
Segmentación de clientes basada en RFM con SAS
- Lee más sobre Segmentación de clientes basada en RFM con SAS
- Inicie sesión para enviar comentarios
 El análisis RFM es una conocida técnica de segmentación del clientes. El modelo toma en consideración tres métricas:
El análisis RFM es una conocida técnica de segmentación del clientes. El modelo toma en consideración tres métricas:
1) Ticket medio de compra (Money)
2) Frecuencia de compra (Frecuency)
3) Tiempo qué hace que no compra (Recency)
En base a estas métricas clasifico a los clientes..
 Desde el punto de vista puramente técnico, se denomina Big Data a los sistemas de información que sobrepasan las capacidades de las tecnologías tradicionales basadas principalmente en base de datos relacionales.
Desde el punto de vista puramente técnico, se denomina Big Data a los sistemas de información que sobrepasan las capacidades de las tecnologías tradicionales basadas principalmente en base de datos relacionales. 


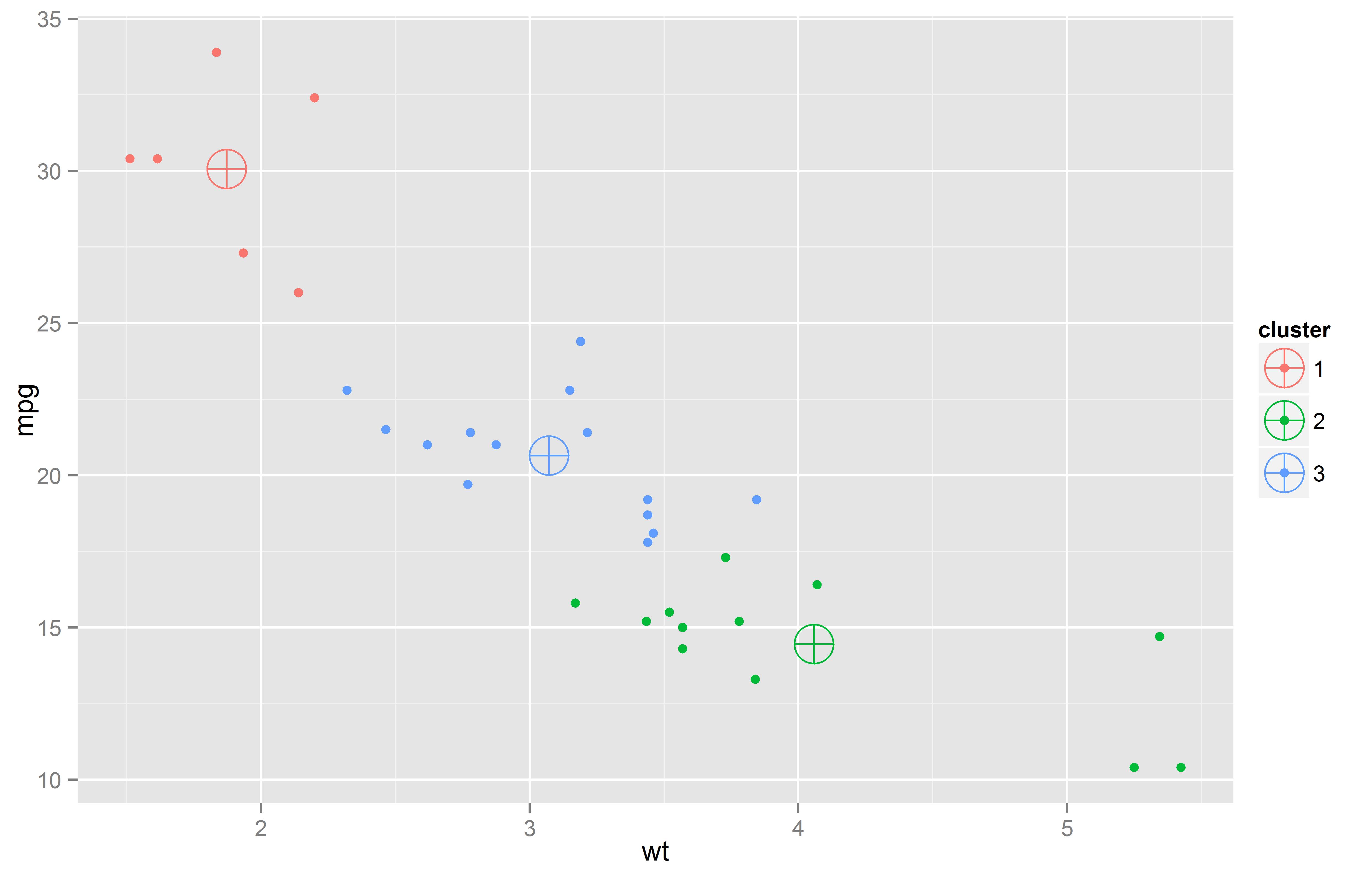
 Los outliers, (o "valores extremos"), son un tema siempre presente cuando se analizan datos, sin importar el origen de los mismos. Aquí se presenta un análisis didáctico y visual hecho con el lenguaje R..
Los outliers, (o "valores extremos"), son un tema siempre presente cuando se analizan datos, sin importar el origen de los mismos. Aquí se presenta un análisis didáctico y visual hecho con el lenguaje R..
 La semana pasada asistí a un encuentro de RugBcn, el Grupo de Usuarios de R de Barcelona, que tenía por objetivo mostrar cómo crear informes automáticos directamente desde R gracias a las librerías rmarkdown y knitr. El título del evento era 'Automatic Reporting with rmarkdown'.
La semana pasada asistí a un encuentro de RugBcn, el Grupo de Usuarios de R de Barcelona, que tenía por objetivo mostrar cómo crear informes automáticos directamente desde R gracias a las librerías rmarkdown y knitr. El título del evento era 'Automatic Reporting with rmarkdown'.
