
Spark es un framework open source de Apache Software Foundation para procesamiento distribuído sobre clusters de ordenadores de grandes cantidades de datos, ideado para su uso en entornos de Big Data, y creado para mejorar las capacidades de su predecesor MapReduce.
Spark hereda las capacidades de escalabilidad y tolerancia a fallos de MapReduce, pero lo supera ampliamente en cuanto a velocidad de procesamiento, facilidad de uso y capacidades analíticas.
Apache Spark se ejecuta sobre una JVM (máquina virtual de Java) y soporta diversos lenguajes como Java, Scala, Python, Clojure y R para el desarrollo de aplicaciones que pueden realizar operaciones de Map y Reduce interactuando con el core de Spark a través de su API.
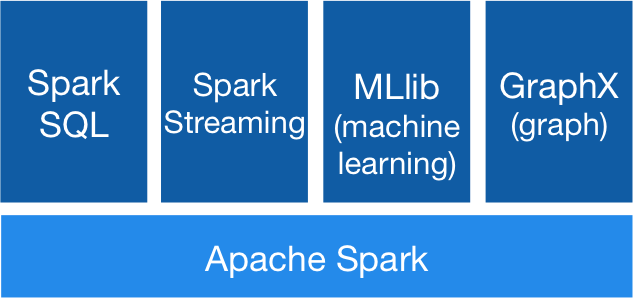
Adicionalmente a la API del Core, a un nivel más alto, el llamado Ecosistema de Spark proporciona librerías que proporcionan capacidades añadidas de Machine Learning y Analítica para Big Data.
Las librerías más importantes de Spark son:
- Spark Streaming: para procesamiento de datos de streming en tiempo real
- Spark SQL + DataFrames: proporciona una capa para poder conectar con datos de Spark a través de una API JDBC, permitiendo así ejecutar consultas de estilo SQL a herramientas tradicionales de BI y visualización de datos.
- Spark MLlib: librería de Aprendizaje Automático, que permite utilizar algoritmos y utilidades de Machine Learning.
- Spark GraphX: es una API para generación de gráficas y computación paralela de gráficos.
- Log in to post comments
