehousing
- IMS Health: Global Data Integration for Financial Information Management
- Customer Master Data Management at Major Telecommunications Company KPN, Netherlands
- Measuring and Improving Data Governance Maturity: A Practical Approach
- Information Management: An Implementer’s Perspective
- Measuring Data Quality in Philips Consumer Lifestyle
- Lowering Cost and Risk with the Data Migration Factory
- Data Profiling and Data Quality Improvement: A Practitioner's Approach
- Velocity Methodology: Best Practices
Solutions
- Campaign Marketing and Customer Relationship Management at Daimler AG
- A Trip to Better and Faster Corporation Travel Management: A B2B Data Transformation Success
- Informatica B2B Data Transformation: Success with LOGTEC for the Defense Logistics Agency
- Assuring Success When Integrating Salesforce CRM with the Rest of Your Business: A Partner Profile with Case Studies from Ellie Mae and Millennium Pharma
- Data Migration Success at G&K Services
- Leveraging HP and Informatica for Large-Scale Data Migration Efforts: A Case Study at CVS Caremark
- Strategy to Implementation: How to Get Started on your Data Quality Initiative
- Identity Resolution: What It Is and Why It Is Important
Tech Talk
- Extreme Automation: Traceability of Requirements through Testing, Governance and Compliance
- Planning and Tuning Informatica for Large Loads
- Tips to Improve Productivity Using Self-Service Support Tools
- Command and Control: Using Informatica Workflows to Regulate Complex Business Processes
- Informatica Developer: Tips and Tricks for Architecture and Development
- Upgrading to the Latest PowerCenter Release: Tips and Tricks, Testing and Pitfalls to Avoid
- Using Team-Based Development: A Practical Exposé
- High-Volume Data Processing (>150GB) Using Informatica
- Informatica Developer Tips for Troubleshooting Common Issues
- Power of Informatica PowerCenter at Verizon Wireless
Business Impact
- Driving Business Value with Integration Competency Centers: Customer Presentations, a Two-Part Series (Part 1 of 2)
- Integration Competency Centers: Panel Discussion, a Two-Part Series (Part 2 of 2)
- Anti-Money Laundering Compliance: Stopping Financial Crime - a Data Quality Approach
- Quantifying Business Value with Informatica: Best Practices and Techniques for Funding Enterprise Data Integration and Data Quality Projects
- Informatica B2B Data Exchange: Success with Paramount Pictures
- Integration Competency Center at Duke Energy
- Building a Business Case for B2B Data Exchange at a Major HMO
- Data Governance in a Global Enterprise
- Enterprise Data Warehouse at a Medical Device Manufacturing Company
- Informatica B2B Data Transformation: Success with GfK Group
Como se puede apreciar, la categoría que más me interesó fue la de Gestión de Datos en la Empresa, seguida de la de Soluciones. De todas maneras debo aclarar que actualmente no utilizo productos de Informática, por lo que las categorías relacionadas con desarrollo o temas específicos del software no me resultaban tan atractivas.
Encontré la mayoría de las sesiones muy enriquecedoras, nadie mejor que los expertos de Informática para asentar conceptos sobre las últimas tendencias en gestión y calidad de datos, en Data Warehousing, o para recomendarte best practices, o pasos a seguir para abordar un proyecto de este tipo.
De todas maneras siempre lo mejor es la presentación de alguien que ha vivido en su empresa una implantación o una experiencia, y que la cuenta bajo una perspectiva más imparcial. En este sentido creo que la mejor sesión a la que asistí fue la Customer Data Management en KPN, presentada por Thomas Reichel (KPN) y Chris Phillips (Informatica)
Tras estos días de Breakout Sessions llegó el jueves 5 en que se celebró la sesión general que marcaba el final del evento. El título de la misma era Gaining the Edge. In Real Time

Después de haber mostrado en la sesión inicial la necesidad de las organizaciones de gestionar sus datos con la mayor eficiencia, y adaptándose al progreso tecnológico, esta sesión se enfocó más a cómo conseguirlo con la ayuda del software y el soporte de Informática, se mostraron las nuevas funcionalidades que ofrece la versión 9 del producto, y cómo aprovecharlas.
Me gustó la demo que realizó Ivan Chong sobre cómo gestionar y realizar procesos de Data Quality con esta nueva versión, pero lo que más me impresionó fue la presentación que hizo Ron Swift, vicepresidente de Teradata, sobre la importancia de gestionar datos en tiempo real para poder reaccionar a tiempo ante determinadas situaciones. Puso el acertado ejemplo de un casino que había implementado un sistema que analizaba en tiempo real el comportamiento de sus clientes mientras jugaban y que, si detectaba que alguno estaba perdiendo demasiado dinero, para no acabar perdiéndolo hacía saltar una alarma que avisaba para que el personal pudiera persuadirlo de seguir jugando.
Para finalizar sólo agradecer a Powerdata la invitación para poder asistir a esta edición del Informatica World, y el amable trato que me han brindado durante todo el viaje.
Integracion y calidad de datos en el PowerDay 2008
Integracion y calidad de datos en el PowerDay 2008 Carlos 26 May, 2008 - 02:16En marzo-abril se celebró la séptima edición de Powerday, un evento anual que organiza PowerData, y que este año tenía por objetivo proporcionar a los asistentes una visión global de la estrategia adecuada para sacar el máximo partido a los datos. Yo tuve la oportunidad de asistir al de Barcelona, y disfrutar con las interesantes ponencias que se realizaron en el mismo.
Fueron presentaciones de una media hora, en las que se habló sobre la importancia de la calidad de datos y los procesos de integración, sobre la situación tecnológica y de mercado actual y, por supuesto, sobre cómo facilitar las cosas con la utilización de herramientas de Informática como PowerCenter.
Estos son los títulos de las presentaciones:
- El valor de los datos correctos trasciende el departamento TI
- Principios prácticos para garantizar una buena calidad de los datos dentro de la organización
- Enmascaramiento de datos: una respuesta efectiva a demandas de confidencialidad
- Integración de datos corporativos en Caprabo
- Importancia de contar con buenos datos en entornos analíticos
- El modelo de organización en tiempo real impone nuevas exigencias en la gestión de la información
- Tendencias del mercado español de gestión de datos
Encontré especialmente interesante la de Caprabo, realizada por Sergio Champel, el Jefe del Area de Arquitectura e Integración de esta empresa. Sergio explicó cómo se habían organizado tanto a nivel de gestión como de arquitectura para llevar a cabo con éxito un ambicioso proyecto de integración y remodelación del sistema de Business Intelligence de Caprabo, con el que han conseguido mejorar importantes procesos de negocio, y 'estrechar los lazos' entre los sistemas operacionales y el Data Warehouse.
Me llamó mucho la atención la frase Aprendemos a utilizar un martillo y todo nos parece un clavo, que Sergio mencionó para dejar claro lo que querían evitar cuando definieron la arquitectura. Me pareció un frase muy acertada, y aplicable a múltiples situaciones.
Destacar también que la presentación Importancia de contar con buenos datos en entornos analíticos la realizó Jorge Zaera, director general de Microstrategy.
Las demás fueron presentadas por expertos y directivos de Powerdata, que supieron mostrar los diferentes aspectos a tener en cuenta en todo lo relacionado con la integración y calidad de los datos, y qué papel juegan estas materias en las últimas tendencias tecnológicas del mercado, cada vez más orientadas al proceso y al servicio, como SaaS (Software as a Service), SOA (Service Oriented Architecture), BPM (Business Process Management), CPM (Corporate Process Management) o EIM (Enterprise Information Management)
Para el que prefiera hablar de cosas más tangibles, también se proporcionó una clasificación de tipos de proyectos que nos podemos encontrar en cuanto a la gestión de los datos:
- Data warehouse
- Migración de datos
- Consolidación de datos
- Master Data Management
- Sincronización de datos
- Intercambio de datos B2B
Tras las presentaciones se realizó un sorteo de un viaje a Las Vegas para asistir a Informatica World 2008. Resulta que el afortunado ganador del sorteo fui yo, por lo que en unas semanas espero estar publicando un nuevo artículo sobre mis experiencias en este evento al otro lado del charco.
Buena documentacion, pero en
Subido por David el 8 Agosto, 2006 - 20:52
Buena documentacion, pero en ingles.
Parece ser que no hay mucha literatura sobres este tema, que considero de vital importancia para las grandes empresas, viendo el volumen de datos que manejan.
Estoy en un proyecto de cuadre de datos entre sistemas en el que la depuracion, limpieza y correccion de datos es fundamental.
Seguire atento a esta web, me parece muy interesante.
Un saludo,
David