Recopilación de artículos sobre Oracle
Recopilación de artículos sobre Oracle Dataprix 1 Agosto, 2008 - 09:18En este libro online vamos recopilando los artículos y entradas del foro y de blogs más interesantes sobre bases de datos Oracle y herramientas relacionadas.
Gracias a todos los usuarios de Dataprix que al compartir su conocimiento hacen que algunas cosas nos resulten más fáciles a los demás.
Libros de Administración Oracle (DBA) y PL/SQL
¿Quieres profundizar más en PL/SQL de Oracle o en administración de bases de datos Oracle? Puedes hacerlo consultando alguno de estos libros de Oracle.
Los libros que ves a continuación son una selección de los que a mi me parecen más interesantes para aprender administración y desarrollo PL/SQL, teniendo en cuenta precio y temática, espero que te puedan ser de utilidad:
- eBooks de Oracle gratuítos para la versión Kindle, o muy baratos (menos de 4€):
- Libros recomendados de Oracle
Administración de la base de datos
Administración de la base de datos Dataprix 8 Septiembre, 2009 - 09:46AWR Formatter para DBA's de Oracle
AWR Formatter para DBA's de Oracle Oscar_paredes 2 May, 2011 - 20:09Todo aquel, especialmente DBA's de Oracle, que suele mirar informes de rendimiento AWR en Oracle para analizar problemas de rendimiento, suele tener su propio procedimiento de lectura y aproximación a todos los datos que nos muestra este informe, pero como DBA siempre he echado en falta alguna herramienta que te facilite la lectura de todos los datos.
La he encontrado! “AWR Formatter” desarrollado por el Oracle DBA Tyler Muth permite facilitar esta lectura. Fantástico, debéis probarlo.
AWR Formatter es una extensión de Chrome (fichero con extensión .crx) gratuita que una vez instalado en el navegador, cada vez que visualizas un report AWR en html, te ofrece la posibilidad de formatearlo para ayudarte a ver toda su información.
Una vez formateado el texto, el HTML se ve en el navegador en distintas pestañas. Destaco las siguientes funcionalidades que te ofrece el formato añadido:
- Posibilidad de realizar dinámicamente conversiones de KB/MB/GB/TB en los distintos indicadores
- Posibilidad de consultar el significado de un determinado evento de espera, parámetro, etc… (esto es realmente útil)
- Tablas formateadas ordenables, casi como un Excel…
- Posibilidad de ver el texto de los comandos SQL’s…
.jpg)
Una de las pestañas llamada “Observations”, pretende dar indicaciones de la lectura del report, pero es una primera aproximación, y por supuesto, cada Oracle DBA debe seguirlo según su responsabilidad.
Espero que lo disfrutéis,
Oscar Paredes
IT Manager
Oracle DBA
Acceso remoto mediante DBLink de Oracle
Acceso remoto mediante DBLink de Oracle Carlos 12 Marzo, 2007 - 23:18Para acceder desde una base de datos Oracle a objetos de otra base de datos Oracle la manera más sencilla es utilizar un DBLink (que sea la más sencilla no significa que siempre sea la más aconsejable, el abuso de los dblinks puede generar muchos problemas, tanto de rendimiento como de seguridad)

Para ello es necesario, con un usuario que posea el privilegio CREATE DATABASE LINK, crear el DBLINK en la base de datos Oracle origen (A) mediante una sencilla sentencia como la siguiente:
SQL> Create database link LNK_DE_A_a_B connect to USUARIO identified by CONTRASEÑA USING 'B';
'LNK_DE_A_a_B' es el nombre del link, 'USUARIO' y 'CONTRASEÑA' son los identificadores del usuario que utilizará el database link para conectarse, los permisos del cual heredarán todos los accesos a través del db link, y B es el nombre de la instancia de la base de datos.
A través del dblink se puede conectar con los objetos de la base de datos remota con los permisos que tenga el usuario que se ha proporcionado en la sentencia de creación.
Para referenciar un objeto de la base de datos remota se ha de indicar el nombre del objeto, concatenado con el carácter '@' y el nombre que se le ha dado al DBLINK.
Ejemplo de consulta de select sobre una tabla a través de una database link:
SQL> select * from TABLA@LNK_DE_A_a_B
Para ampliar información sobre la creación y utilización de database links se puede consultar la documentación de Oracle que se proporciona online en documentacion oracle create database.
Si lo que se quiere es acceder a una base de datos de otro fabricante, se puede crear el DBLink utilizando Heterogeneous Services. Se puede consultar cómo hacerlo con SQLServer en el artículo Heterogeneous services: Conexión desde Oracle a SQLServer
Libros de Administración Oracle (DBA) y PL/SQL
¿Quieres profundizar más en PL/SQL de Oracle o en administración de bases de datos Oracle? Puedes hacerlo consultando alguno de estos libros de Oracle.
Cuestiones sobre los dblinks de Oracle
Cuestiones sobre los dblinks de Oracle Carlos 19 Octubre, 2009 - 16:08Abro este tema a partir del artículo Acceso remoto mediante DBLink de Oracle para que podamos comentar dudas y experiencias sobre la creación y utilización de database links de Oracle.
no tengo el nombre de usuario y contraseña de oracle sql 9i
hola, queria ver si hay alguna manera de accesar con algun nombre de usuario y contraseña universal o algo asi porque acabo de instalar el sql plus, pero no tengo esos datos. gracias y espero me pueda ayudar alguien
- Inicie sesión para enviar comentarios

Entrar en Oracle sin password
Puedes ver como entrar en SQLPlus con un usuario Oracle con rol sysdba en:
http://www.dataprix.com/entrar-en-sqlplus-como-dba-sin-introducir-passw…
Carlos Fernández
Analista de sistemas
- Inicie sesión para enviar comentarios
consulta DBLINKS. paquetes y variable Global_NAME
Estimados, soy nuevo en oracle y estoy haciendo una conexión entre dos servidores pero al momento de compilar mis paquetes me da el error ORA-04052.
Variables:
DBLINKS
Variable Global_name = FALSE;
Tengo el sinonimo:
CREATE SYNONYM r_csh_ppm
FOR awunadm.csh_ppm@toawas
create database link TOAWAS
connect to awunadm identified by awunadm123 using
' (DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 172.20.130.2)(PORT = 1521))
)
(CONNECT_DATA =
(SID = ASYWDB)
(SERVER = DEDICATED)
(GLOBAL_NAME = ASYWDB.UNCTAD.ORG)
)
)
'
EL paquete hace un
select * from r_csh_ppm
Al compilar devuelve el error ORA-04052, me pueden ayudar con esto?
Gracias de antemano
- Inicie sesión para enviar comentarios
Entiendo que desde SQLPlus la
Entiendo que desde SQLPlus la SELECT sobre el sinónimo te funciona correctamente, y el problema lo tienes al intentar utilizar este sinónimo dentro de un PROCEDURE.
Supongo que has escrito global_name (sin la 's') por error. De todas maneras en Oracle global_names puedes encontrar una explicación sobre los GLOBAL_NAMES(S) y el DB_DOMAIN.
- Por si acaso asegúrate de que el parámetro GLOBAL_NAMES está a FALSE en ambas bases de datos.
- Supongo que el error te habrá devuelto el texto:
- ORA-04052 error occurred when looking up remote object %s%s%s%s%s
Cause: An error has occurred when trying to look up a remote object.
Action: Fix the error. Make sure the remote database system has run KGLR.SQL to create necessary views used for querying/looking up objects stored in the database.
En las versiones actuales de BD, este script ya no se llama KGLR.SQL. Si no encuentras este fichero busca catlog.sql y catproc.sql. Aunque en teoría se ejecutan al instalar la base de datos, puedes probar a ejecutarlos en las dos bases de datos, y puede que así se resuelva el problema
- Inicie sesión para enviar comentarios
Hola se que usted es esperto
Hola se que usted es esperto en Oracle tengo la siguiente duda:
mi trabajo o tarea es hacer un replica de una base de datos en oracle 10g express y para ello necesito hacer un database link pero antes
necesito modificar los archivos de la siguiente ruta:
C:\oraclexe\app\oracle\product\10.2.0\server\NETWORK\ADMIN dentro de esta direccion esta el archivo tnsnames.ORA
y la verdad no se cual de estos codigos voy a mo dificar (osea si voy a modificar o agregar nuevas lineas) ALUMNO-PC3 es el nombre de mi maquina y ALUMNO-PC4 EL de la otra maquina. estos son los codigos que hay dentro de este archivo:
XE =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = ALUMNO-PC3)(PORT = 1521)) // en la otra maquina aparece ALUMNO-PC4
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = XE)
)
)
EXTPROC_CONNECTION_DATA =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE))
)
(CONNECT_DATA =
(SID = PLSExtProc)
(PRESENTATION = RO)
)
)
ORACLR_CONNECTION_DATA =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE))
)
(CONNECT_DATA =
(SID = CLRExtProc)
(PRESENTATION = RO)
)
)
LO MISMO TIENEN LAS DOS MAQUINAS dime por favor como quedaria modificado este archivo en ALUMNO-PC3 Y ALUMNO-PC4.
tambien lei que el archivo listener pero no se si tambien se va a modificar y que parte se modificara. este es el codigo:
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(SID_NAME = PLSExtProc)
(ORACLE_HOME = C:\oraclexe\app\oracle\product\10.2.0\server)
(PROGRAM = extproc)
)
(SID_DESC =
(SID_NAME = CLRExtProc)
(ORACLE_HOME = C:\oraclexe\app\oracle\product\10.2.0\server)
(PROGRAM = extproc)
)
)
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE))
(ADDRESS = (PROTOCOL = TCP)(HOST = ALUMNO-PC3)(PORT = 1521))
)
)
DEFAULT_SERVICE_LISTENER = (XE)
Y me gustaria como quedaria creado el dblink que necesito
ambas maquinas tienen instalado el oracle 10g y los usuarios son para ALUMNO-PC3 es HR y contraseña: QWERTY. y para ALUMNO-PC4 es ALUMNOS Y HR y la contraseña para ambos es recursos. y como hacer una consulta una vez creado el database link.
OJALA Y ME RESPONDAS CLARO Y CONCISO YO SOY NOBATO EN ESTO GRACIASSSSSSSS
ANDRES.....
- Inicie sesión para enviar comentarios
En el TNSNAMES se agregan las
En el TNSNAMES se agregan las 'referencias' a los servidores de bases de datos con los que se quiera conectar desde la máquina. Como en tu caso quieres hacer un DBLINK desde ALUMNO-PC3 hasta ALUMNO-PC4 tendrías que modificar el TNSNAMES de ALUMNO-PC3 con los datos de conexión a la BD de ALUMNO-PC4:
XE =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = ALUMNO-PC4)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = XE)
)
)
En principio, si vas a hacer un dblink entre dos BBDD Oracle no tienes porqué modificar la configuración del listener.
Tal como comento en el post Acceso remoto mediante DBLINK de Oracle, para crear después el database link en la BD origen (la de ALUMNO-PC3), deberías ejecutar con un usuario con suficientes privilegios una sentencia como la siguiente:
create database link LINK_de_PC3_a_PC4 connect to ALUMNOS identified by recursos;Y para hacer desde la BD de ALUMNO-PC3 una select sobre una tabla de la BD de ALUMNO-PC4:
select * from TABLA_DE_PC4@LINK_de_PC3_a_PC4;
- Inicie sesión para enviar comentarios
Carlos espero pueda ayudarme
Carlos espero pueda ayudarme con este problemita:
estoy ejecutando el siguiente código desde una BD Oracle 9i para consultar datos de una base de datos en 10g mediante un debelink llamado suiscen:
begin
select *
from persona@suiscen;
end;
pero me genera el siguiente error:
ORA-06550: line 4, column 6:
PL/SQL: ORA-04052: error occurred when looking up remote object SERECE.PERSONA@SUISCEN
ORA-00604: error occurred at recursive SQL level 1
ORA-06502: PL/SQL: numeric or value error
ORA-06512: at line 64
ORA-24757: duplicate transaction identifier
ORA-02063: preceding 4 lines from SUISCEN
ORA-06550: line 3, column 1:
este error solo se presenta cuando esta entre el BEGIN y el END
he investigado y al parecer es un bug y me indican debo migra mi BD que esta en 9i a 10G sera que existe otra salida?
Carlos de antemano mil gracias en lo que me pueda asesorar.
- Inicie sesión para enviar comentarios
Seguro que es un bug? Si
Seguro que es un bug? Si quieres puedes enlazar el lugar donde comentan lo del bug y le echamos un vistazo. Ahora no tengo disponible una BD 9i para probarlo, pero es la primera noticia que tengo de que exista este problema entre versiones.
A mi lo que me parece más indicativo es el error ORA-24757: duplicate transaction identifier. Podría ser que según cómo estén configuradas las BBDD te diera problemas utilizar a la vez el DBLINK desde varios lugares. Asegúrate de que no tengas abierta ninguna otra conexión que utilice el link y vuelve a probar con el Procedure. Para la prueba utiliza el mismo procedure que indicas, no sea que sea el mismo procedure el que abra demasiados enlaces.
Las dos bases de datos están en el mismo servidor? Eso también podría darte algún problema de identificadores.
- Inicie sesión para enviar comentarios
Carlos gracias por la pronta
Carlos gracias por la pronta respuesta....bueno lo del enlace fue tanto lo que busque que no guarde dichos enlaces pero los buscare nuevamente...
las bases de datos están en distintos servidores y lo que me faltó comentar es que el servidor donde esta la BD en 10g esta en modo RAC (Real Apliccation Server) .
Es decir el codigo o procedure funciona correctamente hacia los servidores con Oracle 9i normal y el error me aparece con los dblinks que apuntan hacia las BD que están en RAC.
- Inicie sesión para enviar comentarios
Lo de RAC es un detalle
Lo de RAC es un detalle importante, esas cosas se dicen antes ;)
Si no lo has hecho ya deberías comprobar los valores de los parámetros OPEN_LINKS y OPEN_LINKS_PER_INSTANCE de la BD que está en RAC para saber cuántos dblinks pueden abrirse como máximo en una sesión o una instancia de esta base de datos.
El problema podría ser simplemente que superaras este límite al utilizar el DBLINK desde el procedure.
- Inicie sesión para enviar comentarios
Hola Carlos... te saluda
Hola Carlos... te saluda Ivan, tengo una consulta:
Estoy tratando de crear una conexion DBLINK desde Oracle 11g para conectarme a SQL Server 2008.
Para hacer la conexion utilizo un Driver ODBC 11 de oracle... y la conexion se hace con éxito.
Pero al momento de hacer una consulta (SELECT, INSERT, UPDATE), me sale el siguiente error:
ORA-00942: la tabla o vista no existe
[Microsoft][ODBC SQL Server Driver][SQL Server]El nombre de objeto 'TM0000000001.AREA' no es válido. {42S02,NativeErr = 208}[Microsoft][ODBC SQL Server Driver][SQL Server]No se puede preparar la instrucción o instrucciones. {42000,NativeErr = 8180}
ORA-02063: 2 lines precediendo a SASERVER_LINK
00942. 00000 - "table or view does not exist"
Favor ayudarme para solucionar este problema y poder hacer mis consultar respectivas... gracias
- Inicie sesión para enviar comentarios
Hola Iván Parece sólo que no
Hola Iván
Parece sólo que no te reconoce el nombre de la tabla. ¿Puede ser que te falte el propietario de la tabla de SQL Server? Si la base de datos es TM0000000001 el nombre completo sería 'TM0000000001.dbo.AREA', o 'TM0000000001.ivan.AREA' si fuera del usuario ivan.
Saludos,
- Inicie sesión para enviar comentarios
Carlos ya hice todo lo que me
Carlos ya hice todo lo que me indicaste y el databaselink si lo crea pero al querer consultar manda el siguiente error:
ORA-02019: no se ha encontrado la descripción de la conexión para la base de datos remota
y e buscado este error pero no encuentro la solucion y lo hice tal como me dijistes.
contesta porfa. de ante mano Gracias... ATTE Andres...
- Inicie sesión para enviar comentarios
Puede que la base de datos
Puede que la base de datos tenga el global_names activado, y al utilizar el dblink necesites especificar el nombre del dominio. El tema de los global names lo explico un poco en esta entrada del foro.
Comprueba cuál es el DB_DOMAIN de la base de datos y agrégalo al nombre del DBLINK al utilizarlo. Si utilizas una herramienta visual como SQLDeveloper, por ejemplo, seguramente en el nombre del dblink ya te indicará el nombre completo que tienes que utilizar.
Prueba a hacer esto:
SQL> select * from global_name;GLOBAL_NAME -------------------XE.MIDOMINIO.COM
Lo que te ponga en lugar de MIDOMINIO.COM agregalo en la SELECT del database link:
select * from TABLA_DE_PC4@LINK_de_PC3_a_PC4.MIDOMINIO.COM;Suerte!!
- Inicie sesión para enviar comentarios
Hola, ya hice lo del dominio,
Hola, ya hice lo del dominio, como dominio me aparecia solo XE despues de eso yo cambie el dominio a mibd.dominio.com de la sig manera
-------------------------------------
SQL> alter database rename GLOBAL_NAME to MIBD.DATAPRIX.COM;
Database altered.
-------------------------------------
ya que no me regreso algun domino la primer parte, use lo sig.
------------------------------------
select * from Datos_Personales@LINK_de_pc-3_a_pc-4.MIBD.DOMINO.COM;
y me mando el mismo error (ora-0219) la verdad me gustaria que nos siguieras orientando por que hasta ahora tu apoyo ha sido de mucha ayuda.clarificamos muchas dudas que teniamos probando todo lo que nos has enviado y leyendo los foros que tienes en tu pagina(www.dataprix.com) sin mas que decir me despido deseandole una muy buena tarde.
- Inicie sesión para enviar comentarios
Si has hecho el alter
Si has hecho el alter database como comentas, el dominio que le has asignado a la BD es DATAPRIX.COM
Entonces la select te quedaría:
SELECT * FROM Datos_Personales@LINK_de_pc-3_a_pc-4.DATAPRIX.COMRecuerda que al link sólo le has de agregar el dominio, el nombre de la base de datos no lo tienes que incluir.
Venga, que ya falta menos!!
- Inicie sesión para enviar comentarios
carlos no sirve mi db link ya
carlos no sirve mi db link ya hicimos todos como nos indicaste
y nada pero marca el mismo error.
el db link si lo crea pero al hacer la consulta marca el mismo error no se que sea gracias por la ayuda.
Andres.............
- Inicie sesión para enviar comentarios
No lo hemos especificado,
No lo hemos especificado, pero entiendo que el alter database para modificar el dominio lo has hecho en la base de datos remota (PC4). Otra cosa que habría que hacer es modificar el TNSNAMES de la BD local (la de PC3) teniendo en cuenta el nuevo dominio:
XE.DATAPRIX.COM =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = ALUMNO-PC4)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = XE)
)
)
Y después recrea de nuevo el dblink, incluyendo también el dominio:
SQL> dropdatabase link LINK_de_PC3_a_PC4;
SQL> create database link LINK_de_PC3_a_PC4.DATAPRIX.COM connect to ALUMNOS identified by recursos;
SQL> select * from TABLA_DE_PC4@LINK_de_PC3_a_PC4.DATAPRIX.COM;Enlazo otro post donde también comento cosas sobre los Global Names, por si sirve de ayuda.
Espero que ahora salga todo bien..
- Inicie sesión para enviar comentarios
Tengo dos bases de datos
Tengo dos bases de datos distintas A y B. Tengo un DBLink DBL_BA creado en B que apunta a las tablas creadas en A.
Funciona sin problemas, accedo a los datos de las tablas de A y creo vistas materializadas con esos datos. Mi problema
es que intento que dichas vistas sean de tipo FAST, es decir, que su refresco sea de tipo incremental, pues el volumen de
datos que tengo que manejar es muy grande.
Para ello creo LOGS en las tablas de A:
CREATE MATERIALIZED VIEW LOG ON esquemaA.tabla1
WITH ROWID;
CREATE MATERIALIZED VIEW LOG ON esquemaA.tabla2
WITH ROWID;
Ahora creo la vista materializada tipo FAST a través del dblink en mi base de datos B:
CREATE MATERIALIZED VIEW esquemaB.vmtablas
PARALLEL BUILD IMMEDIATE
REFRESH FAST
AS
SELECT T1.ROWID "CN_ID_1", T2.ROWID "CN_ID_2", T1.DC_NOMBRE, T2.DC_NOMBRE
FROM tabla1@DBL_BA T1, tabla2@DBL_BA T2
WHERE T1.CN_ID = T2.CN_ID;
Obteniendo el siguiente error:
ORA-12015: no se puede crear una vista materializada de refrescamiento rápido a partir de una consulta compleja
Tengo todos los permisos necesarios, he probado a crear sinónimos de las tablas de A, pero sigo obteniendo el mismo
resultado...
Sin embargo, si creo la vista materializada sin utilizar el dblink, es decir, sobre la propia base de datos A,
me la crea sin problemas.
CREATE MATERIALIZED VIEW esquemaA.vmtablas
PARALLEL BUILD IMMEDIATE
REFRESH FAST
AS
SELECT T1.ROWID "CN_ID_1", T2.ROWID "CN_ID_2", T1.DC_NOMBRE, T2.DC_NOMBRE
FROM tabla1 T1, tabla2 T2
WHERE T1.CN_ID = T2.CN_ID;
Espero puedan ayudarme :). Gracias por adelantado
- Inicie sesión para enviar comentarios
La creación de vistas
La creación de vistas materializadas con el método de refresco FAST tiene bastantes restricciones, y el error ORA-12015 que te devuelve parece referirse precisamente a eso.
En el artículo Vistas materializadas de Oracle para optimizar un Datawarehouse incluyo un enlace a la documentación de Oracle donde habla de las restricciones para el método FAST. Si no lo has hecho ya, échale un vistazo. De todas maneras copio las restricciones generales que documenta Oracle:
General Restrictions on Fast Refresh
The defining query of the materialized view is restricted as follows:
-
The materialized view must not contain references to non-repeating expressions like
SYSDATEandROWNUM. -
The materialized view must not contain references to
RAWorLONGRAWdata types. -
It cannot contain a
SELECTlist subquery. -
It cannot contain analytical functions (for example,
RANK) in theSELECTclause. -
It cannot contain a
MODELclause. -
It cannot contain a
HAVINGclause with a subquery. -
It cannot contain nested queries that have
ANY,ALL, orNOTEXISTS. -
It cannot contain a
[START WITH ...] CONNECT BYclause. -
It cannot contain multiple detail tables at different sites.
-
On-commit materialized view cannot have remote detail tables.
-
Nested materialized views must have a join or aggregate.
Como puedes ver parece que con el tipo de refresco FAST y la opción ON-COMMIT no se pueden utilizar tablas remotas en la vista. Pueba a definir la vista forzando la opción de refresco ON-DEMAND, y yo creo que te funcionará.
Ya nos contarás..
- Inicie sesión para enviar comentarios
Efectivamente, la opción
Efectivamente, la opción ON-COMMIT me daba problemas, la cambié a ON-DEMAND, pero el error persistía :(
Me dijeron que podía ser un problema con la versión de oracle y haciendo pruebas descubrí que así era. Ejecutando las Vistas Materializadas en una versión 11g no daba problemas (yo estaba usando la 9i para hacer las pruebas).
Muchas gracias por la ayuda :)
- Inicie sesión para enviar comentarios
Estimado Carlos: Yo podria
Estimado Carlos:
Yo podria atrapar un error de conexion utilizando dblink entre una base de datos y otra para luego indicarle a esa conexion que internte conectarse de nuevo. Lo que deseo es que si un hay un problema conectandome a la base de datos utiliwando dblink el procedo de reconexion se haga automaticamente en un intervalo de tiempo para garantizar que la extraccion de datos se haga siepre.
- Inicie sesión para enviar comentarios
Te entiendo, yo he tenido
Te entiendo, yo he tenido problemas al utilizar un dblink para conectar con un MySQL y cargar datos en el Data Warehouse corporativo. Funcionaba, pero también fallaba demasiado a menudo, y además cuando fallaba se quedaba frito y ya había manera de hacer nada.
En aquel momento no encontré ninguna manera de reconectar automáticamente el link, por lo que no puedo darte una solución en este sentido, no sé si se puede llegar a hacer. Cuando pueda investigaré un poco, o a ver si alguien más nos ayuda.
Lo que sí te puedo contar es que para que el error de conexión no me dejara vacías las tablas destino, lo que hice fue utilizar vistas materializadas en la stage area del DWH, así si la conexión fallaba simplemente la tabla no actualizaba los datos de ese día y no me paraba la carga. Después tenía un control adicional que me informaba si el día se había cargado o no. Supongo que tú lo solucionas tratando el error directamente en la ETL.
Bueno, ya nos contarás si averiguas algo tú antes, el tema es interesante..
- Inicie sesión para enviar comentarios
Hola, mi pregunta es
Hola,
mi pregunta es sencilla. He leído que cuando se hace una select remota a una tabla mediante dblink, internamente
se inicia una trasacción distribuida.
Uso vistas que realizan select remota a otra/s tablas mediante dblink, ¿es necesario poner COMMIT
después del select para cerrar esta trasacción o todo esto lo hace Oracle internamente?.
Gracias
- Inicie sesión para enviar comentarios
Para hacer una select no es
Para hacer una select no es necesario hacer un commit. Independientemente de si se utilizan database links o no, si no modificas datos de ninguna tabla no hay ninguna razón para hacer un commit.
Si Oracle internamente inicia una transacción distribuída, también la cerrará internamente, no tienes que preocuparte por eso.
- Inicie sesión para enviar comentarios
Hola. Tengo un error
Hola.
Tengo un error extraño de bbdd que no se como encajar:
Tengo un package compilado en un oracle 8i, lo llamo desde una app deployada en un jboss 4.5 y el 90% de las veces funciona OK. De vez en cuando falla devolviendo: "ORA-01007: la variable no se encuentra en la lista de selección"... Al entrar en el package y compilar de nuevo funciona OK... no le veo explicación.. salvo que el package utiliza un DBLink que de vez en cuando falla, pero NO en ese procedure !
ALguna explicación ? Muchas gracias.
- Inicie sesión para enviar comentarios
Hola Juan No creo que sea un
Hola Juan
No creo que sea un problema del dblink. Primero porque lo que tú mismo dices de que el database link está en otro procedure, y segundo porque si fallara te devolvería otro tipo de error, más de comunicaciones, conexiones, servidores remotos y esas cosas.
Revisa el procedure y las SELECTS que haces en el mismo. Si te falla sólo a veces tiene que ser que a veces la sentencia devuelve algo que no esperas, o no devuelve nada..
ORA-01007 variable not in select list
Cause: A reference was made to a variable not listed in the SELECT clause.
In OCI, this can occur if the number passed for the position parameter is less than one or greater than the number of variables in the SELECT clause in any of the following calls: DESCRIBE, NAME, or DEFINE.
In SQL*Forms or SQL*Report, specifying more variables in an INTO clause than in the SELECT clause also causes this error.
Action: Determine which of the problems listed caused the problem and take appropriate action.
- Inicie sesión para enviar comentarios
Hola Carlos, Estoy trabajando
Hola Carlos,
Estoy trabajando por primer vez con los dblinks en Oracle On Demand y tengo algunas dudas:
1.- Es necesario que las BD que quiera conectar tengan la misma versión??
2.- Tienen que estar en el mismo servidor las bases que quiera conectar??
Gracias por tu ayuda
- Inicie sesión para enviar comentarios
Laila wrote: Estoy trabajando
[quote=Laila] Estoy trabajando por primer vez con los dblinks en Oracle On Demand y tengo algunas dudas: 1.- Es necesario que las BD que quiera conectar tengan la misma versión?? 2.- Tienen que estar en el mismo servidor las bases que quiera conectar?? [/quote]
Las bases de datos pueden tener versiones diferentes, pero dentro de unos límites, en este comentario ya surgió esta cuestión. En principio no deberías tener problemas entre bases de datos Oracle de versiones 8i, 9i, 10g y 11g.
Sobre los servidores, te confirmo que las bases de datos pueden estar en diferentes servidores.
- Inicie sesión para enviar comentarios
Hola Carlos, tengo un
Hola Carlos, tengo un problema, estoy trabajando con un dblink el cual es ejecutado dentro de un procedure. Cuando ejecuto el procedure directamente del plsql no es mucho el tiempo de respuesta pero sin embargo cuando lo ejecuto desde un form demora demasiado o a veces no responde.
Que puede ser y que podría hacer para optimizarlo?
- Inicie sesión para enviar comentarios
Hola podría ayudarme con una
Hola podría ayudarme con una consulta que tengo sobre los dblink
Tengo un paquete Cl_pruebas1 el cual llama aun procedimiento pt_pruebas.
En el procedimiento pt_pruebas realizo varios select e insert a unas tablas que estan en una base ppt
Select *
From tabla1@ppt.dd.com
Where Customer_Id = Cn_Customerid ;
Insert Into tabla1@ppt.dd.com
En este procedimiento pt_pruebas cierro los dblink y luego en el paquete principal Cl_pruebas1 realizo un commit a todo, pero el problema es que no se estan actualizando las tablas (tabla1@ppt.dd.com) que estan en la base ppt, solo se actualizan para la otra base qppt, no entiendo cual podría ser el problema.
- Inicie sesión para enviar comentarios
La verdad es que yo siempre
La verdad es que yo siempre lo he hecho al revés, siempre intento utilizar los dblinks para hacer selecciones de datos, y las inserciones hacerlas 'en local', es la manera más segura, no tienes problemas adicionales con los permisos y te ahorras estos problemas.
Si puedes haz el INSERT desde la BD 'ppt' utilizando un dblink para seleccionar los datos de la BD donde tienes el procedimiento pt_pruebas.
Puede que te vaya bien echarle un vistazo al tema Insert entre bases de datos remotas enlazadas por dblink
Y si al final descubres algo más, porqué no se puede hacer, u otra manera de hacerlo, no te olvides de explicárnoslo..
- Inicie sesión para enviar comentarios
tengo el siguiente
tengo el siguiente codigo
Imports System.Data.OracleClient
Public Class Form1
Private Sub btnbuscar_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles btnbuscar.Click
Dim cadenaDeConexion As String
Dim conexion As OracleConnection
Dim dsdataset As New DataSet
cadenaDeConexion = " Data source=ORCL; persist security info=false; User ID= SCOTT; password= scott;"
conexion = New OracleConnection(cadenaDeConexion)
conexion.Open()
Dim query As String
query = "select scott.emp.ename , scott.emp.deptno, scott.dept.loc from" & _
" scott.emp inner join scott.dept on scott.emp.deptno = scott.dept.deptno " & _
" where ename like '%" & UCase(Me.txtnombre.Text.Trim) & "%'"
Dim MiAdaptador As New OracleDataAdapter(query, conexion)
Try
MiAdaptador.Fill(dsdataset)
Me.DataGridView1.DataSource = dsdataset.Tables(0)
Catch ex As Exception
End Try
End Sub
lo que busco es llenar un datagrid con la informacion, pero al darle click al boton me aparece el siguiente error ORA-00604: error ocurred at recursive SQL level 1 ORA 06502 PL/SQL numeric or value error: character string buffer to small ORA 06512: at line 10..
que puedo hacer?? no e encontrado la solucion a este problema!! le agradeceria que me ayudara.. muchas gracias
- Inicie sesión para enviar comentarios
Hola, Tengo un servidor en
Hola,
Tengo un servidor en Windows con 10gR2 con un dblink definido a un servidor Solaris con 10gR2 también.
Resulta que migre el servidor Windows a un Solaris con 11gR2 pero ahora los queries que usan el dblink al Solaris 10gR2 tienen un mal rendimiento.
Por ejemplo desde el servidor de Windows duran 20 segundos pero desde el nuevo servidor Solaris duran 157 segundos.
Alguna idea de que pueda ser?
Saludos,
Alberto
- Inicie sesión para enviar comentarios
Así a primera vista parece un
Así a primera vista parece un problema de comunicaciones más que de versiones de BBDD o de SO, y más si son versiones 10g y 11g.
Yo revisaría que todas las comunicaciones entre los servidores estén funcionando al 100% y no haya nada que las esté ralentizando
- Inicie sesión para enviar comentarios
Estimado Carlos, estoy
Estimado Carlos, estoy creando el siguiente trigger:
create or replace trigger trg_autonumero
before insert on t_personas_atendidas
for each row
begin
if :new.codPer is null then
select personas_id.NextVal into :new.codPer from dual;
end if;
end;
y me da error de que "el identificador new.CodPer no se ha declarado", a que se debe.
- Inicie sesión para enviar comentarios
hola! tengo un problema con
hola! tengo un problema con un BDlink y espero me pudieras ayudar. tengo dos bases remotas con oracle 8, creo mi bdlink para conectarme a la otra BD y al probar el bdlink me dice que el enlace no esta activo y al hacer un select o una vista materializada a la BD donde me quiero conectar con el bdlink me dice que TNS:COULD NOT RESOLVE SERVICE NAME.
tengo otro enlace a otra BD remota y ese si funciona sin problemas, todos son oracle 8; no se si falte algo de configuracion en la bd a donde no puedo entrar.
gracias por la ayuda
- Inicie sesión para enviar comentarios
Hola Carlos, quería ver si me
Hola Carlos, quería ver si me puedes ayudar...
Necesito crear un sinónimo con db link para llamar a procedimiento de un paquete que está en otra base de datos pero no me funciona.
Es en Oracle.
Le pongo create public synonym xxx for paquete.procedimiento@dblink
y si lo crea pero cuando hago el llamado del sinónimo para ejecutarlo da error de que no reconoce el sinónimo.
Lo intenté hacer solo con el paquete pero igual cuando llamo al sinónimo como? le especifico cual procedimiento del paquete necesito?.
Si lo hago con un procedimiento solito si me funciona... es con paquete que no.
Si me puedes dar un pista!!.. please!. A ver si me dí a entender!.
- Inicie sesión para enviar comentarios
Saludos Carlos. Mi problema
Saludos Carlos.
Mi problema es el siguiente, tal vez me puedas ayudar !!
Tengo un problema con un DBLink al tratar de ejecutar un procedimiento dentro de un paquete
de la siguiente manera.
Por ejemplo: nombre_paquete.nombre_procedimiento@nombre_dblink(<parámetros>)
La situación es que se realizó una migración y en el servidor anterior todo funciona correctamente
pero en el nuevo servidor esto da problemas. Me han dicho que hay posibilidad de que dé problema
la ejecución de un procedimiento dentro de un paquete haciendo uso de dblinks. He llegado a
pensar que el problema puede ser de configuración del archivo de parámetros; sin embargo;
reviso el archivo y están prácticamente iguales. Las bases de datos tienen nombres distintos.
Básicamente al ejecutarlo obtengo los siguientes errores:

Gracias !!
- Inicie sesión para enviar comentarios
La nueva base de datos tiene
La nueva base de datos tiene exactamente la misma versión que la antigua?
Buscando por el error he encontrado más de una referencia a un bug de la versión 10g, que se soluciona con un parche. También podría ser la misma versión y que a la nueva le falte aplicar el pachset, echa un vistazo por si acaso fuera eso..
This error is an interoperability error due to the bug 4511371, which is fixed by applying the 10.1.0.5.0 patchset for 10gR1 and 10.2.0.2.0 patchset for 10gR2.
Ref. Metalink note 4511371.8
Fuente: Oracle by Madrid
- Inicie sesión para enviar comentarios
Saludos Carlos !! Muchas
Saludos Carlos !!
Muchas gracias por tu pronta respuesta !!
En el ambiente anterior las dos bases de datos eran Oracle 10g Release 2 de 32 bits
En el nuevo ambiente una base de datos es Oracle 10g Release 2 de 32 bits y la otra
es Oracle 11g de 64 bits.
Menciono que en el ambiente anterior todo funcionaba perfectamente, leyendo tus comentarios
he visto que el problema se solucionaba con la Oracle 10g R 2, por lo que me extraña mucho
que en Oracle 11g 64 bits esté danto este problema.
Afectará mucho el manejo de los bits? Esto porque una es de 32 y la otra es de 64?
Muchas gracias Carlos !!
- Inicie sesión para enviar comentarios
El tema 32/64 bits siempre
El tema 32/64 bits siempre puede dar alguna sorpresa, pero yo antes me aseguraría de que la nueva 10g R2 tiene aplicado el patch. Aunque las dos BBDD tengan la misma versión puede que en la anterior estuviera aplicado y en la nueva no.
Busca más información en el metalink para asegurarte antes de hacer nada.
- Inicie sesión para enviar comentarios
A parte de lo que me pueda
- Inicie sesión para enviar comentarios
Hola, mi pregunta es si puedo
- Inicie sesión para enviar comentarios
Sí, sin problemas, con Oracle
Sí, sin problemas, con Oracle SQL puedes crear una tabla a partir de otra con una sentencia CTAS:
CREATE AS SELECT ... FROM otra_tabla@dblink
Si no son muchos datos y la red va bien no deberías tener problemas de rendimiento. Si hablamos de millones de registros para arriba, y la red que conecta las dos bases de datos no va sobrada, tendrías que plantearte opciones de exportación e importación.
- Inicie sesión para enviar comentarios
Buenas tardes Carlos, En el
- Inicie sesión para enviar comentarios
Hola, Tal vez una solucion
- Inicie sesión para enviar comentarios
Hola, estoy intentando
- Inicie sesión para enviar comentarios
Estimado, Estoy Trabajando En
Estimado, Estoy Trabajando En Apex Que Esta En Un Servidor Con Oracle Xe Y Conectandome A Un Servidor Remoto Para Sacar Los Datos De Produccion Lo Que Es Bastante Lento Y Tengo Dos Dudas Espero Me Pueda Ayudar:
1.- Mi Conexion Es A Traves De Dblink Me Comentaron Que De Esta Forma Es Lenta De Que Forma Me Puedo Conectar En Forma Mas Eficiente Manteniendo Mi Servidor Con Apex Y Mi Servidor De Produccion.
2.- Cuando Ejecuto Un Sql En "Sql Comand" De Apex, El Resultado Es Relativamente Rapido, Pero Al Correr Ese Mismo Sql En Una Pagina Este Se Hace Extremadamente Lento. Porque??? Que Pone Mi Pagina Tan Lenta Cuando Debe Mostrar Los Datos. No Estoy Paginando Las Paginas.
Muchas Gracias
- Inicie sesión para enviar comentarios
hola amigos, tengo el
hola amigos, tengo el siguiente problema al tratar de hacer un insert vía un dblink
ORA-01652: unable to extend temp segment by 128 in tablespace TEMP
ORA-02063: preceding line from LNK_HIST_SI
lo que hago es un
Insert into tabla@dblink
select from tabla
where condiciones
y excluyendo lo que ya este con un not exists tabla@dblink;
espero haber sido claro
si ejecuto el solo select no me da ningun problema pero cuando pongo el insert me da el error del tablespace TEMP
en ese tablespace tengo 5 GB y estoy tratando de insertar solo 5 registros.
gracias por los comentarios
- Inicie sesión para enviar comentarios
Muy buenas tardes, una
Muy buenas tardes, una pregunta
Resulta que de sql server 2008 r2 hice un linked server a oracle 9i pero cuando consulto y traigo datos de una tabla de oracle a una en sql server me tarda demasiado tiempo en ejecutar.
No se si es normal porque en la tabla de oracle hay miles de registros, pero los registros los estoy filtrando por fecha no se donde estar el error o si es normal
gracias de antemano
- Inicie sesión para enviar comentarios
Buenas noches, quería
Buenas noches, quería consultarte sobre un error que me está apareciendo en un aplicativo que usa un dblink desde Oracle a MySQL (un esquema de Oracle consume información de una base de datos Mysql), el dblink lo he hecho mediante el Oracle Gateway ODBC que viene con el Oracle, y el error es el siguiente:
java.sql.SQLException: Violación de protocolo
at oracle.jdbc.driver.T4CTTIfun.receive(T4CTTIfun.java:450)
at oracle.jdbc.driver.T4CTTIfun.doRPC(T4CTTIfun.java:186)
at oracle.jdbc.driver.T4C7Ocommoncall.doOLOGOFF(T4C7Ocommoncall.java:61)
at oracle.jdbc.driver.T4CConnection.logoff(T4CConnection.java:491)
at oracle.jdbc.driver.PhysicalConnection.close(PhysicalConnection.java:3754)
at pe.gob.servir.cat.connection.factory.ConnectionFactory.CloseConexion(ConnectionFactory.java:73)
at pe.gob.servir.cat.persistencia.jdbc.MovimientoActivoDAO.getDatosActivosRemotosComplemento(MovimientoActivoDAO.java:218)
at pe.gob.servir.cat.persistencia.jdbc.MovimientoActivoDAO.main(MovimientoActivoDAO.java:384)
Exception in thread "main" java.lang.NegativeArraySizeException
at oracle.jdbc.driver.T4CMAREngine.unmarshalDALC(T4CMAREngine.java:2341)
at oracle.jdbc.driver.T4C8TTIuds.unmarshal(T4C8TTIuds.java:146)
at oracle.jdbc.driver.T4CTTIdcb.receiveCommon(T4CTTIdcb.java:200)
at oracle.jdbc.driver.T4CTTIdcb.receive(T4CTTIdcb.java:144)
at oracle.jdbc.driver.T4C8Oall.readDCB(T4C8Oall.java:771)
at oracle.jdbc.driver.T4CTTIfun.receive(T4CTTIfun.java:346)
at oracle.jdbc.driver.T4CTTIfun.doRPC(T4CTTIfun.java:186)
at oracle.jdbc.driver.T4C8Oall.doOALL(T4C8Oall.java:521)
at oracle.jdbc.driver.T4CPreparedStatement.doOall8(T4CPreparedStatement.java:205)
at oracle.jdbc.driver.T4CPreparedStatement.executeForDescribe(T4CPreparedStatement.java:861)
at oracle.jdbc.driver.OracleStatement.executeMaybeDescribe(OracleStatement.java:1145)
at oracle.jdbc.driver.OracleStatement.doExecuteWithTimeout(OracleStatement.java:1267)
at oracle.jdbc.driver.OraclePreparedStatement.executeInternal(OraclePreparedStatement.java:3449)
at oracle.jdbc.driver.OraclePreparedStatement.executeQuery(OraclePreparedStatement.java:3493)
at oracle.jdbc.driver.OraclePreparedStatementWrapper.executeQuery(OraclePreparedStatementWrapper.java:1491)
at pe.gob.servir.cat.persistencia.jdbc.MovimientoActivoDAO.getDatosActivosRemotosComplemento(MovimientoActivoDAO.java:198)
Por favor si tuviera alguna idea de a que se puede deber el error, le estaré agradecido me pueda ayudar
- Inicie sesión para enviar comentarios
Buenas tardes, Tengo
Buenas tardes,
Tengo creado un DB_Link de Sql Server 2012 a Oracle 11g, puedo hacer consultas a las bd que asigne. Pero me da un error al momento de realizar un update desde Oracle, para que me realice el cambio en la Bd Sql Server. el error es el siguiente: ORA-02070 database does not support update in this context.
Por favor si me pueden ayudar se los agradeceria.
Saludos,
- Inicie sesión para enviar comentarios
Tengo un procedimiento X
Tengo un procedimiento X creado en oracle 12c, en oracle 11g se creo un dblink para ejecutar ese procedimiento X, pero en ocasiones genera los siguientes errores:
ORA-04052: se ha producido un error al consultar el objeto remoto SYSTEM.PK_COR@ADMIN.xxx.com.co
ORA-00604: se ha producido un error a nivel 1 de SQL recursivo
ORA-12154: TNS:no se ha podido resolver el identificador de conexión especificado
04052. 00000 - "error occurred when looking up remote object %s%s%s%s%s"
*Cause: An error has occurred when trying to look up a remote object.
*Action: Fix the error. Make sure the remote database system has run
KGLR.SQL to create necessary views used for querying/looking up
objects stored in the database.
Carlos, no soy el dba, y no se como ayudar a corregir este error.
gracias
- Inicie sesión para enviar comentarios
hola carlos disculpa el abuso
hola carlos disculpa el abuso soy de venezuela y vi en un foro que tu respondes cosas de oracle o si otra persona me puede ayudar le agradezco. bueno te cuento lo que me sucede:
tengo mi BD en oracle 10g y en otro servidor que no es de nosotros también tiene oracle no recuerdo si es la 10g o la 11g
bueno el problema es el siguiente tengo una vista de mi servidor al otro servidor a través de un enlace de base de datos y chevere hago la consulta y funciona pero resulta que si por ejemplo:
tengo mi pantalla donde pido una cédula la consulto en la vista que es del otro servidor y trae el nombre y apellido todo bien hasta aquí, termino de llenar los datos ya de mi tabla que esta servidor y bien al momento de guardar revienta dice error de comunicación me di cuenta que es la vista remota hacia el otro servidor, ya que me cree una pantalla mas sencilla sin hacer la consultar hacia esa vista remota y ahi si guarda pero si pongo algo que consulte a esa vista y guardo en mi tabla sale ese error
PD no recuerdo si siempre pasa o es a ratos ese error el detalle es que sucede es al consultar una vista remota
gracias a todos
- Inicie sesión para enviar comentarios
¿Puedes copiar el texto
¿Puedes copiar el texto completo del error, y la consulta que haces con el dblink remoto?
- Inicie sesión para enviar comentarios
Tengo un problema. conectando
Tengo un problema. conectando entre un IBM i V7R1 , mediante DBLink a una DB Oracle me da un error de formato de de fecha.
ORA-28500: la conexión de ORACLE a un sistema no Oracle ha devuelto este mensaje: [Oracle][ODBC DB2 Wire Protocol driver][UDB DB2 for iSeries and AS/400] STRING REPRESENTATION OF DATETIME VALUE HAS INVALID SYNTAX. 16 *N {HY000,NativeErr = -180} ORA-02063: 2 lines precediendo a DBL_PHIDRDA ORA-06512: en "DA_ABA.ABA_SOLICITUD", línea 547 ORA-06512: en línea 38 Alguien le paso esto? Saludos y gracias por la ayuda
- Inicie sesión para enviar comentarios
Buenas tarde disculpe las
Buenas tarde disculpe las molestias pero estoy necesitando ayuda de un experto como usted. Al instalar Oracle11g Me da a elegir en una opcion si queremos instalar en forma de Escritorio o Servidor .. En cual de esos dos modos instalo para poder crear una DBlink?
- Inicie sesión para enviar comentarios
Hola Jonathan En principio no
Hola Jonathan
En principio no te va a influir en la posibilidad de crear DBLinks si haces la instalación en modo Desktop o en modo Server, ya que en ambos casos vas a instalar el mismo motor, solo que en el modo Server el instalador crea opciones de configuración más avanzadas.
Saludos,
- Inicie sesión para enviar comentarios
Buenos dias, talvez ustedes
Buenos dias, talvez ustedes me pueden ayudar.
Necesito conectarme de un dblink de mi base en mi maquina a otro dblink creado en otra maquina.
En pocas palabras la maquina A tiene un dblink para conectarse consultar tablas de la maquina B. pero la maquina B tiene un dblink para conectarse a una maquina C.
quiero consultar tablas de la maquina C usando el dblink de la maquina B pero de la maquina A
- Inicie sesión para enviar comentarios
Carlos, buenas tardes. le
Carlos, buenas tardes. le comento que he instalado dos base de datos Oracle 11g Express XE, y quiero generar un db link entre las dos base de datos. La verdad es que he buscado por todos lados, como hacer la conexion de estas dos base de datos, pero no puedo conectarme. me da error de time out cuando creo el db link. Dichas bases de datos, estan en diferentes servidores fisicos, las dos base de datos se llaman XE dado a que es la unica forma que se instala el 11g express. hay alguna limitante para generar db link entre dos base de datos express? que cosas puedo controlar o hacer, para generar dichas conexion. Desde ya muchas gracias y disculpa las molestias. César.
- Inicie sesión para enviar comentarios
Que yo sepa Oracle XE no
Que yo sepa Oracle XE no tiene ninguna limitación en cuanto a la creación de database links. Si lo que obtienes es un error de timeout puede que sea un problema de comunicaciones entre las dos bases de datos. Si están en diferentes servidores o máquinas puede que algún firewall o alguna regla impida que se comuniquen entre sí. Revisa sobretodo que los puertos que tengas configurados en las bases de datos, que estén abiertos.
Por defecto la base de datos utiliza el 1521, y para conexiones http el 8080. Si quieres consultar la configuración de los puertos puedes ejecutar desde linea de comandos con el usuario de sistema con que has hecho la instalación en windows, o un user que pertenezca al grupo de Oracle en Linux/Unix:
> lsnrctl status
Antes de nada recuerda también hacer un tnsping para validar que hay comunicación entre las dos bases de datos
Dejar el puerto 8080 por defecto para las comunicaciones por http de BBDD Oracle puede crearte problemas si ya utilizas este puerto para otras aplicaciones, que es algo bastante habitual.
Te muestro cómo consultar por SQL qué puerto tienes configurado en la base de datos, y cómo cambiarlo por otro, el 8089 por ejemplo:
SQL> select dbms_xdb.gethttpport from dual; -------- 8080 SQL> exec dbms_xdb.sethttpport(8089);
- Inicie sesión para enviar comentarios
Carlos buenas tardes. Mira
Carlos buenas tardes. Mira tengo este problema con un DBLINK que en su momento funciona, actualmente me manda este error, de favor tus comentarios por donde puedo buscar o ver que es lo que esta pasando, el DBLINK existe. Me conecto a la base del DBLINK y sin problemas. Al utilizar el DBLINK y nada. 09:34:20 Error: ORA-03113: end-of-file on communication channel SALUDOS
- Inicie sesión para enviar comentarios
Buen dia, Sabes que ejecute
Buen dia,
Sabes que ejecute un procedimiento que usaba dblink varias veces por error en la programación.
Ahora tengo el error presente y no puedo acceder a la aplicación.
El error:
ORA-04052: se ha producido un error al consultar el objeto remoto CLIENTEVIR.ANDES@WEB
ORA-00604: se ha producido un error a nivel 2 de SQL recursivo
ORA-02046: ya ha empezado la transacción distribuida
ORA-02063: line precediendo a WEB
He intentado varias cosas de las que refieres aqui y nada.
He probado: reiniciar el servidor, matar todas las sesiones y lo del dblink.
Alguna idea?????
Gracias,
- Inicie sesión para enviar comentarios
Amigosm estoy haciendo un
Amigosm estoy haciendo un DBlink de oracle a mysql y en la configuración inicial que es configurar la ODBC.ini y el listener me arroja error por el SID. me podría ayudar a como realizar este procedimiento.
- Inicie sesión para enviar comentarios
Backups de bases de datos Oracle
Backups de bases de datos Oracle Dataprix 7 May, 2010 - 19:25Abro este tema a proposito de una consulta de Monica sobre Backups de BBDD Oracle.
Como la creación y gestión de copias de seguridad es un tema muy amplio y puede dar para muchas aportaciones y discusiones mejor dedicarle un tema específico de este foro de BBDD Oracle.
El tema de los backups de
El tema de los backups de BBDD es demasiado amplio, y la utilización de un método u otro depende mucho de tus necesidades. Seguramente estaría bien escribir un artículo sólo sobre backups de BBDD Oracle, pero ahora mismo no creo que tenga tiempo de hacerlo.
Comentarte sólo que a partir de la versión 10g de Oracle la consola de administración web (Oracle Enterprise Manager) facilita mucho las tareas de backup, y es relativamente fácil preparar un sistema de backup sencillo ayudándote del asistente.
Trabajar con RMAN, por ejemplo, requiere mucho más conocimiento.
Eso sí, te recomiendo que antes hagas pruebas en un entorno de desarrollo, con los backups no cuesta mucho acabar consumiendo todo el espacio disponible, o saturando los recursos del server de BBDD.
Te indico también algunos enlaces que he encontrado 'googleando', y pienso que te pueden ser útiles para empezar:
http://www.databasedesign-resource.com/oracle-backup.html
http://systemadmin.es/2009/10/realizar-un-export-backup-de-oracle-mediante-exp
Otra opción es utilizar Oracle Secure Backup para gestionar los backups de BBDD Oracle. Como mínimo tendrás una documentación muy completa en la web de Oracle sobre cómo utilizar este producto y establecer tus políticas de backups para bases de datos Oracle.
- Inicie sesión para enviar comentarios
Segun mi propia experiencia,
Segun mi propia experiencia, trabajar con RMAN no me parece tan complejo una vez profundizamos un poco. La copia es rápida y autocomprimida ocupa poco espacio.
Las copias desde Enterprise Manager son más sencillas pero a mi personalmente todo lo que se puede hacer desde la consola lo acabo haciendo desde linea de comandos... Es bonita pero no es muy de mi agrado para cualquier cosa que no sea detectar picos de uso en la base de datos.
Por cierto, si dispones de suficiente espacio y ventana horaria no está mal acompañar las copias de rman con un export (copia lógica) de la base de datos como apunta Carlos en su segundo enlace.
- Inicie sesión para enviar comentarios
Hola carlos, la cuestion es
Hola carlos, la cuestion es esta
Soy algo nuevo con esto de las bases de datos, cuando yo tome el rol de DBA estaban las estructuras, usuarios, etc. ya creados y he dado una revisada y mantenimiento a esto en primera instancia, ahora queiro establecer un esquema de respaldos, actualmente solamente se hacen respaldos logicos de manera full diaria con el export, pero no se hacen respaldos fisicos de los ficheros de datos, control file, etc. pienso comenzar a hacer los respaldos en frio de la DB ya que esta en modo NOARCHIVELOG, alguna recomendacion que tengas para hacer este tipo de respaldo o algún sitio donde pueda tener mayor referencia tanto a respaldos en caliente y respaldos en frio,
saludos
- Inicie sesión para enviar comentarios
Hola .. tengo un problema
Hola .. tengo un problema ...
en la universidad me mandaron hacer un proyecto de BDD
Oracle esta instalado en una mquina virtual y la interfaz esta hecha en una maquina fisica necesito sacar un respaldo de la base pero no se como hacerlo desde la maquina fisica a la virtual..
podrias ayudarme por favor
- Inicie sesión para enviar comentarios
Checklist de Seguridad en Oracle
Checklist de Seguridad en Oracle drakon 24 Octubre, 2006 - 21:42Oracle normalmente no lo acostumbraremos a encontrar en Pymes sino más bien en empresas grandes. Esto hace que nos tengamos que poner las pilas en términos de seguridad, no aplicar una simple configuración sino, como buenos DBA's, realizar un buen y detallado estudio.
Qué mejor que ayudarnos de un checklist de seguridad para poder aplicar una buena configuración y que no se nos pase absolutamente nada.
Es por ello que adjunto uno en formato pdf y que básicamente se divide en cuatro apartados:
- Reforzamiento
- Actualizaciones de Seguridad
- Contraseñas por defecto
- Puertos por defecto utilizados por Oracle.
Descarga el Checklist de Seguridad en Oracle adjunto.
Espero que os guste..
| Adjunto | Size |
|---|---|
| Oracle_Database_Checklist.pdf | 162 bytes |
Como obtener la lista de tablas con más movimiento (insert,update) en Oracle
Como obtener la lista de tablas con más movimiento (insert,update) en Oracle il_masacratore 14 Agosto, 2009 - 13:46A fin de obtener una lista aproximada de las tablas con más movimientos de la base de datos podemos consultar el contenido de la tabla dba_tables y cruzarlo con el estado actual de cada tabla en la bbdd. Esto puede tener sentido cuando queremos confeccionar una lista de tablas a las que se debe actualizar estadísticas periódicamente o queremos controlar la cantidad de información que genera alguna aplicación en concreto. Los datos que obtenemos por cada tabla son siempre respecto al último analisis de la misma.
La siguiente forma de hacerlo es un poco "rupestre" pero útil a la vez:
- Nos conectamos a la base de datos como system y ejecutamos la siguiente consulta que nos devolvera una lista de selects con todas las tablas de la base de datos (es mejor filtrar para no incluir las tablas de sistema o incluir solo las de un usuario en concreto). En el ejemplo obtendremos solo las de un usuario en concreto:
select 'select ''' || table_name || ''' as TABLA, ''' || sysdate ||
''' as FECHA_ACTUAL, ''' || last_analyzed ||
''' as ULTIMO_ANALISIS, count(*) as RECUENTO,' || num_rows ||
' as RECUENTO_ANALISIS , to_date(''' || sysdate ||
''', ''DD/MM/YYYY'') - to_date(''' || last_analyzed ||
''',''DD/MM/YYYY'') as DIAS_DESDE_ANALISIS , count(*) - ' || num_rows ||
' as DIFERENCIA_RECUENTO, (count(*) - ' ||
num_rows || ')/(to_date(''' || sysdate ||
''', ''DD/MM/YYYY'') - to_date(''' || last_analyzed ||
''',''DD/MM/YYYY'')) as INCREMENTO_DIARIO from ' || owner || '.' ||
table_name || ' union '
from dba_Tables
where owner = 'USUARIO'
Ejemplo del resultado con plsql:
- Copiamos toda la columna en el portapapeles y quitamos el último union. Obtendremos el siguiente resultado:

Podemos ver la tabla con los datos del último analisis de la tabla respecto a los actuales y la variación con su media diaria en número de registros (teniendo en cuenta que un insert(1row) + delete(1row) = 0movimientos
 )
)
Si a esto le sumamos otros datos como tamaños de fila, si la tabla tiene índices y lo que se nos ocurra podemos hacer otros "trabajos manuales" como acumular esos resultados en una tabla para ver que se cuece en nuestra base de datos. Eso sí, cada uno puede adaptar esta técnica a su gusto para cubrir sus necesidades 
Como recuperar la contraseña del usuario sys y system (Oracle 9i)
Como recuperar la contraseña del usuario sys y system (Oracle 9i) il_masacratore 17 Julio, 2009 - 13:15Si pasais a ocupar el puesto de DBA o administrador de Oracle y la persona saliente no os deja anotadas las contraseñas de los usuarios sys y system de la base de datos se puede proceder de la siguiente manera para intentar recuperarlas. Si tenemos el usuario root, podemos cambiar la contraseña de sys y system de Oracle.

Primero debemos conectarnos con SQLPlus al servidor Oracle con el usuario en el que corre la base de datos o root (conectar as sysdba).
A continuación cambiaremos la contraseña del usuario sys de Oracle:
$ sqlplus "/ as sysdba" SQL*Plus: Release 9.2.0.1.0 - Production on Mon Apr 5 15:32:09 2004 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.1.0 - Production With the OLAP and Oracle Data Mining options JServer Release 9.2.0.1.0 - Production SQL> show user USER is "SYS" SQL> passw system Changing password for system New password: Retype new password: Password changed SQL> quit
Luego cambiaremos la contraseña del usuario system de Oracle:
$ sqlplus "/ as system"
SQL*Plus: Release 9.2.0.1.0 - Production on Mon Apr 5 15:36:45 2004
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
SP2-0306: Invalid option.
Usage: CONN[ECT] [logon] [AS {SYSDBA|SYSOPER}]
where <logon> ::= <username>[/<password>][@<connect_string>] | /
Enter user-name: system
Enter password:
Connected to:
Oracle9i Enterprise Edition Release 9.2.0.1.0 - Production
With the OLAP and Oracle Data Mining options
JServer Release 9.2.0.1.0 - Production
SQL> passw sys
Changing password for sys
New password:
Retype new password:
Password changed
SQL> quitAhora ya deberíamos poder conectarnos a nuestra base de datos Oracle como usuario sys y system, utilizando los nuevos passwords que hemos introducido desde SQLPlus.
Libros de Administración Oracle (DBA) y PL/SQL
¿Quieres profundizar más en PL/SQL de Oracle o en administración de bases de datos Oracle? Puedes hacerlo consultando alguno de estos libros de Oracle.
Cómo crear un nuevo esquema en Oracle paso a paso
Cómo crear un nuevo esquema en Oracle paso a paso cfb 22 Octubre, 2006 - 21:44Vamos a ver en tres sencillos pasos cómo crear un esquema de Oracle. Para poder crear un nuevo esquema de Oracle siguiendo estos pasos es necesario iniciar la sesión en la base de datos con un usuario con permisos de administración. Lo más sencillo es utilizar directamente el usuario SYSTEM:
- Creación de un tablespace para datos y otro para índices. Estos tablespaces son la ubicación donde se almacenarán los objetos del esquema de Oracle que vamos a crear.
Tablespace para datos, con tamaño inicial de 1024 Mb, y auto extensible
CREATE TABLESPACE "APPDAT" LOGGING DATAFILE '/export/home/oracle/oradata/datafiles/APPDAT.dbf' SIZE 1024M EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO
Tablespace para índices, con tamaño inicial de 512 Mb, y auto extensible
CREATE TABLESPACE "APPIDX" LOGGING DATAFILE '/export/home/oracle/oradata/datafiles/APPIDX.dbf' SIZE 512M EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO
La creación de estos tablespaces no es obligatoria, pero sí recomendable, así cada usuario de la BD tendrá su propio espacio de datos.
- Creación del usuario que va a trabajar sobre estos tablespaces, y que será el propietario de los objetos que se se creen en ellos
CREATE USER "APP" PROFILE "DEFAULT" IDENTIFIED BY "APPPWD" DEFAULT TABLESPACE "APPDAT" TEMPORARY TABLESPACE "TEMP" ACCOUNT UNLOCK;
Si no se especifica un tablespace, la BD le asignará el tablespace USERS, que es el tablespace que se utiliza por defecto para los nuevos usuarios.
Se puede apreciar también que no hay ninguna referencia al tablespace de índices APPIDX que hemos creado. Si queremos mantener datos e índices separados habrá que acordarse de especificar este tablespace en las sentencias de creación de índices de este usuario, si no se hace éstos se crearán en APPDAT:
CREATE INDEX mi_indice ON mi_tabla(mi_campo) TABLESPACE APPIDX;
- Sólo falta asignarle los permisos necesarios para trabajar. Si se le asignan los roles 'Connect' y 'Resource' ya tiene los permisos mínimos, podrá conectarse a la base de datos y realizar las operaciones más habituales de consulta, modificación y creación de objetos en su propio esquema.
GRANT "CONNECT" TO "APP"; GRANT "RESOURCE" TO "APP";
Completamos la asignación de permisos con privilegios específicos sobre objetos del esquema Oracle para asegurarnos de que el usuario pueda realizar todas las operaciones que creamos necesarias
GRANT ALTER ANY INDEX TO "APP"; GRANT ALTER ANY SEQUENCE TO "APP"; GRANT ALTER ANY TABLE TO "APP"; GRANT ALTER ANY TRIGGER TO "APP"; GRANT CREATE ANY INDEX TO "APP"; GRANT CREATE ANY SEQUENCE TO "APP"; GRANT CREATE ANY SYNONYM TO "APP"; GRANT CREATE ANY TABLE TO "APP"; GRANT CREATE ANY TRIGGER TO "APP"; GRANT CREATE ANY VIEW TO "APP"; GRANT CREATE PROCEDURE TO "APP"; GRANT CREATE PUBLIC SYNONYM TO "APP"; GRANT CREATE TRIGGER TO "APP"; GRANT CREATE VIEW TO "APP"; GRANT DELETE ANY TABLE TO "APP"; GRANT DROP ANY INDEX TO "APP"; GRANT DROP ANY SEQUENCE TO "APP"; GRANT DROP ANY TABLE TO "APP"; GRANT DROP ANY TRIGGER TO "APP"; GRANT DROP ANY VIEW TO "APP"; GRANT INSERT ANY TABLE TO "APP"; GRANT QUERY REWRITE TO "APP"; GRANT SELECT ANY TABLE TO "APP"; GRANT UNLIMITED TABLESPACE TO "APP";
Ahora el usuario ya puede conectarse a la base de datos y comenzar a trabajar sobre su nuevo esquema Oracle.
Entrar en SQLPlus como dba sin introducir password
Entrar en SQLPlus como dba sin introducir password Carlos 31 Marzo, 2008 - 23:09Si tienes el usuario de sistema con el que se ha instalado la base de datos Oracle puedes entrar en SQL plus como usuario DBA y sin introducir ninguna contraseña de la siguiente manera:
- Entra en el sistema con este usuario.
- Desde la linea de comandos, entra en SQLplus poniendo:
> sqlplus "/as sysdba"
Si has necesitado entrar así porque no recordabas la contraseña de algún usuario, ya puedes modificarla/s para poder utilizarlo/s después:
SQL> alter user nombre_usuario identified by nuevo_password;
Te puede pasar que haya más de una Base de datos Oracle instalada en el servidor, por lo que tendrás que asegurarte de que las variables de entorno del usuario de Oracle están apuntando a la base de datos que te interesa.
Para comprobar que has entrado en la base de datos correcta antes de tocar nada puedes ejecutar esta sentencia SQL:
SQL> select name from v$database;
Libros de Administración Oracle (DBA) y PL/SQL
¿Quieres profundizar más en PL/SQL de Oracle o en administración de bases de datos Oracle? Puedes hacerlo consultando alguno de estos libros de Oracle.
Hola me gustaria saber como
Hola me gustaria saber como hago lo mismo pero en centos
- Inicie sesión para enviar comentarios
No sé si te entiendo bien, no
No sé si te entiendo bien, no debería haber diferencia por ser CentOS, sólo tienes que abrir la consola de comandos y ejecutar SQLPlus, que lo tendrás disponible si tienes instalada la BD en esa máquina. Dentro de SQLPlus los comandos son SQL de Oracle, independientes del sistema operativo.
Saludos,
- Inicie sesión para enviar comentarios
ok gracias lo pruebo,no
ok gracias lo pruebo,no conozco el tema en linux y necesito ingresar a la base oracle10g, pero desgraciadamente quien estaba encargado tuvo un accidente y no tengo ningun usuario ni contraseña de la base.
gracias por contestarme si tienes alguna sugerencia de como acceder a ella a parte de la que ya mensionaste me serviria de mucha ayuda.
- Inicie sesión para enviar comentarios
Es muy sencillo entra al
- Inicie sesión para enviar comentarios
Hola que tal Trato de
Hola que tal
Trato de conectarme como indicas pero me marca el siguiente error, ya busque y no puedo encontrar por que es:
C:\oracle2\product\10.2.0\db_2\BIN>sqlplus "/as sysdba"
SQL*Plus: Release 10.2.0.1.0 - Production on MiÚ Nov 24 10:45:39 2010
Copyright (c) 1982, 2005, Oracle. All rights reserved.
ERROR:
ORA-12560: TNS:protocol adapter error
Enter user-name:
ERROR:
ORA-12560: TNS:protocol adapter error
Enter user-name:
ERROR:
ORA-12560: TNS:protocol adapter error
SP2-0157: unable to CONNECT to ORACLE after 3 attempts, exiting SQL*Plus
C:\oracle2\product\10.2.0\db_2\BIN>
Espero me puedas ayudar
Mil gracias
- Inicie sesión para enviar comentarios
Puede ser porque las
Puede ser porque las variables de entorno no estén bien definidas. Estás utilizando el mismo usuario de Windows con el que se hizo la instalación de Oracle? Con ese no te debería fallar.
Si has de utilizar otro tendrás que definir las variables de entorno para él. Si, por ejemplo, no puedes ejecutar SQLPLUS desde fuera del mismo directorio 'BIN' es que el usuario no las tiene definidas.
También puedes comprobar directamente si existe la variable de entorno ORACLE_SID, que debería contener el valor de la instancia local de Oracle.
- Inicie sesión para enviar comentarios
Buen dia a todos! Buscamos
Buen dia a todos! Buscamos perfiles ETL-IPC para trabajar en una compañía estadounidense de renombre internacional (Base en el DF.). Si cubres con el perfil y eres bilingüe envianos mensaje privado o envia tu CV a maricruz.martinez@estrategiasdetalentohumano.com O si conoces de alguien que pueda estar interesado. Asi como este perfil, también tenemos más vacantes en el área de TI. Gracias!!
- Inicie sesión para enviar comentarios
Publicado el 2005, hoy me es
- Inicie sesión para enviar comentarios
Me gustaria saber si alguien
Me gustaria saber si alguien me puede hechar una manito, tengo en mi pc
Toad for Oracle 9 y oracle 8i, cargo una base de datos automáticas todos los días por la mañana, pero necesito que una query con la cual hago el filtro de esta carga se ejecute de forma automática y no manual como lo hago todos los días. Se que por medio de un bach, una llamada a sql plus, este bach o bat lo invoco con un scheduler de windows y podria funcionar... el tema es como hago el llamado a SQL PLUS con un bat.
Saludos y muchas gracias
Alejandro
- Inicie sesión para enviar comentarios
Alejandro, te has planteado
Alejandro, te has planteado hacerlo con un job de Oracle? Si tienes permisos para crear jobs y procedimientos almacenados puedes programar con un job la ejecución de un procedure que contenga la query de la carga, y lo haces todo desde la misma base de datos.
- Inicie sesión para enviar comentarios
ayuda instale 2motores de BD,
ayuda instale 2motores de BD,
oracle express edition 11g y ahora
oracle enterprise 11g
y trato de conectarme a oracle por sqlplus
pero tngo el siguiente error
ORA-12560:TNS: error del adaptador del protocolo
que puedo hacer para que se levante oracle
cuando tenia solo express edition no habia problema
saludos Andrés J
- Inicie sesión para enviar comentarios
Buenos dias Carlos, soy Fans
Buenos dias Carlos,
soy Fans de DATAPRIX y me gusta todo el conocimiento que aquí exponen.
Carlos la pregunta es la siguiente:
Tengo instalado en estos momentos en el servidor de producción Oracle Database 10g
Release 10.2.0.4.0 - 64bit Production
vamos a actualizar a la versión Oracle Database 11g Release 11.2.0.1.0 - 64bit Production
cual es la mejor forma de actualizar mi Oracle ? algunos me han dicho que instale Oracle 11g en el servidor y que cambie las variables de ambiente y despues apague mi ORacle 10g que actualmente es produccion ?
Tu cual me recomendaría teniendo en cuenta que la compañia solo da una espera de 1 dia para esta labor?
Gracias y felicitaciones por sus aportes a esta comunidad.
- Inicie sesión para enviar comentarios
Hola Guillermo Hay varios
Hola Guillermo
Hay varios métodos para hacer un upgrade de Oracle, y la utilización de cada uno depende de muchos factores, entre los que se incluye la experiencia que tengas como DBA, o las herramientas de Oracle que domines mejor.
Lo de cambiar las variables de entorno, puede que se pueda hacer en algún caso, pero me parece algo arriesgado, y seguramente tengas que 'toquetear' alguna cosa más. El factor más importante es el tiempo que puedas tener la base de datos parada, si puedes. Si ese día que comentas la base de datos puede estar parada, para mí el método más seguro es hacer un export en frío de la base de datos de producción, y un import sobre la instalación nueva de la 11g.
Si quieres plantearte otras opciones, he encontrado este artículo de la OTN de Oracle que plantea diferentes escenarios, y aconseja qué hacer en cada uno, tiene hasta un diagrama para ayudarte a tomar la decisión.
El método de utilizar el DBUA (Database Upgrade Assistant) de Oracle, que el artículo explica al final con mucho detalle, creo que también podría servir para el entorno que planteas.
Saludos,
- Inicie sesión para enviar comentarios
En referencia a si se puede
En referencia a si se puede forzar la petición de contraseña a todos los usuarios.....
Podeis hacer....
Editar el sqlnet.ora
y poner
SQLNET.authentication_sevices=none
Entonces no podréis conectar directamente desde sqlplus con connect /as sysdba
dará el error ORA-01031: insufficient privileges
Saludos,
Francisco García Colacios
www.colacios.es
- Inicie sesión para enviar comentarios
Hola a todos, Me gustaría
Hola a todos,
Me gustaría saber si alguine tiene conocimiento de algun metodo de poder detectar bloqueos en una BD oracle 10g y un comando para liberarlas. es decir existen nuevos comandos 10g a la fecha que hagan este trabajo.
Gracias
Cristian Ampuero
- Inicie sesión para enviar comentarios
Buenas Tardes, necesito
Buenas Tardes, necesito ejecutar varios comandos desde la consola para dar permisios a un rol para gestionar objetos tipo JOBS, ejecuto el primer comando SQLPLUS "SYS/PASSWORD@INSTANCIA AS SYSDBA" pero no me logra abrir el sqlplus, alguien podria ayudarme
- Inicie sesión para enviar comentarios
#te validas como root su
- Inicie sesión para enviar comentarios
buen dia, trato de conectarme
buen dia, trato de conectarme a sqlplus con un usuario distinto a oracle, ya le defini las variables de entorno a el y me sale un error en el momento de coneccion "ora 12547 tns: lost contact
- Inicie sesión para enviar comentarios
Entiendo que te refieres
Entiendo que te refieres igualmente a una conexión "sqlplus / as sysdba".
Yo no me encontrado nunca el error "ORA-12547 TNS: Lost Contact" que comentas al conectar con SQLPlus, así que te referencio un par de posts de otros sitios con posibles causas y soluciones para solventar este error de conexión de Oracle:
En Oracle DBA Blog mencionan 5 posibles causas para el error de Oracle ORA12457, y 5 posibles soluciones, basándose en el documento de soporte de Oracle 422173.1
En el blog Oracle en Español explican cómo utilizar la utilidad 'sysresv' para consultar los segmentos de memoria compartida y los semáforos que utiliza una instancia de Oracle:
> $ORACLE_HOME/bin/sysresv
En su caso, eliminando con el comando ipcrm los semáforos y la memoria compartida que le devolvía el comando sysresv, pudieron volver a entrar con SQLPlus /as sysdba sin encontrarse el error ora 12547:
> ipcrm -m [shared_memory_ID] > ipcrm -s [semaphore_ID]
Espero que alguna de estas referencias te ayude a solucionar el error
- Inicie sesión para enviar comentarios
Hola tengo una duda, resulta
Hola tengo una duda, resulta que en oracle 11g 2 tengo la siguiente contraseña "pass"(con todo y dobles comillas) al querer conectarme con sqlplus
con el siguiente comando sqlplys usr/"pass"/BD@10.10.10.10/ORACLE, me conecto sin problemas por medio de un .BAT, el problema es que si en ese mismo .BAT agrego lo siguiente no se conecta, no se conecta a la base de datos y por ende no hace la carga del archivo .CTL
sqlplus usr/"pass"/BD@10.10.10.10/ORACLE control = C:\Users\xxxx\Documents\Compartida\carga\archivocarga.ctl
yo creo que es por la contraseña con esos caracteres, sin embargo alguien sabe como escapar esos carcteres?
- Inicie sesión para enviar comentarios
Prueba a escapar las
Prueba a escapar las comillas, para que Oracle no las interprete, con una contrabarra. Sería algo así:
sqlplus usr/\"pass\"/BD@10.10.10.10/ORACLE control = C:\Users\xxxx\Documents\Compartida\carga\archivocarga.ctl
- Inicie sesión para enviar comentarios
Necesito una manito please,
- Inicie sesión para enviar comentarios
Saludos Carlos! Te escribo
Saludos Carlos!
Te escribo de México, tengo un ERP montado en Oracle 11g y al parecer mi base de datos tuvo un problema, tengo 3 ambientes (test, productivo y practicas) pero solamente mi ambiente productivo esta fuera, las personas que estan revisando el caso me dicen que pueden ver la BD pero no logram ingresar a ella, la pregunta es si se puede ver la BD aun hay posibilidades de ingresar a ella? Tenemos un respaldo, pero es de hace un mes, por consiguiente nos interesa rescatar l aBD actual para no perder informacion.
saludos!
- Inicie sesión para enviar comentarios
Lo normal es que al menos con
Lo normal es que al menos con SQLPlus desde el servidor local, y con el usuario administrador puedas entrar en la base de datos y revisar los errores que pueda tener si no se levanta. No te puedo decir mucho más, porque eso de que 'se vea' (entiendo que desde otro servidor) no me parece lo más relevante, me parece más importante revisar bien los logs y los errores que te devuelva la BD al intentar levantarla.
- Inicie sesión para enviar comentarios
hola carlos disculpa una
hola carlos disculpa una consulta me sale un error que no se ha podido realizar la conexion con el servidor verifique la conexion error n.--2147217843 Descripcion Ora-01017 nombre usuario/contraseña no validos conexion denegada.
me puede ayudar ya le cambie la contraseña como dices en e primer comentario pero me sigue saliendo el error alguna solucion.
Gracias
- Inicie sesión para enviar comentarios
Buen dia. Como puedo ejecutar
Buen dia. Como puedo ejecutar un script desde SQLPlus con un usuario X de la Base de datos en un esquema Y. Es decir quiero que el usuario de la BD llamado "Carlos" ejecute un script de un paquete pero este quede en el esquema de Pedro, sin necesidad de cambiar la creación del paquete ni digitar la clave de "Pedro"
- Inicie sesión para enviar comentarios
GRANT WITH GRANT OPTION: La propiedad transitiva en la concesión de permisos de Oracle
GRANT WITH GRANT OPTION: La propiedad transitiva en la concesión de permisos de Oracle Carlos 23 Junio, 2007 - 13:40La instrucción grant se utiliza para conceder determinados permisos genéricos o bien permisos sobre objetos a usuarios de bases de datos Oracle.
La sintaxis de GRANT para conceder permisos genéricos es la siguiente:
GRANT [privilegios_de_sistema | roles]
TO [usuarios | roles |PUBLIC] {WITH GRANT OPTION }
La sintaxis de GRANT para conceder premisos sobre objetos es la siguiente:
GRANT [ALL {PRIVILEGES} | SELECT | INSERT | UPDATE | DELETE] ON objeto
TO [usuario | rol | PUBLIC] {WITH GRANT OPTION}
La sintaxis de GRANT es muy sencilla, y los privilegios los puede conceder el usuario propietario de los objetos, o un usuario con privilegios de concesión de permisos sobre objetos que no son suyos (DBA's).
Lo que quería comentar es la utilización de la opción de grant WITH GRANT OPTION, que permite que el usuario al que le han concedido permisos pueda a su vez concederlos a otros usuarios.
Ejemplo de GRANT WITH GRANT OPTION
Mostraré la utilidad de esta opción con un ejemplo:
Imaginemos que tenemos un usuario 'U_VISTA', que crea una vista con una consulta que consulta información de un objeto de otro usuario 'U_DATOS'. Hasta aquí es sencillo, ya que con un GRANT del usuario 'U_DATOS' al usuario 'U_VISTA' sobre esos objetos el tema está solucionado. U_DATOS:
SQL> GRANT SELECT ON TABLA TO U_VISTA;
El problema vendría si tenemos un tercer usuario 'U_CONSULTA', que tiene que utilizar esta vista. Se podría pensar que con dar permisos de acceso a este usuario a la consulta por parte de 'U_VISTA', y permisos de acceso a los objetos que consulta la vista por parte de 'U_DATOS' ya estaría todo bien: U_VISTA:
SQL> GRANT SELECT ON VISTA TO U_CONSULTA;
U_DATOS:
SQL> GRANT SELECT ON TABLA TO U_CONSULTA;
Pues no, no es suficiente porque para acceder a estos datos a través de la vista ha de ser el propio propietario de la vista quien conceda los permisos a un tercero. Digamos que para la concesión de privilegios no se cumple la propiedad transitiva.
Para que 'U_CONSULTA' pueda trabajar sobre la VISTA sin que la base de datos le devuelva un error ORA-00942, el propietario de los objetos (o un usuario DBA) ha de conceder privilegios sobre esos objetos al otro usuario, pero con permisos para que este pueda a su vez concederlos a otros usuarios (grant with grant option):
U_DATOS:
SQL> GRANT SELECT ON TABLA TO U_VISTA WITH GRANT OPTION;
U_VISTA:
SQL> GRANT SELECT ON U_DATOS.TABLA TO U_CONSULTA; SQL> GRANT SELECT ON VISTA TO U_CONSULTA;
U_CONSULTA:
SQL> SELECT * FROM VISTA;
Y eso es todo, U_CONSULTA ya puede consultar los datos de la vista gracias a la opción WITH GRANT OPTION del GRANT.
Libros de Administración Oracle (DBA) y PL/SQL
¿Quieres profundizar más en PL/SQL de Oracle o en administración de bases de datos Oracle? Puedes hacerlo consultando alguno de estos libros de Oracle.
Heterogeneous Services: Conexión desde Oracle a SQLServer - DBA Oracle
Heterogeneous Services: Conexión desde Oracle a SQLServer - DBA Oracle Oscar_paredes 30 Diciembre, 2006 - 10:42Este artículo para DBA's de Oracle explica como configurar los servicios de conexión heterogeneous de Oracle para poder visualizar bases de datos SQL Server desde un esquema Oracle, como si fueran objetos propios de Oracle.
En versiones antiguas de Oracle, esta conectividad se podía realizar a través de “Gateways” que se licenciaban de manera independiente del servidor Oracle, pero la posibilidad de realizar lo mismo en sentido contrario a través de SQL Server, posibilitó la aparición de los “Heterogeneous Services” de manera gratuita en Oracle.
Para poder realizar la configuración es necesario contar con los objetos necesarios del catálogo. Por defecto están instalados, pero en determinadas instalaciones puede ser necesario realizarlo manualmente. Para ello, ejecutar como SYS el fichero caths.sql del directorio %ORACLE_HOME%/rdbms/admin. Después, el DBA de Oracle sólo ha de seguir los siguientes pasos:
- Crear un conector ODBC de SQL Server (System DSN) en el administrador de ODBC de Microsoft (por ejemplo, “sqlcon”)
- Ajuste del fichero de inicialización de Heterogeneous Services
Este fichero reside en ORACLE_HOME/HS/ADMIN, y su nombre depende del SID que se asigne al servicio. El nombre usado tipicamente es: hsodbc, de manera que el fichero se llamaría: inithsodbc.ora. Este fichero debe contener como mínimo los siguientes parámetros:
# Nombre de la conexión ODBC
HS_FDS_CONNECT_INFO = sqlmis
HS_FDS_TRACE_LEVEL = 0
HS_OPEN_CURSORS = 300
- Configuración del fichero TNSNAMES.ORA
Se debe añadir la siguiente entrada:
hsodbc =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = <IP_SERVIDOR> ) (PORT = 1521))
)
(CONNECT_DATA = (SID = hsodbc))
(HS=OK)
)
- Configuración del fichero del Listener
LISTENER.ORA: Se debe añadir a la SID_List el siguiente descriptor:
(SID_DESC =
(SID_NAME = hsodbc)
(ORACLE_HOME = C:\oracle\ora92) # el ORACLE_HOME correspondiente
(PROGRAM = hsodbc )
)
- Reinicio del listener
En los servicios del servidor reiniciar el servicio del listener.
- Conectarse con un SQL*Plus a la instancia ORACLE, y crear un database link contra el SQL Server a través de HS:
SQL> create database link hsodbc connect to "usuario" identified by "password" using 'hsodbc'
El usuario y el password deben ser los usuarios de conexión a la BBDD de SQL Server.
Por ejemplo, si el usuario es el “sa” los objetos a los que se llegará serán los objetos de la BBDD de sistema “master”.
Una vez configurado se puede acceder desde un esquema ORACLE a las tablas (objetos en general) de una BBDD SQL Server.
A modo de ejemplo, la sintaxis necesaria para realizar una simple join entre 2 tablas una Oracle y la otra SQL Server sería:
SELECT e.name, d.dept
FROM emp e, dept@hsodbc d
where e.id_dept=d.id_dept;
Oscar Paredes
IT Manager
Oracle DBA
| Adjunto | Size |
|---|---|
| XDAT012006.pdf | 162 bytes |
Conexión desde Oracle a MySQL
Este método sirve para cualquier base de datos? Se puede utilizar también con MySQL?
- Inicie sesión para enviar comentarios
Si que se puede...
Se puede conectar con el mismo sistema un Mysql a una base de datos Oracle.
Como ves el procedimiento sólo utiliza una conexión ODBC, que podría ser hacia SQL Server o hacia MySQL.
Un saludo,
- Inicie sesión para enviar comentarios
Como conectar a distintis ODBC
Realizando la conexión a MaxDB fu exitosa, se realizó siguiendo uno manuales publicados que encontre partiendo de este foro, lo que no he podido es conectarme a varias bases de datos, es decir, se configuran los archivos, pero como hace uno para habilitar un ODBC diferente. Me quiero conectar a una base de datos MaxDB y a otra SQLserver de manera simultánea. Gracias
- Inicie sesión para enviar comentarios
Alguien sabe como enlazar
Alguien sabe como enlazar una base de datos en SQL SERVER con una de ORACLE.
- Inicie sesión para enviar comentarios
Conectar SQL Server contra Oracle
Entiendo que quieres leer o escribir datos desde un SQL Server hacia un oracle.
En primer lugar debes tener el cliente de oracle en la maquina que va ha realizar el enlace. Puede que te sirva el conector OLEDB de SQL Server aunque no puedo asegurarlo puesto que en mi caso tengo las 2 bbdd en la misma máquina.
El nombre de servidor oracle debe ser: nombre_servidor_oracle/SID_oracle (no sirve nombre_servidor_oracle@sid)
usuario y password del schema a usar.
Con esto la conexión desde SQL Server a Oracle funciona perfectamente.
Saludos,
- Inicie sesión para enviar comentarios
Versiones
Sirve este sistema también para SQL Server 2005??
- Inicie sesión para enviar comentarios
SQL Server 2005
El hecho de utilizar un ODBC para el enlace con la base de datos destino hace que el sistema sirva para prácticamente cualquier base de datos.
Si en el servidor de la base de datos Oracle puedes configurar un ODBC que se conecte correctamente a otra base de datos, tienes que poder utilizar Heterogeneous Services para definir un enlace de Oracle a esta base de datos.
Con MySQL funciona, lo he podido comprobar personalmente, con SQLServer 2005 aún lo tendrás más fácil para definir el ODBC.
Carlos Fernández
Analista de sistemas
- Inicie sesión para enviar comentarios
HOLA sobre............"eje
HOLA
sobre............"ejecutar como SYS el fichero caths.sql del directorio %ORACLE_HOME%/rdbms/admin." debo decir que uso el pl/sql ejecute el archivo como usuario sys y funciona mas o menos hasta la mitad del archivo y luego me sale error de sintaxis que no reconoce el comando SQL. como lo soluciono. SE QUE HA PASADO MUCHO TIEMPO DESDE QUE SALIO ESTE TUTORIAL PERO SI ALGUIEN VE ESTO POR FAVOR AYUDAAAAAA!!!!
- Inicie sesión para enviar comentarios
Ejecutar un script como sys
PL/SQL? Lo haces desde una herramienta gráfica? Puede que ese sea el problema. Deberías ejecutarlo con SQLPlus, y dentro de una sesión del servidor donde está instalada la base de datos.
Si estás en linea de comandos con el usuario con el que se ha instalado la base de datos puedes hacer:
>sqlplus "/as sysdba"
Una vez dentro de SQLPLUS ejecutas el script con @ más el camino completo:
SQL>@oracle_home/rdbms/admin/caths
Si lo haces así no te debería fallar.
- Inicie sesión para enviar comentarios
Conexion Oracle_Access
Hola muy buena la respuesta de conexion conSqlServer...
tengo un problema con la conexion Oracle_Access tengo mi base Oracle en Linux y una Base Acces en Windows con una aplicacion.... entonces quisiera saber como hacer la conxion de mi base oracle en Linux hacia la base Access en Windows
Gracias
Attm
Roger Reyes
- Inicie sesión para enviar comentarios
Error en TNSNAMES.ORA
Buen post, aunque me llevó tiempo resolver un pequeño error.
se trata de la linea del TNSNAMES.ORA siguiente
(CONNECT_DATA = (SID = hsodbc))
que debería ser
(CONNECT_DATA = (SERVICE_NAME = hsodbc))
- Inicie sesión para enviar comentarios
Creo que no es un error. El
Creo que no es un error. El post se escribió hace tiempo, cuando se trabajaba normalmente con la versión 9i, y hasta esta versión todo funciona correctamente.
Si no me equivoco debes tener una 10g u 11g, y entonces la cadena sí que ha de ser la que indicas.
Resumiendo:
Para versiones <= 9i:
(CONNECT_DATA = (SID = hsodbc))
Para versiones posteriores a 9i:
(CONNECT_DATA = (SERVICE_NAME = hsodbc))
Gracias por la observación, luigi
- Inicie sesión para enviar comentarios
conexion a MySql
Saludos
queria preguntar por un problema que me surge, se trata que ya me conecto a MySQL 4.1,
pero el problema es que no me despliega las columnas varchar de MySQL y solo me muestra el primer registro y las dos primeras columnas que son numéricas, la tabla tiene 4 columnas
Id tipo int
sucursal tipo double
nombre tipo text
cedula tipo text
, hago select * from facturas@mysql pero solo muestra Id y sucursal del primer registro,
incluso si hago select "nombre" from facturas@mysql me dice que no se conoce la columna
esta con minusculas igual que el MySQL, talvez saben que me falta configurar?
he hecho agregando la clausula WHERE funciona pero siempre me muestra un registro y no reconoce las columnas text, si por ahi tienen alguna pista les agradezco mucho de antemano
- Inicie sesión para enviar comentarios
Me imagino que esto ya se
Me imagino que esto ya se resolvio esto hace mucho tiempo, pero para los que lleguen a leer, a mi me paso lo mismo y era la version del Odbc, utilice el 3.51.27 y listo.
- Inicie sesión para enviar comentarios
El problema era de hace
El problema era de hace tiempo, pero seguro aún sigue pasando, así que gracias por compartir tu solución, seguro que va a ser de ayuda :)
- Inicie sesión para enviar comentarios
Hola. En mi caso, requiero
Hola. En mi caso, requiero pasar los datos desde una base de datos MySQL ubicados en un servidor a una base de datos Oracle ubicados en otro servidor diferente o que por el contrario la base de datos Oracle vaya y consulte los datos de MySQL y los inserte en oracle. Qué necesitaría en este caso? es posible? Gracias de antemano.
- Inicie sesión para enviar comentarios
Con MySQL también debería
Con MySQL también debería funcionarte. La única diferencia es que tendrás que definir el conector ODBC en el servidor de Oracle apuntando hacia MySQL en lugar de hacia SQL Server.
- Inicie sesión para enviar comentarios
Saludos, Estoy realizando una
Saludos,
Estoy realizando una consulta desde oracle a una tabla que esta en sql server, pero mi problema es que me dice en oracle que el tamaño de logitud del nombre de la tabla es muy largo, hay manera de solucionar este problema sin que tenga que tener que cambiar el nombre de la tabla que se encuentra en sql server?
Ejemplo:
SELECT e.name, d.dept
FROM emp e, a1235456789012345678901234567899@hsodbc d
where e.id_dept=d.id_dept;
ORA-00972: identifier is too long
- Inicie sesión para enviar comentarios
Has probado a crear una vista
Has probado a crear una vista en SQL Server con el nombre de tabla 'corto' y llamarla desde HS?
create view v_a12354567890 as select * from a1235456789012345678901234567899
Puede que también te dé el error, pero la prueba es muy rápida.
Si esto no te sirve, una opción desde Oracle es utilizar el package de PL/SQL DBMS_HS_PASSTHROUGH, que te permite ejecutar sentencias en otras bases de datos y recibir los resultados sin que Oracle interprete nada.
No me preguntes cómo funciona porque no lo he utilizado aún, pero te enlazo la documentación del paquete por si te sirve de ayuda.
- Inicie sesión para enviar comentarios
Quisiera saber si con solo
Quisiera saber si con solo poner el ORACLE_HOME funciona o si debo tener alguna libreria en especial. mi BD es ORACLE 11g y la necesito establecer la conexion con un windows server 2008 R2...
gracias
- Inicie sesión para enviar comentarios
En principio no hace falta
En principio no hace falta ninguna librería especial para utilizar Oracle heterogeneous services, sólo que existan los objetos del catálogo que dice el post, y seguir todos los pasos de configuración para que puedas utilizar un ODBC para conectar con SQL Server.
- Inicie sesión para enviar comentarios
Buenas Tardes hay alguna
Buenas Tardes hay alguna forma de realizar una conexión desde Oracle a sqlserver sin licenciamiento de Oracle Gateway, o los diferentes driver ODBC licenciados que existen? mi caso es entre una bd Oracle 11.2.0.4 en AIX y una bd sqlserver 2008 r2, los 2 sistemas a 64bits
- Inicie sesión para enviar comentarios
Puedes conectar desde Oracle
Puedes conectar desde Oracle con SQL Server utilizando drivers ODBC, que son de libre descarga y utilización, no sé si por licenciados quieres decir de pago o es que te suponen algún otro tipo de problema..
- Inicie sesión para enviar comentarios
Hola Buenas Tardes Tengo una
Hola Buenas Tardes Tengo una conexión de oracle a firebird ,pero al realizar un select * from all_tables@DBLINK, no reconoce algunas tablas de firebird ,las cuales las necesito para hacer algunos cruces. Estoy utilizando oracle 10,centos 6. Utilizando oracle 11 en windows funciona correctamente. Gracias
- Inicie sesión para enviar comentarios
Indices invisibles en Oracle 11g
Indices invisibles en Oracle 11g Oscar_paredes 13 Septiembre, 2010 - 20:04A partir de la versión 11g Oracle permite la creación de índices llamados invisibles que permiten llevar realizar cosas realmente interesantes.
Esta invisibilidad se refiere a que el optimizador no tiene en cuenta la existencia de estos índices para la generación de los planes de ejecución.
Esto puede resultar muy interesante en bases de datos en Producción por ejemplo para:
- En el caso de probar nuevos índices sin afectar a las sentencias SQL de las aplicaciones que atacan a la base de datos, puesto que se pueden activar/desactivar de manera muy rápida.
- En el caso de querer probar ciertas sentencias SQL de aplicaciones sin índice sin tener que borrar el índice y perder tiempo recreándolo..
A partir de la versión 11g Oracle permite la creación de índices llamados invisibles que permiten llevar realizar cosas realmente interesantes.
Esta invisibilidad se refiere a que el optimizador no tiene en cuenta la existencia de estos índices para la generación de los planes de ejecución.
Esto puede resultar muy interesante en bases de datos en Producción por ejemplo para:
- En el caso de probar nuevos índices sin afectar a las sentencias SQL de las aplicaciones que atacan a la base de datos, puesto que se pueden activar/desactivar de manera muy rápida.
- En el caso de querer probar ciertas sentencias SQL de aplicaciones sin índice sin tener que borrar el índice y perder tiempo recreandolo.
Mientras un índice permanece invisible se va actualizando con las sentencias DDL (insert, update, ...), de manera que, los hace perfectos para este tipo de pruebas.
Un índice invisible se puede crear invisible o se puede alterar para que sea visible o invisible. Se puede consultar en que estado está un índice mediante la columna "visibility" de la vista DBA_INDEXES.
Un nuevo parámetro de inicialización controla la visibilidad o no de los índices invisibles "optimizer_use_invisible_indexes". Es decir, que aunque un índice sea invisible, si esta parámetro tiene el valor TRUE, el optimizador los ve y los puede usar sin problemas. Por lo que, recomiendo dejarlo siempre con el valor por defecto FALSE.
Ejemplo:
1) Verificamos el valor del parámetro que controla la visibilidad de los índices invisibles:
SQL> show parameter optimizer_use_invisible_indexes NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ optimizer_use_invisible_indexes boolean FALSE
2) Creamos una tabla de ejemplo con un indice visible:
SQL> create table prueba as select * from dba_tables; SQL> create index i_prueba on prueba (table_name);
3) Consultamos su visibilidad
SQL> select index_name , visibility from dba_indexes where index_name = 'I_PRUEBA'; INDEX_NAME VISIBILITY ------------------------------ ------------------------------ --------- I_PRUEBA VISIBLE
4) Consultamos su plan de ejecución forzando el uso del índice: Al ser visible el índice lo usará sin problemas.
SQL> explain plan 2> select /*+ index(prueba i_prueba) */ * from t where table_name Explained. SQL> select * from table(DBMS_XPLAN.DISPLAY); Plan hash value: 2609566873 ---------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 18 | 1 (0)| 00:00:02 | |* 1 | INDEX UNIQUE SCAN |I_PRUEBA | 1 | 18 | 1 (0)| 00:00:02 | ----------------------------------------------------------------------------------------
5) Hacemos invisible el índice
SQL> alter index I_PRUEBA invisible;
6) Consultamos su plan de ejecución forzando el uso del índice con un HINT: El optimizador no tiene en cuenta el índice invisible.
---------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 93 | 1008 | 31 (0)| 00:00:20 | |* 1 | TABLE ACCESS FULL | T | 93 | 1008 | 31 (0)| 00:00:20 | ----------------------------------------------------------------------------------------
Oscar Paredes
IT Manager
Oracle DBA
Limitar número de conexiones por usuario
Limitar número de conexiones por usuario cfb 23 Noviembre, 2007 - 10:34Alguien sabe si en bases de datos Oracle hay alguna manera de limitar el número de conexiones por usuario, o el número de cursores abiertos por conexión de un usuario?
El número de sesiones se
El número de sesiones se puede limitar con los profiles. Basta con añadir el número máximo de sesiones en el profile (sea el de por defecto u otro) y asignar al usuario en concreto.
- Inicie sesión para enviar comentarios
Ampliar número total de procesos
Y para ampliar el número de sesiones abiertas en la base de datos?
He probado con la sentencia 'alter system set processes=150 scope=both' con el usuario de sistema, pero la BD me responde que no se puede:
ORA-02095: el parámetro de inicialización especificado no se puede modificar
También he probado a modificar directamente el parámetro en el spfileexe.ora del directorio dbs, pero este parámetro no aparece en el fichero.
Alguien podría decirme lo que puede estar pasando?
La base de datos sobre la que estoy trabajando es una OracleXE (Oracle Database 10g Express Edition Release 10.2.0.1.0)
- Inicie sesión para enviar comentarios
Contrariamente a lo que me
Contrariamente a lo que me habían explicado se hace de la siguiente manera:
Ejecutamos:
SQL>ALTER SYSTEM SET PROCESSES=150 SCOPE=SPFILE;
y reiniciamos la base de datos.
Parece ser que al ser un parámetro estático y al poner BOTH para cambiarlo como si fuera dinámico falla. Para los estáticos se utiliza SPFILE.
Hasta los programadores de .NET sabemos de oracle!!
- Inicie sesión para enviar comentarios
Definitivamentre quedese en
Definitivamentre quedese en su .NET, si ves la respues del señor calvo..
- Inicie sesión para enviar comentarios
Comentarte que el fichero
Comentarte que el fichero SPFILE no debe modificarse manualmente, ya que quedaría inutilizable.
- Inicie sesión para enviar comentarios
Ora10g: Creación de tablas e indices con la cláusula logging / nologging
Ora10g: Creación de tablas e indices con la cláusula logging / nologging il_masacratore 21 Septiembre, 2010 - 15:30
La cláusula loggin/nologging añadida cuando creamos una tabla, índice, tablespace... determina si se crea registro de la sentencia en los redo log y su correcta restauración desde backup. Tiene guasa porque si creamos una tabla con opción nologging efectivamente no se crea registro pero de alguna manera esta si se tiene en cuenta en el diccionario de datos.
Ejemplo cronológico con malas consecuencias:
06:00 Hacemos backup con rman
09:00 Creamos tabla XXX (nologging)
09:45 Se pierde el datafile de la tabla
09:53 Recuperamos la base de datos (desde la copia, o desde la copia y archive)
Al terminar la recuperación los bloques correspondientes a la tabla/índice son marcados como corruptos y cuando intentemos acceder obtendremos un error como el siguiente:
ORA-01578: bloque de datos ORACLE corrupto (archivo número 43, bloque número 222806)
ORA-01110: archivo de datos 43: '/db/PROD/idatafiles/INDX3_20.dbf'
ORA-26040: Se ha cargado el bloque de datos utilizando la opción NOLOGGING
Casos como el anterior dan que pensar y debemos recapitular para tener más claro cuando hacerlo y cuando no. Debemos tener en cuenta:
- Recuperación/Standby
-Si la base de datos trabaja en modo archivelog. Si no es el caso tiene menos sentido usar la opción logging y por temas de rendimiento o volumen nos conviene más "probar suerte" y hacerlo con nologging.
-Si las copias las hacemos con rman. Si trabajamos en modo archivelog y usarmos rman para hacer backups lo más lógico sería hacerlo todo con la opción logging para reducir la perdida de datos al mínimo.
-Si tenemos una base de datos standby sincronizada mediante aplicación de archive logs. Es un caso como el anterior pero con más razón. Lo más lógico será hacer logging para que los objetos también se creen en el servidor en standby, tenemos que pensar que aquí podemos partir de una copia rman específica de hace tiempo y seguramente no estamos restaurandola cada semana ni cada mes.
-Velocidad de recuperación. En la creación de índices podemos precindir del logging pero debemos considerar que luego puede tocar recrearlos en la base de datos restaurada.
- Rendimiento
-El tiempo necesario para la creación de la tabla/índice. Obviamente si no dejamos log ganamos en velocidad pero aumentamos el riesgo.
-Lo asumible que es la pérdida de esa tabla índice mientras no sea recuperable. Si es una tabla que puede sobrar o prescindible (tabla de traza de cualquier aplicación) pues no pasa nada.
Con todo lo anterior y alguna cosa más que se queda en el tintero puede que nos decidamos a forzar el logging y quitarle ese poder de decisión al que ejecuta la sentencia de creación del objeto (más vale prevenir que curar, que luego vienen los llantos...). Aunque quizás no esté en sus manos, puede usar un ERP que es el intermediario en la creación de objetos de la base de datos y se los crea sin poder cambiar esa opción.
Mucho cuidado!! No vaya a ser que montemos una base de datos en standby y en el momento de la verdad cuando la vayamos a usar no tenga la mitad de las tablas.
Ora10g: ORA-00060 Deadlock detected (II)
Ora10g: ORA-00060 Deadlock detected (II) il_masacratore 21 Abril, 2011 - 17:03Siguiendo con el post anterior creo necesario comentar que existen otros tipos de bloqueo que se producen por un diseño conflictivo que se une a las peculiaridades de oracle.
Dejo primero la traza de ejemplo:
*** ACTION NAME:() 2011-04-21 14:08:01.227
*** MODULE NAME:(MiPrograma.exe) 2011-04-21 14:08:01.227
*** SERVICE NAME:(SYS$USERS) 2011-04-21 14:08:01.227
*** CLIENT ID:() 2011-04-21 14:08:01.227
*** SESSION ID:(1636.58026) 2011-04-21 14:08:01.227
DEADLOCK DETECTED ( ORA-00060 )
[Transaction Deadlock]
The following deadlock is not an ORACLE error. It is a
deadlock due to user error in the design of an application
or from issuing incorrect ad-hoc SQL. The following
information may aid in determining the deadlock:
Deadlock graph:
---------Blocker(s)-------- ---------Waiter(s)---------
Resource Name process session holds waits process session holds waits
TM-0001f1b8-00000000 99 1636 SX SSX 92 1461 SX SSX
TM-0001f1b8-00000000 92 1461 SX SSX 99 1636 SX SSX
session 1636: DID 0001-0063-0003159E session 1461: DID 0001-005C-000375B1
session 1461: DID 0001-005C-000375B1 session 1636: DID 0001-0063-0003159E
Rows waited on:
Session 1461: no row
Session 1636: no row
Aquí lo que primero nos llama la atención es que ya tenemos registros bloqueados como se ve abajo. Además el tipo de bloqueo es distinto (antes X o modo exclusivo, ahora SX o exclusivo compartido?). En la documentación podemos ver más de los tipos.
Aquí el tema está en que deadlocks con bloqueo tipo SX se producen al manipular tablas con claves foraneas donde el campo no está indexado (en la fk, no la pk de la tabla primaria) y estamos intendo hacer update/delete sobre la tabla principal. Por decirlo de alguna manera oracle necesita mantener la integridad referencial y consulta la hija para que se siga cumpliendo.
Solución en este caso? Crear siempre la clave primaria en la tabla principal, un indice y una foregin key en la tabla secundaria. Nada más...
Ora10g: ORA-00060 Deadlock detected
Ora10g: ORA-00060 Deadlock detected il_masacratore 27 Enero, 2011 - 12:02De vez en cuando puede pasar que dos sesiones que se pisen se bloqueen al intentar hacer cambios en los mismos datos (a nivel de registro o a nivel de tabla). En sistemas no concurrentes y/o bien diseñados no tiene por que pasar ya que las aplicaciones suelen estar mínimamente pensadas para evitarlo; o en todo caso en pruebas pre-producción ya se detecta y se corrige. El caso es que incluso aunque se planee evitarlos se pueden producir. En la mayoría de casos se resuelven solitos al acabar de realizar los cambios la sesión bloqueante, incluso ni nos daremos cuenta. En otros casos más infrecuentes se producen bloqueos circulares irresolubles, “deadlocks”, donde se acaba haciendo rollback de una transacción y se genera una entrada en el fichero de alerta:
ORA-00060: Deadlock detected. More info in file /opt/oracle/admin/XXX/udump/XXX_ora_28205.trc
Si consultamos el fichero de traza encontraremos información más detallada: sesiones involucradas, objeto, registro, consulta que lo provoca, etc... Aquí incluyo algunas partes de un fichero de ejemplo. En la primera parte del fichero vemos que sesión sufrirá el rollback(marcada en negrita) y más abajo vemos el bloqueo circular (donde la 1706 espera a la 1693 y viceversa):
...
*** ACTION NAME:() 2011-01-27 08:07:36.110
*** MODULE NAME:(Servicio.exe) 2011-01-27 08:07:36.110
*** SERVICE NAME:(SYS$USERS) 2011-01-27 08:07:36.110
*** SESSION ID:(1693.30703) 2011-01-27 08:07:36.110
DEADLOCK DETECTED ( ORA-00060 )
[Transaction Deadlock]
The following deadlock is not an ORACLE error. It is a
deadlock due to user error in the design of an application
or from issuing incorrect ad-hoc SQL. The following
information may aid in determining the deadlock:
Deadlock graph:
---------Blocker(s)-------- ---------Waiter(s)---------
Resource Name process session holds waits process session holds waits
TX-00090022-00173f07 82 1693 X 21 1706 X
TX-00030014-0013a2dd 21 1706 X 82 1693 X
Rows waited on:
Session 1706: obj - rowid = 0000CF1C - AAAM8cAA5AAACX+AAF
(dictionary objn - 53020, file - 57, block - 9726, slot - 5)
Session 1693: obj - rowid = 0000CF1C - AAAM8cAA5AAACX+AAI
(dictionary objn - 53020, file - 57, block - 9726, slot - 8)
…Con esta información también podemos saber exactamente que objetos y registro/s es el origen de la disputa. Si es algo que se repite de forma cíclica podemos ayudar al responsable de la aplicación dandole más datos (además de las consultas) para que lo resuelva. Para saber que registro de que tabla:
- Convertimos a decimal el obj que se indica al final en hex (0000CF1C->53020)
- Obtenemos el nombre del objeto del diccionario de datos:
SELECT owner, object_name, object_type FROM dba_objects WHERE object_id = 53020; - Consultamos la tabla obtenida buscando el registro por el rowid:
SELECT * FROM tabla WHERE rowid=’AAAM8cAA5AAACX+AAF’’
Un poco más abajo del fichero también se puede ver que consultas han provocado el deadlock y otra información como la cantidad de “waits” de la session en cuestión etc...
Todo esto me hace gracia comentarlo porque a veces desarrolladores mal acostumbrados nos piden que comprobemos si existen bloqueos entre usuarios porque tienen algo que no va tan rápido como siempre. En contraposición también tenemos a usuarios muy impacientes, que cierran a saco sus aplicaciones... Si a ti te pillan en horario, te vienen a preguntar, lo miras sin renegar, miras si existe y si la sessión bloqueante sigue trabajando... Si es el caso y hay que esperar, ¿que le dices? La primera vez le explicas de que va el tema, la segunda vez se lo recuerdas y la tercera que se vaya a tomar un café...
Oracle 10g: Buscando actividad "extra-ordinaria" en nuestra base de datos
Oracle 10g: Buscando actividad "extra-ordinaria" en nuestra base de datos il_masacratore 5 Julio, 2010 - 12:11
Al administrar nuestra base de datos tenemos que lidiar a veces con aplicaciones de terceros(ERPs, etc...) o desarrolladas dentro de la empresa que a veces pueden tener mal planteados algunos procesos o por el motivo que sea traten la base de datos como si fuera exclusivamente suya. Voy a mostraros un ejemplo:
Entorno:
-servidor con dos puntos de montaje. El del sistema operativo donde también residen los archivos de datos de la base de datos y un disco secundario donde tenemos los archivos de copia rman más los archivelogs.
-base de datos Oracle10g funcionando en modo archivelog.
-política de retención de copias de 3 días y 60 archive logs al día de media.
Sintoma:
-Nos quedamos sin espacio donde metemos los backups de la base de datos debido al crecimiento de la generación de más archivelogs de la cuenta.
Detectar la causa:
Si tenemos bien dimensionada la política de retención de backups pero de repente en nuestra base de datos se estan generando más archivelogs de la cuenta puede ser debido a una acividad "extra-ordinaria" en la base de datos. Para detectarla primero podemos consultar el número de ficheros que se generan por hora consultando la tabla v$log_history:
select to_char(FIRST_TIME,'DY, DD-MON-YYYY') day,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'00',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'00',1,0))) d_0,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'01',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'01',1,0))) d_1,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'02',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'02',1,0))) d_2,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'03',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'03',1,0))) d_3,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'04',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'04',1,0))) d_4,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'05',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'05',1,0))) d_5,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'06',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'06',1,0))) d_6,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'07',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'07',1,0))) d_7,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'08',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'08',1,0))) d_5,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'09',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'09',1,0))) d_9,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'10',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'10',1,0))) d_10,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'11',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'11',1,0))) d_11,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'12',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'12',1,0))) d_12,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'13',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'13',1,0))) d_13,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'14',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'14',1,0))) d_14,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'15',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'15',1,0))) d_15,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'16',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'16',1,0))) d_16,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'17',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'17',1,0))) d_17,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'18',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'18',1,0))) d_18,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'19',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'19',1,0))) d_19,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'20',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'20',1,0))) d_20,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'21',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'21',1,0))) d_21,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'22',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'22',1,0))) d_22,
decode(sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'23',1,0)),0,'-',sum(decode(substr(to_char(FIRST_TIME,'HH24'),1,2),'23',1,0))) d_23,
count(trunc(FIRST_TIME)) Total
from v$log_history
group by to_char(FIRST_TIME,'DY, DD-MON-YYYY')
order by to_date(substr(to_char(FIRST_TIME,'DY, DD-MON-YYYY'),5,15) )
(RESULTADO DE EJEMPLO)
Con esto ya vemos que hay un pico el lunes 1 de julio desde horas "intempestivas" hasta las 10:00 de la mañana. Si queremos informarnos más antes de hablar con los responsables podemos consultar la v$sqlarea para detectar consultar repetitivas y pesadas para conocer el sql, número de ejecucuciones, coste , etc... Una consulta ejemplo seria la siguiente:
SELECT sql_text "Sql",
executions "Ejecuciones",
ceil(cpu_time/greatest(executions,1)) "Avg Cpu",
ceil(elapsed_time/greatest(executions,1)) "Avg Disk",
ceil(elapsed_time/greatest(executions,1)) "Avg Time"
FROM v$sqlarea
ORDER BY ceil(elapsed_time/greatest(executions,1)) desc,
ceil(cpu_time/greatest(executions,1)) desc,
ceil(disk_reads/greatest(executions,1)) desc;
De esta manera conoces la tabla que se está "populando" de forma masiva y puedes preguntar al desarrollador cubriendote la espalda de antemano ya que no siempre le conocemos, le tenemos confianza o simplemente sabemos que nos acabará ocultando lo que ha hecho... o peor aún NO SABE LO QUE ESTÁ HACIENDO!!
Oracle 10g: Estadísticas artesanales de nuestra base de datos en el tiempo
Oracle 10g: Estadísticas artesanales de nuestra base de datos en el tiempo il_masacratore 10 Febrero, 2010 - 12:20Normalmente para analizar lo que pasa unas horas antes bastaría con consultar los datos históricos del Enterprise Manager pero no tenemos datos como el detalle de sesiones activas (si la cantidad total) o el estado o programa de cada una de ellas. También consultar las instantáneas en la consola web pero el problema sigue siendo el mismo, la falta de detalle. Pero no todo es insalvable y podemos en tres pasos completar esta información con algo más de detalle.
Paso 1: Crear una tabla con los datos que necesitaremos con un campo fecha.
Paso 2: Crear un procedimiento para alimentar la tabla con datos.
Paso 3: Crear un job con el usuario indicado para acumular datos.
Esta técnica puede ser “cutre” pero muchas veces sirve para analizar con más detalle y a nuestro gusto ciertas estadísticas que son visibles mediante vistas v$ que muestran el estado actual de la base de datos y que directamente no muestran un estado anterior en el tiempo.
Ejemplo para ver que está pasando con la apertura de conexiones y quién las hace:
Os podéis encontrar que en vuestra base de datos que tengáis problemas causados por la mala gestión de conexiones o choque entre aplicaciones que derivan en miles de conexiones abiertas. A esto se le puede sumar que esto ocurre fuera de horario y cuando sucede estamos normalmente en casa, sentados en el sofá viendo la tele.
Creación de la tabla:
create table AUDITORIA_SESIONES AS
(
select s.USERNAME, s.MACHINE, s.STATUS, count(*) as SESIONES, sysdate as FECHA
from v$session s
group by s.USERNAME, s.MACHINE, s.STATUS
);
Creación del procedimiento:
create or replace procedure AUDITAR_SESIONES AS
begin
insert into AUDITORIA_SESIONES
(
select s.USERNAME, s.MACHINE, s.STATUS, count(*) as SESIONES, sysdate as FECHA
from v$session s
group by s.USERNAME, s.MACHINE, s.STATUS
)
commit;
end;
En este caso se debe tener en cuenta que solo puede hacerse con el usuario sys y programar el job con su usuario. Ahora ya solo falta crear el job y consultar los datos cuando los necesitemos.
Ahora, ya depende de cada uno el uso que se le quiera dar. Esta manera de proceder nos puede sacar de un apurillo pero no es cuestión de llenar de basurilla la base de datos.
Oracle 10g: OPEN_CURSORS y SHARED_OPEN_CURSORS
Oracle 10g: OPEN_CURSORS y SHARED_OPEN_CURSORS il_masacratore 29 Enero, 2010 - 16:21Pasos que sigue Oracle para procesar una consulta:
1) Validación Sintáctica
2) Validación Semántica
3) Optimización
4) Generación del QEP (Query Execution Plan)
5) Ejecución del QEP (Query Execution Plan)
En algunos entornos nos podemos encontrar con aplicaciones que realizan ciertas consultas (y digo consultas) de forma muy reetiva de forma continua. Cuando el catálogo es muy amplio, continuo e inevitable debemos tener en cuenta dos parámetros de inicialización de la base de datos: open_cursors y session_cached_cursors.
Open_cursors nos permite establecer el límite de cursores por sesión y su seteo es muy directo. Si se necesitan 1000 y no hay nada que optimizar pues 1000 pondremos. En cambio Session_cached_cursors es algo más complejo y requiere analizarse en base al número máximo de cursores (open_cursors) y la cantidad actual de cursores que se mantienen en "cache" actualmente.
Consulta:
select
'session_cached_cursors' parameter,
lpad(value, 5) value,
decode(value, 0, ' n/a', to_char(100 * used / value, '990') || '%') usage
from
( select
max(s.value) used
from
sys.v_$statname n,
sys.v_$sesstat s
where
n.name = 'session cursor cache count' and
s.statistic# = n.statistic#
),
( select
value
from
sys.v_$parameter
where
name = 'session_cached_cursors'
)
union all
select
'open_cursors',
lpad(value, 5),
to_char(100 * used / value, '990') || '%'
from
( select
max(sum(s.value)) used
from
sys.v_$statname n,
sys.v_$sesstat s
where
n.name in ('opened cursors current', 'session cursor cache count') and
s.statistic# = n.statistic#
group by
s.sid
),
( select
value
from
sys.v_$parameter
where
name = 'open_cursors'
) ;
Ejemplo: PARAMETER VALUE USAGE ---------------------- --------------- ----- session_cached_cursors 100 100% open_cursors 300 57%
Si con el valor actual observamos que el uso es del 100% podemos incrementar de forma moderada el parámetro session_cached_cursors y observar el resultado. Siempre que este por debajo estamos reutilizando todos los que son posibles y estamos optimizando al evitar el "hard parse" de la consulta reduciendo el uso de cpu. Pero cuidado, tampoco vale igualar este parámetro al número máximo de cursores ya que no es oro todo lo que reluce y cuanto más grande sea este valor mayor memoria estamos consumiendo y en servidores cortitos de harware puede pasar factura por otro sitio.
Oracle 10g: Resumir tablespaces transportando tablas e indices
Oracle 10g: Resumir tablespaces transportando tablas e indices il_masacratore 24 Febrero, 2010 - 16:21Por el motivo que sea nos podemos encontrar que en nuestra base de datos Oracle tenemos muchos tablespace y para hacer un poquito de limpieza decidamos resumir los que estén duplicados. Entoces nos dirigimos a OEM y vemos una maravillosa liista de 50 tablespace con nombres sin sentido, algunos vacíos y otros por triplicado por que han llegado al tamaño que consideran máximo (en lugar de tres datafiles) etc etc... Llega el momento de ponerse manos a la obra.
Recordar que para ver el contenido de un tablespace nos podemos dirigir a Oracle Enterprise Manager y en la sección Administración>tablespaces marcar el que queramos, seleccionar en el desplegable Mostrar Dependencias y luego pulsando Ir. Luego veremos una segunda pestaña Dependientes. Ahí se muestran todos los objetos dependientes del tablespace (contenidos, vamos).
Ejemplo a) Solo índices
Nos encontramos que tenemos tres tablespaces IDX1, IDX2 e IDX3 que contiene índices creados por el mismo usuario APL y que son de la misma aplicación; lo que queremos hacer es resumirlos en un único tablespace IDX1. Para hacerlo podemos:
a)Hacer un export/import
b)Modificar indice por índice con la siguiente sql:
ALTER INDEX [indice] REBUILD TABLESPACE [nuevo tablespace]
La opción b) es una buena manera de hacerlo ya que aunque se tarde más el usuario seguro que no se dá ni cuenta.
Ejemplo b) Tablas e índices
Tenemos dos tablespace DAT1 y DAT2, y queremos mover las tablas de DAT2 a DAT1. Opciones:
a)Hacer un export/import
b)Modificar tabla por tabla (más sus índices*).
ALTER TABLE [tabla] MOVE TABLESPACE [nuevo tbspace];
ALTER INDEX [indice] REBUILD;
*En el caso de las tablas, al moverlas de un tablespace a otro hay que reconstruir los índices ya que quedan en estado “unusable”. Cualquier inserción posterior al traslado de tablespace sin la reconstrucción del indice producirá un error ORA.
Tambien mejorará el rendimiento
Pues sí, con este método se puede hacer limpieza y organizar los tablespaces, y también ayuda a mejorar el rendimiento, ya que la reconstrucción de los mismos elimina la fragmentación de datos que puediera existir.
- Inicie sesión para enviar comentarios
Oracle global_names
Oracle global_names il_masacratore 2 Julio, 2009 - 13:26Hola!
Puede alguien explicarme brevemente la utilidad de los global_names? Por lo que he visto existe un parámetro para activar o desactivar su uso. También existe una variable donde se guarda el nombre global de la base de datos actual.
¿Que se puede ver afectado si los desactivas?
¿Que puede verse afectado si cambias el nombre actual?
Buenas, El nombre global de
Buenas,
El nombre global de la base de datos se encuentra en la vista GLOBAL_NAME y está compuesto por el nombre de la base de datos (DB_NAME) más el nombre del dominio (DB_DOMAIN). La utilidad que tiene componerlo con un nombre de dominio es que permite distinguir o referenciar dos bases de datos que se llamen igual, pero que se encuentren en diferentes dominios.
Se me ocurre que yo podría tener, por ejemplo, una base de datos en el servidor de Dataprix, y un réplica de desarrollo en un PC de mi casa, y las distinguiría así:
SQL> select * from global_name;
GLOBAL_NAME
------------------------------------------------------------
MIBD.DATAPRIX.COM
SQL> select * from global_name;
GLOBAL_NAME
------------------------------------------------------------
MIBD.MICASA.COM
Si yo definiera un DBLINK a cada una desde una tercera BD, el dominio me permitiría distinguirlas.
Comentar también que a nivel de parámetros, el global database name se almacena en el parámetro SERVICE_NAMES del fichero de parámetros de inicialización.
Si cambias el nombre actual, si no estás en el caso que en tu sistema se acceda a dos bases de datos con el mismo nombre y diferentes dominios lo que deberías revisar sobretodo son los DBLINKS que haya definidos contra la BD, y teniendo en cuenta si el parámetro global_names (que no es lo mismo que la vista o sinónimo GLOBAL_NAME que acabamos de ver) está a TRUE o FALSE.
Si está a TRUE, este parámetro obliga a que los database links que se definan contra la base de datos utilicen como nombre el GLOBAL_NAME de la misma, por lo que en este caso, si cambias el GLOBAL_NAME, las sentencias que utilicen los DBLINKS devolverían un error ORA-02085 hasta que redefinieras el DBLINK, o modificaras el valor del parámetro global_names a FALSE.
Si global_names está a FALSE, la BD ya no obliga a que el DBLINK utilice el mismo nombre global que la BD que enlaza, pero el nombre global sigue siendo el mismo.
Si la BD arranca con spfile, para desactivar este chequeo a nivel de sistema basta con ejecutar:
SQL> ALTER SYSTEM SET global_names=FALSE; Para evitar problemas, a menos que sea necesario hacerlo de otra manera por las razones que ya hemos comentado, yo suelo poner el parámetro global_names a FALSE, y el valor de GLOBAL_NAME con el mismo dominio que el de mi sistema (cuando creas la BD se suele quedar con el impresionante DB_DOMAIN de Oracle REGRESS.RDBMS.DEV.US.ORACLE.COM, que es fácil que nos de algún problema por su longitud). Modificarlo es tan fácil como:
SQL> alter database rename GLOBAL_NAME to MIBD.DATAPRIX.COM;
Database altered.
- Inicie sesión para enviar comentarios
Oracle10g: Cambiar el juego de carácteres de la base de datos
Oracle10g: Cambiar el juego de carácteres de la base de datos il_masacratore 9 Marzo, 2010 - 12:24Puede suceder que después de instalar Oracle o configurar una nueva base de datos nos demos cuenta de que el juego de carácteres elegido durante la instalación no es el correcto. Lo que se nos puede ocurrir en casos como este es borrar la base de datos y reconfigurarla o cosas peores... Pero no hace falta. Podemos cambiar el juego de carácteres parando la base de datos, levantandola de forma restrictiva, cambiando la configuración y reiniciado la base de datos. Howto:
--Primero nos conectamos con la base de datos
$ sqlplus sys/pwd@prod as sysdba
--Paramos la base de datos
SQL>SHUTDOWN IMMEDIATE;
--Levantamos de forma restrictiva*
SQL>STARTUP MOUNT;
SQL>ALTER SYSTEM ENABLE RESTRICTED SESSION;
SQL>ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
SQL>ALTER DATABASE OPEN;
--Cambiamos el mapa de carácteres
SQL>ALTER DATABASE CHARACTER SET <nuevo mapa de carácteres>;
--Reiniciamos la base de datos y yata
SQL>SHUTDOWN IMMEDIATE;
SQL>STARTUP;
Para comprobar que los cambios han surtido efecto podemos consultar la vista v$nls_parameters y comprobar el valor de nls_characterset. Debemos saber que según el cambio de codificación que hagamos podemos perder datos (si es que los hay) dependiendo del cambio.
*También es útil saber que levantar la base de datos en modo restrictivo es muy útil para realizar tareas de mantenimiento de la base de datos que se pueden hacer más rápido cuando no hay actividad de usuario (como puede ser reconstrucción de índices, reducción de segmentos, etc).
Oracle10g: Manual standby database (planteamiento inicial)
Oracle10g: Manual standby database (planteamiento inicial) il_masacratore 16 Marzo, 2010 - 11:43Una base de datos Oracle en Standby es una copia exacta de una base de datos operativa en un servidor remoto, usada como backup, como copia para consulta, recuperación de desastres, etc.
Una base de datos en modo Standby es algo más que un backup normal ya que se puede poner en producción en caso de desastre en un tiempo menor que si tuvieramos que restaurar una copia (ya sea desde rman o un simple export).
Restaurar una copia desde fichero tarda tiempo, y durante este periodo el sistema no está disponible. Con una base de datos adicional en modo standby no hay nada (o casi nada que restaurar) en caso de desastre. En cuestión de minutos se hace el cambio permitiendo continuidad en el servicio. No nos ofrece las ventajas de rendimiento de un cluster o la seguridad del espejo pero la relación de costes de tiempo y licencia versus ventajas me parece correcta.
Desde un punto de vista global:
- Disponemos de una copia de la base de datos de forma remota, que podemos contabilizar como segundo juego de copias.
- A diferencia de un simple backup, la copia se mantiene viva y los datos son actualizados con mayor frecuencia.
- En caso de desastre la podemos usar en cuestión de minutos sin esperar a restaurar un backup entero, ya sea lógico(export) o físico(rman).
- Sirve como entorno de pruebas más real para la prueba de parches y estimación de tiempos. El volumen de datos es idéntico.
- Tengo entendido que una base de datos en standby se puede usar hasta 10 dias al año sin coste de licencia (aunque mira por donde Microsoft te deja 30 dias... )
Desde un punto de vista técnico:
- Los cambios en la base de datos principal se captura en los archivos de redo log.
- Los archivos de redo no son permanentes, son sobreescritos de forma rotativa (en este estado aún no se copia al segundo servidor).
- Se hace una copia del redo log. La copia permanente se llama archive log.
- Los archive logs(copias de redo log) se transfieren al servidor en standby. En sistemas linux por ejemplo podemos hacerlo mediante rsync.
- Se aplican los archive logs transferidos a la base de datos en standby quedando actualizada.
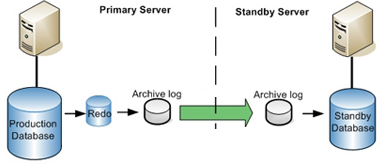
A nivel global los pasos a seguir para montar el chiringuito pueden ser los siguientes:
- Configurar la base de datos principal para que funcione en modo archivelog.
- Preparar un script para hacer una copia en caliente (usando rman).
- Crear un fichero de control standby (control file) en la base de datos principal.
- Copiarlo todo (fichero de configuración, de control y copia rman) en el segundo servidor (donde montamos la base de datos en standby).
- Reconfigurar rutas (usando DB_FILE_NAME_CONVERT en init.ora o a manita).
- Iniciar la segunda base de datos en modo mount standby database.
- Restaurar datos (recover database).
- Sincronizar de forma periódica(cron) transportando (rsync?) y aplicando los archive logs.
En otro post intentaré entrar en más detalle con un ejemplo... y las utilidades que le podemos dar.
No olvidemos la vuelta atrás
Sólo comentar que también es conveniente planificar como último paso la vuelta atrás a la base de datos de producción original en caso de que se tenga que utilizar la base de datos en Standby.
En un tiempo aceptable habrá que volver a recrear o actualizar la BD de producción inicial, pero incluyendo los cambios que se produzcan en el tiempo que esté activa la BD en Standby, y eso puede llegar a ser bastante complicado según las condiciones del entorno..
- Inicie sesión para enviar comentarios
Hola, Respecto al punto
Hola,
Respecto al punto de:
- Tengo entendido que una base de datos en standby se puede usar hasta 10 dias al año sin coste de licencia (aunque mira por donde Microsoft te deja 30 dias... )
En un ambiente de recuperación ante desastres con un server en Standby, Oracle le requerirá licenciar la Base de Datos en standby en misma métrica y cantidad de licencia que la Base de Datos en producción. (asociada a ella).
Para más detalle acceder a: http://www.oracle.com/us/corporate/pricing/sig-070616.pdf
Saludos,
- Inicie sesión para enviar comentarios
Hola Mario Lo que yo
Hola Mario
Lo que yo recuerdo de hace tiempo es que si se monta un RAC en modo activo, es decir, con los servidores Oracle que conforman el cluster funcionando al 100% para dar servicio a las instancias, tienes que licenciar todos los servidores de base de datos que tengas funcionando, pero si se monta en modo Activo/pasivo, con un server activo funcionando en producción, y otro (el pasivo) en standby, con la licencia del activo es suficiente para poder mantener este interesante sistema de recuperación, que ante cualquier problema en el server activo permite tomar el control temporalmente al pasivo.
Eso sí, el pasivo sólo ha de estar activo el tiempo necesario para resolver el problema en el server activo, después el servidor licenciado ha de volver a tomar el control, y el otro volver al modo standby, por eso la licencia sólo permite la utilización del server en Standby como activo durante 10 días.
En el documento de Oracle que mencionas, en la página 18, se enlaza otro documento que aclara el licenciamiento de los entornos de recuperación:
Backup/Failover/Standby/Remote Mirroring – Please see the Licensing Data Recovery Environments document: http://www.oracle.com/us/corporate/pricing/data-recovery-licensing-0705… for more information.
Consultando el otro documento, veo que este método se incluye dentro de Data Recovery using Clustered Environments (Failover), y este párrafo creo que es bastante aclaratorio:
The failover data recovery method is an example of a clustered deployment; where multiple nodes/servers have access to one Single Storage/SAN. In such cases your license for the programs listed on the US Oracle Technology Price, includes the right to run the licensed program(s) on an unlicensed spare computer in a failover environment for up to a total of ten separate days in any given calendar year..
Y, sin embargo, el standby lo menciona dentro del apartado 'Data Recovery Environments using Copying, Synchronizing or Mirroring':
Standby and Remote Mirroring are commonly used terms to describe these methods of deploying Data Recovery environments. In these Data Recovery deployments, the data, and optionally the Oracle binaries, are copied to another storage device..
Yo entiendo entonces que no son necesarias licencias extra siempre que se utilice el método de failover para dos servidores que compartan la unidad de almacenamiento.
- Inicie sesión para enviar comentarios
Oracle10g: Poner la base de datos en modo archivelog y hacer backups con rman
Oracle10g: Poner la base de datos en modo archivelog y hacer backups con rman il_masacratore 17 Junio, 2010 - 12:05El modo archivelog de una base de datos Oracle protege contra la pérdida de datos cuando se produce un fallo en el medio físico y es el primer paso para poder hacer copias de seguridad(en caliente!!) con rman. Para poner la base de datos en modo archivelog (sin usar la flash recovery area) debemos hacer básicamente dos cosas, añadir dos parámetros nuevos al fichero de configuración, reiniciar la base de datos y cambiar el modo trabajo a archivelog.
Como poner la base de datos Oracle 10g en modo archivelog
- Editamos el init.ora para añadir los siguientes parámetros
*.log_archive_dest='/ejemplo/backup/'
*.log_archive_format='SID_%r_%t_%s'
- Reiniciamos la base de datos para que coja los cambios y nos aseguramos.
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount pfile='/ejemplo/pfile/init.ora
ORACLE instance started.
Total System Global Area 272629760 bytes
Fixed Size 788472 bytes
Variable Size 103806984 bytes
Database Buffers 167772160 bytes
Redo Buffers 262144 bytes
Database mounted.
SQL> alter database archivelog;
Database altered.
SQL> alter database open;
Database altered.
SQL> create spfile;
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup
Backups con RMAN
Una vez tenemos la base de datos funcionando en modo archivelog ya podemos plantearnos hacer los backups con rman. Para hacerlos basta con editar un script donde básicamnte hacemos la copia y mantenemos archives en base a cuantos copias queremos mantener y cada cuando ejecutaremos el script. Solo debemos tener cuidado y dimensionar correctamente el número de copias y archivelog que mantemos en base al espacio disponible en el disco. Para saber cuanto espacio necesitaremos podemos aplicar la siguiente formula, suponiendo que la copia sea diaria:
Espacio necesario = (num_backups_rman_mantenidos*tamanyo_backups_rman)+(media_num_redos_al_dia)*(dias_mantenidos).
Pasos para empezar a hacer backups:
- Editamos el script de sistema para el lanzamiento (/ejemplo/scripts/rman.sh) :
#!/bin/bash
export ORACLE_HOME=/opt/oracle/product/10.2/db_1/
export ORACLE_SID=SID
/opt/oracle/product/10.2/db_1/bin/rman @/ejemplo/scripts/rman.sql > /backup/scripts/rman.log
- Script sql que lanzaremos con el sh anterior (/ejemplo/scripts/rman.sql). No hace falta comentarlo porque es muy fácil leer lo que está haciendo en cada paso. Vereis también donde se indica la caducidad de los backups y los archives.
connect target root/password@SID
run {
CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF 3 DAYS;CONFIGURE CONTROLFILE AUTOBACKUP ON;
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '/ejemplo/backup/%F';CONFIGURE CHANNEL DEVICE TYPE DISK FORMAT '/ejemplo/backup/%d_%Y%M%D%U';
CONFIGURE DEVICE TYPE DISK PARALLELISM 1 BACKUP TYPE TO COMPRESSED BACKUPSET;
CONFIGURE MAXSETSIZE TO 8000M;backup database
include current controlfile
plus archivelog;CROSSCHECK BACKUP completed before 'sysdate - 4';
DELETE NOPROMPT OBSOLETE;
DELETE NOPROMPT ARCHIVELOG UNTIL TIME "SYSDATE - 4";
delete noprompt expired backup;
delete noprompt expired archivelog all;
report schema;
}
exit;
- Programamos la tarea (crontab?) y listo!!
Para más información sobre los archive redo logs aquí.
Reducción de Segmentos en Oracle 10g: Shrink Table
Reducción de Segmentos en Oracle 10g: Shrink Table Oscar_paredes 19 Febrero, 2007 - 19:41En Oracle 10g existe una nueva funcionalidad para DBA's de Oracle para a la recuperación del espacio ocupado por una tabla sin necesidad de recrearla: SHRINK TABLE
Es habitual en versiones anteriores a la versión 10g el problema generado por el borrado de registros de una tabla y la generación de “huecos” a nivel de los bloques que componen esa tabla. A modo de ejemplo: es habitual para un DBA de Oracle la duda tras el borrado masivo de muchos registros de una tabla (o de todos) y la comprobación tras la eliminación de los registros de que la tabla ocupa exactamente lo mismo (misma HWM – High Water Mark).
Esta situación también se da en sistemas OLTP donde con el tiempo, y con las inserciones/borrados de registros en determinadas tablas, se van generando espacio no reutilizables por las nuevas inserciones por falta de espacio en los bloques incompletos, y a la larga caídas de rendimiento en los sistemas.
El método tradicional para recuperar este espacio consistía en realizar periódicamente export/import de la tabla en cuestión o recreación de la misma. Eso conllevaba una serie de problemas en la práctica como invalidación de índices, vistas, procedimientos…
En Oracle 10g surge la funcionalidad shrink table, que no sólo permite la recuperación de este espacio y recuperación del acceso óptimo a la misma, sino que permite realizarlo en 2 fases diferenciadas disminuyendo el tiempo de afectación a los usuarios.
Para que el DBA lleve a cabo esta recuperación de espacio puede seguir los siguientes pasos:
- Habilitación de movimientos de filas:
SQL> ALTER TABLE tabla ENABLE ROW MOVEMENT; - Movimiento de las filas:
SQL> ALTER TABLE tabla SHRINK SPACE COMPACT; - Reseteo HWM
SQL> ALTER TABLE tabla SHRINK SPACE;
Tan solo durante el último punto del procedimiento existe bloqueo de tabla, pero sin duda el punto 2 es el más costoso en tiempo y se puede hacer totalmente online.
Oscar Paredes
IT Manager
Oracle DBA
hola que tal es recomendable
- Inicie sesión para enviar comentarios
Seguridad en Oracle
Seguridad en Oracle drakon 30 Enero, 2007 - 22:15En éste post os adjunto varios documentos PDF relacionados con la seguridad y administración de Oracle. Por una parte, sabiendo que incluso el sistema de contraseñas en Oracle 11g es débil, os linko un documento PDF publicado por NGSSoftware y que trata de ayudar a proteger Oracle bajo los ataques de fuerza bruta contra las contraseñas y además donde presenta la herramienta de fuerza bruta: OraBrute.
Por otra parte os linko otro documento PDF dónde explica cómo proteger Oracle en tan sólo 20 minutos que, aunque no es un sistema para proteger completamente la base de datos, sirve como mínimo para tapar aquellos agujeros más evidentes.
Finalmente una pequeña herramienta para aquellos técnicos que viajan de empresa en empresa y puedan aprovecharla. Se llama WinSID y es un sencillo descubridor de instancias de Oracle pero que para su ejecución no es necesario tener el cliente de Oracle instalado. Permite determinar si un servidor remoto tiene una base de datos Oracle y, en caso de encontrarla, obtiene información de servicios, el SID, estadísticas del listener, conexiones establecidas... y además genera un TSNNAMES.ORA para la conexión encontrada. ¿Qué os parece?
mezclas cosas
por un lado hablas de la base de datos (Oracle 10g) y por otro de Oracle Applications (Oracle Applications 11i).
- Inicie sesión para enviar comentarios
WinSID
Acabo de probar el WinSID, y la encuentro fácil de utilizar y bastante útil, hasta me ha devuelto una instancia de Oracle que yo desconocía en el servidor de desarrollo donde lo he probado!
- Inicie sesión para enviar comentarios
Tablespaces Encriptados en Oracle 11g - Oracle DBA
Tablespaces Encriptados en Oracle 11g - Oracle DBA Oscar_paredes 4 Abril, 2011 - 14:40A partir de la release 1 de Oracle 11g, Oracle ofrece a los DBA's la posibilidad de encriptar los tablespaces al completo, para proteger datos sensibles en su interior y accesibles desde Sistema Operativo. Es decir, el objetivo de esta nueva funcionalidad no es proteger datos sensibles de usuarios de la Base de Datos, sino de proteger la información de los datafiles de tablespaces.
Para explicar la utilidad de esta funcionalidad, lo mejor es explicar situaciones en las que sin esta funcionalidad nuestros datos serian vulnerables. Por ejemplo, en el caso de que el fichero de un backup físico de un tablespace de base de datos llegase a manos no deseadas, podría ver algunos datos “en claro” sin problemas. A modo de ejemplo, una simple edición del tablespace (o un simple “cat”) que contuviera la tabla empleados, nos mostraría los campos varchar2 en claro, pudiendo extraer datos sensibles (no os lo creéis, probadlo!).
Para esta funcionalidad, Oracle utiliza el TDE – Transparent Data Encryption, mediante la creación de una Oracle Wallet que se almacena en disco. Por defecto, en la localización $ORACLE_BASE/admin/$ORACLE_SID/wallet, pero es recomendable cambiar su localización mediante el uso del parámetro ENCRYPTION_WALLET_LOCATION en el sqlnet.ora.
Para la creación de esta Wallet:
ALTER SYSTEM SET ENCRYPTION KEY AUTHENTICATED BY "myPassword";
El tablespace encriptado se puede crear de la siguiente manera:
CREATE TABLESPACE seguro_tbs
DATAFILE '/oradata/seguro_ts01.dbf.dbf' SIZE 1M
ENCRYPTION USING 'AES256'
DEFAULT STORAGE(ENCRYPT);
Si no se indica lo contrario, el algoritmo de encriptación usado es el AES256 (Advanced Encryption Standard), pero los siguientes algoritmos también están permitidos:
AES256, AES192, AES128 y 3DES168
Al reiniciar la base de datos, deberemos abrir la wallet para poder consultar los datos de los tablespaces encriptados:
ALTER SYSTEM SET WALLET OPEN IDENTIFIED BY "myPassword";
También podemos cerrarla en cualquier momento:
ALTER SYSTEM SET WALLET CLOSE;
Si no abrimos una wallet, el resultado de cualquier query sobre alguna tabla de dicho tablespace es el error ORA-28365 “wallet is not open”.
La consulta de si un tablespace está encriptado o no, se puede realizar desde la misma vista dba_tablespaces:
SQL> SELECT tablespace_name, encrypted FROM dba_tablespaces;
TABLESPACE_NAME ENCRYPTED
------------------------------ ---------
SYSTEM NO
SYSAUX NO
UNDOTBS1 NO
TEMP NO
SEGURO_TBS YES
Espero que os sea útil.
Oscar Paredes
IT Manager
Oracle DBA
como puedo hacer esa
como puedo hacer esa encriptacion del tablespace en Oracle Express, ya que asi como tu lo has hecho yo tambien pero sobre la version Enterprise y requiero hacerlo sobre la version Express 11g
- Inicie sesión para enviar comentarios
Por favor si tienen una
- Inicie sesión para enviar comentarios
Utilización de sinónimos para compartir objetos
Utilización de sinónimos para compartir objetos Carlos 25 Noviembre, 2006 - 00:23Cómo utilizar los sinónimos de Oracle para que un usuario pueda ver/utilizar objetos de un esquema que pertenezca a otro usuario. Es algo muy sencillo y realmente útil. Lo único que hay que hacer es crear un sinónimo para cada objeto que queramos 'compartir', y después asignar los permisos que interese al esquema que quiere acceder al objeto.

-- Creación del sinónimoCREATE PUBLIC SYNONYM "MI_TABLA" FOR "YO"."MI_TABLA";
Utilizamos un sinónimo público para compartirlo para diferentes esquemas. La asignación de permisos sí que es específica para cada esquema que tenga que acceder al objeto
-- Asignación de permisos para el usuario ELGRANT SELECT ON "YO"."MI_TABLA" TO "EL";
GRANT UPDATE ON "YO"."MI_TABLA" TO "EL";
GRANT INSERT ON "YO"."MI_TABLA" TO "EL";
GRANT DELETE ON "YO"."MI_TABLA" TO "EL";-- Si se quiere dar acceso sólo de consulta a esta misma tabla para otro usuario, bastaría con hacerGRANT SELECT ON "YO"."MI_TABLA" TO "ELLA";
Ahora "EL" y "ELLA" ya pueden trabajar sobre "MI_TABLA" cada uno con los permisos que el propietario de la tabla ha decidido
Lenguaje Oracle SQL, PL/SQL y desarrollo
Lenguaje Oracle SQL, PL/SQL y desarrollo Dataprix 8 Septiembre, 2009 - 09:49Cómo hacer o mejorar sentencias Oracle SQL, utilizar PL/SQL y los procedimientos almacenados, o cualquier cosa relacionada con el desarrollo o explotación de bases de datos Oracle
Construcción de scripts Oracle SQL con ayuda del diccionario
Construcción de scripts Oracle SQL con ayuda del diccionario Carlos 7 Junio, 2007 - 23:12Es bastante habitual si se trabaja con bases de datos que a menudo se tenga que realizar alguna tarea de creación o alteración de estructuras, análisis, recompilación, etc. sobre objetos de la base de datos. Para ello se suele crear un script con numerosas sentencias DDL, en las que la mayoría de las veces lo único que cambia es el nombre del objeto a tratar.
Crear sentencia Oracle SQL que genera sentencias Oracle
En estos casos puede ahorrarnos mucho trabajo la utilización del diccionario de la base de datos para construir estas sentencias dinámicamente. Pondremos como ejemplo la creación de un nuevo campo para almacenar la fecha de creación de los registros en todas las tablas de un esquema de una base de datos ORACLE. Para ello utilizaríamos la siguiente sentencia de SQL Oracle:
SELECT 'ALTER TABLE ' || OWNER || '.' || TABLE_NAME || ' ADD FECHA_CREACION DATE DEFAULT SYSDATE;'
FROM ALL_TABLES WHERE OWNER ='HR'; El resultado de esta sentencia SQL Oracle sería algo como esto, las sentencias SQL que queremos utilizar en realidad:
ALTER TABLE HR.DEPARTMENTS ADD FECHA_CREACION DATE DEFAULT SYSDATE; ALTER TABLE HR.EMPLOYEES ADD FECHA_CREACION DATE DEFAULT SYSDATE; ALTER TABLE HR.JOB_HISTORY ADD FECHA_CREACION DATE DEFAULT SYSDATE; ALTER TABLE HR.JOBS ADD FECHA_CREACION DATE DEFAULT SYSDATE; ALTER TABLE HR.LOCATIONS ADD FECHA_CREACION DATE DEFAULT SYSDATE; ALTER TABLE HR.REGIONS ADD FECHA_CREACION DATE DEFAULT SYSDATE; ALTER TABLE HR.COUNTRIES ADD FECHA_CREACION DATE DEFAULT SYSDATE;
Crear script con Oracle SQL para ejecutar sentencias SQL
Ahora sólo restaría guardar estas sentencias en un script y ejecutarlo, o lanzarlas directamente desde la aplicación que utilicemos para interactuar con nuestra base de datos.
Para el que tenga que (o prefiera) trabajar desde un terminal o linea de comandos, la manera de hacer esto mismo con SQLPLUS sería la siguiente:
SQL> SET HEADING OFF
SQL> SET FEEDBACK OFF
SQL> SPOOL C:\campo_auditoria.sql
SQL> SELECT 'ALTER TABLE ' || OWNER || '.' || TABLE_NAME || ' ADD FECHA_CREACION DATE DEFAULT SYSDATE;'
FROM ALL_TABLES WHERE OWNER ='HR';
SQL> SPOOL OFF;
SQL> SET FEEDBACK ON
SQL> SET HEADING ON Y finalmente ejecutar el script generado, aunque es recomendable una revisión previa de las sentencias generadas:
SQL> @C:\campo_auditoria.sql
Estructura de la Dimension Tiempo y Script de carga con Oracle SQL
Estructura de la Dimension Tiempo y Script de carga con Oracle SQL Carlos 29 Agosto, 2009 - 23:47Con este script de Oracle SQL se crea una tabla DIM_TIEMPO y se rellena con los valores comprendidos entre las fechas que se indiquen en las variables FechaDesde y FechaHasta. Puede ser muy útil para la creación de la tabla de tiempo de cualquier Data Warehouse.
Esta es la versión para una base de datos Oracle, con Oracle SQL, que se suma a las que han creado anteriormente il_masacratore y Dario Bernabeu para Microsoft SQL Server y Oracle MySQL en sus respectivos blogs:
Estructura de la Dimensión Tiempo y Script de carga para Ms SQL Server
Estructura de la Dimensión Tiempo y Procedure de carga para MySQL
----------------------------------------------------
-- SQL de Creación de la tabla DIM_TIEMPO --
----------------------------------------------------
drop table DIM_TIEMPO;
create table DIM_TIEMPO
(
FechaSK number not null,
Fecha date not null PRIMARY KEY,
Año number not null,
Trimestre number not null,
Mes number not null,
Semana number not null,
Dia number not null,
DiaSemana number not null,
NTrimestre varchar2(7) not null,
NMes varchar2(15) not null,
NMes3L varchar2(3) not null,
NSemana varchar2(10) not null,
NDia varchar2(6) not null,
NDiaSemana varchar2(10) not null
);------------------------------------------------------------
-- Script Oracle SQL de carga de los datos entre fechas --
------------------------------------------------------------
DECLARE
FechaDesde date;
FechaHasta date;
BEGIN
--Borrar datos actuales, si fuese necesario
--TRUNCATE TABLE DIM_TIEMPO
--Rango de fechas a generar: del 01/01/2006 al 31/12/Año actual+2
FechaDesde := TO_DATE('20060101','YYYYMMDD');
FechaHasta := TO_DATE((TO_CHAR(sysdate,'YYYY')+2 || '1231'),'YYYYMMDD');
WHILE FechaDesde <= FechaHasta LOOP
INSERT INTO DIM_TIEMPO
(
FechaSK,
Fecha,
Año,
Trimestre,
Mes,
Semana,
Dia,
DiaSemana,
NTrimestre,
NMes,
NMes3L,
NSemana,
NDia,
NDiaSemana
)
VALUES
(
to_char(FechaDesde,'YYYYMMDD'),
FechaDesde,
to_char(FechaDesde,'YYYY'),
to_char(FechaDesde, 'Q'),
to_char(FechaDesde,'MM'),
to_char(FechaDesde,'WW'),
to_char(FechaDesde,'DD'),
to_char(FechaDesde,'D'),
'T'||to_char(FechaDesde, 'Q')||'/'||to_char(FechaDesde,'YY'),
to_char(FechaDesde,'MONTH'),
to_char(FechaDesde,'MON'),
'Sem '||to_char(FechaDesde,'WW')||'/'||to_char(FechaDesde,'YY'),
to_char(FechaDesde,'DD MON'),
to_char(FechaDesde,'DAY')
);
--Incremento del bucle
FechaDesde := FechaDesde + 1;
END LOOP;
END;
Como cada uno se adaptará el formato de las fechas al que más le convenga, aprovecho para adjuntar esta tabla de ayuda obtenida de Oradev. Contiene descripciones de la sintaxis que se puede utilizar en las máscaras de formato de fechas de las funciones TO_CHAR y TO_DATE de Oracle:
| Format mask | Description |
|---|---|
| CC | Century |
| SCC | Century BC prefixed with - |
| YYYY | Year with 4 numbers |
| SYYY | Year BC prefixed with - |
| IYYY | ISO Year with 4 numbers |
| YY | Year with 2 numbers |
| RR | Year with 2 numbers with Y2k compatibility |
| YEAR | Year in characters |
| SYEAR | Year in characters, BC prefixed with - |
| BC | BC/AD Indicator * |
| Q | Quarter in numbers (1,2,3,4) |
| MM | Month of year 01, 02...12 |
| MONTH | Month in characters (i.e. January) |
| MON | JAN, FEB |
| WW | Weeknumber (i.e. 1) |
| W | Weeknumber of the month (i.e. 5) |
| IW | Weeknumber of the year in ISO standard. |
| DDD | Day of year in numbers (i.e. 365) |
| DD | Day of the month in numbers (i.e. 28) |
| D | Day of week in numbers(i.e. 7) |
| DAY | Day of the week in characters (i.e. Monday) |
| FMDAY | Day of the week in characters (i.e. Monday) |
| DY | Day of the week in short character description (i.e. SUN) |
| J | Julian Day (number of days since January 1 4713 BC, where January 1 4713 BC is 1 in Oracle) |
| HH | Hournumber of the day (1-12) |
| HH12 | Hournumber of the day (1-12) |
| HH24 | Hournumber of the day with 24Hours notation (1-24) |
| AM | AM or PM |
| PM | AM or PM |
| MI | Number of minutes (i.e. 59) |
| SS | Number of seconds (i.e. 59) |
| SSSSS | Number of seconds this day. |
| DS | Short date format. Depends on NLS-settings. Use only with timestamp. |
| DL | Long date format. Depends on NLS-settings. Use only with timestamp. |
| E | Abbreviated era name. Valid only for calendars: Japanese Imperial, ROC Official and Thai Buddha.. (Input-only) |
| EE | The full era name |
| FF | The fractional seconds. Use with timestamp. |
| FF1..FF9 | The fractional seconds. Use with timestamp. The digit controls the number of decimal digits used for fractional seconds. |
| FM | Fill Mode: suppresses blianks in output from conversion |
| FX | Format Exact: requires exact pattern matching between data and format model. |
| IYY or IY or I the last 3,2,1 digits of the ISO standard year. Output only | |
| RM | The Roman numeral representation of the month (I .. XII) |
| RR | The last 2 digits of the year. |
| RRRR | The last 2 digits of the year when used for output. Accepts fout-digit years when used for input. |
| SCC | Century. BC dates are prefixed with a minus. |
| CC | Century |
| SP | Spelled format. Can appear of the end of a number element. The result is always in english. For example month 10 in format MMSP returns "ten" |
| SPTH | Spelled and ordinal format; 1 results in first. |
| TH | Converts a number to it's ordinal format. For example 1 becoms 1st. |
| TS | Short time format. Depends on NLS-settings. Use only with timestamp. |
| TZD | Abbreviated time zone name. ie PST. |
| TZH | Time zone hour displacement. |
| TZM | Time zone minute displacement. |
| TZR | Time zone region |
| X | Local radix character. In america this is a period (.) |
Adjunto procedimiento
Adjunto procedimiento completo de PL/SQL de Oracle al que se le adicionan 3 campos: periodo que no es relevante, fecha de corte que es el ultimo dia del trimestre de la fecha, la fecha de corte anterior que es la fecha del anterior trimestre.
Espero les sirva.
CREATE OR REPLACE PROCEDURE CARGADIMTIEMPO IS
tmpVar NUMBER;
FechaDesde date;
FechaHasta date;
FechaDesdeStr VARCHAR2(8);
err_num NUMBER;
err_msg VARCHAR2(255);
BEGIN
tmpVar := 0;
FechaDesde := TO_DATE('19941231','YYYYMMDD');
FechaHasta := TO_DATE('20181231','YYYYMMDD');
WHILE FechaDesde <= FechaHasta LOOP
FechaDesdeStr := to_char( FechaDesde, 'YYYYMMDD') ;
INSERT INTO DIM_TIEMPO
(
FechaSK,
Fecha,
Año,
Trimestre,
Mes,
Semana,
Dia,
DiaSemana,
NTrimestre,
NMes,
NMes3L,
NSemana,
NDia,
NDiaSemana,
Periodo,
FechaCorte,
FechaCorteAnt
)
VALUES
(
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD') ,'YYYYMMDD'),
FechaDesde,
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'MM'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'WW'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'DD'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'D'),
'T'||to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q')||'/'||to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YY'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'MONTH'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'MON'),
'Sem '||to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'WW')||'/'||to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YY'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'DD MON'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'DAY'),
CASE
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 1 THEN 3
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 2 THEN 6
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 3 THEN 9
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 4 THEN 12
END,
CASE
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 1 THEN TO_DATE('31/03/' || to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'), 'DD/MM/YYYY')
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 2 THEN TO_DATE('30/06/' || to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'), 'DD/MM/YYYY')
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 3 THEN TO_DATE('30/09/' || to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'), 'DD/MM/YYYY')
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 4 THEN TO_DATE('31/12/' || to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'), 'DD/MM/YYYY')
END,
CASE
WHEN to_char(to_date(FechaDesdeStr,'YYYYMMDD'), 'Q') = 1 THEN TO_DATE('31/12/' || to_char(to_number(to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'))-1), 'DD/MM/YYYY')
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 2 THEN TO_DATE('31/03/' || to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'), 'DD/MM/YYYY')
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 3 THEN TO_DATE('30/06/' || to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'), 'DD/MM/YYYY')
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 4 THEN TO_DATE('30/09/' || to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'), 'DD/MM/YYYY')
END
);
-- Incremento del bucle
commit ;
FechaDesde := FechaDesde + 1;
END LOOP;
EXCEPTION
WHEN NO_DATA_FOUND THEN
NULL;
WHEN OTHERS THEN
-- Consider logging the error and then re-raise
err_num := SQLCODE;
err_msg := SQLERRM;
DBMS_OUTPUT.put_line('Error Problemas :'||TO_CHAR(err_num) || ' ' || err_msg );
DBMS_OUTPUT.put_line(err_msg);
END CARGADIMTIEMPO;
- Inicie sesión para enviar comentarios
Gracias por la aportación de
Gracias por la aportación de esta ampliación :)
- Inicie sesión para enviar comentarios
Insert entre bases de datos remotas enlazadas por dblink de Oracle
Insert entre bases de datos remotas enlazadas por dblink de Oracle cfb 19 Agosto, 2008 - 22:28Para hacer un insert con Oracle SQL desde una tabla de una base de datos TablaBD1 a otra base de datos TablaBD2 a través de un dblink debería haber dos maneras:
1- Crear el database link en la base de datos origen BD1 y hacer el insert hacia la tabla de la base de datos destino BD2 a través de este dblink
SQL en la base de datos Oracle BD1:
CREATE [PUBLIC] DATABASE LINK BD1toBD2_dblink
CONNECT TO usuario2
IDENTIFIED BY password2
USING 'BD2';
INSERT INTO TablaBD2@BD1toBD2_dblink
(SELECT * FROM TablaBD1);
* Para simplificar suponemos que las tablas tienen la misma estructura
2- Crear el database link en la base de datos destino BD2 y hacer el insert seleccionando los registros de la tabla de la base de datos origen BD1 a través de este dblink:
SQL en la base de datos Oracle BD2:
CREATE [PUBLIC] DATABASE LINK BD2toBD1_dblink
CONNECT TO usuario1
IDENTIFIED BY password1
USING 'BD1';
INSERT INTO TablaBD2
(SELECT * FROM TablaBD1@BD2toBD1_dblink);
Yo hasta ahora he utilizado siempre el SQL de la segunda opción para enlazar bases de datos Oracle, supongo que porque parece más simple utilizar un dblink para seleccionar datos de una tabla de una base de datos remota que para insertarlos remotamente. Pues parece que lo mejor es buscar las cosas simples porque he podido comprobar que la primera opción no funciona, por lo menos a mi.
He probado a hacerlo creando con SQL un dblink entre dos bases de datos Oracle 10g y la inserción no se realizaba. Lo curioso es que la sentencia SQL, en lugar de devolverme un error me devolvía un mensaje de '0 registros insertados', cuando haciendo la SELECT sí que obtenía registros.
Yo he llegado a la conclusión de que la opción de insertar datos directamente en una tabla de una base de datos Oracle remota a través de un database link no funciona, hay que hacer una SELECT desde la base de datos 'destino'. Para simplificar, la @ ha de estar en la tabla de la sentencia SQL de SELECT, no en la de INSERT.
Si alguien tiene una explicación mejor le agradecería que lo comentara, porque el tema me parece bastante curioso.
Saludos Cordiales, Tengo dos
Saludos Cordiales,
Tengo dos base de datos en Oracle 9i y necesito efectuar replicacion de datos entre ellos, ahora mismo uso DBLINK para mantener actualizada la información, pensamos cambiar a vistas materializadas, pero recientemente eschamos el STREAMS de Oracle, lo ha utilizado? podria sugerirme algunos link o información al respecto? el problema básico es que tengo una TABLA A en una DB 1 que constantemente se incrementa en el número de registros (Ocurren INSERT constantemente) y debemos actualizar la TABLA B en una BD 2. Cuando insertamos en la TABLA B cada vez que se inserte en la TABLA A se quedan conexiones abiertas que nunca se cierran y degrada el performance de la BD 1 y de la BD 2.
Puedes Ayudarnos?
Gracias de antemano
- Inicie sesión para enviar comentarios
Las vistas materializadas
Las vistas materializadas pueden ser un buena opción para gestionar esta replicación, pero si las inserciones son muy frecuentes donde vas a notar mejora, con cualquier método que utilices para refrescar, es si en lugar de actualizar cada vez que insertas en la tabla origen, lo haces de manera agrupada, seleccionando los registros que han cambiado cada cierto tiempo para hacer un sólo insert cada x tiempo en lugar de un insert/update por registro creado o modificado.
Sobre STREAMS de Oracle yo no los he utilizado nunca, así que si los pruebas y nos explicas qué tal funcionan te lo agradezco.
Sobre vistas materializadas, te enlazo un artículo que explica cómo utilizar las vistas materializadas, e incluye enlaces a la documentación oficial de Oracle, espero que te ayude.
Y si te quedan dudas, en el foro tenemos abierto un tema sobre vistas materializadas de Oracle.
Saludos,
- Inicie sesión para enviar comentarios
Hola, Muy buen aporte! Sólo
Hola, Muy buen aporte!
Sólo me queda una consulta... Haciendo el dblink éste permite que las modificaciones sean bidireccionales?
Muchas gracias!
Saludos.-
- Inicie sesión para enviar comentarios
Hola Manuel. El DBLink es
Hola Manuel.
El DBLink es para utilizarlo desde la instancia de base de datos en la que se define, y desde esta poder enlazar con otras, pero de manera unidireccional, tanto para modificaciones como para consultas.
Es decir, que desde las bases de datos que se enlazan con el database link no se puede utilizar ni se ve este mismo dblink para conectar con la primera. Para hacerlo habria que definir un nuevo dblink en la otra base de datos.
Saludos!
- Inicie sesión para enviar comentarios
Perfecto! Muchisimas gracias!
Perfecto! Muchisimas gracias!
- Inicie sesión para enviar comentarios
Amigo necesito realizar un
Amigo necesito realizar un insert desde una bd SQL Server a Oracle, como hago para ejecutar o hacer un llamado a un Stored Procedure que realice un insert en la BD Oracle desde una Bd SQL Server
- Inicie sesión para enviar comentarios
Oracle 10g: Posible optimización de volcado masivo de datos
Oracle 10g: Posible optimización de volcado masivo de datos il_masacratore 12 Febrero, 2010 - 18:06
En Oracle SQL, se pueden optimizar ejecuciones batch que hagan un volcado masivo de datos en una misma tabla usando sentencias de insert o update por registro dentro de un bloque. Se pueden optimizar con el uso de parámetros (si el cliente lo permite) o si usamos odbc con bind variables.
Recordemos los pasos que sigue Oracle para procesar una consulta:
- Validación Sintáctica
- Validación Semántica
- Optimización
- Generación del QEP (Query Execution Plan)
- Ejecución del QEP (Query Execution Plan)
Las sentencias SQL pueden recoger los parámetros por valor (where salario>1000) o una vez compilada la sentencia haciendo uso de Bind Variables (where salario>:b1). La ventaja de la segunda opción es que Oracle compila un única vez la sentencia y reutiliza el código compilado para cada uno de los valores para los parámetros. Pero hay que ir con ojo ya que en este segundo caso, Oracle no puede calcular el grado de selectividad de una consulta y, en su lugar, aplica un grado de selectividad por defecto (asociado a cada tipo de operación), lo cual puede dar lugar a decisiones "equivocadas".
Por lo tanto, trabajando por costes es desaconsejable el uso de Bind Variables, salvo que trabajemos con sentencias Oracle SQL que se van a ejecutar repetidas veces y que no ofrezcan muchas dudas en cuanto a los posibles planes de acceso que puede generar.
En casos probados como el siguiente el tiempo de ejecución se reduce hasta en un 90% en una inserción de 100.000 registros...
SQL para Creación de la tabla necesaria para la prueba:
create table PRUEBA ( NUM number(22), TEXTO varchar(100) );
SQL de Carga con parámetros por valor:
declare v_i number; begin loop INSERT INTO PRUEBA VALUES (3, '50'); v_i := v_i + 1; exit when v_i > 1000000; end loop; rollback; end;
SQL de Carga con parámetros usando bind variables
declare v_i number; begin loop execute immediate 'INSERT INTO PRUEBA VALUES (:x, :y)' using 3, '50'; v_i := v_i + 1; exit when v_i > 1000000; end loop; rollback; end;
Adjunto los resultados de la prueba realizada antes de aplicar cambios en producción (un viernes por la tarde )
| FILAS | POR VALOR | CON BIND VARIABLES |
| 10000 | 5,3350 | 0,4370 |
| 100000 | 58,5160 | 6,1000 |
| 1000000 | (A)570,1060 | (B)54,1950 |
Oracle Flashback Query
Oracle Flashback Query Juan_Vidal 13 Septiembre, 2011 - 09:53
Revisamos brevemente en este post la funcionalidad flashback query que aporta el gestor de BBDD de Oracle desde su versión 9i.
Básicamente se trata de un tipo de sql de Oracle que accede a datos que existían en la base de datos en un momento anterior, pero que en el momento en el que se ejecuta la sql pueden no existir o haber sufrido modificaciones. Para ello, Oracle utiliza los datos que quedan disponibles durante un tiempo en el segmento de UNDO. Este segmento, como es sabido, almacena los datos anteriores a una serie de modificaciones. Se utiliza para asegurar la consistencia en la lectura de una consulta previa a la confirmación de las modificaciones (commit) y pueden ser utilizados en una posible recuperación (rollback).
La sentencia de Oracle SQL flashback query nos permite ver datos de la tabla que han sido borrados o modificados. Ejecutando una flashback query accedemos a datos de una foto de datos consistentes en un punto determinado, especificando para ello la hora del sistema o bien el número de cambio del sistema (SCN). La base de datos debe estar configurada para trabajar en Automatic Undo Management (AUM). Para ello revisar los siguientes parámetros de la base de datos Oracle:
undo_management = auto undo_tablespace = UNDOTBS001 (tablespace que alberga el segmento de undo) undo_retention = 3600 (tiempo en segundos que tenemos retenido el dato en el segmento de undo)
Hay que tener en cuenta respecto al parámetro undo_retention que si el tablespace de UNDO no es lo suficientemente grande como para mantener ese tiempo todas las transacciones, el gestor de base de datos las va a sobreescribir. Igualmente, considerar que para poder ejecutar el comando flashback query de Oracle SQL debemos tener permisos sobre el package BDMS_FLASHBACK. Para ello:
sys> grant execute on dbms_flashback to usuario1;
Veamos un ejemplo. Supongamos que queremos realizar una consulta SQL sobre una tabla que contiene facturas de clientes y queremos acceder a los datos de un cliente que previamente hemos borrado:
sys> select to char(sysdate, ‘dd-mm-yyyy hh24:mi’) fecha_sistema from dual; fecha_sistema ------------------------- 12-09-2011 12:05 sys> delete from t_facturas where cod_cliente = ‘00125’; 4 registros borrados sys> commit;
Media hora después ejecutamos:
sys> select to char (sysdate, ‘dd-mm-yyyy hh24:mi’) fecha_sistema from dual
fecha_sistema
-------------------------
12-09-2011 12:35
sys> exec dbms_flashback.enable_at_time (to_date('12-09-2011 12:05, 'DD-MM-YYYY HH24:MI'));
sys> select to char (sysdate, ‘dd-mm-yyyy hh24:mi’) fecha_sistema from dual
fecha_sistema
-------------------------
12-09-2011 12:35
sys> exec dbms_flashback.enable_at_time (to_date(’12-09-2011 12:05, ‘DD-MM-YYYY HH24:MI’));
Procedimiento PL/SQL terminado correctamente.
sys> select * from t_facturas where cod_cliente = ‘00125’;
……
……
……
……
4 registros seleccionados.
sys> execute dbms_flasback.disable;
sys> select count(*) from t_facturas where cod_cliente = ‘00125’;
count(*)
------
0
Se puede obtener lo mismo accediendo por el número de cambio SCN:
sys> select dbms_flashback.get_system_change_number from dual; GET_SYSTEM_CHANGE_NUMBER ------------------------ 1307125 sys> exec dbms_flashback.enable_at_system_change_number(1307125); Procedimiento PL/SQL terminado correctamente
Existe también la posibilidad de emplear la sentencia ‘select ... as of...’:
sys> select * from t_facturas where cod_cliente = ‘00125’ as of timestamp to_timestamp (’12-09-2011 12:05', ‘DD-MM-YYYY HH24:MI’); sys> select * from t_facturas where cod_cliente = ‘00125’ as of scn 1307125;
Hay que tener en cuenta que mientras la sesión está en el modo Flashback Query, solo podemos ejecutar sentencias SELECT. Las sentencias SQL de actualización (insert, delete y update) no están permitidas.
En el trabajo diario con esta opción es útil el uso de tablas temporales para trabajar con los datos recuperados:
sys> create table t_facturas_ant as (select * from t_facturas where cod_cliente = ‘00125’ as of timestamp to_timestamp (’12-09-2011 12:05, ‘DD-MM-YYYY HH24:MI’);
Otras opciones Flashback Query
A continuación listamos algunas funcionalidades que aporta Oracle relacionadas con operaciones Flashback Query:
- Flashback Version Query: Acceso al histórico de cambios de una tabla.
- Flashback Transaction Query: Acceso al histórico de cambios de una transacción determinada.
- Flashback Table: Acceso a datos anteriores, pero para una única tabla.
- Flashback Drop: Recuperar una tabla borrada (‘papelera reciclaje’).
- Flashback Database: Permite dejar la BBDD tal y como se encontraba en un tiempo pasado. Similar a restaurar un backup, pero con las limitaciones temporales de los procesos flashback, aunque mucho más rápido que recuperar la copia del backup. Es necesario tener el modo flashback activado, así como la flash recovery area.
Algunas de estas opciones requieren que el gestor sea 'Enterprise Edition'.
Se trata, como se ha dicho, de una sentencia de Oracle SQL bastante útil, con múltiples opciones de “rebobinado” y que nos puede sacar de más de un apuro.
Recopilación scripts y consultas útiles de Oracle
Recopilación scripts y consultas útiles de Oracle Carlos 14 Marzo, 2007 - 00:33¿Quién no tiene su chuleta de consultillas útiles que se suelen utilizar en el día a día, y en nuestras aventuras y desventuras con la base de datos?

Listado de consultas SQL de Oracle, la mayoría sobre las vistas del diccionario de Oracle, para obtener información sobre objetos de la base de datos propios o a los que tiene permisos de acceso si se trata de un usuario normal, y sobre objetos de cualquier usuario si el usuario es DBA.
La idea es crear un pequeño un repositorio para poder consultar desde cualquier lugar para facilitarnos la vida, o sacarnos de algún que otro apuro.
Consultas para usuarios de Oracle
Consultas que se pueden hacer a nivel de usuario sin privilegios de administrador, suelen ir también sobre el diccionario de datos de Oracle, pero retornan datos de los objetos a los que el usuario tiene acceso
-- Consulta Oracle SQL sobre el Diccionario de datos -- Con esta vista se consultan los nombres de las tablas o vistas del diccionario a las que el usuario tiene acceso, útil para saber dónde buscar información sobre objetos a los que el usuario tiene acceso select * from dictionary where table_name like '%TABLES%'
-- Consulta Oracle SQL que muestra los metadatos de la/s tabla/s especificada/s por nombre -- (en este caso todas las tablas que lleven la cadena "XXX") select * from ALL_ALL_TABLES where upper(table_name) like '%XXX%'
-- Consulta Oracle SQL que muestra las descripciones de los campos de una tabla especificada (en este caso todas las tablas que lleven la cadena "XXX") select * from ALL_COL_COMMENTS where upper(table_name) like '%XXX%'
-- Consulta Oracle SQL para conocer las tablas propiedad del usuario actual select * from user_tables
-- Consulta Oracle SQL para conocer todos los objetos propiedad del usuario conectado a Oracle select * from user_catalog
-- Consulta Oracle SQL para conocer los productos Oracle instalados y la versión select * from product_component_version
-- Consulta Oracle SQL para conocer los roles y privilegios por roles select * from role_sys_privs
-- Consulta Oracle SQL para conocer las reglas de integridad y columna a la que afectan select constraint_name, column_name from sys.all_cons_columns
-- Consulta Oracle SQL para conocer las tablas de las que es propietario un usuario, en este caso "xxx" SELECT table_owner, table_name from sys.all_synonyms where table_owner like '%xxx%' -- Consulta Oracle SQL como la anterior, pero de otra forma más efectiva (tablas de las que es propietario un usuario) SELECT DISTINCT TABLE_NAME FROM ALL_ALL_TABLES WHERE OWNER LIKE '%HR%' -- Consulta Oracle SQL para conocer el tamaño ocupado por una tabla concreta sin incluir los índices de la misma select sum(bytes)/1024/1024 MB from user_segments where segment_type='TABLE' and segment_name='NOMBRETABLA'
-- Consulta Oracle SQL para conocer el tamaño ocupado por una tabla concreta incluyendo los índices de la misma
select sum(bytes)/1024/1024 Table_Allocation_MB from user_segments
where segment_type in ('TABLE','INDEX') and
(segment_name='NOMBRETABLA' or segment_name in
(select index_name from user_indexes where table_name='NOMBRETABLA'))
-- Consulta Oracle SQL para conocer el tamaño ocupado por una columna de una tabla
select sum(vsize('NOMBRECOLUMNA'))/1024/1024 MB from NOMBRETABLA-- Consulta Oracle SQL para obtener todas las funciones de Oracle: NVL, ABS, LTRIM, ...
SELECT distinct object_name
FROM all_arguments
WHERE package_name = 'STANDARD'
order by object_name
Consultas para DBAs de Oracle
Consultas sobre vistas de sistema, normalmente requieren permisos de DBA o administrador
-- Consulta Oracle SQL sobre la vista que muestra el estado de la base de datos select * from v$instance
-- Consulta Oracle SQL que muestra si la base de datos está abierta select status from v$instance
-- Consulta Oracle SQL sobre la vista que muestra los parámetros generales de Oracle
-- Parámetros de Oracle, valor actual y su descripción SELECT v.name, v.value value, decode(ISSYS_MODIFIABLE, 'DEFERRED', 'TRUE', 'FALSE') ISSYS_MODIFIABLE, decode(v.isDefault, 'TRUE', 'YES', 'FALSE', 'NO') "DEFAULT", DECODE(ISSES_MODIFIABLE, 'IMMEDIATE', 'YES','FALSE', 'NO', 'DEFERRED', 'NO', 'YES') SES_MODIFIABLE, DECODE(ISSYS_MODIFIABLE, 'IMMEDIATE', 'YES', 'FALSE', 'NO', 'DEFERRED', 'YES','YES') SYS_MODIFIABLE , v.description FROM V$PARAMETER v WHERE name not like 'nls%' ORDER BY 1 select * from v$system_parameter
-- Consulta Oracle SQL para conocer la Versión de Oracle select value from v$system_parameter where name = 'compatible'
-- Consulta Oracle SQL para conocer la Ubicación y nombre del fichero spfile select value from v$system_parameter where name = 'spfile'
-- Consulta Oracle SQL para conocer la Ubicación y número de ficheros de control select value from v$system_parameter where name = 'control_files'
-- Consulta Oracle SQL para conocer el Nombre de la base de datos select value from v$system_parameter where name = 'db_name'
-- Consulta Oracle SQL sobre la vista que muestra las conexiones actuales a Oracle -- Para visualizarla es necesario entrar con privilegios de administrador select osuser, username, machine, program from v$session order by osuser
-- Consulta Oracle SQL que muestra el número de conexiones actuales a Oracle -- agrupado por aplicación que realiza la conexión select program Aplicacion, count(program) Numero_Sesiones from v$session group by program order by Numero_Sesiones desc
-- Consulta Oracle SQL que muestra los usuarios de Oracle conectados -- y el número de sesiones por usuario select username Usuario_Oracle, count(username) Numero_Sesiones from v$session group by username order by Numero_Sesiones desc -- Consulta Oracle SQL que muestra propietarios de objetos y número de objetos por propietario select owner, count(owner) Numero from dba_objects group by owner
-- Consulta Oracle SQL para el DBA de Oracle que muestra los tablespaces, -- el espacio utilizado, el espacio libre y los ficheros de datos de los mismos Select t.tablespace_name "Tablespace", t.status "Estado", ROUND(MAX(d.bytes)/1024/1024,2) "MB Tamaño", ROUND((MAX(d.bytes)/1024/1024) - (SUM(decode(f.bytes, NULL,0, f.bytes))/1024/1024),2) "MB Usados", ROUND(SUM(decode(f.bytes, NULL,0, f.bytes))/1024/1024,2) "MB Libres", t.pct_increase "% incremento", SUBSTR(d.file_name,1,80) "Fichero de datos" FROM DBA_FREE_SPACE f, DBA_DATA_FILES d, DBA_TABLESPACES t WHERE t.tablespace_name = d.tablespace_name AND f.tablespace_name(+) = d.tablespace_name AND f.file_id(+) = d.file_id GROUP BY t.tablespace_name, d.file_name, t.pct_increase, t.status ORDER BY 1,3 DESC
-- Consulta Oracle SQL que muestra los usuarios de Oracle y datos suyos (fecha de creación, estado, id, nombre, tablespace temporal,...) Select * FROM dba_users
-- Consulta Oracle SQL para conocer tablespaces y propietarios de los mismos select owner, decode(partition_name, null, segment_name, segment_name || ':' || partition_name) name, segment_type, tablespace_name,bytes,initial_extent, next_extent, PCT_INCREASE, extents, max_extents from dba_segments Where 1=1 And extents > 1 order by 9 desc, 3
-- Últimas consultas SQL ejecutadas en Oracle y usuario que las ejecutó select distinct vs.sql_text, vs.sharable_mem, vs.persistent_mem, vs.runtime_mem, vs.sorts, vs.executions, vs.parse_calls, vs.module, vs.buffer_gets, vs.disk_reads, vs.version_count, vs.users_opening, vs.loads, to_char(to_date(vs.first_load_time, 'YYYY-MM-DD/HH24:MI:SS'),'MM/DD HH24:MI:SS') first_load_time, rawtohex(vs.address) address, vs.hash_value hash_value , rows_processed , vs.command_type, vs.parsing_user_id , OPTIMIZER_MODE , au.USERNAME parseuser from v$sqlarea vs , all_users au where (parsing_user_id != 0) AND (au.user_id(+)=vs.parsing_user_id) and (executions >= 1) order by buffer_gets/executions desc
-- Consulta Oracle SQL para conocer todos los tablespaces select * from V$TABLESPACE
-- Consulta Oracle SQL para conocer la memoria Share_Pool libre y usada select name,to_number(value) bytes from v$parameter where name ='shared_pool_size' union all select name,bytes from v$sgastat where pool = 'shared pool' and name = 'free memory'
-- Cursores abiertos por usuario
select b.sid, a.username, b.value Cursores_Abiertos
from v$session a,
v$sesstat b,
v$statname c
where c.name in ('opened cursors current')
and b.statistic# = c.statistic#
and a.sid = b.sid
and a.username is not null
and b.value >0
order by 3
-- Consulta Oracle SQL para conocer los aciertos de la caché (no debería superar el 1 por ciento)
select sum(pins) Ejecuciones, sum(reloads) Fallos_cache,
trunc(sum(reloads)/sum(pins)*100,2) Porcentaje_aciertos
from v$librarycache
where namespace in ('TABLE/PROCEDURE','SQL AREA','BODY','TRIGGER');-- Sentencias SQL completas ejecutadas con un texto determinado en el SQL SELECT c.sid, d.piece, c.serial#, c.username, d.sql_text FROM v$session c, v$sqltext d WHERE c.sql_hash_value = d.hash_value and upper(d.sql_text) like '%WHERE CAMPO LIKE%' ORDER BY c.sid, d.piece
-- Una sentencia SQL concreta (filtrado por sid) SELECT c.sid, d.piece, c.serial#, c.username, d.sql_text FROM v$session c, v$sqltext d WHERE c.sql_hash_value = d.hash_value and sid = 105 ORDER BY c.sid, d.piece
-- Consulta Oracle SQL para conocer el tamaño ocupado por la base de datos select sum(BYTES)/1024/1024 MB from DBA_EXTENTS
-- Consulta Oracle SQL para conocer el tamaño de los ficheros de datos de la base de datos select sum(bytes)/1024/1024 MB from dba_data_files
-- Consulta Oracle SQL para conocer el espacio ocupado por usuario SELECT owner, SUM(BYTES)/1024/1024 MB FROM DBA_EXTENTS group by owner
-- Consulta Oracle SQL para conocer el espacio ocupado por todos los objetos de la base de datos, muestra los objetos que más ocupan primero SELECT SEGMENT_NAME, SUM(BYTES)/1024/1024 MB FROM DBA_EXTENTS group by SEGMENT_NAME order by 2 desc
-- Consulta Oracle SQL para conocer el espacio ocupado por los diferentes segmentos (tablas, índices, undo, rollback, cluster, ...) SELECT SEGMENT_TYPE, SUM(BYTES)/1024/1024 MB FROM DBA_EXTENTS group by SEGMENT_TYPE
Libros de Administración Oracle (DBA) y PL/SQL
¿Quieres profundizar más en PL/SQL de Oracle o en administración de bases de datos Oracle? Puedes hacerlo consultando alguno de estos libros de Oracle.
tablespaces en oracle
Saludos a todos.. Tengo una pregunta, en esta página se indica como ver
los datos de un tablespace desde Oracle Enterprise Manager,
pero ¿Se lo puede hacer via comandos desde SQL * Plus?..
- Inicie sesión para enviar comentarios
En este mismo tema tienes la
En este mismo tema tienes la respuesta. Entre las consultas SQL de la entrada inicial hay varios que consultan datos de tablespaces, que se encuentran en vista dba_tablespaces.
Otro ejemplo podría ser una query como esta:
select TABLESPACE_NAME, INITIAL_EXTENT, NEXT_EXTENT, MIN_EXTENTS, MAX_EXTENTS, PCT_INCREASE, STATUS, CONTENTS, LOGGING, FORCE_LOGGING
from dba_tablespaces
where TABLESPACE_NAME like 'mitablespace%';
- Inicie sesión para enviar comentarios
Para comparar dentro de un
Para comparar dentro de un DECODE con parte de un texto del contenido de un campo, es decir, para poder utilizar un like u otras funciones en lugar de la igualdad que toma por defecto el DECODE se puede hacer lo siguiente:
SELECT DECODE(CAMPO,
(select CAMPO from dual where CAMPO like 'A%'),
'Campo comienza por A',
(select name from dual where name like 'B%'),
'Campo comienza por B',
'Campo no comienza ni por A ni por B')
FROM TABLA;- Inicie sesión para enviar comentarios
Cuando un tablespace se queda
Cuando un tablespace se queda sin espacio se puede ampliar creando un nuevo fichero de datos, o ampliando uno de los existentes.
Para consultar el espacio ocupado por cada datafile se puede utilizar la consulta de la lista anterior:
•• Consulta Oracle SQL para el DBA de Oracle que muestra los tablespaces, el espacio utilizado, el espacio libre y los ficheros de datos de los mismos:
SELECT t.tablespace_name "Tablespace", t.status "Estado",
ROUND(MAX(d.bytes)/1024/1024,2) "MB Tamaño",
ROUND((MAX(d.bytes)/1024/1024) -
(SUM(decode(f.bytes, NULL,0, f.bytes))/1024/1024),2) "MB Usados",
ROUND(SUM(decode(f.bytes, NULL,0, f.bytes))/1024/1024,2) "MB Libres",
t.pct_increase "% incremento",
SUBSTR(d.file_name,1,80) "Fichero de datos"
FROM DBA_FREE_SPACE f, DBA_DATA_FILES d, DBA_TABLESPACES t
WHERE t.tablespace_name = d.tablespace_name AND
f.tablespace_name(+) = d.tablespace_name
AND f.file_id(+) = d.file_id GROUP BY t.tablespace_name,
d.file_name, t.pct_increase, t.status ORDER BY 1,3 DESCUna vez que localizamos el datafile que podríamos ampliar ejecutaremos la siguiente sentencia para hacerlo:
ALTER DATABASE
DATAFILE '/db/oradata/datafiles/datafile_n.dbf' AUTOEXTEND
ON NEXT 1M MAXSIZE 4000MCon esta sentencia, el datafile continuaría ampliándose hasta llegar a un máximo de 4Gb.
Si preferimos crear un nuevo datafile porque los que tenemos ya son demasido grandes, una sentencia que podríamos utilizar es la siguiente:
ALTER TABLESPACE "MiTablespace"
ADD
DATAFILE '/db/oradata/datafiles/datafile_m.dbf' SIZE
100M AUTOEXTEND
ON NEXT 1M MAXSIZE 1000MCrearíamos un nuevo fichero de datos de 100 Mb, y en modo autoextensible hasta 1000 Mb. Por supuesto, el path especificado debe ser el específico de cada base de datos, y se debe utilizar para todo el proceso un usuario con privilegios de DBA.
- Inicie sesión para enviar comentarios
Para matar una sesión de
Para matar una sesión de Oracle hay que utilizar, con un usuario con permisos de DBA, el comando
ALTER SYSTEM KILL SESSION 'SID,SERIAL#';Para obtener el SID y el SERIAL# que necesitamos se puede utilizar la consulta:
SELECT p.*, s.*
FROM v$session s, v$process p
WHERE p.addr(+)=s.paddr
ORDER BY SIDEsta consulta devolvería los datos de todas las sesiones abiertas, se pueden restringir los resultados a las sesiones que interesen añadiendo condiciones en el where.
Si el número de sesiones que hay que eliminar es elevado, se puede utilizar esta misma consulta para crear las sentencias necesarias dinámicamente:
SELECT 'alter system kill session '''||s.sid||','||p.serial#||''';'
FROM v$session s, v$process p
WHERE p.addr(+)=s.paddr
AND s.username='USER'; (por ejemplo)Sobretodo cuidado con la condición que se incluye en el where, ya que si no se especificara nada, por ejemplo, se matarían todas las sesiones de la base de datos.
Para crear un script con estas sentencias consultar Construcción de scripts con ayuda del diccionario
- Inicie sesión para enviar comentarios
Gente, capas que hay gente
Gente, capas que hay gente que ya sabia de estas funciones pero bueno simplemente para dejarlo plasmado en alguna pagina y le pueda llegar a ser de gran utilidad a todo el mundo. Lo que voy a postear me llevo un tiempo encontrarlo y la idea con esto es lograr que sea mas facil encontrarlo y ademas que funcione porque hay mucha basura dando vueltas en la internet.
una funcion muy util que recien encontre hoy dia es: SYS_CONTEXT.
NOTA: USERENV es un nombre que describe la sesion actual y con ella y la funcion sys_context se puede conseguir:
•• identificador del cliente
SELECT sys_context('USERENV', 'CLIENT_IDENTIFIER') FROM dual;
•• nombre del esquema donde uno esta conectado
SELECT sys_context('userenv', 'CURRENT_SCHEMA') FROM dual;
•• ID del esquema donde uno se encuentra conectado
SELECT sys_context('USERENV', 'CURRENT_SCHEMAID') FROM dual;
•• nombre de la base de datos.
SELECT sys_context('USERENV', 'DB_NAME') FROM dual;
•• nombre del host
SELECT sys_context('USERENV', 'HOST') FROM dual;
•• nombre de la instancia
SELECT sys_context('USERENV', 'INSTANCE_NAME') FROM dual;
••los formatos de moneda, fechas.
SELECT sys_context('USERENV', 'NLS_CURRENCY') FROM dual; SELECT sys_context('USERENV', 'NLS_DATE_FORMAT') FROM dual;
•• nombre del territorio. ejemplo : 'AMERICA';
SELECT sys_context('USERENV', 'NLS_TERRITORY') FROM dual;
•• server host nome
SELECT sys_context('USERENV', 'SERVER_HOST') FROM dual;
•• ID de la session del usuario
SELECT sys_context('USERENV', 'SESSION_USERID') FROM dual;
•• SID (session number) util para matar sesiones luego con el numero.
SELECT sys_context('USERENV', 'SID') FROM dual;
•• LISTA DE PAQUETES UTL (utilidades de oracle, envio de mails mediante SMTP entre otros)
SELECT * FROM ALL_OBJECTS
WHERE OBJECT_NAME LIKE '%UTL_%'
AND OBJECT_TYPE = 'PACKAGE'
•• LISTA DE PAQUETES DBMS (otras utilidades del Data Base Manager System)
SELECT * FROM ALL_OBJECTS
WHERE OBJECT_NAME LIKE '%DBMS_%'
AND OBJECT_TYPE = 'PACKAGE'estas dos listas digamos son utiles como para ver las que hay y luego investigar un poco mas como se utilizan en internet.
•• Envio de e-mail a multiples usuarios mediante la utilidad UTL_SMTP.
Otra cosa que me costo mucho encontrar y en definitiva me lo termino contando un amigo del trabajo es como utilizar el paquete UTL_SMPT para mandar un mail a multiples recipientes. (a varias personas)
Mi idea es unicamente explicar este problema, como usarlo se los dejo para que lo investiguen que no es muy dificil.
si se tiene los mails en un VARCHAR de la siguiente manera
alguien@xxx.com;alguien1@xxx.com;alguien2@xxx.com;alguien3@xxx.com;alguien4@xxx.com
una vez hecho los pasos :
g_mail_conn := utl_smtp.open_connection (p_mailhost,p_mailport); -- <-- apertura de conexion. utl_smtp.helo(g_mail_conn,p_mailhost); utl_smtp.mail(g_mail_conn,p_sender);
hay que definir el recipiente con la funcion utl_smtp.rcpt(); tener en cuenta que este recipiente se va a instanciar en nuestro caso 5 veces (una vez por cada e-mail y no todos en uno solo OJO!)
osea : utl_smtp.rcpt( p_mail_conn , alguien@xxx.com );
utl_smtp.rcpt( p_mail_conn , alguien@xxx.com1 );
utl_smtp.rcpt( p_mail_conn , alguien@xxx.com 2);
utl_smtp.rcpt( p_mail_conn , alguien@xxx.com 3);
utl_smtp.rcpt( p_mail_conn , alguien@xxx.com4 );para cortar los mails concatenados en un VARCHAR y cumplir el proposito anterior pueden usar este procesos que me toco hacer que hace lo anteriormente descrito.
PROCEDURE Pi_Prepare_Recip_Mail ( p_mail_conn IN OUT utl_smtp.connection,
p_rec_mails IN VARCHAR2)
IS
MAILS VARCHAR2(1000) := p_rec_mails;
SingleMail VARCHAR2(255);
--
NO_MORE_MAILS BOOLEAN := FALSE;
EOM NUMBER; -- end of mail.
BOM NUMBER := 1; -- begin of mail.
COC NUMBER ; -- number of characters.
MAIL_NUMBER NUMBER := 1;
BEGIN
LOOP
EOM := INSTR(MAILS,';',1,MAIL_NUMBER);
IF EOM = 0 THEN
EOM := LENGTH(MAILS) + 1;
NO_MORE_MAILS := TRUE;
END IF;
COC := (EOM) - BOM;
SingleMail := SUBSTR(MAILS,BOM,COC);
utl_smtp.rcpt( p_mail_conn , SingleMail ); -- <-- recipiente de salida.
EXIT WHEN NO_MORE_MAILS;
MAIL_NUMBER := MAIL_NUMBER + 1 ;
BOM := EOM + 1;
END LOOP;
END Pi_Prepare_Recip_Mail;se instancia este procesos pasandole la conexion de mail y la lista de mails osea:
p_rec_mail VARCHAR2(300) := alguien@xxx.com;alguien1@xxx.com;alguien2@xxx.com;alguien3@xxx.com;alguien4@xxx.com;
instancia --> Pi_Prepare_Recip_Mail( g_mail_conn , p_rec_mail );
En si es dificil de entender y mas de explicar, trate de ser lo mas claro posible. Cualquier duda sobre este tema escriban.
•• cambiar el lenguaje de la fecha.
select to_char(sysdate,'day', 'NLS_DATE_LANGUAGE=Spanish') from dual
select to_char(sysdate,'month', 'NLS_DATE_LANGUAGE=Spanish') from dual
•• correr las estadisticas para una determinada tabla (esto aumenta la velocidad de respuesta de las tablas en
aquellos casos donde el volumen de registros es considerablemente grande)
ANALIZE TABLE <nombre de la tabla> COMPUTE STATISTICS;
-- realizarlo en un porcentaje (en un 25 %)
ANALIZE TABLE <nombre de la tabla> COMPUTE STATISTICS SAMPLE 25 percent;
-- realizarlo solo para una determinada cantidad de registros)
ANALIZE TABLE <nombre de la tabla> COMPUTE STATISTICS SAMPLE 1000 rows;
•• ponerle comentarios a las tablas y a sus columnas para que el significado de cada campo tenga mayor
comprencion.
COMMENT ON TABLE <table_name> IS 'comentario a escribir';
COMMENT ON COLUMN <table_name>.<column_name> IS 'comentario a escribir aca';Con esto hay para divertirse un buen rato..... nunca termina de sorprenderme Oracle...
- Inicie sesión para enviar comentarios
Si hiciste las consultas hace
Si hiciste las consultas hace tiempo y no tenías activada la auditoría de Oracle sobre el usuario que las ejecutó no creo que las puedas recuperar.
Para poder saber las sentencias SQL que ha ejecutado un usuario tienes que decir previamente a la base de datos que haga un seguimiento de las mismas, se ha de auditar al usuario.
Es una medida de seguridad, y si se abusa de ella puede llegar a afectar negativamente al rendimiento de la base de datos, por lo que deberías aplicarla sólo si es necesario. Por supuesto, necesitarás un usuario con privilegios de DBA para poder hacerlo.
En el documento Guide to auditing in Oracle applications, elaborado por www.integrigy.com, se explica bastante bien cómo activar la auditoría en bases de datos Oracle y las diferentes opciones que hay.
También puedes consultar la información del tema que hemos abierto sobre auditoría, seguimiento y seguridad en Oracle.
A partir de la versión 10g, con la consola web de administración (Enterprise Manager Console) también tienes la opción de consultar sentencias SQL ejecutadas durante las últimas 24 horas. Seguramente no te solucionará tu actual problema, pero para analizar ejecuciones y problemas más recientes siempre va bien.
- Inicie sesión para enviar comentarios
How to send e-mail from Oracle
Hola,
solo queria compartir esta pagina que me parece muy interesante sobre como enviar mail desde Oracle
http://www.dba-oracle.com/t_email_mailing_messages_plsql.htm
:-D
- Inicie sesión para enviar comentarios
Gracias por la aportación,
Gracias por la aportación, pero más arriba betorey_24 ya nos explica cómo enviar mails con Oracle, y en castellano ;)
De todas maneras la página de BC que enlazas es una buena referencia, muchas veces he acabado en ella buscando cómo solucionar algún tema de Oracle.
- Inicie sesión para enviar comentarios
Cómo seleccionar un determinado número de registros en Oracle
Para hacer que nuestra consulta nos devuelva sólo los n primeros registros, y no saturar ni servidores ni aplicaciones cliente cuando trabajamos con tablas grandes, en Oracle tan sólo hay que añadir la condición where rownum < n a la sentencia SQL.
Por ejemplo:
SELECT * FROM tabla_ventas
WHERE rownum < 100;
Aunque nuestra tabla de ventas tenga 10.000.000 de registros, esta consulta sólo nos devolverá los primeros 99 que encuentre.
- Inicie sesión para enviar comentarios
Hola Carlos, he encontrado
Hola Carlos, he encontrado cosas muy interesnates aqui y tambien veo que mucha ayuda, espero me puedas ayudar con un problemita que tengo. Ya tengo listo el proceso que me manda el correo desde oracle a varias persona y con un texto fijo que mando como parametro, pero me falta saber como mandar el resultado de una consulta por el mismo correo ¿Me puedes ayudar?
Gracias.
- Inicie sesión para enviar comentarios
Estimado, una pregunta,
Estimado, una pregunta, existira alguna vista o consulta en Oracle que ayude a Saber dentro de las sesiones activas o inactivas cuales son o fueron los ultimos procesos que se ejecutaron (updates, select, delete, etc)? Gracias por tu pronta respuesta! Saludos!
- Inicie sesión para enviar comentarios
Las sesiones actuales las
Las sesiones actuales las puedes consultar con la vista v$session y las sentencias SQL que se ejecutan con v$sqltext.
Para enlazar estas dos vistas has de utilizar el campo sql_hash_value de la primera y hash_value de la segunda, y luego aplica las condiciones que te interesen.
En los scripts anteriores hay algún ejemplo de consulta de sentencias. Para sacar las sentencias que se están ejecutando podrías hacer algo así:
SELECT c.sid, c.status, d.piece, c.serial#, c.username, d.sql_text
FROM v$session c, v$sqltext d
WHERE c.sql_hash_value = d.hash_value
ORDER BY c.sid, d.pieceLa ordenación por los campos sid y piece es importante porque las sentencias están 'troceadas' en diferentes registros.
- Inicie sesión para enviar comentarios
Hola amigos, alguien sabe que
Hola amigos, alguien sabe que software se puede usar para ver graficamente el contenido de un paquete es decir :
el paqueteI tiene dos procesos: "proceso1","proceso2"; el proceso1 contiene: 3 Cursores y presenta 3 funciones o algo asi, cuando de un click a cada objeto que compone el paquete desplegar el cuerpo del codigo.
help me pls.
saludos
- Inicie sesión para enviar comentarios
Hola, el PL/SQL Developer, te
Hola, el PL/SQL Developer, te puede servir, no es gratuito, pero te lo puedes bajar de taringa.com
Saludos.
- Inicie sesión para enviar comentarios
Complementando un poco la
Complementando un poco la información espero les sirva esto.
MUESTRA LOS ROLES ASIGNADOS AL USUARIO ACTUAL
SELECT granted_role "Rol", admin_option "Admin" FROM user_role_privs;
MUESTRA LOS PRIVILEGIOS A NIVEL SISTEMA DEL USUARIO ACTUAL
SELECT privilege "Privilegio", admin_option "Admin" FROM user_sys_privs;
VERIFICAR LOS ROLES DE CUALQUIER USUARIO DE LA DB, CONECTADO COMO SYS O DBA
SELECT * FROM DBA_ROLE_PRIVS
Saludos
- Inicie sesión para enviar comentarios
Hola Carlos.. A lo mejor tu
Hola Carlos.. A lo mejor tu me puedes ayudar, se que hay una combinacion de memoria para que el porcentaje de aciertos de una base de datos oracle 9i no este muy baja, pero he manejado muchas hipotesis y no he podido rendir mi base de datos a un nivel optimo ( que no baje del 90% del porcentaje de aciertos) actualmente la tengo como en 60%, que puedo hacer para que el porcentaje de aciertos no sea tan bajo..
- Inicie sesión para enviar comentarios
Muy útiles estos
Muy útiles estos scripts.
Añado uno relativo a consulta de espacio disponible, ya habeís listado alguno, pero este me parece sencillo y de utilidad también:
SELECT SYSDATE AS FECHA_ACT, DEDICADO.TABLESPACE "TABLESPACE", ROUND (DEDICADO.ESPACIO, 2) "ESPACIO DEDICADO (GB)", ROUND (LIBRE.ESPACIO, 2) "ESPACIO LIBRE (GB)", ROUND (DEDICADO.ESPACIO - LIBRE.ESPACIO, 2) "ESPACIO USADO (GB)", LPAD (ROUND ((LIBRE.ESPACIO / DEDICADO.ESPACIO) * 100, 2) || '%', 6, ' ') "% ESPACIO LIBRE" FROM (SELECT DDF.TABLESPACE_NAME "TABLESPACE", SUM (DDF.BYTES) / 1024 / 1024 / 1024 "ESPACIO" FROM DBA_DATA_FILES DDF WHERE DDF.TABLESPACE_NAME IN ('tablespace1', ' tablespace2') GROUP BY DDF.TABLESPACE_NAME) DEDICADO, (SELECT DFS.TABLESPACE_NAME "TABLESPACE", SUM (DFS.BYTES) / 1024 / 1024 / 1024 "ESPACIO" FROM DBA_FREE_SPACE DFS WHERE DFS.TABLESPACE_NAME IN ('tablespace1', ' tablespace2') GROUP BY DFS.TABLESPACE_NAME) LIBRE WHERE DEDICADO.TABLESPACE = LIBRE.TABLESPACE ORDER BY LIBRE.ESPACIO / DEDICADO.ESPACIO ASC- Inicie sesión para enviar comentarios
Hola !!! Tengo un
Hola !!!
Tengo un problema que no se como resolver, tengo un procedimiento que le estoy mandando como parametro el nombre de una funcion, dentro del procedimiento quiero que se ejecute la funcion pero no se como ejecutarla, lo que tengo en el codigo es algo asi:
resultado_funcion := p_nombre_funcion;
pero esto solo le asigna a la variable resultado_funcion el nombre de la funcion que tiene el parametro p_nombre_funcion.
Como puedo hacer para que se ejecute la funcion ???
Gracias y Saludos.
- Inicie sesión para enviar comentarios
Este caso requiere de uso SQL
Este caso requiere de uso SQL dinámico con la instrucción EXECUTE IMMEDIATE, ésta es muy potente, ya que permite el uso de parámetros con gran efeciencia. Recuerda revisar el prerequisito de roles para que se pueda ejecutar las funciones o procedimientos.
saludos
mabefa
- Inicie sesión para enviar comentarios
Genial, me alegro de haberte
- Inicie sesión para enviar comentarios
Excelente recopilación, me ha
- Inicie sesión para enviar comentarios
Estimado, agradecería puedas
- Inicie sesión para enviar comentarios
Rafael, no acabo de entender
- Inicie sesión para enviar comentarios
buenos dias una pregunta, hay
- Inicie sesión para enviar comentarios
Para localizar el path del
Para localizar el path del fichero Init.ora puedes probar con alguna de estas opciones:
SQL> show parameter ifile; SQL> select value from v$parameter where name = 'ifile';
- Inicie sesión para enviar comentarios
Hola agradeciendo la buena
- Inicie sesión para enviar comentarios
Hola yo tengo diversas
- Inicie sesión para enviar comentarios
Hola Carlos! quisiera ver si
- Inicie sesión para enviar comentarios
Saludos, este tema me ha
- Inicie sesión para enviar comentarios
Saludos, ya encontré como
- Inicie sesión para enviar comentarios
Hola Pomball, te paso una
- Inicie sesión para enviar comentarios
Buenas tardes, Estoy haciendo
- Inicie sesión para enviar comentarios
Buenas noches, mi pregunta es
- Inicie sesión para enviar comentarios
Si te he entendido bien, lo
Si te he entendido bien, lo que puedes hacer es comparar con la concatenación de los dos campos. Algo así:
select * from tabla1 where cd_Grupo in (select cd_Grupo_or || cd_Grupo_be from tabla2);Saludos,
- Inicie sesión para enviar comentarios
auxilio carlos esta consulta
- Inicie sesión para enviar comentarios
Bueno, las agrupaciones
- Inicie sesión para enviar comentarios
Buenos tardes como puedo
- Inicie sesión para enviar comentarios
Por favor lo que necesito es
Por favor lo que necesito es leer los archivos de un directorio y guardar los nombres de los archivos en otro archivo para luego trabajar con los datos del archivo creado. Ademas luego de haber leído los archivos necesito cambiar su nombre a manera de tener un estado de archivos leídos y no leídos aun.
Gracias si alguien me puede echar una mano.
- Inicie sesión para enviar comentarios
Como podria consultar desde
Como podria consultar desde plsql el tamaño de un archivo que se encuentra en una ruta de mi maquina.
Saludos
- Inicie sesión para enviar comentarios
Carlos buenos días, quisiera
- Inicie sesión para enviar comentarios
Hola Patric No acabo de ver
Hola Patric
No acabo de ver bien el orden. ¿Primero alterar el campo y luego vaciarlo? Si el campo tiene datos creo que te dará error. Te copio un ejemplo del foro de la OTN de un método para cambiar el tipo de datos de un campo apoyándote en otro campo auxiliar:
SQL> create table "USER" (UserId varchar2(5))
Table created.
SQL> insert into "USER" values ('12345')
1 row created.
SQL> alter table "USER" add (UserId_tmp number(5))
Table altered.
SQL> update "USER" set userid_tmp=userid
1 row updated.
SQL> alter table "USER" set unused column userid
Table altered.
SQL> alter table "USER" rename column userid_tmp to userid
Table altered.
SQL> alter table "USER" drop unused columns
Table altered.
SQL> desc "USER"
TABLE USER
Name Null? Type
----------------------------------------- -------- ----------------------------
USERID NUMBER(5)
Otra opción que te podría funcionar más rápido, si tienes espacio y no hay muchas restricciones sobre la tabla, es utilizar como apoyo una tabla entera en lugar de un campo en la misma tabla. Tendrías que hacer una copia de la tabla original, y después truncar la original, modificar el tipo de datos del campo con un alter, y finalmente hacer un insert desde la copia con un TO_CHAR para el campo que quieres cambiar de tipo.
De todas maneras, yo haría igualmente el backup de la tabla que vas a modificar.
- Inicie sesión para enviar comentarios
Buenas tardes carlos o
Buenas tardes carlos o cualquier que me pueda colaborar le explico con un ejemplo tengo muchos procedimiento que se manejan en form 10g y otros desde php, resulta que hay algun procedimiento no se cual que me esta borrando unos datos en una tabla me gustaria saber si esto es posible y como
quiero hacer un trigger que me diga que usario la fecha y que procedmiento esta invocando sea el insert el update o delete de una tabla
yo ya he hecho trigger y guarda datos normal cuando inserta actualiza o borra y guardo lo que habia antes o despues el usuario que lo hizo y la fecha hasta aqui todo perfecto, pero hay una forma de saber que procedimiento o funcion fue el que invoca la tabla aaaa de modo que el trigger capture cual fue ese procedimiento o funcion (osea el nombre) y lo guardo en mi disparador de la base, de datos de modo que asi puedo saber en donde esta el error y corregirlo mas rapido y no estar mirando todos los ciento de procedimiento que pueda existir y ahi si corregirlo, osea como se dice ir al grano, con ese trigger que quiero hacer es guardar que PROCEDIMIENTO o FUNCION (su nombre) invoca la tabla aaa
muchas gracias a todos estos son mis correos por si me puede escribir le estaria agradecido
asanchez@unet.edu.ve
lalcubo@gmail.com
- Inicie sesión para enviar comentarios
Estimados, Antes que nada
- Inicie sesión para enviar comentarios
Estimados, Ante todo
- Inicie sesión para enviar comentarios
Hola tengo una duda acerca de
Hola tengo una duda acerca de crear un nuevo esquema en una base de datos.
existe un servidor d base de datos que tiene 3 esquemas (son de 3 docentes) y ha llegado un nuevo docente asi que necesito crear un nuevo esquema pero no se que pasos seguir. En internet encuentro diversas formas y confunde.
manejo este servidor desde la terminal.
- Inicie sesión para enviar comentarios
hola buenas disculpe como
hola buenas disculpe como puedo ver un subtotal en una bd.?
- Inicie sesión para enviar comentarios
Hola, muy interesante tu
Hola, muy interesante tu sitio, tengo una pregunta que quizas es tonta pero soy nuevo en esto y es la siguiente.
¿Existe una forma de ver que afectaciones tiene la accion de un boton en una aplicacion en la base de datos?
por ejemplo que al dar click en un check y salvar las modificaciones, saber que realizo a nivel base de datos si ejecuto algun procedimiento almacenado?
saludos y disculpa por la pregunta un poco fuera de lugar
- Inicie sesión para enviar comentarios
Hola Javier Si el botón
Hola Javier
Si el botón ejecuta un procedimiento almacenado puedes revisar el código del procedimiento para comprobar qué es lo que hace, o ejecutar tú directamente el procedimiento desde la base de datos, si estás seguro de que no vas a estropear nada.
Si el procedure es muy complejo, y cuesta seguirlo, puedes al menos buscar las sentencias SQL que incluye y ver sobre qué tablas se hacen inserts, updates o deletes, y consultar después los datos de esas tablas para comprobar qué es lo que ha cambiado.
Saludos,
- Inicie sesión para enviar comentarios
Como saber con una conslta si
Como saber con una conslta si algun proceso: paquete, procedimiento o funcion esta siendo utilizada por algun usuario
Saludos....
- Inicie sesión para enviar comentarios
Hola Franco Podrías probar
Hola Franco
Podrías probar este script que he encontrado en AskTom. Te muestra lo que cada usuario está ejecutando, y podrías adaptarlo buscando en sql_text partes del SQL de los packages o funciones que te interese controlar.
---------------- showsql.sql --------------------------
column status format a10
set feedback off
set serveroutput on
select username, sid, serial#, process, status
from v$session
where username is not null
/
column username format a20
column sql_text format a55 word_wrapped
set serveroutput on size 1000000
declare
x number;
begin
for x in
( select username||'('||sid||','||serial#||
') ospid = ' || process ||
' program = ' || program username,
to_char(LOGON_TIME,' Day HH24:MI') logon_time,
to_char(sysdate,' Day HH24:MI') current_time,
sql_address, LAST_CALL_ET
from v$session
where status = 'ACTIVE'
and rawtohex(sql_address) <> '00'
and username is not null order by last_call_et )
loop
for y in ( select max(decode(piece,0,sql_text,null)) ||
max(decode(piece,1,sql_text,null)) ||
max(decode(piece,2,sql_text,null)) ||
max(decode(piece,3,sql_text,null))
sql_text
from v$sqltext_with_newlines
where address = x.sql_address
and piece < 4)
loop
if ( y.sql_text not like '%listener.get_cmd%' and
y.sql_text not like '%RAWTOHEX(SQL_ADDRESS)%')
then
dbms_output.put_line( '--------------------' );
dbms_output.put_line( x.username );
dbms_output.put_line( x.logon_time || ' ' ||
x.current_time||
' last et = ' ||
x.LAST_CALL_ET);
dbms_output.put_line(
substr( y.sql_text, 1, 250 ) );
end if;
end loop;
end loop;
end;
/
column username format a15 word_wrapped
column module format a15 word_wrapped
column action format a15 word_wrapped
column client_info format a30 word_wrapped
select username||'('||sid||','||serial#||')' username,
module,
action,
client_info
from v$session
where module||action||client_info is not null;
Saludos,
- Inicie sesión para enviar comentarios
select * from sys.dba_users
select * from sys.dba_users order by username como sacar los datos mas ordenados en tablas sale esto
USERNAME USER_ID PASSWORD ------------------------------ ---------- ------------------------------ ACCOUNT_STATUS LOCK_DATE EXPIRY_DA -------------------------------- --------- --------- DEFAULT_TABLESPACE TEMPORARY_TABLESPACE CREATED ------------------------------ ------------------------------ --------- PROFILE INITIAL_RSRC_CONSUMER_GROUP ------------------------------ ------------------------------ EXTERNAL_NAME -------------------------------------------------------------------------------- PASSWORD E -------- -
- Inicie sesión para enviar comentarios
Hola tengo una consulta como
Hola tengo una consulta como puedo averiguar dentro de un esquema todas las tablas que ya no se estan usando por ejemplo sacar un listado con todas las temporales creadas por el usuario que ya no se registran o no tienen movimientos por años saludos y gracias.
- Inicie sesión para enviar comentarios
Hola a todos expertos
Hola a todos expertos DBA,
Necesito llevar a cabo una analisis sobre archivos SQL REDO y deseo encontrar especificamente sobre este REDO datos relacionados a una Columna y Valor que se me han indicado buscar, actualmente mi proceso es muy rudimentario, y busco dentro de todo el REDO posibles coincidencias con el campo.
Select * FROM LOGMINER_MONITOR WHERE (LGMN_SQL_REDO LIKE '%589%' and LGMN_SQL_REDO LIKE '%SEGU466%' ) and LGMN_TIMESTAMP between to_date('03/07/2017 00:00:00','dd/mm/yyyy hh24:mi:ss') and to_date('08/07/2017 23:59:59','dd/mm/yyyy hh24:mi:ss') ORDER BY LGMN_TIMESTAMP DESCSe me solicita buscar específicamente en la columna Historics el Valor 598 y el otro valor de la columna INVDS = SEGU466.
Podrian ayudarme eh dado de topes, ya que no soy nuevo en temas de BD.
Agradecere el apoyo.
- Inicie sesión para enviar comentarios
Estoy realizando un query
Estoy realizando un query donde debo acceder a tablas que esta en otras 2 maquinas con un usuario y password distinto; y no quieren crear un dblink
- Inicie sesión para enviar comentarios
Quisiera saber en oracle como
Quisiera saber en oracle como extraer solo los atributos que no son nulos. Ejemplo tengo una tabla de trabajo para realizar un update a otra tabla (maestra), los campo son en común, pero solo se actualizarán de la tabla maestra aquellos campos que en la tabla de trabajo esten poblados, es decir debo descartar lo que sean null. Por favor me podrian ayudar??
- Inicie sesión para enviar comentarios
Estimado, Espero se encuentre
Estimado, Espero se encuentre bien, Quisiera saber la forma de realizar un update de una tabla maestra desde una tabla de trabajo en donde hay campos en común pero solo se actualizarán los campos que no estan null en la tabla de trabajo. ya que asi se registraron.
- Inicie sesión para enviar comentarios
Buenas tardes! Quisiera saber
Buenas tardes! Quisiera saber cómo consultar los logins de la Base de Datos que no han tenido actividad/conexión en la BD en determinado tiempo con el fin de depurar usuarios inactivos.
- Inicie sesión para enviar comentarios
Hola, quisiera su ayuda para
Hola, quisiera su ayuda para saber como hacer que los UPDATE a la tabla "X" se tomen para la base de datos "Y" sin importar desde que base de datos se ejecute o que base de datos tengan como default. La base de datos que utilizo es Oracle SqlDeveloper. Espero puedan ayudarme >_<)
- Inicie sesión para enviar comentarios
Buenas tardes, gracias por
Buenas tardes, gracias por los tips, me sirvieron de mucho, consulte a otro compañero sobre el tema y me comento que para ver los objetos del usuario actual era mucho mejor consultar a la vista dbaobject, mi pregunta es cual es la diferencia entre consultar a esta vista y a las tablas: user_objects, user_tables,....etc?
- Inicie sesión para enviar comentarios
Hola katy La diferencia de
Hola katy
La diferencia de cara a consultar información está simplemente en la información que te muestran. Las vistas del diccionario suelen mostrar información cruzada sobre varias tablas, pero si tú tienes suficiente con la información que te da una tabla como las de user_objects o user_tables, o prefieres hacer tu misma una query que haga joins entre esas tablas para sacar la información que necesitas no tienes porqué utilizar las vistas.
Y si la vista ya se ajusta a la info que precisas, pues trabajo que te ahorras :)
- Inicie sesión para enviar comentarios
Consulta Oracle SQL para
- Inicie sesión para enviar comentarios
SSRS: #Error en una celda de importe decimal de reporte utiliza Oracle SQL
SSRS: #Error en una celda de importe decimal de reporte utiliza Oracle SQL il_masacratore 27 Abril, 2011 - 16:41Hasta el momento desconozco exactamente como o donde se detalla cada tipo de error en la ejecución de un informe de reporting services de Microsoft SQL Server. He tratado con derivados de falta de permisos, procesados incompletos de cubos pero hasta ahora ningun #Error en una celda por que sí.
El error en cuestión me aparece en la ejecución de un pequeño informe que tira de un origen de datos ODBC contra una base de datos Oracle donde se muestran totales (sumas, no porcentajes) y me ha sorprendido mucho la falta de detalle sobre el error que se produce. Para más dificultad, encima es en una combinación de parámetros concreta (las n ejecuciones anteriores han funcionado) y no en toda la columna sino en una celda. Además arrastra todo subtotal o total en el que se incluya...
Después de mirar el log del servidor de Reporting Services, después de comprobar la consulta en un cliente externo con la misma, tras pensar mal del formato me da por comprobar en el diseñador de informes el origen de datos, me hago una prueba con parámetros al tuntun y bien, pero al poner los valores problemáticos consigo que se al menos aparezca el error:
Error al leer datos del conjunto de resultados de la consulta. OCI-22053: error de desbordamiento.Pues nada, encontrado esto ya estoy más feliz ya que el error es que ado.net+oracle+odbc no lleva muy bien los números de 38 digitos...
Para esto podemos hacer un workaround que consiste en usar en la consulta la función trunc(número, decimales) de Oracle SQL para que nos trunque el valor en su parte decimal donde nosotros decidamos.
Traducción de terminología Oracle - DB2 LUW
Traducción de terminología Oracle - DB2 LUW Oscar_paredes 25 Marzo, 2011 - 12:52Con la versión 9.7 de DB2 LUW, IBM hace un guiño a todos los DBA's de Oracle, mucho más numerosos en el mercado que los DBA's de DB2.
Para ello, en la versión 9.7 de DB2 LUW ha introducido modos de compatibilidad de Oracle que permiten realizar tareas en DB2 con la facilidad y conocimiento que tienen los DBA de Oracle. Sin embargo, es importante conocer la traslación de terminología entre Oracle y DB2 si tienes la intención de meterte en el mundo IBM DB2.
En este primer artículo sobre equivalencias entre IBM DB2 y Oracle, relaciono una serie de elementos para que esa introducción sea sencilla y se pueda leer la documentación de IBM DB2 fácilmente. Entre ellos, terminología general de estas bases de datos, versiones, utilidades y vistas.
| COMPONENTES GENERALES | |
| ORACLE | DB2 LUW |
| Instance | Instance |
| File/Datafile | Container |
| Database | Database |
| Tablespace | Tablespace |
| Schema | Schema |
| Table | Table |
| Index | Index |
| View | View |
| Trigger | Trigger |
| Packages | Modules |
| Stored Procedures | Stored Procedures |
| SQL Plus | DB2 CLP |
| Data Block | Data Page |
| Dictionary | Catalog |
| Alert Log | Diag log |
| Redo Log | Log File |
| Segments | Space Consumming Objects |
| SGA | Instance/DB Shared Memory |
| VISTAS CATÁLOGO | |
| ORACLE | DB2 LUW |
|
ALL_ |
SYSIBM.* SYSSTAT.* SYSCAT.* |
| UTILIDADES | |
| ORACLE | DB2 LUW |
| RMAN IMPORT EXPORT SQL*loader DB_VERIFY ANALYZE |
BACKUP IMPORT EXPORT LOAD RESTORE REORG REORGCHK RUNSTATS |
| VERSIONES | |
| ORACLE | DB2 LUW |
| EXPRESS EDITION | EXPRESS-C |
| STANDARD EDITION ONE | EXPRESS EDITION |
| STANDARD EDITION | WORKGROUP EDITION |
| ENTERPRISE EDITION | ENTERPRISE SERVER EDITION |
Espero que os sea útil.
Oscar Paredes
IT Manager
Oracle DBA
En el artículo de IBM
En el artículo de IBM developerWorks Leverage your Oracle 11g skills to learn DB2 9.7 for Linux, UNIX and Windows hacen una comparativa muy buena de las similitudes y diferencias entre los dos motores, a nivel de arquitectura, objetos, gestión de memoria, etc.
Aunque todo el artículo es muy recomendable, sólo los dos esquemas de comparación a nivel de estructura de sistema que copio a continuación ya pueden resultar de gran ayuda:
Figure 1. Oracle system structure on Linux, UNIX, and Windows
Figure 2. DB2 on Linux, UNIX, and Windows system structure

- Inicie sesión para enviar comentarios
UPDATE con JOIN en ORACLE SQL
UPDATE con JOIN en ORACLE SQL hminguet 8 Julio, 2008 - 10:16Supongamos que queremos actualizar en nuestra base de datos ORACLE el campo de costes de la tabla de hechos FAC_TABLE con el coste unitario de nuestra tabla de COSTES.
Con Oracle SQL podemos hacerlo de dos maneras:
- Consulta Lenta, pero si es para pocos datos o para lanzarlo esporádicamente nos puede valer
update FAC_TABLE ft set COSTE_UNITARIO =
(select distinct COSTE_UNITARIO
from COSTES ct
where (ft.id_articulo = ct.id_articulo);
- La mejor manera es esta, y el rendimimento es óptimo si tiene constraints)
UPDATE (SELECT ft.COSTE_UNITARIO AS old_coste,
ct.COSTE_UNITARIO AS new_coste
FROM FAC_TABLE ft INNER JOIN COSTES ct ON ft.id_articulo = ct.id_articulo)
) SET old_coste = new_coste;Para que esta segunda opción funcione necesitamos tener UNIQUE or PRIMARY KEY constraint en ct.id_articulo.
Si no tienes esta constraint, puedes utilizar el hint /*+BYPASS_UJVC*/ después de la palabra UPDATE (bypass update join view constraint).
El rendimiento aumenta si tenemos la constraint pero aún sin ella debe correr mucho más que la primera opción.
Espero que os ayude.
Héctor Minguet.
Pruebas del UPDATE con JOIN
He tenido la oportunidad de probar este tipo de update con tablas grandes, de varios millones de registros, y realmente funciona como comentas.
He lanzado un update con la primera opción y he decidido cancelarlo cuando he visto que comenzaba a afectar negativamente al rendimiento de la base de datos. El tiempo estimado que me daba la consola de Enterprise Manager para terminar era de 1 hora y media.
Después de cancelar he probado la segunda opción y me he encontrado con el error ORA-01779 porque no tenía una clave única definida sobre el campo de la tabla con la que hacía la join. Como la tabla era demasiado grande para crear un índice único sin estudiarlo primero, he probado la opción de incluir el hint /*+BYPASS_UJVC*/ (para hacer esto hay que asegurarse antes de que la correspondencia es realmente de 1:1, si no podemos obtener resultados inesperados), y el update se ha realizado correctamente en menos de 15 minutos, una diferencia considerable.
Ahora a ver si alguien se anima y nos cuenta la mejora que se obtiene con la segunda opción, pero creando una clave única en la tabla 'enlazada', y sin utilizar el hint.
- Inicie sesión para enviar comentarios
Hola se agradece este
Hola se agradece este bypass.
Justamente tenía que actualizar unas tablas que tenian correlativos repetidos y tenian que ser secuenciales, realicé una tabla temporal y despues aplicar un update. De igual forma tenia que hacer un procedimiento almacenado pero en fin... con este bypass, todo bien.
El tiempo de respuesta en la actualizacion el descuebe GRACIAS!!!
gracias.
atte.
Maricela de CHILE
- Inicie sesión para enviar comentarios
Gracias. Lo utilice para una
Gracias.
Lo utilice para una actualizacion de varios campos y se comporto de maravilla.
- Inicie sesión para enviar comentarios
Utilice un script con este
Utilice un script con este hint /*+BYPASS_UJVC*/ y funciona una muy bien... Bajo un script de 9 hs a 6 segungos....
Pero cuando lo quiero utilizar dentro de un Package aparece un error "PL/SQL: ORA-01031: Insufficient privileges"
¿ALGUIEN PUEDE AYUDARME CON ESTE TEMA?
DESDE YA MUCHAS GRACIAS.
- Inicie sesión para enviar comentarios
Bueno lo mas probable es que
Bueno lo mas probable es que sea esto, mira una cosa son los permisos que tienes tu o tu usario y otra los permisos que tiene el paquete por ejemplo digamos que tu tienes el usuario au0001 y cuando corres esto si puedes hacerlo debido a tus permisos, pero cuando pones esto dentro del paquete que esta en el esquema au0002 y dicho esquema no tiene esos priviliegios, pues es claro que te truena aun si tu como usuario au0001 si tengas el permiso y seas tu el que corre el paquete , el paquete truena por ser el o su esquema mejor dicho el que no tiene los permisos.
- Inicie sesión para enviar comentarios
Hola intente hacerlo de las
Hola intente hacerlo de las dos maneras, el update tradicional y con el hint, con el primero se tarda bastante, lo cancele, con el segundo me marca el error ORA-01031 - Insufficient privileges, lo estoy haciendo en el mismo esquema, la tabla de la que quiero actualizar tiene llave unique en el campo que uso para unir con la tabla que tiene la información ¿A que se debe que con uno no me marque el error y con el segundo si?
- Inicie sesión para enviar comentarios
¡¡¡ UPS !!! Perdón. Gracias
¡¡¡ UPS !!! Perdón. Gracias por la ayuda.
- Inicie sesión para enviar comentarios
Muchisimas gracias por tu
- Inicie sesión para enviar comentarios
Me ha servido su update con
- Inicie sesión para enviar comentarios
La explicación es muy buena y
La explicación es muy buena y me ha servido en varios proyectos cuando la base de datos es Oracle 10g, sin embargo en Oracle 11g el hint ha desaparecido y no se puede utilizar, he leído algo acerca del tema y en todos lados lo que dice es que debo cambiar la instrucción y no utilizar más el hint bypass_ujvc.
¿Como han hecho para mitigar la eliminación del hint? ¿Es correcto mejor hacerlo por merge?
Gracias!
- Inicie sesión para enviar comentarios
Pues sí, si a partir de la
Pues sí, si a partir de la versión 11g R2 el HINT BYPASS_UJVC ya no es válido porque Oracle lo ha dejado como deprecated hay que dejar de utilizarlo, y además hay que tenerlo en cuenta en upgrades o migraciones desde versiones anteriores, ya que si se utilizaba este HINT en versiones anteriores a la 11g, al lanzar las queries que contengan el hint BYPASS_UJVC el analizador devolverá un error y la query fallará.
Una buena alternativa, tal como ya apuntas, es utilizar un MERGE para este tipo de operaciones en que se haya recurrido al HINT al no disponer de una clave primaria para el campo por el que se hace la join de la SELECT del UPDATE, aunque si se puede conseguir la clave primaria o única para ese campo, seguramente el UPDATE será más rápido.
Al utilizar el MERGE, hay que asegurarse igualmente de que la JOIN entre tabla origen y destino sea INNER, que no existan duplicados en las tablas para esos registros, porque entonces podemos encontrarnos el error ORA-30926, o efectos inesperados en los resultados. Si se diera el caso, habría que anular los duplicados eliminándolos antes de hacer la join, o modificando la query añadiendo un group by para aplicar un SUM, MAX, MIN u otra operación sobre el campo con valores duplicados.
Libros de Administración Oracle (DBA) y PL/SQL
¿Quieres profundizar más en PL/SQL de Oracle o en administración de bases de datos Oracle? Puedes hacerlo consultando alguno de estos libros de Oracle.
- Inicie sesión para enviar comentarios
Hola! Necesito algo de ayuda
Hola!
Necesito algo de ayuda con un Update de toda una columna..
La idea es actualizar la columna reintegro de la tabla tarjeta, la cual está relacionada con otras tablas (empresa, certificado,persona,institucion) donde ley=S de la tabla institucion
Les comento las consultas que he realizado sin éxito:
================== update tarjeta set reintegro ='0' where (select reintegro, ley_anterior from tarjeta , institucion where ley='S') ================== ================== Update tarjeta SET reintegro= '0' INNER JOIN empresa on tar_emp_codigo = empcodigo INNER JOIN certificado on empcodigo = cem_empcodigo INNER JOIN persona on per_documento = cem_perdocumento INNER JOIN institucion on per_inscodigo = inscodigo WHERE (ley='S') ==================
Me podrían ayudar?
Gracias
- Inicie sesión para enviar comentarios
Hola buenas tardes, no se si
- Inicie sesión para enviar comentarios
Hola, me ha sido muy útil
- Inicie sesión para enviar comentarios
Vistas materializadas de Oracle para optimizar un Datawarehouse
Vistas materializadas de Oracle para optimizar un Datawarehouse Carlos 13 Agosto, 2008 - 09:21Como las cargas de un Data warehouse se realizan de manera periódica, y además es habitual la creación de tablas agregadas para mejorar la eficiencia y tiempo de respuesta de nuestros informes, un recurso de optimización física que puede aportar grandes mejoras es la utilización de vistas materializadas.
Qué es una vista materializada
La vista materializada no es más que una vista, definida con una sentencia SQL de Oracle, de la que además de almacenar su definición, se almacenan los datos que retorna, realizando una carga inicial y después cada cierto tiempo un refresco de los mismos.
Así, si tenemos un Datawarehouse que se actualiza diariamente, podríamos utilizar vistas materializadas para ir actualizando tablas intermedias que alimenten nuestros esquemas de DWH, o directamente para implementar tablas agregadas que se refrescarán a partir de nuestras tablas base.
La creación de este tipo de vistas con Oracle SQL no es tan compleja como puede parecer, lo más importante es tener claro cada cuánto tiempo queremos actualizar la información de las vistas, y qué método de refresco utilizar.
También tendremos que asegurarnos de que nuestra licencia de base de datos nos permite utilizarlas (ha de ser una versión Enterprise).
Sintaxis básica de Oracle SQL para la creación de una vista materializada
CREATE MATERIALIZED VIEW mi_vista_materializada
[TABLESPACE mi_tablespace]
[BUILD {IMMEDIATE | DEFERRED}]
[REFRESH {ON COMMIT | ON DEMAND | [START WITH fecha_inicio] NEXT fecha_intervalo } |
{COMPLETE | FAST | FORCE} ]
[{ENABLE|DISABLE} QUERY REWRITE] AS
SELECT t1.campo1, t2.campo2
FROM mi_tabla1 t1 , mi_tabla2 t2
WHERE t1.campo_fk = t2.campo_pk AND …
Comentarios sobre las diferentes opciones de la sentencia Oracle SQL de creación de la vista:
-
Carga de datos en la vista
BUILD IMMEDIATE:
Los datos de la vista se cargan en el mismo momento de la creación
BUILD DEFERRED:
Sólo se crea la definición, los datos se cargarán más adelante. Para realizar esta carga se puede utilizar la función REFRESH del package DBMS_MVIEW:
begin
dbms_mview.refresh('mi_vista_materializada');
end;
-
Método y temporalidad del refresco de los datos
Cada cuánto tiempo se refrescarán:
REFRESH ON COMMIT:
Cada vez que se haga un commit en los objetos origin definidos en la select
REFRESH ON DEMAND:
Como con la opción DEFERRED del BUILD, se utilizarán los procedures REFRESH, REFRESH_ALL_MVIEWS o REFRESH_DEPENDENT del package DBMS_MVIEW
REFRESH [START WITH fecha_inicio] NEXT fecha_intervalo:
START WITH indica la fecha del primer refresco (fecha_inicio suele ser un SYSDATE)
NEXT indica cada cuánto tiempo se actualizará (fecha_intervalo podría ser SYSDATE +1 para realizar el refresco una vez al día)
-
De qué manera se refrescarán
REFRESH COMPLETE:
El refresco se hará de todos los datos de la vista materializada, la recreará completamente cada vez que se lance el refresco
REFRESH FAST:
El refresco será incremental, es la opción más recomendable, lo de fast ya da una idea del porqué.
Este tipo de refresco tiene bastantes restricciones según el tipo de vista que se esté creando.
Se pueden consultar en General Restrictions on Fast Refresh de la documentación oficial de Oracle
Una de las cosas importantes a tener en cuenta es que para poder utilizar este método casi siempre es necesario haber creado antes un LOG de la Vista materializada, indicando los campos clave en los que se basará el mantenimiento de la vista.
Se utiliza la instrucción de Oracle SQL "CREATE MATERIALIZED VIEW LOG ON":
CREATE MATERIALIZED VIEW LOG ON mi_tabla_origen WITH PRIMARY KEY INCLUDING NEW VALUES;
REFRESH FORCE:
Con esta opción se indica que si es posible se utilice el metodo FAST, y si no el COMPLETE.
Para saber si una vista materializada puede utilizar el método FAST, el package DBMS_MVIEW proporciona el procedure EXPLAIN_MVIEW
-
Activación de la reescritura de consultas para optimizar el Data warehouse
ENABLE QUERY REWRITE:
Se permite a la base de datos la reescritura de consultas
DISABLE QUERY REWRITE:
Se desactiva la reescritura de consultas
La opción QUERY REWRITE es la que más vamos a utilizar si queremos las vistas materializadas para optimizar nuestro Data warehouse.
Esta opción permite crear tablas agregadas en forma de vistas materializadas, y que cuando se lance una SELECT la base de datos pueda reescribirla para consultar la tabla o vista que vaya a devolver los datos solicitados en menos tiempo, todo de manera totalmente transparente al usuario
Lo único que hay que hacer es crear las tablas agregadas como vistas materializadas con QUERY REWRITE habilitado.
Ejemplos de vistas materializadas de Oracle
Son muchas combinaciones, pero la sentencia final no es tan compleja.
Primer paso de la ETL de un Data warehouse
Si quisiéramos crear con SQL de Oracle una vista materializada de una tabla que se refresque un día a la semana, y de manera incremental haríamos lo siguiente:
CREATE MATERIALIZED VIEW LOG ON mi_tabla_origen WITH PRIMARY KEY INCLUDING NEW VALUES; CREATE MATERIALIZED VIEW mi_vista_materializada REFRESH FAST NEXT SYSDATE + 7 AS SELECT campo1, campo2, campo8 FROM mi_tabla_origen WHERE campo2 > 5000;
Esta vista podría servirnos para alimentar la carga de un Data Mart que se realizara semanalmente. Podríamos programarla para que se refrescara justo antes del inicio del proceso de carga, o como primer paso en la ETL, y ya tendríamos los datos necesarios actualizados, e independientes del origen de datos (no tendríamos que molestar más al operacional). Otra ventaja a tener en cuenta es que si hay algún problema con el acceso a los datos de origen, si no los hemos eliminado, en la vista materializada aún tendremos los datos del último refresco, con lo que aunque el refresco fallara no nos encontraríamos un error que truncara la carga de nuestro Data Warehouse, o una tabla vacía.
Por supuesto, en las condiciones del WHERE de la sentencia SQL de creación podríamos seleccionar sólo los registros necesarios, sólo los del último mes, etc.
Tablas agregadas para optimizar el Data Warehouse
Otro ejemplo importante sería la utilización de vistas materializadas para la creación de tablas agregadas.
-- Oracle SQL para crear agregadas con materilized views CREATE MATERIALIZED VIEW ventas_agregadas_mv BUILD IMMEDIATE REFRESH COMPLETE ENABLE QUERY REWRITE AS SELECT id_producto, sum(importe) total_ventas FROM ventas GROUP BY id_producto;
Con esta sencilla sentencia de Oracle SQL se crearía una tabla agregada de total de ventas por producto de una supuesta tabla de ventas que seria la tabla de hechos.
A nivel de sesión también habría que asegurarse de que la opción QUERY_REWRITE estuviera activada. Por si acaso, desde SQL Plus, se puede habilitar con la sentencia SQL:
SQL> ALTER SESSION SET QUERY_REWRITE_ENABLED=TRUE;
Si ahora dentro de esta sesión se ejecuta la sentencia SQL
SQL> SELECT sum(importe)
FROM ventas;la base de datos preparará el plan de ejecución teniendo en cuenta la vista materializada creada e internamente realizará la selección sobre la vista ventas_agregadas_mv.
Una manera sencilla de comprobarlo, aparte de examinar el plan de ejecución, o de comparar tiempos antes y después de la creación de la vista, o desactivando el QUERY_REWRITE, es comprobar que esta query SQL devuelve resultados en el mismo tiempo que la query
SELECT sum(importe) FROM ventas_agregadas_mv;
Para consultar más detalles, o la sintaxis SQL completa de la creación de vistas materializadas Oracle, el capítulo Create Materialized View del manual de referencia SQL de Oracle es un buen recurso.
Con Oracle Enterprise Manager (OEM), o con la consola web de la base de datos también se pueden crear las vistas materializadas de una manera más asistida, pero igualmente es importante tener claros los conceptos antes de hacerlo.
Libros de Administración Oracle (DBA) y PL/SQL
¿Quieres profundizar más en PL/SQL de Oracle o en administración de bases de datos Oracle? Puedes hacerlo consultando alguno de estos libros de Oracle.
Los libros que ves a continuación son una selección de los que a mi me parecen más interesantes para aprender administración y desarrollo PL/SQL, teniendo en cuenta precio y temática, espero que te puedan ser de utilidad:
- eBooks de Oracle gratuítos para la versión Kindle, o muy baratos (menos de 4€):
Instalaciones y sistemas
Instalaciones y sistemas Dataprix 8 Septiembre, 2009 - 09:52Bases de datos embedded: Apache Derby y Sleepy cat
Bases de datos embedded: Apache Derby y Sleepy cat alone 9 Febrero, 2007 - 16:19Cuando hablamos de bases de datos, normalmente nos imaginamos un gran servidor, com grandes cantidades de información en su interior. Ahora bien, también existen bases de datos minúsculas para entornos donde el espacio, tanto de almacenaje como de proceso, es muy importante.
Dentro del proyecto Apache existe un proyecto llamado Derby. Derby es una base de datos relacional, implementada totalmente en Java que tiene la particularidad del pequeño tamaño que supone. Sun, a partir de Apache Derby, ha desarrollado su propia base de datos llamada JavaDB.
Así mismo, Oracle ha adquirido la base de datos Sleepy cat, desarrollada incialmente en la universidad de Berkeley.
Em ambos casos, sorprende el rendimiento, tanto en velocidad como en capacidad, y la funcionalidad.
Crear BD Oracle en Windows y Linux
Crear BD Oracle en Windows y Linux cfb 13 Febrero, 2007 - 01:22En el site www.ajpdsoft.com se publica el manual online Instalacion Oracle 9i sobre Windows, donde se explica paso a paso y con captura de pantallas cómo instalar una BD Oracle 9i sobre windows, cómo solucionar algunos de los errores típicos que suelen aparecer durante la instalación, cómo levantar el listener, comprobar el estado de la base de datos, y alguna cosa más..
Instalación de Oracle 10g Express bajo Debian
Instalación de Oracle 10g Express bajo Debian sabueso 20 Agosto, 2006 - 04:55La gente de Debian Administration nos muestra como instalar en pocos pasos un Oracle 10g Express.
El proceso de instalacion se realiza via Apt , y tb nos explican como dejarlo a punto para su utilizacion.
El articulo podemos encontrarlo aqui
Instalación de una base de datos Oracle sobre Linux
Instalación de una base de datos Oracle sobre Linux Carlos 14 Julio, 2008 - 18:14Para instalar una base de datos Oracle sobre una distribución Linux lo mejor es seguir las indicaciones de Oracle. En Oracle by example - Oracle database 10g on a single instance Oracle explica de una manera bastante clara cómo hacerlo.
Una cosa importante a tener en cuenta es que cada distribución LINUX tiene sus peculiaridades, y que no todo sirve para todas. Lo más recomendable es utilizar las que están certificadas por Oracle, eso no garantiza que no surgan problemas, pero por lo menos Oracle los documenta. Oracle suele certificar para distribuciones SUSE en su versión empresarial (SLES) y RedHat.
Una buena opción, si queremos tener lo más parecido a las versiones empresariales, y poder ir actualizando nuestro SO, puede ser utilizar Open SUSE o CentOS. Otra puede ser utilizar su propia distribución Oracle Enterprise Linux
Instalación desatendida Oracle Express Edition - Oracle XE silent mode installation
Instalación desatendida Oracle Express Edition - Oracle XE silent mode installation Oscar_paredes 12 Octubre, 2007 - 11:42Debido a la gratuidad de esta versión de Oracle suele ser común su uso para instalaciones masivas en múltiples PC's, TPV's...
Este artículo orientado a DBA's de Oracle y desarrolladores resume brevemente como realizar una instalación desatendida de Oracle XE.
Esta instalación es tan sencilla como ejecutar el instalador de Oracle XE con los siguientes parámetros:
> oraclexe /s /f1"fichero_respuesta.iss" /f2"fichero_de_log"
El primer fichero indica los parámetros básicos de la instalación, y el segundo será el log resultante de la instalación.
Los parámetros configurables en el fichero de respuesta de la instalación son:
** szDir - Path de instalación del software y de ficheros de datos
** TNSPort - Puerto Listener BBDD
** MTSPort - Puerto MTS
** HTTPPort - Puerto HTTP consola
** SYSPassword - Password del usuario SYS
** bOpt1 - 1 or 0 : Ejecución o no al final de la consola a través del navegador
El resultado de la instalación se puede consultar en el fichero de log. Sin embargo, en caso de problemas este fichero no resulta muy útil, para ello se puede consultar el fichero generado en el directorio %systemroot% (en Windows C:\WINDOWS).
Además de una instalación desatendida también es posible realizar una desinstalación o reparación desatendida.
Oscar Paredes
IT Manager
Oracle DBA
| Adjunto | Size |
|---|---|
| oraclexe_response.txt | 162 bytes |
Copia de la base de datos
Y si el valor de los parámetros fuera el mismo en la nueva instalación (path, puertos, etc), funcionaría la nueva base de datos copiando directamente los ficheros de una BD vacía (o con datos, según interese más) en la máquina destino?
Obviamente antes pararíamos la BD origen.
- Inicie sesión para enviar comentarios
LAMP o LAOP
LAMP o LAOP Oscar 7 Julio, 2008 - 23:06Navegando por la red he encontrado en PHP y otras yerbas un artículo que habla de un manual de PHP y Oracle. Conocía las siglas LAMP, pero no las siglas LAOP.
Resumiendo, un manual sencillo y creado por el equipo de Oracle para todos aquellos que tienen pensado una posible migración de MySql a Oracle en su gestor de contenidos, sobre todo, los de caracter empresarial.
Qué bueno, también puede ser
Qué bueno, también puede ser útil para quien piensa que conectar con Oracle desde PHP es complicado ;)
Ahora sólo falta que los proveedores de hosting incluyan un Oracle XE en sus paneles de control
- Inicie sesión para enviar comentarios
Oracle RAC One Node
Oracle RAC One Node Oscar_paredes 7 Abril, 2011 - 14:38En la release 2 de Oracle 11g, se introduce un nuevo producto Oracle Real Application Clusters One Node (Oracle RAC One Node).
La definición rápida del producto seria: es una instancia de Oracle RAC pero ejecutado en 1 único nodo. No es que sea una única máquina física, puede estar corriendo en diversos servidores físicos (de hecho, es lo habitual) sino que una instancia de Base de Datos está ejecutándose únicamente en 1 nodo al mismo tiempo (* aunque ya veremos que está afirmación no es del todo cierta).
Lo más fácil es ver un esquema para entenderlo a la perfección:
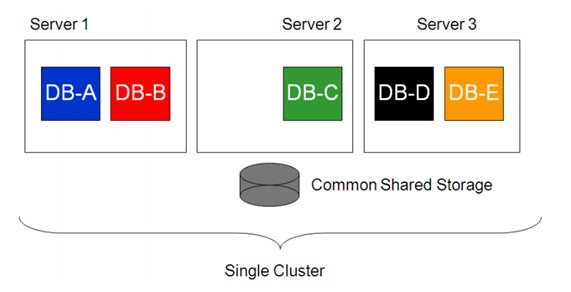
En este esquema, tenemos 3 servidores físicos que contienen un total de 5 instancias Oracle ejecutándose con Oracle RAC One Node. Cada nodo tiene un S.O., es decir, no son máquinas virtuales distintas.
Cuáles son sus ventajas más destacables:
- Permite al DBA de Oracle dar alta disponibilidad de una instancia de Base de Datos, tanto a nivel de fallo de Servidor, o a nivel de BBDD (notar que por ejemplo, VMware sólo lo proporcionaría a nivel del hardware del Servidor). Es decir, en el ejemplo anterior, una caída o problema de indisponibilidad del Server 2, haría que la base de datos DB-C se moviera a otro servidor físico, de manera automática.
- Permite al Oracle DBA repartir recursos físicos online (Instance Caging). Por ejemplo, en el ejemplo anterior, si el Server 1 tuviera 4 procesadores físicos, se podría indicar que la instancia DB-A tuviera asignado 3 y la instancia DB-B tuviera sólo 1 asignado. Además, se podría reasignar dinámicamente sin necesidad de reinicio de ningún tipo, en caso de necesidad de más procesador por parte de una de las instancias.
- En caso de mantenimiento de uno de los servidores físicos (p.e., por necesidad de aplicar parches, se podría mover sus instancias dinámicamente y sin pérdida de servicio. Esta característica se realiza a través de Oracle Omotion. Para evitar pérdida de servicio, durante breves instantes, Oracle RAC One Node levanta una nueva instancia en el servidor destino, de manera que, en ese periodo de tiempo existen 2 instancias atacando a la misma Base de Datos (como con Oracle RAC).
- Posibilidad de upgradear a Oracle RAC en cualquier momento sin corte de servicio.
Como véis, el almacenamiento debe ser compartido.
Al igual que Oracle RAC, Oracle RAC One Node utiliza el software de clusterización Oracle Clusterware para el control de los recursos clusterizados en los distintos nodos. Esto hace, lógicamente, que la compatibilidad con otros productos de clusterización (Veritas, Sun Cluster, etc..) no sea posible.
Oracle para vendernos el producto, insiste en las ventajas de tener n-máquinas físicas con Oracle RAC One Node en comparación con tenerlas dentro de una granja VMware. Estas ventajas se pueden resumir en:
- Mayor eficiencia en el uso de recursos, al no utilizar la capa del hypervisor.
- Facilidad en la instalación de parches (menos Sistemas Operativos y posibilidad de cambiar el servidor que da servicio).
- Modificación dinámica de la CPU sin necesidad de reinicar.
El licenciamiento es más barato que Oracle RAC, de manera que, este producto se puede ver como una aproximación de coste inferior, para posteriormente actualizarla a Oracle RAC:
Espero que os sea útil.
Oscar Paredes
IT Manager
Oracle DBA
Oracle XE, la base de datos gratuita de Oracle
Oracle XE, la base de datos gratuita de Oracle Carlos 29 Diciembre, 2006 - 00:34Oracle ofrece una versión gratuita de su base de datos, con el principal objetivo de introducir en el 'mundo Oracle' a desarrolladores, DBAs, estudiantes y formadores, y vendedores de hardware y software que quieran distribuir junto con sus productos una base de datos sin costes de licencia. El producto es Oracle 10g Express Edition (Oracle Database XE) y, obviamente, tiene sus limitaciones.
Sólo puede utilizar 1 procesador del servidor donde esté instalada, un máximo de 1 Gb de RAM, y tiene limitado el almacenamiento a 4 Gb de datos de usuario. Cuando se superen estas limitaciones, Oracle ofrece un sencillo proceso de actualización a otras versiones más completas, y en las que sí que hay que pagar licencias.
De todas maneras es una opción muy válida para quien quiera practicar con bases de datos Oracle, o para quien necesite una base de datos limitada en cuanto a tamaño, pero fiable y eficiente, y gratuita.
Con la base de datos, Oracle incluye también Oracle Application Express, un entorno sencillo e intuitivo que permite realizar gráficamentes las tareas básicas de administración de la base de datos.
Se puede descargar esta base de datos, o consultar información más concreta sobre la misma en Oracle Database XE.
Recomiendo consultar antes de la instalación el Datasheet de Oracle Database XE, y las características de Oracle Application Express.
Oracle sobre Linux
Oracle sobre Linux Carlos 17 Agosto, 2006 - 21:40Tradicionalmente las bases de datos Oracle de una cierta envergadura se han ido instalando sobre servidores con SO UNIX, y también sobre sistemas servidores windows.
Con el reconocimiento de Linux como un SO suficientemente fiable para su utilización en grandes servidores, las grandes corporaciones comienzan a plantearse la utilización de este sistema por la flexibilidad, y acceso al código fuente que ofrece, y por la ausencia de costes en licencias.
Así, una opción que cada vez ganará más adeptos es la instalación de BBDD Oracle sobre Linux.
En el caso de éxito descrito por Oracle en el pdf adjunto se muestra el interesante ejemplo del Grupo Gas Natural, donde se tomó la decisión de migrar la base de datos Oracle que albergaba el Data Warehouse corporativo desde potentes máquinas en plataforma UNIX a servidores más modestos en cluster sobre una plataforma Linux.
Concretamente, la base de datos se migró a Oracle 9i con Real Application Cluster sobre Linux RedHat.
Con esta solución se consiguió una reducción de los costes, a la vez que mejoraban tanto el rendimiento como la escalabilidad del sistema.
Oracle-on-Linux VMware Tool Kits
Oracle-on-Linux VMware Tool Kits drakon 15 May, 2007 - 23:18Estaba navegando por la web de Oracle, concretamente unos apartados para principiantes como yo: "Getting Started". Éstos apartados te guían en muchos temas, incluso puedes encontrar un buen checklist de configuración de seguridad, para principiantes.
Además de ésto he encontrado unos Tool Kits para que en poco tiempo puedas montarte en tu escritorio Windows una VMWare con GNU/Linux y con el Oracle Database 10g preconfigurado. Los Tool Kits están disponibles con Red Hat o Novell. Y además viene acompañado de una guía que explica incluso cómo instalar VMWare.
Todo ésto bajo licencia de evaluación está claro. Si hay alguien que lo ha probado o que lo va a testear, que exponga sus opiniones al respecto.
Ya está disponible Oracle 10g para Windows Vista
Ya está disponible Oracle 10g para Windows Vista Carlos 30 May, 2007 - 22:27Para los que quieren estar siempre a la última y para los amantes del riesgo, desde el 4 de mayo está disponible la última versión del servidor de base de datos de Oracle para Windows Vista. Se puede descargar en Oracle Database 10g Release 2 para Windows Vista
Si alguien se anima y la prueba puede ser interesante cualquier comentario al respecto..
ayuda oracle vista
hola nesecito que me ayuden tengo instlado el oracle 10.2.0.2 y nesecito pasarlo a oracle 10.2.0.3 debido a que se trabajara en windows vista..espero me ayudes
- Inicie sesión para enviar comentarios
Resolución de Bugs y Errores
Resolución de Bugs y Errores Dataprix 8 Septiembre, 2009 - 09:5510 bugs de Oracle en 10 minutos
10 bugs de Oracle en 10 minutos sabueso 7 Septiembre, 2007 - 19:11Cesar Cerrudo, de Black Hat muestra como con herramientas libres buscar bugs dentro de una base de datos.
La noticia , aqui
Bugs de Oracle o de Windows?
Las herramientas utilizadas para detectar estos bugs son Process Explorer, WinObj, Pipeacl, and Interactive Disassembler (IDA), y la plataforma utilizada un Windows.
Ahora están investigando si estos problemas de seguridad son de la base de datos o del propio Windows, que nos avise quien se entere de las conclusiones.
De todas maneras detectar problemas de seguridad en un software que corra bajo esta plataforma es importante, pero no me parece un gran hallazgo.
A ver si alguien se anima a encontrar otros 10 bugs sobre la versión 10g de Oracle sobre UNIX, o incluso la de LINUX y nos lo cuenta..
Carlos Fernández
Analista de sistemas
- Inicie sesión para enviar comentarios
El error ORA-30926 como resultado de una operación Merge
El error ORA-30926 como resultado de una operación Merge Carlos 17 Febrero, 2009 - 22:01El error ORA-30926 suele producirse cuando se realizan operaciones Merge, y lo normal es que nos deje algo descolocados, ya que la descripción del mismo no da demasiada información sobre lo que está pasando:
ORA-30926: unable to get a stable set of rows in the source tables.
Normalmente este error se produce cuando en la operación Merge a una fila destino que hay que actualizar le corresponden más de una fila en la tabla origen. Como el motor no sabe qué registro escoger devuelve un error. Es un problema de duplicidad en la tabla origen.
Ejemplo:
- Tenemos:
TABLA_ORIGEN con los valores
ID Descripcion
1 'El primer valor'
1 'El valor con id duplicado'
2 'Otro valor'Y TABLA_DESTINO con los valores
ID Descripcion
1 'Valor a actualizar'
2 'Este no dará problemas'
3 'Este se queda igual'
- Queremos hacer un merge utilizando la siguiente sentencia:
MERGE into TABLA_DESTINO dest
USING TABLA_ORIGEN ori ON (dest.ID = ori.ID)
WHEN MATCHED THEN UPDATE SET a.Descripcion = b.Descripcion;
Con estos datos obtendríamos el siguiente error sobre TABLA_ORIGEN:
ORA-30926: no se ha podido obtener un juego de filas estable en las tablas de origen
- Ante este error tenemos 3 opciones:
1-. Eliminar los registros duplicados de la tabla origen:
DELETE FROM TABLA_ORIGEN WHERE id=1 AND Descripcion='El valor con id duplicado'
2-. Revisar las claves por las que hacemos la join en el merge:
Si utilizamos también el campo Descripcion en el enlace ya sólo habrá cero o un registro origen para cada destino:
MERGE into TABLA_DESTINO dest
USING TABLA_ORIGEN ori ON (dest.ID = ori.ID AND dest.Descripcion=ori.Descripcion)
WHEN MATCHED THEN UPDATE SET a.Descripcion = b.Descripcion;
(En este ejemplo no tiene mucho sentido porque la tabla son sólo estos dos campos, y además la join no encontrará coincidencias)
3-. Utilizar en lugar del MERGE un UPDATE con JOIN y el HINT /*+BYPASS_UJVC */ para saltarnos la validación del motor, y cruzar los dedos:
UPDATE /*+ BYPASS_UJVC */
( SELECT ori.ID ori_ID,
ori.Descripcion ori_Descripcion,
dest.ID dest_ID,
dest.Descripcion dest_Descripcion
FROM TABLA_ORIGEN ori, TABLA_DESTINO dest
WHERE ori.ID = dest.ID)
SET dest_Descripcion = ori_Descripcion;
Obviamente las más recomendables son la primera o la segunda, según el caso. La tercera opción, desde que la versión 11g R2 de Oracle ya no acepta el hint BYPASS_UJVC por considerarlo Deprecated, es ya totalmente desaconsejable para entornos de producción porque aunque ahora funcione por ser versiones anteriores a la 11g, las queries que incorporen este hint fallarán cuando se actualice la base de datos a una versión a partir de la 11g R2.
Otra buena opción para evitar el error ORA-30926 en operaciones de MERGE es modificar la sentencia aplicando un distinct para evitar los duplicados, o utilizando un group by y una función de agregación Min, Max o Sum, por ejemplo, sobre los campos que contengan los valores duplicados.
ORA-01555 Snapshot too old
ORA-01555 Snapshot too old il_masacratore 11 Agosto, 2009 - 16:37ORA-01555 Snapshot too old
La base de datos de una compañia normalmente tiene que aguantar algunas transacciones largas y pesadas. Si la base de datos es Oracle, está recien instalada y poco manipulada esas transacciones y sus primeras ejecuciones tienen pocas probabilidades de éxito. Es entonces cuando acaba apareciendo el fatídico ORA-01555, alias "... snapshot to old".
La gestión de consultas largas en Oracle viene limitada por el tamaño del tablespace de deshacer (undotbs). A mayor tamaño sera posible gestionar las transacciones más largas y pesadas. En Oracle 10g recien instalado el tamaño de este tablespace se reducido y uno no se suele dar cuenta hasta que falla la cosa.
Si la versión es la 10 se puede modificar directamente desde Oracle Enterprise Manager (consola web) en el apartado de administración, "Gestión de Deshacer". Allí tenemos el tiempo de retención, el tamaño del tablespace y podemos usar también el asesor para ver el tiempo de retención posible en base al tamaño en mb del tablespace.
Algo así:
En resumidas cuentas, le asignamos un tamaño mayor al tablespace que tengamos de "deshacer" y a ver si vale...
Para más información dejo aquí el Link de Oracle: https://www.oracle.com/technetwork/oramag/index.html
Ora10g: TNS-12518 Listener could not hand off client connection
Ora10g: TNS-12518 Listener could not hand off client connection il_masacratore 13 Septiembre, 2010 - 17:07
Cuando se produce este error el listener de nuestra base de datos Oracle está rechazando conexiones y no nos podemos conectar de ninguna manera con la base de datos. Para ver que está pasando podemos consultar el log del listener en /opt/oracle/product/10.2/db_1/network/log/listener.log para ver que nos cuenta el sistema. En el caso que nos ocupa podemos encontrar una entrada como la siguiente:
"TNS-12518: TNS:listener could not hand off client connection"
En el caso que me he encontrado este error puede producirse porque el número de procesos actuales de la base de datos está muy cerca del límite establecido en la configuración (por defecto 150). Inmediatamente se puede solucionar reiniciando el listener pero es recomendable revisar el valor del parámetro processes para incrementarlo. El valor máximo que le asignemos a este parámetro es trivial pero si lo modificamos debemos recalcular el valor de transacctions y sessions para que tengan en cuenta las sessiones de sistema de esta manera:
processes=x
transacctions=x*1.1
sessions=(processes*1.1)+5
Si con esto vemos que no se soluciona o queremos investigar más podemos activar la traza del listener para saber más sobre lo que acontece...
Oracle 10g - Suse Enterprise Error Consola: java.lang.Exception: Failed to get Number of users
Oracle 10g - Suse Enterprise Error Consola: java.lang.Exception: Failed to get Number of users Oscar_paredes 2 Octubre, 2007 - 12:48Este error de la consola de Oracle 10gR2 con Suse Enterprise (confirmado versión 10) hace que durante la navegación por la consola vayan apareciendo errores en la parte superior con el mensaje:
java.lang.Exception: Failed to get Number of users
La solución que puede aplicar el DBA de Oracle pasa por realizar los siguientes pasos:
- Parar la consola de Oracle:
>emctl stop dbconsole
- Ir al directorio:
>cd $ORACLE_HOME/sysman/admin/scripts
- Realizar backup del fichero osLoad.pl
- Editar el fichero osLoad.pl y cambiar las siguientes lineas:
>>> my $loadavg = NIL;
<<< my $loadavg = "0.46, 0.66, 0.61";
>>>> my $nusers = NIL;
<<<< my $nusers = 1;
- Grabar el fichero y arrancar la consola
>emctl start dbconsole
Oscar Paredes
IT Manager
Oracle DBA
certificacion SUSE
Pues si que es un incordio que nada mas instalar salga este mensaje de error. Se supone que SUSE esta certificado por Oracle para la version 10g de la base de datos, no?
Esperemos que en la proxima release ya no pase, no afecta a nada, pero no da muy buena imagen. Es una pena, porque la nueva consola esta muy conseguida y la facilidad de administracion es realmente impresionante..
- Inicie sesión para enviar comentarios
Que es una "certificacion" ?
Hace tiempo pensaba igual que tu , que una certificacion era una garantia de una "autopista de instalacion".
Pues no , una certificacion creo que en los tiempos que corren , solo quiere decir que alguien te va a escuchar via telefonica o por correo y van a tener un contrato con la empresa N para que si el producto no tira por causas del sistema operativo , todos trabajen en conjunto para llegar a la solucion.
- Inicie sesión para enviar comentarios
error de oracle 10g
Buenas noches al tratar de abrir oraclo10g me manda un error y no me permite accesar al aplicativo de antemano espero me ayuden con este error el error es el siguiente solo en algunas maquinas lo manda gracias
error (0xc0000008) error de la aplicacion la aplicacion no se ha podido inicializar correctamente
espero me ayuden de antemano gracias
- Inicie sesión para enviar comentarios
Espol
Hola a todos aquí les dejo un buen link de las estupendas carreras
ofertadas por una de las mejores universidades de Sudamérica la
Escuela Superior Politécnica del Litoral, entren y conozcan de
las diversas novedades q tienen para todos.
christian armas
- Inicie sesión para enviar comentarios
Estudiar informática
Pues para quien esté pensando en estudiar informática en España aquí dejo otro link donde gente 'con carrera' da su opinión sobre el panorama actual:
- Inicie sesión para enviar comentarios
Resolver el error “ORA-1031 – INSUFICIENT PRIVILEGES” - Oracle DBA
Resolver el error “ORA-1031 – INSUFICIENT PRIVILEGES” - Oracle DBA Oscar_paredes 1 Enero, 2007 - 22:42El error ORA-1031 - Insuficient privileges es uno de los errores más comunes que se puede encontrar un DBA de Oracle durante la conexión como SYSDBA a entornos Windows no administrados de manera cotidiana.
Además tiene la característica de que siempre aparece cuando más puede molestar ;-)
Oscar Paredes
IT Manager
Oracle DBA
Otras herramientas Oracle
Otras herramientas Oracle Dataprix 8 Septiembre, 2009 - 10:00Las suites de Business Intelligence de Oracle
Las suites de Business Intelligence de Oracle Carlos 21 Octubre, 2009 - 23:34Oracle, aparte de su famoso gestor de base de datos, dispone de un gran catálogo de productos de software, muchos desarrollados internamente y otros adquiridos mediante la compra de otras compañías. Dentro del entorno del Business Intelligence este hecho es aún más notable, ya que justamente varias de las últimas adquisiciones de Oracle han sido operaciones de compra de fabricantes de software de BI.
El resultado es que, aunque cada herramienta de BI tiene unas características y un mercado más apropiado, existen muchos solapamientos, y cuesta un poco situarse a la hora de elegir qué software o conjunto de herramientas podríamos utilizar para nuestro proyecto de Business Intelligence.
Para acabar de complicarlo hay que pensar también en las condiciones del licenciamiento y que el software suele comercializarse en suites que agrupan diferentes herramientas bajo un criterio que puede favorecernos o no.
Un buen ejemplo del efecto que esta situación puede provocar es el post Confusión con Oracle Business Intelligence, de Business Intelligence fácil
Yo tampoco soy un experto en el software BI de Oracle, pero voy a hacer un resumen de lo que conozco y me parece importante tener en cuenta de las tres suites que comercializa Oracle para Business Intelligence.
Cabe decir que este no es el único software de BI de Oracle, y que después de la adquisición de Hyperroll aún se complicará más el panorama, pero creo que con esto analizaremos las soluciones más utilizadas.
Las suites de BI Oracle siguen la nomenclatura de las diferentes ediciones de bases de datos que ya conocemos, por lo que ayuda mucho si ya estamos familiarizados con ella. Tenemos una Oracle BI Standard Edition 1 (BISE1), que es la más modesta y orientada a pymes. Después viene la Oracle BI Standard Edition (BISE), que en teoría correspondería a la versión intermedia. La versión más completa es la Oracle BI Enterprise Edition Plus (BIEE), orientada a la gran empresa.
Oracle Business Intelligence Standard Edition (BISE)
Comienzo con la BI Standard Edition porque se diferencia mucho de las otras dos. Esta suite es la que tiene más historia. Es la evolución de las clásicas herramientas de reporting de Oracle, con Discoverer a la cabeza. Es la que tiene el coste menor por usuario nominal, pero no incluye la base de datos. Utiliza IAS para proveer el acceso web a los informes y cuadros de mando.
Oracle BISE Puede encajar en entornos en los que se trabaja casi exclusivamente con Oracle, y no se quiera hacer una inversión demasiado grande para el BI o el reporting. De todas maneras, aunque Discoverer ha mejorado bastante, y ahora hasta puede funcionar en modo OLAP, creo que sigue estando lejos del nivel de herramientas de BI como BI Answers o Hyperion, que Oracle ofrece en las otras suites, y que son fruto de sus adquisiciones.
De hecho, aunque la suite se sigue comercializando, es bastante complicado encontrarla en la web de Oracle, no parece que la intención sea apostar por ella para el futuro.
Estos son los productos que incorpora:
- Oracle BI Discoverer: Acceso a los datos tanto Relacional como OLAP y cuadros de mando personalizables.
- Oracle BI Spreadsheet Add-in: Acceso OLAP a los datos desde hojas de cálculo Excel.
- Oracle BI Beans: Para construir aplicaciones de business intelligence a medida.
- Oracle Reports Services: Reporting empresarial de alto nivel de detalle.
Oracle Business Intelligence Standard Edition 1 (BISE1)
Esta es la suite más modesta, muy asequible para pymes. Incluye todo lo necesario para tener funcionando en poco tiempo un sistema de Business Intelligence. Eso si, se ha de instalar todo en un servidor, y este ha de ser un Windows Server.
La licencia no permite utilizar más de dos CPU's del servidor y sólo permite utilizar otra fuente de datos directa aparte de la BD que incluye. El licenciamiento es obligatoriamente por usuario nominal, y se pueden licenciar entre 5 y 50 usuarios. La licencia es fácilmente transformable a una Enterprise, ya que esta última incluye el software de la Standard.
La instalación de Oracle BISE1 se realiza fácilmente, y en un sólo proceso instala en el servidor la base de datos, la herramienta de ETL Oracle Warehouse Builder (la versión básica), el servidor de BI y el resto de aplicaciones.
Este servidor de BI permite acceder por web a la herramienta de reporting analítico y de cuadros de mando, tanto para diseño como para explotación. Todo este entorno viene de la adquisición de Siebel que Oracle hizo ya hace algún tiempo, y su anterior denominación era Siebel Analytics.
Es un entorno de BI muy completo y fácil de utilizar, aunque no utiliza estructuras propias de OLAP, trabaja directamente sobre el modelo Relacional de la base de datos.
Las herramientas que incluye la suite son las siguientes:
- Oracle BI Server: Acceso centralizado a los datos y motor de cálculo que se apoya en un modelo lógico de información empresarial común (nivel de abstracción de los metadatos)
- Oracle BI Server Administrator: Creación de los metadatos y niveles de abstracción
- Oracle BI Answers: Autoservicio ad-hoc que permite a los usuarios finales crear fácilmente diagramas, tablas dinámicas, informes y cuadros de mando, y navegar con capacidades de drill up/down.
- Oracle BI Interactive Dashboards: Cuadros de mando interactivos para entornos de análisis.
- Oracle BI Publisher (también conocido como XML Publisher): Reporting operacional empresarial y distribución de informes con gran nivel de detalle.
- Oracle Database Standard Edition One: Base de datos
- Oracle Warehouse Builder (core ETL): Diseño de base de datos y de extracción, transformación y carga (ETL) que ayuda a gestionar el ciclo de vida de los datos y metadatos.
El proceso básico para llegar a crear informes analíticos o dashboards con esta suite sería:
- Diseño de la ETL y creación de estructuras dimensionales en tablas con OWB
- Definición de metadatos y capas Física, de Negocio y de Presentación con Oracle BI Server Administrator
- Creación de informes analíticos y cuadros de mando con BI Answers e Interactive Dashboards
Para crear y distribuir informes operacionales se puede utilizar de manera autónoma BI Publisher.
Los informes se diseñan con Microsoft Word o Adobe Acrobat (instalando un add-in) y después también se pueden publicar y editar mediante servidor web WebDav.
Este software, aunque se integra con el portal de BI Dashboards es propio de Oracle, y es un poco más engorroso de utilizar. No se suele usar a menos que existan necesidades específicas que no se puedan solucionar con BI Answers.
Se puede obtener más información sobre Oracle BISE1 en la sección del producto de la web de Oracle.
Para aprender en poco tiempo cómo empezar a trabajar con esta suite, con el apoyo de esquemas de ejemplo que se cargan al instalar el producto, recomiendo especialmente seguir el Tutorial de Oracle Business Intelligence Edition One.
Oracle Business Intelligence Enterprise Edition Plus (BIEE)
Esta es la suite orientada a la gran empresa y a trabajar con múltiples orígenes de datos.
Está compuesta por todas las herramientas de Oracle BISE1 (exceptuando la base de datos) más algunas complementarias aplicables al mismo entorno, y que amplian la funcionalidad de la misma con utilidades de CPM, monitorización y alertas o para poder utilizar las funciones analíticas en modo desconectado.
[[ad]] Lo del Plus viene por el software de Hyperion, que se ha añadido para ampliar más aún la funcionalidad disponible, sobretodo en cuanto a utilidades de Reporting Financiero, una de sus mejores bazas. Este software funciona muy bien en modo OLAP, aunque para ello necesita apoyarse en un motor multidimensional, y Oracle BI Server no lo es, aunque con la versión empresarial sí que se pueda conectar a motores OLAP y otros tipos de orígenes de datos .
En todo caso, para sacar el máximo partido a las aplicaciones de Hyperion lo más indicado es disponer de o adquirir también una base de datos MOLAP como Essbase. También se pueden utilizar otros orígenes Multidimensionales como SAP BW, o Microsoft OLAP.
Si la suite se licencia por usuarios el mínimo es 50, y también se puede licenciar por procesador. No está limitada en cuanto a número de orígenes de datos, usuarios o CPU's más que por el presupuesto disponible.
Como contiene todas las aplicaciones de la versión BISE1, especialmente el servidor de BI, el paso de la versión más modesta a la Enterprise es inmediato, aunque si se quieren utilizar las aplicaciones de Hyperion la cosa se complica un poco más.
Este es el listado de aplicaciones que la componen: (marco en gris las que también forman parte de Oracle BISE1)
- Oracle BI Server: Acceso centralizado a los datos y motor de cálculo que se apoya en un modelo lógico de información empresarial común (nivel de abstracción de los metadatos)
- Oracle BI Server Administrator: Creación de los metadatos y niveles de abstracción
- Oracle BI Answers: Autoservicio ad-hoc que permite a los usuarios finales crear fácilmente diagramas, tablas dinámicas, informes y cuadros de mando, y navegar con capacidades de drill up/down.
- Oracle BI Interactive Dashboards: Cuadros de mando interactivos para entornos de análisis.
- Oracle BI Publisher (también conocido como XML Publisher): Reporting operacional empresarial y distribución de informes con gran nivel de detalle.
- Oracle BI Delivers: Alertas y monitorización proactivas de la actividad del negocio.
- Oracle BI Disconnected Analytics: Funcionalidad analítica completa en modo desconectado para profesionales 'móbiles'. Utiliza técnicas de replicación.
- Oracle BI Briefing Books: Instantáneas de páginas de cuadros de mando para visualizar y compartir en modo desconectado.
- Hyperion Interactive Reporting: Reporting ad-hoc intuitivo e interactivo.
- Hyperion SQR Production Reporting: Generación de informes con formatos de presentación de alta calidad, preparado para trabajar con grandes volúmenes
- Hyperion Financial Reporting: Reporting financiero y de gestión con formateado en 'calidad de libro'
- Hyperion Web Analysis: Análisis, presentación y reporting OLAP basado en web
Más información en la librería de documentación online de BIEE.
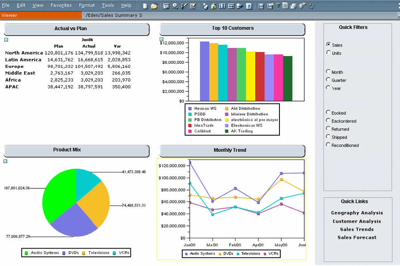
Finalmente, comentar que en cuanto a los procesos de ETL, para trabajar con Oracle BIEE lo habitual es adquirir también Oracle Data Integrator ya que esta ETL está preparada para trabajar con diferentes aplicaciones y orígenes o destinos de datos, y en proyectos que utilicen la versión empresarial éste suele ser el caso.
Oracle Warehouse Builder funciona bien y se puede utilizar libremente si se tiene alguna licencia de base de datos, pero está bastante limitado en cuanto a conectores con diferentes orígenes de datos empresariales, y el destino ha de ser siempre una base de datos Oracle.
Además las referencias a OWB también están comenzando a desaparecer de las listas de productos de la web de Oracle.
De hecho pasan cosas curiosas como que si sigues un enlace a Warehouse Builder ( https://www.oracle.com/us/solutions/ent-performance-bi/index.html) te redirigen directamente a la sección de Oracle Data Integrator (https://www.oracle.com/us/products/middleware/data-integration/index.html), lo cual nos da una buena pista de la ETL de Oracle que va a evolucionar más.
Ficheros como origen de datos en OWB
Ficheros como origen de datos en OWB cfb 24 Diciembre, 2007 - 18:46Tengo instalado un Oracle Warehouse Builder que está configurado 'a tres capas', con un Windows Server como BD servidora-repositorio principal, una BD destino sobre LINUX, y el cliente del Centro de Diseño un windows XP.
He definido un origen de datos de fichero y para la conexión, en la ubicación de archivos he especificado un directorio que 've' la máquina XP.
Esto me permite hacer todo correctamente, hasta que quiero iniciar la carga, momento en que el centro de control me devuelve el siguiente error:
Y:\Dimensiones\Geografia\CARGA_POBLACIONES.ctl (El sistema no puede hallar la ruta especificada)
Supongo que el problema es que hay que definir el origen del fichero con un path al que se pueda acceder desde el servidor del repositorio, o el de destino.
Estoy en lo cierto? Con copiar los archivos a uno de estos servidores tendría suficiente para poder preparar la carga?
Gracias por anticipado,
Los ficheros origen de OWB han de estar en el servidor
Pues sí, he probado a crear un directorio en el servidor donde tengo el repositorio de Warehouse Builder, he creado una nueva ubicación de archivo especificando este path, lo he asociado al módulo del fichero, y al ejecutar la carga ya funciona correctamente.
Problema solucionado!
- Inicie sesión para enviar comentarios
Buenas , y como has creado
Buenas , y como has creado una ubicacion de una maquina unix o windows , porque a mi no me deja crear ubicaciones de fichero nada mas que en mi maquina windows y no me deja entrar en unix para definirla
- Inicie sesión para enviar comentarios
Crea el directorio
Crea el directorio directamente desde el sistema en lugar de intentarlo desde dentro de OWB.
Utiliza la linea de comandos con una conexión SSH o algo así y el comando
>mkdir nombre_directorioDespués seguro que desde Warehouse Builder puedes seleccionar la ubicación.
- Inicie sesión para enviar comentarios
Instalacion de Oracle Workflow
Instalacion de Oracle Workflow cfb 16 May, 2008 - 22:48Para poder organizar y poder definir y automatizar flujos de proceso con los mappings de OWB hay que utilizar Oracle Workflow.
En teoría la instalación es muy sencilla, pero yo estoy teniendo bastantes problemas. Alguien conoce una guía sobre cómo hacerlo sobre un Linux?
Tampoco me aclaro mucho sobre las diferentes versiones que hay. Oracle lo tiene en su web directamente como producto Oracle Workflow Server, o como parte de la base de datos 10g, en el companion CD, aparte de la versión que viene embedida en Oracle E-Business Suite, que no sé si se corresponde a alguna de las anteriores o es otra 'especial'.
Además está la opción 'stand alone' y la 'middle tier', que no sé exactamente en qué consisten cada una, ni cómo decidir cuál quiero, pero me conformo con una que me funcione en la misma base de datos, y con el Warehouse Builder que tengo también en el mismo servidor, no necesito acceder por web.
Alguien sabe cómo lo tendría que hacer?
Como aún no he conseguido
Como aún no he conseguido instalar OWF en Linux sobre una SLES, he optado por hacerlo sobre un windows server 2003 que utilizo como entorno de desarrollo. Tal como sospechaba no he tenido ningún problema especial.
He instalado una BD Oracle 10g con la configuración estándar, y después he realizado la instalación del Oracle Workflow que se encuentra en el Companion CD del software de instalación de la base de datos.
Primero el asistente realiza la instalación del software sobre el home de la BD anterior, y después hay que ejecutar el configurador. Lo único que puede ser menos intuitivo es que donde hay que indicar el 'Descriptor de Conexion TNS' no sirve poner el SID de la instancia de la Base de datos, hay que poner el descriptor completo, tal como lo
haríamos en el TNSNAMES (recomiendo hacerlo en una única linea, ya que los saltos de linea pueden dar problemas):
(DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST =servidor)(PORT = 1521)))(CONNECT_DATA = (SERVER = DEDICATED)(SERVICE_NAME = owfbd)) )
Tras poner correctamente esta cadena todo ha funcionado perfectamente, ahora sólo falta descubrir cómo hacerlo para completar sin errores la ejecución de este instalador en Suse Linux Enterprise Server.
Realmente, a nivel general, con este SO certificado por Oracle me estoy encontrando demasiados problemas de instalación, y poca documentación. Esperemos que la cosa vaya mejorando..
- Inicie sesión para enviar comentarios
Instalacion de OWB
Por fin he podido instalar Oracle Workflow sobre Linux, y he visto que el problema no venía del SO (SLES) sino de la versión de OWF. Resulta que la base de datos es una Oracle 10g R2, y el instalador de OWF que yo utilizaba era la versión 2.6.3, y esta sólo va bien para la Release 1. Al instalar la versión 2.6.4 de Workflow todo ha ido perfectamente. Por si alguien se encuentra en la misma situación nota importante:
- Oracle Workflow 2.6.3 se instala sobre una base de datos Oracle Database 10g Release 1 (10.1.x.x)
-
Oracle Workflow 2.6.4 se instala sobre una base de datos Oracle Database 10g Release 2 (10.2.x.x)
Tras la instalación, antes de poder desplegar el primer flujo de procesos me ha vuelto a surgir algun problemilla que se resuelve rápidamente, pero que reproduzco para facilitar la vida al próximo que se lo encuentre:
El idioma español no está activado en el repositorio de workflow.
RPE-02072: No se ha activado el idioma NLS E de Oracle Workflow en el repositorio de Oracle Workflow. Actívelo utilizando el archivo de comandos del servidor wfnlena.sql de Oracle Workflow.
Siguiendo las indicaciones del mismo mensaje de error se soluciona el tema. En mi caso el script estaba en D:\oracle\product\10.2.0\db\wf\admin\sql, se ha de buscar en el directorio de instalación de la BD donde tengamos el repositorio de OWF.
Desde SQLPLUS, con el usuario OWF_MGR (propietario del repositorio) se ejecuta wfnlena.sql, y ya se puede desplegar correctamente:
E:\oracle\product\10.2.0\db\wf\admin\sql>sqlplus owf_mgr/pwd@owfdb @wfnlena 'E' 'Y'
'E' --> Idioma español
'Y' --> YES, para marcarlo como activado
Si no te apetece buscar donde está el script, puede ser más sencillo entrar en la BD con el usuario de workflow y simplemente ejecutar este update:
SQL>update WF_LOCAL_LANGUAGES set
INSTALLED_FLAG = 'Y'
where CODE = 'E';
Privilegios insuficientes para crear dblinks.
ORA-01031: privilegios insuficientes
RPE-02207: No se puede crear el enlace de base de datos DWH.DATAPRIX.COM@WB_LK_STG en el usuario de ubicación OWF_MGR. Consulte la excepción mostrada para obtener más información, asegúrese de que se ha otorgado el privilegio del sistema 'CREATE DATABASE LINK' y vuelva a intentarlo.
Esto se soluciona abriendo una sesión en la base de datos del workflow con el usuario de sistema, y otorgando el permiso a mi usuario de workflow:
SQL> GRANT CREATE DATABASE LINK TO "OWF_MGR";
Otros detalles
Por último, recordar que cuando se crea el usuario del workflow en el entorno de OWB hay que quitar la selección de la opción 'Used as target schema?', ya que este usuario no es de destino.
Otro detalle importante, pero sólo si Oracle Workflow se instala en una BD diferente a la que se utiliza para Oracle Warehouse Builder, es que el usuario de Workflow (en mi caso OWF_MGR) que se crea en el entorno de OWB ha de tener el mismo PWD que el usuario OWF_MGR de la BD donde se ha instalado Oracle Workflow.
- Inicie sesión para enviar comentarios
Me han sido de gran ayuda
Me han sido de gran ayuda vuestros posts sobre el OWF, pero ahora al usarlo necesito acceder al Oracle Workflow Manager, que está como opción en el companion CD (OWF middle tier). Pero no hay manera de que se deje instalar. Alguien lo ha instalado alguna vez con éxito ??
- Inicie sesión para enviar comentarios
Finalmente la solución ha
Finalmente la solución ha sido muy sencilla y es la de no usar el instalador que viene con el Companion CD de Oracle sino usar el que setup.exe del oracle que ya tenemos instalado,
$ORACLE_HOME$\oui\bin
luego le indicamos desde donde queremos instalar, por ejemplo
\Oracle 10 Installer\10201_companion_win32\companion\stage\products.xml
Lo instalamos en un nuevo HOME
Y listo
Como curiosidad comentar que el botón para matar un proceso se encuentra "oculto" teniendo que ir a la opción de ver diagrama para encontrarlo.
Espero que sea de ayuda.
- Inicie sesión para enviar comentarios
Me alegro de que hayas podido
Me alegro de que hayas podido instalarlo.
Gracias por comentar cómo lo has conseguido, seguro que va a ser útil para alguien más..
- Inicie sesión para enviar comentarios
Estimados, me pueden ayudar
Estimados, me pueden ayudar con la instalación de Workflow, estoy en un ambiente Windows7 ... tengo instalada la BD ORACLE STANDAR 11.2.0.1 g
DENTRO de la casa de OWB en el siguiente directorio se encuentra el asistente de configuración Worflow
D:\app\Kiuby\product\11.2.0\dbhome_1\owb\wf\install\wfinstall.bat
Una ves abierto me sale la pantalla q carlos mostro:
que datos tengo q poner ahi:
Opción de Instalación: Solo Servidor
Cuenta de Workflow: owf_mgr ---> esta cuenta es por defecto o tengo q crear el usiario en el asintente de warehouse builder ???
En descripción de conexion TNS: SOLO EH PUESTO ASI: localhost:1521:orcl
o tengo q especificar todo como ah puesto carlos
DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST =servidor)(PORT = 1521)))(CONNECT_DATA = (SERVER = DEDICATED)(SERVICE_NAME = owfbd)) )
tengo el siguiente error: java.lang.Exception:Invalid connection (0)
ayuda por favor
- Inicie sesión para enviar comentarios
Hace mucho que no lo toco, y
Hace mucho que no lo toco, y te hablo de memoria, pero la cuenta debe existir en la base de datos.
Lo que es seguro es que has de poner la cadena completa del descriptor de conexión TNS, seguramente por eso no te conecta, porque la descripción es incorrecta.
- Inicie sesión para enviar comentarios
Gracias Carlos eh puesto ya
Gracias Carlos
eh puesto ya el descriptor pero tengo el mismo problema, una duda al conectarme con el usuario owf_mgr por sqlplus me dice q el usuario no existe, estoy un poco confundido
ese usuario se me crea automáticamente al instalar el motor de BD con la Base orcl,o como?
eh visto en algunos blogs aconsejan que debo sacar el instalador de worflow fuera de la casa de owb pero no estoy seguro
ayuda
- Inicie sesión para enviar comentarios
Lo eh solucionado despues de
Lo eh solucionado despues de romperme un poco la cabeza
revisando uno de los log de worflow ubicados en:
D:\app\Kiuby\product\11.2.0\dbhome_1\owb\wf\install\ nombre_del_archivo.log
me encontre con este error ORA-00604: error occurred at recursive SQL level 1
ORA-12705: Cannot access NLS data files or invalid environment specified
este error se debe
En mi caso, el problema se da cuando tengo el sistema operativo -y el conjunto de caracteres- configurado para Ecuador. Para solucionarlo en las aplicaciones Java, podemos agregar opciones para configurar el locale que queremos que la JVM utilice, de forma que no tome el del sistema operativo. Esto se hace agregando las siguientes opciones al ejecutar el comando java:
-Duser.region=us -Duser.language=en
Una 2da opción, válida en Windows es cambiar la configuración regional y de idioma para algún país que Oracle soporte (Estados Unidos, España, México, etc.). Hay que tener en cuenta sin embargo que esta configuración nos puede afectar otros programas, especialmente en la configuración de moneda, formato de fecha o de separación de miles. ---> esta es la q aplique
En concreto la solución esta en ir a panel de control\configuracion regional y idioma\cambiar formato\ podemos escojer la opcion ingles reino unido
ejecutar nuevamente el instalador dbhome_1\owb\wf\install\wfinstall.bat
poner los parametros y listo
espero que le sirva al alguien :D
- Inicie sesión para enviar comentarios
Me alegra que hayas podido
Me alegra que hayas podido solucionarlo, la configuración regional es algo que siempre da algún problema como no esté todo perfecto.
Te agradezco que compartas la solución que has encontrado, y seguro que no soy el único que te lo va a agradecer.
Saludos,
- Inicie sesión para enviar comentarios
Lanzamiento de Oracle Data Integrator
Lanzamiento de Oracle Data Integrator Carlos 26 Septiembre, 2007 - 23:02Oracle, tras la compra de la empresa Sunopsis, ha lanzado al mercado la nueva herramienta Oracle Data Integrator (ODI), basada en la que comerciaba esta compañía.
Esta herramienta entra en el segmento de las de E-LT, o de Extracción, Carga y Transformación (una evolución del concepto de ETL), y aporta más flexibilidad, mayor capacidad de integración con diferentes fuentes y destinos de datos, y realiza los procesos de transformación dentro de los mismos servidores de bases de datos, de ahí el cambio en el orden de las siglas E-LT, al realizarse así el proceso de Transformación normalmente después que el de Carga.
Se puede consultar más información sobre la misma en Lanzamiento de Oracle Data Integrator.
Con esta noticia queda claro porqué Oracle Warehouse Builder se puede utilizar libremente desde hace ya un tiempo si se ha adquirido la licencia de algún servidor de base de datos Oracle. Tenemos una nueva herramienta que nos va a hacer plantearnos si OWB se ha quedado obsoleto. Ahora sólo falta evaluar hasta qué punto las mejoras que aporta el nuevo software compensan el coste de adaptación y de la licencia.
Limpieza de datos con Oracle Warehouse Builder
Limpieza de datos con Oracle Warehouse Builder Carlos 4 May, 2007 - 22:13En el enlace Managing Data Quality se puede acceder a un artículo de Ron Hardman sobre cómo realizar procesos de limpieza de datos con Oracle Warehouse Builder.
El artículo comienza con una introducción a la calidad de los datos y maneras de gestionarla, siendo una de ellas la utilización de las opciones de limpieza de datos de Oracle Warehouse Builder.
Lo interesante es que se muestra cómo descargar un script con datos de prueba, y cómo configurar la herramienta para probar las utilidades de Profiling, definición de Reglas (Data Rules), y corrección o limpieza de los datos. De esta manera se puede ver y probar de manera sencilla cómo implementar un proceso básico de Data Cleansing con esta herramienta.
El artículo original está en inglés pero buscando en la web de Oracle he encontrado los 3 documentos que adjunto, traducidos al castellano, y relacionados con OWB y la limpieza de datos:
- Informe Ejecutivo - Oracle Warehouse Builder 11g Versión 1 Información General
- Oracle Warehouse Builder Data Quality Option
- Oracle Warehouse Builder Enterprise ETL Option
Oracle BI Publisher
Oracle BI Publisher Juan_Vidal 22 Junio, 2011 - 00:08Mostramos a continuación un resumen de capacidades de esta herramienta integrada en la suite de B.I. de Oracle incluyendo las funcionalidades incluídas en la versión 11g.
Existe también la versión standalone XML Publisher Enterprise independiente de la suite de Oracle.
Oracle BI Publisher permite publicar y distribuir informes en al ámbito del Reporting operacional empresarial con gran nivel de detalle. Estos informes pueden ser creados desde el mismo portal (editor DHTML). Cuenta con una interfaz gráfica que facilita enormemente el trabajo. A nivel de SQL, permite escribir las sentencias directamente o ayudarse de un Query Builder. Una gran ventaja de la herramienta es que el diseño del informe puede estar basado en plantillas realizadas con Microsoft Word, Excel o Adobe Acrobat.
Oracle BI Publisher ofrece también soporte para Adobe Flex, de forma que se pueden crear plantillas en Flex, formato que permite crear informes y formularios interactivos. BI Publisher separa la creación de los datos (XML) del proceso de formateo. El motor puede tratar cualquier dato XML, permitiendo la integración con cualquier sistema que genere XML, como servicios web o cualquier fuente de datos JDBC.
BI Publisher puede fusionar diferentes fuentes de datos en un único documento de salida. En cuanto a distribución de informes cuenta con un planificador que nos permite programar el envío del informe. Como posibles plataformas de distribución tenemos fax, impresora, mail y publicarse en el portal. De igual forma permite múltiples formatos de salida puede ser: pdf, rtf, html, xml ,xls, etc..
BI Publisher está basado en el estándar W3C XSL-FO. Es una aplicación J2EE que puede ser desplegada en cualquier contenedor J2EE.
Como resumen una gran alternativa para poder publicar cualquier tipo de informe de alta fidelidad.
Hola, es de pago esta
Hola, es de pago esta herramienta ??
- Inicie sesión para enviar comentarios
La herramienta está integrada
La herramienta está integrada dentro de la suite de Business Analytics de Oracle.
- Inicie sesión para enviar comentarios
Oracle Data Integrator 11g
Oracle Data Integrator 11g Juan_Vidal 7 Septiembre, 2011 - 11:38Oracle Data Integrator es la herramienta de integración de datos de Oracle. Es la apuesta de Oracle en cuestiones de integración de datos y sustituye a OWB (Oracle Warehouse Builder). Forma parte de la solución OFM (Oracle Fusion Middleware) y está totalmente integrada con otras soluciones Oracle relacionadas con la gestión de datos:
- Oracle Data Profiling
- Oracle Exadata
- Oracle Business Intelligence
- Oracle SOA Suite
- Oracle Database
- Oracle Data Warehousing
- Oracle Master Data Management
Repasamos brevemente las principales funcionalidades y novedades de la versión 11 de esta herramienta:
.jpg)
Conectividad:
La actual versión 11g, permite una extensa conectividad con la mayoría de las bases de datos, ERPs, CRMs, sistemas B2B, ficheros planos, ficheros XML, directorios LDAP, conexiones vía ODBC, JDBC y una muy conseguida integración con arquitecturas SOA.
Funcionalidades de integración de datos:
ODI simplifica bastante todas las tareas de integración y gestión de datos caben destacar los siguientes puntos:
- Población y actualización entornos Data Warehouse: Ejecución de procesos con alto volumen de datos, obteniendo excelentes tiempos de respuesta. Actualización de data warehouses, data marts, cubos OLAP y sistemas analíticos en general. Gestiona de forma transparente las cargas totales o incrementales, considera dimensiones SCD (Slowly Changes Dimensions), asegura la integridad y consistencia de datos y facilita la trazabilidad del dato (origen del dato, detalle de transformaciones y destino del dato). Procesos de integración de datos basados en datos de entrada, procesos batch, eventos y ejecución de servicios.
- Arquitecturas Orientadas a Servicios (SOA): Permite desarrollar servicios de integración de datos (acceso a datos, validaciones, transformación, volcado de datos, etc.) para su posterior integración de forma poco costosa en infraestructuras basadas en arquitecturas SOA, dotando a esta infraestructura de capacidades para gestionar altos volúmenes de datos, alto rendimiento en los procesos y volcados de datos masivos.
- Master Data Management (MDM): Facilita la gestión de datos maestros con funcionalidades para la sincronización de datos. Permite la conexión entre los datos maestros y el Data Warehouse, asegurando la integridad entre las dimensiones y jerarquías MDM y las tablas de hechos del Data Warehouse. Actualización de MDM data hubs (concentradores de datos con tablas de referencias cruzadas a todos los sistemas fuente) para cada uno de los dominios de los maestros de datos (ejemplo : cliente, producto, etc..). Integración con procesos BPEL (Business Process Execution Language)y los servicios webs compuestos por este lenguaje de orquestación.
- Procesos de migración de datos: Gestiona volcados de datos masivos entre sistemas antiguos y los nuevos sistemas de forma eficiente, pudiendo incluir en el movimiento de datos transformaciones complejas, así como la sincronización de datos entre ambos sistemas durante su periodo de coexistencia.
Arquitectura E-LT:
ODI modifica el tradicional concepto ETL (Extract, Transform, Load), pasando a E-LT (Extract – Load, Transform). La arquitectura E-LT extrae los datos de los sistemas fuente, los carga en base de datos y realiza todas las transformaciones en la propia base de datos. En el tradicional ETL el proceso de transformación puede ser realizado en un entorno hardware y software diferente al de la base de datos de destino, mientras que en un esquema E-LT la transformación y el volcado se realizan en una misma plataforma hardware y software. Lógicamente un esquema E-LT reduce el tráfico de datos, pero hay que dotar al motor de la base de datos de destino de capacidades de transformación y movimiento de datos potentes, capacidades que provee ODI. Así mismo, ODI permite realizar dentro de la base de datos transformaciones complejas al mismo nivel que el servidor que realiza la capa de transformación en un ETL convencional.
Considerar igualmente que una arquitectura E-LT se realiza toda la optimización de recursos (disco, memoria, proceso) en la base de datos, lo cual permite una configuración del rendimiento más centralizada. La propia ejecución de las transformaciones puede ser diferente en una arquitectura y otra, ya que hay herramientas ETL que evalúan las transformaciones registros a registro y en el caso E-LT se realiza por lotes de registros. ODI permite combinar la potencia del motor de la base de datos con las prestaciones hardware que Oracle puede ofrecer alcanzando una arquitectura E-LT de alto rendimiento.
Alta productividad en el diseño de procesos de integración de datos:
ODI introduce un entorno de desarrollo basado en JDeveloper que reduce los tiempos de desarrollo y permite diseñar de forma intuitiva procesos de transformación y volcado de datos complejos. Nuevas funcionalidades como ‘quick-edit’ implementan de forma sencilla actualizaciones masivas.
Uno de los principales objetivos de ODI es centrar a los desarrolladores y a los usuarios de negocio en describir las transformaciones a realizar, sin necesidad de invertir mucho tiempo en los aspectos técnicos relativos a la implementación de estas transformaciones. ODI plantea al desarrollador un diseño declarativo más centrado en las necesidades de transformación que en los procedimientos. Permite centrarse en ‘qué hacer’, en lugar de ‘cómo hacer’. El diseñador describe las fuentes origen y destino y los procesos de transformación e integración, ODI genera los procedimientos y el código necesario para implementarlos.
Alta disponibilidad y escalabilidad:
ODI se integra con la plataforma Oracle Fusion Middleware. En esta plataforma ODI ofrece sus componentes como aplicaciones Java EE, optimizados para aprovechar al máximo las capacidades de su servidor de aplicaciones Oracle WebLogic. Los componentes ODI están provistos de funcionalidades que permiten su despliegue en un entorno de alta disponibilidad, escalabilidad y seguridad. Los componentes de ODI desplegados en el servidor de aplicaciones WebLogic se benefician de las funcionalidades de este en cuestiones relativas a escalabilidad, pooling de conexiones JDBC y balanceo de carga de trabajo. Igualmente ODI puede beneficiarse de las capacidades de trabajo de bases de datos en grupo (clusters, grupos de máquinas) que permite Oracle RAC (Real Application Clusters), con todas las capacidades que conllevan un motor de base de datos de alta disponibilidad de estas características.
Gestión y administración centralizadas (consola ODI):
La consola de ODI se realiza en un entorno bajo un framework Ajax que mejora la experiencia de usuario (ADF Oracle Application Development Framework). Desde esta consola se pueden crear entornos de trabajo, realizar exports e imports de repositorios de datos, controlar procesos, monitorizar sesiones, control y seguimiento de errores, diseñar procesos, realizar informes de trazabilidad, etc..
Esta interfaz se integra con la Enterprise Manager Fusion Middleware Control y permite a los administradores monitorizar no sólo los componentes de integración de datos ODI, sino todos los componentes de la plataforma Oracle Fusion Middleware.
ODI Knowledge Modules:
Los Knowledge Modules son el núcleo de la arquitectura ODI. Proveen a la arquitectura Oracle de flexibilidad, modularidad y fácil ampliación. Soportan plataformas de terceros, heterogéneas fuentes de datos y data warehousing appliances. Los KM implementan los flujos de datos y definen plantillas para generación de código involucrando diferentes sistemas y plataformas. Los KM permiten la creación de flujos de datos sin que la complejidad de las reglas de transformación cambie su diseño. Por otro lado, son muy específicos ya que los procesos y el código generado están orientados y optimizados a la tecnología de base con la que se integran. ODI dispone de una librería de módulos KM para adaptarlos a medida definiendo unas mejores prácticas.
Lista de KM disponibles:
Generic SQL,Hypersonic SQL,IBM DB2/400, DB2 UDB, Informix, JD Edwards Enterprise One, JMS, Microsoft Access, Microsoft SQL, Netezza, Oracle Database, Oracle Data Quality for Data Integrator, Oracle E-Business Suite, Oracle Enterprise Service Bus, Oracle GoldenGate, Oracle Hyperion Essbase, Financial Management, Planning, Oracle OLAP, Oracle PeopleSoft , Oracle Siebel CRM , SalesForce, SAP ERP & BW , SAS, Sybase ASE, Sybase IQ y Teradata.
Información más extensa sobre la herramienta en la propia site de productos de Oracle: 'https://is.gd/lY8xD9'
Hola Paty, No soy experto en
Hola Paty,
No soy experto en temas de hardware, pero necesito más datos para responderte. Dimensionar ODI depende de muchos factores:
- Tamaño de la BBDD
- Volumen de procesos ETL a generar (espacio metadata)
- Disposición de servidores: servidor de metadatos, servidor de ejecución, servidor de BBDD,...
- Necesidad de recursos en ejecución: paralelismo, necesidad de caché
Un saludo,
- Inicie sesión para enviar comentarios
Oracle SQL Developer
Oracle SQL Developer Carlos 30 Abril, 2008 - 23:55Oracle SQL Developer es la herramienta gráfica gratuita que proporciona Oracle para que no sea necesario utilizar herramientas de terceros (como el conocido TOAD, o el PL/SQL Developer) para desarrollar, o simplemente para ejecutar consultas o scripts SQL, tanto DML como DDL, sobre bases de datos Oracle.
La apariencia y funcionalidad es similar a la de otras herramientas de este tipo, por lo que es una buena opción si no tenemos especial predilección por otras herramientas.
Además, en las últimas versiones ha incorporado mejoras como permitir conectar con bases de datos no Oracle, como SQLServer, MySQL o Access. La conexión con MySQL o SQLServer se realiza a través de JDBC, y de manera bastante sencilla. Una vez establecida la conexión se pueden explorar los objetos de las bases de datos como si se tratara de una de Oracle, y ejecutar sobre ellas sentencias SQL, aunque en cuanto a funcionalidades más avanzadas como la creación de estructuras este tipo de conexión estará mucho más limitada.
Se puede consultar más información o descargar la herramienta en www.oracle.com/technology/software/products/sql/index.html

Cómo conectar Oracle SQL Developer con MySQL
A modo de ejemplo comentaré los sencillos pasos que se pueden seguir para poder utilizar SQL Developer con una base de datos MySQL:
- Descargar y descomprimir el driver JDBC para MySQL, que se puede obtener en la zona de descargas de conectores de la web de MySQL.
- En el directorio generado localizar el archivo .jar, que es el binario que contiene el conector. El nombre ha de ser algo así como 'mysql-connector-java-...-bin.jar'. Esta prueba está hecha con la versión 5.1.7, pero mejor descargar la más reciente.
- En la opción de menú Herramientas, entrar en Preferencias.. y abrir las opciones de Base de datos y seleccionar Controladores JDBC de Terceros. Hacer click sobre el botón Agregar Entrada, y con el explorador de archivos seleccionar el archivo .jar que hemos descargado.
- Después de esto, en la ventana que se abre al agregar conexiones os debería aparecer una nueva pestaña MySQL que permite definir una conexión con MySQL.
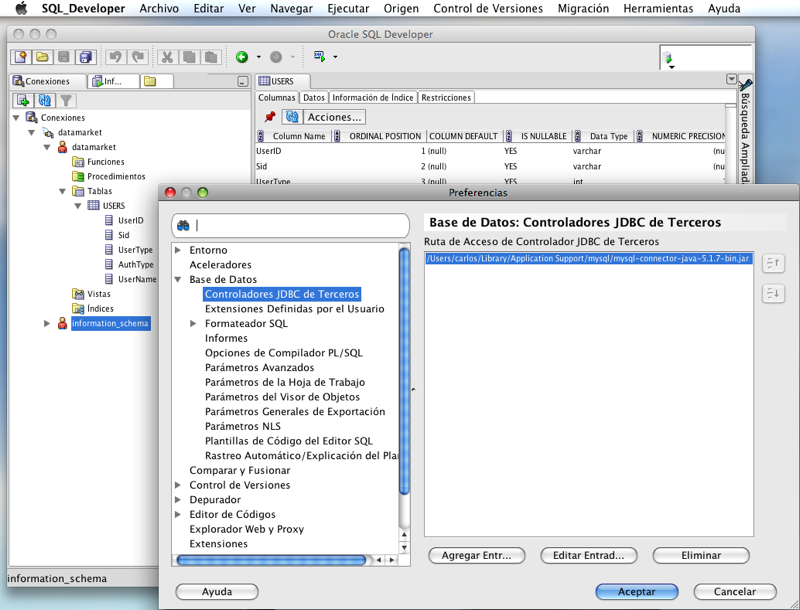
Cómo conectar Oracle SQL Developer con SQL Server y Sybase
Comento también los pasos que se pueden seguir para poder utilizar SQL Developer con una BD SQL Server o Sybase, aunque lo único que cambia es el driver que se utiliza:
- Descargar y descomprimir el driver JDBC para SQL Server/ Sybase. El proyecto open source jTDS proporciona un driver que sirve para ambas bases de datos. Sólo hay que seleccionarlo de la sección de Download
- En el directorio generado localizar el archivo .jar, que es el binario que contiene el conector. El nombre ha de ser algo así como 'jtds-... .jar'. Para que lo tengáis aún más fácil adjunto la versión 1.2.3, que es la que yo he utilizado ahora.
- En la opción de menú Herramientas, entrar en Preferencias.. y abrir las opciones de Base de datos y seleccionar Controladores JDBC de Terceros. Hacer click sobre el botón Agregar Entrada, y con el explorador de archivos seleccionar el archivo .jar que hemos descargado.
- Después de esto, en la ventana que se abre al agregar conexiones os debería aparecer una nueva pestaña SQLServer que permite definir una conexión con SQL Server.
Espero que te haya parecido útil!
Oracle SQL Developer
Oracle SQL Developer Carlos 18 May, 2009 - 10:54En el artículo Oracle SQL developer comentábamos la existencia del software Oracle SQL Developer, la herramienta gratuita de Oracle, que te permite conectar y trabajar a nivel de SQL, desarrollo y de estructura sobre bases de datos tanto Oracle como de otros fabricantes a las que se pueda conectar por JDBC (SQLServer o MySQL, por ejemplo).
Abrimos este tema en el foro para comentar y recopilar temas de instalación, funcionamiento o simplemente opiniones sobre Oracle SQL Developer.
Libros de Administración Oracle (DBA) y PL/SQL
¿Quieres profundizar más en PL/SQL de Oracle o en administración de bases de datos Oracle? Puedes hacerlo consultando alguno de estos libros de Oracle.
Los libros que ves a continuación son una selección de los que a mi me parecen más interesantes para aprender administración y desarrollo PL/SQL, teniendo en cuenta precio y temática, espero que te puedan ser de utilidad:
- eBooks de Oracle gratuítos para la versión Kindle, o muy baratos (menos de 4€):
- Libros recomendados de Oracle
Va de coña!
Me lo acabo de instalar, lo estoy probando y va estupendo!! Gracias por el post Carlos!! Drk
- Inicie sesión para enviar comentarios
Amigo por lo que pude leer
Amigo por lo que pude leer en su vinculo, pense que me puede ayudar, disculpeme la molestia, lo que pasa es que el SQL developer me pide eñ PATHNAME para JAVA.EXE, soy muy novato y no se que hacer, me puede ayudar?
- Inicie sesión para enviar comentarios
Por cierto..
Si teneis problemas a la hora de establecer conexiones es porque debéis configurar el fichero "sqldeveloper.conf" y agregar lo siguiente:
AddJavaLibFile ../../lib/java/api/jaxb-api.jar
AddJavaLibFile ../../lib/java/api/jsr173_api.jar
AddJavaLibFile ../../j2ee/home/lib/activation.jar
AddJavaLibFile ../../lib/java/shared/sun.jaxb/2.0/jaxb-xjc.jar
AddJavaLibFile ../../lib/java/shared/sun.jaxb/2.0/jaxb-impl.jar
AddJavaLibFile ../../lib/java/shared/sun.jaxb/2.0/jaxb1-impl.jar
Saludos,
- Inicie sesión para enviar comentarios
Hola, gracias, yo tengo
- Inicie sesión para enviar comentarios
Yo lo he utilizado y,para mi
Yo lo he utilizado y,para mi es mejor que el TOAD.
- Inicie sesión para enviar comentarios
TOAD vs Oracle Developer
Yo creo que está bien, sobretodo teniendo en cuenta que no hay que pagar por él, pero encuentro que le pasa lo que a la mayoría de los programas hechos con JAVA, que se nota un poco la lentitud. Con el TOAD la respuesta a cada click es instantánea, aparte de que tiene bastantes más opciones, por lo menos la versión de pago.
- Inicie sesión para enviar comentarios
Conectar con Oracle 8i
Es posible conectarse a base de datos Oracle 8i ??
Ya lo he probado con una 10g y va excelente, pero tengo otra 8i y no me puedo conectar, existe forma alguna de hacerlo ??
Gracias;
- Inicie sesión para enviar comentarios
Conectar Oracle SQL Developer con Oracle 8i
Parece ser que como a partir de la versión 1.5 SQL Developer utiliza los drivers JDBC de la versión 11g, y estos ya no soportan la versión 8i de la base de datos. O sea, que las últimas versiones de SQLDeveloper no pueden conectar con Oracle 8i. La última versión de Oracle SQL Developer que te permite conectar con una BD Oracle 8i es la 1.2
En este foro de Oracle lo discuten, y no parece que haya muchas soluciones, aparte de utilizar en paralelo las dos versiones de esta herramienta. Si al final encontraras alguna solución mejor háznoslo saber.
- Inicie sesión para enviar comentarios
Hola, estoy intentando
Hola, estoy intentando conectarme a bases de datos 8i con el SQL Developer.
probe con todas las versiones disponibles en el sitio de Oracle: http://www.oracle.com/technetwork/developer-tools/sql-developer/downloa…
Oracle SQL Developer 1.1 Patch 3 (1.1.3.27.66)
Oracle SQL Developer 1.2.1 (1.2.0.32.13)
Oracle SQL Developer 1.5 (1.5.0.53.38)
Oracle SQL Developer 1.5.1 (1.5.0.54.40)
Oracle SQL Developer 1.5.3 (1.5.3.57.83)
Oracle SQL Developer 1.5.4 (1.5.4.59.40)
Oracle SQL Developer 1.5.5 (1.5.5.59.69)
Oracle SQL Developer 2.1 (2.1.0.63.73)
En la 1.2 y 1.2 me deja conectarme, pero cuando me conecto me sale el cartel de "Database Versions 9.x and above are supported" y por mas que este conectado, no me deja ver ninguna tabla o ejecutar consultas.
Alguna idea?
Muchas gracias,
Martin
- Inicie sesión para enviar comentarios
cuestion
ya lo descague pero me tengo problemas para ejecutarlo me pide patname for java.exe, no se cual es, alguien sabe?
- Inicie sesión para enviar comentarios
Debes bajar la versión con
Debes bajar la versión con JDK, es una aplicación hecha en java.
Oracle SQL Developer for Windows. (This zip file includes the JDK 1.5.0_06)
(96 M)
To install and run:
- Download the file above
- Extract sqldeveloper.zip into any folder, using folder names
- Within that folder, open the sqldeveloper folder
- Double-click sqldeveloper.exe
- Inicie sesión para enviar comentarios
Conexion BD ORACLE 10g
Hola desearia que me explicaran como hacer una conexión para empezar a trbajar en esta herramienta
- Inicie sesión para enviar comentarios
con oracle
Para una nueva conexion Oracle:
Vas a connections, click derecho new connection
connection name : nombre de la conexion ej: LocalHost
UserName : system ( comunmente es este , si es que tienes el oracle exprr)
password : la pass que estableciste cuando lo instalaste
Port y sid dejarlo tal cual.
El oracle esta en el puerto 8080 , pero si tienes apache tomcat tendra un conflicto entonces deberas cambiarlo
le pones test para ver si esta funcionando y si pasas conectas eso es todo.
Puedes tener mas de una conexion abierta
- Inicie sesión para enviar comentarios
SQL DEVELOPER
Tenes idea de donde puedo bajar el sql developer en castellano ?
muchas gracias
Saludos
Sebastian
- Inicie sesión para enviar comentarios
En la web de Oracle sólo hay
En la web de Oracle sólo hay una versión, no parece que haya más por idiomas. En la documentación de Oracle sobre las features este producto, en la característica 'Globalization', especifica que a partir de la versión 1.5.1 el entorno está disponible para 9 idiomas.
Yo he probado a instalar la última versión y por defecto ya te coge el idioma que tengas en local, no he encontrado ninguna opción para modificarlo. Lo que sí es cierto es que no lo traduce todo, pero la mayoría sí.
- Inicie sesión para enviar comentarios
Comment
Se ve chido y es facil de usar, pero es lento..
- Inicie sesión para enviar comentarios
Problemas al escribir en el SQL worksheet
Buenas a todo el mundo!
Resulta que trabajo con esta herramienta y tengo un problema que me está empezando a tocar las narices de verdad. Cuando estoy escribiendo una consulta en el SQL worksheet, no me deja hacer un salto de línea, copiar, pegar, desplazarme con la flechas del teclado, suprimir, borrar... y en general todo lo que no sea escribir. Esto me paso un día de golpe (supongo que presioné alguna combinación rara de teclas), antes podía hacer todo esto sin problemas.
Lo he reinstalado y sigue igual, solo se me ocurre alguna cosa del java o algo así. Alguien le ha pasado? y lo mas importante, .. alguien sabe como solucionarlo?
Gracias de antemano!
- Inicie sesión para enviar comentarios
ya está!
Contesto yo mismo, ya que por fín he encontrado la solución al problema más desesperante que havia tenido en mucho tiempo.
Supongo que con alguna combinación de teclas havia activado otro modo de teclado, pero el caso es que se pueden poner los valores por defecto en Tools>preferences>accelerators... allí haces un load preset... y todo vuelve como antes... por fin!
- Inicie sesión para enviar comentarios
Fallo del teclado
muchas gracias por tu aporte, yo tenia lo mismo y tambien hice la reinstalacion... no se como lo desonfigure, pero tu respuesta lo soluciono... talvez fue un atajo de teclas involutario... pero de cualquier manera muchas gracias...
- Inicie sesión para enviar comentarios
Muchas gracias. Tenía el
Muchas gracias. Tenía el mismo problema con las teclas
- Inicie sesión para enviar comentarios
Gracias, me estaba volviendo
Gracias, me estaba volviendo loco con eso. También me pasaba en el Eclipse, tenés idea pq pasa eso y que es?
- Inicie sesión para enviar comentarios
Podría ser problema del
Podría ser problema del tamaño de buffer que utilicen las aplicaciones para exportar los datos, y a lo mejor se puede modificar de alguna manera. También puede ser que la generación del fichero se haga utilizando algún package de Oracle tipo UTL_FILE, y también exista alguna manera de configurarlo.
Pero todo son suposiciones, a ver si hay suerte y alguien que se haya peleado antes con el problema y lo haya resuelto dentro del SQL Developer (o de Eclipse) nos puede decir algo mas concreto..
- Inicie sesión para enviar comentarios
Mira a ver si es tan simple
- Inicie sesión para enviar comentarios
Muchas gracias!!!!, siguiendo
Muchas gracias!!!!, siguiendo los pasos que indicaste, se soluciona el problema de la nueva línea y copiar y pegar.
- Inicie sesión para enviar comentarios
Andreu wrote: Contesto yo
Contesto yo mismo, ya que por fín he encontrado la solución al problema más desesperante que havia tenido en mucho tiempo.
Supongo que con alguna combinación de teclas havia activado otro modo de teclado, pero el caso es que se pueden poner los valores por defecto en Tools>preferences>accelerators... allí haces un load preset... y todo vuelve como antes... por fin!
[/quote] ********* Andrey: Cuando esta configurado en Español tenemos: Preferencias, aceleradores, en el combobox de categoria selecciona Depurar, y busca Ir a fin de metodo. Seleccionas el boton derecho cargar predefinido y luego aceptar y tu editor regresa a estado normal con el teclado.- Inicie sesión para enviar comentarios
No muestra pestaña conexiones
En una PC pegamos el SQL Developer 1.5 y ahora no me muestra la pestaña de conexiones que antes me mostraba. ¿Cómo hago para que aparezca?
- Inicie sesión para enviar comentarios
Alguien tiene la respuesta a
- Inicie sesión para enviar comentarios
No sé si lo habéis visto,
No sé si lo habéis visto, pero en este mismo tema, Nora comentaba que tenía este mismo error The network adapter could not establish the connection (en el comentario número #61).
Echad un vistazo, a ver si alguna de las cosas que se comentan os sirven para solucionarlo, pero lo primero aseguraos de que vuestro cliente de Oracle funciona bien conectando desde SQLPlus a una base de datos Oracle.
Saludos,
- Inicie sesión para enviar comentarios
Con problemas
hola a todos, tengo un problema con el SQL DEVELOPER, la primera vez que lo instale (por asi decirlo) corrio sin problemas, pero cuando empece a ver algunas opciones, y no recuerdo bien que modifique, el asunto es que ahora cuando cargo simplemente no se puede cargar la ventana, si veo en el Task Manager veo el proceso sqldeveloper.exe corriendo, pero no lo veo como aplicación.
Alguien puede ayudarme en verdad me agrado bastante el IDE y me gustaría volver a utilizarlo.
Ah, borré el programa y todas sus entradas en el REGEDIT, lo volvi a desempaquetar, pero nada, incluso desinstale el JDK y lo volvi a instalar y nada.
- Inicie sesión para enviar comentarios
Configuración Punto decimal
Buenas,
tengo una consulta con el SQL Developer. Cuando hago una extracción de datos con la opción INSERT los decimales me los separa con la coma, en vez del punto.
Si después intento utilizar el INSERT no puede diferenciar la separación de campos y la separación de los decimales. La solución está en separar con puntos los decimales, pero no sé cómo. ¿alguna idea? Gracias.
- Inicie sesión para enviar comentarios
Si en el menú seleccionas
Si en el menú seleccionas Herramientas > Preferencias.. , y en la ventana de preferencias Base de datos > Parámetros NLS tienes una caja de texto Separador de decimales donde se puede indicar el carácter que quieras, en este caso cambiar la coma por el punto.
- Inicie sesión para enviar comentarios
Hola a todos, Cambie el
Hola a todos,
Cambie el separador decimal a punto (.) pero igual me sigue mostrando los valores de las variables con coma (,) cuando ejecuto un procedimiento almacenado. Por favor alguien sabe que más falta cambiar???
- Inicie sesión para enviar comentarios
Ya tengo la respuesta: le
Ya tengo la respuesta: le coloqué ., y funcionó.
- Inicie sesión para enviar comentarios
Pero no le habías puesto ya
Pero no le habías puesto ya el punto? O has puesto punto y punto y coma? Hablamos de los parámetros del pantallazo, no?
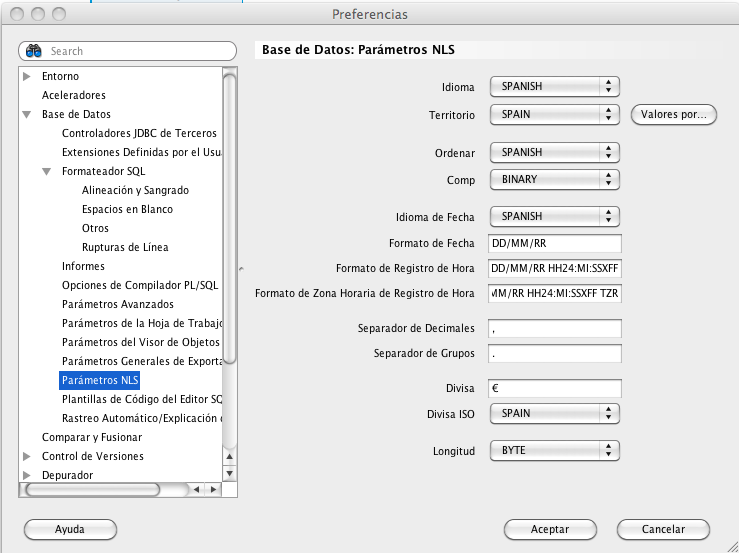
- Inicie sesión para enviar comentarios
Muchas Gracias Andreu, el
Muchas Gracias Andreu, el problema del teclado en oracle sql developer, ya lo he resuelto, era muy desesperante estar así y pude resolver gracias a tí.
Saludos!!
- Inicie sesión para enviar comentarios
Gracias Andreu sufri del
Gracias Andreu sufri del mismo problema
- Inicie sesión para enviar comentarios
Qué alegría encontrarme aquí
Qué alegría encontrarme aquí con la solución del problema con el teclado. Gracias Andreu!
- Inicie sesión para enviar comentarios
No consigo poner el
No consigo poner el SQLDEVELOPER en español he mirado que en el fichero sqldeveloper.conf de la carpeta bin poniendo
AddVMOption -Duser.language=ES
AddVMOption -Duser.region=ES
deberia ponerse el ui en español y no lo consigo, que hago mal?
- Inicie sesión para enviar comentarios
Hola soy novato y tengo una
Hola soy novato y tengo una duda sobre este programa, resulta que necesito pasar una BD completa que tengo en SQL 2005 a Oracle 10g pero no logro poder realizar ninguna conexion ni ocn SQl ni con Oracle.
POr favor podrian explicar como puedo hacer cada una de las conexiones, que necesito y si puedo migrar datos entre esas BD ya conectadas??
Espero por favor me puedan ayudar...
- Inicie sesión para enviar comentarios
Sobre cómo realizar las
Sobre cómo realizar las conexiones ya se comentaba en el artículo inicial sobre SQL Developer, o en este mismo tema, y también puedes consultar la propia ayuda de la herramienta.
Una vez que tengas las dos bases de datos conectadas podrás acceder a los datos de las dos, pero no estarán conectadas entre sí. Para hacer una migración completa deberías utilizar la utilidad de migración que incluye Oracle SQL Developer, que con un asistente te va solicitando los datos necesario para hacer una migración de otros tipos de bases de datos a una base de datos Oracle.
- Inicie sesión para enviar comentarios
Ok perecto gracias a tu ayuda
Ok perecto gracias a tu ayuda ya tengo las conexiones de ambas bases de datos. La migracion tenia pensado realizarla de forma Standart y no Quick pero no se si el volumen de los datos califique para Standart ya que aunq si bien el esquema tiene 3000 tablas en general el backup que me generaba SQL era de solo 900 MB. Que me recomendais??
Muchas gracias por la ayuda..
- Inicie sesión para enviar comentarios
Bueno, haz la prueba tu mismo
Bueno, haz la prueba tu mismo y luego nos cuéntas qué opción te ha funcionado mejor..
- Inicie sesión para enviar comentarios
Hola Carlos, prove la opcioin
Hola Carlos, prove la opcioin Standart de conversión y funciono bastante bien,lo migro todo perfectamente. Es muy bueno el programa y muy recomendado, ahora mientras realizaba otras pruebas por ignorancia mientras realizaba una conversion del modelo "Model Converted" le aplique en el check de que "Run in Background" algo asi para poder realizar otras acciones y ella siguiera gestionando lo que hacia. El problema es que ahora no me muestra nunca el desarrollo de las actividades por haberle dado click a ese check y no se como remediar esto para que me siga mostrando el progreso de las actividades. Por favor espero me puedan ayudar para volver a la normalidad la aplicacion...
Gracias,
- Inicie sesión para enviar comentarios
He intentado de todo desde
He intentado de todo desde revisar todas las preferencias del programa para saber cual puede ser hasta comparar esas preferencias con las de otro al que no le cambie la opcion, pero nada incluso si intento correr el programa desde otra maquina en la red, me acepta las conecciones y todo pero de igual manera no me muestra la ventana de procesamiento... claro que lo deje procesando para ver si lo hacia de todos modos pero paso mucho tiempo y nada...
Estoy realmente preocupado por favor su ayuda me sera muy importante.
Gracias
- Inicie sesión para enviar comentarios
Alonso, lo siento pero no he
Alonso, lo siento pero no he trasteado demasiado la utilidad de migración y no he llegado nunca a activar esta opción de 'Run in background'.
Lo que tampoco entiendo bien es si el problema es que se te quedan para funcionar en background todas las migraciones, o también afecta a cualquier worksheet.
Otra información importante que puedes proporcionar es la versión de SQL Developer que utilizas, porque en versiones antiguas había algún bug relacionado con las ejecuciones en background.
Bueno, a ver si alguien que haya probado más las migraciones nos ilumina un poco..
- Inicie sesión para enviar comentarios
Carlos, tengo una antigua
Carlos, tengo una antigua copia de seguridad de SQLServer 2000, es un archivo con extensión .bak
Como hago para abrirlo para mis consultas con SQL Developer.
Saludos y felicitaciones por la pagina, cada vez soy más un asiduo visitante.
Eduardo.
Lima - Perú
- Inicie sesión para enviar comentarios

Eduardo, SQL Developer
Eduardo, SQL Developer trabaja sobre bases de datos activas, por lo que no creo que puedas hacer nada directamente sobre un backup de base de datos.
Tendrías que recuperar el backup desde una base de datos SQL Server, y después conectar con esta base de datos desde Oracle SQL Developer.
Una vez hecho esto, con la base de datos de SQL Server funcionando, si quieres prescindir del motor de SQL Server, podrías utilizar la utilidad de migración para importar la BD completa, o sólo lo que necesites a tu base de datos Oracle.
- Inicie sesión para enviar comentarios
Hola a todos(as), me
Hola a todos(as), me descargue la ultima version de oracle sqldeveloper 2.1.1( para 64 bits ) ya que trabajo en windows 7 profesional de 64 bits, y lo instalo y toda la cosa excelente, me inicia la interfaz y todo, y cuando quiero crear una nueva coneccion a la BD mediante : file>new>Data Base Conecction, supuestamente me tendria que salir una ventana , pero no me sale nada., ni un error no me muestra.
Haber si me pueden ayudar a solucionar eso. gracias.
- Inicie sesión para enviar comentarios
Hola No se si alguien me
Hola
No se si alguien me puede ayudar. soy nueva con este programa y vengo del Toad, y hay algunas cosas que no encuentro pero sobre todo dos que tienen que estar pero no las encuentro
1- Como puedo saber que paquetes estan correctamente compilados y que paquetes tienen errores??? cuando pulso compilar todo me dice que 4 paquetes tienen errores pero no puedo ver cuales??? en el toad y otras herramientas similares te muestra un icono diferente...
2- Como puedo hacer un expor de toda la base de datos, pero que cada objeto me lo ponga en un archivo, ahora mismo utilizo la opción Herramientas -> Exportación de base de datos, pero ahi me lo crea todo en un solo archivo txt, y esos como backup es un rollo, por que si tengo que recuperar solo un objeto no es nada comodo.
Muchas gracias.
- Inicie sesión para enviar comentarios
buenas. tengo un problema..
buenas.
tengo un problema.. cuando configuro mi conexion a la base de datos esta se realiza bien pero no me deja ver ni tablas, ni las vistas, paquetes o procedimientos, pero me hace la conexion sin errores y hasta puedo hacer consultas, que puede ser?
- Inicie sesión para enviar comentarios
Si no tienes problema al
Si no tienes problema al conectarte tiene que ser una cuestión de permisos del usuario que utilizas.
Asegúrate primero de que tenga los roles básicos para trabajar sobre su propio esquema, normalmente CONNECT y RESOURCE:
SQL> GRANT "CONNECT" TO "USER";SQL> GRANT "RESOURCE" TO "USER";
Recuerda también que un usuario que no sea DBA normalmente sólo ve sus propios objetos, también puede ser simplemente que el usuario con el que te conectas no haya creado aún ningún objeto en su esquema. Puedes probar a crear una tabla, a ver si luego la ves con el explorador:
SQL> create table temporal (campo1 varchar2(1));
- Inicie sesión para enviar comentarios
Hola, bueno te queria
Hola, bueno te queria preguntar si conoces como puedo importar archivos (.txt, .xls, etc...) a una base de datos sql desde el oracle sql developer, te cuento tengo un macbook y logre conectarme a la base SQL y puedo exportar datos facilmente y consultar, el punto es que no se como importar datos a dicha Base de Datos, desde Windows lo hago sin problemas (manager de sql), pero desde mac no se como realizar dicha importacion, si me puedes ayudar te lo agradeceria
saludos
- Inicie sesión para enviar comentarios
Con SQL te refieres a
Con SQL te refieres a SQLServer? Supongo que te refieres a un asistente de importación que te cargue el contenido de un fichero plano o un XML en tablas. Que yo sepa Oracle SQL Developer no tiene esa funcionalidad, como mucho podrías encontrar algo en la herramienta de migración si la BD destino fuera Oracle.
Lo que puedes hacer, si los datos vienen de otra BD, es exportarlos en formato SQL, y eso sí que lo podrías importar con SQL Developer.
Si no vienen de bases de datos tendrás que recurrir a algún script o aplicación más orientada a SQL Server que te permita hacer esta importación. Otra opción que puedes explorar es utilizar el comando BULK INSERT de Transact SQL, que desde el mismo entorno SQL te permite importar datos de ficheros en tablas. Puede importar datos incluso desde ficheros que estén en directorios de red compartidos.
- Inicie sesión para enviar comentarios
Buenos dias Acabo de
Buenos dias
Acabo de ejercutar una consulta que me arroja mas de 200.000 registros y necesito pasarlo a un archivo txt y que el delimitador sea un Tab o algo diferente a como(,) o punto y como(;) y no se por donde cambiarlo...
Muchas gracias
- Inicie sesión para enviar comentarios
Buenas: No llevo mucho tiempo
Buenas:
No llevo mucho tiempo usando esta herramienta pero te digo lo que yo se.
1.- Si son mas de 200.000 registros puede que sobrepases el tamaño maximo (5120 KB).
2.- Con la exportación en formato txt no se puede elegir delimitador simplemente exporta el resultado tal cual tu lo hayas formateado por lo tanto tendras que montar la consulta para que tenga el formato exacto que quieres que tenga en el fichero.
3.- El unico formato de exportación que te permite elegir un caracter delimitador el el csv.
Yo lo que hago es utilizar este como formato intermedio exportando al portapapeles en vez de a un fichero y una vez conseguido el formato lo pego en un fichero txt, xls, word o donde me interese.
Espero te sirva de ayuda
Saludos
- Inicie sesión para enviar comentarios
una consulta acabo de bajar
una consulta acabo de bajar las version 2.1.1.64, pero cuando me quiero conectar a una base de datos de oracle me dice que el usuario y la clave estan incorrectas
pero solo cuando entro con un usuario que no es el owner, con el owner no da problem
gracias de antemano
- Inicie sesión para enviar comentarios
Luis Quezada wrote:una
[quote=Luis Quezada]una consulta acabo de bajar las version 2.1.1.64, pero cuando me quiero conectar a una base de datos de oracle me dice que el usuario y la clave estan incorrectas, pero solo cuando entro con un usuario que no es el owner, con el owner no da problem
[/quote]
Lo que comentas no creo que tenga nada que ver con la versión de SQL Developer, tiene que ser problema del usuario/contraseña que utilizas, o de permisos del usuario. Para asegurarte prueba a conectar con ese usuario desde otro entorno, por ejemplo desde linea de comandos con SQLPlus.
- Inicie sesión para enviar comentarios
La verdad quisiera saber cómo
La verdad quisiera saber cómo insertar múltiples datos por medio de SQL seveloper a una tabla de mi base de datos ya me ha tocado INSERT INTO pauthent_relation(`id`,`user_id`,`group_id`) VALUES (28, 1, 1); uno a uno, soy nuevo en esto de las base de datos Gracias
- Inicie sesión para enviar comentarios
Seguramente el TNSNAMES que
Seguramente el TNSNAMES que se está utilizando es el último que se ha instalado, supuestamente el de C:\app\Administrador\product\11.2.0\dbhome_2\network/admin. También puedes consultar en las variables de entorno cuál es el path que está utilizando el cliente Oracle de tu máquina.
Para consultar datos de conexión mejor mírate el Tnsnames.ora, pero es sólo como referencia, porque SQL Developer no lo utiliza. Como desde SQLPlus sí que puedes entrar, los parámetros del tnsnames relativos a la instancia en la que entras tienen que servirte para la definición de la conexión de SQL Developer.
Por ejemplo, si para entrar con SQL Plus utilizas este comando:
> sqlplus hr/pwd@orcl
Consultas la entrada del TNSNAMES que define ORCL y verás que tienes HOST=CASA.lan y PORT=1521, que es lo que tendrías que informar en la definición de la conexión de Oracle SQL Developer:
Utiliza el botón 'Probar' para comprobar que la conexión te funcione, así es muy rápido hacer pruebas con diferentes parámetros.
- Inicie sesión para enviar comentarios
Hola, al inciciar el sql
Hola, al inciciar el sql developer no se ejecuta, sale una ventana, en la cual solo puedo interactuar con oel tabulador y el aceptar, ¿Que puede ser?.
Lo necesito para clase y me estoy retrasando bastante en la asignatura Bases De Datos
Muchas gracias
- Inicie sesión para enviar comentarios
Hola, espero que sepas mucho
- Inicie sesión para enviar comentarios
Hola, espero me puedan
- Inicie sesión para enviar comentarios
Con muchos registros los
Con muchos registros los datos formateados siempre consumen más recursos. Seguramente el problema lo tengas más en la parte de Excel que en la de Oracle SQL Dev.
Prueba a exportar en formato de texto, o csv, y yo creo que no tendrás problemas.
Si no, la alternativa es hacer la exportación desde fuera de Oracle SQL Developer, con comandos de exportación de la base de datos, o con un script desde Oracle SQL Plus.
- Inicie sesión para enviar comentarios
Hola: alguien me puede
- Inicie sesión para enviar comentarios
En el artículo Oracle SQL
En el artículo Oracle SQL Developer, que referenciaba al principio de este tema, se explica cómo realizar las conexiones de Oracle SQL Dev. Lo has consultado y te da el error que dices o no lo habías visto? Qué error te devuelve el programa?
Por cierto, acabo de ver que ya se puede descargar la versión 4.0 Early Adopter 2 de Oracle SQL Developer, a ver quién se atreve a probarla y nos cuénta qué tal se comporta :)
- Inicie sesión para enviar comentarios
Muy valioso el aporte Carlos,
- Inicie sesión para enviar comentarios
Si quieres hacerlo en la
Si quieres hacerlo en la misma consulta, y una de las bases de datos es Oracle y la otra tiene un conector ODBC, podrías enlazarlas utilizando un database link de Oracle que enlazara a la otra base de datos utilizando Heterogeneous Services.
Te enlazo el artículo de Oscar Paredes Heterogeneous Services: Conexión desde Oracle a SQL Server que explica cómo configurarlo. Una vez bien configurado, la nomenclatura es la de un dblink normal.
- Inicie sesión para enviar comentarios
BUENAS TARDES, He instalado
- Inicie sesión para enviar comentarios
Hola, he tenido problemas en
- Inicie sesión para enviar comentarios
buenas, estoy comenzando a
- Inicie sesión para enviar comentarios
Se ha producido un error al
- Inicie sesión para enviar comentarios
Hola, te comento que soy
- Inicie sesión para enviar comentarios
Quiero saber si puedo
Quiero saber si puedo compilar scripts PL/SQL con sqldeveloper. Si es posible, quisiera orientación acerca de como hacerlo, ya que lo he intentado y no he podido. Gracias.
- Inicie sesión para enviar comentarios
Hola, Tengo una duda, Me sale
Hola,
Tengo una duda,
Me sale una zona en la parte de arriba de color peor unicamente en esta pagina web.
Pero si entro con el telefono movil no esta.
- Inicie sesión para enviar comentarios
Gracias por avisar, pero
Gracias por avisar, pero puedes concretar eso de color peor? No será el aviso de las cookies? En principio está todo bien.
Te agradezco si nos puedes enviar un email con un pantallazo a admin @ dataprix.com, y así sabremos seguro a qué te refieres, o si te va mejor registrarte y abrir un tema adjuntando el pantallazo en el foro http://www.dataprix.com/forum/general/dataprix, que es para comentar cuestiones sobre el funcionamiento de la web.
Un saludo,
- Inicie sesión para enviar comentarios
Hola, Soy novata, y seguro
Hola,
Soy novata, y seguro que es una pregunta estupida....
No encuentro como para publicar las imagenes.
Gracias. :)
- Inicie sesión para enviar comentarios
Hola. Para tienes que
Hola. Para tienes que utilizar un usuario registrado (http://www.dataprix.com/user) y abrir un tema nuevo del foro, entonces desde el mismo editor ya podrás adjuntar el fichero con la imagen.
Cuando lo tengas seguimos por allí y borramos estos comentarios.
Saludos,
- Inicie sesión para enviar comentarios
Que tal Carlos y foro en
Que tal Carlos y foro en general,
Es cierto que es poderosa esta herramienta, solo tengo una duda, como se realiza el cambio de contraseña de un usuario que ya expiro, desde sqlplus o toad por ejemplo aparece la ventana de dialogo o pide el cambio de contraseña, cosa que el sqldeveloper solo aparece el mensaje y no te permite cambiarla.
Saludos
- Inicie sesión para enviar comentarios
Puedes probar a cambiar el
Puedes probar a cambiar el password con un comando alter user de una sola línea, así no necesitas ningún diálogo:
SQL> alter user usuario_bd identified by usuario_pwd;
Otra opción es hacerlo desde el entorno gráfico. SQL Developer, en el área de conexiones, al hacer click con el botón derecho sobre cualquiera de ellas, te ofrece la opción de cambiar el pasword (Reset password) directamente. El problema es que nosmalmente esta opción sale en gris porque por JDBC no se puede hacer y la herramienta necesita que tengas instalado un cliente de Oracle para hacerlo por OCI.
Si te sale en gris te va a ser más sencillo probar el alter user (y si tienes privilegios para cambiar el password), o ir por SQLPlus, pero igualmente te enlazo este post donde explican muy bien cómo instalar el Cliente de Oracle para habilitar la opción de resetear passwords en Oracle SQL Developer.
Saludos!
- Inicie sesión para enviar comentarios
Hola, pregunto por el cambio
Hola, pregunto por el cambio de contraseña con código.
SQL> alter user usuario_bd identified by usuario_pwd;
podrias poner un ejemplo? gracias
- Inicie sesión para enviar comentarios
necesito cambiar mi
necesito cambiar mi contraseña con el código para una entrega de una práctica
Sé que es esa línea de código pero no entiendo muy bien como lo tengo que poner con mi usuario y tal.
¿Podrías poner un ejemplo?
Gracias
- Inicie sesión para enviar comentarios
Buenas tardes expertos.
Buenas tardes expertos.
Basicamente se me presenta el siguiente error cundo intento conectarme a al base de datos
Se ha producido un error al realizar la operación solicitada:
Error de E/S: The Network Adapter could not establish the connection
Código de proveedor 17002
la primera vez que lo intale funciono perfectamente pero luego no he podido. Favor si me pudieras ayudar
Gracias.
- Inicie sesión para enviar comentarios
El error 17002 desde SQL
El error 17002 desde SQL Developer es equivalente al error ORA-12541 de la base de datos, o sea, que por alguna razón la conexión no puede llegar al listener de la base de datos Oracle remota. Tienes que revisar todo lo que puede fallar por el camino, y si el listener de la base de datos está levantado.
- 1. Si utilizas el tnsnames.ora, lo primero revisa que esté todo correcto, aunque si antes conectabas y no ha habido cambios lo más probable es que ya lo tengas bien.
-
2. Revisa que las dos máquinas se puedan comunicar, que no haya ningún puerto cerrado y esas cosas.. Para esto te puede ir bien, depués de hacer un ping desde el cliente al servidor, utilizar el tnsping:
> tnsping nombre_del_servicio
o también
> tnsping ‘(ADDRESS=(PROTOCOL=tcp)(HOST=nombre_servidor_o_ip)(PORT=1575))’
- 3. Si tienes comunicación desde la máquina cliente, entonces el problema ya debería estar en el servidor, que realmente podría no tener levantado el servicio del listener de Oracle. En este post sobre el listener tienes información para comprobar su estado, y levantarlo si es necesario.
- Inicie sesión para enviar comentarios
que tal, estoy usando varias
que tal, estoy usando varias versiones de la herramienta y he intentado conectarme a una base de datos de un cliente la cual esta en oracle 8i.
Me aparece el siguiente mensaje.
Estado: Fallo:Fallo de la Prueba: Versión de Oracle Database no soportada.
Por favor su ayuda urgente necesito realizar la conexion usando esta herramienta, o en su caso una version free
- Inicie sesión para enviar comentarios
Seguramente tienes instalado
Seguramente tienes instalado el cliente 11g, que ya no soporta las versiones 8i de bases de datos Oracle. Prueba a instalar en su lugar un cliente 10g, que sí soporta las 8i.
- Inicie sesión para enviar comentarios
Buen día, tengo una pregunta
Buen día, tengo una pregunta y de antemano muchas gracias por la respuesta.
Necesito limitar el numero de dígitos decimales en cualquier consulta que haga, actualmente y repentinamente me deja hasta 20 dígitos decimales, por lo cual cuando paso la información a excel este me distorsiona los valores.
Me gustaría saber si se puede configurar PL SQL Developer para que me limite el numero de decimales a mostrar pero desde la herramienta PL SQL develope y se se puede en que ruta.
Muchas gracias.
- Inicie sesión para enviar comentarios
hola. ante todo gracias por
hola.
ante todo gracias por la atención prestada,
mi inquietud es que cuando se generan los archivos planos para generar el pago de nomina por transferencia al banco. uno de los empleados aparece con el número de identificación (cédula de ciudadanía) en 0000000000 y en el banco lo rechazan, agradezco las posibles recomendaciones del caso.
- Inicie sesión para enviar comentarios
Buenos días , mi problema es
Buenos días , mi problema es de rendimiento de la aplicación , es muy lenta al conectarse a una base de datos , al hacerle click en la conexión se puede demorar al rededor de 2 minutos en abrirla , tengo al rededor de 30 conexiones en la aplicación configuradas . Hay alguna forma de aumentar el rendimiento ,por ejemplo tengo el toad y la consola de enterprise manager y el mismo numero de conexiones y en esas aplicaciones no tengo problemas .
SO :window 8 , memoria : 4GB .
Gracias
- Inicie sesión para enviar comentarios
Tardar 2 minutos por conexión
Tardar 2 minutos por conexión es muy exagerado, realmente has de tener un problema con algún conector, con la configuración o algo así.
He encontrado un post con consejos para mejorar el rendimiento de SQL Developer con Windows Vista. Es antiguo, pero puede que los consejos que da te sirvan: Post para mejorar el rendimiento de Oracle SQL Developer
Saludos,
- Inicie sesión para enviar comentarios
Hola, me gustaría saber si se
Hola,
me gustaría saber si se puede (y en tal caso cómo) configurar que al ejecutar un conjunto de sentencias SQL como script en la hoja de trabajo, cuando falle alguna, te pida confirmación de seguir o no.
Muchas gracias
- Inicie sesión para enviar comentarios
Hola, que tal. SQL developer
Hola, que tal.
SQL developer tiene alguna opción para convertir de manera automática a myúscula las funciones y palabras reservadas?
Ejemplo:
case
when
select
nvl
y que al escribirlas sea automático? sin necesidad de oprimir teclas adicionales?
Gracias!
- Inicie sesión para enviar comentarios
Para convertir a mayúscula
Para convertir a mayúscula las palabras clave, en 'Herramientas --> Preferencias --> Base de datos --> Formateador SQL --> Otros' tienes un selector con el que puedes configurar la opción de 'Palabras clave en mayusculas', utilizando esta opción al aplicar formato debería ponerte las palabras clave en mayúsculas.
Lo que ya no te puedo decir es si existe la opción de que aplique este formateado de mayúsculas 'al vuelo'. Yo creo que no porque en los estilos por defecto del editor de códigos sólo puedes seleccionar para cambiar colores y estilo de fuente, pero no descarto que haya alguna manera de hacerlo. Si la encuentras avisa!
- Inicie sesión para enviar comentarios
Hola carlos como haces para
Hola carlos como haces para incluir imagenes en las repuestas ?
- Inicie sesión para enviar comentarios
Hola Isaac Para poder incluir
- Inicie sesión para enviar comentarios
Ok, Carlos por favor ponme el
Ok, Carlos por favor ponme el perfil.
- Inicie sesión para enviar comentarios
Listo Isaac, ya eres
Listo Isaac, ya eres colaborador de Dataprix, enhorabuena!
- Inicie sesión para enviar comentarios
Hola tengo un problema al
Hola tengo un problema al escribir sentencias en la hoja de trabajo del sqldeveloper, al darle un salto de linea (enter), me cambia la sentencia a minúsculas, me gustaría que toda la sentencia fuera en mayúsculas.
- Inicie sesión para enviar comentarios
Tengo una problema, no puedo
Tengo una problema, no puedo hacer un enter en el editor de codigo, y no puedo navegar entre las lineas de mis querys, no se realmente que paso, ayer trabaje muy bien y hoy amaneci con este problema.
Podrian apoyarme, debe ser algun parametro
- Inicie sesión para enviar comentarios
Hola, tengo un problema con
Hola, tengo un problema con el host de la base de datos y me gustaria saber si puede ayudarme, la cuestion es que cuando intento tener una conexion a la base de datos, en la parte de la cadena de conexion me aparece un host diferente al establecido en el archivo tnsnames.ora, me gustaria saber a que se debe que cargue un host difeferente al establecido en dicho archivo y como puedo corregirlo, de ante mano gracias por la ayuda
- Inicie sesión para enviar comentarios
Comprueba que no tengas más
Comprueba que no tengas más de un fichero TNSNAMES.ora en tu máquina, puede que esté cogiendo la información de otro. El tnsnames que developer utiliza por defecto es el que hay en el directorio $ORACLE_HOME/network/admin, o si no el que haya definido en la variable de entorno TNS_ADMIN. Si tu máquina es Windows el problema podría ser que no tengas definida esta variable de entorno. Tendrías que definirla y asignarle como valor el path al directorio donde tienes el tnsnames.
- Inicie sesión para enviar comentarios
Hola soy nueva con lo que es
Hola soy nueva con lo que es base de datos y tengo que realizar una consulta entre dos tablas distintas y comparar los datos , entonces si los datos que estan en la tabla A no existen en la tabla B mostrarlos., como se puede realizar esta consulta
tengo el join de las dos tablas listas, pero no se como comparar los datos que no existen
gracias por cualquier ayuda...
- Inicie sesión para enviar comentarios
Te recomiendo revises
- Inicie sesión para enviar comentarios
Tengo un servidor con SunOS
Tengo un servidor con SunOS donde está la BBDD de Oracle y las distintas bases de datos (instancias).
Entro con un usuario unix normal, llamo a sqldeveloper y puedo ver todas las instancias y entrar en ellas.
El problema es que no se que usuario de Oracle soy que tngo todos esos permisos...
¿Hay alguna forma de saberlo? básicamente para evitar que cualquiera pueda acceder a cualquier dato, (aunque sean todos de desarrollo).
Un saludo.
Luis
- Inicie sesión para enviar comentarios
Me respondo solo. Se entra en
- Inicie sesión para enviar comentarios
Luis, gracias por compartir
- Inicie sesión para enviar comentarios
Tengo una duda, a la que no
- Inicie sesión para enviar comentarios
Apara copiar los encabezados
- Inicie sesión para enviar comentarios
hola tengo unas consultas y
- Inicie sesión para enviar comentarios
ve hacia el árbol de objetos,
- Inicie sesión para enviar comentarios
Hola, buenas. Necesitaríamos
- Inicie sesión para enviar comentarios
Por lo que yo se, necesitas
- Inicie sesión para enviar comentarios
Entra al siguiente
{kind=link}
C:\Users\is_delacruz\Pictures\foro sql developer\menu.png
luego das clic en nuevo modelo relacional:
C:\Users\is_delacruz\Pictures\foro sql developer\menu2.png
{kind=link}
y por ultimo solo arrastra las tablas que desean mostrar en el diagrama.
Espero haberte ayudado.
- Inicie sesión para enviar comentarios
por que en la hoja de
- Inicie sesión para enviar comentarios
Porque tienes activo Num
- Inicie sesión para enviar comentarios
Cordial saludo
- Inicie sesión para enviar comentarios
Revisate manuales de sql,
Revisate manuales de sql, especificamente de funciones de agrupacion.
- Inicie sesión para enviar comentarios
Buenas noches, estoy tratando
- Inicie sesión para enviar comentarios
No puedes migrar datos de dos
- Inicie sesión para enviar comentarios
Hola, existe alguna manera de
- Inicie sesión para enviar comentarios
Si, dirigite en SQLDev a Tool
- Inicie sesión para enviar comentarios
Estimado esta opcion ya la he
- Inicie sesión para enviar comentarios
Como puedo crear tablas en un
- Inicie sesión para enviar comentarios
Conéctate como ese usuario y
- Inicie sesión para enviar comentarios
Hola. me gustaria mucho que
- Inicie sesión para enviar comentarios
Yo tengo un problema al
Yo tengo un problema al conectarme a una base de datos hecha en SQL Server, ya que no me muestra las tablas que existen es dicha Base, pero si puedo hacer consultas exitosas... Cuando intento abrir la estructura de la Base me muestra un error con la siguiente leyenda
Se ha producido un error al realizar la operacion solicitada:
El nombre de la columna 'suid' no es valido.
Código del proveedor 207
Ojala alguien pueda ayudarme
- Inicie sesión para enviar comentarios
Hola tengo en mi equipo
Hola tengo en mi equipo Windows 8, ya instale la Base de datos de Oracle y todo parece que se instalo correctamente ahora quiero instalar sql developer para poder ingresar solo que al bajar la version sqldeveloperx64 que tiene incluido el jdk la ejecuto en mi lap y empieza a cargar pero cierra la ventana y baje tambien el sqldeveloper que necesita jdk pero no me funciona, hay algun truco que desconozca para poder instalar oracle 11g en mi lap? Les agradezco su respuesta.
- Inicie sesión para enviar comentarios
Buenos Dias Estimados Favor
Buenos Dias Estimados
Favor alguien me puede ayudar:
Necesito realizar una migracion de Mysql a oracle, saben como hacerlo desde sql developer?
- Inicie sesión para enviar comentarios
Pues dificilmente, porque por
Pues dificilmente, porque por ejemplo, las fechas te van a dar más de un dolor de cabeza.
Lo normal es exportarlos a un fichero y luego importar ese fichero, al que a veces, hay que pasar procesos para adaptar el contenido.
Además debes tener en cuenta el juego de caracteres de cada BBDD
- Inicie sesión para enviar comentarios
Hola buenas tardes carlos
Hola buenas tardes carlos quiero hacerte una consulta. Fijate que tengo un modelo entidad-relacion en oracle sql developer data modeler, el cual quiero sincronizar con una base de datos que tengo en oracle sql developer y el problema es que no se como hacerlo, ya he intentado por ejemplo. archivo/importar/modelo de oracle designer. luego selecciono la conexion y le doy importar, me aparece el combo de las conexiones que deseo importar en este caso es una, pero cuando busco no me aparece el archivo del modelado ya que lo tengo registrado con extension.dmd haz de cuenta que el archivo se llama prueba.dmd, pero no me lo reconoce el asistente ya que solo acepta archivos .xml y por lo tanto no puedo subir el archivo donde hice mis correcciones para poder sincronizarlo con mi base de datos ¿ que me aconsejas que haga ? de antemano muchas gracias.
- Inicie sesión para enviar comentarios
Hola, tengo un problema a la
Hola,
tengo un problema a la hora de exportar una base de datos de sql
Si lo exporto a excel, hace todo el proceso pero no exporta ningun dato.
Si lo exporto a texto me coge un nº de registros muy pequeño. No en todos los casos el mismo nº de registros.
Si lo selecciono y copio me da un mensaje de COMMAND NO HANDLE
Comentaros que hasta hace dos dias no tenia este problema, ha sido de un dia para otro.
Sabeis qué ha podido ocurrir??
Muchas gracias
- Inicie sesión para enviar comentarios
Indícale que lo haga en
Indícale que lo haga en múltiples ficheros.
- Inicie sesión para enviar comentarios
En oracle sql Developer en
En oracle sql Developer en donde puedo encontar el archivo sqlnet.ora?
- Inicie sesión para enviar comentarios
Ejecutando desde SQL
Ejecutando desde SQL Developer la siguiente sentencia:
export * tablaY where mail=x;
da como resultado : 1 Fila ha sido actualizada
pero no consigo averiguar cual? qué se ha modificado exactamente? Entenderia que esa sentencia exporta todos los campos de la tablaY donde el campo mail vale x pero al no poner fichero ni nada donde lo exporta? y por qué sale el mensaje de fila actualizada?
Cualquier ayuda es grata ! Gracias.
- Inicie sesión para enviar comentarios
Aqui les comparto un link de
Aqui les comparto un link de gran utilidad, a mi me sirvio mucho para filtrar datos de una tabla:
- Inicie sesión para enviar comentarios
Hola que tal tengo un gran
Hola que tal tengo un gran problema tengo un servidor con windows server 2003 y ya caduco la licencia que compre ahora al encender el servidor me pide que registre la licencia y no me deja ingreasr al sitema que puedo hacer para sacar mi base de datos sin perder la informacion ya intente con modo de prueba pero no me permite para la base de datos
- Inicie sesión para enviar comentarios
cada ves que creo una
cada ves que creo una conexion se crea con las tablas creadas de conexiones anteriores, como puedo hacer para crear conexiones totalmente limpias? :C
- Inicie sesión para enviar comentarios
Buenas tardes. Estoy tratando
Buenas tardes.
Estoy tratando de hacer un SP delete, y si lo hace pero siento temor de que genere bloqueos ya que son tablas muy muy grandes. Tengo entendido que se puede hacer una depuracion de 500 en 500 para evitar estos bloqueos, he visto unos ejemplos y jugado pero creo son mas orientados a SQLServer que a Oracle.
Me podrias orientar o saber si tienes alguna entrada sobre este tema, te agradeceria.
Te comento que lo que he visto y jugado es algo como esto
SET ROWCOUNT 500 delete_more:
stmt_str := 'DELETE FROM schema.table WHERE (schema.table.campo_date) BETWEEN TO_DATE('''||start_date||''') AND TO_DATE('''||end_date||''')';
IF @@ROWCOUNT > 0 GOTO delete_more
SET ROWCOUNT 0Pero no logro hacer un SP.. Tipo.
create or replace PROCEDURE "SP_DELETE_CC_" AS
start_date date;
end_date date;
stmt_str varchar2(1000);
BEGIN
select FECHAINICIO into start_date from SOURCE_SCHEMA.SOURCE_TABLE_CC
where DESCRIPCION='SOURCE_SCHEMA.TABLE' AND ID_ ='20';
select FECHAFIN into end_date from SOURCE_SCHEMA.SOURCE_TABLE_CC
where SUJETO_DESCRIPCION='SOURCE_SCHEMA.TABLE' AND ID_SUJETO ='20';
SET ROWCOUNT 500 delete_more:
stmt_str := 'DELETE FROM TARGET_SCHEMA.TARGET_TABLE WHERE (TARGET_SCHEMA.TARGET_TABLE.CAMPO_DATE) BETWEEN TO_DATE('''||start_date||''') AND TO_DATE('''||end_date||''')';
IF @@ROWCOUNT > 0 GOTO delete_more SET ROWCOUNT 0 EXECUTE IMMEDIATE stmt_str;
EXECUTE IMMEDIATE 'commit';
END;Muchas Gracias
- Inicie sesión para enviar comentarios
Hola a todo@s, tengo la
Hola a todo@s, tengo la siguiente consulta que ejecuto con : SELECT mar_nu_prov,unidades,familia, replace(round(neto_sin_iva, 2) - rappel,'.',',') AS neto FROM alma, (SELECT lin_codigo, mar_descripcion, LPad(mar_familia, 5, ' ') || ' ' || fam_nombre as Familia, LPad(mar_subfamilia, 5, ' ') || ' ' || subfam_nombre as SubFamilia, mar_pre_costo costo_art, mar_pre_medio medio_art, '' as proveedor, Sum(lin_uni) as unidades, Sum(lin_bonif) as bonif, Sum(lin_bultos) as bultos, Sum(round(round(lin_uni * lin_p_venta,2) * (1 - lin_descuento_t/100), 2)) as ventas, Sum(lin_uni * mar_peso) as kilos, Sum(Round(lin_p_costo * (lin_uni + lin_bonif), 2)) as costo, Sum(Round(lin_p_medio * (lin_uni + lin_bonif), 2)) as pmedio, ((sum(round(round(lin_uni * lin_p_venta, 2) * (1 - lin_descuento_t/100), 2))) - sum(round((lin_uni + lin_bonif) * lin_p_costo, 2))) as BenfBruto, ((sum(round(round(lin_uni * lin_p_venta, 2) * (1 - lin_descuento_t/100), 2))) - sum(round((lin_uni + lin_bonif) * lin_p_medio, 2))) as BenfPM, Sum(round(round(round(lin_uni * lin_p_venta, 2) * (1 - lin_descuento_t / 100), 2) * (1 - glin_dto_pp / 100) * (1 - glin_dto_adicio_01 / 100) * (1 - glin_dto_adicio_02 / 100) * (1 - glin_dto_adicio_03 / 100), 2)) as neto_sin_iva, Sum(round(round(round(round(lin_uni * lin_p_venta, 2) * (1 - lin_descuento_t / 100), 2) * glin_recargo / 100, 2) * (1 + lin_iva_v / 100), 2)) rappel, Sum(glin_descuento_i) glin_descuento_i, Sum(round(Round(round(round(lin_uni * lin_p_venta,2) * (1 - lin_descuento_t/100),2) * (1 - glin_dto_pp / 100) * (1 - glin_dto_adicio_01 / 100) * (1 - glin_dto_adicio_02 / 100) * (1 - glin_dto_adicio_03 / 100), 2) * (lin_iva_v/100), 2)) IVA_V FROM linfac, glinfac, articulo, familia, subfam, proved01, vendedor,client01 WHERE glin_n_fac = lin_n_fac AND glin_estado = lin_estado AND glin_estado IN (1, 6, 8) AND Trim(mar_n_articulo) = Trim(lin_codigo) AND mar_familia = fam_codigo AND mar_subfamilia = subfam_codigo (+) AND mar_familia = subfam_codigo_fam (+) AND glin_fecha BETWEEN To_Date('01/01/2015', 'dd/mm/yyyy') AND To_Date('31/12/2015','dd/mm/yyyy') AND glin_cliente BETWEEN 430010001 AND 430999999 AND glin_alma BETWEEN 2 AND 40 AND glin_vendedor BETWEEN 2 AND 2 AND mar_familia BETWEEN 1 AND 99 AND glin_zona BETWEEN 0 AND 999 AND lin_provee = prove_cuenta (+) AND mcl_vendedor = ven_codigo (+) and glin_cliente = mcl_n_cliente GROUP BY lin_codigo, mar_descripcion, LPad(mar_familia, 5, ' ') || ' ' || fam_nombre, LPad(mar_subfamilia, 5, ' ') || ' ' || subfam_nombre, mar_pre_costo, mar_pre_medio,glin_recargo ) , articulo A WHERE alm_codigo = lin_codigo AND alm_codigo = A.mar_n_articulo GROUP BY lin_codigo, A.mar_descripcion,mar_nu_prov,familia, subfamilia,costo_art, medio_art,unidades, bultos, bonif, ventas, costo, pmedio, BenfBruto, BenfPM, neto_sin_iva, glin_descuento_i, iva_v ,rappel, kilos, A.mar_tipo_arti, A.mar_unid_bulto esta conmsulta me da un resulto como el siguiente: PROVEEDOR UNIDADES FAMILIA PRECIO 400010144 154 1 Tubería de Sanitaria 34,17 400010144 25 1 Tubería de Sanitaria 10,19 400010144 6 1 Tubería de Sanitaria 7,68 400010555 31 1 Tubería de Sanitaria 52,02 400010144 4 1 Tubería de Sanitaria 3,64 400010008 22 3 Abastecimiento PE 55,48 400010008 6 3 Abastecimiento PE 39,65 400010837 4 2 Tubería de Saneamiento 54,28 400010008 6 3 Abastecimiento PE 34,98 400010008 2 3 Abastecimiento PE 142,13 400010664 41 3 Abastecimiento PE 111,69 400010664 9 3 Abastecimiento PE 36,07 400010664 32 3 Abastecimiento PE 179,36 400010364 6 3 Abastecimiento PE 21,42 400010364 6 3 Abastecimiento PE 31,55 400010627 0 3 Abastecimiento PE 0 400010664 6 3 Abastecimiento PE 89,28 400010144 38 1 Tubería de Sanitaria 9,95 400010144 3 1 Tubería de Sanitaria 2,4 400011000 2 4 Abastecimiento PP 33,72 400010751 87 5 Abastecimiento PB Terrain 215,38 400010751 3207 5 Abastecimiento PB Terrain 534,45 400010751 86 5 Abastecimiento PB Terrain 328,7 400010751 1 5 Abastecimiento PB Terrain 2,57 400010751 0 5 Abastecimiento PB Terrain 0 400010833 0 7 Abastecimiento Fund. 0 400010774 -6 8 Abastecimiento CU. -1,8 400010774 1 8 Abastecimiento CU. ,2 400010774 26 8 Abastecimiento CU. 9,86 400010774 8 8 Abastecimiento CU. 6,24 400010774 8 8 Abastecimiento CU. 8,42 400010774 6 8 Abastecimiento CU. 5,3 400010882 127 4 Abastecimiento PP 279,87 400010882 217 4 Abastecimiento PP 92,77 400010308 15 9 Abastecimiento Galvanizado 16,95 400010352 50 10 Fijación 27,38 400010352 49 10 Fijación 65,84 400010944 118 10 Fijación 16,32 400010832 15 10 Fijación 7,2 400010352 11 10 Fijación 18,89 400010180 2 12 Tubería de presión 40,28 400010144 6 12 Tubería de presión 6,46 400010352 10 10 Fijación 22,9 400010540 1 12 Tubería de presión 9,08 400010180 6 12 Tubería de presión 27,92 400010180 1 12 Tubería de presión 5,78 400010751 56 10 Fijación 16 400010751 8 10 Fijación 2,11 400010180 18 12 Tubería de presión 19,15 400010180 8 12 Tubería de presión 42,63 NECESITO POR FAVOR QUE ALGUIEN ME AYUDE, QUIERO AGRUPAR POR PROVEEDOR, FAMILIA Y QUE SUME LAS UNIDADES Y TOTALES DEL PRECIO Y NO TENGO NI IDEA DE COMO HACER ESTO, AGRADECERÍA ENORMEMENTE SI ALGUIEN PUEDIERA AYUDARME. UN SALUDO PARA TODOS DESDE TENERIFE . ESPAÑA
- Inicie sesión para enviar comentarios
Hola, quiero establecer una
Hola, quiero establecer una conexión y al hacer la prueba me sale un cartel que me dice "String index out of range:19841", me p'odrían ayudar con eso? Muchas gracias.
- Inicie sesión para enviar comentarios
Oracle Warehouse Builder 10g disponible sin cargo
Oracle Warehouse Builder 10g disponible sin cargo Carlos 9 May, 2007 - 22:20Si trabajas con bases de datos Oracle y te estás planteando la posibilidad de utilizar una herramienta ETL (Extract, Transform & Load) para la alimentación de un Data warehouse, o simplemente para facilitar integraciones o migraciones de datos, te puede ir muy bien saber que Oracle permite la utilización de la versión básica de su herramienta de ETL Oracle Warehouse Builder 10g Release 2, sin coste adicional de licencias.
Eso sí, has de disponer de al menos una licencia de Oracle Database Standard Edition One, Oracle Database Standard Edition o Oracle Database Enterprise Edition.
Para más detalles, consultar el artículo de Oracle Press Oracle Anuncia la Disponibilidad General de Oracle Warehouse Builder 10g Release 2
Oracle WorkFlow sobre OWB
Oracle WorkFlow sobre OWB cfb 29 May, 2008 - 11:14Tengo instalado Oracle Workflow, y lo utilizo desde Oracle Warehouse Builder. Para definir los flujos de proceso no hay ningún problema, todo bien, y la validación también me la da como correcta. El problema me lo encuentro cuando quiero desplegar un workflow desde el control center. Parece que cuando tiene que crear el dblink se encuentra un nombre demasiado largo, que sobrepasa los 30 caracteres que permite PL/SQL en los nombres de variables.
El mensaje de error que devuelve al intentar hacer el despliegue es este:
| Nombre | Acción | Estado | Log |
| ODS | Crear | Error |
ORA-06550: línea 1, columna 29: PLS-00114: el identificador 'DWH.REGRESS.RDBMS.DEV.US.O' es demasiado largo |
| ODS | Crear | Error |
RPE-02215: Fallo al probar el sinónimo ODS_WB_RTI_WORKFLOW_UTIL. |
| ODS | Crear | Error |
RPE-02260: Database User OWF_MGR must be a Control Center User. Please use the OWB Design Client against the Control Center repository to grant the Control Center User role. |
Yo creo que tiene que ver con el churro que la base de datos añade a los nombres de DBLINK en la versión 10g (es la que he utilizado como repositorio de OWF), que hace que este sea demasiado largo.
Alguien sabe si es este el problema o puede ser otra cosa? Si fuera este, cómo hago para que la base de datos no agregue al nombre el 'REGRESS.RDBMS.DEV.US.ORACLE'. Si el link se llamara sólo 'DWH' seguro que ya no tendría problema.
Efectivamente el problema
Efectivamente el problema estaba en el nombre del dblink que crea OWF. A partir de la versión 10g, las bases de datos Oracle tienen un nombre global compuesto por el nombre de la instancia, lo que siempre hemos llamado SID, y el dominio. Este dominio por defecto es REGRESS.RDBMS.DEV.US.ORACLE.COM, o sea que el nombre global de mi base de datos era DWH.REGRESS.RDBMS.DEV.US.ORACLE.COM
Al crear cualquier DBLink, la base de datos agrega al mismo el nombre del dominio:
SQL>create database link mi_db_link connect to scott identified by tiger using 'dwh'; Database link created. SQL> select db_link from user_db_links;
DB_LINK ------------------------------------------
MI_DB_LINK.REGRESS.RDBMS.DEV.US.ORACLE.COM
Este dominio realmente no sirve de mucho, por lo que no pasa nada si se cambia por otro más corto (con un usuario con privilegios de DBA):
SQL> select * from global_name;
GLOBAL_NAME --------------------------------------------------------------------------------
DWH.REGRESS.RDBMS.DEV.US.ORACLE.COM
SQL> alter database rename global_name to dwh.dataprix.com;
Base de datos modificada.
Ahora que hemos cambiado el nombre del dominio podemos volver a crear el dblink, y el nombre que le asigna la base de datos ha de ser más corto: SQL> dropdatabase link mi_db_link;
Enlace con la base de datos borrado.
SQL> create database link mi_db_link connect to scott identified by tiger using 'dwh';
Enlace con la base de datos creado.
SQL> select db_link from user_db_links;
DB_LINK --------------------------------------------------------------------------------
MI_DB_LINK.DATAPRIX.COM
Nuestro database link ahora se llama MI_DB_LINK.DATAPRIX.COM, con una longitud menor que 30 caracteres, por lo que el Workflow ya no tiene ningún problema al hacer el 'deploy'.
Como resumen, por si alguien se ha perdido, lo único que había que hacer era reducir el nombre global de la base de datos con:
SQL> alter database rename global_name to miBD.mi.dominio.com;
- Inicie sesión para enviar comentarios
Requerimientos de Targets de Oracle Warehouse Builder
Requerimientos de Targets de Oracle Warehouse Builder Carlos 14 May, 2008 - 23:02Estoy utilizando OWB como herramienta de ETL para la carga de un Datawarehouse, pero también me gustaría utilizarlo para realizar cargas o actualizaciones de datos puntuales en otras bases de datos Oracle.
El problema es que, por lo que he podido ver, para cada BD en la que quiero tocar o cargar algún dato, tengo que tener instalado un servidor de OWB. Son bases de datos de producción y encuentro algo arriesgado y no muy lógico que para insertar registros en una sola tabla, por ejemplo, tenga que hacer previamente una instalación de la herramienta.
Alguien sabe si con OWB hay alguna manera de poder definir un esquema destino en otra base de datos sin tener que hacer una instalación del 'runtime' en esa base de datos?
Hola Carlos. No es posible
Hola Carlos.
No es posible deployar mappings en una bbdd que no tenga instalado el "Control Center" de Warehouse Builder.
Con lo cual no puedes registrar "targets" fuera de la bbdd donde está WB.
Puedes crear mappings, tablas, vistas pero nada mas. Todo lo que hagas quedará solamente como metadatos en el proyecto sin poder generar nada en el destino.
Espero haberte ayudado.
Saluditos,
- Inicie sesión para enviar comentarios
Comparativas y documentación
Comparativas y documentación Dataprix 8 Septiembre, 2009 - 12:58Comparativa de MySQL vs Oracle database
Comparativa de MySQL vs Oracle database cfb 13 Julio, 2006 - 09:17La filosofía del código abierto cada día gana más adeptos, y los sistemas y herramientas que se desarrollan están entrando en las empresas, sobretodo gracias al hecho de que en la mayoría de los casos no es necesario pagar licencias por su utilización.
Esta clara ventaja competitiva respecto al software de 'código cerrado' que se distribuye bajo costosas licencias hace que las distribuciones de software Open Source estén arrebatando cuota de mercado a importantes empresas como Microsoft y Oracle.
La cuestión está en si estas herramientas tienen la misma calidad, y pueden garantizar el mismo soporte a las empresas que las utilicen.
Un ejemplo de este hecho es la utilización de MySQL frente al gestor de bases de datos Oracle. En el artículo que adjunto se realiza una comparativa bastante completa entre ambos.
Que cada uno saque sus propias conclusiones.
Para empezar no creo que
Para empezar no creo que estas dos gestores de bases de datos esten encuadrados en el mismo sector, pricipalmente porque MySQL no tiene el soporte que tiene Oracle.
MySQL estaria destinado a pequeñas y medianas empresas que requieren potencia, facilidad pero no estan dispuestos a desembolsar una gran cantidad de dinero en licencias. Ademas, normalmente las aplicaciones tampoco requieren "lo ultimo" en base de datos, asi que MySQL suele ser la mejor eleccion.
Oracle esta mas orientado a las grandes empresas a las que les gusta olvidarse de los problemas y externalizarlo todo. De esta manera Oracle con sus consultores, con la documentacion disponible y en general con el soporte que otorga a sus clientes consigue con creces el objetivo de que la empresa se "lave las manos" en temas de bases de datos. Eso evidentemente tiene un precio.
Hblando de rendimiento no creo que la diferencia sea tan grande como nos quieren ahcer creer, MySQL esta preparado para cargas de trabajo muy elevadas y no tiene nada que envidiar nada de Oracle, lo que pasa es que normalmente en temas de hardware a Oracle le dan todos los caprichos y a MySQL le destinan los servidores menos potentes, y asi es normal que Oracle tenga un rendimiento mas elevado.
Un saludo,
David
- Inicie sesión para enviar comentarios
Soporte de MySQL
Bueno, tampoco hay que olvidar que MySQL ya dispone de servicios de soporte que ya no tienen mucho que envidiar al ofrecido por Oracle, aunque por supuesto para esto sí que hay que pagar.
Existe la MySQL Network que ofrece soporte online, MySQL AB ofrece servicios de consultoría, y por supuesto están todos los foros, IRC's y webs de la comunidad. Incluso existen certificaciones oficiales. Además, hay que tener en cuenta que los técnicos que se encuentran tras este soporte son los mismos que han desarrollado el SGBD, y que ante un bug de la aplicación posiblemente podrán reaccionar de manera más rápida, o incluso hacer una adaptación especial del gestor para el problema concreto que un cliente pueda tener.
Se puede consultar información sobre estos temas en http://www.mysql.org/support/
- Inicie sesión para enviar comentarios
Por si la comparativa del
Por si la comparativa del documento anterior resulta demasiado extensa, o simplemente para contrastar información, en el archivo al que se puede acceder desde el link adjunto se puede consultar una comparativa más esquematizada (2 páginas) de las principales funcionalidades que ofrecen MySQL, PostgreSQL y Oracle, realizada por un compañero de trabajo. De paso, si alguien quiere consultar su blog, se pueden encontrar cosas muy interesantes, sobretodo sobre el mundo del software de libre distribución.
- Inicie sesión para enviar comentarios
Hola carlos, estaria
Hola carlos, estaria interesado en poder ver la comparativa, especilamente entre Oracle y PostgreSQL. Con la direccion que dajastes no me aparece nada. Muchas gracias
- Inicie sesión para enviar comentarios
Ficheros de comparativas
Hola Eugenio
He vuelto a adjuntar el documento del artículo inicial, que al parecer se perdió al actualizar la versión de Drupal.
Sobre la otra comparativa (Oracle y PostgreSQL), efectivamente el blog de 3DES ya no está activo en el dominio indicado. Intentaré averiguar si ha cambiado de dominio y, si es así, actualizaré el enlace en cuanto lo sepa.
Carlos Fernández
Analista de sistemas
- Inicie sesión para enviar comentarios
PostgreSQL y MySQL
PostgreSQL ya no es tan complicada como decian y a partir de su version 8.2.3, las voces que decian que era lenta, se terminaron.
Mysql corre hasta en un W98, una base de datos que se tilde de tal no podria correr en un sistema asi, PostgreSQL por lo menos en entornos windows requiere NTFS. XP y Windows 2000 serian adecuados.
Desde 8.2.3 PostgreSQL tiene una velocidad que se pone a tiro, incluso ganando mayores prestaciones, desde su version 5 MySql, aumenta su prestacion, pero seamos sinceros, perdio velocidad. Aunque haciendo un Join de mas de dos tablas siempre tuvo mala performance.
PostgreSQL hoy por hoy es la unica base de datos capaz de jugar bien en todos los campos.
Es libre, puede pelear hoy o ser una alternativa para trabajar en esos espacios donde hoy trabaja MySQL, pero MySQL no puede escalar y lograr lo que PostgreSQL logra con multiprocesadores.
El motor de integridad de Mysql es comprado por oracle
Es libre y hoy supera a MSSQL aun corriendo en Windows 2000 server, propiedad de la misma empresa que MSSQL. Y tiene toda la funcionalidad de MSSQL.
Es gratis y pelea a la par con Oracle, siendo la comunidad de PostgreSQL y su pagina oficial una buena fuente de documentacion y soporte.
Habiendo trabajado 10 años con MSSQL hace 3 pase a PostgreSQL, aun desarrollo en Visual Basic, estoy lejos de una guerra santa, pero antes de elegir PostgreSQL, por la popularidad de MySQL, probe este, con un join de tres tablas no pudo superar a access, en aquel momento.
Al principio no me fue comodo, hasta que encontre los GUI adecuados, ahora me quedo con PostgreSQL, que si ocupa el lugar que le corresponde, veremos caer mucho software propietario.
Hasta Luego
- Inicie sesión para enviar comentarios
Prueba PostgreSQL
La verdad es que todo lo que he oído de esta base de datos es bueno, pero parece que en el entorno Open source, o por lo menos el de web, el que sigue 'triunfando' es MySQL, será cuestión de costubres, marqueting, herramientas, soporte, comodidad, o quizás existan razones técnicas..
Yo aún no he tenido ocasión de trabajar con PostgreSQL, y me gustaría hacer alguna prueba. Sería de gran ayuda saber cuáles son 'los GUI adecuados', y poder así comparar con otros SGBD.
Un saludo
- Inicie sesión para enviar comentarios
pgadmin3 ...
es para mi lo mas comodo :)
- Inicie sesión para enviar comentarios
PostgreSQL y MySQL
Creo que deberias hacer tambien un curso de marketing. Por otra parte si Oracle es tan bueno (que lo es!), por que motivo es muchas veces mas masivo MySQL o es que todos los profesionales informaticos que no lo usan son mediocres?.
Debes ser cuidadoso con tus comentarios o de lo contrario como ya te dije, estudia Marketing o crea tu propia BD.
Saludos.
- Inicie sesión para enviar comentarios
si en Oracle los usuarios
si en Oracle los usuarios principales son oracle, sys, system para manejo de la base de datos en mysql, cuales serían?
- Inicie sesión para enviar comentarios
Documentación online de Oracle database
Documentación online de Oracle database Carlos 23 Septiembre, 2006 - 21:21Si quieres acceder a la documentación online de Oracle 9i puedes hacerlo a través del enlace adjunto. Es la ayuda oficial de Oracle.
 Oracle 9i Database Online Documentation
Oracle 9i Database Online Documentation
Si prefieres consultar la documentación online de Oracle 10g:
 Oracle Database 10g Online Documentation
Oracle Database 10g Online Documentation
Encontrarás los manuales oficiales de Oracle de todo lo relativo a la base de datos, tanto para principiantes como para usuarios avanzados, y en formato PDF y HTML.
Encuentro especialmente útiles el 2 Day DBA y la SQL Reference, y si tienes o vas a implementar un Datawarehouse sobre una base de datos Oracle ya tardas en descargarte la Data Warehousing Guide
Y si ya estás utilizando una base de datos Oracle 11g:
 Oracle Database 11g Online Documentation
Oracle Database 11g Online Documentation
Base de datos Oracle 12c: las mejoras
Base de datos Oracle 12c: las mejoras Natik Ameen 12 May, 2014 - 19:20

La base de datos Oracle 12c destaca por la gran cantidad de novedades que incorpora con respecto a cualquier otra versión. Como se puede deducir de su nombre, las nuevas características de esta versión se orientan especialmente hacia el Cloud Computing.
Larry Ellison ya destacó en la sesión inaugural del OpenWorld 2012 que, de hecho, es la release de base de datos más importante que han lanzado en mucho tiempo.
Para esta versión, se han realizado drásticos cambios de arquitectura que han dado como resultado más de 500 nuevas características!
En este post vamos a echar un vistazo a las principales mejoras introducidas en la release 12c de la base de datos de Oracle.
Bases de datos 'conectables'
La arquitectura multitenant permite que las bases de datos se consoliden en un único servidor a la vez que se mantienen separadas entre ellas. Esta nueva arquitectura permite compartir la SGA, la CPU y otros recursos, reduciendo ampliamente la cantidad requerida de memoria y de CPU, en comparación con la que sería necesaria para mantener las bases de datos por separado.
Heatmaps de bases de datos
Oracle database 12c monitoriza la actividad de cada columna de las tablas, determina qué tipo de compresión se adapta mejor a cada una, y puede realizar la compresión.
Índices duplicados
Esta característica permite crear índices duplicados sobre el mismo conjunto de columnas. Esto puede ser muy útil en entornos de Data Warehouse en los que se puede mejorar el rendimiento implementando a la vez índices de tipo Bitmap y de tipo B-tree sobre las mismas columnas.
Result sets implícitos
Una de las principales utilidades de los tipos de PL/SQL es para devolver result sets desde una función o un procedimiento almacenado. Ahora, con la release 12c, ya no va a ser necesario proceder de esta manera, ya que se podrá devolver por referencia el mismo cursor desde las mismas funciones y procedures.
Seguridad a nivel de PL/SQL
Ahora los DBA podemos asignar roles a bloques de código PL/SQL. Parece sencillo pero es impresionante. Oracle se está asegurando de que la seguridad se puede otorgar incluso a nivel de cada bloque.
Columnas de Identidad
Esta mejora ha sido tomada otras bases de datos como MySQL y MS SQLServer. Estos gestores de bases de datos ya permiten utilizar desde hace tiempo para las claves primarias columnas de tipo 'identity', que tienen la habilidad de autoincrementar por defecto el valor del campo de clave.
Mejoras en los valores por defecto de las columnas
Hay bastantes nuevas formas de definir valores por defecto para una columna. Ahora se pueden utilizar las funciones NextVal y CurrVal de las secuencias. También se pueden especificar valores por defecto para Nulos explícitos proporcionados en sentencias Insert para asegurarse de que determinadas columnas siempre contienen un valor. También ahora se pueden definir valores por defecto de sólo metadatos para campos de columna tanto opcionales como obligatorios.
Opciones para limitar filas
Las nuevas cláusulas de limitación de filas, Offset y Fetch, permiten crear consultas de tipo Top N sin saber absolutamente nada de las funciones analíticas. Además estas cláusulas permiten paginar a través de los datos para selecionar ciertos subconjuntos de datos.
Tipos de datos extendidos
Los tamaños máximos de Varchar2 y NVarchar2 se han incrementado de 4K a 32K. El tamaño del tipo de dato RAW también se ha ampliado de 2K a hasta 32K. Todos estos tamaños están disponibles con la opción Extended Data Types que puede activarse por medio de un parámetro de inicialización y ejecutando un script.
Encriptación mejorada
La encriptación mejorada permite la creación y gestión de 'wallets' por SQL, en lugar de hacerlo a través utilidades de linea de comandos. También permite la gestión remota de una manera sencilla. La función de encriptación se ha incorporado también en los wallets/claves de exports e imports entre bases de datos conectables. El almacenamiento de loss wallets es en ASM, para mayor seguridad.
Separación de Tareas
SYSDBA – Super usuario
SYSOPER – Menos privilegios que SYSDBA, pero con bastante poder.
SYSBACKUP – Puede utilizarse específicamente para realizar operaciones de backup y restauración.
SYSDG – Disponible para administración de data guard.
SYSKM – Habilitado para realizar tareas básicas de mantenimiento.
Características de Oracle 12c no soportadas en Bases de datos contenedoras
Estas son algunas de las características de bases de datos Oracle 12c que no están soportadas en la base de datos contenedora de una arquitectura multitenant:
- Continuous Query Notification
- Flashback Data Archive
- Heat Maps
- Automatic Data Optimization
 Por Natik Ameen
Por Natik Ameen
DBA Senior de Oracle RAC, Exadata y GoldenGata
Blogger experto en VitalSoftTech
Estimado, Primeramente
Estimado,
Primeramente felicitaciones por el gran aporte !!!
Me ha quedado un poco mas claro de las grandiosas funcionalidades de oracle 12c.
Saludos.
- Inicie sesión para enviar comentarios
Hola que tal, oye la
Subido por Jorge G (no verificado) el 27 Noviembre, 2014 - 09:19
Hola que tal, oye la extensión no la permite crome. Dice que no está en su web store. No hay otra manera de poder utilizarla?
Gracias!