

La ciencia de datos y la inteligencia artificial han dejado de ser disciplinas emergentes para convertirse en pilares fundamentales de la estrategia empresarial moderna. En un mercado global donde la capacidad de extraer insights accionables de grandes volúmenes de información determina la ventaja competitiva, contar con las herramientas adecuadas de Data Science y AI no es un lujo: es una necesidad imperativa.

El ecosistema de software para ciencia de datos ha experimentado una evolución exponencial en los últimos años, con plataformas que integran capacidades avanzadas de machine learning, procesamiento de lenguaje natural, visión por computador y análisis predictivo en entornos unificados que aceleran el time-to-value y democratizan el acceso a tecnologías antes reservadas para especialistas.
En este análisis, exploraremos las que consideramos diez mejores soluciones de software de Data Science y AI disponibles en 2025, evaluando sus capacidades técnicas, casos de uso óptimos, curvas de aprendizaje y propuestas de valor para ayudar tanto a científicos de datos experimentados como a organizaciones que inician su transformación digital a seleccionar la plataforma más adecuada para sus objetivos específicos.
Dentro de cada una encontrarás un enlace para acceder a la reseña exhautiva que hemos elaborado para que puedas profundizar en sus características, fortalezas y debilidades, y contar con más información que te ayude a seleccionar la que mejor se ajuste a las necesidades de tu compañía.
El Panorama Actual de Data Science y AI Empresarial
Antes de adentrarnos en las soluciones individuales, es fundamental comprender el contexto tecnológico y empresarial que está definiendo el mercado de Data Science y AI en 2025.
La Democratización de la Inteligencia Artificial
Una de las tendencias más significativas es la democratización del acceso a capacidades avanzadas de IA. Lo que hace una década requería equipos especializados con doctorados en estadística y acceso a infraestructura computacional costosa, hoy está disponible mediante interfaces visuales, AutoML (Machine Learning Automatizado) y plataformas cloud que abstraen la complejidad subyacente.
Esta democratización no elimina el valor de los expertos, sino que amplía el alcance de la ciencia de datos, permitiendo que analistas de negocio, ingenieros de software y domain experts contribuyan directamente a iniciativas de IA, mientras los data scientists se concentran en problemas de mayor complejidad y valor estratégico.
Integración de MLOps y Producción de Modelos
El desafío ya no es construir modelos de machine learning precisos en entornos de desarrollo, sino llevarlos a producción de forma confiable, monitorizarlos continuamente y actualizarlos cuando su rendimiento degrada. MLOps (Machine Learning Operations) ha emergido como disciplina crítica, y las plataformas modernas integran capacidades end-to-end que cubren todo el ciclo de vida del modelo, desde experimentación hasta despliegue y governance.
IA Generativa y Large Language Models
La irrupción de modelos de lenguaje grandes (LLMs) como GPT-4, Claude y soluciones especializadas ha abierto nuevas posibilidades para análisis de texto, generación de código, síntesis de información y automatización de tareas cognitivas complejas. Las plataformas modernas están integrando capacidades de IA generativa como componentes fundamentales, no como complementos experimentales.
Edge AI y Modelos Distribuidos
Con la proliferación de dispositivos IoT y requisitos de latencia ultra-baja, el procesamiento de inferencias de IA en edge devices se ha vuelto crítico. Las plataformas avanzadas soportan no solo entrenamiento centralizado sino también despliegue optimizado en dispositivos con recursos limitados.
Ética y IA Responsable
Las preocupaciones sobre sesgo algorítmico, explicabilidad de decisiones automatizadas y uso ético de datos personales han llevado a que las organizaciones prioricen herramientas que incorporen capacidades de fairness testing, interpretabilidad de modelos y documentación de linaje para auditoría.
Criterios de Evaluación para Software de Data Science y AI
Al evaluar las soluciones incluidas en este ranking, hemos considerado sus características en múltiples dimensiones críticas que determinan el valor real que una plataforma puede aportar:
Capacidades de machine learning: Amplitud de algoritmos soportados (supervisado, no supervisado, refuerzo), facilidad para experimentar con diferentes enfoques y capacidades de AutoML para acelerar desarrollo.
Gestión del ciclo de vida completo: Cobertura desde preparación de datos y feature engineering hasta entrenamiento, validación, despliegue, monitorización y reentrenamiento de modelos.
Integración de datos: Facilidad para conectar con diversas fuentes de datos (bases de datos, data lakes, APIs, streaming), procesar información estructurada y no estructurada, y realizar transformaciones complejas.
Escalabilidad y rendimiento: Capacidad para manejar volúmenes masivos de datos, entrenar modelos complejos en tiempos razonables y escalar infraestructura computacional según demanda.
Colaboración y productividad: Funcionalidades que facilitan trabajo en equipo, versionado de experimentos, reproducibilidad de resultados y transferencia de conocimiento entre miembros.
Despliegue y operacionalización: Opciones para poner modelos en producción (APIs REST, batch scoring, edge deployment), integración con sistemas empresariales y capacidades de MLOps.
Interpretabilidad y explicabilidad: Herramientas para entender decisiones de modelos, detectar sesgos y generar explicaciones comprensibles para stakeholders no técnicos.
Ecosistema y extensibilidad: Disponibilidad de librerías, modelos pre-entrenados, integraciones con herramientas populares y capacidad de personalización mediante código.
Curva de aprendizaje y usabilidad: Balance entre poder y accesibilidad, disponibilidad de interfaces visuales para usuarios menos técnicos y opciones code-first para expertos.
Costo total de propiedad: Modelo de pricing (licencias, consumo cloud), costos de infraestructura, recursos humanos requeridos y ROI esperado.
1. Databricks Data Intelligence Platform
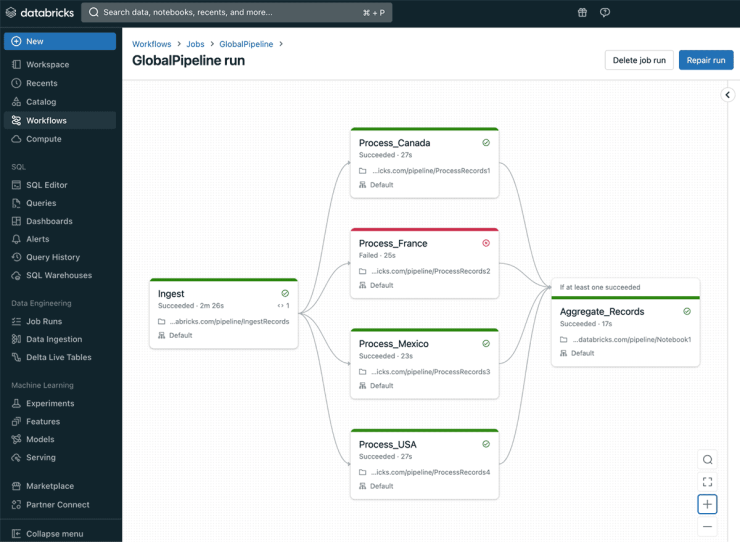
Databricks encabeza el ranking de Dataprix como la referencia indiscutible en plataformas unificadas de datos e inteligencia artificial. Su propuesta se basa en el concepto de Lakehouse, un híbrido entre data lake y data warehouse que permite gestionar datos estructurados y no estructurados en un mismo entorno.
Esta plataforma, construida sobre Apache Spark, ofrece un espacio colaborativo donde científicos de datos, ingenieros y analistas trabajan juntos en notebooks compartidos, con versiones controladas y pipelines reproducibles. Uno de sus pilares es Delta Lake, la capa de almacenamiento que permite versionar los datos, realizar “time travel” y asegurar su consistencia.
Databricks ha evolucionado mucho más allá de su origen como motor de procesamiento distribuido. Con la incorporación de MLflow, la plataforma ofrece gestión integral del ciclo de vida de los modelos: seguimiento de experimentos, versionado, despliegue y monitoreo. Además, su ecosistema está preparado para manejar tanto cargas tradicionales de machine learning como proyectos de IA generativa a gran escala, integrando modelos de lenguaje y frameworks modernos.
Su mayor virtud es la escalabilidad y el rendimiento, lo que la convierte en la opción preferida por grandes corporaciones con volúmenes masivos de datos. Sin embargo, esa misma amplitud puede requerir una curva de aprendizaje considerable y una inversión inicial elevada en infraestructura. Es una herramienta pensada para empresas que ya han recorrido parte del camino de madurez analítica y buscan un entorno unificado para sus equipos de datos.
2. Google Cloud – Vertex AI Platform
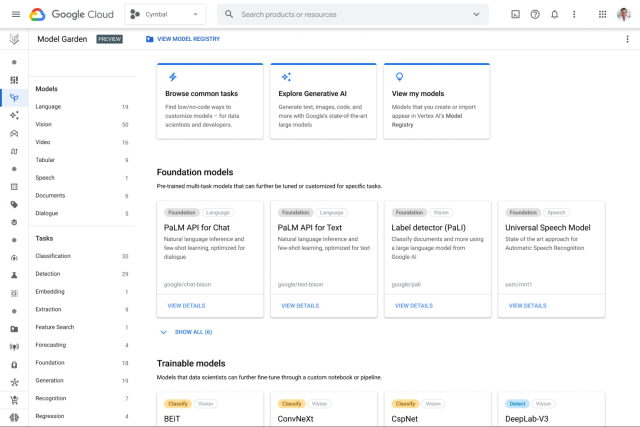
Vertex AI es la plataforma de inteligencia artificial de Google Cloud, y una de las más completas y automatizadas del mercado. Dataprix la sitúa en la segunda posición por su capacidad de integrar, en un solo flujo, todo el ciclo de vida de un proyecto de machine learning: desde la preparación de datos hasta el despliegue y monitoreo de modelos.
Uno de los grandes atractivos de Vertex AI es su interoperabilidad con el ecosistema de Google. Al integrarse de forma nativa con BigQuery, Dataflow, Dataproc o Looker, facilita que los datos fluyan de manera natural entre almacenamiento, procesamiento y análisis. Además, ofrece servicios de AutoML para generar modelos predictivos sin necesidad de escribir código, junto con entornos totalmente personalizados para desarrolladores experimentados que desean entrenar modelos con TensorFlow, PyTorch o scikit-learn.
Vertex AI también ha incorporado herramientas para la gestión de características (Feature Store), pipelines de entrenamiento y supervisión continua de modelos en producción. Más recientemente, Google ha impulsado su plataforma hacia la IA generativa, ofreciendo integraciones directas con modelos base y APIs avanzadas que permiten crear asistentes conversacionales, clasificadores o sistemas de recomendación inteligentes.
Su facilidad de uso, sumada a la infraestructura escalable y segura de Google Cloud, la convierten en una excelente opción para organizaciones que ya operan en este ecosistema. El reto principal puede residir en la dependencia del entorno Google y en la necesidad de adaptar arquitecturas híbridas o multi-nube si se desea integrar con otros proveedores.
3. Amazon SageMaker

En el tercer lugar del ranking se encuentra Amazon SageMaker, la propuesta de AWS para acelerar el desarrollo y operación de modelos de machine learning. SageMaker se distingue por su amplitud de servicios, que cubren desde la preparación de datos hasta el despliegue en producción, ofreciendo una infraestructura robusta, escalable y segura.
SageMaker ofrece a los equipos de datos un conjunto de herramientas como SageMaker Studio, un entorno de desarrollo integrado para ML; Feature Store, para gestión centralizada de características; y Model Monitor, que permite vigilar la deriva de los modelos una vez desplegados. Todo ello está estrechamente conectado con el resto del ecosistema de AWS, incluyendo S3, Glue, Lambda o Redshift.
El enfoque de SageMaker es ofrecer flexibilidad total: puede ser utilizado tanto por expertos en código como por analistas que se apoyan en sus funciones de AutoML. Además, permite ejecutar modelos con soporte de GPU o CPU según las necesidades del proyecto, optimizando costos mediante instancias “spot” o escalado automático.
Su mayor fortaleza —el nivel de control y la capacidad de personalización— también puede convertirse en una barrera para los equipos menos experimentados. La complejidad de configuración y la necesidad de comprender bien la arquitectura AWS hacen que sea una plataforma ideal para empresas con equipos técnicos maduros o con infraestructura ya basada en Amazon Web Services.
4. Azure Machine Learning
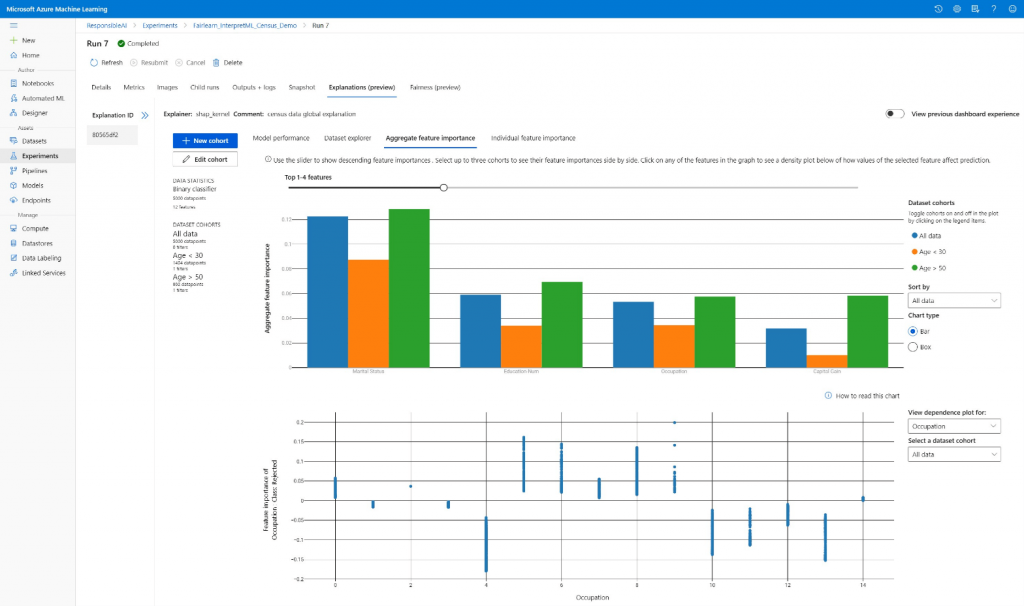
La propuesta de Microsoft, Azure Machine Learning, ocupa el cuarto puesto del top de Dataprix. Es una plataforma empresarial que permite construir, entrenar y desplegar modelos de machine learning de forma escalable, con integración total en el ecosistema Azure.
Azure ML combina facilidad de uso con potencia. Dispone de herramientas visuales para diseñar flujos de trabajo, pero también permite a los científicos de datos trabajar directamente en código mediante notebooks, SDKs y entornos personalizados. Su AutoML facilita la creación rápida de modelos, mientras que las funcionalidades de MLOps —versionado de experimentos, gestión de pipelines, control de modelos en producción— garantizan una operación controlada y repetible.
Una de sus ventajas diferenciales es la integración con el resto del entorno Microsoft: Azure Synapse, Power BI, Data Lake Storage o Azure Databricks se conectan sin fricciones. Además, la plataforma incorpora medidas avanzadas de seguridad y cumplimiento, apoyadas en Azure Active Directory, que resultan esenciales en sectores regulados.
Azure ML es ideal para organizaciones que ya trabajan con Microsoft y desean consolidar su estrategia de datos dentro de un marco unificado. Su reto puede estar en la diversidad de opciones y configuraciones, que requiere planificación previa para aprovechar todas sus capacidades.
5. Dataiku
En el quinto lugar, Dataiku representa un enfoque diferente dentro del universo de la ciencia de datos. Su filosofía se centra en la democratización de la analítica, permitiendo que tanto perfiles técnicos como de negocio colaboren en la creación de modelos y soluciones basadas en datos.
La interfaz visual de Dataiku facilita la preparación, exploración y modelado de datos sin necesidad de escribir código, aunque ofrece integración plena con lenguajes como Python o R para quienes deseen profundizar. Esta dualidad hace que Dataiku sea una herramienta muy versátil, capaz de unir a distintos tipos de profesionales en un mismo entorno.
Uno de sus puntos fuertes es la capacidad para automatizar tareas repetitivas mediante flujos de trabajo reproducibles y pipelines programables. Además, incluye funciones de gobernanza de modelos, control de versiones y seguimiento de experimentos, aspectos cada vez más valorados por las organizaciones que buscan escalar su práctica de ciencia de datos.
Dataiku brilla especialmente en entornos corporativos donde se busca colaboración transversal y rapidez para prototipar soluciones. Su desafío está en el costo y la necesidad de una infraestructura adecuada para grandes volúmenes de datos, aunque su curva de aprendizaje es considerablemente más amigable que la de las plataformas puramente técnicas.
6. DataRobot Platform
DataRobot, en la sexta posición, ha sido pionera en el concepto de AutoML: la automatización del proceso de creación y validación de modelos. Su plataforma permite a los usuarios construir modelos predictivos de alta precisión sin requerir un conocimiento profundo en estadística o programación, algo que la ha hecho especialmente atractiva para empresas que buscan acelerar sus proyectos de inteligencia artificial.
Con el tiempo, DataRobot ha evolucionado más allá del AutoML para convertirse en una solución integral de gestión del ciclo de vida del modelo. Su plataforma incorpora herramientas para explicabilidad, detección de sesgos, gobernanza, despliegue y monitorización en tiempo real. Todo esto se presenta bajo una interfaz intuitiva que facilita la colaboración entre equipos técnicos y de negocio.
La clave del éxito de DataRobot es la combinación entre automatización e interpretabilidad. La plataforma no solo genera modelos, sino que ofrece métricas detalladas y visualizaciones que explican cómo cada variable influye en los resultados. Esto resulta esencial para la confianza y la adopción de la IA en entornos empresariales.
Aunque su orientación es claramente empresarial, DataRobot mantiene cierta limitación para usuarios que buscan un control muy granular o arquitecturas completamente personalizadas. Aun así, su propuesta de valor es sólida para organizaciones que necesitan resultados rápidos y fiables con un marco de gobernanza robusto.
7. IBM watsonx
En séptimo lugar, Dataprix incluye IBM watsonx, la evolución moderna de la legendaria línea Watson. Este ecosistema combina tres pilares fundamentales: watsonx.ai, orientado al desarrollo y entrenamiento de modelos de IA; watsonx.data, una plataforma abierta de datos optimizada para IA; y watsonx.governance, enfocada en la trazabilidad, ética y control de modelos.
Watsonx representa la visión de IBM de una inteligencia artificial confiable y auditable, un aspecto que cobra cada vez más importancia ante las regulaciones emergentes en torno al uso ético de la IA. Su arquitectura abierta le permite integrarse con múltiples fuentes de datos y frameworks, mientras que su interfaz de desarrollo soporta tanto modelos tradicionales de ML como modelos fundacionales de gran escala (foundation models).
Una de las grandes fortalezas de watsonx es su enfoque en la gobernanza. Permite rastrear la procedencia de los datos, controlar versiones de modelos, verificar el cumplimiento de políticas internas y evaluar el riesgo de sesgos. Esto la convierte en una herramienta especialmente relevante para sectores como banca, salud o administración pública, donde la transparencia y el cumplimiento normativo son imprescindibles.
Si bien IBM watsonx no busca competir en simplicidad con plataformas más ligeras, su robustez y enfoque ético la posicionan como una solución estratégica para empresas que desean construir confianza en sus sistemas de IA.
8. Snowflake Data & AI Platform
Snowflake, ampliamente conocido por su capacidad como data warehouse en la nube, ha dado un paso decisivo hacia el mundo de la inteligencia artificial. Dataprix destaca su transformación en una plataforma unificada de datos y AI, capaz de servir como base para proyectos analíticos y de machine learning de gran escala.
El punto fuerte de Snowflake es su arquitectura basada en separación de cómputo y almacenamiento, que ofrece un rendimiento sobresaliente y escalabilidad casi ilimitada. Esto permite a las organizaciones procesar y compartir datos de manera eficiente entre departamentos y partners, manteniendo un control de seguridad riguroso.
En los últimos años, Snowflake ha añadido funciones para ejecutar modelos de IA directamente sobre los datos, sin necesidad de moverlos. Esto reduce la latencia y mejora la seguridad. Además, su ecosistema de “Snowflake Marketplace” facilita el acceso a modelos y datasets de terceros, lo que amplía las posibilidades de innovación.
Aunque no es una plataforma de machine learning en sentido estricto —su enfoque sigue centrado en los datos—, Snowflake se ha convertido en una piedra angular para entornos donde el dato es el activo principal y la IA se construye alrededor de él. Es una opción excelente para organizaciones que desean mantener todo su pipeline analítico en un entorno optimizado, gobernado y altamente disponible.
9. RapidMiner
RapidMiner figura en la novena posición del listado de Dataprix y representa una de las soluciones más veteranas y consolidadas en el ámbito de la analítica predictiva. Su enfoque visual y modular permite crear modelos sin necesidad de programar, lo que la ha convertido en una herramienta especialmente popular en entornos educativos y corporativos de adopción temprana de la ciencia de datos.
El usuario puede construir flujos de trabajo completos arrastrando y conectando componentes, desde la preparación de los datos hasta el entrenamiento y la validación de modelos. Este enfoque de “low-code” no impide que los usuarios avanzados incorporen scripts de Python o R cuando lo necesiten, lo que añade flexibilidad a la herramienta.
RapidMiner ha mantenido su relevancia gracias a una comunidad activa y a la evolución constante de su producto. En sus versiones más recientes, ha añadido funciones de AutoML, integración con la nube y despliegue de modelos, acercándose así al concepto de plataforma integral.
Sus limitaciones surgen cuando los proyectos demandan escalabilidad extrema o integración con ecosistemas empresariales más amplios. Sin embargo, su valor como plataforma de aprendizaje, prototipado y proyectos de tamaño medio sigue siendo incuestionable.
10. Domino Data Lab
Cerrando el top 10 de Dataprix se encuentra Domino Data Lab, una plataforma que ha ganado protagonismo por su enfoque en la colaboración y gobernanza de proyectos de ciencia de datos a escala empresarial. Domino proporciona un entorno unificado donde los equipos pueden desarrollar modelos en distintos lenguajes y frameworks, compartir resultados, versionar experimentos y gestionar despliegues.
A diferencia de las plataformas orientadas al “no-code”, Domino está diseñada para equipos técnicos maduros que necesitan mantener orden y reproducibilidad en proyectos complejos. Su capacidad para integrarse con herramientas como Git, Jenkins o Kubernetes permite aplicar principios de ingeniería de software al desarrollo de modelos de machine learning.
Domino destaca también por su orientación a la gestión del conocimiento: cada experimento, dataset o modelo puede documentarse y rastrearse, lo que facilita auditorías y cumplimiento normativo. Esto la convierte en una plataforma de referencia para organizaciones que manejan numerosos proyectos simultáneamente y requieren control centralizado sin sacrificar flexibilidad técnica.
Su adopción suele darse en grandes corporaciones con equipos multidisciplinarios y políticas de compliance estrictas. Aunque no es la opción más económica, su capacidad de escalar y mantener la trazabilidad de cada proceso la sitúan entre las soluciones empresariales más robustas del mercado.
Comparación y análisis transversal
El análisis de las diez plataformas seleccionadas por Dataprix revela una clara convergencia: todas buscan ofrecer un entorno unificado donde los datos, los modelos y los equipos convivan de forma coherente. Sin embargo, cada una aborda ese objetivo desde un ángulo distinto.
Databricks, SageMaker, Vertex AI y Azure ML representan el núcleo cloud del mercado, con infraestructuras de enorme potencia, integración nativa con sus ecosistemas y capacidades avanzadas de automatización y MLOps. Son plataformas para organizaciones con estrategia cloud consolidada.
Dataiku y DataRobot ocupan el espacio de la democratización y automatización, orientadas a hacer la IA accesible para equipos mixtos de negocio y tecnología. IBM watsonx introduce el componente ético y de gobernanza, cada vez más demandado en la industria. Snowflake actúa como plataforma de datos base, sobre la cual se construyen las aplicaciones de IA. Finalmente, RapidMiner y Domino Data Lab ofrecen enfoques complementarios: uno facilita la entrada y el aprendizaje, el otro la madurez y el control empresarial.
Tabla comparativa de las plataformas
| Plataforma | Enfoque principal | Puntos fuertes | Ideal para |
|---|---|---|---|
| Databricks | Unificación de datos e IA (Lakehouse) | Escalabilidad, rendimiento, MLflow integrado | Grandes empresas con ecosistemas distribuidos |
| Vertex AI | ML gestionado en Google Cloud | AutoML, pipelines integrados, IA generativa | Organizaciones que operan en Google Cloud |
| SageMaker | Plataforma completa de ML en AWS | Control técnico, amplia infraestructura | Equipos expertos en entorno AWS |
| Azure ML | ML empresarial en ecosistema Microsoft | Integración nativa, gobernanza, seguridad | Empresas basadas en Azure |
| Dataiku | Analítica colaborativa y democratización | Interfaz visual + código, gobernanza de modelos | Organizaciones con perfiles mixtos |
| DataRobot | AutoML y gestión del ciclo de vida | Velocidad, interpretabilidad, control de sesgos | Empresas que buscan automatización rápida |
| IBM watsonx | IA confiable y ética | Gobernanza, trazabilidad, transparencia | Sectores regulados (finanzas, salud, gobierno) |
| Snowflake | Plataforma de datos con IA integrada | Rendimiento, seguridad, data sharing | Empresas centradas en datos y analítica |
| RapidMiner | Analítica visual low-code | Facilidad de uso, comunidad activa | Organizaciones en fase inicial de adopción |
| Domino Data Lab | Gestión colaborativa y gobernanza | Reproducibilidad, escalabilidad, control | Grandes corporaciones con múltiples proyectos |
Tendencias Transformadoras en Data Science y AI
El campo de Data Science y AI continúa evolucionando a velocidad vertiginosa, con varias tendencias que están redefiniendo mejores prácticas y capabilities:
Large Language Models y IA Generativa Empresarial
Los LLMs están siendo integrados en plataformas de Data Science como capabilities fundamentales para tareas como generación automática de código (copilots), síntesis de documentación, generación de features basadas en texto y augmentation de datos. Las organizaciones están explorando fine-tuning de modelos fundacionales para dominios específicos y RAG (Retrieval Augmented Generation) para grounding en conocimiento empresarial propietario.
MLOps Maduro y Continuous Intelligence
La convergencia de prácticas DevOps con machine learning está madurando hacia CI/CD completo para modelos de IA. Esto incluye testing automático de modelos (unit tests, integration tests, shadow deployment), monitoring continuo con alertas automáticas ante degradación y retraining triggers basados en drift detection. Las plataformas líderes están incorporando estas capacidades como features core, no add-ons.
Federated Learning y Privacy-Preserving ML
Las preocupaciones sobre privacidad están impulsando técnicas que permiten entrenar modelos sobre datos distribuidos sin centralización. Federated learning, differential privacy y encrypted computation están transicionando de investigación académica a implementaciones productivas, particularmente en healthcare, finance y casos con datos multi-party sensibles.
AutoML de Nueva Generación
Más allá de automatización básica de selección de algoritmos, AutoML está evolucionando hacia neural architecture search, combined algorithm selection y meta-learning que adapta estrategias de búsqueda basándose en características del dataset y tarea. Esto está reduciendo gaps entre modelos automáticos y aquellos creados por expertos.
Multimodal AI
Los sistemas de IA están trascendiendo modalidades individuales (texto, imagen, audio) hacia modelos unificados que procesan información multimodal simultáneamente. Esto habilita casos de uso como búsqueda cross-modal, generación de descripciones de imágenes y análisis comprehensivo de contenido multimedia.
AI on Edge y Model Optimization
La demanda por inferencia en dispositivos edge está impulsando técnicas de compresión de modelos (quantization, pruning, distillation) que reducen footprint computacional sin sacrificar accuracy significativamente. Las plataformas están incorporando herramientas para optimizar y desplegar modelos en dispositivos con recursos limitados.
Estrategias para Selección e Implementación Exitosa
Elegir e implementar una plataforma de Data Science y AI requiere planificación estratégica y consideración de múltiples factores organizacionales:
Evaluación de Madurez Organizacional
Antes de seleccionar una herramienta, es crítico evaluar honestamente:
Madurez de datos: ¿Los datos están centralizados y accesibles, o fragmentados en silos? ¿Existe data governance establecida? La plataforma más sofisticada no compensará fundamentos de datos débiles.
Capacidades técnicas del equipo: ¿El equipo incluye data scientists experimentados que requieren flexibilidad máxima, o analistas que se beneficiarían de interfaces visuales y AutoML? El skill mix determina qué features son críticas vs nice-to-have.
Infraestructura existente: ¿On-premise, cloud público, híbrido? ¿Qué vendors (AWS, Azure, GCP)? ¿Inversiones significativas en tecnologías específicas que requieren integración? Alineamiento con infraestructura existente reduce complejidad.
Casos de uso prioritarios: ¿Predictive analytics sobre structured data, NLP, visión por computador, time series forecasting, recommendation? Diferentes plataformas destacan en diferentes dominios.
Estrategia de Adopción Incremental
Las implementaciones exitosas típicamente siguen aproximación iterativa:
Fase de proof of concept: Seleccionar caso de uso acotado con valor de negocio claro, formar equipo pequeño multifuncional, implementar rápidamente y demostrar ROI tangible. Esto genera momentum y funding para expansión.
Construcción de foundations: Establecer data pipelines confiables, implementar MLOps básico (versioning, deployment, monitoring), crear templates y best practices reutilizables, y entrenar equipo en plataforma seleccionada.
Escalamiento y evangelización: Extender a casos de uso adicionales, formar comunidad interna de practice, crear center of excellence que provea soporte y acelera proyectos, y medir impacto mediante métricas de negocio.
Optimización continua: Refinar procesos basándose en lecciones aprendidas, incorporar nuevas capacidades de plataforma conforme evolucionan, y mantener skills del equipo actualizados mediante training continuo.
Consideraciones de Build vs Buy vs Partner
Las organizaciones enfrentan decisión entre:
Build: Construir capacidades custom usando frameworks open source (TensorFlow, PyTorch, scikit-learn). Máxima flexibilidad pero requiere expertise profundo y esfuerzo significativo en tooling y operations.
Buy: Adquirir plataforma comercial comprehensive. Acelera time-to-value, reduce overhead operacional y proporciona soporte, pero implica vendor lock-in y costos recurrentes.
Partner: Colaborar con consultoras especializadas o service providers. Acceso a expertise sin overhead de contratación permanente, pero puede generar dependencia y costos elevados a largo plazo.
La respuesta óptima frecuentemente involucra híbrido: plataforma comercial como foundation, complementada con componentes open source custom para necesidades específicas y partnerships estratégicos para acelerar casos complejos.
Factores Críticos de Éxito en Proyectos de Data Science y AI
Más allá de seleccionar la herramienta correcta, el éxito en iniciativas de Data Science y AI depende de múltiples factores organizacionales y metodológicos:
Alineamiento con Objetivos de Negocio
El error más común en proyectos de IA es desconexión entre capabilities técnicas y necesidades de negocio. Los proyectos exitosos comienzan identificando problemas específicos de negocio con KPIs claros (reducción de costos operativos en X%, incremento de conversión en Y%, mejora de customer satisfaction score) y trabajan backwards hacia soluciones técnicas.
Establecer un business case robusto antes de iniciar desarrollo, con estimaciones conservadoras de ROI y timeline realista, garantiza que el proyecto mantenga apoyo ejecutivo incluso cuando surgen desafíos técnicos inevitables.
Data-First Mindset
El machine learning es fundamentalmente dependiente de calidad y cantidad de datos. Los equipos exitosos invierten tiempo significativo en:
Exploración y comprensión profunda de datos disponibles, sus limitaciones, sesgos y gaps antes de modelado.
Data augmentation y feature engineering creativo que transforma datos crudos en representaciones que facilitan aprendizaje algorítmico.
Continuous data quality monitoring que detecta degradación, drift y anomalías que pueden socavar modelos en producción.
Data partnerships estratégicos que enriquecen datasets internos con información externa complementaria.
Experimentación Disciplinada
La ciencia de datos es inherentemente experimental. Los equipos de alto rendimiento implementan prácticas que aceleran iteración mientras mantienen rigor:
Versionado exhaustivo de datos, código, configuraciones y modelos que garantiza reproducibilidad completa de experimentos.
Tracking sistemático de experimentos con todas las configuraciones, métricas y artifacts para permitir comparaciones objetivas.
Failure analysis riguroso que documenta qué no funcionó y por qué, convirtiendo fallos en aprendizajes valiosos.
A/B testing en producción que valida mejoras de modelos con usuarios reales antes de full rollout.
Foco en Productización Desde Día Uno
El "research to production gap" es uno de los mayores obstáculos en proyectos de IA. Las organizaciones exitosas diseñan para producción desde el inicio:
Consideration de requisitos operacionales (latencia, throughput, disponibilidad, costos) durante fase de diseño, no como afterthought post-desarrollo.
CI/CD pipelines que automatizan testing, packaging y deployment, reduciendo fricción para llevar modelos a producción.
Monitoring comprehensivo que rastrea no solo performance técnico (latency, errors) sino también business metrics y data/model drift.
Incident response procedures documentados para casos donde modelos fallan o producen resultados incorrectos en producción.
Gestión de Stakeholders y Expectativas
Los proyectos de IA frecuentemente sufren de expectativas infladas alimentadas por hype mediático. La gestión efectiva incluye:
Educación sobre capabilities y limitaciones reales de AI para stakeholders no técnicos, evitando promesas imposibles.
Comunicación regular de progreso con demos tangibles y explicaciones en lenguaje de negocio, no jerga técnica.
Quick wins tempranos que demuestran valor y construyen credibilidad antes de acometer desafíos más complejos.
Transparencia sobre incertidumbre inherente en modelos probabilísticos y casos donde automatización completa no es apropiada.
El Panorama Competitivo: Diferenciación Estratégica
Con docenas de plataformas compitiendo en el espacio de Data Science y AI, entender los ejes de diferenciación ayuda a una selección informada:
Breadth vs Depth
Algunas plataformas (Databricks, Azure ML, Vertex AI) ofrecen amplitud comprehensiva cubriendo todo el ciclo de vida de datos y ML. Otras (DataRobot para AutoML, Alteryx para preparación de datos) se especializan profundamente en segmentos específicos.
La elección depende de si prefieres "single pane of glass" con integración profunda end-to-end vs "best-of-breed" para cada función con integración mediante APIs y ETL.
Code-First vs Visual-First
Plataformas como SageMaker y Databricks priorizan workflows code-first con notebooks, apropiado para data scientists experimentados. Soluciones como RapidMiner enfatizan construcción visual, democratizando acceso a audiencias menos técnicas.
Equipos híbridos se benefician de plataformas (Dataiku, Azure ML) que soportan ambos paradigmas simultáneamente.
Cloud-Native vs Deployment-Flexible
Soluciones cloud-native (SageMaker, Vertex AI) optimizan para su cloud específico con integración profunda pero menos portabilidad. Plataformas agnósticas (Databricks, DataRobot) se despliegan en múltiples clouds u on-premise, proporcionando flexibilidad a costa de integración menos profunda.
Consideraciones de Seguridad y Compliance
Para organizaciones en sectores regulados o manejando datos sensibles, las consideraciones de seguridad y compliance son críticas:
Protección de Datos Sensibles
Las plataformas deben proporcionar:
Encryption at rest y in transit para proteger datos durante almacenamiento y transmisión.
Fine-grained access controls que permitan especificar quién puede acceder qué datos y modelos con granularidad de columna/fila.
Data masking y anonymization que permitan trabajo con datos de producción en entornos de desarrollo sin exponer información sensible.
Audit logging comprehensivo que rastree todos los accesos y modificaciones para cumplimiento y forense.
Model Governance y Explainability
Regulaciones emergentes (EU AI Act, regulaciones de fair lending) requieren:
Documentation automática de linaje de modelos, datasets utilizados, assumptions y limitaciones.
Explainability techniques (SHAP, LIME, counterfactuals) que permitan explicar decisiones individuales de modelos.
Bias detection y mitigation que identifique y corrija disparate impact en grupos protegidos.
Human-in-the-loop workflows para decisiones de alto riesgo donde automatización completa no es apropiada.
Compliance con Regulaciones Específicas
Para sectores específicos:
GDPR/CCPA: Right to explanation de decisiones automatizadas, data minimization, consent management.
HIPAA (Healthcare): Protected Health Information handling, Business Associate Agreements, encryption standards.
SOC 2 / ISO 27001: Security controls, availability guarantees, incident response procedures.
Model Risk Management (Financial Services): Model validation, stress testing, governance frameworks.
Las plataformas enterprise-grade (Databricks, DataRobot, Azure ML, SageMaker) proporcionan certificaciones y features específicas para facilitar compliance.
ROI y Medición de Impacto
Justificar inversión en plataformas de Data Science y AI requiere frameworks claros para medir retorno:
Métricas de Productividad
Time-to-model: Reducción en tiempo desde idea hasta modelo en producción (baseline vs con plataforma).
Model velocity: Número de modelos desplegados por trimestre, indicador de throughput organizacional.
Reusability: Porcentaje de componentes (features, pipelines, modelos) reutilizados cross-project.
Democratization: Número de usuarios activos y diversidad de roles (data scientists, analysts, engineers).
Métricas de Impacto de Negocio
Revenue impact: Incremento en ventas atribuible a recommendation engines, pricing optimization, lead scoring.
Cost reduction: Ahorros operacionales via automation, optimización de recursos, reducción de churn.
Risk mitigation: Fraude detectado y prevenido, compliance penalties evitadas, downtime reducido.
Customer experience: Mejoras en NPS, satisfaction scores, resolution times atribuibles a IA.
Métricas de Excelencia Técnica
Model performance: Accuracy, precision, recall, AUC-ROC de modelos en producción vs benchmarks.
Model decay rate: Velocidad a la cual modelos degradan, indicador de robustez.
Incident frequency: Número de production incidents relacionados con ML por mes.
Tech debt: Tiempo dedicado a mantener modelos legacy vs desarrollar nuevas capacidades.
Conclusión: Construyendo Ventaja Competitiva mediante Data Science y AI
El ecosistema de herramientas de Data Science y AI en 2025 es más rico y competitivo que nunca. El Top 10 de Dataprix muestra un panorama equilibrado entre plataformas cloud, soluciones de automatización y entornos centrados en gobernanza y colaboración. La elección ideal dependerá del nivel de madurez analítica, los recursos técnicos disponibles y la estrategia de datos de cada organización.
La selección de la plataforma apropiada de Data Science y AI es una decisión estratégica que impacta no solo eficiencia técnica sino también velocidad de innovación, capacidad de atraer talento y habilidad de adaptarse conforme la tecnología evoluciona.
Para grandes empresas con recursos significativos que buscan plataformas comprehensivas enterprise-grade, Databricks, DataRobot, Amazon SageMaker y Azure ML representan opciones probadas con ecosistemas maduros y soporte de clase mundial. IBM watsonx aporta el componente ético indispensable
Organizaciones que priorizan democratización y accesibilidad para audiencias no técnicas encontrarán en RapidMiner y Dataiku interfaces que empoderan citizen data scientists sin sacrificar capacidades avanzadas para expertos.
Equipos conscientes de costos o en etapas tempranas pueden beneficiarse del poder de KNIME y H2O.ai, herramientas open source que, aunque no hayan entrado en este ranking, proporcionan capacidades sofisticadas sin barreras de licenciamiento, permitiendo escalar inversión conforme la organización madura.
Para casos de uso especializados, las opciones cloud-native (Vertex AI para NLP/visión state-of-the-art, SageMaker para escala extrema) proporcionan integración profunda con servicios complementarios que aceleran implementación.
Más allá de la herramienta específica seleccionada, el éxito requiere enfoque holístico que combine tecnología con:
- Estrategia clara que alinee iniciativas de IA con objetivos empresariales medibles
- Data foundations sólidas que garanticen disponibilidad de datos de calidad
- Talento apropiado con mezcla de skills técnicos y comprensión de negocio
- Cultura data-driven que valore experimentación y decisiones basadas en evidencia
- Procesos MLOps maduros que garanticen confiabilidad operacional
El campo de Data Science y AI continúa evolucionando rápidamente. Las organizaciones exitosas no solo adoptan herramientas actuales sino cultivan capacidad de aprendizaje continuo, experimentación disciplinada y adaptación ágil conforme emergen nuevas técnicas, arquitecturas y posibilidades.
La pregunta ya no es si adoptar Data Science y AI, sino cómo hacerlo estratégicamente para construir ventaja competitiva sostenible. Con la plataforma apropiada, el talento correcto y la ejecución disciplinada, las organizaciones pueden transformar datos de commodity en su activo más valioso y fuente principal de innovación.
