Administración, tips, SQL y utilidades sobre bases de datos SQL Server
Administración, tips, SQL y utilidades sobre bases de datos SQL Server Dataprix 15 April, 2022 - 12:16
Recopilación de dudas técnicas, db scripts y consultas de administración y desarrollo sobre bases de datos Microsoft SQL Server
Cómo crear un identificador secuencial en una tabla de SQL Server
Cómo crear un identificador secuencial en una tabla de SQL Server Carlos 3 April, 2020 - 18:57 Para crear un identificador único de secuencia en una tabla de SQL Server lo más sencillo es definir un campo de tipo Identity, y que se vaya generando sólo, pero si no se puede utilizar esta solución, o no es apropiada para un caso concreto, una solución muy sencilla para informar de manera puntual un campo con un número secuencial para cada fila es utlizar ROW_NUMBER() OVER para generar esa secuencia.
Para crear un identificador único de secuencia en una tabla de SQL Server lo más sencillo es definir un campo de tipo Identity, y que se vaya generando sólo, pero si no se puede utilizar esta solución, o no es apropiada para un caso concreto, una solución muy sencilla para informar de manera puntual un campo con un número secuencial para cada fila es utlizar ROW_NUMBER() OVER para generar esa secuencia.
Si, por ejemplo, queremos generar estos identificadores consecutivos para todas las filas de una tabla 'MyTable' en un campo 'MyRow_id' , sólo tenemos que hacer algo así:
-- Update MyRow_id with a sequential identifier ;WITH TableRanked AS( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) as rownumber, MyRow_id FROM MyTable ) UPDATE TableRanked SET MyRow_id=rownumber OPTION (MAXDOP 1)
Esta sería una solución puntual, otra cosa es si se desea mantener este campo actualizado..
Cómo crear una tabla con una select (CTAS) en SQLServer
Cómo crear una tabla con una select (CTAS) en SQLServer Carlos 4 June, 2012 - 17:24En Oracle, para crear fácilmente una tabla a partir de una consulta SQL se puede utilizar la siguiente sentencia:
CREATE TABLE NuevaTabla AS (SELECT * FROM OtraTabla);
Este tipo de sentencia se conoce como Create Table As Select (CTAS). Es muy útil para hacer pruebas rápidas con datos, para crear tablas de muchos campos que se parecen mucho a otras, o para 'materializar' una vista creando una tabla a partir de la select sobre la vista.

El caso es que en SQL Server también se puede hacer lo mismo, pero la sintaxis cambia bastante, y para el que esté más acostumbrado a la de Oracle puede serle útil saber que con SQL Server, para crear una tabla a partir de una sentencia SQL se puede utilizar una instrucción como esta:
SELECT * INTO NuevaTabla FROM OtraTabla;
Cómo recuperar los privilegios de administración (SYSADMIN) en SQLServer
Cómo recuperar los privilegios de administración (SYSADMIN) en SQLServer Carlos 26 May, 2012 - 11:39Si eres DBA y no puedes gestionar tus instancias de SQL Server porque no puedes entrar con el usuario 'sa', y no tienes ningún otro usuario con rol SYSADMIN, en el post How to connect to SQL Server if you are completely locked out, de MSSQLTips, nos explican una manera de recuperar el acceso a SQL Server como SYSADMIN.
Es algo parecido al método que explicaba il_masacratore para Recuperar la contraseña del usuario sys y system en Oracle, la clave está en entrar en la base de datos utilizando el usuario de sistema Administrador del servidor en el que está instalada.
Al conectar en modo 'single user' con un administrador local del servidor, podremos disfrutar de los permisos de administración de SYSADMIN para recuperar todo lo que haga falta, o asignar los privilegios necesarios a cualquier usuario.
Cómo reiniciar el valor de un campo identity de SQL Server
Cómo reiniciar el valor de un campo identity de SQL Server Carlos 26 July, 2012 - 22:30
Si una tabla de SQL Server tiene un campo de tipo identidad, o identity, en un momento dado puede interesar volverlo a dejar con su valor inicial, o a otro valor que interese para que siga autoincrementándose a partir del mismo.
Con un sencillo comando DBCC se puede dejar el valor actual del campo identity al que se desee, aunque hay que tener cuidado con no utilizar un valor que al incrementarse se pueda encontrar registros que ya existan con ese valor.
Lo más habitual es utilizar este comando cuando, por ejemplo, se eliminan todos los registros de una tabla, y se quiere volver a comenzar a insertar registros identificados por el campo autoincremental a partir de un valor inicial, normalmente 0. Si se utiliza para cualquier otra cosa hay que tener cuidado con los conflictos que puedan aparecer con registros existentes en la tabla.
Este es el comando para inicializar a cero el valor actual del autoincremental de un campo identity de la tabla 'mi_tabla', en una base de datos SQLServer: DBCC CHECKIDENT ('mi_tabla', RESEED,0) Espero que sea de utilidad,Muchas Gracias me funciono
Muchas Gracias me funciono perfectamente...!!
- Log in to post comments
Contadores y Rangos o funcion Rank() en SQLServer
Contadores y Rangos o funcion Rank() en SQLServer hminguet 3 October, 2011 - 14:40Crear contadores en SQLSERVER, simple pero útil.
1. Contador de registros:
select num = (select count(*) from d_Category r where r.id_Category<=t.id_category), t.* from d_category t
1.1. Con la función Ranking (sólo a partir del SQLSERVER 2005):
select rank() over (order by t.id_Category asc) as Ranking, t.* from d_category t order by 1
2. Contador por la suma del valor de un campo (por ranking).
En este caso obtendremos los 10 mejores clientes en ventas del 2010
select rank=count(*), s1.Customer, Val=round(s1.Val,0) from (select Customer, Val=round(sum(importe),0) from f_sales where year=2010 group by Customer) s1, (select Customer, Val=round(sum(importe),0) from f_sales where year=2010 group by Customer) s2 where s1.Val<= s2.Val group by s1.Customer having count(*)<11 order by 1
2.1. Con la función Ranking (sólo a partir del SQLSERVER 2005):
select * from ( select rank() over (order by importe desc) as Ranking, a.* from (select customer, sum(importe) as importe from f_sales where year=2010 group by Customer ) a ) F_TABLE where Ranking<=10y filtramos por los 10 primeros, por ejemplo.
Espero que os ayude.
Héctor Minguet.

Con respecto a la función
Con respecto a la función rank() over.., en lugar de necesitar una ordenación de todos los registros para sacar los 10 primeros, como en el último ejemplo, podemos necesitar una ordenación parcial de grupos de registros. Por ejemplo, en lugar de los 10 clientes con más importe pueden interesarnos los 10 clientes de cada zona con mayor importe, que es algo más habitual.
Ordenar registros agrupados con rank() over (partition by campo1 order by campo2)
Para ordenar agrupaciones de registros y quedarnos con los que nos interese (los primeros, los últimos..) lo único que hay que hacer es añadir a la sentencia la clausula 'partition by' de SQLServer para que nos haga las agrupaciones, y devuelva así el ranking, pero dentro de cada grupo o partición. Con el ejemplo anterior sería algo así:
select * from
(
select rank() over (partition by zona order by importe desc) as Ranking,
a.*
from (select zona, customer, sum(importe) as importe
from f_sales where year=2010 group by zona, Customer ) a
) F_TABLE
where Ranking<=10 Con esta consulta obtendríamos los 10 mejores clientes de cada zona, rankeados del 1 al 10 por su importe.
Eliminar duplicados en SQL Server con rank over y partition by
Este tipo de sentencias también puede ser muy útil para eliminar duplicados, y quedarnos sólo con un registro de varios. Sería algo tan simple como agrupar con partition by por los campos que queremos que nos definan los registros únicos, y quedarnos sólo con el primero de los que nos devuelva la ordenación.
Si, por ejemplo, sabemos que tenemos clientes duplicados porque se han hecho altas de clientes cuando estos ya existían, y el cliente bueno es el de la última fecha de alta, podemos 'librarnos' de los obsoletos con algo así:
select * from
(
select rank() over (partition by customer order by fecha_alta desc) as Ranking,
a.*
from (select customer, fecha_alta, sum(importe) as importe
from f_sales where year=2010 group by Customer, fecha_alta ) a
) F_TABLE
where Ranking=1
Eliminar duplicados en SQL Server con row_number over y partition by
El método con rank() para eliminar registros duplicados sólo tiene un problemilla, y es que el rank, si en el campo por el que ordena se encuentra dos valores iguales, devuelve la misma posición o rango a los dos registros del grupo, es decir, que si un cliente se diera de alta dos veces el mismo día, y esa fuera la fecha de alta más reciente, el rank nos devolvería un 1 para los dos registros, y nos quedaríamos con los dos, comiéndonos el duplicado.
Para evitar que nos pase esto, que además puede costar de ver, y generar bastantes problemas si se nos cuela el registro duplicado, en lugar de rank() se puede utilizar row_number(), que devuelve un número para cada registro del grupo, aunque el valor de la ordenación sea el mismo.
Siguiendo con el ejemplo anterior, para asegurarnos de que nos quedamos sólo con uno de los registros de cliente que se han podido dar de alta en varias ocasiones, sólo tenemos que cambiar rank() por row_number():
select * from
(
select row_number() over (partition by customer order by fecha_alta desc) as fila,
a.*
from (select customer, fecha_alta, sum(importe) as importe
from f_sales where year=2010 group by Customer, fecha_alta ) a
) F_TABLE
where fila=1 La sentencia anterior sería para hacer la selección de los registros que nos interesan, descartando los duplicados, y después se pueden guardar en una tabla con un insert, por ejemplo.
Pero si queremos eliminar los registros duplicados existentes en una tabla la sentencia SQL a utilizar sería diferente. La subselect del ejemplo ya no tiene sentido, ahora crearemos una sentencia SQL más sencilla trabajando directamente sobre todos los registros de una tabla customer_table.
Además, contaremos con la ayuda del ;with de CTE para eliminar los duplicados que no interesan, tal como se sugiere en este tema sobre borrado de registros duplicados:
;with duplicado as ( select row_number() over (partition by customer order by fecha_alta desc) as fila, c.* from customer_table c ) delete from duplicado where fila>1
Bueno, pues así ya tenemos controlados contadores, rangos, agrupaciones y duplicados en SQL Server, y tenemos algunos ejemplos de la función rank() de SQLServer, que cuesta un poco de entender, pero una vez que se aprende a utilizar nos puede evitar muchos quebraderos de cabeza con nuestras consultas, que de otra manera se pueden complicar bastante, y más si además queremos deshacernos de registros duplicados.
- Log in to post comments
Insert from select en SQL Server
Insert from select en SQL Server Carlos 10 October, 2016 - 19:38 Insertar registros con una select
Insertar registros con una select
Para hacer un insert para añadir registros a una tabla a partir de una sentencia Select en SQL Server se puede hacer algo tan simple como esto:
insert into mi_tabla_destino select * from mi_tabla_origen
Insertar registros con nombre de campo o diferente número con una select
Eso siempre que los campos de ambas tablas sean iguales. Si no coinciden exactamente, en número, nombre, etc., en lugar de utilizar el * hay que indicar el nombre de los campos que vamos a utilizar en la tabla origen y la tabla destino:
insert into mi_tabla_destino (campo_destino1, campo_destino2, campo_destino3) select (campo_origen1, campo_origen2, campo_origen3)
Crear una nueva tabla a partir de una select (CTAS)
Esto si la tabla ya existe, si lo que se quiere es crear una nueva tabla a partir de los datos de una select sobre otras tablas, algo conocido como CTAS (Create As Select), la sintaxis de la sentencia cambia un poco:
SELECT * INTO dbo.Destination FROM dbo.SourceSELECT * INTO dbo.Destination FROM dbo.SourceSELECT * INTO dbo.Destination FROM dbo.SourceSELECT * INTO dbo.Destination FROM dbo.SourceSELECT * INTO dbo.Destination FROM dbo.Sourceselect * into mi_nueva_tabla_destino from mi_tabla_origen
UPDATE con JOIN en SQLServer
UPDATE con JOIN en SQLServer hminguet 8 July, 2008 - 10:25Supongamos que queremos actualizar en nuestra bbdd SQLServer el campo de costes de la tabla de hechos FAC_TABLE con el coste unitario de nuestra tabla de COSTES.
UPDATE FAC_TABLE SET COSTE_UNITARIO = ct.COSTE_UNITARIO FROM COSTES ct WHERE FAC_TABLE.id_articulo = ct.id_articulo
Algo más sencillo que en Oracle.
Espero que os ayude.
Héctor Minguet.
Reconozco que esta sentencia
Reconozco que esta sentencia de UPDATE a partir de una SELECT de otra tabla en SQLServer es simple y efectiva pero, aunque no lo parezca, para mi es más fácil de recordar, y te diría que más comprensible esta otra sentencia SQL de Update, que yo calificaría de más estandar, y en la que se separa la condición de Join de los filtros del Where:
UPDATE Fact SET coste_unitario = ct.coste_unitario FROM FAC_TABLE Fact INNER JOIN Costes ct ON Fact.id_articulo = ct.id_articulo WHERE Fact.idfecha > 20120101
Alguien conoce alguna sentencia SQL mejor, o diferente, para hacer un 'UPDATE FROM SELECT' con SQL Server?
- Log in to post comments
Holas yo soy muy partidario,
Holas
yo soy muy partidario, cuando se complica mucho la cosa, de los bloques cte (tambien para oracle), se ve muy claro todo:
;with fact_CTE as (
SELECT fact.coste_unitario,
ct.coste_unitario as coste_unitario_UPD
FROM FAC_TABLE Fact
INNER JOIN Costes ct ON Fact.id_articulo= ct.id_articulo
WHERE Fact.idfecha > 20120101 )
UPDATE fact_CTE set coste_unitario= coste_unitario_UPD
- Log in to post comments
Buena sugerencia. En
Buena sugerencia. En estos ejemplos de Updates con join las sentencias son bastante simples, pero con queries más complejas la utilización de bloques CTE con el with de SQL Server puede simplificar muchísimo la comprensión de la sentencia, y a veces también el rendimiento.
- Log in to post comments
esta claro y me sirvió muchas
- Log in to post comments

Libros de SQL Server ¿Quieres
Libros de SQL Server
¿Quieres profundizar más en Transact-SQL o en administración de bases de datos SQL? Puedes hacerlo consultando alguno de estos libros de SQL Server
También puedes revisar la lista completa de los últimos libros de SQL Server publicados en Amazon según lo que te interese aprender.
- Log in to post comments
Excelente post...me sirvió
Excelente post...me sirvió para solucionar un problemon (problema grande) en mi trabajo.
Gracias
- Log in to post comments
DBlink en sql server
DBlink en sql server gilson 12 January, 2010 - 20:12Mi pregunta es muuy sencilla, es posible crear un dblink en sql server, y si es posible, como lo hago, muchisimas gracias!
saludos a todos
En su última entrada de blog,
En su última entrada de blog, il_masacratore comentaba Cómo acceder a MySQL desde SQL Server utilizando un Servidor Vinculado de SQL Server, que sería el equivalente a un database link de Oracle.
Espero que esto ya te sirva.
- Log in to post comments
Para crear un linked server
Para crear un linked server de SQL Server que conecte con una base de datos Oracle primero hay que instalar el conector OLEDB de Oracle, y después crear y configurar el linked server con T-SQL, o con SSMS.
Instalar el conector OLEDB de Oracle
Si no lo tienes, hay que instalar un cliente de Oracle que incluya este conector. Ojo porque el Instant client, el cliente básico de Oracle no lo incluye, se puede instalar el cliente, y después un paquete de complemento que lo incluya, pero lo más recomendable es instalar el paquete ODAC (Oracle Data Access Components), que sí que incluye el proveedor OLEDB de Oracle.
Si tienes un SQLServer de 64 bits en teoría es mejor que utilices los conectores de 64 bits que incluye este ODAC 64 bits de Oracle, pero si vas a conectar desde Visual Studio o desde SSIS curiosamente a día de hoy sólo te funcionarán los conectores de 32 bits, que puedes descargar desde la versión ODAC with Oracle Developer Tools for Visual Studio, de 32 bits. Según lo que vayas a hacer puede que lo mejor sea instalar los dos.
Apps de 32 bits en Ordenador con Windows 10 de 64bits y SQL Server de 64bits
Si tienes algún problema con esta instalación, otra opción que no suele fallar es instalar directamente un Oracle XE en tu máquina cliente, que también incluye el driver OLEDB, y no ocupa mucho más que el ODAC con las Tools. Nunca está de más disponer de una pequeña base de datos Oracle en la máquina que se va a conectar al server, aunque sólo sea para hacer pruebas. Puedes descargar el instalador de Oracle XE 11g desde aqui. Elige la versión de 32 o 64 bits con el mismo criterio que para las ODAC, si vas a conectar también Visual Studio/SSIS, aunque tu sistema y tu SQL Server sean de 64 bits instala la BD Oracle de 32 bits.
Crear el linked server a Oracle en SQL Server
Si ya tienes bien instalado el proveedor OLEDB de Oracle esta debería ser la parte más fácil. Se puede hacer desde el entorno gráfico de SQL Server Management Studio, utilizando el botón derecho sobre la carpeta 'Servidores vinculados' para crear un nuevo linked server que utice OLEDB para conectar con una BD Oracle.
Enlazo un sitio que lo explica bastante bien, y te dejo dos pantallazos de ayuda para la parte donde te pueden surgir más dudas.
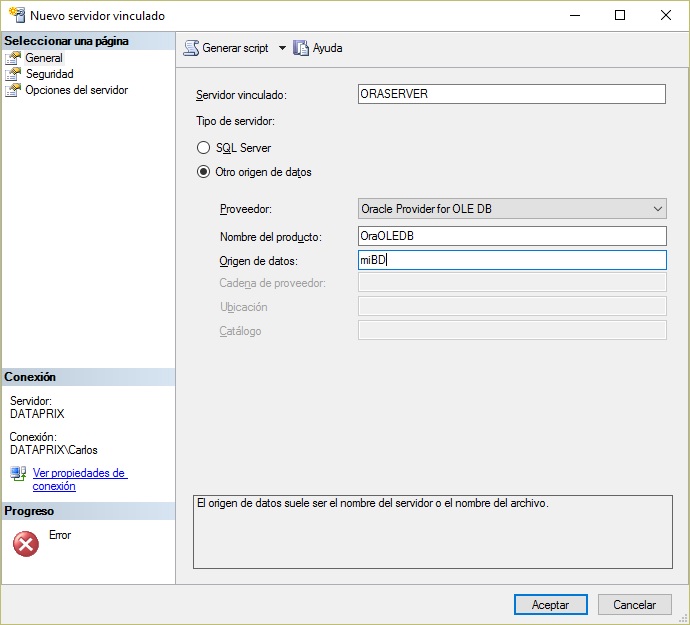
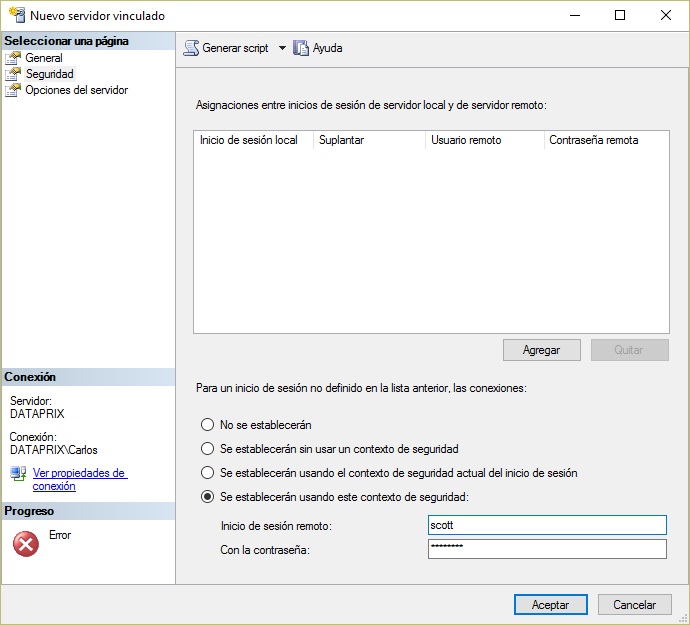
- Log in to post comments
Limitaciones en las funciones de SQL Server
Limitaciones en las funciones de SQL Server Carlos 21 December, 2016 - 17:22 Las funciones de usuario de SQL Server tienen bastantes limitaciones comparadas con otras funciones de otras bases de datos, como Oracle, o con lo que se puede hacer en los procedimientos almacenados.
Las funciones de usuario de SQL Server tienen bastantes limitaciones comparadas con otras funciones de otras bases de datos, como Oracle, o con lo que se puede hacer en los procedimientos almacenados.
Las principales limitaciones, bajo mi punto de vista, son estas dos:
- Dentro de una función de SQL Server no se pueden ejecutar sentencias de actualización de datos como INSERT, UPDATE o DELETE, es decir, que una función de usuario NO puede modificar valores de las tablas de una base de datos.
- Las funciones de T-SQL no permiten el tratamiento de excepciones con bloques TRY CATCH
Es importante recordar estas limitaciones antes de comenzar a desarrollar funciones personalizadas, porque es bastante habitual terminar creando un procedure porque alguna cosa no se puede hacer o controlar con una función.
¿Conoces más limitaciones de las funciones de usuario de TSQL?
SQL Dinámico con retorno de valores en procedimientos de SQL Server
SQL Dinámico con retorno de valores en procedimientos de SQL Server Carlos 30 December, 2016 - 08:51 Si necesitas parametrizar algo más que los valores de los campos que se introducen en la parte del WHERE en una sentencia T-SQL de un procedimiento almacenado seguramente vas a tener que utilizar SQL dinámico, aunque si se puede hacer lo mismo sin SQL dinámico siempre es mejor, más seguro y más eficiente.
Si necesitas parametrizar algo más que los valores de los campos que se introducen en la parte del WHERE en una sentencia T-SQL de un procedimiento almacenado seguramente vas a tener que utilizar SQL dinámico, aunque si se puede hacer lo mismo sin SQL dinámico siempre es mejor, más seguro y más eficiente.
Ejemplo de sentencias que se pueden hacer dentro de un procedure con SQL 'Estático'
INSERT INTO estadisticas(idFecha,fecha,bd,tabla,campo,filtro,funcion,valor) values (@idfecha,getdate(),@bd,@tabla,@campo,'','COUNT',@valor) SELECT @valor= valor FROM estadisticas WHERE bd=@bd and tabla=@tabla and campo=@campo
Ejemplos de sentencias que se pueden hacer dentro de un procedure con SQL dinámico
Si es necesario parametrizar el nombre de la tabla de la query, o partes de la sentencia fuera del WHERE, se puede utilizar SQL dinamico con la opción poco recomendada porque el motor no puede optimizar nada, y porque se corre el peligro de sufrir un ataque de SQL Injection de montar la sentencia en un string, y ejecutarlo directamente con EXEC.
Un ejemplo de lo que se puede hacer, pero es mejor evitar:
SET @SQLQuery= 'SELECT ' + cast(@funcion as NVARCHAR(50)) + '('+ cast(@campo as NVARCHAR(50)) +')
FROM ' +cast(@bd as NVARCHAR(50))+ '.' + cast(@tabla as nvarchar(50))
EXECUTE(@SQLQuery)Un ejemplo para obtener el mismo resultado, pero de manera más segura y eficiente. Se define además una variable de salida para recuperar un valor de la query.
Sin duda esta es la opción más recomendada para ejecutar SQL dinámico en procedures de T-SQL:
DECLARE
@Tabla sysname,
@Funcion nvarchar(50),
SET @SQLQuery='SELECT @valor=' + @funcion + '(' + @campo + ') FROM ' + QUOTENAME(@tabla)
EXECUTE sp_executesql @SQLQuery, N'@campo nvarchar(50),@valor bigint OUTPUT',
@campo=@campo,@valor=@valor OUTPUT
SELECT @valor as valor
Destacar que @tabla y @funcion son variables locales que se pueden preparar dinámicamente dentro del procedure, e incluirlas directamente en la sentencia y que @campo sería, por ejemplo, un parámetro del procedure.
@Tabla es de tipo sysname porque se utiliza como nombre de tabla en el FROM, si se definiera como NVARCHAR en algunos casos podrían producirse errores de ejecución.
Referencias de otros sitios con más detalles y ejemplos: MSQLTips, Codeproject
Herramientas de administración para DBA's de SQL Server
Herramientas de administración para DBA's de SQL Server Carlos 22 September, 2016 - 18:39 Con SQL Server Management Studio se gestiona bastante bien la administrción básica de SQL Server, pero siempre hay herramientas que pueden ayudar a hacer las cosas más fáciles.
Con SQL Server Management Studio se gestiona bastante bien la administrción básica de SQL Server, pero siempre hay herramientas que pueden ayudar a hacer las cosas más fáciles.
Mi idea es dejar aquí una lista de las que consideremos más útilles, y así podamos consultarla en cuanto tengamos que hacer alguna cosa específica.
Las primeras que propongo son gratuítas, o tienen versión free, al menos para una instancia, sin caducidad:
Herramientas y scripts complementarios gratuítos para SQLServer
- SQLSentry Plan Explorer
Perfecta para optimizar consultas, y mucho más completa que el analizador de Management Studio. Además se puede agregar como Add-In de SSMS para poder llamarla directamente desde un plan de ejecución de SSMS. - Toad for SQL Server
La versión free para mi no aporta mucho más que SSMS, pero en un listado de software freeware para DBA'a creo que no debe faltar Toad :) - Redgate SQL Search
Un Add-in superútil de redgate para SQL Server Management Studio que permite realizar búsquedas sobre los objetos y de la base de datos y localizar fragmentos de código SQL en tablas, vistas, procedimientos almacenados, funciones, vistas, jobs.. - Idera SQL Check
Útil herramienta para monitorización del rendimiento cuya versión gratuíta se puede utilizar con un servidor y para monitorizar hasta 20 métricas, sin necesidad de instalar ningñun agente. - Who is active (sp_whoisactive)
Procedimiento almacenado para monitorización de actividad y optimización del rendimiento - SQL Server Maintenance Solution
Scripts de Ola Hallengren para mantenimiento de bases de datos SQL Server (DatabaseBackup.sql, DatabaseIntegrityCheck.sql, IndexOptimize.sql, CommandExecute.sql y CommandLog.sql)
Plataforma interactiva con 600+ cursos de datos. Practica SQL directamente en el navegador con ejercicios guiados, proyectos reales y certificaciones reconocidas. El primer capítulo de cada curso es gratis.
Enlace de afiliado · Dataprix puede recibir una comisión
¿Utilizas otras herramientas complementarias para administrar tus bases de datos SQL Server? Dinos cuáles son y haremos crecer la lista..
Ssmstools, sp_whoisactive y
Ssmstools, sp_whoisactive y los scripting de olla hallegreen.
- Log in to post comments
Gracias por tu aportación, he
Gracias por tu aportación, he incluído SP_Whoisactive y SQLServer MaintenanceSolution en la lista de herramientas y scripts gratuítos.
SSMS Tools Pack también parece muy útil, pero no es gratuíta, aunque es bastante barata, así que la dejo aquí enlazada. La licencia de demo sirve para 60 días de prueba.
- Log in to post comments
Gracias por el Aporte, y
- Log in to post comments
Almacenar usuario y dominio
Almacenar usuario y dominio jatb 23 June, 2013 - 04:53Hola a todos,
Espero me puedan ayudar, quiero guaradar el historial de los usuarios que visualizan los reportes, los parametros del reporte son los parametros que pasan por el sp en sql, ahora lo que quiero es guaradar en una tabla que usuario y el dominio esta generando el reporte.
Como se puede lograr esto?
Dentro del sp incluye un
Dentro del sp incluye un insert into tabla_custom con todos los valores hora de ejecucion y demas.
Suele usarse este metodo mas para debug añadiendo bloque try catch, pudiendo detectar errores no reportados por el usuario.
- Log in to post comments
Base de datos de una web sincronizada con BBDD de locales
Base de datos de una web sincronizada con BBDD de locales Carlos 27 August, 2009 - 11:57Jorge pregunta en otro tema lo siguiente:
[quote=jorgebcl] Hola, Carlos esta genial el ETL, te hago otra consulta, esta muy bueno el tema, ya que esto es de base de datos, como funciona un pagina que se dedica a vender articulos por intenet en cuanto a la base de datos?, la idea aqui es que todos los locales esten en linea y haci usar esa base de datos para la venta en WEB, pero la linea dedicada es muy costasa y no estoy viendo el retorno por ninguna parte(ya que las ventas por intenet de nuestros articulos uqe son neumaticos es una idea que quizas mas adelante funcion como tirerack), la pregunta es como lo hacen las empresas que tiene esta figura, no seria mejor hacre un respaldo cada una hora por ejemplo y usar estos respaldos de locales para que la web se conexte a esta base de respaldo, lo que tendria baja probabiilidad de no tener stock, y ahorrarmen la linea dedicada. Saludos Jorge [/quote]
Hola Jorge
Si no tienes la necesidad de mantenerlo todo sincronizado en tiempo real puede que sea buena idea ahorrarte la línea dedicada. Tal como comentas, si tienes locales y una web puedes mantener una base de datos centralizada que se vaya actualizando con los datos de todos los puntos de venta, y esta actualización no es necesario que sea en tiempo real. Supongo que también tendrás que pensar en una actualización en sentido contrario.
- Lo más sencillo sería trabajar con descargas de datos cada cierto tiempo. El stock deberías actualizarlo más a menudo, pero los datos maestros como artículos y tarifas pueden actualizarse diariamente, por ejemplo. En la parte de la base de datos centralizada/ servidora de la web puedes tener un SQL Server y utilizar SSIS para incorporar los datos que provengan de los locales.
- Si la tecnología de la aplicación de punto de venta te lo permite también podrías plantearte la utilización de web services para mantener el stock lo más actualizado posible.
- Y si pudieras utilizar bases de datos SQL Server en el punto de venta podría funcionarte muy bien, y sin tener que pagar más licencias, utilizar SQL Server Express en los locales y realizar la sincronización entre la BD servidora y las locales mediante el mecanismo de replicación de SQL Server. En el sentido de BD local a BD Servidora seguramente tendrías que seguir utilizando SSIS, por las limitaciones de uso de la versión Express.
Aparte de la reducción de los costes de la linea, ten en cuenta que de esta manera también independizas el funcionamiento de todos los puntos de venta, ya que cada uno tiene su propia base de datos que funciona independientemente de lo que pase fuera. Si un TPV se queda sin ADSL podrá seguir vendiendo sin problemas hasta que recupere la conexión.
Bueno, parece que tienes otro proyecto interesante entre manos, ya nos contarás por qué tecnología te decides y cómo te va..
Ola carlos, me comentan aca
Ola carlos, me comentan aca que por diseño del sistema que se desarrollo esta, estubo pensando siempre para que este en linea, por lo que la base de datos es solo una, para hacer lo que tu me dijiste habria que tener fotos de toda esta informacion, al parecer habria que hacerlo asi, estan cotizando tener en los locales Ancho de banda mayor. Yo no estaba al inicio del proyecto, pero me parece que demoraria mucho un replantamiento del tema......el problema con esto que llevar demasiado tiempo
Saludos
- Log in to post comments
Si todo está diseñado para
Si todo está diseñado para trabajar con una base de datos servidora está claro que cambiar a un funcionamiento con ésta más bases de datos locales supone un cambio importante que tiene sus ventajas, pero también sus costes e inconvenientes.
Al menos tienes un plan B en mente por si tuvieras algún problema con la 'opción online'.
- Log in to post comments
Crear en SQL Server un rol adicional para ejecutar stored procedures
Crear en SQL Server un rol adicional para ejecutar stored procedures Carlos 21 November, 2017 - 20:12 Cómo crear un rol en SQL Server para poder dar a los usuarios fácilmente permisos para ejecutar stored procedures.
Cómo crear un rol en SQL Server para poder dar a los usuarios fácilmente permisos para ejecutar stored procedures.
En SQL Server no existe un rol predefinido para que un usuario pueda ejecutar stored procedures, aparte del db_owner.
Si se trabaja con stored procedures y se quiere permitir a usuarios que no tengan porqué ser owners de una base de datos ejecutar procedimientos almacenados de la misma, se puede crear un rol específico con un grant de permisos de ejecución 'EXECUTE'.
Así después sólo hay que asignar ese rol a los usuarios que tengan que ejecutar stored procedures de una base de datos.
Es tan fácil como hacer algo así:
-- Crea un nuevo rol para ejecutar stored procedures CREATE ROLE db_execute -- Asigna permisos de ejecución de procedimientos almacenados al rol GRANT EXECUTE TO db_execute -- Agrega un usuario al recién creado rol db_execute role EXEC sp_addrolemember 'db_execute', 'usuario'
Después de esto 'usuario' ya podrá ejecutar stored procedures de la base de datos en la que se ha creado el rol aunque no sea 'db_owner' de esa base de datos..
Generación de codificación geográfica y zona de tiempo a partir de direcciones en SQL Server con PowerShell, T-SQL y GoogleMaps
Generación de codificación geográfica y zona de tiempo a partir de direcciones en SQL Server con PowerShell, T-SQL y GoogleMaps Carlos 26 September, 2016 - 15:21 Generar las coordenadas geográficas a partir de una dirección utilizando la API de Web Services de Google Maps, y todo dentro de SQL Server, me parece algo tan útil como técnicamente interesante.
Generar las coordenadas geográficas a partir de una dirección utilizando la API de Web Services de Google Maps, y todo dentro de SQL Server, me parece algo tan útil como técnicamente interesante.
Como estoy seguro de que no tardaré en probarlo o necesitarlo para algo, enlazo aquí el post de MSSQLTips sobre cómo hacerlo para saber dónde encontrarlo como lo necesite, y me guardo la función de llamada a la API:
#
# Name: Get-Geo-Coding
# Purpose: Use Google api 4 address 2 location calc.
#
function Get-Geo-Coding {
[CmdletBinding()]
param(
[Parameter(Mandatory = $true)]
[String] $ServiceKey,
[Parameter(Mandatory = $true)]
[string] $FullAddress
)
# Create request string
[string]$ApiUrl = ""
$ApiUrl += "https://maps.googleapis.com/maps/api/geocode/xml?address="
$ApiUrl += $FullAddress
$ApiUrl += "&key="
$ApiUrl += $ServiceKey
# Make request
$Request = [System.Net.WebRequest]::Create($ApiUrl)
$Request.Method ="GET"
$Request.ContentLength = 0
# Read responce
$Response = $Request.GetResponse()
$Reader = new-object System.IO.StreamReader($Response.GetResponseStream())
# Return the result
return $Reader.ReadToEnd()
}
Importar base de datos desde Oracle
Importar base de datos desde Oracle gilson 21 January, 2010 - 14:24Buenas a todos, tengo una base de datos en oracle 9i, y me gustaria migrar esa base de datos a sql server 2008, ojala alguien podria ayudarme con esto, desde ya estoy muy agradecido.
saludos a todos
buenas, resulta que estoy
buenas, resulta que estoy tomado un curso de transact sql en la universidad y quiero probar, muchas gracias por tu ayuda!
saludos!
- Log in to post comments
Instalacion de SQL SERVER 2008 EN xp con SP2
Instalacion de SQL SERVER 2008 EN xp con SP2 gilson 18 January, 2010 - 13:12Buenas a todos, tengo un problema al instalar el motor, me sale un error al iniciar el mismo, les comento que anteriormente tenia el sql 2005 que al parecer no lo desinstale correctamente, por que al iniciar mi pc me sale un error del sql dumper, que podria hacer para solucionar este problema?, es posible descargar nuevamente la utilidad sql dump, o que me dices ustedes?..
Muchisimas gracias por su ayuda
Saludos
Podrías especificar el error
Podrías especificar el error que comentas que te sale al iniciar SQL Server? También sería útil saber la versión de SQL Server que has instalado, si es Express, Standard o Enterprise. No creo que sea el caso, pero recordemos que la Enterprise, por ejemplo, se ha de instalar sobre un Windows Server.
De todas maneras puedes consultar en la web de Soporte de Microsoft el artículo Cómo desinstalar manualmente una instancia de SQL Server 2005, puede que así encuentres lo que se haya quedado sin desisntalar.
Otra cosa que también te podría ser de utilidad, sobretodo si has detectado que algo en concreto se ha quedado sin desinstalar es la herramienta Windows Installer CleanUp Utility, que se suele utilizar cuando los desinstaladores estandar no terminan bien su trabajo
- Log in to post comments
Los campos identity se saltan 1000 números aleatoriamente
Los campos identity se saltan 1000 números aleatoriamente Carlos 23 May, 2014 - 18:49
En el grupo SQL Server Si! de Linkedin, me han hecho una consulta sobre un funcionamiento anormal de los campos Identity de una base de datos SQL Server. La traslado aquí porque es algo que a mi nunca me ha pasado.
En un SQL Server 2012 sp1 las claves primarias definidas como campos identity, en distintas tablas, y de manera aleatoria, cada semana en una, por ejemplo, se saltan 1000 registros de la secuencia.
Como digo es algo que nunca me he encontrado, así que si alguien tiene idea de lo que puede estar ocurriendo en esta base de datos le agradezco que lo comparta.
Desde Twitter, Daniel Trabas
Desde Twitter, Daniel Trabas (@DaniT20), ha sugerido que podrían ser registros que se eliminen, o transacciones sucias.
Lo de los registros que se eliminen parece demasiado simple, pero tiene mucho sentido, podría haber algún proceso, procedure, aplicación etc. que por alguna razón fuera eliminando esos 1.000 registros, ¿habéis comprobado si os faltan datos o están todos y el hueco está sólo en la numeración?
Yo nunca he visto algo así, pero otra opción que se me ocurre es que por bloqueos o algo así os estén fallando algunas operaciones de insert, pero el contador se incremente igual. ¿Tenéis definidos triggers en las tablas o son todo inserts sin más? Con los triggers podrían pasar cosas de este tipo..
- Log in to post comments
En otros foros ha realizado
En otros foros ha realizado la misma consulta, y es un problema que trae sqlserver 2012 sp1, se de colocar en el parametro del trace flag 272, (-t272) con ello desaparece el problema
- Log in to post comments
Gracias Hans, ya tenemos otro
Gracias Hans, ya tenemos otro misterio de SQL Server resuelto :)
Enlazo uno de los blogs que he encontrado al buscar 'trace flag 272' donde explican cómo utilizar el parámetro, y también otra manera de evitar el problema, gracias a la opción NOCACHE en la creación de la secuencia:http://jamessql.blogspot.com.es/2013/07/gap-issue-in-sql-server-2012-id…
- Log in to post comments
Tengo este problema y no he
Tengo este problema y no he podido solucionarlo alguien me puede comentar si ya lo pudieron solucionar y como?
saludos
- Log in to post comments
Esto sucede siempre que se
Esto sucede siempre que se reinicia el computador mientras está funcionando (grabando o leyendo datos) el motor de SQL, y se daña la secuencia de las tablas que estaban en uso. Hasta ahora no he encontrado solución. Me ha tocad siempre que sucede esto, reparar los datos y reinicializar la numeración.
- Log in to post comments
Buenas tardes Respecto al uso
Buenas tardes
Respecto al uso de columnas con propiedad Identity.
Valores consecutivos después de un reinicio del servidor u otros errores: SQL Server podría almacenar en memoria caché los valores de identidad por motivos de rendimiento y algunos de los valores asignados podrían perderse durante un error de la base de datos o un reinicio del servidor. Esto puede tener como resultado espacios en el valor de identidad al insertarlo.
Si no es aceptable que haya espacios, la aplicación debe usar mecanismos propios para generar valores de clave. El uso de un generador de secuencias con la opción NOCACHE puede limitar los espacios a transacciones que nunca se llevan a cabo. https://docs.microsoft.com/es-es/sql/t-sql/statements/create-table-transact-sql-identity-property
- Log in to post comments
Tiene mucho sentido, desde
Tiene mucho sentido, desde luego si no hay manera de garantizar que nunca se generen estos saltos y es crítico que los id's sean siempre consecutivos, hay que pensar en utilizar otras soluciones, como un mantenimiento independiente de las secuencias en estructuras, o una consulta del último valor para poder generar el siguiente antes de cada inserción, más ineficiente, pero más seguro, gracias por las dos sugerencias.
- Log in to post comments
Particionamiento de tablas en SQLServer 2005
Particionamiento de tablas en SQLServer 2005 josimac 18 May, 2008 - 01:05Hola a todos.
Es sabido por todo el mundo de las capacidades de particionamiento que posee Oracle desde sus mas antiguos releases. En Sql Server 2000 existia una especie de "chapuza" para poder hacerlo mediante restricciones "CHECK" en los campos y utilizando vistas mediante UNIONS.
El panorama en SQL Server 2005 a mejorado un poco respecto a eso.
No puedo dar fe absoluta sobre las ventajas de utilizar dicho particionamiento (lo usé en una tabla de hechos con pocos millones de registros) pero al menos es una tecnología más reciente que las "vistas".
PASO 1: Crear una función de partición
CREATE PARTITION FUNCTION [MiFuncionDeParticion] (char(15))
AS RANGE LEFT FOR VALUES ('VALOR1', 'VALOR2', 'VALOR3')
PASO 2: Crear un schema para la partición con el grupo de archivos SQL a utilizar
CREATE PARTITION SCHEME [MiNombreDeSchema]
AS PARTITION [MiFuncionDeParticion] ALL TO ([PRIMARY]) <------- Nombre del grupo de archivos de SQL Server.
PASO 3: Se crea la tabla que va a ser particionada
CREATE TABLE [dbo].[MiTabla] (
[CAMPO1] [int] NOT NULL,
[CAMPO2] [int] NOT NULL,
[CAMPO3] [char](15) COLLATE Modern_Spanish_CI_AS NOT NULL,
[CAMPO4] [char](15) COLLATE Modern_Spanish_CI_AS NOT NULL,
[CAMPO5] [float] NULL
) ON [MiNombreDeSchema] ([CAMPO3])
Existen mas valores de configuración para realizar este tipo de particiones.
Si alquien quiere saber mas...... en la documentación de SQL hay más información y si no, pues podeis preguntar lo que querais.
Saludos,
Yo tengo una tabla con 45
Yo tengo una tabla con 45 millones de registros. Como hago para hacer la particíon con SQL Server 2005? En el ejemplo veo que creas la tabla pero se puede hacer sobre una ya creada?
- Log in to post comments
Las tablas particionadas
Las tablas particionadas almacenan los registros separados por particiones, por lo que pasar de una tabla normal a una particionada implicaría mover físicamente todos los datos. No creo que exista ninguna opcion de ALTER TABLE que te permita hacer esto, y si la hubiera seguramente lo que haría es recrear la tabla completa.
Precisamente por el gran volumen de registros que tienes yo te recomendaría crear una tabla vacía particionada, y hacer después una migración de los datos insertándolos en esta tabla particionada, y sin tocar la original, por si algo no sale como esperabas.
Esto además, dependiendo de las condiciones del entorno, te permitirá hacer alguna prueba de rendimiento sobre ambas tablas para comprobar que el particionamiento realmente te beneficia.
Ya nos explicarás..
- Log in to post comments
carlos wrote: Las tablas
[quote=carlos]
Las tablas particionadas almacenan los registros separados por particiones, por lo que pasar de una tabla normal a una particionada implicaría mover físicamente todos los datos. No creo que exista ninguna opcion de ALTER TABLE que te permita hacer esto, y si la hubiera seguramente lo que haría es recrear la tabla completa.
Precisamente por el gran volumen de registros que tienes yo te recomendaría crear una tabla vacía particionada, y hacer después una migración de los datos insertándolos en esta tabla particionada, y sin tocar la original, por si algo no sale como esperabas.
Esto además, dependiendo de las condiciones del entorno, te permitirá hacer alguna prueba de rendimiento sobre ambas tablas para comprobar que el particionamiento realmente te beneficia.
Ya nos explicarás..
[/quote]
Exacto...
Particionar una tabla que ya contiene registros los veo una temeridad y más con semejante volumen de registros.
En cualquier caso, creo que no se puede hacer sobre una tabla ya existente.
Saluditos,
- Log in to post comments
Ok. Voy a realizar la
Ok.
Voy a realizar la prueba.
Se puede realizar partición sobre cualquier tipo de datos?
Por ej me serviria realizar la particion por un campo "usuario" que es un varchar.
Si me aparecen nuevos usuarios en la tabla, puedo agregar nuevas particiones?
- Log in to post comments
Para particionar la tabla has
Para particionar la tabla has de definir los rangos en los que se han de agrupar los registros. Para ello se utiliza la función de particionamiento, que te permite definir estos grupos a partir de los valores de campos de los registros.
Estos campos pueden ser de diferentes tipos de datos. Puedes utilizar campos varchar, de fecha, enteros, etc.
Los nuevos registros entrarán en la partición que les toque según tengas definida la función de particionamiento.
Lo normal es crear rangos, por fechas, o por orden alfabético o numérico.
Aunque se puede hacer, yo no te aconsejaría crear una partición para cada usuario. Primero por lo que tu mismo dices, con cada nuevo usuario tendrías que crear una nueva partición. Segundo, seguro que la distribución de registros por usuario no es muy homogénea, lo más eficiente es que no haya demasiadas diferencias de volumen entre las particiones.
- Log in to post comments
Veo que el post tiene ya algo
Veo que el post tiene ya algo de tiempo.. pero espero obtener alguna respuesta. De qué manera puedo establecer la partición de una tabla alfabéticamente, de forma que en una partición se acomoden todos los resgistros que empiecen de la a "a" a la "f", por ejemplo.. es posible hacer eso?
- Log in to post comments
Hola Xóchitl Selene Los
Hola Xóchitl Selene
Los valores que pongas en la función de partición son utilizados como rangos SIEMPRE.
Es decir, si miras el siguiente ejemplo:
Crear una función de partición
CREATE PARTITION FUNCTION [MiFuncionDeParticion] (char(1))
AS RANGE RIGHT FOR VALUES ('A', 'G', 'M', 'Z')
Se comportará creando 5 grupos:
1.) < 'A'
2.) >= 'A' y < 'G' (es decir, de la A a la F)
3.) >= 'G' y < 'M'
4.) >= 'M' y < 'Z'
5.) >= 'Z'
Esto te funcionará seguro.
Saludos,
- Log in to post comments
Muchas gracias josimac me ha
Muchas gracias josimac me ha servido mucho :).
Tengo otra consulta..
Para hacer un particionamiento vertical como sería??.. Entiendo en teoría q ese particionamiento es para dividir una tabla en varias con menos campos en una relación 1:1, y que juntándolas se forma la misma tabla inicial.. Pero esto significa crear nuevas tablas con los campos divididos??.. No se puede hacer esto de forma lógica tal como se hace en el particionamiento horizontal?? o cómo podría hacerlo para no tener q crear nuevas tablas?
De antemano muchas gracias..
- Log in to post comments
Hola de nuevo. Si me permites
Hola de nuevo.
Si me permites la pregunta, ¿para que quieres hacer algo así?
Desde el punto de vista transaccional vas ha incrementar las escrituras en bbdd.
Desde el punto de vista de reporting o dw te verás en la obligación de hacer un diseño lógico del tipo snow-flake con lo que eso comporta (más joins para desnormalizar las tablas).
Si lo que quieres es "particionar" esos datos para , por ejemplo, crear diferentes orígenes de datos que alimenten un cubo OLAP puedes hacerlo mediante vistas de la tabla.
Si nada de que lo que te he dicho te convence.... entonces necesito que me contestes la primera pregunta que te hago.
Saludos,
- Log in to post comments
Gracias. Es parte de una
Gracias. Es parte de una práctica de bases de datos distribuidas :). Supongo que tendré que recurrir a la creación de las nuevas tablas.
Por otra parte, regresando al script de particionamiento.. despues de crear la funcion y el esquema de partición he intentado crear la tabla de la siguiente manera:
CREATE TABLE articulos
(
ArtID int identity(1,1) NOT NULL,
ArtLetra char(1) COLLATE Modern_Spanish_CI_AS NOT NULL,
CONSTRAINT PK_Art PRIMARY KEY(ArtID)
) ON practicalAbcDistributionScheme(ArtLetra);
GO
pero al ejecutar me muestra el siguiente mensaje:
La columna 'ArtLetra' es una columna de particionamiento del índice 'PK_Art'. Las columnas de particionamiento de un índice único deben ser un subconjunto de la clave de índice.
--
le quito la linea que hace referencia al campo llave ( CONSTRAINT PK_Art PRIMARY KEY(ArtID) )
y el script es ejecutado de manera correcta.. por qué sucede eso??
Mi solución es declarar los campos sin llaves y después modificarlas para indicarles los campos llave.. pero como se hace para no tener que hacerlo así?
- Log in to post comments
Cuando declaras el campo
Cuando declaras el campo "ArtID" como autoincremental le estás asignando una primary key. Cuando la función de particionamiento genere más de una tabla vas a tener codigos iguales en distintas tablas que no van a servirte para nada.
Si quieres utilizar claves surrogadas las vas a tener que gestionar en tiempo de carga, es decir, calcularlas tu. Creo que se queja de eso.
- Log in to post comments
Hola, Mi caso es parecido
Hola,
Mi caso es parecido sólo que las particiones están en función de la fecha. Tenemos una tabla ya particionada con unos 40 mill de registros. El caso es que sólo debemos guardar 6 meses, quizás me explico mejor con un ejemplo. Pongamos que estamos en Junio del 2010, mi tabla tendrá 6 particiones ordenadas por fecha que serán las correspondientes a enero, febrero, marzo, ..., y junio, pero al llegar julio, debemos desprendernos de enero para así seguir teniendo 6 particiones que irían desde febrero hasta julio.
¿Me podríais orientar cómo puedo hacer este proceso de reciclado de particiones?
Muchas gracias.
- Log in to post comments
Tendrás que hacerlo mediante
Tendrás que hacerlo mediante un script que elimine la partición del mes más antiguo, y cree la del nuevo mes.
Es fácil decirlo, pero no tan trivial de implementar. La eliminación de la partición de ha de hacer de una manera eficiente, sobretodo la tabla particionada es grande, como es tu caso. Hay que evitar que se termine haciendo un delete de cada registro.
Te enlazo algunas entradas del blog de Dan Guzman, que presenta una solución para mover la partición a una tabla auxiliar, sobre la que después se puede hacer un truncate, e incluye los scripts para hacerlo:
Sliding Window Table Partitioning
Automating Sliding Window Maintenance
Automating RANGE RIGHT Sliding Window
Te enlazo de paso Partition Details and Row Counts, que te puede ser de utilidad para obtener información de las particiones.
- Log in to post comments
quiero que me ayudes en un
- Log in to post comments
Problema con funcion escalar
Problema con funcion escalar gilson 2 March, 2010 - 12:35buen dia a todos, tengo un problema con una funcion escalar, lo que quiero es que me devuelva un tipo de dato money pero al ejecutar la funcion me retorna 0.00, y no se por que esta sucediendo eso
aqui les dejo la codificacion de la funcion
USE [sisfinan]
GO
/****** Object: UserDefinedFunction [dbo].[obtener_total_interes_sistema_aleman] Script Date: 03/02/2010 00:00:08 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create function [dbo].[obtener_total_interes_sistema_aleman]
(
@deuda money,
@plazo smallint,
@tasa real,
)
returns money
as
begin
declare @monto_interes money,@id_cuota smallint, @total_interes money
select @id_cuota = 1;
while @id_cuota <= @plazo
begin
select @monto_interes = @monto_interes + @deuda *(@tasa/100),
@total_interes = @total_interes + @monto_interes,
@deuda = @deuda - @capital
select @id_cuota = @id_cuota +1;
end;
return isnull(@total_interes,0);muchas gracias por su ayuda
saludos
Creo que lo que te falta es
Creo que lo que te falta es inicializar las variables que utilizas en los cálculos. Seguramente intervienen en las operaciones con valor nulo, y por eso el resultado también es nulo.
Asígnale valor inicial 0 a monto_interes y a total_interes, y asegúrate de que deuda se pasa también con un valor definido.
- Log in to post comments
hola carlos, ayer justamente
hola carlos, ayer justamente inicialize las variables y me funciona perfectamente, muchas gracias por tu ayuda, ahora tengo
otro pequeño problema, al ejecutar un procedimiento me sale este error Mens 2732, Nivel 16, Estado 1, Procedimiento
sp_ins_propuesta, Línea 449 El número de error 8134 no es válido. El número debe estar comprendido entre 13000 y 2147483647 y no puede ser 50000.,
a que se debera este error por que todos los errores capturo con raiserror('mensaje',16,1)
muchisimas gracias por tu ayuda
saludos
- Log in to post comments
Habría que ver el código del
Habría que ver el código del PROCEDURE, pero en algún lugar se tiene que estar asignando el número 8.134 como código de error. Puede que sea en alguna función o procedure a los que llame el principal.
Deberías poder encontrarlo y cambiar ese número por uno mayor que 13.000.
- Log in to post comments
ok carlos voy a buscarlo,
ok carlos voy a buscarlo, agradezco mucho tu ayuda, saludos
lo raro es que uso el mismo raiserror para un procedimiento que inserta personas y no tengo ningun problema con ese procedure
- Log in to post comments
Problemas en conexiones remotas a servidores de SQL Server
Problemas en conexiones remotas a servidores de SQL Server Carlos 4 May, 2016 - 20:24Recientemente he tenido problemas para establecer una conexión remota a un servidor SQL Server 2012 de mi red. La conexión estaba bien definida, los puertos estaban abiertos, el server permitía conexiones remotas y, sin embargo, no había manera de conectar desde otra máquina, con SQL Server Management Studio, por ejemplo.
Después de mucho revisar descubrí que el problema venía de las opciones de configuración de red de SQL Server, que no estaban bien definidas en el servidor. Lo apunto aquí por si le pasa a alguien más. En mi caso tenía deshabilitado el protocolo 'Canalizaciones con nombre', y ha de estar habilitado, y en las propiedades del protocolo TCP/IP faltaba incluir la IP del servidor, y el puerto TCP, normalmente el 1433.
Todo esto se configura abriendo el 'Administrador de configuración de SQL Server' o 'SQL Server Configuration Manager' desde el menú de aplicaciones de Microsoft SQL Server, subcarpeta 'Herramientas de configuración'.
Como una imagen vale más que 1.000 palabras, esta es la captura de pantalla de la configuración que me ha resuelto el problema de conexión remota a SQL Server.
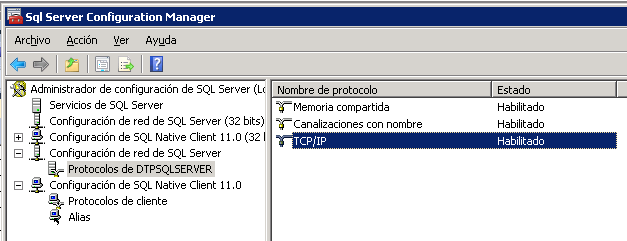
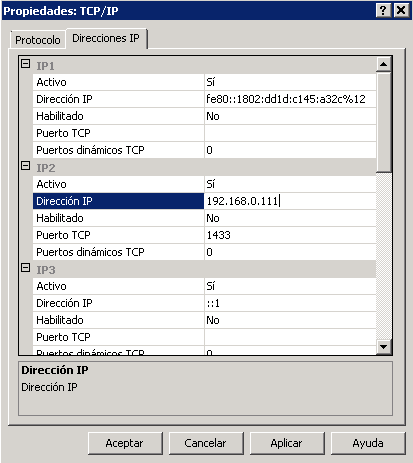
Espero que sirva de ayuda!
Sos Grande Amigo Gracias por
Sos Grande Amigo Gracias por tu aporte. Mi problema era una conexion que se desconectaba, pero desde otro segmento de la red. En el local si funcionaba, el remoto por vpn NO, me ayudo mucho tu aporte para revisar...
- Log in to post comments
Hola Emmanuel, me alegro que
Hola Emmanuel, me alegro que te haya servido de ayuda!
Enlazo un post donde explico con más detalle cómo configurar el server SQL para permitir conexiones remotas
- Log in to post comments
Saltarse las constraints en SQL Server
Saltarse las constraints en SQL Server Anonimo (not verified) 8 September, 2009 - 18:13Tengo que hacer una carga masiva de datos en muchas tablas de SQL Server que tienen definidas bastantes constraints, sobretodo claves foráneas (FK) entre tablas.
He intentado seguir un orden para cargarlas para que no me devuelva errores de restricciones de integridad, pero son tantas que no consigo encontrar el orden correcto.
Estoy pensando ya en eliminar las FK de todas las tablas, pero seguro que hay alguna manera mejor de solucionarlo.
Alguien me puede ayudar?
Las constraints de una tabla
Las constraints de una tabla de SQL Server se pueden desactivar temporalmente con la opción NOCHECK CONSTRAINT ALL de ALTER TABLE.
El comando quedaría así:
ALTER TABLE tabla NOCHECK CONSTRAINT ALL;
Con esto se desactivan y puedes hacer la carga de datos sin que te molesten las FK
Después, para volver a activarlas sólo tienes que hacer este otro ALTER TABLE:
ALTER TABLE tabla WITH CHECK CHECK CONSTRAINT ALL;
Reactiva las constraints chequeando que los datos de las tablas las cumplan
Si quieres volver a habilitarlas sin validar los datos que hayas cargado, aunque no es muy recomendable también se puede hacer:
ALTER TABLE tabla CHECK CONSTRAINT ALL;
Espero que te sea de ayuda,
- Log in to post comments
¿Y no habrá ningun tipo de
¿Y no habrá ningun tipo de problema en cuanto los datos/registros que hayas modificado una vez vuelvas a activar las CONSTRAINTS?
Por ejemplo si yo cambio el valor de un campo, el cual lo esta cogiendo de una primary key de otra tabla, al volver a a activar las CONSTRAINTS, ¿No habrá conflictos?
- Log in to post comments
Justamente al desactivar los
Justamente al desactivar los constraints pierdes la garantía de que los datos respetan el modelo relacional, y entonces la responsabilidad es tuya con las modificaciones que hagas, que una vez terminadas han de seguir manteniendo la integridad referencial del modelo, o al menos de los constraints que haya definidos.
Es decir, que tendrás conflictos al reactivarlos sólo si no respetas las reglas que definen los constraints.
- Log in to post comments
Utilización del monitor del sistema para supervisar recursos
Utilización del monitor del sistema para supervisar recursos Carlos 21 July, 2010 - 00:53En el tema de Scripts y consultas útiles de Oracle Fernando pregunta cómo consultar con una query los cursores abiertos en la base de datos.
No sé si se puede hacer directamente con una consulta, como en Oracle, pero como mínimo se puede utilizar la utilidad Monitor del sistema para controlar temas de rendimiento, y consultar indicadores y medidas de rendimiento sobre cursores y otros objetos de la base de datos y del sistema.
Para abrir la aplicación hay que ejecutar en el Windows donde esté instalada la instancia de SQL Server, desde el menú inicio o desde linea de comandos el programa perfmon.
Enlazo la ayuda en linea de Microsoft TechNet donde se hace referencia a los objetos de SQL Server que se pueden monitorizar, y también a la parte que concreta los indicadores del objeto Cursor Manager by Type, cuyo primer contador es el número de cursores activos.
Si alguien conoce una manera diferente o más sencilla de monitorizar los cursores de la base de datos le agradeceremos que lo comparta :)
Hola Carlos Estoy un poco
Hola Carlos
Estoy un poco desesperado, no lo encuentro por ninguna parte, sabrías alguna query para sacar los cursores abiertos, pero en SQL Server??
muchas gracias por tu ayuda.
- Log in to post comments
Información, tips y utilidades sobre SQL Server Integration Services (SSIS)
Información, tips y utilidades sobre SQL Server Integration Services (SSIS) Dataprix 26 April, 2022 - 12:45
Recopilación de dudas técnicas, consultas, tips y opiniones de SQL Server Analysis Services, motor de datos analíticos de Microsoft SQL Server.Recopilación de dudas técnicas, consultas, tips y opiniones de SQL Server Integration Services, la herramienta ETL de Integración de datos de Microsoft SQL Server.
Cambio del proyecto de modo implementación de paquetes a implementación de proyectos
Cambio del proyecto de modo implementación de paquetes a implementación de proyectos Carlos 27 December, 2016 - 20:46Para cambiar el modo de implementación de paquetes a proyectos, y poder desplegar el proyecto en el catálogo IS de SQL Server se puede utilizar el asistente que se inicia fácilmente con un clic en el botón derecho sobre el proyecto, en el explorador de soluciones, y seleccionando la opción 'Convertir al modelo de implementación de proyectos'.
Es todo muy intuitivo menos, al menos para mi, el paso de seleccionar las configuraciones que se han de convertir. En mi caso utilizaba configuraciones para alimentar variables con valores almacenados en la tabla SSIS Configurations de SQL Server, y los paquetes que utilizaban estas configuraciones me salían con un estado 'No se puedo conectar con el servidor', error de inicio de sesión..
Este problema se soluciona con la opción 'Agregar configuraciones..', que permite volver a introducir los datos de conexión y 'leer' las configuraciones de la tabla SSIS Configurations. Se agrega una nueva configuración con el asistente para cada una de las que está en estado 'No se pudo conectar..' y después se seleccionan sólo las nuevas, que ya han de mostrar un estado 'Aceptar'.
Con esta acción se consigue pasar la validación, y el asistente ya puede realizar la conversión de los paquetes a modo proyecto, aunque el asistente en realidad no habilita la configuración en los paquetes, y si es necesario que las variables del package sigan recogiendo sus valores de los que se guardan en la tabla [SSIS Configurations] de la base de datos SQL Server, hay que habilitar después en cada paquete la configuración de paquetes, y agregar de nuevo las definiciones de configuraciones que se estaban utilizando en el modo de implementación de paquetes.
Como a partir de SSIS 2012 la tendencia es utilizar parámetros y variables de entorno en las implementaciones de proyecto, la opción de seguir utilizando configuraciones de paquetes en 'modo proyecto' está un poco escondida, pero se puede utilizar y funciona.
Para habilitar la configuración de paquetes a partir de SSIS 2012 hay que situarse en la pestaña de 'Flujo de control' y acceder a las propiedades haciendo click en la pantalla de fondo, o seleccionar propiedades después de hacer clic con el botón derecho. En la sección 'Varios' de propiedades del flujo del paquete la propiedad 'configurations' permite acceder al asistente para habilitar y crear configuraciones de paquetes. Después de habilitarlo, al crear una nueva configuración, si ya existía una configuración en la tabla [SSIS Configurations], el asistente lo detecta y permite reutilizarla.
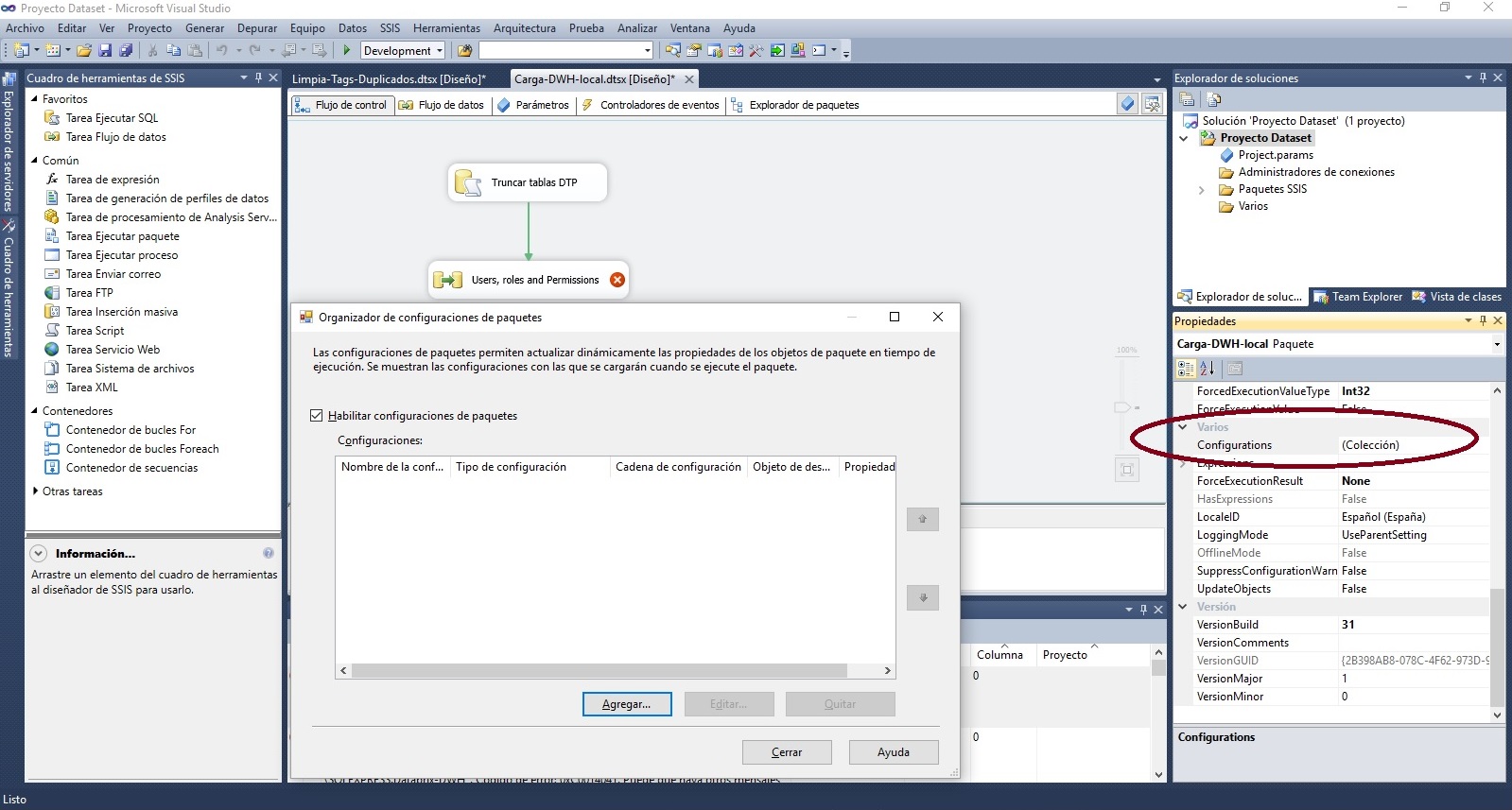
También habrá que revisar las variables del paquete, y cambiar la expresión que haya generado el asistente de conversión, que será algo así como '$Package::variable' por la variable de usuario, en este caso sería 'User::variable', y eliminar también los parámetros que el asistente genera, y que ya no se utilizarán porque se han cambiado por las variables de usuario que se alimentan ahora desde la tabla de configuración de SQL Server, [SSIS Configurations].
Carga masiva de ficheros
Carga masiva de ficheros roberto 22 May, 2009 - 13:39Buenas,
tengo un problema con SSIS, estoy intentando hacer una carga sobre una tabla desde varios ficheros que tengo en un directorio pero me veo obligado a crear un origen de datos para cada fichero. El problema añadido es que los ficheros cambian de nombre segun la fecha, asi que el proceso no me sirve para posteriores cargas.
¿Hay alguna manera de definir un origen de datos que cargue todo el contenido de un directorio, o algun tipo de script que haga un union de los ficheros?
Gracias,
Roberto
Hola Roberto, a mi me paso lo
Hola Roberto,
a mi me paso lo mismo hace unas semanas, intentando hacer una carga en la que se veian involucrados varios ficheros con el mismo formato pero diferente nombre. Es algo habitual que recibas ficheros diariamente y que el sistema tenga que cargarlos sin tener que especificarle el nombre de fichero exacto.
Ya que no especificas la version, te digo lo que sé de la que yo estoy usando, SQLServer 2008.
En esta version me encontre con que el origen de tipo fichero plano te obliga a crear una conexion a fichero especificando el nombre exacto. Para hacer lo que quieres, previamente tienes que ir al panel Connection Managers (debajo del area de diseño) y crear una conexion a multiples ficheros. La conexion a multiples ficheros no esta disponible por defecto en el menu contextual, asi que tendras que ir por New Connection... y ahi te saldra una lista con todas las conexiones que acepta SSIS, seleccionas MULTIPLEFLATFILE y en el dialogo de configuracion si que te deja elegir directorio y multiples ficheros mediante mascara. Una vez hayas creado la conexion a multiples ficheros, añades el origen de datos a fichero plano en el diseñador y en vez de crear la conexion a un fichero con nombre exacto veras que tienes la conexion a multiples ficheros en la lista desplegable. La seleccionas, haces los mapeos y ya esta!
Espero que te haya servido.
- Log in to post comments
Consultas y comandos para controlar ejecuciones de packages del catálogo de SSIS
Consultas y comandos para controlar ejecuciones de packages del catálogo de SSIS Carlos 26 October, 2016 - 19:53 Consultar las ejecuciones del catálogo de SSIS activas, y parar una ejecución
Consultar las ejecuciones del catálogo de SSIS activas, y parar una ejecución
Después de conectar a la base de datos del catálogo, para comprobar las ejecuciones que hay activas actualmente se puede ejecutar la siguiente query:
select * from catalog.executions where start_time is not null and end_time is null
En los resultados de esta consulta, el primer campo que podremos ver es el execution_id, que es el id de la ejecución del proceso, el mismo que podremos ver desde el entorno gráfico si consultamos las operaciones activas haciendo click con el botón derecho sobre la base de datos del catálogo, y seleccionamos la opción 'Operaciones activas'.
Desde el mismo entorno gráfico se puede utilizar el botón 'Detener' para parar una ejecución, aunque también se puede hacer con un comando de consulta utilizando el execution_id que ha salido en la consulta anterior (si, por ejemplo el id fuera 12345):
Exec catalog.stop_operation @operation_id = 12345
Consultar los mensajes de ejecuciones de paquetes del catálogo de SSIS
Query para consultar los mensajes de las ejecuciones de los paquetes (en este caso de la última ejecución realizada):
SELECT event_message_id,MESSAGE,package_name,event_name,message_source_name,package_path,execution_path,message_type,message_source_type
FROM (
SELECT em.*
FROM SSISDB.catalog.event_messages em
WHERE
em.operation_id = (SELECT MAX(execution_id) FROM SSISDB.catalog.executions)
AND event_name NOT LIKE '%Validate%'
)q
--WHERE --event_name = 'OnPostExecute' and
-- message like '%Finalizado%'and
-- package_name = 'Package.dtsx'
-- execution_path LIKE '%<ejecutable>%'
ORDER BY message_time DESCCómo utilizar Google Sheets como origen o destino de SSIS
Cómo utilizar Google Sheets como origen o destino de SSIS Carlos 4 September, 2019 - 09:10 Se puede hacer descargando la API de Google, y creando un script para leer y escribir en una hoja de cálculo de Google Docs.
Se puede hacer descargando la API de Google, y creando un script para leer y escribir en una hoja de cálculo de Google Docs.
Enlazo los dos sitios que he encontrado sobre cómo hacerlo:
https://www.statslice.com/leveraging-google-docs-with-ssis
https://sqldeveloperramblings.blogspot.com.es/2010/06/ssis-google-spreadsheets-data-source.html
Otra opción más sencilla, pero de pago sería utilizar el componente que ha desarrollado cdata:
https://www.cdata.com/drivers/gsheets/ssis/
Error de SSIS al conectar con Excel ejecutando desde el catálogo
Error de SSIS al conectar con Excel ejecutando desde el catálogo Carlos 12 March, 2020 - 21:20Al utilizar Excel como origen de datos en SSIS suele pasar que nuestro sistema es de 64 bits, y el conector de Excel que funciona aún es de 32 bits.
Desde Visual Studio en nuestra máquina cliente se suele solucionar marcando en las propiedades del proyecto que la ejecución se fuerce en 32 bits en lugar de 64, pero después puede pasar que despleguemos el paquete en un servidor SQL Server, y el conector no funcione.
Aunque lo ejecutemos igualmente en 32 bits, marcando en las propiedades avanzadas de la ejecución del paquete el check de '32-bit runtime', (o haciendo lo mismo en un job que lance el paquete si no queremos tener que marcar el check en cada ejecución), si el server no tiene el driver de 32 bits, que se suele instalar con las office, y en la máquina cliente sí solemos tener, el resultado suele ser un fallo en la ejecución.
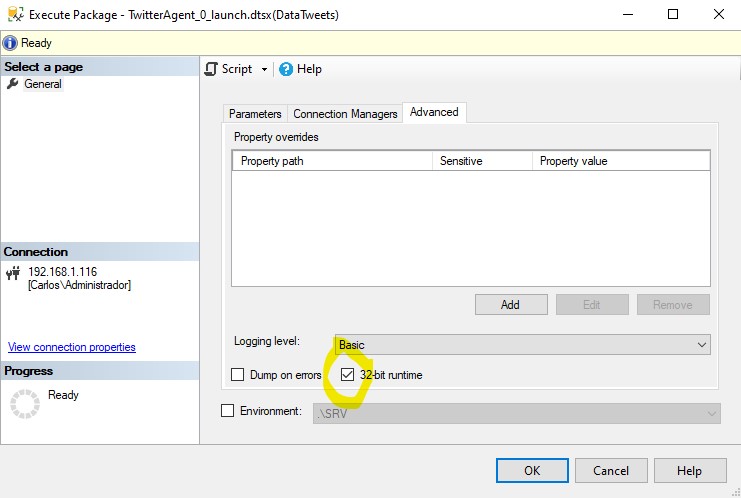
Este es el error que registra el catálogo:
Error: El proveedor OLE DB Microsoft.Jet.OLEDB.4.0 solicitado no está registrado. Si el controlador de 64 bits no está instalado, ejecute el paquete en modo de 32 bits
Si hemos hecho que paquete se ejecute en modo de 32 bits y a pesar de ello falla, entonces lo que tiene que faltar es el driver, así que normalmente la solución es tan sencilla como descargar de esta dirección de la página de descargas de Microsoft el componente redistribuible de 32 bits del motor de access y ejecutarlo en el servidor.
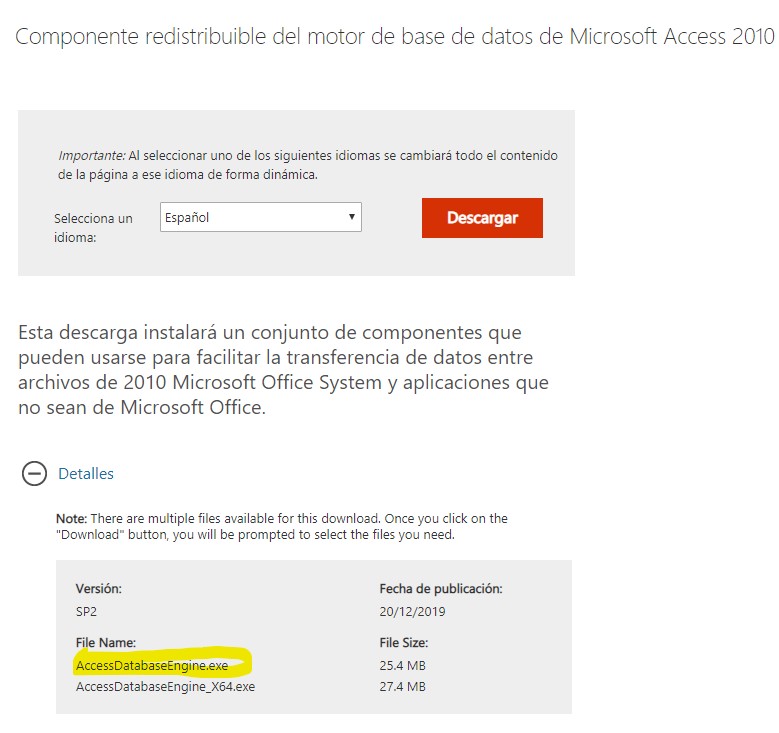
La otra solución es esperar a que Microsoft se decida a sacar un conector de 64 bits que funcione con Excel y Office, que este tema ya huele.. ;)
Introduccion a la metodologia SQLBI
Introduccion a la metodologia SQLBI Dataprix 2 October, 2008 - 00:26En SQLBI han preparado el primer borrador de un documento que propone una metodología para implementar soluciones de BI con las herramientas de la suite de Business Intelligence de Microsoft.
Aunque la metodología se enfoca hacia estas herramientas, los conceptos son extensibles a cualquier proyecto de BI. Esta es la traducción de los títulos principales del índice:
Introducción
Arquitectura de una solución de BI
Clasificación de soluciones de BI
Actores
Usuario / Cliente
Analista BI
Microsoft BI Suite
Arquitectura
Componentes de una solución de BI
La metodología de Kimball
Cuándo y porqué utilizar la metodología Kimball
La metodología Inmon
Cuándo y porqué utilizar la metodología Inmon
Construyendo la arquitectura
Diseñando los datos relacionales
Adjunto esta primera versión del documento, y espero que dentro de poco pueda actualizar el post con otra versión con nuevos capítulos..
Una vez publicada la
Una vez publicada la metodología, Alberto Ferrari y Marco Russo nos obsequian con el manual SQLBI Methodology at work, una aplicación práctica de la misma utilizando como base recursos que proporciona Microsoft para probar las funcionalidades BI de SQLServer:
- El package AWDataWarehouseRefresh
- Adventure Works DW
Los autores muestran como reconstruir la solución BI de Microsoft aplicando su propia metodología para obtener para obtener así otra versión de esta solución. No se atreven a decir que mejor que la original, eso tendremos que juzgarlo los que la probemos..
Traduzco a continuación el índice del documento:
Introducción
La imagen completa
El proceso de análisis
Análisis del paquete de ETL
Análisis de las vistas de orígenes de datos de SSAS
Utilización de esquemas
Base de datos del Data Warehouse
Área de análisis Financiera
Área de análisis Común
Área de análisis de Producción
Área de análisis de Ventas
Utilidad del Nivel del Data Warehouse
Base de datos espejo OLTP
Carga del espejo OLTP
Vistas del espejo OLTP
Base de datos de configuración
Configuración del Area de análisis de Ventas
Ficheros CSV transformados en tablas
Fase de ETL del Data Warehouse
Prestar atención a los planes compilados para las vistas
Valores Actuales/Históricos
Tipos de datos XML
Vistas de Data Mart
Fase de ETL de los Data Mart
Tratamiento de las Claves Subrogadas
Tratamiento de Valores Ficticios
Implementación de los cubos
Vista de Origen de Datos
Canal de Ventas
Promociones
Documentación del proyecto
- Log in to post comments
Ayuda - Jobs - SSIS -
Ayuda - Jobs - SSIS - jatb 17 July, 2013 - 17:41Hola con todos,
Tengo el siguiente caso:
Mi carga de datos esta hecha en DTS 2000 y estamos en la migracion a SSIS, con el programa DTS Backup 2000 los migre a SSIS hasta aquí todo perfecto.
Cree las tareas dentro del paquete de SSIS lo ejecuto manualmente el resultado es ok.
El paquete lo guardo Package Collection SQL Server, pongo el servidor en la opcion de Proetction Level Do not save sensitive data, voy al Management studio me conecto a Integratios Services y en la carpeta MSDB esta el paquete le doy click derecho run package y el estado de finalizacion es ok.
Cuando creo el job me da el siguiente error al momento de ejecutar:
Porque se pierde la conexión al momento de crear el JOB, cuál puede ser una posible solución ?
Error: 2013-07-17 10:12:12.01 Code: 0xC0202009 Source: XXXX Connection manager "XXX" Description: SSIS Error Code DTS_E_OLEDBERROR. An OLE DB error has occurred. Error code: 0x80004005. An OLE DB record is available. Source: "Microsoft OLE DB Provider for ODBC Drivers" Hresult: 0x80004005 Description: "[Microsoft][ODBC Driver Manager] Data source name not found and no default driver specified". End Error Error: 2013-07-17 10:12:12.01 Code: 0xC020801C Source: Data Flow Task OLE DB Source [1] Description: SSIS Error Code DTS_E_CANNOTACQUIRECONNECTIONFROMCONNECTIONMANAGER. The AcquireConnection method call to the connection manager "XX" failed with error code 0xC0202009. There may be error messages posted before this with more information on why the AcquireConnection method call failed. End Error Error: 2013-07-17 10:12:12.01 Code: 0xC0047017 Source: Data Flow Task SSIS.Pipeline Description: component "OLE DB Source" (1) failed validation and returned error code 0xC020801C. End Error Error: 2013-07-17 10:12:12.01 Code: 0xC004700C Source: Data Flow Task SSIS.Pipeline Description: One or more component failed validation. End Error Error: 2013-07-17 10:12:12.01 Code: 0xC0024107 Source: Data Flow Task Description: There were errors during task validation. End Error DTExec: The package execution returned DTSER_FAILURE (1). Started: 10:12:11 AM Finished: 10:12:12 AM Elapsed: 0.281 seconds. The package execution failed. The step failed.
La conexión que da el error es la migrada de DB2, realice el mismo ejercicio pero solo con la conexión a sql y el resultado es ok.
Ahora al crear un new datasource , provider Native OLD BE\Micro... for DB2.
Existen algunos campos Initial Catalog, package collection y defautl schema, que debe ir ahi como obtengo esa información?
En la pestaña Advance existe DBM2 plataform, Host CCSID y PC code page que es otra duda que tengo.
Hola Jatb. El problema es la
- Log in to post comments
Carga lenta Desde AS400
Carga lenta Desde AS400 jatb 9 March, 2013 - 00:55
Hola Jonathan Supongo que ya
Hola Jonathan
Supongo que ya habréis hecho pruebas, pero me parece una diferencia demasiado grande para venga sólo por el cambio de versión de DTS a SSIS. Yo antes que nada me aseguraría de que no hay algún factor más que os ralentiza esta carga, como saturación de las bases de datos, espacio, bloqueos..
De la parte de SSIS tampoco tengo gran experiencia, pero yo revisaría sobretodo los parámetros de carga, asegurándome de que estuvieran orientados a cargas masivas, sin validaciones ni transformaciones, y utilizando el máximo de memoria posible. Según cómo lo hagas suele ser la opción 'Fast Load', y revisar las opciones 'FastLoadOptions'.
Te enlazo el post Using SQL Server Integration Services to Bulk Load Data, que comenta bastante detalladamente tres métodos de carga que podrías probar. Si has utilizado OLE DB, por ejemplo, si la revisión de parámetros no te funciona, puedes probar con el componente SQL Server Destination, que según el artículo permite definir propiedades como BATCHSIZE=0 para realizar toda la carga en un solo batch.
You might have noticed that the Advanced screen does not include any options related to batch sizes. SSIS handles batch sizes differently from other batch-loading options. By default, SSIS creates one batch per pipeline buffer and commits that batch when it flushes the buffer. You can override this behavior by modifying the Maximum Insert Commit Size property in the SQL Server Destination advanced editor. You access the editor by right-clicking the component and then clicking Show Advanced Editor. On the Component Properties tab, modify the property with the desired setting:
- A setting of 0 means the entire batch is committed in one large batch. This is the same as the BULK INSERT option of BATCHSIZE = 0.
- A setting less than the buffer size but greater than 0 means that the rows are committed whenever the number is reached and also at the end of each buffer.
- A setting greater than the buffer size is ignored. (The only way to work with batch sizes larger than the current buffer size is to modify the buffer size itself, which is done in the data flow properties.)
Espero que te sea de ayuda,
- Log in to post comments
Gracias Carlos, Lei el
Gracias Carlos,
Lei el articulo que me has dicho, pero esto es mas orientado a archivos planos o conexiones entre bases sql, pero de as400 a sql server no sirve.
Te cuento un poco mas para hacer la conexion utilizo el proivder: IBM DB2 UDB for iSeries IBMDA400 OLE DB Provider, al hacer test me da ok, dentro del OLE DB Source utilizo esta conexion compartida y ingreso SQL command y pongo en preview y me muestra la data, esto le uno al OLE DB Destination utilizando la propieda fast load, mapeo los datos y previwe y todo ok.
Cuando mando ejecutar el contenderon me trae un promedio de 20000 por minuto que es un tiempo alto ya que en el DTS 2000 en 2 minutos ya trae los 7mil registros.
Para la tranfornmacion de datos e utilizado Multicast, Derived Column, entre otros pero la respuesta es igual de lenta.
Los epsacios en discos y lo relacionado con la bdd esta muy bien.
Espero alguien me ayude.
Saludos
- Log in to post comments
Bueno, te sirve toda la parte
Bueno, te sirve toda la parte de configuración de los componentes destino, OLE DB o SQL Server Destination. Si no has encontrado nada que ya no hayas probado ya es otra cosa.
Otra cosa que puedes hacer es separar la importación de datos de las transformaciones, es decir, hacer una carga directa desde OLE DB Source a OLE DB Destination, que puedes dejar en una tabla temporal de SQL Server. Después haces todas las transformaciones desde la tabla temporal hacia la definitiva, así separas entornos y seguro que lo tienes más fácil para localizar el 'cuello de botella'.
- Log in to post comments
La manera que solucione no
La manera que solucione no se si es la adecuada es con el uso de tablas vinculadas con access, con esto la respuesta fue la misma que trabajar con DTS del 2000.
Es sorprendente que una version 8 años mas a ctual sea 100% mas lenta la carga desde as400.
Saludos
- Log in to post comments
A mi me ha pasado varias
A mi me ha pasado varias veces que he intentado hacer algo utilizando los componentes de SSIS para que sea más fácil de mantener, y al final, por la manera en que Integration Services trata el flujo de datos, prácticamente registro a registro, para que la carga no se haga eterna he terminado por eliminar los componentes y hacer la mayor parte del 'trabajo' con llamadas a sentencias SQL.
De todas maneras para una simple importación de datos no tendrían que pasar estas cosas, es muy fuerte que te funcione mejor con tablas vinculadas con access, y espero que al menos el problema sea sólo al importar desde AS400, algún bug en el driver o algo así..
Muchas gracias por compartir la solución, y me alegro de que al menos hayas podido solventar el problema de lentitud, aunque haya sido 'tirando de Access' :)
- Log in to post comments
Conexiones Oracle en DTSx. Solución.
Conexiones Oracle en DTSx. Solución. josimac 2 August, 2012 - 16:36Un problema bastante común cuando realizamos un proyecto que tiene lectura y/o escritura desde una dts a un oracle, es que cuando se crea un job de ejecución se pierde el password de acceso a oracle.
Una solución a esto es editar las conexiones del paquete dentro del job y ponerle a mano el password. El problema es que cada vez que cambiamos la dts se tiene que hacer lo mismo.
La solución definitiva ha esto es crear una variable de tipo string en el paquete que contiene la cadena de conexión completa.
Dicha cadena sería:
"Data Source=;User ID=;Provider=OraOLEDB.Oracle.1;Persist Security Info=True;Password=;"
Una vez hecho esto, hay que entrar en la propiedades de la conexión en el "Connection Manager" (parte inferior de la dts) y añadir una expresión clicando con el ratón en la elipse.
Añadir una expresión de tipo "ConnectionString" y arrastar en el diálogo la varible que hemos rellenado antes.
Ya está. Saludos!
Licencias de SQL Server
Licencias de SQL Server stbanti 11 August, 2009 - 18:46Hola a todos
Me estoy planteando un proyecto empresarial que va tener como base tecnológica una base de datos, procesos de integración (ETL), y puede que alguna cosa de Business Intelligence.
De las opciones disponibles me gusta bastante SQL Server porque ya viene con SSIS y Analysis Services, y encuentro Integration Services muy manejable.
De cara a las licencias necesitaría un servidor de base de datos y 2 usuarios de acceso, que trabajarían desde clientes Windows. He buscado información sobre licencias para ir preparando mis previsiones, pero no sé si me aclaro bien. Lo que me ha parecido entender es que necesito una licencia para el server y dos para los clientes (CALs). Lo que pasa es que sólo he encontrado un precio para una SQLServer Standard Edition de unos 6.000 $ por procesador (para USA). Supongo que debe haber otro licenciamiento a nivel de usuario más económico, ya que yo sólo voy a necesitar que la utilicen 2 usuarios.
Alguien me puede decir donde encontrarlo, o cuánto me podría costar todo el montaje? Tampoco tengo claro como funcionan los upgrades o el coste de mantenimiento anual una vez adquirida la licencia inicial.
Gracias por anticipado,
sobre las licencias de SQL
sobre las licencias de SQL Server, te cuento que cuando compras compras la ultima version
en este momento seria SQL Server 2008 standart, sale alrededor de U$S 780 en argentina
necesitarias tambein 2 cal por usuario que salen U$S168 cada una, con esto te bastaria
para lo que necesitas. El modo de licenciamiento de microsoft no es anual, por lo que al comprar la
licencia no necesitarias pagar nada mas, los upgrade de version te salen casi como comprar
la version nueva, pero los service pack son sin costo.
saludos
- Log in to post comments
Necesito Agregar Componentes de Auditar/MAIL en Proceso de ETL
Necesito Agregar Componentes de Auditar/MAIL en Proceso de ETL alfonsocutro 18 January, 2014 - 18:18Buenas esta vez, necesito una ayuda bastante basica, pero como soy novato en el mundo SQLServer todo medio complejo.
Estoy haciendo un Proyecto BI relacionado con un Banco y donde estoy en la etapa de ETL (inicial) c/SISS de AS/400 a SQLServer 2012
Resulta que traigo todas las tablas de intervinientes del Ambiente de AS/400 a SQLServer.
Hasta ahora marcha todo bien, pero estoy necesitando tener todo auditado (hora de inicio, hora de fin, etc) y ademas quiero que dispare algún mail (caso de tener algún inconveniente que envie un mail a los responsables del proceso de ETL).
Bueno era eso no mas. Disculpen
Para la auditoría, si te
Para la auditoría, si te creas un flujo de datos, dentro de las transformaciones de flujo de datos que puedes utilizar,
en el cuadro de herramientas, tienes la transformación que se llama 'Auditoría', que supongo que es la que comentas, y que puedes utilizar para añadir al flujo de datos campos de información como hora de ejecución, nombre del usuario, del equipo, de la tarea.. Luego guardas lo que te interese en un campo de la tabla destino y ya lo tienes.
Otra opción es utilizar la transformación 'Columna derivada' y añadir en la misma un campo que calcule lo que
quieras registrar, como por ejemplo la función 'GETDATE()' para calcular la fecha y hora actual.
Para enviar un email si el proceso va bien o mal, entre los elementos del flujo de control hay una tarea 'Tarea enviar correo',
pero es demasiado simple, y sólo te funcionará en determinadas condiciones. Yo cuando lo implementé al final utilicé una
'Tarea script' que ejecutaba un código de visual basic (.vb) para hacer el envío de un email utilizando el objeto 'SmtpClient'.
Esta tarea se puede ejecutar al final del flujo de control para el caso de que todo vaya bien, y también puedes llamar
a la misma tarea, o a otra del mismo tipo, una vez creada, desde el evento OnError del controlador de eventos (pestaña 'Controladores de eventos').
Espero haberte aclarado algo..
- Log in to post comments

muchisimas Gracias
muchisimas Gracias CARLOS!!!!
Vamos a ver como continua este Proceso de ETL.
Estamos en contacto.
- Log in to post comments
Carlos: Ya logre mejorar un
Carlos:
Ya logre mejorar un 80 % del Proyecto -->(Paquete SISS)
Colocando en comienzo y en al fin del Flujo de Datos la función "GETDATE()" para calcular las respectivas fechas.
Las mismas se almacenan en una Tabla donde esta toda esa data.
Me estaría faltando rescatar esos datos para mandarlos por el Conector de manda MAIL.
Seguramente hay muchas formas de hacer este Proceso, asi que escucho Mejoras!!!!!
Saludos y Muchas Gracias Carlos (x ayudarme nueva//)
Saludos!!!!
- Log in to post comments
Problema al ejecutar un paquete SSIS desde un proyecto del catálogo de Integration Services de SQLServer
Problema al ejecutar un paquete SSIS desde un proyecto del catálogo de Integration Services de SQLServer Carlos 16 June, 2016 - 13:08 Recientemente he llevado a cabo una migración de un proyecto de SSIS 2008 a SSIS 2010 fruto de una migración de un servidor SQL Server 2008 R2 a un SQL Server 2012.
Recientemente he llevado a cabo una migración de un proyecto de SSIS 2008 a SSIS 2010 fruto de una migración de un servidor SQL Server 2008 R2 a un SQL Server 2012.
En primera instancia, tras el proceso de migración y hacer algunos ajustes, todo funcionó correctamente, y todos los paquetes se ejecutaban sin problemas, tanto desde el entorno IDE de Integracion Services, SQL Server Data Tools, como si se programaba su ejecución desde el agente de SQL Server.
Para aprovechar las nuevas características de SQL Server 2012, el siguiente paso fue la conversión de las conexiones de cada paquete a conexiones globales, y cargar el proyecto y los paquetes dentro del catálogo de Integration Services de la nueva base de datos, y configurar un entorno de producción y otro de desarrollo dentro del mismo catálogo para poder así lanzar los mismos procesos en uno u otro entorno de una manera flexible y bien controlada, un gran avance de esta versión de SSIS.
Todo bien menos un problema que surge al programar la ejecución de los paquetes del catálogo desde el agente de SQL Server. La ejecución de los paquetes se lanza correctamente, pero uno de ellos siempre produce una excepción devolviendo un error de memoria. No es problema de la llamada desde el agente porque este paquete en realidad se llama desde otro paquete, que es el que ejecuta el job del agente, y los otros packages a los que llama se ejecutan sin problemas.
Lo más extraño es que este error sólo se produce en la ejecución desde el catálogo de IS de la base de datos, pero si se ejecuta el mismo paquete desde SQL Server Data Tools, tanto directamente como llamándolo desde el otro package, el paquete se ejecuta con normalidad, no devuelve ningún error, y hace todo lo que tiene que hacer.
Es verdad que este package es uno de los que maneja mayor volumen de datos, y por eso en algún punto debe tener algún problema de memoria que lo hace fallar al ejecutarlo desde el catálogo, pero debería funcionar igual desde ambos entornos, no?
¿Alguien se ha encontrado algún problema parecido? ¿Puede ser algún problema de configuración de la base de datos o del entorno de ejecución?
El error de overflow de
El error de overflow de memoria se puede solucionar configurando los componentes para utilizar buffers de memoria en lugar de utilizar la opción por defecto que no los utiliza, y para más seguridad se puede definir un fichero donde almacenar la caché si la memoria llega a su límite, pero lo raro sigue siendo que con SQL Server 2008 no hubiera ningún problema, y con SQL Server 2012 surjan estos problemas con la gestión de la memoria.
Además me he encontrado otro cliente al que le ha pasado lo mismo al pasar de 2008 a 2012. ¿Alguien sabe si es un problema de la versión, o si no es un problema sino que la gestión de memoria se ha de llevar de otra manera?
¿A alguien le ha pasado lo mismo con SQL Server 2014 o 2016?
- Log in to post comments
Problema con los parámetros de un origen de flujo de datos OLEDB
Problema con los parámetros de un origen de flujo de datos OLEDB Carlos 5 May, 2014 - 23:24
Estoy preparando una carga de un Data Warehouse con Integration Services de un SQL Server 2008, y me he encontrado un problema con los parámetros de un origen de flujo de datos OLEDB de SSIS que no he podido resolver, yo le veo pinta de bug, pero lo planteo aquí por si alguien también se lo ha encontrado y me puede iluminar.
En una tarea de flujo de datos, tengo el origen de flujo de datos de OLEDB definido con una select que incluye un parámetro, que es el valor de una variable FechaActual de tipo DateTime, y que en el proceso de carga contiene la fecha actual.
La tabla sobre la que se ejecuta la consulta contiene registros con fechas hasta el día actual, y la sentencia select del origen es la siguiente:
select * from ax_almacenlote where DATEDIFF(day,max_createddatetime,?)=0 or DATEDIFF(day,max_modifieddatetime,?)=0
El resultado esperado serían los registros de esta tabla con fecha de creación o modificación a día de hoy (FechaActual), pero, aunque he comprobado que los registros existen, el flujo de datos no devuelve ningún registro.
Lo más curioso es que después de hacer un montón de pruebas me doy cuenta de que si le añado 2 días a la comparación de fechas obtengo el resultado que esperaba, es decir, los registros creados o modificados en el día actual. Esta sería la Select que me saca estos registros:
select * from ax_almacenlote where DATEDIFF(day,max_createddatetime,?)<3 or DATEDIFF(day,max_modifieddatetime,?)<3
Curioso no? Alguien me puede explicar porqué hay que añadir 2 días para que funcione esta comparación de fechas? Yo no le encuentro la lógica.
Para asegurarme de que no es un tema de la base de datos, o de la consulta, he capturado las queries que se generan en SQL Server, y los resultados siguen indicando que el problema está en la parte de Integration Services. Estas son las queries de cada caso:
Primero, esta es la consulta de base de datos que he intentado parametrizar y que, poniénle la fecha actual donde va el parámetro de SSIS devuelve correctamente los registros creados o modificados en el día actual, a la consulta o a los datos no se les puede echar la culpa:
select * from ax_almacenlote where DATEDIFF(day,max_createddatetime,getdate())=0 or DATEDIFF(day,max_modifieddatetime,getdate())=0
Después, al ejecutar el proceso con la consulta inicial en el origen OLEDB, la que no devuelve nada, la base de datos muestra esta select:
select * from ax_almacenlote where DATEDIFF(day,max_createddatetime,@P1)=0 or DATEDIFF(day,max_modifieddatetime,@P2)=0
Finalmente, al añadir los dos días a la comparación para que el flujo retorne los datos del día actual, esta es la sentencia SQL que muestra la base de datos como ejecutada:
select * from ax_almacenlote where DATEDIFF(day,max_createddatetime,@P1)<3 or DATEDIFF(day,max_modifieddatetime,@P2)<3
Si alguien lo entiene le agradezco que me lo explique porque yo no le veo ningún sentido.
Puede ser porque el formato
Puede ser porque el formato de fecha que está enviando a la select está girada porque la envia en formato texto.
Por ejemplo:
En mi caso, si hago un "select getdate()" me devuelve: "09/05/14 18:13:23"
Acto seguido, ejecuto la select tuya con lo que me devuelve el getdate():
select * from entidades where DATEDIFF(day,comodin10,'09/05/14 18:13:23')=0
El resultadoes un frustrante "0 Rows"
Pero si giras el mes y el año devuelve los registros que tiene que devolver:
select * from entidades where DATEDIFF(day,comodin10,'05/09/14 18:13:23')=0
Resultado "698 Rows"
- Log in to post comments
Vale, seguro que los tiros
Vale, seguro que los tiros van por ahí, pero a mi la select ejecutada directamente contra la base de datos me devuelve los registros que espero, la select ya está bien para el formato de fecha que utiliza la base de datos.
¿Puede ser que SSIS o el driver de OLEDB cambien el formato de la fecha?
- Log in to post comments
Podría ser. Para asegurarte
Podría ser. Para asegurarte de que el formato de fecha es el que esperas puedes probar a especificarlo, en la base de datos, o mejor en el componente, antes de la select. Algo así:
set dateformat dmy; declare @fecha datetime set @fecha = getdate() select * from Mitabla where DATEDIFF(day,CampoDeFecha,@fecha)=0
- Log in to post comments
Problema en el exceso de caracteres en la expresion de flujo de datos
Problema en el exceso de caracteres en la expresion de flujo de datos Anonimo (not verified) 11 December, 2009 - 21:45Tengo un mega Query que necesito poner en la expresion de flujo de datos, pero pasa el limite de 4000 caracteres ya intente de 1000 usando variables. que se podria hacer??
Seguro que una query tan
Seguro que una query tan grande no la puedes partir, aunque sea utilizando tablas temporales intermedias? Así también tendrías más controlado lo que haces, porque normalmente meter mano y mantener consultas de estas proporciones suele ser complicado.
Otra opción sería utilizar un fichero para almacenar la query. No lo he probado, pero el SQLSourceType te permite seleccionarlo con el tipo File connection.
También, según lo que tengas que hacer, podr&ias crear un procedimiento almacenado en la base de datos, meter dentro la consulta, y llamar al procedure desde SSIS.
- Log in to post comments
Utilizar SSIS o DTS para trabajar con BBDD Oracle
Utilizar SSIS o DTS para trabajar con BBDD Oracle Carlos 1 August, 2010 - 11:24Abro este tema para comentar cuestiones sobre conexiones de DTS o SQL Server Integration Services que utilicen como origen de datos una base de datos Oracle para recoger datos, ejecutar procesos, etc.
Sabes tengo rutinas en
Sabes tengo rutinas en SQLServer 2005 DTS que levantan bastos, pero necesito automatizar la ejecución.
Ya que actualmente se ejecuta cuando nos llega un correo de confirmacion donde otras rutinas han terminado.
La ejecución es manual,manualmente ejecuto el dts
Soy nueva en Oracle.
Por fa como podria automatizarlo?
- Log in to post comments
Tendrás que explicármelo
Tendrás que explicármelo mejor. Por lo que he entendido lanzas manualmente procesos de DTS que atacan una BD Oracle, y quieres que se ejecuten automáticamente cuando llegue un mail.
Eso deberías hacerlo desde el mismo DTS, no?
- Log in to post comments
Es justo lo que quisiera
Es justo lo que quisiera saber, como puedo hacer para que un DTS se ejecute cuando llegue un correo o cuando una tabla en BD Oracle esté actualizado a la fecha del día.
- Log in to post comments
No sé mucho de DTS, pero se
No sé mucho de DTS, pero se me ocurre que podrías Planificar el package DTS para ejecución para que se lanzara cada cierto tiempo, y dentro de tu package agregar una tarea que consultara el valor de la tabla de Oracle, y ejecutara las tareas que ya tienes preparadas sólo si se cumpliera la condición de la expresión que tendrías que definir en función de la fecha.
Supongo que debe haber otras soluciones más elegantes con manejadores de eventos y similares, pero esta seguro que te funciona sin complicarte mucho.
- Log in to post comments
Información, tips y utilidades sobre SQL Server Analysis Services (SSAS)
Información, tips y utilidades sobre SQL Server Analysis Services (SSAS) Dataprix 28 April, 2022 - 19:28
Recopilación de dudas técnicas, consultas, tips y opiniones de SQL Server Analysis Services, motor de datos analíticos de Microsoft SQL Server.
SSAS proporciona funcionalidades de modelo de datos semánticos para aplicaciones de business intelligence, análisis de datos e informes, como Power BI, Excel, Reporting Services y otras herramientas de visualización de datos.
Analysis Services
Analysis Services Anonimo (not verified) 15 April, 2010 - 02:27Buenas tades, actualmente trabajo con analysys services instalado en un servidor windows 2003, pero necesito instalar analysis services en una computadora con windows XP y desde esta misma computadora ejecutar excel y conectarme a los cubos, hasta el momento no lo he logrado, esto es posible?
El mensaje de error es:
No se puede conectar con el origen de datos. Razon: no se puede encontrar el servidor de la base de datos. Compruebe si el nombre de la base de datos que escribió es correcto o póngase en contacto con el administrador de la misma para obtener ayuda.
Saludos
Si, eso es posible.Que
Si, eso es posible.Que versión de Excel usas? Que versión de SSAS?
Es posible que no hayas seleccionado el servidor de SSAS?
Es posible que no hayas seleccionado conexion a SSAS al momento de hacer la conexión en Excel y hayas puesto conexion a SQL?
- Log in to post comments
Analysis Services no abre los roles
Analysis Services no abre los roles Boreal 24 May, 2010 - 03:15Buenas tardes:
Tengo un servidor con windows server 2000, el cual se ocupa para conectarse a un as400 sacar información y mostrarla a los usuarios por medio de excel (cubos), este server perntecene a un dominio denominado domain.
Ahora se acaba de crear un dominio diferente denominado cmex, entonces deseo cambiar al server de domain a cmex y en la sección de analysis services agregar el rol de cmex/Administrator, pero cuando lo cambie de dominio y accese con el user administrator de dominio cmex (superusuario), al inicia me manda el siguiente error:
ID. de suceso: 26
Origen: Cuadro emergente de aplicación
Descripción: Aplicación emergente: Administrador de control de servicios: error al menos un servicio o controlador durante el inicio del sistema. Utilice el Visor de sucesos para examinar los detalles en el registro de sucesos.
y todos mis servicios de sql están arriba, pero cuando abro el analisis services para agregar el rol no abre absolutamente nada.
Les agradecería si alguien supiera acerca de este issue ya que es un server de producción.
Nuevamente mil gracias y Saludos!
Hola, En principio parece un
Hola,
En principio parece un problema con el servicio y la cuenta de inicio, que debes cambiar a una del nuevo dominio.
Utiliza SQL Server Configuration Manager y desde allí revisa las cuentas con las que está iniciandose el servicio, y cambialas por cuentas del nuevo dominio.
Aquí tienes un link con información de las configuraciones recomendadas para las cuentas de SQL Server
http://technet.microsoft.com/en-us/library/ms143504.aspx
y en él aparecen otra serie de links donde puedes ver más detalles aún.
Ya nos cuentas si una vez visto esto, y arrancado el servicio correctamente, consigues acceder o qué problema queda aún por resolver.
Si trabajas habitualmente con SQL Server y todos los servicios que incluye, te recomiendo que utilices este grupo de Microsoft:
http://social.msdn.microsoft.com/Forums/es-ES/sqlserveres
donde estamos muchos compañeros dispuestos a ayudarte
Un saludo
Salvador Ramos
http://www.salvador-ramos.com
-------------------------------------------
http://www.cursosqlserver.com (video-cursos gratuitos sobre SQL Server)
http://www.sqlserversi.com (información sobre SQL Server y Business Intelligence)
http://www.helpdna.net (información sobre SQL Server y Microsoft .Net)
-------------------------------------------
- Log in to post comments
O si no se puede arreglar
O si no se puede arreglar existe alguna manera de hacerlo manualmente?
Gracias!
- Log in to post comments
Herramientas de BI de Microsoft
Herramientas de BI de Microsoft Carlos 26 April, 2009 - 21:37En esta presentación de MicrosoftTechNet se muestra cómo se combinan las diferentes herramientas y Microsoft ... Servers para montar una plataforma completa de BI/BPM. Recomiendo especialmente los esquemas de los slides 5 y 17, donde podemos ver cómo se relacionan SQLServer Analysis Services, Office Excel, Office PerformancePoint Server y Office Sharepoint Server:
Qué software hace falta?
Entonces por lo que veo si no hace falta montar algo muy grande con Analysis Services, Reporting Services y Excel ya sería suficiente, y si se necesita hacer dashboards, temas de gestión del rendimiento y más integración, acceso por web, etc habría que usar PerformancePoint y SharePoint, no?
- Log in to post comments
Pues sí, eso parece. Adjunto
- Log in to post comments
http://www.beyebuilder.com es
- Log in to post comments
Ocultar en el cubo miembros de dimensiones que no tengan datos
Ocultar en el cubo miembros de dimensiones que no tengan datos BIDev 2 March, 2012 - 13:32Hay alguna manera de hacer que en el cubo de Analisis Services se oculten los miembros de una dimensión que no tengan datos en la tabla de hechos?.
En la base de datos sí que quiero tener la dimensión completa, pero en el cubo no quiero que me aparezcan los miembros que no están enlazados en la tabla de hechos para que el usuario no tenga que filtrar esos registros cuando haga sus consultas sobre el cubo.
Alguien sabe cómo se puede hacer?
Problemas con el Analysis Services 2000
Problemas con el Analysis Services 2000 m a 29 June, 2009 - 16:34Hola a todos, primero saludos, soy un nuevo usuario del sitio y espero poder tener una relacion de ayuda mutua con todo el foro.
estoy creando un sistema Data Ware House para un sistema de administración de recursos humanos, y bueno el cubo lo tengo listo en Analysis Services del sql server 2000 y lo puedo conectar con el excel desde mi maquina pero al momento de querer acceder al cubo desde otra maquina no lo puedo hacer ni a palos! me he puesto a revisar el problema y segun algunos articulos dicen que hay que instalar el service pack 4 para cada componente pero ya lo instale y nada que funciona.... por favor alguien sabe como puedo hacer para que las maquinas remotas se puedan conectar?
ademas estoy yendo a usar un pentaho, solo que aun no se como se usa esa herramienta... como veran me falta mucho por aprender de BI pero estoy muy aplicado porque el sistema lo necesito de urg.
Saludos
m a
Antes de nada te quiero dar
Antes de nada te quiero dar la bienvenida a Dataprix  .
.
Sobre el problema que comentas con Analysis Services 2000 lo primero que se me ocurre es que el problema pueda estar en la versión de Excel. Cuál estas utilizando?
Las que parecen ir bien con Analysis Services 2000 son MSOffice Excel 2002 y Excel 2003, enlazo el Complemento de Excel 2002/2003 para SQL Server Analysis Services SP1
Sobre Excel 2007 y Analysis Services 2000 no he encontrado ninguna referencia donde se comente que funciona, puede que sólo sea compatible con SQL Server 2005
Incluyo también algunos enlaces de la página de soporte de Microsoft sobre problemas entre Analysis Services 2000 y Excel por si alguno no lo hubieras consultado ya:
Error al conectarse a OLAP después de instalación de SQL Server 2000 Analysis Services
XL2000: No se ve cubos creados en Analysis Services de SQL 2000 Server
No se puede ver todos los cubos al conectarse desde Excel 2000 a Analysis Services
Si adjuntas el detalle del error que te da o comentas en más detalle qué es lo que falla podemos mirar de investigar un poco más..
Sobre Pentaho, si no lo has hecho ya, te recomiendo que pruebes la imagen virtual que ha creado Dario, ya que la mayoría de la información y demos que puedes encontrar por ahí son sobre componentes específicos, y es complicado hacerse una idea global de cómo funciona todo el sistema, y más instalarlo de cero. En esta imagen lo tienes todo instalado sobre Ubuntu, funcionando y con ejemplos y datos de prueba.
- Log in to post comments
URGENTE.- Buenos días, tengo
URGENTE.-
Buenos días, tengo problemas con Analysis Services 2000, no permite agregar usuarios en Database Roles, pero en SQL si lo hace. Cuando presiono el botón Add no hace nada, tampoco muestra mensajes en el visor de sucesos. ¿Tienen idea de que pueda estar pasando? Gracias.
- Log in to post comments
Parece un problema de
Parece un problema de permisos. Que puedas hacer algo a nivel de usuarios en la BD de SQL Server 2000 y desde Analysis Services no seguramente es porque la seguridad de Analysis Services 2000 funciona con las cuentas de usuario y grupos de Windows, no con los de la base de datos. Deberías crear las cuentas y los grupos con Active Directory.
Asegúrate sobretodo que el usuario con el que estás administrando desde Analysis Services pertenezca al OLAP Administrators group
Extraigo un fragmento del documento INF: Permisos que se necesita para administrar un servidor OLAP, de los servicios de soporte de Microsoft:
Hay ciertos permisos requeridos para conectarse a un servidor OLAP mediante el OLAP Manager o secuencia de comandos de DSO:
- Debe tener permiso de acceso a la siguiente clave del registro en el servidor:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\OLAP Server\Server Connection Info - Debe tener permisos de escritura en el recurso compartido oculto MsOLAPRepository $, que contiene el repositorio de servicios OLAP y bloqueo de archivos. De forma predeterminada este recurso compartido es el directorio bin en los servicios OLAP directorio.
- También debe tener derechos de control total en los directorios Bin y datos en el programa de programa\Microsoft Analysis Services\Bin directorio. De manera predeterminada, estas carpetas deben permite todos control total, pero si por motivos de seguridad desea reforzar la seguridad, asegúrese de que el grupo Administradores OLAP mantiene los derechos de control total.
Al instalar Servicios OLAP, se crea un grupo local denominado 'Administradores de OLAP' y se le da 'Control total' para la clave del registro anterior y el recurso compartido de $ MsOLAPRepository. También se agrega el instalador al grupo 'Administradores de OLAP'.
Espero que te sirva de ayuda,
- Log in to post comments
Tengo el mismo problema, que
Tengo el mismo problema, que le doy add en database roles; y no muestra; pero en una máquina con Windows XP con mi usuario si me permite; pero en una con Windows Vista no. Las dos máquinas están conectadas al DOMINIO.
Gracias
- Log in to post comments
Hola es la primera vez que
Hola es la primera vez que ingreso a esta pagina y por fa necesito de su ayuda
Estoy haciendo un sistema que abarca varias bases de datos en una sola base de datos, estoy utilizando paquetes ETL, y para las consultas estoy elaborando cubos OLAP, pero al momento de implementar el cubo me sale un error que dice que no tengo permisos para crear cubos, pero SQL SERVER 2005 lo instale como administrador, ahora he leido que para que funcione el Analisis Server debe estar instalado el SP1 y ya lo instale pero resulta y no lo puedo hacer por favor me pueden ayudar
Saludos
Sol Fernández
- Log in to post comments