 La orientación de Microstrategy 9 con el Data Mining es integrarlo totalmente en su plataforma de Business Intelligence y que no sea un producto aparte como en muchos otros fabricantes (lo que nos obliga a realizar los análisis en un sistema paralelo). Esta integración se realiza a traves de las métricas predictivas, que estaran disponibles en el sistema como un elemento mas del sistema de BI.
La orientación de Microstrategy 9 con el Data Mining es integrarlo totalmente en su plataforma de Business Intelligence y que no sea un producto aparte como en muchos otros fabricantes (lo que nos obliga a realizar los análisis en un sistema paralelo). Esta integración se realiza a traves de las métricas predictivas, que estaran disponibles en el sistema como un elemento mas del sistema de BI.
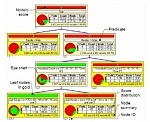
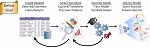
Ademas, soporta el estandar de la industria PMML (Predictive Model Markup Language), lo que nos permite importar modelos de data mining desde otras plataformas y crear de forma automatica en el repositorio de metadatos las metricas predictivas. Recordemos que PMML es un estandar de la industria en XML desarrollado por el Data Mining Group(DMG) para describir los modelos predictivos. En su desarrollo han participado los principales fabricantes de software de datamining, incluyendo Microstrategy. Este estandar soporta un gran numero de algoritmos de data mining, como son las Redes Neuronales, Clustering, Regresion, Arboles de Decision y Asociacion. PMML se puede generar en las principales aplicaciones de DM como son SAS®, SPSS®, Microsoft®, Oracle®, IBM®, KXEN™, ANGOSS y otros. Microstrategy es la primera plataforma BI que soporta el estandar, y su plataforma incluye, de forma integrada con el resto de elementos, la creación de modelos y la distribución de los resultados a los usuarios a traves del visor de modelos previsibles, que presenta unas características e información gráfica diferente según el tipo de análisis que estemos realizando. Los resultados de los estudios se pueden incluir como un elemento mas en los Dashboards de analisis...