
Building Hadoop Clusters [Video] - Review (en español)
- Lee más sobre Building Hadoop Clusters [Video] - Review (en español)
- Inicie sesión para enviar comentarios
Estimad@s,
una vez más se trata de una review de un video curso publicado por Packt Publishing. En este caso les haré un comentario sobre "Building Hadoop Clusters" cuyo autor es Sean Mikha.
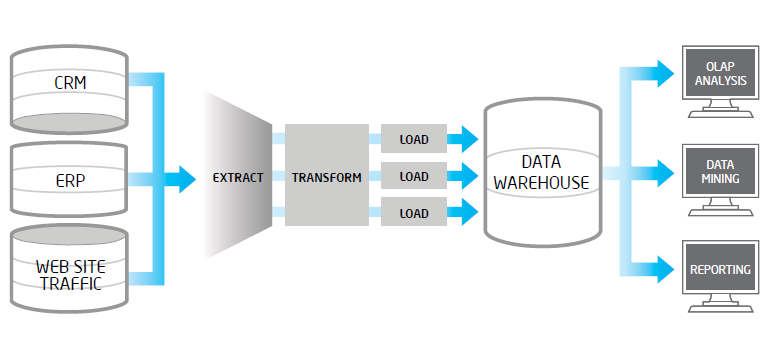 En el presente post pretendemos mostrar la problemática que con frecuencia encontramos en los procesos de extracción, validación y carga de datos en los entornos Big Data. Un proceso ETL tradicional, extrae datos desde múltiples fuentes origen, después los valida, normaliza, realiza determinadas transformaciones y vuelca los mismos en un entorno datawarehouse para su posterior análisis. Cuando en los datos fuentes, tenemos volúmenes altos, una frecuencia de actualización alta en origen o bien son datos no estructurados, estos procesos ETL suelen tener problemas..
En el presente post pretendemos mostrar la problemática que con frecuencia encontramos en los procesos de extracción, validación y carga de datos en los entornos Big Data. Un proceso ETL tradicional, extrae datos desde múltiples fuentes origen, después los valida, normaliza, realiza determinadas transformaciones y vuelca los mismos en un entorno datawarehouse para su posterior análisis. Cuando en los datos fuentes, tenemos volúmenes altos, una frecuencia de actualización alta en origen o bien son datos no estructurados, estos procesos ETL suelen tener problemas.. .png) Una de las herramientas más maduras en el mundo Big Data es el framework de licencia libre Apache Hadoop. En este post exponemos de forma resumida la integración entre Hadoop y uno de los fabricantes líder en analítica de negocio: SAS.
Una de las herramientas más maduras en el mundo Big Data es el framework de licencia libre Apache Hadoop. En este post exponemos de forma resumida la integración entre Hadoop y uno de los fabricantes líder en analítica de negocio: SAS.
 Estos días he estado leyendo el libro Big Data Analytics with R and Hadoop, de Vignesh Prajapati, un libro que explica cómo integrar el paquete de análisis estadístico R y la plataforma de Big Data Apache Hadoop, para romper la barrera de la mayor limitación de R, que es la limitada cantidad de datos que acepta como juegos de datos para procesar.
Estos días he estado leyendo el libro Big Data Analytics with R and Hadoop, de Vignesh Prajapati, un libro que explica cómo integrar el paquete de análisis estadístico R y la plataforma de Big Data Apache Hadoop, para romper la barrera de la mayor limitación de R, que es la limitada cantidad de datos que acepta como juegos de datos para procesar.



 Si miramos alrededor nuestro, vemos que cualquier dispositivo que usamos genera datos, estos pueden ser analizados actualmente. De esta gran cantidad de datos que tenemos a nuestro alcance, sólo el 20% se trata de información estructura y el 80% son datos no estructurados. Estos últimos añaden complejidad en la forma que se tienen que almacenar y analizar.
Si miramos alrededor nuestro, vemos que cualquier dispositivo que usamos genera datos, estos pueden ser analizados actualmente. De esta gran cantidad de datos que tenemos a nuestro alcance, sólo el 20% se trata de información estructura y el 80% son datos no estructurados. Estos últimos añaden complejidad en la forma que se tienen que almacenar y analizar.