Descubriendo el Business Intelligence
Descubriendo el Business Intelligence respinosamilla 25 February, 2010 - 17:27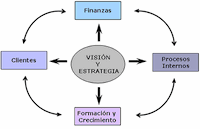 Hola a todos:
Hola a todos:
Soy Roberto, un profesional de la informática en el mundo SAP. Hace unos años trabaje en un proyecto de Business Intelligence en una de las empresas donde estuve, con un Datawarehouse para Analisis de Ventas utilizando herramientas de MicroStrategy.
Desde ese momento, siempre me quedo el gusanillo de dedicarme a profundizar en esa materia, quedandome con las ganas de especializarme en algo tan interesante y con tanto potencial de futuro.
Ahora, diez años despues (debe de ser la llegada de los 40, que están a la vuelta de la esquina), he recogido fuerzas para retomar el tema. Desde este foro espero ir contandoos mis evoluciones, descubrimientos e inquietudes.
Objetivo: formarme en el mundo BI y compartir con vosotros la experiencia (por si a alguien le puede ayudar o resultar interesante).
Roadmap:
1) Introducción y profundización en la teoría del Business Intelligence.
2) Definición de un proyecto base enfocado a una experiencia de empresa final.
3) Diseño e Implementación del proyecto utilizando herramientas Open y herramientas Propietarias.
4) Seguimiento del proyecto, documentación y comparativas entre las herramientas utilizadas.
5) Publicación de los resultados. Conclusiones
Cualquier ayuda se agradece de antemano
Empecemos…
¿Qué es Business Intelligence?
¿Qué es Business Intelligence? respinosamilla 25 February, 2010 - 17:29Qué es Business Intelligence o Inteligencia de Negocio exactamente? Ha llegado el momento de entenderlo.
De forma general, el BI suele definirse como la transformación de datos de la compañia en conocimiento para obtener una ventaja competitiva. Si lo asociamos directamente a las tecnologías de la información, podemos definir Business Intelligence como el conjunto de metodologías, aplicaciones y tecnologías que permiten reunir, depurar y transformar datos de los sistemas transaccionales e información desestructurada (interna y externa a la compañia) en información estructurada para su explotación directa (reporting, análisis OLAP, mineria de datos, etc.) o para su análisis y conversión en conocimiento como soporte a la toma de decisiones sobre el negocio.
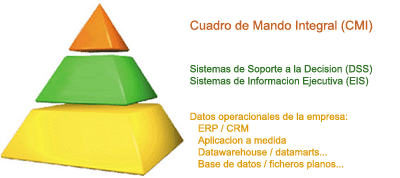
Para empezar a entender conceptos, nada mejor que un esquema básico que incluye los elementos mas comunes de un sistema BI.

Imagen obtenida del documento de la empresa Ibermatica (muy buenas definiciones sobre qué es Business Intelligence para entrar en calor):
En la Wikipedia también se define qué son los sistemas de Business Intelligence
Definición de Business Intelligence
También lo podriamos definir como el proceso de convertir datos en conocimiento y conocimiento en acción, para la toma de decisiones. Algo así como la siguiente ecuacción:
Datos + Análisis = CONOCIMIENTO
Podriamos igualmente describir BI como el concepto que integra por un lado el almacenamiento y por otro lado el procesamiento de grandes cantidades de datos, con el principal objetivo de transformarlos en conocimiento y en decisiones en tiempo real, a través de un sencillo análisis y exploración. Al contar con la información exacta y en tiempo real, es posible identificar y corregir situaciones antes de que se conviertan en problemas o perdidas de control, permitiendonos igualmente identificar oportunidades o readaptarnos antes los cambios que se vayan produciendo.
Las herramientas de inteligencia se basan en la utilización de un sistema de información de inteligencia que se forma con distintos datos extraídos de los datos de producción, con información relacionada con la empresa o sus ámbitos y con datos económicos.
Mediante las herramientas y técnicas ELT (extraer, cargar y transformar), o actualmente ETL (extraer, transformar y cargar) se extraen los datos de distintas fuentes, se depuran y preparan (homogeneización de los datos) para luego cargarlos en un almacén de datos. Los origenes de datos habituales pueden ser las aplicaciones de Gestión Empresarial (ERP´s), estudios de mercado, ficheros de datos internos o externos a la empresa en diferentes formatos y destructurados, etc. El almacén de datos o Datawarehouse es una base de datos enfocada exclusivamente al análisis de la información, por lo que se utiliza, según el uso que se la vaya a dar, técnicas especificas de diseño a la hora de construirla. Los datos provenientes de diferentes fuentes se normalizan para poder integrarlos de forma conjunta y posibilitar el posterior análisis.
Por último, las herramientas de inteligencia analítica posibilitan el analísis de esta información que hemos incluido en el DataWarehouse con diferentes metodologías, objetivos y tecnologías, como veremos mas adelante en mas detalle.
Características de herramientas y metodologías de BI
Este conjunto de herramientas y metodologías tienen en común las siguientes características:
- Accesibilidad a la información. Los datos son la fuente principal de este concepto. Lo primero que deben garantizar este tipo de herramientas y técnicas será el acceso de los usuarios a los datos con independencia de la procedencia de estos.
- Apoyo en la toma de decisiones. Se busca ir más allá en la presentación de la información, de manera que los usuarios tengan acceso a herramientas de análisis que les permitan seleccionar y manipular sólo aquellos datos que les interesen.
- Orientación al usuario final. Se busca independencia entre los conocimientos técnicos de los usuarios y su capacidad para utilizar estas herramientas.
Niveles de realización de BI (Herramientas de Explotacion)
De acuerdo a su nivel de complejidad se pueden clasificar las soluciones de Business Intelligence en:
- Consultas e informes simples (Querys y reports).
- Cubos OLAP (On-Line Analytic Processing). Exploración, tablas dinámicas, etc.
- EIS: Soluciones que permiten visualizar, de una forma rápida y fácil, el estado de una determinada situación empresarial, presente o pasada, y que permite detectar anomalías o oportunidades.
- DSS: Aplicación informática que basándose en modelos matemáticos y mediante análisis de sensibilidad permite ayudar a la toma de decisiones.
- Data Mining o minería de datos: Pueden considerarse sistemas expertos que nos permiten “interrogar a los datos” para obtener información
- KMS: nuevas tecnologias para la gestión del conocimiento y su integración en una única plataforma.
En definitiva, una solución BI completa, utilizando la combinación de estos elementos, nos permitiria:
- Observar ¿qué está ocurriendo?
- Comprender ¿por qué ocurre?
- Predecir ¿qué ocurriría?
- Colaborar ¿qué debería hacer el equipo?
- Decidir ¿qué camino se debe seguir?
A continuación, veremos un poco mas en profundidad en que consiste el Datawarehouse, así las diferentes soluciones de BI que podremos desarrollar, profundizando en la teoría de cada una de ellas.
Y como para aprender no hay nada como escuchar y leer a los que hace algún tiempo tuvieron el mismo proposito que nosotros (aprender sobre el mundo BI), os recomiendo el link:
Business Intelligence, por donde empezar, donde el bloguero Salvador Ramos contesta a un hipotetico asistente a un curso sobre los pasos a seguir para formarse en la materia.
Recomendación eBook de BI
Para terminar, os recomiendo que os leais el libro: Business Intelligence: Competir con información de Josep Lluis Cano (gracias a Miguel Angel Perez por encontrarlo).
El libro es un recorrido muy completo por todos los componentes y terminologia del Business Intelligence, desde aspectos generales, teoria, modelado de datos, componentes que forman un sistema BI, elementos a considerar en un proyecto, criterios para selección de herramientas. Incluye lista de herramientas de BI mas importantes (también OpenSource) y ejemplos prácticos de proyectos en diferentes compañias (Cortefiel, Codorniu, Loteria y Apuestas del Estado, etc.), identificando las herramientas que se usaron en cada uno de ellos, objetivos, implementadores. Ademas incluye muchos ejemplos prácticos de cada concepto conforme se van desarrollando dentro del libro.
Totalmente recomendable.
Soluciones de Business Intelligence
Soluciones de Business Intelligence respinosamilla 25 February, 2010 - 20:55Un esquema simplificado de los elementos que conforman un sistema Business Intelligence podría ser el siguiente:
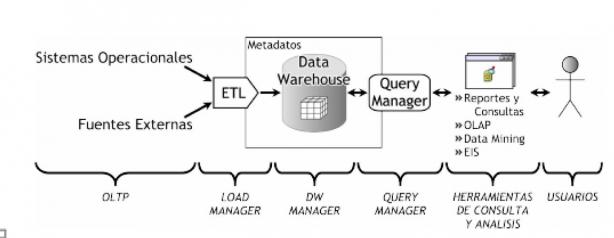
De acuerdo a su nivel de complejidad se pueden clasificar las soluciones de Business Intelligence en:
•Consultas e informes simples (Querys y reports): mediante consultas sobre la base de datos o con herramientas de generación de informes, podemos obtener información simple en multiples formatos. Serían las herramientas que nos permiten que el usuario se construya sus propios reportes. Es el nivel mas simple de solución dentro del BI. Por ejemplo, un informe típico podrían ser las ventas por familia, por zona geográfica, el número de empleados y coste salarial por delegación, etc. Estaría destinado a usuarios con una aptitud técnica limitada y orientado a analizar de una forma sencilla tipo foto la información histórica. Los generadores de informes son cada vez mas avanzados, permitiendonos definir multiples formatos de presentación, definición de filtros, exportación de los datos obtenidos a multiples formatos (excel, pdf, etc), plantillas, campos calculados, totalización, agrupación, etc. Nos permitirian contestar a la pregunta “¿que sucedio?”.
•Cubos OLAP (On-Line Analytic Processing). Exploración, tablas dinámicas, etc. El siguiente paso es pasar de la visión estática de los datos a una visión dinámica, donde podemos ir “navegando” por los datos, bajando en el nivel de detalle, cambiando la dimensión por la cual analizamos la información. El tipico ejemplo sería una tabla con los datos de ventas y margenes por delegación de una empresa, y cuando observamos un indicador de rentabilidad negativa, buceamos en los datos de esta delegación hasta dar con el producto que se esta vendiendo a precios de coste con margen negativo. Este sería el tipico ejemplo de los Cubos Olap y los visores multidimensionales que nos permiten “profundizar en los datos”. Nos permitirían contestar a la pregunta: ¿que sucedio y por que?.
•EIS (Executive information system): Soluciones que permiten visualizar, de una forma rápida y fácil, el estado de una determinada situación empresarial, presente o pasada, y que permite detectar anomalías o oportunidades. Aplicaciones de alto nivel que pretenden, mediante el acceso a las diferentes bases de datos de una empresa, ofrecer a sus directivos los elementos clave para que puedan tomar decisiones sobre la marcha de sus negocios. Generalmente el directivo accede a pantallas gráficas o cuadros de mando en las que se resumen los elementos más importantes que debe tener en cuenta para la toma de decisiones. Podrían contestar a la pregunta: ¿que necesito conocer ahora?.
•DSS: Aplicación informática que basándose en modelos matemáticos y mediante análisis de sensibilidad permite ayudar a la toma de decisiones.
•Data Mining o minería de datos: Pueden considerarse sistemas expertos que nos permiten “interrogar a los datos” para obtener información. Consiste en la extracción no trivial de información que reside de manera implícita en los datos. Dicha información era previamente desconocida y podrá resultar útil para algún proceso. En otras palabras, la minería de datos prepara, sondea y explora los datos para sacar la información oculta en ellos. Las bases de la minería de datos se encuentran en la inteligencia artificial y en el análisis estadístico. Mediante los modelos extraídos utilizando técnicas de minería de datos se aborda la solución a problemas de predicción, clasificación y segmentación. Un ejemplo podría ser una entidad bancaria que buceando en los datos de sus clientes puede determinar nuevos segmentos de mercado a los que ofrecer determinados productos o el tipico supermercado que analizando las ventas en una franja horaria determinada, es capaz de realizar promociones de determinados productos que se venden mas en determinadas horas (el tipico ejemplo de las ventas de pañales y cerveza). Contestarian a las preguntas: ¿que es interesante?, ¿que podría pasar?.
•KMS: nuevas tecnologicas para la gestión del conocimiento y su integración en una única plataforma. Son herramienta no relacionadas directamente con el Business Intelligence, pero nos permiten gestionar toda la información y el conocimiento que hay en la empresa para poder sacar un mayor partido de ella. Por ejemplo, toda la documentación interna, manuales, procedimientos que existe en la empresa esta guardada en un gestor documental que una vez indexado, se puede consultar por los integrantes de la organización de una forma ágil. Al fin y al cabo, la información es poder y cuanto mas rapida se pueda obtener, mas beneficios genera.
Las soluciones de Bussiness Intelligence varían según las necesidades de los usuarios, sus perfiles, su necesidad de información, etcetera. Estos elementos serán los que determinen el tipo de herramienta a elegir, aunque muchas veces podremos utilizar combinaciones de ellas para cubrir nuestras necesidades.
Vamos a profundizar en cada una de las soluciones de Business Intelligence, con aspectos más especificos, presentado ejemplos de cada una de las soluciones y enumerando las mas importantes que encontramos en el mercado (tanto a nivel propietario como de Open Source).
Consultas e informes simples (Querys y reports)
Consultas e informes simples (Querys y reports) respinosamilla 25 February, 2010 - 21:00Serian todas aquellas herramientas que nos van a permitir realizar consultas o informes (querys o reports) para obtener información sobre los datos.
Este tipo de herramientas las podemos utilizar en dos ambitos:
-Entorno transaccional: desde las herramientas de informes o querys, atacamos directamente a la base de datos donde se registran las transacciones cotidianas de la empresa. En este entorno, las consultas son mucho mas complejas, los tiempos de respuesta son mayores y seguramente estaremos interfiriendo con otros procesos informaticos que comparten la plataforma (imaginemos el ejemplo de una lectura historica de datos años atras, en el mismo servidor donde se esta realizando la facturación de clientes).
-Entorno del Data warehouse: atacamos directamente a la base de datos que esta optimizada para el análisis. Utilizamos una estructura y tecnología muchos mas apropiada y obtenemos mejores resultados, velocidad, etc.
Por ejemplo, un informe típico podrían ser las ventas por familia, por zona geográfica, el número de empleados y coste salarial por delegación, etc. Estaría destinado a usuarios con una aptitud técnica limitada y orientado a analizar de una forma sencilla tipo foto la información histórica.
Las herramientas de informes y querys son cada vez mas avanzadas, permitiendonos definir multiples formatos de presentación, definición de filtros, exportación de los datos obtenidos a multiples formatos (excel, pdf, etc), plantillas, campos calculados, totalización, agrupación, etc. Igualmente, dispondremos de diferentes tipos de gráficos que nos permitiran ver la información de diferentes modos (charts, semaforos, graficos de barras, de tarta,etc, etc). Nos permitirian contestar a la pregunta “¿que sucedio?”.
De cara a la utilización de este tipo de herramientas, podemos definir varios niveles de utilización según la experiencia y formación del usuario, que podrían ser:
•Los usuarios poco expertos podrán solicitar la ejecución de informes
o querys predefinidas según unos parámetros predeterminados (preparamos un repositorio de informes ya diseñados, y el usuario simplemente indicara los criterios de selección al ejecutarlos).
•Los usuarios con cierta experiencia podrán generar querys flexibles mediante una aplicación que proporcione una interfaz gráfica de ayuda.
•Los usuarios altamente experimentados podrán escribir, total o parcialmente, la consulta en un lenguaje de interrogación de datos.
Las herramientas igualmente nos pueden ofrecer funcionalidades adicionales para la distribución de los informes realizados en el ambito de la organización, scheduling para la realización de cálculos, utilización de plantillas e informes predefinidos, repositorios de informes, filtros, etc.
Algunas herramientas para reporting Propietarias son (aunque existen una multitud de herramientas y cada una de ellas podrá ser apropiada según nuestras necesidades):
1. Oracle BI Publisher
2. Microsoft Reporting Services
3. BusinessObjects Crystal Reports (SAP)
4. Microstrategy
5. Information Builders
6. IBM Cognos
Algunas herramientas para reporting de Opensource ( gracias a Todobi.com):
1. BIRT Project (Actuate)
2. Pentaho
3. OpenRPT
4. OpenReports
5. FreeReportBuilder
6. Magallanes
7. ART – A lightweight reporting solution
8. DataVision
9. The Wabit – Open Source Reporting Tool
10. Rilb
11. JavaEye Reporting Tool – JERT
12. iReport
Cubos OLAP (On-Line Analytic Processing)
Cubos OLAP (On-Line Analytic Processing) respinosamilla 25 February, 2010 - 09:50Cubos OLAP (On-Line Analytic Processing): Son las herramientas que se basan en la capacidad de analizar y explorar por los datos. Nos permiten cambiar el enfoque del “¿que esta pasando?” que podemos obtener a través de las herramientas de reporting al “¿por que esta pasando?”.
Para descubrir el “por que”, los usuarios pueden navegar y profundizar en los datos para analizar los detalles o patrones.Las herramientas OLAP nos proporcionan analisis interactivo por las diferentes dimensiones de los datos (por ejemplo, tiempo, producto, cliente, criterios geográficos, etc) y por los diferentes niveles de detalle (para la dimensión tiempo, habrá nivel de detalle año, trimestre, mes, dia).
Esto significaría pasar de la visión estática de los datos a una visión dinámica, donde podemos ir “navegando” por los datos, bajando en el nivel de detalle, cambiando la dimensión por la cual analizamos la información. El tipico ejemplo sería una tabla con los datos de ventas y margenes por delegación de una empresa, y cuando observamos un indicador de rentabilidad negativa, buceamos en los datos de esta delegación hasta dar con el producto que se esta vendiendo a precios de coste con margen negativo. Este sería el tipico ejemplo de los Cubos Olap y los visores multidimensionales que nos permiten “profundizar en los datos”. Nos permitirían contestar a la pregunta: ¿que sucedio y por que?.

Ejemplo de Visor Olap (Palo Web Client)
Para entender qué se analiza mediante los cubos Olap, hemos de saber que la información de gestión se compone de conceptos de información (dimensiones) y coeficientes de gestión (indicadores), que los cuadros directivos de la empresa pueden consultar según las dimensiones de negocio que se definan.Dichas dimensiones de negocio se estructuran a su vez en distintos niveles de detalle (por ejemplo, la dimensión geográfica puede constar de los niveles nacional, provincial, ayuntamientos y sección censal).
Este tipo de sistemas ha existido desde hace tiempo, en el mundo de la informática bajo distintas denominaciones: cuadros de mando, MIS, EIS, etc.
En general, los sistemas OLAP deben:
- Soportar requerimientos complejos de análisis.
- Analizar datos desde diferentes perspectivas.
- Soportar análisis complejos contra un volumen ingente de datos.
La funcionalidad de los sistemas OLAP se caracteriza por ser un análisis multidimensional de datos corporativos, que soportan los análisis del usuario y unas posibilidades de navegación, seleccionando la información a obtener. Normalmente este tipo de selecciones se ve reflejada en la visualización de la estructura multidimensional, en unos campos de selección que nos permitan elegir el nivel de agregación (jerarquía) de la dimensión, y/o la elección de un dato en concreto, la visualización de los atributos del sujeto, frente a una(s) dimensiones en modo tabla, pudiendo con ello realizar, entre otras las siguientes acciones:
- Rotar (Swap): alterar las filas por columnas (permutar dos dimensiones de análisis)
- Bajar (Down): bajar el nivel de visualización en las filas a una jerarquía inferior.
- Detallar (Drilldown): informar para una fila en concreto, de datos a un nivel inferior.
- Expandir (Expand): id. anterior sin perder la información a nivel superior para éste y el resto de los valores.
- Colapsar (Collapse): operación inversa de la anterior.
Para ampliar el glosario de conceptos OLAP y de otros relacionados con el mundo BI, os recomiendo la visita a la página:
https://www.dssresources.com/glossary/olaptrms.html
Tal y como la tecnología y los usuarios han evolucionado y madurado, las distinciones entre OLAP y las herramientas de reporting se han vuelto considerablemente confusas. Podemos tener informes bien formateados o sumarizados basados en datos multidimensionales y el usuario querrá enseguida navegar y bucear en los datos para ver el problema con una metrica en particular. En este caso, el usuario no querra ser forzado a tener que pasar a una herramienta separada para analizar y explorar. Las siguientes características continuan distinguiendo las herramientas OLAP de las herramientas de query y reporting tools:
- En una herramienta Multidimensional los usuarios analizan los valores numericos de diferentes dimensiones (como producto, tiempo, geografia). En un informe, por otro lado, solo hay una dimensión de análisis.
- El cambio entre las diferentes dimensionales de analisis y los diferentes niveles de ellas es muy rápido en este tipo de herramientas. Si un usuario hace un doble click en la dimensión tiempo, en el nivel Año, rapidamente va a poder ver la información de un mes o de un día en concreto, sin tiempos de espera excesivos. En un informe, los tiempos de calculo pueden ser muy considerables (hasta llegar incluso al punto de tener que se programados en procesos batch su ejecución).
- La herramienta Olap es sumamente interactiva, permitiendonos pivotar sobre la información viendola desde diferentes perspectivas y cambiar dichas perspectivas de una forma muy rapida. Analizando las ventas por mes, podremos cambiar la visión de la información para verla por producto o por tipo de cliente. Ademas se pueden establecer filtrados interactivos y el desglose de la información se puede realizar para un subconjunto de la dimension en concreto. Este tipo de interacción con los datos es imposible con los informes (aunque posible en algunos productos).
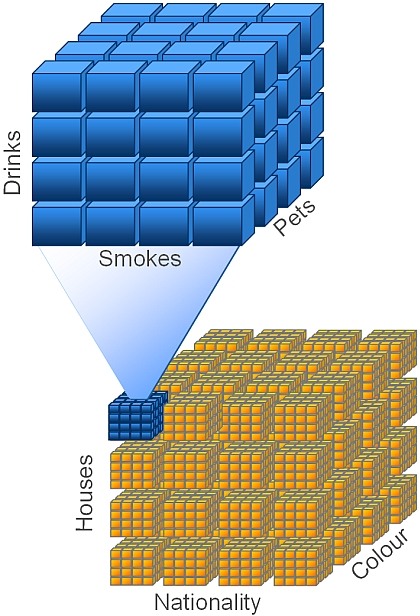
Para distinguir los requerimientos OLAP, es importante distinguir entre las plataformas OLAP y los interfases de usuario OLAP.
Plataformas OLAP
La plataforma OLAP es aquella en la que se almacenan los datos para permitir el análisis multidimensional. El cubo mostrado en la imagen superior representa una base de datos OLAP. En este contexto, los usuarios finales no tendrán que preocuparse como se almacena la información, si se replica, tiene cache o que tipo de arquitectura utiliza, pero todos estos aspectos si influiran en que tipo de herramienta front-end puede utilizar, que podrá analizar y como.
Hay cuatro tipos de arquitectura OLAP:
1.Relational OLAP (ROLAP): este tipo de plataforma almacena los datos en una base de datos relacional, lo que implica que no es necesario que los datos se repliquen en un almacenamiento separado para el análisis (veremos que en la mayoría de los casos es preferible esta diferenciación). Los calculos se realizan en una base de datos relacional, con grandes volumenes de datos y tiempos de navegación no predecibles. Parte de la premisa que las capacidades Olap se desarrollan mejor contra este tipo de bases de datos.
El sistema ROLAP utiliza una arquitectura de tres niveles. La base de datos relacional maneja los requerimientos de almacenamiento de datos, y el motor ROLAP proporciona la funcionalidad analítica.
- El nivel de base de datos usa bases de datos relacionales para el manejo, acceso y obtención del dato.
- El nivel de aplicación es el motor que ejecuta las consultas multidimensionales de los usuarios.
- El motor ROLAP se integra con niveles de presentación, a través de los cuales los usuarios realizan los análisis OLAP.
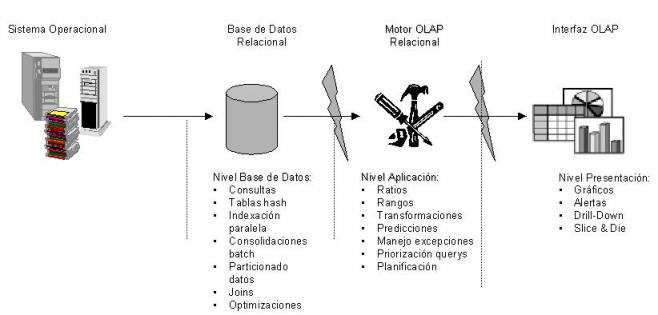
Los usuarios finales ejecutan sus análisis multidimensionales, a través del motor ROLAP, que transforma dinámicamente sus consultas a consultas SQL. Se ejecutan estas consultas SQL en las bases de datos relacionales, y sus resultados se relacionan mediante tablas cruzadas y conjuntos multidimensionales para devolver los resultados a los usuarios.
La arquitectura ROLAP es capaz de usar datos precalculados si estos están disponibles, o de generar dinámicamente los resultados desde los datos elementales si es preciso. Esta arquitectura accede directamente a los datos del Data Warehouse, y soporta técnicas de optimización de accesos para acelerar las consultas. Estas optimizaciones son, entre otras, particionado de los datos a nivel de aplicación, soporte a la desnormalización y joins múltiples.
Algunos fabricantes son: Oracle’s BI EE, SAP Netweaver BI, MicroStrategy, Cognos 8, BusinessObjects Web Intelligence.
2. Multidimensional OLAP (MOLAP):los datos son replicados en plataformas con un almacenamiento construido a proposito que asegura mayor velocidad en los análisis. Los calculos se llevan a cabo en un servidor con una base de datos multidimensional, partiendo de la premisa que un sistema OLAP estara mejor implantado almacenando los datos multidimensionalmente.
El sistema MOLAP utiliza una arquitectura de dos niveles: La bases de datos multidimensionales y el motor analítico.
- La base de datos multidimensional es la encargada del manejo, acceso y obtención del dato.
- El nivel de aplicación es el responsable de la ejecución de los requerimientos OLAP. El nivel de presentación se integra con el de aplicación y proporciona un interfaz a través del cual los usuarios finales visualizan los análisis OLAP. Una arquitectura cliente/servidor permite a varios usuarios acceder a la misma base de datos multidimensional.
La información procedente de los sistemas operacionales, se carga en el sistema MOLAP, mediante una serie de rutinas batch. Una vez cargado el dato elemental en la Base de Datos multidimensional (MDDB), se realizan una serie de cálculos en batch, para calcular los datos agregados, a través de las dimensiones de negocio, rellenando la estructura MDDB. Tras rellenar esta estructura, se generan unos índices y algoritmos de tablas hash para mejorar los tiempos de accesos a las consultas.
Una vez que el proceso de compilación se ha acabado, la MDDB está lista para su uso. Los usuarios solicitan informes a través del interface, y la lógica de aplicación de la MDDB obtiene el dato. La arquitectura MOLAP requiere unos cálculos intensivos de compilación. Lee de datos precompilados, y tiene capacidades limitadas de crear agregaciones dinámicamente o de hallar ratios que no se hayan precalculados y almacenados previamente.
Algunos fabricantes son: Oracle’s Hyperion Essbase, Microsoft Analysis Services, TM1, SAS OLAP, Cognos PowerCubes.
3. Hybrid OLAP (HOLAP): plataformas que usan una combinación de varias técnicas de almacenamiento.Las agregaciones se realizan en cache, pero el drill-down a traves de la base de datos relacional. Algunos fabricantes son: Microsoft Analysis Services, SAS OLAP, Oracle’s Hyperion Essbase.
4. Dynamic OLAP (DOLAP): generan una pequeña cache multidimensional cuando los usuarios ejecutan las consultas contra la base de datos. Algunos fabricantes son: BusinessObjects Web Intelligence, Oracle’s Hyperion Interactive Reporting(formerly Brio).
ROLAP vs. MOLAP (Comparativa)
Cuando se comparan las dos arquitecturas, se pueden realizar las siguientes observaciones:
El ROLAP delega la negociación entre tiempo de respuesta y el proceso batch al diseño del sistema. Mientras, el MOLAP, suele requerir que sus bases de datos se precompilen para conseguir un rendimiento aceptable en las consultas, incrementando, por tanto los requerimientos batch.
- Los sistemas con alta volatilidad de los datos (aquellos en los que cambian las reglas de agregación y consolidación), requieren una arquitectura que pueda realizar esta consolidación ad-hoc. Los sistemas ROLAP soportan bien esta consolidación dinámica, mientras que los MOLAP están más orientados hacia consolidaciones batch.
- Los ROLAP pueden crecer hasta un gran número de dimensiones, mientras que los MOLAP generalmente son adecuados para diez o menos dimensiones.
- Los ROLAP soportan análisis OLAP contra grandes volúmenes de datos elementales, mientras que los MOLAP se comportan razonablemente en volúmenes más reducidos (menos de 5 Gb).
- Por ello, y resumiendo, el ROLAP es una arquitectura flexible y general, que crece para dar soporte a amplios requerimientos OLAP. El MOLAP es una solución particular, adecuada para soluciones departamentales con unos volúmenes de información y número de dimensiones más modestos.
Visores OLAP
Los visores Olap son las herramientas que nos permiten “atacar” a la base de datos OLAP para sacar todo el partido a los datos con las consideraciones que hemos indicado. Una de las herramientas mas utilizada para visualizar el cubo es Microsoft Excel. De hecho, tres de los productos Olap lideres la utilizaron inicialmente como unico interfaz (Oracle’s Hyperion Essbase, Microsoft Analysis Services, SAP Business Explorer). Con Excel, los usuarios abren su hoja e inmediatamente pueden hacen drill en las celdas y en las Excel Pivot Tables para recuperar y explorar sus datos.
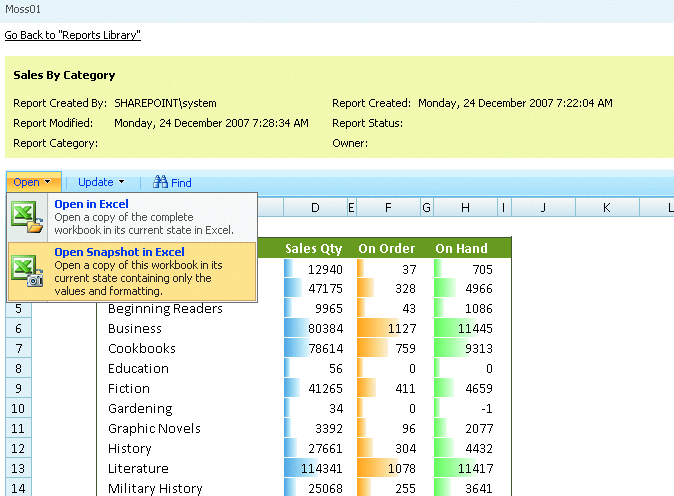
Ejemplo de Excel comoVisor Olap
Hoy en dia, Excel continua siendo una importante interfaz OLAP, pero ademas, los usuarios pueden explorar los datos a traves de los visores OLAP. Hay visores basados en Web, que ademas tienen capacidades de navegacion y charting avanzadas. Tambien pueden disponer de herramientas de query y de generación de informes.
Expresiones Multidimensionales (MDX): en un lenguaje query similar al SQL que nos permite realizar consultas sobre una base de datos OLAP. Microsoft desarrollo este lenguaje para trabajar con su servidor OLAP, y al ganar el MDX aceptación entre la industria, un gran numero de fabricantes la incorporaron a sus bases de datos, de forma que hoy muchos visores OLAP generan MDX para acceder y analizar los datos de diferentes bases de datos OLAP.
Igual que las herramientas de query y reporting permiten a los usuarios recuperar información de las bases de datos relaciones sin conocer el lenguaje SQL, los visores OLAP nos permiten acceder a los datos de un BD Olap sin necesidad de conocer las expresiones multidimiensionales del lenguaje MDX.
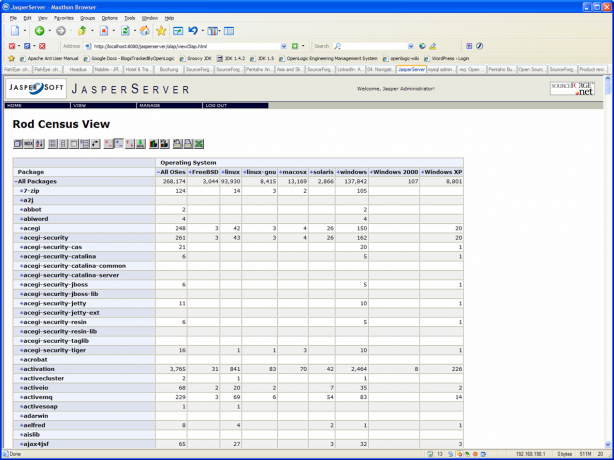
Ejemplo de Visor Olap (Jpivot)
Una relación de visores OLAP Open Source la podemos encontrar en la web de todobi.com.
Hola a todos tengo un archivo
- Log in to post comments
EIS (Executive information system). Cuadros de Mando Integral. DSS (Decission Support System)
EIS (Executive information system). Cuadros de Mando Integral. DSS (Decission Support System) respinosamilla 25 February, 2010 - 10:00Sistema de Información para Ejecutivos
Definiciones obtenidas de la web: https://www.sinnexus.com/business_intelligence/
Soluciones que permiten visualizar, de una forma rápida y fácil, el estado de una determinada situación empresarial, presente o pasada, y que permite detectar anomalías o oportunidades. Aplicaciones de alto nivel que pretenden, mediante el acceso a las diferentes bases de datos de una empresa, ofrecer a sus directivos los elementos clave para que puedan tomar decisiones sobre la marcha de sus negocios. Generalmente el directivo accede a pantallas gráficas o cuadros de mando en las que se resumen los elementos más importantes que debe tener en cuenta para la toma de decisiones. Podrían contestar a la pregunta: ¿que necesito conocer ahora?.
Un Sistema de Información para Ejecutivos o Sistema de Información Ejecutiva es una herramienta software, basada en un DSS, que provee a los gerentes de un acceso sencillo a información interna y externa de su compañía, y que es relevante para sus factores clave de éxito.
La finalidad principal es que el ejecutivo tenga a su disposición un panorama completo del estado de los indicadores de negocio que le afectan al instante, manteniendo también la posibilidad de analizar con detalle aquellos que no estén cumpliendo con las expectativas establecidas, para determinar el plan de acción más adecuado.
De forma más pragmática, se puede definir un EIS como una aplicación informática que muestra informes y listados (query & reporting) de las diferentes áreas de negocio, de forma consolidada, para facilitar la monitorización de la empresa o de una unidad de la misma.
El EIS se caracteriza por ofrecer al ejecutivo un acceso rápido y efectivo a la información compartida, utilizando interfaces gráficas visuales e intutivas. Suele incluir alertas e informes basados en excepción, así como históricos y análisis de tendencias. También es frecuente que permita la domiciliación por correo de los informes más relevantes.
A través de esta solución se puede contar con un resumen del comportamiento de una organización o área específica, y poder compararla a través del tiempo. Es posible, además, ajustar la visión de la información a la teoría de Balanced Scorecard o Cuadro de Mando Integral impulsada por Norton y Kaplan, o bien a cualquier modelo estratégico de indicadores que maneje la compañía.
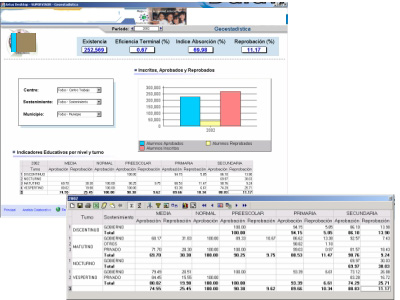
Cuadro de Mando Integral
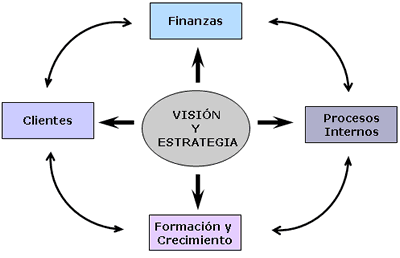
El Cuadro de Mando Integral (CMI), también conocido como Balanced Scorecard (BSC) o dashboard, es una herramienta de control empresarial que permite establecer y monitorizar los objetivos de una empresa y de sus diferentes áreas o unidades.
También se puede considerar como una aplicación que ayuda a una compañía a expresar los objetivos e iniciativas necesarias para cumplir con su estrategia, mostrando de forma continuada cuándo la empresa y los empleados alcanzan los resultados definidos en su plan estratégico.
Diferencia con otras herramientas de Business Intelligence
El Cuadro de Mando Integral se diferencia de otras herramientas de Business Intelligence, como los Sistemas de Soporte a la Decisión (DSS) o los Sistemas de Información Ejecutiva (EIS), en que está más orientados al seguimiento de indicadores que al análisis minucioso de información. Por otro lado, es muy común que un CMI sea controlado por la dirección general de una compañía, frente a otras herramientas de Business Intelligence más enfocadas a a la dirección departamental. El CMI requiere, por tanto, que los directivos analicen el mercado y la estrategia para construir un modelo de negocio que refleje las interrelaciones entre los diferentes componentes de la empresa (plan estratégico). Una vez que lo han construido, los responsables de la organización utilizan este modelo como mapa para seleccionar los indicadores del CMI.
Tipos de Cuadros de Mando
El Cuadro de Mando Operativo (CMO), es una herramienta de control enfocada al seguimiento de variables operativas, es decir, variables pertenecientes a áreas o departamentos específicos de la empresa. La periodicidad de los CMO puede ser diaria, semanal o mensual, y está centrada en indicadores que generalmente representan procesos, por lo que su implantación y puesta en marcha es más sencilla y rápida. Un CMO debería estar siempre ligado a un DSS (Sistema de Soporte a Decisiones) para indagar en profundidad sobre los datos.
El Cuadro de Mando Integral (CMI), por el contrario, representa la ejecución de la estrategia de una compañía desde el punto de vista de la Dirección General (lo que hace que ésta deba estar plenamente involucrada en todas sus fases, desde la definición a la implantación). Existen diferentes tipos de cuadros de mando integral, si bien los más utilizados son los que se basan en la metodología de Kaplan & Norton. La principales características de esta metodología son que utilizan tanto indicadores financieros como no financieros, y que los objetivos estratégicos se organizan en cuatro áreas o perspectivas: financiera, cliente, interna y aprendizaje/crecimiento.
 La perspectiva financiera incorpora la visión de los accionistas y mide la creación de valor de la empresa. Responde a la pregunta: ¿Qué indicadores tienen que ir bien para que los esfuerzos de la empresa realmente se transformen en valor? Esta perspectiva valora uno de los objetivos más relevantes de organizaciones con ánimo de lucro, que es, precisamente, crear valor para la sociedad.
La perspectiva financiera incorpora la visión de los accionistas y mide la creación de valor de la empresa. Responde a la pregunta: ¿Qué indicadores tienen que ir bien para que los esfuerzos de la empresa realmente se transformen en valor? Esta perspectiva valora uno de los objetivos más relevantes de organizaciones con ánimo de lucro, que es, precisamente, crear valor para la sociedad.
La perspectiva del cliente refleja el posicionamiento de la empresa en el mercado o, más concretamente, en los segmentos de mercado donde quiere competir. Por ejemplo, si una empresa sigue una estrategia de costes es muy posible que la clave de su éxito dependa de una cuota de mercado alta y unos precios más bajos que la competencia. Dos indicadores que reflejan este posicionamiento son la cuota de mercado y un índice que compare los precios de la empresa con los de la competencia.
La perspectiva interna recoge indicadores de procesos internos que son críticos para el posicionamiento en el mercado y para llevar la estrategia a buen puerto. En el caso de la empresa que compite en coste, posiblemente los indicadores de productividad, calidad e innovación de procesos sean importantes. El éxito en estas dimensiones no sólo afecta a la perspectiva interna, sino también a la financiera, por el impacto que tienen sobre las rúbricas de gasto.
La perspectiva de aprendizaje y crecimiento es la última que se plantea en este modelo de CMI. Para cualquier estrategia, los recursos materiales y las personas son la clave del éxito. Pero sin un modelo de negocio apropiado, muchas veces es difícil apreciar la importancia de invertir, y en épocas de crisis lo primero que se recorta es precisamente la fuente primaria de creación de valor: se recortan inversiones en la mejora y el desarrollo de los recursos.
Pese a que estas cuatro son las perspectivas más genéricas, no son “obligatorias”. Por ejemplo, una empresa de fabricación de ropa deportiva tiene, además de la perspectiva de clientes, una perspectiva de consumidores. Para esta empresa son tan importantes sus distribuidores como sus clientes finales.
Una vez que se tienen claros los objetivos de cada perspectiva, es necesario definir los indicadores que se utilizan para realizar su seguimiento. Para ello, debemos tener en cuenta varios criterios: el primero es que el número de indicadores no supere los siete por perspectiva, y si son menos, mejor. La razón es que demasiados indicadores difuminan el mensaje que comunica el CMI y, como resultado, los esfuerzos se dispersan intentando perseguir demasiados objetivos al mismo tiempo. Puede ser recomendable durante el diseño empezar con una lista más extensa de indicadores. Pero es necesario un proceso de síntesis para disponer de toda la fuerza de esta herramienta.
No obstante, la aportación que ha convertido al CMI en una de las herramientas más significativas de los últimos años es que se cimenta en un modelo de negocio. El éxito de su implantación radica en que el equipo de dirección se involucre y dedique tiempo al desarrollo de su propio modelo de negocio.
Beneficios de la implantación de un Cuadro de Mando Integral
- La fuerza de explicitar un modelo de negocio y traducirlo en indicadores facilita el consenso en toda la empresa, no sólo de la dirección, sino también de cómo alcanzarlo.
- Clarifica cómo las acciones del día a día afectan no sólo al corto plazo, sino también al largo plazo.
- Una vez el CMI está en marcha, se puede utilizar para comunicar los planes de la empresa, aunar los esfuerzos en una sola dirección y evitar la dispersión. En este caso, el CMI actúa como un sistema de control por excepción.
- Permita detectar de forma automática desviaciones en el plan estratégico u operativo, e incluso indagar en los datos operativos de la compañía hasta descubrir la causa original que dió lugar a esas desviaciones.
Riesgos de la implantación de un Cuadro de Mando Integral
- Un modelo poco elaborado y sin la colaboración de la dirección es papel mojado, y el esfuerzo será en vano.
- Si los indicadores no se escogen con cuidado, el CMI pierde una buena parte de sus virtudes, porque no comunica el mensaje que se quiere transmitir.
- Cuando la estrategia de la empresa está todavía en evolución, es contraproducente que el CMI se utilice como un sistema de control clásico y por excepción, en lugar de usarlo como una herramienta de aprendizaje.
- Existe el riesgo de que lo mejor sea enemigo de lo bueno, de que el CMI sea perfecto, pero desfasado e inútil.
Podeis ampliar información en la monografía realizada por Francisco Martínez Fernández.
Sistemas de Soporte a la Decisión (DSS)
Un Sistema de Soporte a la Decisión (DSS) es una herramienta de Business Intelligence enfocada al análisis de los datos de una organización.
En principio, puede parecer que el análisis de datos es un proceso sencillo, y fácil de conseguir mediante una aplicación hecha a medida o un ERP sofisticado. Sin embargo, no es así: estas aplicaciones suelen disponer de una serie de informes predefinidos en los que presentan la información de manera estática, pero no permiten profundizar en los datos, navegar entre ellos, manejarlos desde distintas perspectivas… etc.
El DSS es una de las herramientas más emblemáticas del Business Intelligence ya que, entre otras propiedades, permiten resolver gran parte de las limitaciones de los programas de gestión. Estas son algunas de sus características principales:
Informes dinámicos, flexibles e interactivos, de manera que el usuario no tenga que ceñirse a los listados predefinidos que se configuraron en el momento de la implantación, y que no siempre responden a sus dudas reales.
No requiere conocimientos técnicos. Un usuario no técnico puede crear nuevos gráficos e informes y navegar entre ellos, haciendo drag&drop o drill through. Por tanto, para examinar la información disponible o crear nuevas métricas no es imprescindible buscar auxilio en el departamento de informática.
Rapidez en el tiempo de respuesta, ya que la base de datos subyacente suele ser un datawarehouse corporativo o un datamart, con modelos de datos en estrella o copo de nieve. Este tipo de bases de datos están optimizadas para el análisis de grandes volúmenes de información (vease ánalisis OLTP-OLAP).
Integración entre todos los sistemas/departamentos de la compañía. El proceso de ETL previo a la implantación de un Sistema de Soporte a la Decisión garantiza la calidad y la integración de los datos entre las diferentes unidades de la empresa. Existe lo que se llama: integridad referencial absoluta.
Cada usuario dispone de información adecuada a su perfil. No se trata de que todo el mundo tenga acceso a toda la información, sino de que tenga acceso a la información que necesita para que su trabajo sea lo más eficiente posible.
Disponibilidad de información histórica. En estos sistemas está a la orden del día comparar los datos actuales con información de otros períodos históricos de la compañía, con el fin de analizar tendencias, fijar la evolución de parámetros de negocio… etc.
Diferencia con otras herramientas de Business Intelligence
El principal objetivo de los Sistemas de Soporte a Decisiones es, a diferencia de otras herramientas como los Cuadros de Mando (CMI) o los Sistemas de Información Ejecutiva (EIS), explotar al máximo la información residente en una base de datos corporativa (datawarehouse o datamart), mostrando informes muy dinámicos y con gran potencial de navegación, pero siempre con una interfaz gráfica amigable, vistosa y sencilla.
Otra diferencia fundamental radica en los usuarios a los que están destinadas las plataformas DSS: cualquier nivel gerencial dentro de una organización, tanto para situaciones estructuradas como no estructuradas. (En este sentido, por ejemplo, los CMI están más orientados a la alta dirección).
Por último, destacar que los DSS suelen requerir (aunque no es imprescindible) un motor OLAP subyacente, que facilite el análisis casi ilimitado de los datos para hallar las causas raices de los problemas/pormenores de la compañía.
Tipos de Sistemas de Soporte a Decisiones
Sistemas de información gerencial (MIS)
Los sistemas de información gerencial (MIS, Management Information Systems), tambien llamados Sistemas de Información Administrativa (AIS) dan soporte a un espectro más amplio de tareas organizacionales, encontrándose a medio camino entre un DSS tradicional y una aplicación CRM/ERP implantada en la misma compañía.
Sistemas de información ejecutiva (EIS)
Los sistemas de información ejecutiva (EIS, Executive Information System) son el tipo de DSS que más se suele emplear en Business Intelligence, ya que proveen a los gerentes de un acceso sencillo a información interna y externa de su compañía, y que es relevante para sus factores clave de éxito.
Sistemas expertos basados en inteligencia artificial (SSEE)
Los sistemas expertos, también llamados sistemas basados en conocimiento, utilizan redes neuronales para simular el conocimiento de un experto y utilizarlo de forma efectiva para resolver un problema concreto. Este concepto está muy relacionado con el datamining.
Sistemas de apoyo a decisiones de grupo (GDSS)
Un sistema de apoyo a decisiones en grupos (GDSS, Group Decision Support Systems) es “un sistema basado en computadoras que apoya a grupos de personas que tienen una tarea (u objetivo) común, y que sirve como interfaz con un entorno compartido”. El supuesto en que se basa el GDSS es que si se mejoran las comunicaciones se pueden mejorar las decisiones.
Definiciones obtenidas de la web: https://www.sinnexus.com/business_intelligence/
Algunos de los productos del mercado orientados a EIS y DSS los podemos obtener en la web de Dataprix.com
DataMining o Mineria de Datos.
DataMining o Mineria de Datos. respinosamilla 25 February, 2010 - 09:50Introducción
(Definiciones extraidas del Consejo Superior de Informatica, del documento Manual para la adquisición de un sistema de Data Warehouse, en https://www.csi.map.es/csi/silice/Elogicos.html ).
El Data Mining es un proceso que, a través del descubrimiento y cuantificacion de relaciones predictivas en los datos, permite transformar la información disponible en conocimiento útil de negocio.Esto es debido a que no es suficiente “navegar” por los datos para resolver los problemas de negocio, sino que se hace necesario seguir una metodología ordenada que permita obtener rendimientos tangibles de este conjunto de herramientas y técnicas de las que dispone el usuario.
Constituye por tanto una de las vías clave de explotación del Data Warehouse, dado que es este su entorno natural de trabajo.
Se trata de un concepto de explotación de naturaleza radicalmente distinta a la de los sistemas de información de gestión, dado que no se basa en coeficientes de gestión o en información altamente agregada, sino en la información de detalle contenida en el almacén.
Adicionalmente, el usuario no se conforma con la mera visualización de datos, sino que trata de obtener una relación entre los mismos que tenga repercusiones en su negocio.
Técnicas de Data Mining
Para soportar el proceso de Data Mining, el usuario dispone de una extensa gama de técnicas que le pueden ayudar en cada una de las fases de dicho proceso, las cuales pasamos a describir:
Análisis estadístico:
Utilizando las siguientes herramientas:
1.ANOVA: o Análisis de la Varianza, contrasta si existen diferencias significativas entre las medidas de una o más variables continuas en grupo de población distintos.
2.Regresión: define la relación entre una o más variables y un conjunto de variables predictoras de las primeras.
3.Ji cuadrado: contrasta la hipótesis de independencia entre variables. Componentes principales: permite reducir el número de variables observadas a un menor número de variables artificiales, conservando la mayor parte de la información sobre la varianza de las variables.
4.Análisis cluster: permite clasificar una población en un número determinado de grupos, en base a semejanzas y desemejanzas de perfiles existentes entre los diferentes componentes de dicha población.
5.Análisis discriminante: método de clasificación de individuos en grupos que previamente se han establecido, y que permite encontrar la regla de clasificación de los elementos de estos grupos, y por tanto identificar cuáles son las variables que mejor definan la pertenencia al grupo.
Métodos basados en árboles de decisión:
El método Chaid (Chi Squared Automatic Interaction Detector) es un análisis que genera un árbol de decisión para predecir el comportamiento de una variable, a partir de una o más variables predictoras, de forma que los conjuntos de una misma rama y un mismo nivel son disjuntos. Es útil en aquellas situaciones en las que el objetivo es dividir una población en distintos segmentos basándose en algún criterio de decisión.
El árbol de decisión se construye partiendo el conjunto de datos en dos o más subconjuntos de observaciones a partir de los valores que toman las variables predictoras. Cada uno de estos subconjuntos vuelve después a ser particionado utilizando el mismo algoritmo. Este proceso continúa hasta que no se encuentran diferencias significativas en la influencia de las variables de predicción de uno de estos grupos hacia el valor de la variable de respuesta.
La raíz del árbol es el conjunto de datos íntegro, los subconjuntos y los subsubconjuntos conforman las ramas del árbol. Un conjunto en el que se hace una partición se llama nodo.
El número de subconjuntos en una partición puede ir de dos hasta el número de valores distintos que puede tomar la variable usada para hacer la separación. La variable de predicción usada para crear una partición es aquella más significativamente relacionada con la variable de respuesta de acuerdo con test de independencia de la Chi cuadrado sobre una tabla de contingencia.
Algoritmos genéticos:
Son métodos numéricos de optimización, en los que aquella variable o variables que se pretenden optimizar junto con las variables de estudio constituyen un segmento de información. Aquellas configuraciones de las variables de análisis que obtengan mejores valores para la variable de respuesta, corresponderán a segmentos con mayor capacidad reproductiva. A través de la reproducción, los mejores segmentos perduran y su proporción crece de generación en generación. Se puede además introducir elementos aleatorios para la modificación de las variables (mutaciones). Al cabo de cierto número de iteraciones, la población estará constituida por buenas soluciones al problema de optimización.
Redes neuronales:
Genéricamente son métodos de proceso numérico en paralelo, en el que las variables interactúan mediante transformaciones lineales o no lineales, hasta obtener unas salidas. Estas salidas se contrastan con los que tenían que haber salido, basándose en unos datos de prueba, dando lugar a un proceso de retroalimentación mediante el cual la red se reconfigura, hasta obtener un modelo adecuado.
Lógica difusa:
Es una generalización del concepto de estadística. La estadística clásica se basa en la teoría de probabilidades, a su vez ésta en la técnica conjuntista, en la que la relación de pertenencia a un conjunto es dicotómica (el 2 es par o no lo es). Si establecemos la noción de conjunto borroso como aquel en el que la pertenencia tiene una cierta graduación (¿un día a 20ºC es caluroso?), dispondremos de una estadística más amplia y con resultados más cercanos al modo de razonamiento humano.
Series temporales:
Es el conocimiento de una variable a través del tiempo para, a partir de ese conocimiento, y bajo el supuesto de que no van a producirse cambios estructurales, poder realizar predicciones. Suelen basarse en un estudio de la serie en ciclos, tendencias y estacionalidades, que se diferencian por el ámbito de tiempo abarcado, para por composición obtener la serie original. Se pueden aplicar enfoques híbridos con los métodos anteriores, en los que la serie se puede explicar no sólo en función del tiempo sino como combinación de otras variables de entorno más estables y, por lo tanto, más fácilmente predecibles.
Metodología de aplicación:
Para utilizar estas técnicas de forma eficiente y ordenada es preciso aplicar una metodología estructurada, al proceso de Data Mining. A este respecto proponemos la siguiente metodología, siempre adaptable a la situación de negocio particular a la que se aplique:
Muestreo
Extracción de la población muestral sobre la que se va a aplicar el análisis. En ocasiones se trata de una muestra aleatoria, pero puede ser también un subconjunto de datos del Data Warehouse que cumplan unas condiciones determinadas. El objeto de trabajar con una muestra de la población en lugar de toda ella, es la simplificación del estudio y la disminución de la carga de proceso. La muestra más óptima será aquella que teniendo un error asumible contenga el número mínimo de observaciones.
En el caso de que se recurra a un muestreo aleatorio, se debería tener la opción de elegir El nivel de confianza de la muestra (usualmente • el 95% o el 99%).
El tamaño máximo de la muestra (número máximo de registros), en cuyo caso el sistema deberá informar del el error cometido y la representatividad de la muestra sobre la población original.
•El error muestral que está dispuesto a cometer, en cuyo caso el sistema informará del número de observaciones que debe contener la muestra y su representatividad sobre la población original.
•Para facilitar este paso s debe disponer de herramientas de extracción dinámica de información con o sin muestreo (simple o estratificado). En el caso del muestreo, dichas herramientas deben tener la opción de, dado un nivel de confianza, fijar el tamaño de la muestra y obtener el error o bien fijar el error y obtener el tamaño mínimo de la muestra que nos proporcione este grado de error.
Exploración
Una vez determinada la población que sirve para la obtención del modelo se deberá determinar cuales son las variables explicativas que van a servir como “inputs” al modelo. Para ello es importante hacer una exploración por la información disponible de la población que nos permita eliminar variables que no influyen y agrupar aquellas que repercuten en la misma dirección.
El objetivo es simplificar en lo posible el problema con el fin de optimizar la eficiencia del modelo. En este paso se pueden emplear herramientas que nos permitan visualizar de forma gráfica la información utilizando las variables explicativas como dimensiones.
También se pueden emplear técnicas estadísticas que nos ayuden a poner de manifiesto relaciones entre variables. A este respecto resultará ideal una herramienta que permita la visualización y el análisis estadístico integrados.
Manipulación
Tratamiento realizado sobre los datos de forma previa a la modelización, en base a la exploración realizada, de forma que se definan claramente los inputs del modelo a realizar (selección de variables explicativas, agrupación de variables similares, etc.).
Modelización
Permite establecer una relación entre las variables explicativas y las variables objeto del estudio, que posibilitan inferir el valor de las mismas con un nivel de confianza determinado.
Valoración
Análisis de la bondad del modelo contrastando con otros métodos estadísticos o con nuevas poblaciones muestrales.
___________________________________________________________________________________________________
En el artículo de Luis Carlos Molina, coordinador del programa de Data Mining de la UOC, también se dan definiciones interesantes desde otro punto de vista (..”torturando a los datos hasta que confiesen” ).
https://www.uoc.edu/web/esp/art/uoc/molina1102/molina1102.html
En este artículo se da una vision global de todo lo relacionado con DataMining, así como ejemplos prácticos de su utilización.
___________________________________________________________________________________________________
Mas información, igualmente, en la monografía elaborada por Cynthia Presser Carne
https://www.monografias.com/trabajos/datamining/datamining.shtml
___________________________________________________________________________________________________
Algunas herramientas de DataMining serían las siguientes (obtenidas de la página www.dataprix.com):
· Aqua BAS 2008 / Aqua eSolutions
· IBM / SPSS: Herramienta de data mining que permite desarrollar modelos predictivos y desplegarlos para mejorar la toma de decisiones. Está diseñada teniendo en cuenta a los usuarios empresariales, de manera que no es preciso ser un experto en data mining.
· dVelox 2.5/ Apara: Plataforma analítica para la toma de decisiones en tiempo real que predice los escenarios futuros más probables para optimizar los procesos críticos de cualquier empresa, Está orientada a los sectores de banca, finanzas y márketing.
· Microsoft SQL Server 2008 Datamining: Solución que ofrece un entorno integrado para crear modelos de minería de datos (Data Mining) y trabajar con ellos. La solución SQL Server Data Mining permite el acceso a la información necesaria para tomar decisiones inteligentes sobre problemas empresariales complejos. Data Mining es la tecnología de BI que ayuda a construir modelos analíticos complejos e integrar esos modelos con sus operaciones comerciales.
· MicroStrategy Data Mining Services /Microstrategy: Componente de la plataforma de BI de MicroStrategy que proporciona a los usuarios, modelos predictivos de data mining. Permite realizar tareas de data mining mediante el uso de métricas construidas con funciones predictivas o importadas de modelos de datos de herramientas de data mining de terceros.
· SAS Enterprise Miner / SAS: Solución de minería de datos que proporciona gran cantidad de modelos y de alternativas. Permite determinar pautas y tendencias, explica resultados conocidos e identifica factores que permiten asegurar efectos deseados. Además, compara los resultados de las distintas técnicas de modelización, tanto en términos estadísticos como de negocio, dentro de un marco sencillo y fácil de interpretar.
· Oracle DataMining: Función de Oracle 11g Enterprise Edition que permite diseñar aplicaciones de BI que más tarde realizan funciones de «minería» en las bases de datos corporativas para descubrir nueva información e integrarla con las aplicaciones de negocio.
· MIS Delta Miner / MIS: Herramienta concebida para efectuar análisis de alto nivel, detección de desviaciones y análisis interactivo sobre múltiples fuentes, tanto transaccionales (SQL Server, Oracle, DB2, etc) como multidimensionales (Hyperion Essbase, SAP BW, MS Analysis Services y Oracle Express).
· Teradata Warehouse Miner / Teradata: Solución que facilita la construcción de modelos analíticos directamente sobre la base de datos, eliminando así la necesidad de extraer muestras a sistemas del exterior. Además permite analizar datos sin cambiarlos de sitio y es capaz de visualizar la información para representar regresiones lineales o logísticas.
Dentro de las herramientas OpenSource:
· Weka: Solución de minería de datos OpenSource desarrollada en la Universidad de Waikato, que consiste en una collecion de algoritmos implementados en Java para realizar minería de datos. En la actualidad esta asociado al proyecto pentaho.
· R: proyecto OpenSource de DataMining de la Universidad de Auckland.
· RapidMiner: proyecto OpenSource de DataMining.
Una lista mas completa de herramientas datamining la encontramos en la comunidad KDNUGGETS.COM (Data Mining Community’s ) en el siguiente link.
Para terminar,os recomiendo la lectura de la serie de articulos que hablan de Data Mining publicados en dataminingarticles.com (gracias a bifacil.com).
Si quereis entrar un poco mas en profundidad, podeis ver la presentación Data Mining.Extracción de Conocimiento en Grandes Bases de Datos, realizada por José M. Gutiérrez, del Dpto. de Matemática Aplicada de la Universidad de Cantabria, Santander.

Data Mining. Extracción de Conocimiento en Grandes Bases de Datos
View more presentations from respinosamilla.
En la presentación se da una visión de la Teoria de Data Mining y se hace un repaso de las diferentes tecnicas existentes, incluyendo ejemplos prácticos. Igualmente, se habla de los programas comerciales mas importantes.
Tambien os puede ser util la documentación y materiales del curso Aprendizaje Automatico y Dataming, realizado en la Universidad Miguel Hernandez de Elche por Cesar Fernandez.
KMS: Knowledge Management System o Sistemas para gestión del Conocimiento.
KMS: Knowledge Management System o Sistemas para gestión del Conocimiento. respinosamilla 25 February, 2010 - 09:50Nuevas tecnologias desarrolladas para la gestión del conocimiento y su integración en una única plataforma. Son herramientas no relacionadas directamente con el Business Intelligence, pero nos permiten gestionar toda la información y el conocimiento que hay en la empresa para poder sacar un mayor partido de ella. Por ejemplo, toda la documentación interna, manuales, procedimientos que existen en la empresa estara guardada en un gestor documental que una vez indexado, se puede consultar por los integrantes de la organización de una forma ágil. Al fin y al cabo, la información es poder y cuanto mas rapida se pueda obtener, mas beneficios genera.

Knowledge Management System (KM System) se refiere a los sistemas informáticos para gestionar el conocimiento en las organizaciones, que soportan la creación, captura, almacenamiento y distribución de la información. Estos sistemas son una parte mas de la estrategia de Gestión del Conocimiento dentro de las organizaciones.
La idea de un sistema KM es permitir a los empleados tener un acceso completo a la documentación de la organización, origenes de información y soluciones. El tipico ejemplo es la empresa donde un ingeniero conoce la composiciones de metales que podria reducir el nivel del ruidos en motores. Compartiendo esta información, se podria ayudar a diseñar motores mas efectivos o podria ayudar y dar ideas a otros componenes de la organización a diseñar mejores equipamientos o a mejorar los productos. Otro ejemplo podría ser el departamento comercial que necesita información sobre los clientes y puede consultar la información recopilada por otros compañeros al respecto. O el departamento de sistemas que tienes todos sus manuales de administración y documentación informatizados y es facil buscar soluciones a problemas presentados anteriormente en dicha información.
Un sistema KM podría incluir lo siguiente:
- Tecnologia documental que permita la creación, gestion y comparticion de documentos con un formato determinado (como Lotus Notes, portales Web de gestion documental, Bases de datos distribuidas).
- Ontologia/taxonomia: similar a la tecnologias de documentacion para crear un sistema de terminologias que son usadas por sumarizar, organizar o clasificar los documentos ( por ejemplo Autor, Materia, Organizacion, etc).
- Proporcionar mapas de red de la organización para mostar el flujo de comunicacion entre las entidades y los individuos.
- Desarrollo de herramientas sociales dentro de la organizacion para sacar un mayor aprovechamiento de la creacion del sistema KM.
Los sistemas KMS trabajan con información, aunque es una disciplina que se extiende mas alla de los sistemas informaticos. Las caracteristicas mas importantes de un sistema KMS pueden incluir:
- Proposito: un KMS tiene que tener el explicito objetivo de la gestion del conocimiento, permitiendo la colaboracion, el compartir buenas practicas y similares.
- Contexto: Una perspectiva de los sistemas KMS es ver que el conocimiento es información organizada con inteligencia, acumulada e integrada en un contexto de creación y aplicacion de dicho conocimiento.
- Procesos: el sistema KMS es desarrollado para soportar y permitir procesos de conocimiento intensivo, como tareas o proyectos de creación, construcción, identificación, captura, selección, evaluación, acceso, recuperación y aplicación, que es el llamado ciclo de vida del conocimiento.
- Participantes: Los usuarios pueden jugar roles activos de participantes involucrados en las redes del conocimiento y en las comunidades, aunque esto no tiene porque ser necesariamente el caso. Los sistemas KMS esta diseñados para que el conocimiento se desarrolle colectivamente y la distribución de dicho conocimiento sea un proceso continuo de cambio, reconstrucción y aplicación en diferentes contextos, por diferentes participantes con diferentes backgrounds y experiencias.
- Instrumentos: el sistema KMS debe soportar instrumentos de gestión del conocimiento, como la captura, creación y comparticion de aspectos codificables de la experiencia, la creacion de directorios de conocimiento corporativos, con su correcta clasificacion, taxonomia u ontologia, localizadores de experiencia, sistemas de gestion de habilidades, herramientas de colaboracion para permitir conectar personas interesadas en los mismos temas, permitiendo de esta manera la creación de redes de conocimiento.
Un KMS ofrece servicios integrados para desarrollar instrumentos KM para una red de participantes, que seran trabajadores activos del conocimiento durante todo el ciclo de vida de este. Los sistemas KMS pueden ser usados para procesos de cooperacion, colaboracion entre comunidades, organizaciones virtuales, sociedades u otras redes virtuales, para gestionar contenidos, actividades, interactuar y generar flujos de trabajo, proyectos, trabajos, departamentos, privilegios, roles, participantes con el proposito de extraer y generar nuevo conocimiento, darle valor y transferirlo, generando nuevos servicios, usando nuevos formatos e interfaces en diferentes canales de comunicacion.
El termino KMS puede ser asociado a los programas Open Source y las licencias, iniciativas y politicas Open Source Software, Open Standards, Open Protocols and Open Knowledge.
Beneficios de los sistems KM
Algunas de las ventajas mas destacables de los sistemas KM son:
- La información organizacional valiosa se comparte a traves de la estructura de la organización.
- Podemos evitar reinventar la rueda, reduciendo trabajo redundante reutilizando trabajo ya realizado por otros en la misma organizacion.
- Reducción de los tiempos de formación de los nuevos empleados.
- Retencion de la propiedad Intelectual de los trabajos despues de que el empleado abandone la empresa. Es como si el conocimiento fuera codificado.
Herramientas KMS
Opensource: Alfresco, Nuxeo, OpenKm.
Propietarias: En la web de la revista KMWorld tenemos una lista de los fabricantes mas importantes.
La base de datos analítica (el Datawarehouse o Almacén de Datos)
La base de datos analítica (el Datawarehouse o Almacén de Datos) respinosamilla 25 February, 2010 - 09:50Hasta ahora, hemos visto las diferentes herramientas y técnicas que podemos utilizar para explotar nuestros sistemas de Business Intelligence, para analizar la información y obtener conocimiento de los datos.
En algunos casos, desde esas mismas herramientas podríamos estar accediendo a nuestros sistemas transaccionales para analizar la información (lease ERP, CRM u otros sistemas), pero seguramente tendriamos problemas en cuanto a tiempos de respuesta; información repartida en diferentes sistemas que no son homogeneos, lo que dificulta el proceso de análisis; complejos reportes poco flexibles, etc, etc.
Para solucionar esto surgío el concepto de Dawarehouse o Almacen de Datos. Es una base de datos orientada al análisis y que es el CORAZON de todo proyecto de Business Intelligence. Esta base de datos deberá de poder soportar todos los tipos de herramientas de analisis que podamos utilizar.
Antes de continuar, os recomiendo visualizar el video elaborado por Josep Curto para sus alumnos de la UOC. En el se explican todos los concenptos referentes a DW, el Modelo Dimensional y todos sus componentes. También os recomiendo la serie de articulos temáticos publicados en su blog, gran trabajo.
Veamos un poco mas a fondo en que consiste:
(Definiciones extraidas del Consejo Superior de Informatica, del documento Manual para la adquisición de un sistema de Data Warehouse).
3.1. Justificación histórica
En la actualidad, las tecnologías de la información han automatizado los procesos de carácter típicamente repetitivo o administrativo, haciendo uso de lo que llamaremos sistemas de información operacionales.Entendemos por aplicaciones operacionales, aquellas que resuelven las necesidades de funcionamiento de la empresa. En este tipo de sistemas, los conceptos más importantes son la actualización y el tiempo de respuesta. Una vez satisfechas las necesidades operacionales más acuciantes, surge un nuevo grupo de necesidades sobre los sistemas de la empresa, a las cuales vamos a calificar como necesidades informacionales. Por necesidades informacionales, entendemos aquellas que tienen por objeto obtener la información necesaria, que sirva de base para la toma de decisiones tanto a escala estratégica como táctica. Estas necesidades informacionales se basan en gran medida en el análisis de un número ingente de datos, en el que es tan importante el obtener un valor muy detallado de negocio como el valor totalizado para el mismo. Es fundamental también la visión histórica de todas las variables analizadas, y el análisis de los datos del entorno. Estos requerimientos no son, a priori, difíciles de resolver dado que la información está efectivamente en los sistemas operacionales. Cualquier actividad que realiza la empresa está reflejada de forma minuciosa en sus bases de datos.
La realidad, sin embargo, es distinta, puesto que al atender las necesidades de tipo informacional, los responsables de sistemas se tropiezan con múltiples problemas. En primer lugar, al realizar consultas masivas de información (con el fin de conseguir el ratio, valor agrupado o grupo de valores solicitados), se puede ver perjudicado el nivel de servicio del resto de sistemas, dado que las consultas de las que estamos hablando, suelen ser bastante costosas en recursos. Además, las necesidades se ven insatisfechas por la limitada flexibilidad a la hora de navegar por la información y a su inconsistencia debido a la falta de una visión global (cada visión particular del dato está almacenada en el sistema operacional que lo gestiona).
En esta situación, el siguiente paso evolutivo ha venido siendo la generación de un entorno gemelo del operativo, que se ha denominado comúnmente Centro de Información, en el cual la información se refresca con menor periodicidad que en los entornos operacionales y los requerimientos en el nivel de servicio al usuario son más flexibles. Con esta estrategia se resuelve el problema de la planificación de recursos ya que las aplicaciones que precisan un nivel de servicio alto usan el entorno operacional y las que precisan consultas masivas de información trabajan en el Centro de Información. Otro beneficio de este nuevo entorno, es la no inferencia con las aplicaciones operacionales.
Pero no terminan aquí los problemas. La información mantiene la misma estructura que en las aplicaciones operacionales por lo que este tipo de consultas debe acceder a multitud de lugares para obtener el conjunto de datos deseado. El tiempo de respuesta a las solicitudes de información es excesivamente elevado. Adicionalmente, al proceder la información de distintos sistemas, con visiones distintas y distintos objetivos, en muchas ocasiones no es posible obtener la información deseada de una forma fácil y además carece de la necesaria fiabilidad.
De cara al usuario estos problemas se traducen en que no dispone a tiempo de la información solicitada y que debe dedicarse con más intensidad a la obtención de la información que al análisis de la misma, que es donde aporta su mayor valor añadido.
3.2.- ¿QUÉ ES UN DATA WAREHOUSE?
Tras las dificultades de los sistemas tradicionales en satisfacer las necesidades informacionales, surge el concepto de Data Warehouse, como solución a las necesidades informacionales globales de la empresa. Este término acuñado por Bill Inmon, se traduce literalmente como Almacén de Datos. No obstante si el Data Warehouse fuese exclusivamente un almacén de datos, los problemas seguirían siendo los mismos que en los Centros de Información.
La ventaja principal de este tipo de sistemas se basa en su concepto fundamental, la estructura de la información. Este concepto significa el almacenamiento de información homogénea y fiable, en una estructura basada en la consulta y el tratamiento jerarquizado de la misma, y en un entorno diferenciado de los sistemas operacionales. Según definió Bill Inmon, el Data Warehouse se caracteriza por ser:
Integrado: los datos almacenados en el Data Warehouse deben integrarse en una estructura consistente, por lo que las inconsistencias existentes entre los diversos sistemas operacionales deben ser eliminadas. La información suele estructurarse también en distintos niveles de detalle para adecuarse a las distintas necesidades de los usuarios.
Temático: sólo los datos necesarios para el proceso de generación del conocimiento del negocio se integran desde el entorno operacional. Los datos se organizan por temas para facilitar su acceso y entendimiento por parte de los usuarios finales. Por ejemplo, todos los datos sobre clientes pueden ser consolidados en una única tabla del Data Warehouse. De esta forma, las peticiones de información sobre clientes serán más fáciles de responder dado que toda la información reside en el mismo lugar.
Histórico: el tiempo es parte implícita de la información contenida en un Data Warehouse. En los sistemas operacionales, los datos siempre reflejan el estado de la actividad del negocio en el momento presente. Por el contrario, la información almacenada en el Data Warehouse sirve, entre otras cosas, para realizar análisis de tendencias. Por lo tanto, el Data Warehouse se carga con los distintos valores que toma una variable en el tiempo para permitir comparaciones.
No volátil: el almacén de información de un Data Warehouse existe para ser leído, y no modificado. La información es por tanto permanente, significando la actualización del Data Warehouse la incorporación de los últimos valores que tomaron las distintas variables contenidas en él sin ningún tipo de acción sobre lo que ya existía.
E.F. Codd, considerado como el padre de las bases de datos relacionales, ha venido insistiendo desde principio de los noventa, que disponer de un sistema de bases de datos relacionales, no significa disponer de un soporte directo para la toma de decisiones. Muchas de estas decisiones se basan en un análisis de naturaleza multidimensional, que se intentan resolver con la tecnología no orientada para esta naturaleza. Este análisis multidimensional, parte de una visión de la información como dimensiones de negocio. Estas dimensiones de negocio se comprenden mejor fijando un ejemplo, para lo que vamos a mostrar, para un sistema de gestión de expedientes, las jerarquías que se podrían manejar para el número de los mismo para las dimensiones: zona geográfica, tipo de expediente y tiempo de resolución.
La visión general de la información de ventas para estas dimensiones definidas, la representaremos, gráficamente como el cubo de la derecha:

Un gerente de una zona estaría interesado en visualizar la información para su zona en el tiempo para todos los productos que distribuye.
Un director de producto, sin embargo querría examinar la distribución geográfica de sus productos, para toda la información histórica almacenada en el Data Warehouse.
O se podría también examinar los datos en un determinado momento o una visión particularizada. A su vez estas dimensiones tienen una jerarquía, interpretándose en el cubo como que cada cubo elemental es un dato elemental, del que se puede extraer información agregada.
Y así por ejemplo se podría querer analizar la evolución de las ventas en Galicia de libros de Física por meses desde Febrero del 1996 hasta Marzo del 1997.Ello es fácil de obtener (incluso a “golpe de ratón”) si la información de ventas se ha almacenado en un Data Warehouse, definiendo estas jerarquías y estas dimensiones de negocio.
En este sentido citamos las palabras de D. Wayne Calloway Director Ejecutivo de Operaciones de Pepsico en una asamblea general de accionistas:
“Hace diez años les pude decir cuántos Doritos vendimos al Oeste del Mississipi. Hoy no sólo les puedo decir eso mismo, sino cuántos vendimos en California, en el Condado de Orange, en la ciudad de Irvine, en el Supermercado local Von’s, en una promoción especial, al final del pasillo 4, los jueves”.
Otra característica del Data Warehouse es que contiene datos relativos a los datos, concepto que se ha venido asociando al término de metadatos. Los metadatos permiten mantener información de la procedencia de la información, la periodicidad de refresco, su fiabilidad, forma de cálculo, etc., relativa a los datos de nuestro almacén.Estos metadatos serán los que permitan simplificar y automatizar la obtención de la información desde los sistemas operacionales a los sistemas informacionales.
Los objetivos que deben cumplir los metadatos, según el colectivo al que va dirigido, serían:
• Soportar al usuario final, ayudándole a acceder al Data Warehouse con su propio lenguaje de negocio, indicando qué información hay y qué significado tiene. Ayudar a construir consultas, informes y análisis, mediante herramientas de navegación.
• Soportar a los responsables técnicos del Data Warehouse en aspectos de auditoría, gestión de la información histórica, administración del Data Warehouse, elaboración de programas de extracción de la información, especificación de las interfaces para la realimentación a los sistemas operacionales de los resultados obtenidos, etc.
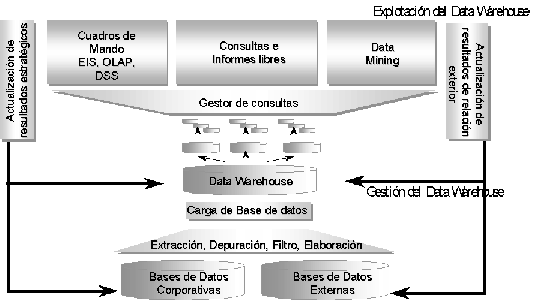
Para comprender el concepto de Data Warehouse, es importante considerar los procesos que lo conforman. A continuación se describen dichos procesos clave en la gestión de un Data Warehouse:
Extraccion: obtención de información de las distintas fuentes tanto internas como externas.
Elaboracion: filtrado, limpieza, depuración, homogeneización y agrupación de la información.
Carga: organización y actualización de los datos y los metadatos en la base de datos.
Explotacion: extracción y análisis de la información en los distintos niveles de agrupación.
Desde el punto de vista del usuario, el único proceso visible es la explotación del almacén de datos, aunque el éxito del Data Warehouse radica en los tres procesos iniciales que alimentan la información del mismo y suponen el mayor porcentaje de esfuerzo (en torno a un 80%) a la hora de desarrollar el almacén.
Las diferencias de un Data Warehouse con un sistema tradicional las podríamos resumir en el siguiente esquema:
Una de las claves del éxito en la construcción de un Data Warehouse es el desarrollo de forma gradual, seleccionando a un departamento usuario como piloto y expandiendo progresivamente el almacén de datos a los demás usuarios. Por ello es importante elegir este usuario inicial o piloto, siendo importante que sea un departamento con pocos usuarios, en el que la necesidad de este tipo de sistemas es muy alta y se puedan obtener y medir resultados a corto plazo.
Terminamos este apartado, resumiendo los beneficios que un Data Warehouse puede aportar:
• Proporciona una herramienta para la toma de decisiones en cualquier área funcional, basándose en información integrada y global del negocio.
• Facilita la aplicación de técnicas estadísticas de análisis y modelización para encontrar relaciones ocultas entre los datos del almacén; obteniendo un valor añadido para el negocio de dicha información.
• Proporciona la capacidad de aprender de los datos del pasado y de predecir situaciones futuras en diversos escenarios.
• Simplifica dentro de la empresa la implantación de sistemas de gestión integral de la relación con el cliente.
• Supone una optimización tecnológica y económica en entornos de Centro de Información, estadística o de generación de informes con retornos de la inversión espectaculares.
3.3.Data Warehouse vs. Data Mart
La duplicación en otro entorno de datos es un término que suele ser mal interpretado e incomprendido. Así es usado por los fabricantes de SGBD en el sentido de simple réplica de los datos de un sistema operacional centralizado en sistemas distribuidos. En un contexto de Data Warehouse, el término duplicación se refiere a la creación de Data Marts locales o departamentales basados en subconjuntos de la información contenida en el Data Warehouse central o maestro.
Según define Meta Group, “un Data Mart es una aplicación de Data Warehouse, construida rápidamente para soportar una línea de negocio simple”. Los Data Marts, tienen las mismas características de integración, no volatilidad, orientación temática y no volatilidad que el Data Warehouse. Representan una estrategia de “divide y vencerás” para ámbitos muy genéricos de un Data Warehouse.
Esta estrategia es particularmente apropiada cuando el Data Warehouse central crece muy rápidamente y los distintos departamentos requieren sólo una pequeña porción de los datos contenidos en él. La creación de estos Data Marts requiere algo más que una simple réplica de los datos: se necesitarán tanto la segmentación como algunos métodos adicionales de consolidación.
La primera aproximación a una arquitectura descentralizada de Data Mart, podría ser venir originada de una situación como la descrita a continuación.
El departamento de Marketing, emprende el primer proyecto de Data Warehouse como una solución departamental, creando el primer Data Mart de la empresa. Visto el éxito del proyecto, otros departamentos, como el de Riesgos, o el Financiero se lanzan a crear sus Data Marts. Marketing, comienza a usar otros datos que también usan los Data Marts de Riesgos y Financiero, y estos hacen lo propio. Esto parece ser una decisión normal, puesto que las necesidades de información de todos los Data Marts crecen conforme el tiempo avanza.
Cuando esta situación evoluciona, el esquema general de integración entre los Data Marts pasa a ser, la del gráfico anterior. En esta situación, es fácil observar cómo este esquema de integración de información de los Data Marts, pasa a convertirse en un rompecabezas en el que la gestión se ha complicado hasta convertir esta ansia de información en un auténtico quebradero de cabeza. No obstante, lo que ha fallado no es la integración de Data Marts, sino su forma de integración.
En efecto, un enfoque más adecuado sería la coordinación de la gestión de información de todos los Data Marts en un Data Warehouse centralizado. En esta situación los Data Marts obtendrían la información necesaria, ya previamente cargada y depurada en el Data Warehouse corporativo, simplificando el crecimiento de una base de conocimientos a nivel de toda la empresa.
Esta simplificación provendría de la centralización de las labores de gestión de los Data Marts, en el Data Warehouse corporativo, generando economías de escala en la gestión de los Data Marts implicados.
Según un estudio de IDC ( International Data Corporation ) tras analizar 541 empresas, la distribución de las implantaciones de Data Warehouse y Data Marts en la actualidad, y sus opiniones respecto a esta distribución en el futuro, nos muestra los siguientes datos:
La proporción actual de implantaciones de Data Warehouse es casi el doble que el de Data Mart. No obstante, seguramente tras la andadura inicial de alguno de estos proyectos de Data Mart, se ve como más adecuado para el futuro este enfoque “divide y vencerás”, previéndose una inversión de estos papeles y duplicando la implantación de Data Marts a los Data Warehouse.
Probablemente, el 5% de usuarios que disponen de tecnología de Data Warehouse y piensan renunciar a ella en el futuro, no han realizado previamente un estudio de factores implicados en un Data Warehouse, o han pasado por la situación inicial de partida, y no se han planteado una reorganización del mismo.
3.4.COMPONENTES A TENER EN CUENTA A LA HORA DE CONSTRUIR UN DW
3.4.1.Hardware
Un componente fundamental a la hora de poder contar con un Data Warehouse que responda a las necesidades analíticas avanzadas de los usuarios, es el poder contar con una infraestructura Hardware que la soporte. En este sentido son críticas, a la hora de evaluar uno u otro hardware, dos características principales:
Por un lado, a este tipo de sistemas suelen acceder pocos usuarios con unas necesidades muy grandes de información, a diferencia de los sistemas operacionales, con muchos usuarios y necesidades puntuales de información. Debido a la flexibilidad requerida a la hora de hacer consultas complejas e imprevistas, y al gran tamaño de información manejada, son necesarias unas altas prestaciones de la máquina.
Por otro lado, debido a que estos sistemas suelen comenzar con una funcionalidad limitada, que se va expandiendo con el tiempo (situación por cierto aconsejada), es necesario que los sistemas sean escalables para dar soporte a las necesidades crecientes de equipamiento. En este sentido, será conveniente el optar por una arquitectura abierta, que nos permita aprovechar lo mejor de cada abricante.
En el mercado se han desarrollado tecnologías basadas en tecnología de procesamiento paralelo, dan el soporte necesario a las necesidades de altas prestaciones y escalabilidad de los Data Warehouse. Estas tecnologías son de dos tipos:
• SMP (Symmetric multiprocessing, o Multiprocesadores Simétricos): Los sistemas tienen múltiples procesadores que comparten un único bus y una gran memoria, repartiéndose los procesos que genera el sistema, siendo el sistema operativo el que gestiona esta distribución de tareas. Estos sistemas se conocen como arquitecturas de “casi todo compartido”. El aspecto más crítico de este tipo de sistemas es el grado de rendimiento relativo respecto al número de procesadores presentes, debido a su creciente no lineal.
• MPP (Massively parallel processing, o Multiprocesadores Masivamente Paralelos): Es una tecnología que compite contra la SMP, en la que los sistemas suelen ser casi independientes comunicados por intercambiadores de alta velocidad que permiten gestionarlos como un único sistema. Se conocen por ello como arquitecturas de “nada compartido”. Su escalabilidad es mayor que la de los SMP.
Según Meta Group, las tendencias de mercado indican que las arquitecturas SMP aportan normalmente suficientes características de escalabilidad, con una mayor oferta y un menor riesgo tecnológico. Sin embargo, cuando las condiciones de escalabilidad sean extremas, se puede plantear la opción MPP. No obstante, se están produciendo avances significativos en arquitecturas SMP, que han ogrado máquinas con un crecimiento lineal de rendimiento hasta un número de 64 procesadores.
3.4.2.-Software de almacenamiento (SGBD)
Como hemos comentado, el sistema que gestione el almacenamiento de la información (Sistema de Gestión de Base de Datos o SGBD), es otro elemento clave en un Data Warehouse. Independientemente de que la información almacenada en el Data Warehouse se pueda analizar mediante visualización multidimensional, el SGBD puede estar realizado utilizando tecnología de Bases de Datos Relacionales o Multidimensionales.
Las bases de datos relacionales, se han popularizado en los sistemas operacionales, pero se han visto incapaces de enfrentarse a las necesidades de información de los entornos Data Warehouse. Por ello, y puesto que, como hemos comentado, las necesidades de información suelen atender a consultas multidimensionales, parece que unas Bases de Datos multidimensionales, parten con ventaja. En este sentido son de aplicación los comentarios que realizamos en el apartado de hardware, por requerimientos de prestaciones, escalabilidad y consolidación tecnológica.
Al igual que en el hardware, nuevos diseños de las bases de datos relacionales, las bases de datos post-relacionales, abren un mayor abanico de elección. Estas bases de datos post-relacionales, parten de una tecnología consolidada y dan respuesta al agotamiento de las posibilidades de los sistemas de gestión de bases de datos relacionales, ofreciendo las mismas prestaciones aunque implantadas en una arquitectura diseñada de forma más eficiente.
Esta mayor eficiencia se consigue instaurando relaciones lógicas en vez de físicas, lo que hace que ya no sea necesario destinar más hardware a una solución para conseguir la ejecución de las funciones requeridas. El resultado es que la misma aplicación implantada en una BD postrelacional requiere menos hardware, puede dar servicio a un mayor número de usuarios y utilizar mecanismos intensivos de acceso a los datos más complejos. Asimismo, esta tecnología permite combinar las ventajas de las bases de datos jerárquicas y las relacionales con un coste más reducido. Ambos sistemas aportan como ventaja que no resulta necesario disponer de servidores omnipotentes, sin que puede partirse de un nivel de hardware modesto y ampliarlo a medida que crecen las necesidades de información de la compañía y el uso efectivo del sistema.
Dejamos fuera del ámbito de esta guía el detallar cómo los proveedores de bases de datos han optimizado los accesos a los índices, o las nuevas posibilidades que ofrece la compresión de datos (menos espacio para la misma información lo que implica, entre otras ventajas, que más información se puede tener en caché), para lo que remitimos a la prensa especializada o a las publicaciones de los fabricantes.
3.4.3.- Software de extracción y manipulación de datos
En este apartado analizaremos un componente esencial a la hora de implantar un Data Warehouse, la extracción y manipulación. Para esta labor, que entra dentro del ámbito de los profesionales de tecnologías de la información, es crítico el poder contar con herramientas que permitan controlar y automatizar los continuos “mimos” y necesidades de actualización del Data Warehouse.
Estas herramientas deberán proporcionar las siguientes funcionalidades:
• Control de la extracción de los datos y su automatización, disminuyendo el tiempo empleado en el descubrimiento de procesos no documentados, minimizando el margen de error y permitiendo mayor flexibilidad.
• Acceso a diferentes tecnologías, haciendo un uso efectivo del hardware, software, datos y recursos humanos existentes.
• Proporcionar la gestión integrada del Data Warehouse y los Data Marts existentes, integrando la extracción, transformación y carga para la construcción del Data Warehouse corporativo y de los Data Marts.
• Uso de la arquitectura de metadatos, facilitando la definición de los objetos de negocio y las reglas de consolidación.
• Acceso a una gran variedad de fuentes de datos diferentes.
• Manejo de excepciones.
• Planificación, logs, interfaces a schedulers de terceros, que nos permitiran llevan una gestión de la planificación de todos los procesos necesarios para la carga del DW.
• Interfaz independiente de hardware.
• Soporte en la explotación del Data Warehouse.
A veces, no se suele prestar la suficiente atención a esta fase de la gestión del Data Warehouse, aun cuando supone una gran parte del esfuerzo en la construcción de un Data Warehouse. Existen multitud de herramientas disponibles en el mercado que automatizan parte del trabajo.
3.4.4.- Herramientas Middleware
Como herramientas de soporte a la fase de gestión de un Data Warehouse, analizaremos a continuación dos tipos de herramientas:
• Por un lado herramientas Middleware, que provean conectividad entre entornos diferentes, para ayudar en la gestión del Data Warehouse.
• Por otro, analizadores y aceleradores de consultas, que permitan optimizar tiempos de respuestas en las necesidades analíticas, o de carga de los diferentes datos desde los sistemas operacionales hasta el Data Warehouse.
Las herramientas Middleware deben ser escalables siendo capaces de crecer conforme crece el Data Warehouse, sin problemas de volúmenes. Tambien deben ser flexibles y robustas, sin olvidarse de proporcionar un rendimiento adecuado. Estarán abiertas a todo tipos de entornos de almacenamiento de datos, tanto mediante estándares de facto (OLE, ODBC, etc.), como a los tipos de mercado más populares (DB2, Access, etc.). La conectividad, al menos en estándares de transporte (SNA LU6.2, DECnet, etc.) debe estar tambien asegurada.
Con el uso de estas herramientas de Middleware lograremos:
• Maximizar los recursos ejecutando las aplicaciones en la plataforma más adecuada.
• Integrar los datos y aplicaciones existentes en una plataforma distribuida.
• Automatizar la distribución de datos y aplicaciones desde un sistema centralizado.
• Reducir tráfico en la red, balanceando los niveles de cliente servidor (mas o menos datos en local, mas o menos proceso en local).
• Explotar las capacidades de sistemas remotos sin tener que aprender multiples entornos operativos.
• Asegurar la escalabilidad del sistema.
• Desarrollar aplicaciones en local y explotarlas en el servidor.
Los analizadores y aceleradores de querys trabajan volcando sobre un fichero de log las consultas ejecutadas y datos asociados a las mismas (tiempo de respuesta, tablas accedidas, método de acceso, etc). Este log se analiza, bien automáticamente o mediante la supervisión del administrador de datos, para mejorar los tiempos de accesos.
Estos sistemas de monitorización se pueden implementar en un entorno separado de pruebas, o en el entorno real. Si se ejecutan sobre un entorno de pruebas, el rendimiento del entorno real no se vé afectado. Sin embargo, no es posible optimizar los esfuerzos, puesto que los análisis efectuados pueden realizarse sobre consultas no críticas o no frecuentemente realizadas por los usuarios.
El implantar un sistema analizador de consultas, en el entorno real tiene además una serie de ventajas tales como:
• Se pueden monitorizar los tiempos de respuesta del entorno real.
• Se pueden implantar mecanismos de optimización de las consultas, reduciendo la carga del sistema.
• Se puede imputar costes a los usuarios por el coste del Data Warehouse.
• Se pueden implantar mecanismos de bloqueo para las consultas que vayan a implicar un tiempo de respuesta excesivo.
3.4.5.Conclusiones y consideraciones de interes.
El Data Warehouse va a ser el elemento principal en nuestro sistema de Inteligencia de Negocio. De su correcta definición, procesamiento y carga de datos va a depender el exito posterior del proyecto.
Aunque el usuario al final solo vea un conjunto de herramientas de analisis que utilizar para “atacar” a los datos, por delante hay una serie de procesos que hacen que toda la información proveniente de diferentes sistemas haya sido identificada, extraida, procesada, homogeneizada, depurada y cargada en el Datawarehouse. Esto es posible a través de las herramientas ETL y Middleware. Y esta es la parte que normalmente mas tiempo lleva en cualquier proyecto.
Muchas veces conviene elegir un departamento piloto para implantar sistemas de este tipo que luego nos permitan vender internamente dentro de la organización los proyectos.
Habrá que dar siempre importancia a la formación como eje fundamental al uso de las herramientas.
Los proyectos de BI y DW no van a ser solo proyectos tecnológicos, hay mucho mas detras, y aunque en ellos se utilize la tecnología tiene que haber conocimiento empresarial para poder reflejar en el lo que realmente se necesita, desde los niveles mas bajos hasta los superiores de toma de decisiones. En este momento el consultor de BI también tiene que ser capaz de aportar no solo su conocimiento tecnológico, sino también conocimiento de las area de negocio y de los diferentes elementos que se van a utilizar en el diseño, desarrollo y explotación de un sistema de BI (ver el artículo de Jorge Fernández en su blog: El consultor de Bi, ese bicho raro ).
3.4.6. Nuevas tendencias en el mundo DW. El Datawarehouse 2.0.
Los sistemas DW han evolucionado en los ultimos años conforme han surgido nuevas necesidades. Los motivos de esta evolución son varios, y los podemos resumir en:
- Uso de herramientas de analisis que obligaban a estructuras diferentes optimazadas al uso de determinadas tecnologías (por ejemplo el data mining o el uso de herramientas estadísticas).
- Simplificación de la gestión de sistemas DW complejos formados por multiples datamarts orientados a cada departamento en los que se pierde el concepto de Corporativo (que hace que se pierdan oportunidades ).
- De la unión de multiples aplicaciones pequeñas (Datamarts o Datawarehouse), no surge toda la información corporativa. Sería necesario construir este Centro a partir del cual se van a generar todos los DW necesarios para todos los ambitos de análisis.
- Proceso Online: los procesos de actualización hacían que hubiera muchos momentos en los que no se podía acceder a los datos. Igualmente, podría haber cierto retardo en la disponibilidad de la información, lo que nos impedia poder hacer análisis inmediatos (analisis mas orientados a la operacion del negocio).
- Evolución tecnologica en las herramientas ETL, costes de la tecnología (los costes han bajando de tal forma que permiten abordar los proyectos de una forma mas amplia), etc.
Por todo esto surge el concepto de CIF ( Corporate Information Factory), que podría incluir todos los elementos que vemos en la imagen siguiente:
El Corporate Information Factory (CIF) es una arquitectura conceptual que describe y categoriza los almacenes de informacion usados para operar y gestionar con exito una infraestructura de BI robusta.
El uso de esta arquitectura o de otras mas sencillas va a depender del tipo de compañia, los requerimientos de analisis y hasta donde se quiera llegar en el uso del BI. Los elementos que forman el CIF, de forma resumida, son los siguientes:
Data Warehouse: es el almacen de datos, según las definiciones vistas hasta ahora. Pero ademas, en esta arquitectura, es el punto central de la integración de datos. Centraliza toda la información, nos da una vision en comun de la información de toda la organización y proporciona los datos para llenar de contenido el resto almacenes de datos especificos, a través de los procesos de Data delivery (extracción de datos con condiciones de filtrado, sumarización, etc para otros tipos de analisis).
Operational Data Store: es un almacen de datos, como el DW, pero orientado a las toma de decisiones tacticas. Se alimenta de datos actuales de los sistemas operacionales, nos es un sistema historico, tiene la información mucho mas en detalle y los tiempos de actualización suelen ser mucho mas rápidos para permitir la toma de decisiones rápidas sobre los datos de operación del negocio. Sería un sistema cercano al tiempo real y suele incluir información sobre clientes, materiales, stocks, ventas, etc.
Data Acquisition: son todas las herramientas y sistemas de gestión que nos permite la extracción, transformación y carga de los datos provenientes de los diferentes sistemas origen (sistemas externos, ERP, sistemas internos, ficheros, etc), en nuestro Datawarehouse. Serian las herramientas ETL y los sistemas de gestión de la adquisición de datos (Data Acquisition Management).
Data Delivery: son las operaciones de agregacion de la información, filtrado por dimensiones especificas o requerimientos de negocio, reformateo o procesamiento de la información para soportar el uso de herramientas de BI especificas, y finalmente, la transmisión de la información a través de la organización (para dar contenido a los Datamarts o Warehouse especificos).
A partir del DW podremos construir subconjuntos de el orientados al uso de tecnicas especificas de BI:
Exploration Warehouse: almacen de exploración para utilizar herramientas de tipo estadistico y de exploracion.
Data Mining Warehouse: almacen para el uso de tecnicas de datamining.
Olap Data Mart: almacen de datos para el uso de analisis multidimensionales (tipo OLAP).
Operational Mart: subconjunto del ODS (operational Data Store), para permitir analisis operacional restringido a un ambito menor.
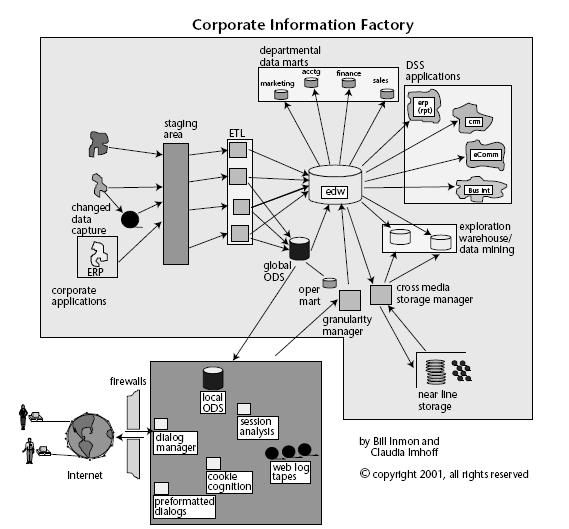
Si quereis saber mas sobre las nuevas arquitecturas, os recomiendo los libros:
The data warehouse toolkit : the complete guide to dimensional modeling
Ralph Kimball, Margy Ross. — 2nd ed.
ISBN 0-471-20024-7
Mastering data warehouse design
Imhoff, Claudia
Galemmo, Nicholas
Geiger, Jonathan G.
ISBN:978-0-471-32421-8
DW 2.0: The Architecture for the Next Generation of Data Warehousing
William Inmon
Derek Strauss
Genia Neushloss
ISBN: 978-0-12-374319-0
Ambitos de aplicación de la Inteligencia de Negocio y del DW.
Ambitos de aplicación de la Inteligencia de Negocio y del DW. respinosamilla 25 February, 2010 - 09:50Los sistemas BI y DW pueden ser aplicables en cualquier ambito de la empresa y las organizaciones, aunque los ambitos más comunes en los que se utilizan podrían ser los siguientes (Definiciones extraidas del Consejo Superior de Informatica, del documento Manual para la adquisición de un sistema de Data Warehouse).
4.1. Data Warehouse y Sistemas de Marketing
La aplicación de tecnologías de Data Warehouse supone un nuevo enfoque de Marketing, haciendo uso del Marketing de Base de Datos. En efecto, un sistema de Marketing Warehouse implica un marketing científico, analítico y experto, basado en el conocimiento exhaustivo de clientes, productos, canales y mercado.
Este conocimiento se deriva de la disposición de toda la información necesaria, tanto interna como externa, en un entorno de Data Warehouse, persiguiendo con toda esta información, la optimización de las variables controladas del Marketing Mix y el soporte a la predicción de las variables no controlables (mediante técnicas de Data Mining). Basándose en el conocimiento exhaustivo de los clientes se consigue un tratamiento personalizado de los mismos tanto en el día a día (atención comercial) como en acciones de promoción específicas.
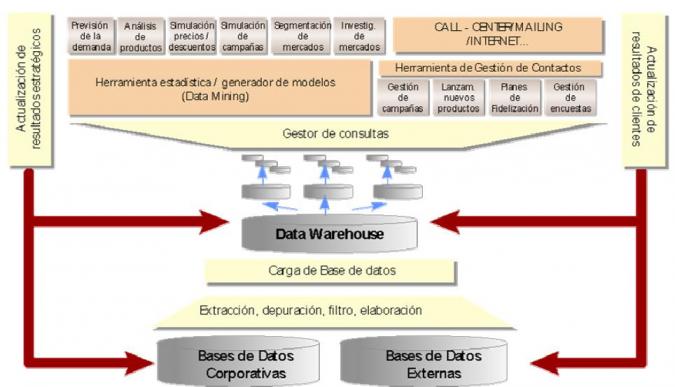
Las áreas en las que se puede aplicar las tecnologías de Data Warehouse a Marketing son, entre otras:
• Investigación Comercial.Segmentación de mercados.
• Identificación de necesidades no cubiertas y generación de nuevos productos, o modificación de productos existentes.
• Fijación de precios y descuentos: Definición de la estrategia de canales de comercialización y distribución
• Definición de la estrategia de promoción y atención al cliente
• Relación con el cliente:
• Programación, realización y seguimiento de acciones comerciales
• Lanzamiento de nuevos productos
• Campañas de venta cruzada, vinculación, fidelización, etc.
• Apoyo al canal de venta con información cualificada
4.2. Data Warehouse y Análisis de Riesgo Financiero
El Data Warehouse aplicado al análisis de riesgos financieros ofrece capacidades avanzadas de desarrollo de aplicaciones para dar soporte a las diversas actividades de gestión de riesgos. Es posible desarrollar cualquier herramienta utilizando las funciones que incorpora la plataforma, gracias a la potencionalidad estadística aplicada al riesgo de crédito.
Así se puede usar para llevar a cabo las siguientes funcionalidades:
• Para la gestión de la posición:Determinación de la posición, Cálculo de sensibilidades, Análisis what/if, Simulaciones, Monitorización riesgos contra límites, etc.
• Para la medición del riesgo: Soporte metodología RiskMetrics (Metodología registrada de J.P. Morgan / Reuters), Simulación de escenarios históricos, Modelos de covarianzas, Simulación de Montecarlo, Modelos de valoración, Calibración modelos valoración, Análisis de rentabilidad, Establecimiento y seguimiento. de límites, Desarrollo/modificación modelos, Stress testing, etc. El uso del Data Warehouse ofrece una gran flexibilidad para creación o
modificación de modelos propios de valoración y medición de riesgos, tanto motivados por cambios en la regulación, como en avances en la modelización de estos instrumentos financieros.
Ello por cuanto se puede almacenar y poner a disposición información histórica de mercado y el uso de técnicas de Data Mining nos simplifica la implantación de cualquier método estadístico. Los métodos de previsión, se pueden realizar usando series históricas, (GARCH, ARIMA, etc.).
Pero la explotación de la información nos permite no solo la exploración de los datos para un conocimiento de la información histórica, sinotambién para examinar condiciones de normalidad de las que la mayoría de las metodologías de valoración del riesgo parten.
Además de implantar modelos ya existentes, se pueden acometer análisis con vistas a determinar modelos propios, basados en análisis de correlación para el estudio de la valoración del riesgo de carteras o procesos de simulación de Montecarlo.
Todo ello en una plataforma avanzada de gestión de la información basada en la fácil visualización de la misma y de su análisis estadístico como soporte a metodologías estándar de facto, o a las particularidades de cada entorno.
4.3. Data Warehouse y Análisis de Riesgo de Crédito
La información relativa a clientes y su entorno se ha convertido en fuente de prevención de Riesgos de Crédito. En efecto, existe una tendencia general en todos los sectores a recoger, almacenar y analizar información crediticia como soporte a la toma de decisiones de Análisis de Riesgos de Crédito.
Los avances en la tecnología de Data Warehouse hacen posible la optimización de los sistemas de Análisis de Riesgo de Crédito:
Para la gestión del riesgo de crédito los sistemas operacionales han ofrecido:
• Sistemas de Información para Gerencia (MIS) e informes de Soporte a la Decisión de Problemas (DSS) estáticos y no abiertos a nuevas relaciones y orígenes de datos, situación en la que la incorporación de nuevas fuentes de información ha sido un problema en lugar de una ventaja.
• Exploraciones de datos e informes cerrados y estáticos.
•Análisis sin inclusión de consideraciones temporales lo que imposibilita el análisis del pasado y la previsión del futuro.
• Herramientas de credit-scoring no flexibles, construidas sobre algoritmos difícilmente modificables, no adaptados al entorno de la empresa, o exclusivamente basados en la experiencia personal no contrastada, con lo que los sistemas han ayudado a repetir los errores en vez de a corregirlos.
Pero estos sistemas tradicionales se enfrentan a una problemática difícil de resolver para acomodarse a las necesidades analíticas de los Sistemas de Análisis del Riesgo, necesidades que se pueden cubrir mediante el uso de tecnologías de Data Warehouse.
Dentro de la Prevención de Impagados, utilizando sistemas OLAP se puede obtener el grado interno de concentración de riesgos con el cliente, y almacenar la variedad de fuentes internas o externas de información disponibles sobre el mismo. Ello nos permite obtener sin dificultad la posición consolidada respecto al riesgo del cliente. El análisis se puede realizar asimismo por las diferentes características de la operación para la que se realiza el análisis, en cuanto al plazo y la cuantía de la misma, la modalidad de crédito elegida, la finalidad de la operación o las garantías asociadas a la misma. Usando las mismas capacidades es fácil el establecer una segmentación ABC de la cartera de clientes potenciales o reales que nos optimicen el nivel de esfuerzo en el Análisis de Riesgos.
En el soporte al proceso de Anticipación al Riesgo, se puede dar un adecuado soporte a la correcta generación y consideración de señales de alerta, teniendo en cuenta las pautas y condicionantes diferenciados dependiendo del tipo de cliente y producto usando Data Mining Para el caso del Seguimiento del ciclo de Impagados, de nuevo el uso de sistemas OLAP, simplifican el análisis la diversidad de los diferentes parámetros que intervienen en el mismo, tales como la jerarquía de centros de recobro a contemplar, la diferente consideración dependiendo de la antigüedad del impago, del cliente o del importe impagado. Un
sistema de Data Mining puede aconsejar la mejor acción en caso de impagados, litigio, precontencioso, etc. frente a los parámetros de importe, antigüedad, zona geográfica, etc.
Estos sistemas hacen que el analista se dedique con más intensidad al análisis de la información, que es donde aporta su mayor valor añadido, que a la obtención de la misma. No obstante, estos sistemas deben de huir de las automatizaciones completas sin intervención del analista: es él el que mejor sabe lo que quiere descubrir. “La herramienta debe ser un medio y no un fin”.
4.4. Data Warehouse: Otras áreas de aplicación
Otras áreas de la empresa han aplicado las soluciones que proporciona la tecnología Data Warehouse para mejorar gran parte de sus procesos actuales. Entre ellas destacamos:
• Control de Gestión: Sistemas de Presupuestación, Análisis de Desviaciones, Reporting (EIS, MIS, etc.)
• Logística: Mejora de la relación con proveedores, Racionalización de los procesos de control de inventarios, Optimización de los niveles de producción,
Fases en la implantación de un sistema DW. Metodologia para la construcción de un DW.
Fases en la implantación de un sistema DW. Metodologia para la construcción de un DW. respinosamilla 25 February, 2010 - 09:50Antes de comenzar nuestro proyecto de BI, vamos a determinar que tipo de metodología vamos a utilizar. Existen diferentes metodos, todos relacionados con el ambito del despliegue de sistemas de información, con alguna concreción referente a los sistemas de BI y DW.
5.1. Metodogia Hefesto.
Como una gran aportación podemos mencionar la Metodología Hefesto, creada por Bernabeu Ricardo Dario (disponible con licencia GNU FDL):
Pagina de la metodologia en el blog Open Business Intelligence.
Consulta Online del libro aquí.
Descarga del Libro aquí.
El libro es un resumen muy completo de todo lo relacionado con el Business Intelligence y los DW, y puede ser un punto de partida de gran calidad para iniciarnos en la materia. En la segunda parte del libro se desarrolla la metodología Hefesto, creada y revisada por esta persona, que ademas ha compartido con todo el mundo con licencia GNU su completo trabajo.
La metodología esta orientada a la construcción de DW para Analisis Dimensional (OLAP) y comprende las siguientes fases, que podemos ver en el gráfico de la derecha. 
5.1.1. Análisis de requerimientos.
Identificar preguntas para las que queremos tener respuesta y los objetivos que se quieren conseguir con el nuevo sistema.
Analizar las preguntas para determinar las perspectivas de análisis y los indicadores de negocio.
Diseñar el modelo conceptual, que incluira las perspectivas e indicadores identificados. A través del modelo se podrán alcanzar claramente cuales son los alcances del proyecto, y será un punto de partida con alto nivel de definición para su exposición a los usuarios y responsables.
5.1.2. Analisis de los sistemas transaccionales.
Determinación de indicadores: identificar el origen de los indicadores en los sistemas transaccionales y determinar la forma de su calculo.
Correspondencias: establecer correspondencias entre los elementos definidos en el modelo conceptual y las fuentes de datos existentes en elos OLTP (sistemas transaccionales).
Definición del nivel de granuralidad: nivel de detalle de los datos a obtener para cada dimensión de análisis.
Modelo conceptual ampliado con los campos identificados para cada perspectiva.
5.1.3. Modelo lógico del ETL.
Tipo de modelo lógico del DW: selección del tipo de esquema que utilizaremos (estrella, copo de nieve, etc).
Tabla de dimensiones:Construccion de las tablas de dimensiones para cada una de las perspectivas de analisis considerada.
Tablas de Hechos: definición de las tablas de hechos que contendras la información a partir de los cuales construiremos los indicadores de análisis.
Uniones: relaciones entre las tablas de dimensiones y las tablas de hechos.
5.1.4. Procesos ETL: analisis, definición y desarrollo de todos aquellos procesos necesarios para la extracción, transformación y carga de datos desde los sistemas origen para “llenar” el DW.
5.1.5. Perfomance y mantenimiento del DW: ajustes en el diseño del DW y mantenimiento en el tiempo.
5.2. En otro nivel tenemos la metodología desarrollada por SAS, llamada The SAS Rapid Data Warehouse Methodology
( Podeis descargar el documento en el link ).
Tal y como aparecía en un artículo en ComputerWorld: “Un Data Warehouse no se puede comprar, se tiene que construir“. Como hemos mencionado con anterioridad, la construcción e implantación de un Data Warehouse es un proceso evolutivo.
Este proceso se tiene que apoyar en una metodología específica para este tipo de procesos, si bien es más importante que la elección de la mejor de las metodologías, el realizar un control para asegurar el seguimiento de la misma.
En las fases que se establezcan en el alcance del proyecto es fundamental el incluir una fase de formación en la herramienta utilizada para un máximo aprovechamiento de la aplicación. El seguir los pasos de la metodología y el comenzar el Data Warehouse por un área específica de la empresa, nos permitirá obtener resultados tangibles en un corto espacio de tiempo.
Planteamos aquí la metodología propuesta por SAS Institute: la “Rapid Warehousing Methodology”. Dicha metodología es iterativa, y está basada en el desarrollo incremental del proyecto de Data Warehouse dividido en cinco fases:
- Definición de los objetivos
- Definición de los requerimientos de información
- Diseño y modelización
- Implementación
- Revisión
5.2.1-Definición de los objetivos
En efecto, como punto de arranque de todo, es preciso “vender la idea” a los usuarios finales de un Data Warehouse. Esto es así, por ser una idea bastante novedosa y sobre la que pueden surgir recelos de su efectividad. Estos recelos se pueden eliminar comenzando por un pequeño módulo, del cual se valoren los beneficios posteriores, para iniciar progresivamente el desarrollo de nuevos módulos, cada uno con un coste unitario cada vez más reducido, pero sin embargo con unos beneficios distribuidos cada vez mayores por poder cada vez incluir más información.
El simple hecho de realizar un informe de necesidades previas en el que se enumeren la situación de los datos entre los diversos sistemas operacionales, puede ser un hecho decisivo para emprender un proyecto de este tipo. Muchas veces la información existente se encuentra tan poco normalizada, existen tantas discrepancias entre estos sistemas, que el abordar un Data Warehouse en el que se limpien estos datos y se normalicen pueden aportar un valor intangible: “la calidad y fiabilidad de la información“.
La venta de esta idea no sólo se ha de realizar frente a la Dirección sino que es preciso realizarla a todos los niveles: a la Dirección, Gerencia e incluso al área de Desarrollo.
Tras esta venta de la idea, comienzan dos fases similares al análisis de requisitos del sistema (ARS según abreviaturas de la metodología METRICA): la definición de objetivos y requerimientos de información, en el que se analicen las necesidades del comprador.
Definición de los objetivos
En esta fase se definirá el equipo de proyecto que debe estar compuesto por representantes del departamento informático y de los departamentos usuarios del Data Warehouse además de la figura de jefe de proyecto.
Se definirá el alcance del sistema y cuales son las funciones que el Data Warehouse realizará como suministrador de información de negocio estratégica para la empresa. Se definirán así mismo, los parámetros que permitan evaluar el éxito del proyecto.
5.2.2.-Definición de los requerimientos de información
Tal como sucede en todo tipo de proyectos, sobre todo si involucran técnicas novedosas como son las relativas al Data Warehouse, es analizar las necesidades y hacer comprender las ventajas que este sistema puede reportar.
Es por ello por lo que nos remitimos al apartado de esta guía de Análisis de las necesidades del comprador. Será en este punto, en donde detallaremos los pasos a seguir en un proyecto de este tipo, en donde el usuario va a jugar un papel tan destacado.
Definición de los requerimientos de información
Durante esta fase se mantendrán sucesivas entrevistas con los representantes del departamento usuario final y los representantes del departamento de informática. Se realizará el estudio de los sistemas de información existentes, que ayudaran a comprender las carencias actuales y futuras que deben ser resueltas en el diseño del Data Warehouse
Asimismo, en esta fase el equipo de proyecto debe ser capaz de validar el proceso de entrevistas y reforzar la orientación de negocio del proyecto. Al finalizar esta fase se obtendrá el documento de definición de requerimientos en el que se reflejarán no solo las necesidades de información de los usuarios, sino cual será la estrategia y arquitectura de implantación del Data Warehouse.
5.2.3.-Diseño y modelización
Los requerimientos de información identificados durante la anterior fase proporcionarán las bases para realizar el diseño y la modelización del Data Warehouse.
En esta fase se identificarán las fuentes de los datos (sistema operacional, fuentes externas,..) y las transformaciones necesarias para, a partir de dichas fuentes, obtener el modelo lógico de datos del Data Warehouse. Este modelo estará formado por entidades y relaciones que permitirán resolver las necesidades de negocio de la organización.
El modelo lógico se traducirá posteriormente en el modelo físico de datos que se almacenará en el Data Warehouse y que definirá la arquitectura de almacenamiento del Data Warehouse adaptándose al tipo de explotación que se realice del mismo.
La mayor parte estas definiciones de los datos del Data Warehouse estarán almacenadas en los metadatos y formarán parte del mismo.
5.2.4.-Implementación
La implantación de un Data Warehouse lleva implícitos los siguientes pasos:
- Extracción de los datos del sistema operacional y transformación de los mismos.
- Carga de los datos validados en el Data Warehouse. Esta carga deberá ser planificada con una periodicidad que se adaptará a las necesidades de refresco detectadas durante las fases de diseño del nuevo sistema.
- Explotación del Data Warehouse mediante diversas técnicas dependiendo del tipo de aplicación que se de a los datos:
- Query & Reporting
- On-line analytical processing (OLAP)
- Executive Information System (EIS) ó Información de gestión
- Decision Support Systems (DSS)
- Visualización de la información
- Data Mining ó Minería de Datos, etc.
La información necesaria para mantener el control sobre los datos se almacena en los metadatos técnicos (cuando describen las características físicas de los datos) y de negocio (cuando describen cómo se usan esos datos). Dichos metadatos deberán ser accesibles por los usuarios finales que permitirán en todo momento tanto al usuario, como al administrador que deberá además tener la facultad de modificarlos según varíen las necesidades de información.
Con la finalización de esta fase se obtendrá un Data Warehouse disponible para su uso por parte de los usuarios finales y el departamento de informática.
5.2.5.-Revisión
La construcción del Data Warehouse no finaliza con la implantación del mismo, sino que es una tarea iterativa en la que se trata de incrementar su alcance aprendiendo de las experiencias anteriores.
Después de implantarse, debería realizarse una revisión del Data Warehouse planteando preguntas que permitan, después de los seis o nueve meses posteriores a su puesta en marcha, definir cuáles serían los aspectos a mejorar o potenciar en función de la utilización que se haga del nuevo sistema.
5.2.6.-Diseño de la estructura de cursos de formación
Con la información obtenida de reuniones con los distintos usuarios se diseñarán una serie de cursos a medida, que tendrán como objetivo el proporcionar la formación estadística necesaria para el mejor aprovechamiento de la funcionalidad incluida en la aplicación. Se realizarán prácticas sobre el desarrollo realizado, las cuales permitirán fijar los conceptos adquiridos y servirán como formación a los usuarios.
Ambas metodologías tienen muchos aspectos en común y utilizaremos una combinación de las técnicas descritas en ambas para la realización de nuestro proyecto PILOTO.
5.3.Otras metodologias.
En el libro Mastering data warehouse design ( Imhoff, Claudia; Galemmo, Nicholas; Geiger, Jonathan G.) ISBN:978-0-471-32421-8, podemos encontrar una metodologia para proyectos de este tipo, desde metodos para la definición del Modelo de Negocio (con consideraciones a tener el cuenta segun el sector de la empresa que estemos analizando)., recogida de requerimientos, técnicas de reuniones, así como información técnica de como modelizar y diseñar el DW.
E imprescindible para diseñar correctamente nuestro DW y para formarnos en este ambito:
The Data Warehouse Lifecycle Toolkit ( Kimball, Ralph; Ross, Margy; Thornthwaite, Warren; Mundy, Joy; Becker, Bob) ISBN: 978-0-470-149777-5
The data warehouse toolkit : the complete guide to dimensional modeling. 2ed (Kimball, Ralph; Ross, Margy) ISBN: 978-0-471-20024-7
Estos dos libros son fundamentales para entender todo lo necesario en el ambito del DW. Ademas, en la segunda edición, aparecen ejemplos de diseño en las diferentes areas de una empresa (Ventas, Contabilidad, Recursos Humanos, Finanzas) y de diferentes sectores.
Como un resumen de las metodologías descritas en estos libros, es interesante la siguiente presentación de Manuel Torres, de la Universidad de Almeria:
Como aportación interesante para nuestra tarea de construir el DW, la serie de articulos publicado en Business Intelligence Facil ( Como construir un Datawarehouse ), que nos hablan de como definir y construir los diferentes elementos que forman un DW, y sobre todo, que errones no cometer.
- Introducción: Cómo no construir un datawarehouse
- Artículo 1: Datawarehouse
- Artículo 2: Dimensiones
- Artículo 3: Jerarquías
- Artículo 4: Dimensiones lentamente cambiantes
- Artículo 5: Claves subrogadas
- Artículo 6: Tablas de hecho
- Artículo 7: DWH organizado por temas
- Artículo 8: Tablas agregadas
- Artículo 9: Máximo nivel de detalle
- Artículo 10: Rendimiento
- Artículo 11: Unificar los hechos
- Artículo 12: Unificar las dimensiones
Igualmente, os dejo los links igualmente a un serie de artículos publicados por Josep Curso en su blog, os pueden ser muy utiles en los diferentes aspectos que teneis que tener en cuenta a la hora de construir un DW:
- Definiciones de Kimball & Inmon.
- Arquitectura de un data warehouse.
- Contexto para un data warehouse.
- Data Warehousing, Data Warehouse y Data Mart.
- ¿Qué es una Staging Area?
- Definiciones.
- Estrella y copo de nieve.
- Slowly Changing dimensions (e información ampliada en la entrada del Blog de Bernabeu Dario en Dataprix, incluyendo ejemplos reales).
- Medidas (I).
- Medidas (II).
- Tabla de hecho.
Para terminar, son de gran calidad los materiales del curso “Creando el próximo DataWarehouse: Integración y Calidad de Datos”, de la Facultad de Informatica de la UPC (dentro del programa Aules Empresa 2009). Os dejo una de las presentaciones:
Nuestro primer proyecto. Definición y consideraciones iniciales.
Nuestro primer proyecto. Definición y consideraciones iniciales. respinosamilla 25 February, 2010 - 09:50Hasta aquí hemos visto en que consiste un sistema Business Intelligence, que tecnologias se utilizan en la actualidad para su desarrollo, los diferentes elementos que lo componen (bases de datos, herramientas, técnicas, etc), cuales son las tendencias actuales en dicho campo y una metodología básica para poder abordar un proyecto de este tipo.
Partiendo de aqui, vamos a pasar de la teoria a la práctica y vamos a afrontar el desarrollo de nuestro primer proyecto. Es un proyecto totalmente ficticio, basado en consideraciones generales y con el que intentaremos plasmar todo lo visto hasta ahora.
Proyecto EnoBI: nos vamos a mover en el ambito de una empresa productora de vino. Es una empresa de tamaño medio, en plena fase de expansión con la compra de varias bodegas por todo el territorio nacional y en diferentes denominaciones de origen, que pretende dotar a este plan de expansión de las herramientas tecnologicas apropiadas para afianzar dicho proceso. El proyecto se va a afrontar gradualmente, liderado por el departamento de ventas, cuyo manager ha utilizado herramientas de este tipo en otras organizaciones del sector de distribución y es consciente de las posiblidades que van a ofrecer a la empresa.
El proyecto va a consistir en la construcción de un DW departamental (Datamart), para el analisis de ventas y margenes. El Datamart se explotara con herramientas de query y reporting en un primer nivel, y con herramientas OLAP en un segundo nivel. Se prepararan cuadros de mando en los diferentes niveles del departamento de ventas para facilitar el analisis de los indicadores de negocio o KPI según el ambito de actuación. Igualmente, habra un cuadro de mando para dirección donde se presentara la información mas importante relacionada con la marcha de las ventas.
En un segundo nivel, se pretenden utilizar técnicas de analisis y de datamining para determinar nichos de mercado a los que ofrecer productos especificos (o identificar targets para el desarrollo de nuevos productos) y para el analisis de las promociones que se realizan con determinados clientes del sector distribución.
Es un proyecto piloto dentro de la empresa y si tiene exito, se aplicara a otros ambitos de la compañia.
El proyecto se quiere implementar en la fase final con dos tipos de herramientas: herramientas propietarias y herramientas open source (que definiremos mas adelante).
La fase de definición de objetivos, analisis y toma de requerimientos, asi como de modelización, diseño, construcción de la BD e implementación de los procesos ETL será común a ambos “subproyectos”.
Las herramientas a utilizar durante el proyecto serán las siguientes:
1) Herramientas para gestión de proyectos: Microsoft Project 2007.
2) Herramientas ETL: Talend y Pentaho Data Integration.
3) Herramientas para la gestión de incidencias del proyecto y el mantenimiento posterior: Eventum (Mysql).
4) Base de datos: Mysql.
5) Gestor de documentación y herramienta de colaboración: Alfresco.
En la parte final, las herramientas para la explotación del DW serán las siguientes:
5) Herramientas BI OpenSource: Pentaho Community Edition ( y la trial Pentaho BI Suite 3.5 ).
6) Herramientas BI Propietarias: Microstrategy Reporting Suite (y la trial Microstrategy 9 para los ambitos no cubiertos por las version anterior).
Definición de objetivos. Analisis de requerimientos.
Definición de objetivos. Analisis de requerimientos. respinosamilla 25 February, 2010 - 09:50La Empresa
La compañia Bodegas Vinicolas SA (BVSA) nacio en la denominación de origen Rioja en 1970 y en la actualidad, tras varios procesos de compra y ampliación de instalaciones, dispone de bodegas en Ribera del Duero, Rueda, Toro, Somontano, Priorat, Yecla, La Mancha y Alicante. En su portfolio de productos hay graneles, vinos jovenes, crianzas, reservas y gran reserva, de diferentes variedades, con o sin denominación de origen y con diferentes formatos de envasado ( garrafas, tetra brik, granel, botellas de diferentes tamaños, etc ). Cada bodega tiene su propio almacén desde el que se sirve la mercancia, aunque las ventas estan centralizadas en la Bodega de La Rioja, donde hay un Call Center que recoge todos los pedidos nacionales e internacionales, y desde el que se atiende a los clientes del Club de Vinos. Cada bodega puede tener sus propias referencias así como referencias producidas en las otras bodegas, para venta en la tiendas propias o para distribución.
La compañia trabaja con clientes de todos los tipos, desde tiendas Gourmets o especializadas en vinos, Restaurantes y Hoteles, Mayoristas, Grandes cadenas de Distribución e Hipermercados. En el caso de grandes clientes, se sirve directamente a los centros desde cada bodega, aunque hay un estudio para construir un centro logístico que recoga la producción de todas las bodegas y realize la distribución, bien directamente a los clientes o a los centros logísticos propios de cada uno de ellos. Igualmente, se venden vinos a traves de internet y venta por correo en un Club de Vinos que se ha montado con el soporte de un portal Web donde se pueden comprar las referencias, se hacen selecciones mensuales y se ofrece gran cantidad de información referente al mundo del vino a los clientes que forman parte de este club.
El Club de Vinos se quiere fomentar como un canal de venta directa por su gran potencial de crecimiento, y a partir del cual también realizar estudios especificos de mercado y lanzamiento de nuevos productos, asi como programas de fidelización.
La empresa es una empresa joven y apuesta por la tecnologia en todos los ambitos de actuación, desde el propiamente relacionado con su sector (maquinaria, recolección automatica, instalaciones modernas en las bodegas), como a nivel de sistemas de información, donde trabajan con el ERP de Sap.
Objetivos
La empresa pretende desarrollar un proyecto de BI para sacar el mayor partido posible a la información de ventas de la que dispone. El director comercial actua como sponsor de este proyecto, que ademas es un proyecto piloto dentro de la compañia y que se ampliara a otros departamentos en el caso de obtener de él el exito esperado.
La construcción del DW y el uso posterior de herramientas de BI se va a centrar en los procesos de negocio de ventas. Se pretende construir un Datamart departamental para ventas y marketing que será alimentado con la información proveniente de su sistema operacional.
El objetivo es disponer de toda la información referente a ventas, productos, clientes, logistica, promociones en un unico almacén de datos a partir del cual poder extraer información de las siguiente manera:
1) A nivel de reporting y consultas ad-hoc.
2) Navegación dimensional por los datos utilizando herramientas OLAP.
3) Preparacion de cuadros de mando para los diferentes niveles de actuación: bodegas, representantes de ventas, servicios centrales, dirección, etc.
4) Establecer las bases para estudio de promociones, analisis y dataming en los clientes del Club de Vinos.
Analisis de requerimientos
Despues de varias reuniones con el responsable comercial, los responsables comerciales de cada bodega/delegación y el departamento de sistemas, y a partir de los requerimientos de información, se decide:
a) El ambito del proyecto será, como hemos indicado, los procesos de negocio relacionados con ventas. El objetivo es tener un mejor conocimiento de la casuistica de ventas, incluyendo las promociones, para poder analizar la información desde todas las perspectivas posibles de interes para el negocio.
b) Granularidad de la información: en un principio se piensa, a partir de los requerimientos de información, quedarnos en el detalle acumulado de ventas por dia, producto, cliente. Pero durante la revisión de requerimientos se amplia el ambito del proyecto con los estudios referentes al Club de Vinos y se decide incluir también en el DW la información referente a promociones, para poder explotarla posteriormente. Por eso se decide que el nivel de granularidad sea cada uno de los pedidos de ventas, para poder reflejar en el las promociones y permitir luego estudios mas profundos a nivel de data mining. Obviando la sumarización, permitimos mas funcionalidades en el futuro. Como incoveniente, el numero de registros será mucho mayor, pero no es significativo en este proyecto, pues se trabaja con unos 2000 clientes, unas 500 referencias y no mas de 100 mil pedidos anuales.
c) Dimensiones: las perspectivas por las que se quiere analizar la informacion en la empresa BVSA son las siguientes.
Dimensión Tiempo: incluira los atributos dia, mes, año, semana, trimestre, semestre, dia semana, festivo o no.
Dimensión Producto: incluira los atributos material, familia, d.o., varietal, formato venta, unidad medida, l/envase, linea de producto, target.
Dimensión Cliente: incluira todos los atributos relacionados con el cliente, como código cliente, agrupador, responsable comercial, canal, tipo de cliente, pais, region, provincia, cod. postal y población.
Dimensión Logística: incluira los atributos relacionados con la distribucion (dejando preparado el sistema para el futuro centro logistico). Los atributos serán centro y sus propiedades (numero almacenes, capacidad, etc).
Dimensión Promociones, Ofertas, Dtos: incluira el tipo de promoción, fechas de la promoción, dto. aplicado y toda la información de interes relacionada con la promoción (publicidad, cupones, carteleria, ubicacion, etc).
d) Hechos: los valores de negocio que vamos a querer analizar serán los siguientes:
Unidades Vendidas, Venta en litros, Precio Unitario, Importe Bruto, Importe Descuentos, Importe Promociones, Importe Neto, Coste Unitario, Coste Total, Margen %, Margen Unitario, Margen total.
De este analisis podemos ya construir el modelo conceptual del DW de la empresa, que podría ser algo asi:
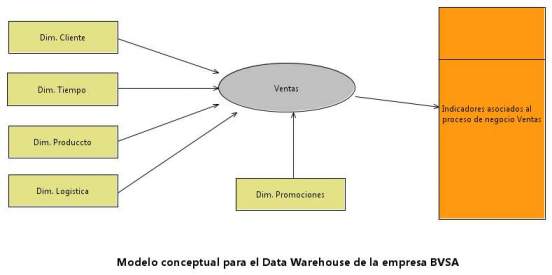
Desarrollando el modelo conceptual, vamos a profundizar en cada una de las dimensiones, construyendo el modelo lógico. El modelo inicial sería el siguiente:
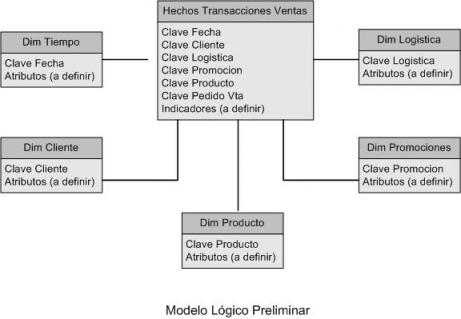
El desarrollo de cada una de las dimensiones de análisis y de los indicadores de estudio de nuestro modelo es el siguiente:
Dimensión Tiempo.
Como todos sabemos, es la dimesión básica de cualquier modelo, pues el tiempo siempre es una de las perspectivas por las que queremos analizar la información. Los datos que forman esta dimensión los generaremos para un periodo de tiempo determinado (por ejemplo 10 o 20 años, para incluir periodos pasados y periodos futuros). Vamos a intentar generar el mayor número posible de atributos para esta dimensión para facilitar luego el análisis. Ademas, el número de componentes o registros de esta dimensión va a ser limitado y no hay problemas de tamaño en la BD.
Incluira los siguientes atributos:
Fecha Clave: fecha en la notacion yyyymmdd para procesarla como enteros. Será la clave de la dimensión.
Fecha: fecha en la notación habitual (dd-mm-yyyy).
Fecha en texto: fecha formateada ( por ejemplo: 15 de abril de 2009).
Dia de la semana: dia de la semana en texto (lunes, martes, miercoles,..).
Numero de dia de la semana: dia 1,2,3…7.
Dia del Mes: numero de dia de la fecha en el mes (dia 14, dia 28, dia 31).
Dia del Año: numero de día de la fecha en el año (dia 234, dia 365).
Semana: numero de semana donde se incluye la fecha (semana 23).
Semana del año: notacion año-semana para comparativas, cabeceras (YYYY-SS, 2008-45).
Mes: número del mes en el año (Enero = 1, Febrero = 2, etc).
Descripcion del Mes: descripción en texto del mes (Enero, Febrero, Marzo,…).
Mes del año: notación año-mes para comparativas,cabeceras (YYYY-MM, 2008-11).
Trimestre: trimestre donde se incluye la fecha (1T,2T,3T o 4T).
Trimestre del año: notacion año-trimestre para comparativas, cabeceras (YYYY-TT, 2008-1T).
Semestre: semestre donde se incluye la fecha (1S, 2S).
Semestre del año: notacion año-semestre para comparativas, cabeceras (YYYY-SS, 2008-1S).
Año: año de la fecha, con 4 digitos.
Festivo: indicador de si la fecha es un festivo o no.
Fin de semana: indicador si la fecha es fin de semana o dia entre semana.
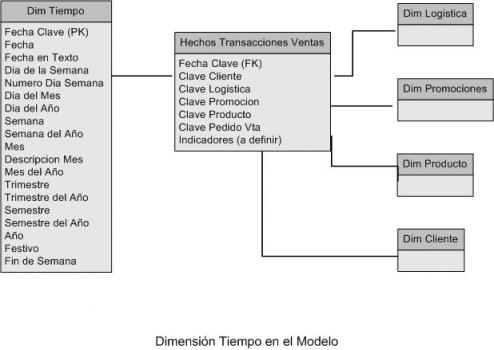
Algunos de los atributos que incluimos para esta dimensión se podrían calcular en el momento de ejecutar las consultas, pero al ser una tabla pequeña, es preferible por temas de rendimiento tenerlos ya calculados y utilizarlos cuando nos haga falta según el requerimiento de información.
Dimensión Producto.
En esta dimensión incluiremos todos los atributos relacionados con los productos de venta o materiales, tales como las diferentes clasificaciones, propiedades, etc. En nuestro modelo, tendrán relevancia las siguientes:
Material: clave que identifica a cada uno de los productos vendidos en la compañia. Es la clave de la dimensión. Utilizaremos los códigos numericos definidos en nuestro ERP, que ya estan homogeneizados.
Descripcion Material: texto que describe las características del material (por ejemplo, Viña Pomela Reserva 2004 ).
Familia: clasificación de los productos por naturaleza del producto (codigo nemotecnico que incluimos en el DW para facilitar el trabajo de los usuarios y para las relaciones con el sistema operacional).
Descripcion Familia: texto que describe los diferentes valores del atributo familia ( 01 Blanco Joven, 02 Blanco Crianza, 03 Rosado, 04 Tinto Joven, 05 Tinto Barrica 6m, 06 Tinto Crianza, 07 Tinto Reserva, 08 Tinto Gran Reserva, 09 Tinto Seleccion, 20 Aceites, 30 Productos Gourmet, 40 Quesos). Los ultimos códigos nos indican que tambien se venden productos que no son vinos, y que tambien tendremos en cuenta en nuestros análisis.
Denominación Origen: texto que nos describe la denominación de origen a la que esta adscrita el vino. Los posibles valores para este atributo serían Ribera del Duero, Rueda, Toro, Somontano, Priorat, Yecla, La Mancha y Alicante. Igualmente, hay otros vinos que estan adscritos a la categoria Vinos de la Tierra, Vinos de Autor y Vinos sin DO.
Varietal: composición del producto (variedad/es de uva utilizadas en su elaboración). Por ejemplo, Monastrell, Tempranillo, Syrah, Merlot, Carbenet, Petit Verdot, Verdejo y las combinaciones de variedades.
Formato venta: formato de venta en el que se distribuye el producto. Cada vino (aun viniendo de la misma elaboración), tendrá un codigo de producto diferente según el formato en el que se venda. Ejemplos de valores para este atributo serán Granel, Tetra Brik, Botella, Pack, Bote, Paquete (estos ultimos para productos no vinicolas).
Unidad medida: unidad de medida utilizada para la venta de los materiales (C/U, Litros, Cajas, etc).
Litros: equivalencia en litros.
Linea de producto: otra clasificación de los productos. Se incluyen los códigos del sistema operacional para facilitar el trabajo de los usuarios.
Descripción linea de producto: texto que describe cada una de las lineas de producto definidas. Por ejemplo 01 Vinos Mesa, 02 Bodega Seleccion, 03 Cavas, 04 Gran Bodega, 05 Vinos unicos, 10 Merchandising, 20 Ediciones y Publicaciones, 30 Productos Selectos. Nos permiten ver la clasificación de los materiales desde otra perspectiva.
Target: indica el segmento de mercado al que esta dirigido el producto ( Gran Consumo, Gourmet, Lujo, Jovenes, etc).
Todos estos datos estan presente en nuestro sistema operacional. El modelo lógico para esta dimensión seria algo asi:
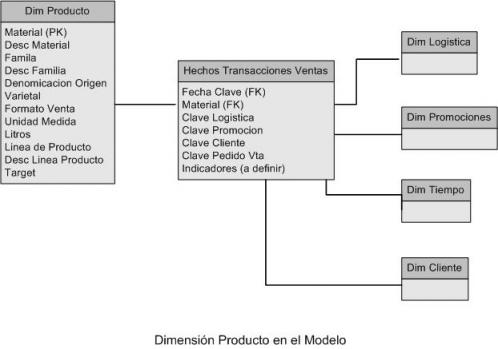
Dimensión Cliente.
La dimensión Cliente nos permitira el análisis desde la perspectiva de todos los atributos relacionados con el cliente, como código cliente, agrupador, responsable comercial, canal, tipo de cliente, pais, region, provincia, cod. postal y población. No van a permitir analizar quien nos compra, bajo que agrupaciones, clasificaciones y criterios geográficos (que van asociados a cada cliente).
Cliente: identifca al cliente que realiza una transacción de compra. Sera la clave de la dimensión Cliente.
Descripcion Cliente: Datos identificativos de cada cliente. Por ejemplo, Mercadona Muchamiel I, Carrefour San Juan, etc.
Agrupador: los clientes que pertenecen a una cadena (por ejemplo, grandes superficies), estan identificados individualmente (cada tienda, centro, etc). El agrupador es el código que agrupa a todas las tiendas o centros en un nivel superior (que podría coincidir con el nivel de facturación o contable). Por ejemplo, todos los clientes que realizan pedidos que pertenecen a Centro Comerciales Carrefour compartiran el código de agrupador, que los agrupa a todos con fines analíticos.
Descripcion Agrupador: Datos identificativos del cliente agrupador. Para el ejemplo anterior, la descripción sería Centros Comerciales Carrefour.
Responsable Comercial: responsable del departamento comercial que tiene asignado al cliente.
Canal: canal de venta. Incluimos la codificación del sistema operacional para facilitar el uso.
Descripcion Canal: descripciones de cada canal de venta (por ejemplo, 01 Venta Club, 02 Venta Directa, 03 Venta Intermediacion Propia, 04 Venta Representantes, etc.).
Tipo de Cliente: clasificacion de los clientes según su naturaleza. También se incluye la codificación del ERP.
Descripcion Tipo Cliente: descripciones de los tipos de cliente ( 01 Cliente contado, 02 Cliente Club, 03 Minorista, 04 Restauracion, 05 Hoteles, 06 Tiendas Gourmet, 07 Tiendas Bodega, 08 Supermercados, 09 Grandes Superficies, 10 Hipermercados, 11 Centrales de compras, …).
Todos los atributos relacionados con el ámbito geográfico del cliente (relacionado con el punto de venta): Pais, Region, Provincia, Cod.Postal, Poblacion.
Codigo Nielsen: codigo asociado al cliente para estudios de mercado.
El modelo lógico para la dimensión cliente sería el siguiente:
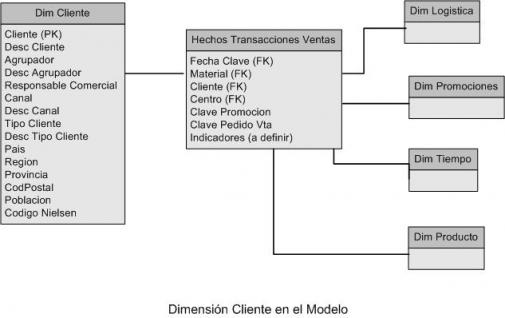
Dimensión Logística.
En esta dimensión veremos la información desde la perspectiva logística de la venta, es decir, desde que lugares se sirven las ventas. Esta información nos puede permitir en el futuro optimizar nuestros procesos de distribucion. Los atributos de esta dimensión serán los siguientes:
Centro: centro de distribución. Sera la clave de la dimensión logística.
Desc. Centro: Identificacion del centro logístico.
Todos los atributos relacionados con el ámbito geográfico del centro logístico: Pais, Region, Provincia, Cod.Postal, Poblacion. Todos los datos geográficos, que se utilizan aquí o en la dimensión cliente estan homogeneizados.
Capacidad Almacenamiento: volumen de almacenamiento disponible en m3.
Almacenes: numero de almacenes en el centro logistico/bodega.
Tecnologia almacén: tipo de tecnologia usada para la gestión del almacén.
El modelo lógico en la dimensión logística sería el siguiente:
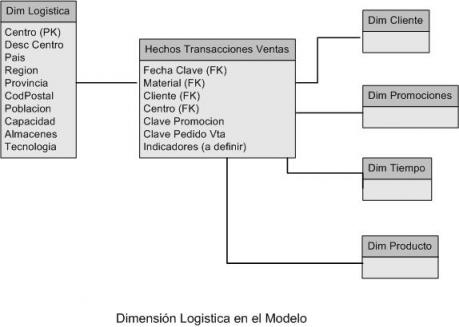
Dimensión Promociones.
La dimensión promociones es una dimensión causal (a diferencia de todas las que hemos visto hasta ahora, que eran casuales). Esto implica que el contenido de esta dimensión afecta a los procesos de venta y no todo ha quedado registrado en los sistemas transaccionales (en el erp seguramente solo haya quedado identificada la promoción y los descuentos o ventajas que aplica), pero no otros muchos aspectos.
Los atributos de la dimensión promociones serán los siguientes:
Promocion: código que identifica a la promoción. Es la clave de la dimensión.
Desc.Promoción: texto explicativo de la promoción.
Tipo Promocion: promocion propia, promoción estudio, promoción en cadena, promoción-concurso, etc.
Tipo Descuento: descuento porcentual, descuento importe, 3×2, 2×1, regalo por volumen, etc.
Tipo Publicidad: folletos, prensa, internet.
Tipo Accion: Acciones comerciales incluidas en la campaña (degustación, stand, promotores, vehiculos, etc).
Fecha Inicio: fecha inicio de la promoción.
Fecha Fin: fecha final de la promoción.
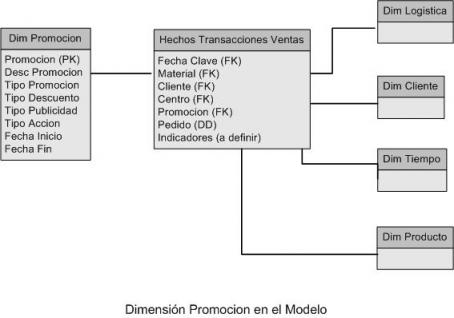
Dimensión Pedido de Venta (Dimensión Degenerada).
La dimensión pedido de venta, que es clave en la tabla de hechos, es una dimensión degenerada. Esto significa que la clave se identifica a si mismo y no tiene ningún atributo adicional, por lo que no es necesario construir una tabla de dimensión para ella. Solo lo vamos a utilizar para realizar analisis a nivel de transacción y no es necesario identificar ni concretar nada mas en el.
Indicadores de nuestro modelo (Hechos)
Los valores de negocio que querremos analizar para nuestras perspectivas o dimensiones serán los siguientes:
Unidades Vendidas: unidades vendidas en cada una de las lineas de detalle del pedido.
Venta en litros: conversión a litros (en el caso de que fuera posible) de las unidades vendidas.
Precio Unitario: precio unitario de venta.
Importe Bruto: importe bruto de venta (sin incluir condiciones comerciales de los clientes ni promociones).
Importe Descuentos: importe descuentos aplicados, según las condiciones pactadas con los clientes (no son las promociones).
Importe Promociones: importe descuentos aplicados por las promociones en curso.
Importe Neto: importe neto de las ventas, unas vez descontados los descuentos y promociones.
Coste Unitario: coste unitario del producto.
Coste Total: importe del coste total.
Margen %: porcentaje de margen de la venta.
Margen Unitario: margen unitario de venta por producto.
Margen total: margen total de la transacción.
Habrá otros muchos indicadores que se podrán construir a partir o como calculo de los definidos. A la hora de construir el modelo físico, determinaremos que indicadores nos guardamos en la base de datos y cuales se calcularan en el momento de ejecutar los informes o herramientas (por ejemplo, los indicadores no sumarizables). También puede haber indicadores que nos interese tener calculados en la base de datos por temas de diseño o por evitar errores en los cálculos según el usuario que lo defina (sería algo asi como unificar un indicador).
Nuestro modelo lógico completo, incluyendo todas las dimensiones e indicadores sería el siguiente:
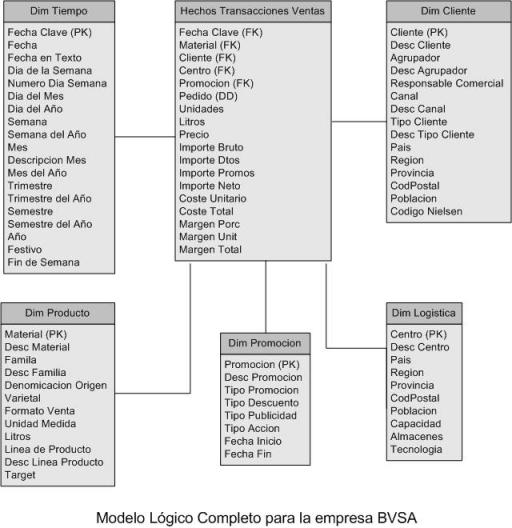
no sale nada
no sale nada
- Log in to post comments
El modelo Lógico de nuestro DW. Revisión. Construcción de un prototipo para validación.
El modelo Lógico de nuestro DW. Revisión. Construcción de un prototipo para validación. respinosamilla 25 February, 2010 - 09:50Antes de continuar con las siguientes fases del proyecto, se revisa el modelo propuesto y es aprobado. Se va a construir un prototipo para verificar su corrección y funcionalidad antes de pasar al diseño físico definitivo, el analisis del sistema ERP para la identificación de las dimensiones e indicadores y la construcción de los procesos ETL, que serán los que darán vida a nuestro DW (y que recordemos que sera una de las fases mas complejas y con mas carga de trabajo del proyecto).
Como hemos indicado anteriormente, el módelo lógico definitivo sería el siguiente:

La fase de construcción de un prototipo se podría obviar pero es interesante dedicar unas jornadas a la construcción de un pequeño prototipo con datos reales (o lo mas reales posible ) para que los usuarios puedan validar los resultados del diseño. De esta forma, validamos el modelo antes de empezar la tediosa tarea de construirlo fisicamente y llenarlo de datos desde nuestros sistemas operacionales u otras fuentes. En algunos proyectos, la construcción del prototipo se realiza en el momento de la venta del proyecto como una herramienta de ayuda a la toma de decisión de la compra.
Para la construcción de nuestro prototipo, partiendo del modelo lógico, vamos a utilizar Mysql ( y la herramienta de diseño Mysql Workbench ). Para la construcción del prototipo, utilizaremos la Microstrategy Reporting Suite. Es la suite gratuita que Microstrategy ha lanzado al mercado para hacer frente a la proliferación de los productos OpenSource y para establecer su propia estrategia de captación de clientes (hoy en día ya no valen estrategias de precios de licencia por las nubes). En nuestro caso, hemos registrado una licencia para 25 usuarios. La licencia free incluye lo siguiente:
Características incluidas en Microstrategy Reporting Suite: www.microstrategy.es
Puede ser un buen punto de partida para un pequeño proyecto o para la validación de productos (aunque al final estamos con un fabricante propietario y estamos de alguna manera “cogidos” a un producto cerrado ). Tener en cuenta que tenemos acceso a una gran parte de las herramientas, así como soporte por correo y online, recursos de formación, video tutoriales, etc, que pueden ser una gran ayuda para familiarizarnos con el producto. También se incluye una amplia documentación en pdf de todos los elementos que forman la suite.
En las entradas del blog iremos publicando el modelo de datos físico utilizado para la construcción del prototipo, la copia de seguridad de mysql con los datos “reales” cargados y los metadatos definidos en la herramienta de Microstrategy por si alguien se anima a construir y validar su propio prototipo.
Por tanto, las cuatro fases de construcción del prototipo serán las siguientes:
1) Diseño físico “preliminar”, orientado a la construcción del prototipo.
Construimos el modelo relacional a través de la herramienta MySQL Workbench, y el diseño final sería el siguiente:
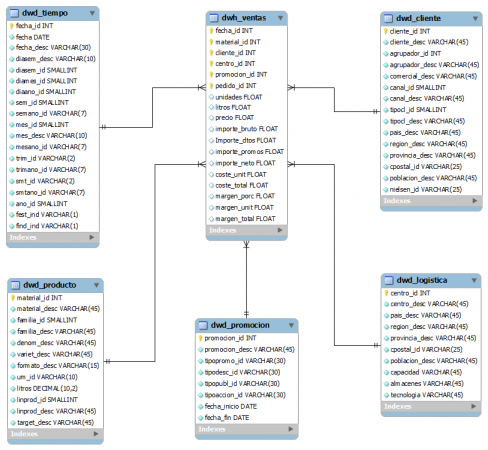
Antes de continuar, y al revisar el modelo físico, nos damos cuenta que es conveniente seguir un criterio para el nombrado de los campos que luego facilite el trabajo en la definición del modelo de datos con las herramientas de Microstrategy, asi como en el momento de definir las jerarquias de los atributos de las dimensiones (tema del que todavia no hemos hablado).
Por tanto, antes de continuar, procedemos a un ajuste del módelo fisico y la nomenclatura de los campos (por ejemplo, para los atributos que haya un código y una descripción, siempre llamaremos campox_id al campo del atributo, y campo campox_desc al campo de descripción del atributo). Es una forma de normalizar y utilizar un convenio que nos permite luego trabajar con mas claridad (teniendo en cuenta la cantidad de atributos diferentes de los que disponemos en nuestro proyecto). Para los atributos donde solo haya un identificador (sea numerico o texto, como por ejemplo, para la denominación de origen), llamaremos al campo nombreatributo_id (por ejemplo denomin_id para la denominación de origen de un producto o variet_id para la varietal utilizada en la elaboración del vino).
El esquema fisico revisado quedaría así:
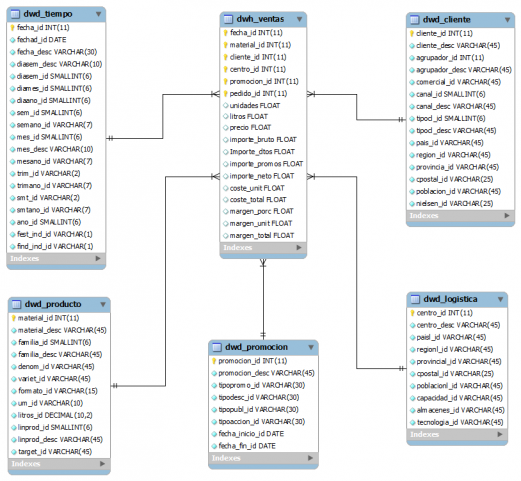
El fichero del modelado con la herramienta lo podeis encontrar en el link: enobi.mwb
El fichero con las sentencias sql para la creación del esquema fisico en el link: enobi.sql
2) Llenado de datos “reales”.
En MySQL, creamos un catalogo que se llama EnoBI. Este catalogo va a almacenar los datos de nuestro DW (luego veremos que tenemos otros catalogos, como el del Metadatos de Microstrategy, el de estadísticas, etc). En este catalogo creamos las tablas físicas tal y como hemos definido y creamos un juego de datos de ejemplo para poder validar el modelo con el prototipo. Algunos ejemplos de los datos simulados serian los siguientes:
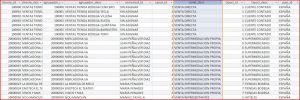
Ejemplo de Datos Simulados
El acceso completo a los datos lo teneis en el link siguiente, donde se accede al fichero de backup de la base de datos realizado con MySQL Administrator: backup.sql
3) Implementación del modelo utilizando Microstrategy Reporting Suite. Definición del modelo de metadatos.
Una vez tenemos preparada nuestra base de datos, ya podemos empezar a preparar el entorno de la Microstrategy Reporting Suite para trabajar con dicha base de datos y para hacer el modelado que luego nos va a permitir utilizar las herramientas de Microstrategy. Debemos realizar varias tareas, que en resumen son:
- Instalación de la Microsoft Reporting Suite. Registro de la licencia y activación. En nuestro caso, hemos instalado en un Windows 7 Ultimate (necesitamos tener instalado el Office XP o superior y tener activado el IIS Internet Information Server en el sistema, pues la Suite hace uso de ella para el tema de acceso Web a los informes).
- Configuración de origenes ODBC: en nuestro caso, no tenemos acceso directo a la bd de datos y vamos a definir los siguientes origenes de datos ODBC:
- Metadatos: es el catalogo donde Microstrategy se va a guardar todas las definiciones del modelo de datos, informes, etc. Le llamamos ENOBI_MD.
- Historial: donde Microstrategy se guarda un historial de las acciones realizadas sobre los objetos. Le llamamos ENOBI_HS.
- Origen de datos: será para acceder a datos del DW en si. Le llamamos ENOBI_DW.
- Ejecución del Configuration Wizard: nos va a permitir realizar de forma asistida la configuración de los elementos mas importantes del sistema. Se configuran 3 aspectos:
- Tablas de repositorio de metadatos e historial: no pide el catalogo donde se van a ubicar y ejecuta las sentencias sql para crear la estructura de tablas necesaria.
- Configuración del Microstrategy Intelligence Server.
- Configuración de Origenes del Proyecto: definición de un origen de Proyecto y su vinculación con el Microstrategy Intelligence Server. Luego sobre el podremos construir nuestro proyecto de BI.
- A continuación vamos a crear nuestro proyecto. Podemos utilizar el Project Builder o la herramienta Desktop (con el Architect o el Project Creation Assistant), donde se realiza la creación del proyecto con un asistente y luego se mantienen los diferentes elementos que lo conforman. Vamos a utilizar el Project Builder para este primer paso (es una herramienta orientada a la construcción de prototipos y para la construcción de Sistemas Productivos se recomienda el Architect/Project Creation Assitant ). El resumen de pasos seguido es el siguiente:
- Selección del origen de datos para guardar los metadatos e identificación del proyecto. Al seleccionar el origen del proyecto estamos indicado en que esquema de bd de metadatos vamos a guardar todo el modelo.
- Selección del origen de datos del DW.
- Selección de la tabla de hechos.

- Selección de indicadores de nuestro modelo: campos de tabla de hechos que queremos utilizar como indicadores de negocio en nuestro modelo.
- Selección de atributos de las dimensiones.
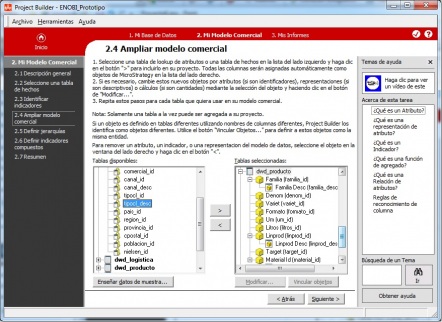
- Definición de las jerarquias entre los atributos: ya veremos en el desarrollo del proyecto como se definen las jerarquias de los diferentes atributos que tenemos en nuestras dimensiones (que al fin y al cabo son los que nos van a permitir la navegación estructurado por los datos). Sin jerarquía el modelo dimensional no tiene sentido.
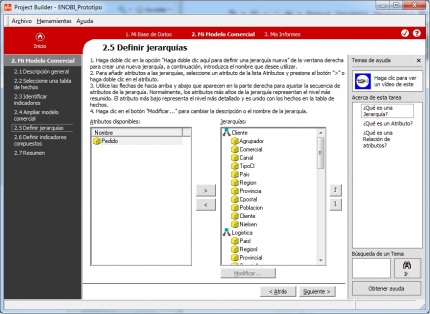
- Definición de indicadores calculados (a partir de indicadores base).
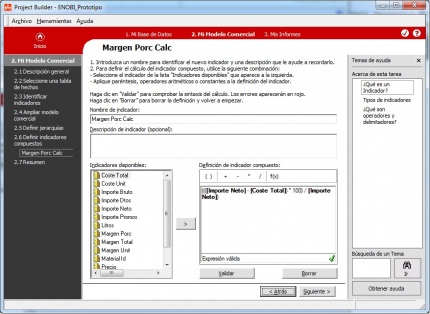
Realizamos algunos ajustes en las jerarquias, así como en la definición de indicadores y la asociación que realiza Microstrategy entre los campo id y los campos desc. El modelo esta preparado para la definición de los informes de ejemplo para presentar para la aprobación del módelo lógico presentado.
La definición de las jerarquias de los atributos las podeis encontrar en un documento word en el link: jerarquias.doc
4) Construcción de informes ejemplo. Preparación de la plataforma de prototipo para la revisión con usuarios.
En la siguiente entrada del blog analizaremos los informes construidos para el prototipo, con ejemplos de los mas usuales.
El enlace al fichero de back
El enlace al fichero de back up de la base de datos esta caido, alguien lo tiene por ahi??
Estoy siguiendo este ejemplo y me vendría fenomenal
Muchas gracias.
- Log in to post comments
Enhorabuena con su
Enhorabuena con su presentación! Muy clara, y muy instrcutiva.
Utilizo Birst pero eso me parece un alternativo muy interesante.
- Log in to post comments
Estaba emocionado con el
Estaba emocionado con el ejemplo, lastima que ya n oesten disponibles los archivos.
- Log in to post comments

He preguntado a Roberto, y me
He preguntado a Roberto, y me ha dicho que los ficheros se perdieron en un cambio de proveedor de hosting. Es una pena, pero desde luego con sus explicaciones ya está aportando mucha luz a todo aquel que se está iniciando en el mundo del BI o de MicroStrategy.
Si alguien se anima a preparar un ejemplo nuevo que me lo pase, y lo adjuntamos al tutorial.
Saludos!
- Log in to post comments
Presentación del prototipo. Ajustes en el módelo para análisis de clientes.
Presentación del prototipo. Ajustes en el módelo para análisis de clientes. respinosamilla 25 February, 2010 - 09:50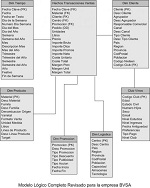 Despues de trabajar unos dias en el, hemos conseguido construir nuestro prototipo reflejando en el toda la estructura de nuestro modelo lógico.
Despues de trabajar unos dias en el, hemos conseguido construir nuestro prototipo reflejando en el toda la estructura de nuestro modelo lógico.
Ademas, hemos generado un lote de informes ejemplo para poder presentar al “cliente” y con ellos explotar todas las posibilidades del diseño elegido.
Algunos de los informes son los siguientes.
Ventas por canal y día de la semana (en formato Web, es decir, accediendo desde el portal via navegador)...
Despues de trabajar unos dias en el, hemos conseguido construir nuestro prototipo reflejando en el toda la estructura de nuestro modelo lógico.
Ademas, hemos generado un lote de informes ejemplo para poder presentar al “cliente” y con ellos explotar todas las posibilidades del diseño elegido.
Algunos de los informes son los siguientes.
- Ventas por canal y día de la semana (en formato Web, es decir, accediendo desde el portal via navegador):
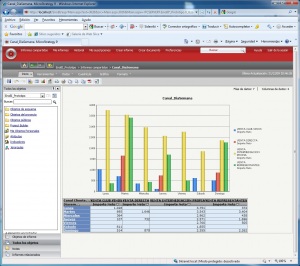
- Ventas por linea de producto y semana (Web):
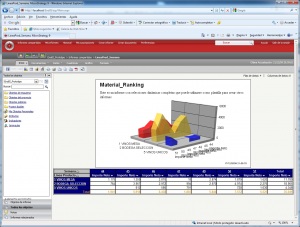
- Año y Linea de Producto (Web):
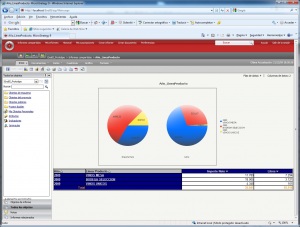
- Analisis de promociones Web (Via Microstrategy Desktop):
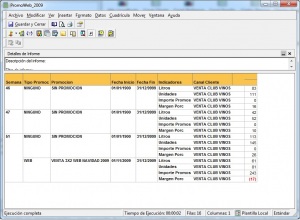
Al observar este informe vemos que hay rentabilidades negativas, y navegamos a nivel de cliente y de material para ver que estamos, con la promoción, vendiendo por debajo de coste:
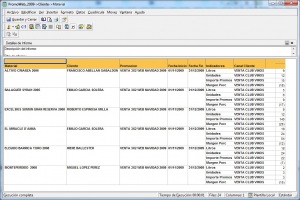
En este informe hemos utilizado los umbrales para poder dar formato o colores diferentes a los indicadores que queremos que nos avisen de algún hecho a tener en cuenta (en este caso, rentabilidad negativa).
- Ventas por región (Via Microstrategy Desktop):
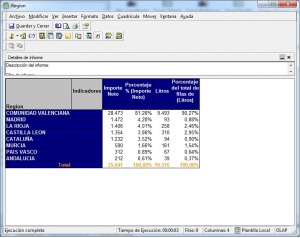
En este informe hemos utilizado otro aspecto interesante, que es la generación de porcentajes según el peso de un valor en el total de valores de un indicador (para nuestro ejemplo, el importe neto de ventas y el total de litros vendidos).
- Ventas por Tipo Cliente / Linea Producto (Via Microstrategy Desktop):
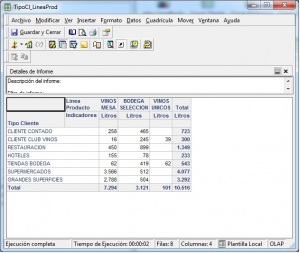
- Analisis de Ventas y Rentabilidad por Tipo Cliente (Via Microstrategy Desktop):
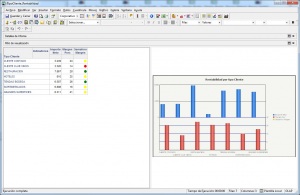
En este informe hemos utilizado umbrales con un simbolo con diferentes colores según el rango de valores del indicador, que nos servira para localizar valores por debajo de lo deseado, valores en el limite o valores por encima de los previsto (de una forma gráfica muy rapida de analizar).
- Ranking de ventas por Cliente (en este hemos utilizado los porcentajes sobre el indicador y hemos ordenado por el porcentaje para sacar los clientes con mayores volumenes):
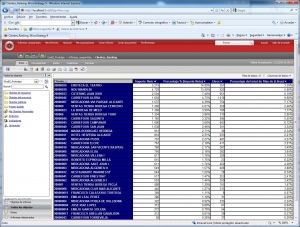
El mismo informe, pero ejecutando desde el Desktop en lugar de la Web.
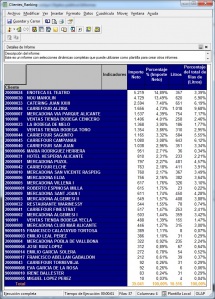
- Informe de Ventas por Denominación de Origen y Varietal (Variedad de Uva utilizada en la elaboración):
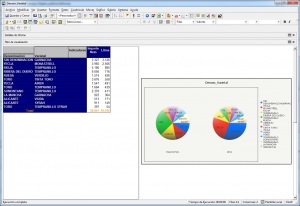
En este informe se observa, gracias al grafico de tarta, que aunque por volumen de litros la uva mas vendida es la Garnacha sin denominación de origen, el mayor volumen de ventas en importe lo tenemos en la varietal Tempranillo de la denominación de origen de Ribera del Duero.
- Ranking de Materiales:
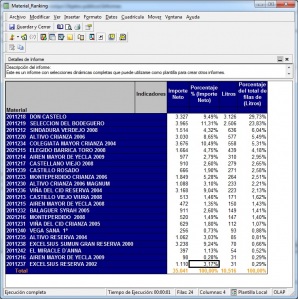
- Analisis de ventas por Target (destino):
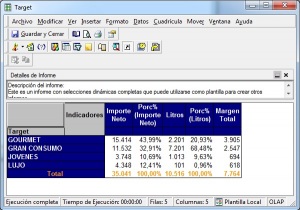
En este informe también se observa que aunque el mayor volumen de litros lo tenemos en el Target Gran Consumo, el mayor volumen de ventas esta en Gourmet (de ahí que la empresa quiera fomentar ese target, utilizando, por ejemplo, el Club de Vinos).
- Análisis de ventas por Mes y Canal:
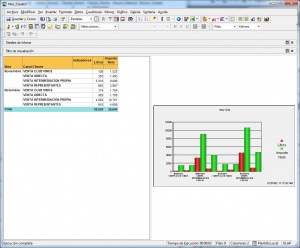
En este informe observamos la subida de las ventas en el mes de diciembre en todos los canales por la Navidad.
- Analisis de ventas por día y Canal:
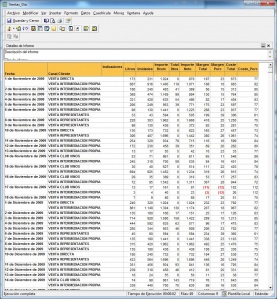
Como ejemplo de navegación, hemos seleccionado el día 01 de Noviembre y hemos ido a la dimensión Cliente, al atributo Agrupador, de la siguiente manera:
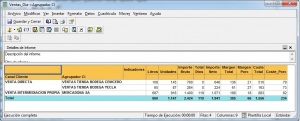
El mismo informe utilizando el portal Web quedaría:
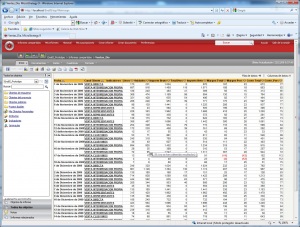
Y la navegación por las dimensiones en Web:
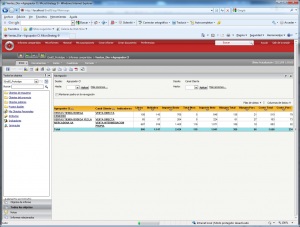
La navegación hacia arriba en las dimensiones quedaría algo asi:
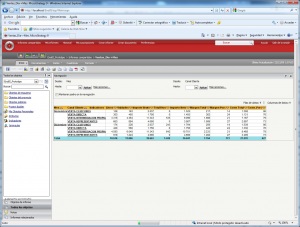
- Ventas por centro de distribución y denominación origen:
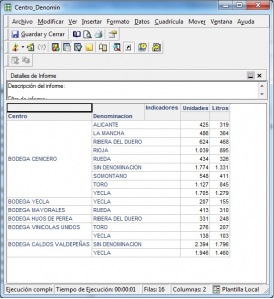
- Ejemplo de dimensiones y jerarquias definidas en el Prototipo para la navegación por la información:
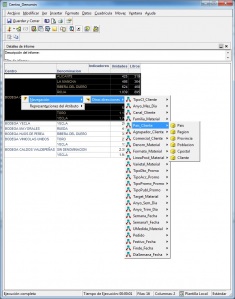
Con todos estos informes nos hemos hecho una idea y hemos podido mostrar al cliente las posibilidades de la herramienta y alguno de los análisis que podriamos realizar. Pero ahora vamos a ver los inconvenientes, es decir, donde nuestro Modelo Lógico no ha llegado y que cosas se han de reajustar.
Ajustes en el módelo para análisis de clientes
Uno de los requerimientos de nuestro cliente era que el Datamart departamental de Ventas nos permitiese hacer un análisis profundo de los clientes del Club de Vinos, para realizar análisis sobre ellos, estudio de lanzamiento de nuevos productos, promociones, etc.
Durante la revisión del prototipo, se constata que se ha de ampliar la información referente a los clientes de este canal. Es decir, se han de añadir nuevos atributos a la dimensión cliente para poder facilitar posteriormente nuevos análisis. Los atributos añadidos en la fase de revisión son los siguientes:
- Edad.
- Estado Civil.
- Numero Hijos.
- Sexo.
- Email.
- Nivel Estudios.
- Nivel Ingresos.
- Fecha Antiguedad.
- Preferencias.
- Tipo Pago.
- Nivel Club (Estandar, Oro, Platino).
Como hemos visto, también se han añadido criterios para poner en marcha el club de fidelización y poder hacer ofertas especificas y personalizadas para los clientes mas antiguos o los clientes con mayor nivel de compra.
Tras la revisión, el modelo lógico con los cambios en la dimensión de clientes quedaría así:
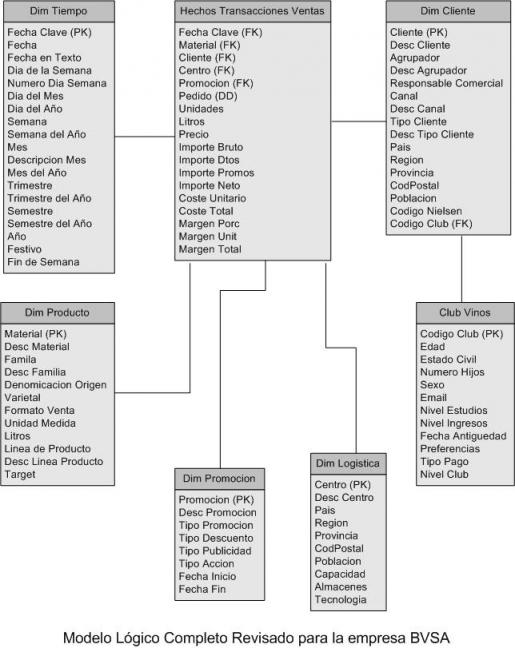
Hemos modificado nuestro esquema en Estrella a un esquema en Copo de Nieve para añadir una nueva rama en la dimensión cliente donde se registran los datos correspondientes a los clientes que son del Club de Vinos.
Nuestro proyecto sigue avanzando y es hora de continuar con el resto de pasos. A partir de ahora, vamos a analizar los sistemas operacionales para identificar los origenes de la información (desde donde llenaremos nuestro DW), construir el modelo físico definitivo e implementar los procesos de traspaso de información (carga inicial y procesos de actualización regulares). En ese momento entrarán en juego las herramientas ETL, que nos permitiran que nuestro proyecto tome vida definitiva con los datos reales del cliente. Como hemos indicado varias veces, es una de las partes mas complejas del proyecto y puede suponer hasta el 80% del esfuerzo de construcción de un DW.
Análisis del sistema Operacional para identificación de Dimensiones, Atributos e Indicadores. Preparación de los procesos ETL.
Análisis del sistema Operacional para identificación de Dimensiones, Atributos e Indicadores. Preparación de los procesos ETL. respinosamilla 25 February, 2010 - 09:50Una vez disponemos del módelo lógico completo y revisado, vamos a analizar cada una de las dimensiones, sus atributos e indicadores de negocio para identificar en los sistemas operacionales de la empresa el origen de los datos. Es decir, el lugar en las tablas de las aplicaciones ( aquí también caben otros origenes de información, como aplicaciones web, hojas excel, ficheros planos, etc), desde los cuales vamos a obtener los datos para llenar de manera efectiva nuestro DataWarehouse.
Este proceso de análisis será el punto de partida para la construcción de los procesos ETL ( Extraction, Transform and Load ) que nos permitirán automatizar la carga de nuestro sistema BI. Los procesos ETL seran un conjunto de trabajos o jobs, con diferentes pasos de diferentes tipos ( extracción de datos, filtrado, transformación, mapeo, verificación de errores, logs, etc), que provocaran que nuestro modelo lógico sea llenado con los datos de los sistemas de gestión de la empresa y de esa manera permitir su analisis según los requerimientos establecidos utilizando las herramientas de Business Intelligence.
La metodología para la identificación de cada uno de los componentes de nuestro DW va a consistir en revisar una por una las dimensiones y sus atributos, así como la tabla de hechos, y para cada componente, anotaremos en que lugar del sistema origen se encuentra, cuales son sus características, que tipo de transformaciónes deberemos realizar sobre ellos así como cualquier otra observación a tener en cuenta para la elaboración posterior de los procesos ETL.
Dimensión Tiempo: la dimensión tiempo es una dimensión ficticia, que no existe en nuestro ERP o sistema operacional como tal, y que construiremos a partir de los calendarios (en nuestro caso, generaremos los datos correspondientes a 20 años, desde el año 2000 al año 2020). Para la construcción de la dimensión y de todos sus atributos, construiremos un proceso ETL para la carga inicial de esta dimensión.

Transformaciones para la creación de la Dimensión Tiempo
Dimensión Producto: los datos principales de la dimensión Producto están en nuestro ERP Sap en la tabla MARA Maestro de Materiales. El origen de cada uno de los atributos y las transformaciones a realizar vienen descritas en la siguiente tabla:
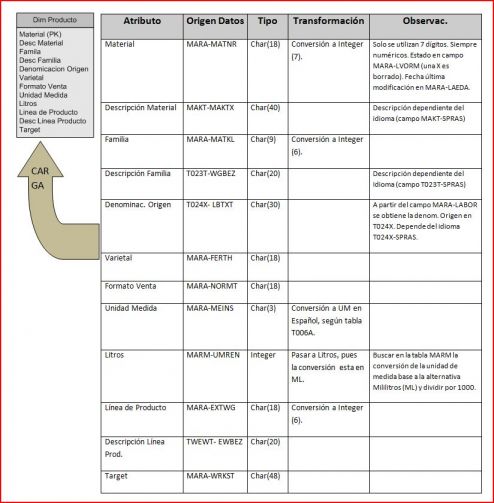
Transformaciones para la creación de la Dimension Producto
Dimensión Cliente: los principales datos de los clientes en Sap los tenemos en la tabla KNA1. El origen de cada uno de los atributos y las transformaciones a realizar vienen descritas en la siguiente tabla:
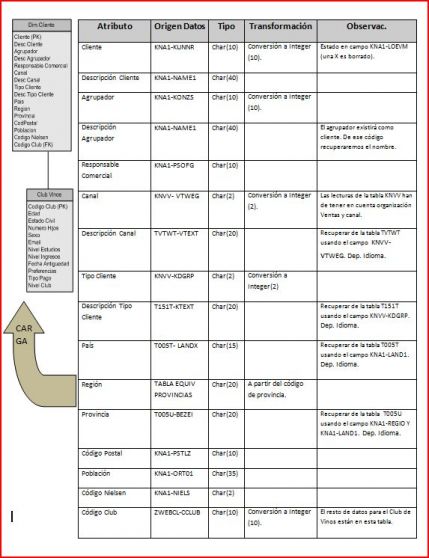
Transformaciones para la creación de la Dimension Cliente
Dimensión Logística: Los datos de los centros logísticos se encuentran en la tabla T001W. El origen de cada uno de los atributos y las transformaciones a realizar vienen descritas en la siguiente tabla:
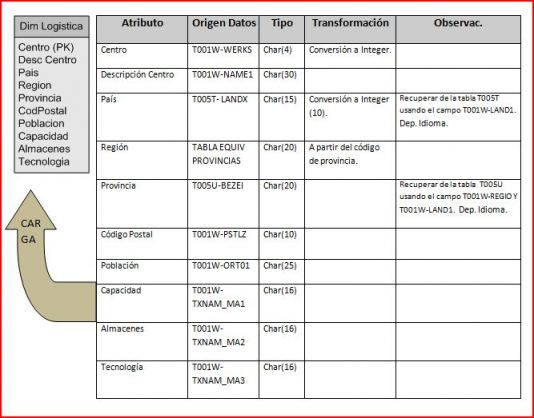
Transformaciones para la creación de la Dimension Logistica
Dimensión Promoción: Los datos de las promociones se encuentran en la tabla KONA. El origen de cada uno de los atributos y las transformaciones a realizar vienen descritas en la siguiente tabla:
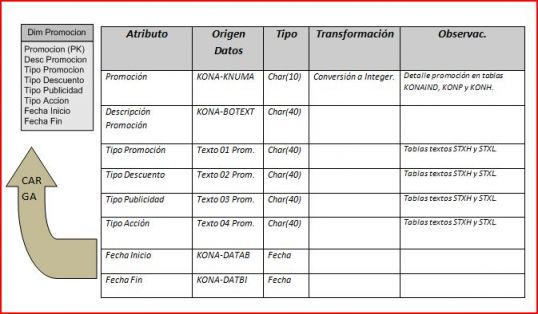
Transformaciones para la creación de la Dimension Promocion
Hechos Transacciones de Ventas: los datos de negocio de las operaciones de venta estan registrados en las tablas de pedido de nuestro ERP y en tablas paralelas (cabecera de ventas VBAK y detalle de ventas VBAP) . El origen de las claves de la tabla de hechos y de los indicadores de negocio, asi como las transformaciones a realizar vienen descritas en la siguiente tabla:
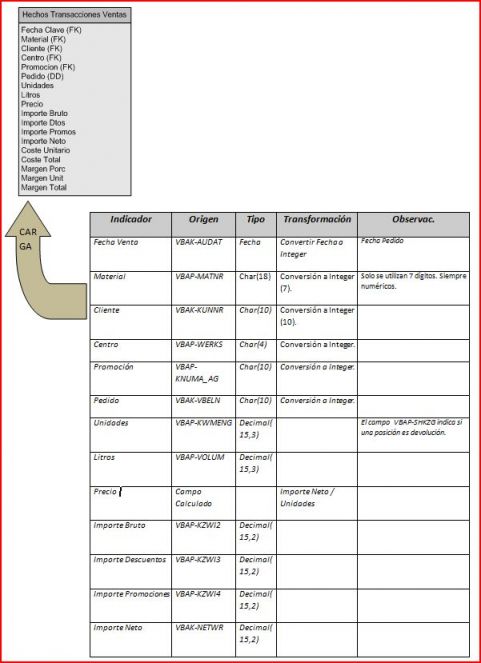
Transformaciones para la creación de la tabla Hechos de Venta (I)
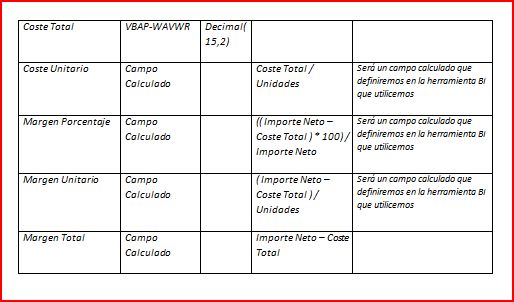
Transformaciones para la creación de la tabla Hechos de Venta (II)
Los campos calculados no siempre es necesario guardarlos en la tabla de Hechos, sobre todo si son campos que no tiene sentido tener calculado cuando estemos navegando por las dimensiones (como los porcentajes). Nos guardaremos para ellos los operadores necesarios para poder realizar los cálculos.
Nota: el origen de los datos aquí descrito es un modelo de ejemplo que puede tener una complejidad mayor o diferencias considerables si estuviesemos trabajando con sistemas reales. Solo trata de ser un ejemplo de como se deben de identificar los origenes de datos para el posterior proceso de extracción (recordar que estamos trabajando con un empresa ficticia para el desarrollo del proyecto). En la documentación también se debería de tener en cuenta cualquier casuistica a aplicar en cada atributo de cara a su conversión en atributos normalizados dentro del DW e incluir esas excepciones en la documentación de cara a los procesos ETL y a posteriores mantenimientos sobre el sistema.
Antes de continuar, veremos en la siguiente entrada del blog que son las herramientas ETL con un poco mas de profundidad, antes de pasar a la construcción del modelo físico definitivo y los procesos de llenado.
Herramientas ETL. ¿Que son, para que valen?. Productos mas conocidos. ETL´s Open Source.
Herramientas ETL. ¿Que son, para que valen?. Productos mas conocidos. ETL´s Open Source. respinosamilla 25 February, 2010 - 09:50En la publicación 3 de nuestro Blog, cuando hablabamos de Data Warehousing, pasamos por encima de las herramientas ETL, considerandolas un elemento fundamental en la construcción, explotación y evolución de nuestro Data Warehouse (DW).

Esquema Tipico de Herramienta ETL
[[ad]]
Decíamos que las herramientas ETL, deberían de proporcionar, de forma general, las siguientes funcionalidades:
- Control de la extracción de los datos y su automatización, disminuyendo el tiempo empleado en el descubrimiento de procesos no documentados, minimizando el margen de error y permitiendo mayor flexibilidad.
- Acceso a diferentes tecnologías, haciendo un uso efectivo del hardware, software, datos y recursos humanos existentes.
- Proporcionar la gestión integrada del Data Warehouse y los Data Marts existentes, integrando la extracción, transformación y carga para la construcción del Data Warehouse corporativo y de los Data Marts.
- Uso de la arquitectura de metadatos, facilitando la definición de los objetos de negocio y las reglas de consolidación.
- Acceso a una gran variedad de fuentes de datos diferentes.
- Manejo de excepciones.
- Planificación, logs, interfaces a schedulers de terceros, que nos permitiran llevan una gestión de la planificación de todos los procesos necesarios para la carga del DW.
- Interfaz independiente de hardware.
- Soporte en la explotación del Data Warehouse.
Es hora de ampliar las definiciones y entrar un poco mas a fondo en lo que son realmente las ETL´s:
Definición de ETL
Si ampliamos las definiciones, en la Wikipedia se dice lo siguiente de las herramientas ETL:
ETL son las siglas en inglés de Extraer, Transformar y Cargar (Extract, Transform and Load). Es el proceso que permite a las organizaciones mover datos desde múltiples fuentes, reformatearlos y limpiarlos, y cargarlos en otra base de datos, data mart, o data warehouse para analizar, o en otro sistema operacional para apoyar un proceso de negocio.
Los procesos ETL también se pueden utilizar para la integración con sistemas heredados (aplicaciones antiguas existentes en las organizaciones que se han de integrar con los nuevos aplicativos, por ejemplo, ERP´s. La tecnología utilizada en dichas aplicaciones puede hacer dificil la integración con los nuevos programas).
Proceso de Extracción con Software ETL
[[ad]] La primera parte del proceso ETL consiste en extraer los datos desde los sistemas de origen. La mayoría de los proyectos de almacenamiento de datos fusionan datos provenientes de diferentes sistemas de origen. Cada sistema separado puede usar una organización diferente de los datos o formatos distintos. Los formatos de las fuentes normalmente se encuentran en bases de datos relacionales o ficheros planos, pero pueden incluir bases de datos no relacionales u otras estructuras diferentes. La extracción convierte los datos a un formato preparado para iniciar el proceso de transformación.
Una parte intrínseca del proceso de extracción es la de analizar los datos extraídos, de lo que resulta un chequeo que verifica si los datos cumplen la pauta o estructura que se esperaba. De no ser así los datos son rechazados.
Un requerimiento importante que se debe exigir a la tarea de extracción es que ésta cause un impacto mínimo en el sistema origen. Si los datos a extraer son muchos, el sistema de origen se podría ralentizar e incluso colapsar, provocando que éste no pueda utilizarse con normalidad para su uso cotidiano. Por esta razón, en sistemas grandes las operaciones de extracción suelen programarse en horarios o días donde este impacto sea nulo o mínimo.

Interfaz Grafico herramienta ETL
Proceso de Transformación con una Herramienta ETL
La fase de transformación de un proceso de ETL aplica una serie de reglas de negocio o funciones sobre los datos extraídos para convertirlos en datos que serán cargados. Algunas fuentes de datos requerirán alguna pequeña manipulación de los datos. No obstante en otros casos pueden ser necesarias aplicar algunas de las siguientes transformaciones:
- Seleccionar sólo ciertas columnas para su carga (por ejemplo, que las columnas con valores nulos no se carguen).
- Traducir códigos (por ejemplo, si la fuente almacena una “H” para Hombre y “M” para Mujer pero el destino tiene que guardar “1″ para Hombre y “2″ para Mujer).
- Codificar valores libres (por ejemplo, convertir “Hombre” en “H” o “Sr” en “1″).
- Obtener nuevos valores calculados (por ejemplo, total_venta = cantidad * precio).
- Unir datos de múltiples fuentes (por ejemplo, búsquedas, combinaciones, etc.).
- Calcular totales de múltiples filas de datos (por ejemplo, ventas totales de cada región).
- Generación de campos clave en el destino.
- Transponer o pivotar (girando múltiples columnas en filas o viceversa).
- Dividir una columna en varias (por ejemplo, columna “Nombre: García, Miguel”; pasar a dos columnas “Nombre: Miguel” y “Apellido: García”).
- La aplicación de cualquier forma, simple o compleja, de validación de datos, y la consiguiente aplicación de la acción que en cada caso se requiera:
- Datos OK: Entregar datos a la siguiente etapa (Carga).
- Datos erróneos: Ejecutar políticas de tratamiento de excepciones (por ejemplo, rechazar el registro completo, dar al campo erróneo un valor nulo o un valor centinela).

Interfaz Grafico de la herramienta ETL Kettle - Pentaho
Proceso de Carga con Software de ETL
La fase de carga es el momento en el cual los datos de la fase anterior (transformación) son cargados en el sistema de destino. Dependiendo de los requerimientos de la organización, este proceso puede abarcar una amplia variedad de acciones diferentes. En algunas bases de datos se sobrescribe la información antigua con nuevos datos. Los data warehouse mantienen un historial de los registros de manera que se pueda hacer una auditoría de los mismos y disponer de un rastro de toda la historia de un valor a lo largo del tiempo.
Existen dos formas básicas de desarrollar el proceso de carga:
- Acumulación simple: La acumulación simple es la más sencilla y común, y consiste en realizar un resumen de todas las transacciones comprendidas en el período de tiempo seleccionado y transportar el resultado como una única transacción hacia el data warehouse, almacenando un valor calculado que consistirá típicamente en un sumatorio o un promedio de la magnitud considerada.
- Rolling: El proceso de Rolling por su parte, se aplica en los casos en que se opta por mantener varios niveles de granularidad. Para ello se almacena información resumida a distintos niveles, correspondientes a distintas agrupaciones de la unidad de tiempo o diferentes niveles jerárquicos en alguna o varias de las dimensiones de la magnitud almacenada (por ejemplo, totales diarios, totales semanales, totales mensuales, etc.).
La fase de carga interactúa directamente con la base de datos de destino. Al realizar esta operación se aplicarán todas las restricciones y triggers (disparadores) que se hayan definido en ésta (por ejemplo, valores únicos, integridad referencial, campos obligatorios, rangos de valores). Estas restricciones y triggers (si están bien definidos) contribuyen a que se garantice la calidad de los datos en el proceso ETL, y deben ser tenidos en cuenta.
Procesamiento en Herramientas ETL
Un desarrollo reciente en el software ETL es la aplicación de procesamiento paralelo. Esto ha permitido desarrollar una serie de métodos para mejorar el rendimiento general de los procesos ETL cuando se trata de grandes volúmenes de datos. Hay 3 tipos principales de paralelismos que se pueden implementar en las aplicaciones ETL:
- De datos: Consiste en dividir un único archivo secuencial en pequeños archivos de datos para proporcionar acceso paralelo.
- De segmentación (pipeline): Permitir el funcionamiento simultáneo de varios componentes en el mismo flujo de datos. Un ejemplo de ello sería buscar un valor en el registro número 1 a la vez que se suman dos campos en el registro número 2.
- De componente: Consiste en el funcionamiento simultáneo de múltiples procesos en diferentes flujos de datos en el mismo puesto de trabajo.
Estos tres tipos de paralelismo no son excluyentes, sino que pueden ser combinados para realizar una misma operación ETL.
Una dificultad adicional es asegurar que los datos que se cargan sean relativamente consistentes. Las múltiples bases de datos de origen tienen diferentes ciclos de actualización (algunas pueden ser actualizadas cada pocos minutos, mientras que otras pueden tardar días o semanas). En un sistema de ETL será necesario que se puedan detener ciertos datos hasta que todas las fuentes estén sincronizadas. Del mismo modo, cuando un almacén de datos tiene que ser actualizado con los contenidos en un sistema de origen, es necesario establecer puntos de sincronización y de actualización.
Desafíos para los procesos y Herramientas de ETL
[[ad]] Los procesos ETL pueden ser muy complejos. Un sistema ETL mal diseñado puede provocar importantes problemas operativos.
En un sistema operacional el rango de valores de los datos o la calidad de éstos pueden no coincidir con las expectativas de los diseñadores a la hora de especificarse las reglas de validación o transformación. Es recomendable realizar un examen completo de la validez de los datos (Data profiling) del sistema de origen durante el análisis para identificar las condiciones necesarias para que los datos puedan ser tratados adecuadamente por las reglas de transformación especificadas. Esto conducirá a una modificación de las reglas de validación implementadas en el proceso ETL.
Normalmente los data warehouse son alimentados de manera asíncrona desde distintas fuentes, que sirven a propósitos muy diferentes. El proceso ETL es clave para lograr que los datos extraídos asíncronamente de orígenes heterogéneos se integren finalmente en un entorno homogéneo.
La escalabilidad de un sistema de ETL durante su vida útil tiene que ser establecida durante el análisis. Esto incluye la comprensión de los volúmenes de datos que tendrán que ser procesados según los acuerdos de nivel de servicio (SLA: Service level agreement). El tiempo disponible para realizar la extracción de los sistemas de origen podría cambiar, lo que implicaría que la misma cantidad de datos tendría que ser procesada en menos tiempo. Algunos sistemas ETL son escalados para procesar varios terabytes de datos para actualizar un data warehouse que puede contener decenas de terabytes de datos. El aumento de los volúmenes de datos que pueden requerir estos sistemas pueden hacer que los lotes que se procesaban a diario pasen a procesarse en micro-lotes (varios al día) o incluso a la integración con colas de mensajes o a la captura de datos modificados (CDC: change data capture) en tiempo real para una transformación y actualización continua.
Algunas Herramientas ETL
- Ab Initio
- Benetl
- BITool – ETL Software
- CloverETL
- Cognos Decisionstream (IBM)
- Data Integrator (herramienta de Sap Business Objects)
- ETI*Extract (ahora llamada Eti Solution)
- IBM Websphere DataStage (antes Ascential DataStage)
- Microsoft Integration Services
- Oracle Warehouse Builder
- WebFocus-iWay DataMigrator Server
- Pervasive
- Informática PowerCenter
- Oxio Data Intelligence ETL full web
- SmartDB Workbench
- Sunopsis (Oracle)
- SAS Dataflux
- Sybase
- Syncsort: DMExpress.
- Opentext (antes Genio, Hummingbird).
Libros
- Kettle (ahora llamado Pentaho Data Integration).
- Scriptella Open Source ETL Tool.
- Talend Open Studio.
Las herramientas ETL no tienen porqué utilizarse sólo en entornos de Data Warehousing o construcción de un DW, sino que pueden ser útiles para multitud de propósitos, como por ejemplo:
- Tareas de Bases de datos: También se utilizan para consolidar, migrar y sincronizar bases de datos operativas.
- Migración de datos entre diferentes aplicaciones por cambios de versión o cambio de aplicativos.
- Sincronización entre diferentes sistemas operacionales (por ejemplo, nuestro entorno ERP y la Web de ventas).
- Consolidación de datos: sistemas con grandes volumenes de datos que son consolidades en sistemas paralelos para mantener historicos o para procesos de borrado en los sistemas originales.
- Interfases de datos con sistemas externos: envio de información a clientes, proveedores. Recepción, proceso e integración de la información recibida.
- Interfases con sistemas Frontoffice: interfases de subida/bajada con sistemas de venta.
- Otros cometidos: Actualización de usuarios a sistemas paralelos, preparación de procesos masivos (mailings, newsletter), etc.
Para que nos hagamos una idea de las herramientas ETL mas importantes, podemos leer el informe Gartner, que es una comparativa de las productos mas importantes del mercado, posicionandolos en el según diferentes criterios, y hablando de las ventajas y puntos de riesgo de cada fabricante.

Fuente: Gartner
Las características mas importantes que ha de incluir un software ETL según Gartner son las siguientes:
- Conectividad / capacidades de Adaptación (con soporte a origenes y destinos de datos): habilidad para conectar con un amplio rango de tipos de estructura de datos, que incluyen bases de datos relacionales y no relacionales, variados formatos de ficheros, XML, aplicaciones ERP, CRM o SCM, formatos de mensajes estandar (EDI, SWIFT o HL7), colas de mensajes, emails, websites, repositorios de contenido o herramientas de ofimatica.
- Capacidades de entrega de datos: habilidad para proporcionar datos a otras aplicaciones, procesos o bases de datos en varias formas, con capacidades para programación de procesos batch, en tiempo real o mediante lanzamiento de eventos.
- Capacidades de transformación de datos: habilidad para la transformación de los datos, desde transformaciones básicas (conversión de tipos, manipulación de cadenas o calculos simples), transformaciones intermedias (agregaciones, sumarizaciones, lookups) hasta transformaciones complejas como analisis de texto en formato libre o texto enriquecido.
- Capacidades de Metadatos y Modelado de Datos: recuperación de los modelos de datos desde los origenes de datos o aplicaciones, creación y mantenimiento de modelos de datos, mapeo de modelo fisico a lógico, repositorio de metados abierto (con posiblidad de interactuar con otras herramientas), sincronización de los cambios en los metadatos en los distintos componentes de la herramienta, documentación, etc.
- Capacidades de diseño y entorno de desarrollo: representación grafica de los objetos del repositorio, modelos de datos y flujos de datos, soporte para test y debugging, capacidades para trabajo en equipo, gestion de workflows de los procesos de desarrollo, etc.
- Capacidades de gestión de datos (calidad de datos, perfiles y minería).
- Adaptación a las diferentes plataformas hardware y sistemas operativos existentes: Mainframes (IBM Z/OS), AS/400, HP Tandem, Unix, Wintel, Linux, Servidores Virtualizados, etc.
- Las operaciones y capacidades de administración: habilidades para gestion, monitorización y control de los procesos de integración de datos, como gestión de errores, recolección de estadisticias de ejecución, controles de seguridad, etc.
- La arquitectura y la integración: grado de compactación, consistencia e interoperabilidad de los diferentes componentes que forman la herramienta de integración de datos (con un deseable minimo número de productos, un unico repositorio, un entorno de desarrollo común, interoperabilidad con otras herramientas o via API), etc.
- Capacidades SOA.
Observamos que en el informe del año 2009, se incluye por primera vez un software ETL Open Source, que es Talend. Tambien se habla de Pentaho, cuya herramienta Kettle, tambien es Open Source. Ambas herramientas serán las que utilizemos en nuestro proyecto para la construcción de los procesos ETL.

Interfaz Grafico de la herramienta ETL Talend
A continuación indicamos algunos links interesantes sobre herramientas ETL:
- Comparando soluciones ETL Open Source y comerciales. (beyenetwork.es).
- Herramientas ETL (o mundo ETL). (mundobi.wordpress.com).
- Herramientas ETL en Dataprix
Podeis echar un vistazo al directorio EOS de productos OpenSource para ver otros productos de Software ETL Open Source, así como valoraciones de estos y casos reales de uso.
La elección de un software de ETL puede ser una tarea compleja que va a tener mucha repercusión en el desarrollo posterior de un proyecto. Podeis ver la comparativa de ETL´s OpenSource vs ETL´s Propietarias a continuación (gracias a https://www.jonathanlevin.co.uk/). Aqui se habla de que las herramientas ETL Open Source ya estan empezando a ser una alternativa real a los productos existentes y se estan desarrollando con rapidez.
Informatica Pentaho Etl Tools Comparison from Roberto Espinosa
Hola a todos, la verdad es
- Log in to post comments
Estoy recopilando mas
Estoy recopilando mas material de estudio de BigData, para dedicarme como trabajo sobre todo en aplicacion de organizaciones comerciales. Saludos
- Log in to post comments
Hola Graciela Para
Hola Graciela
Para introducirte y aprender sobre el mundo Big Data, y conocer las diferentes opciones Open source para trabajar con BigData, te recomiendo este completo documento que ha preparado Stratebi, y que puedes descargar libremente (y sin registro):
Saludos!
- Log in to post comments
hola a todos, pregúntale
hola a todos,
pregúntale alguien a podio instalar y manejar una herramienta ETL
- Log in to post comments
un saludo a todo el equipo y
un saludo a todo el equipo y un abrazo cordial 2015 son mis mayores deseos
y gracias por este apoyo
- Log in to post comments
Excelente articulo, muy
Excelente articulo, muy completo abarca todas las arista, me sirvió mucho, gracias = )
- Log in to post comments
Buen aporte justo tenia unas
Buen aporte justo tenia unas dudas sobre etl y si existian en open source
gracias
- Log in to post comments
Hola, he estado intentando
Hola, he estado intentando configurar Pentaho Community con sql server express 2012, lo cual ha sido inutil cada intento, pues, los drivers que trae esta version de Pentaho para conexion son los mysql, y los que encuentro de mssql server ninguno pega. Alguien que halla tenido alguna experiencia o idea de lograr hacerlo? Y realmente si, excelente post!
- Log in to post comments
Prueba consultando cómo
Prueba consultando cómo hacerlo en este otro tema:
http://www.dataprix.com/foro/software-it/software-open-source/pentaho-b…
Creo que te servirá
- Log in to post comments
Pésimo articulo y mediocre
Pésimo articulo y mediocre explicación, no explicas el detalle solo simples subtítulos y muy breve detalle, puntuación 2 de 10.
- Log in to post comments
Proceso ETL para la carga de la Dimensión Tiempo. Ejemplo de uso de la ETL Talend.
Proceso ETL para la carga de la Dimensión Tiempo. Ejemplo de uso de la ETL Talend. respinosamilla 25 February, 2010 - 09:50Una vez identificados los origenes de datos, podemos proceder a la construcción de las tablas físicas de nuestro modelo y al desarrollo de los procesos de llenado. Empezaremos el proceso con la Dimensión Tiempo. Como ya indicamos, esta dimensión no dependera de nuestro ERP u otros sistemas externos, sino que la construiremos a partir de los calendarios. Generaremos todos los registros necesarios para esta tabla para un periodo de 20 años, que va desde el 01 de Enero de 2000 (para los datos históricos anteriores que también cargaremos en nuestro DW) hasta el 31 de Diciembre de 2020.
La definición física de la tabla no ha variado tras el análisis de los origenes de datos, y será la siguiente:
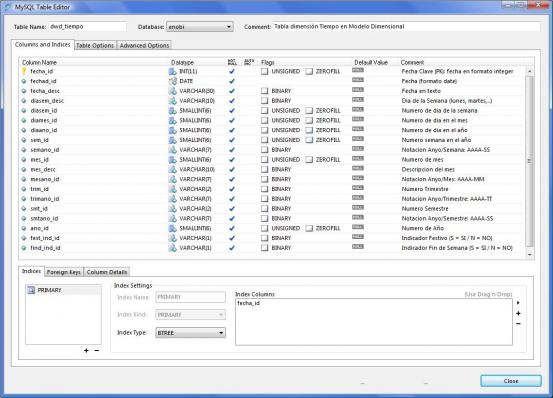
Diseño Fisico Tabla Dimensión Tiempo en MySql
Los procesos que tendremos que implementar utilizando Talend serán los siguientes (tal y como vimos en una entrada anterior del Blog):
.jpg)
Transformaciones para la creación de la Dimensión Tiempo
Vamos a utilizar Talend con la opción de generación en lenguaje Java (también podriamos utilizar el lenguaje PERL). El utilizar Java significa que todos los procesos y transformaciones que definamos se van a “traducir” a lenguaje Java a nivel interno. Aunque no es estrictamente necesario conocer el lenguaje Java para trabajar con Talend, su conocimiento nos va a facilitar mucho el trabajo con la herramienta y nos va a permitir definir nuestro propio código para la transformaciones o procesos que no se incluyen de forma estandar.
Talend esta basado en el entorno de desarrollo Eclipse. Es un entorno gráfico con amplias funcionalidades donde la definición de las transformaciones se realiza de una forma visual muy intuitiva, seleccionando y arrastrando componentes y estableciendo relaciones entre ellos. Incluye un entorno de Debug para poder analizar los procesos y sus errores, así como la posibilidad de establecer trazas para realizar un seguimiento de los procesos cuando los estamos desarrollando y validando.
En la imagen siguiente vemos un ejemplo de un job desarrollado con Talend:
Entorno gráfico de la herramienta Talend
Los componentes mas importantes dentro del entorno gráfico son los siguientes:
Repositorio de Objetos en Talend
Repositorio: incluye todos los objetos que podemos definir utilizando Talend, clasificado en un arbol de la siguiente manera:
- Business Models: Talend dispone de una herramienta gráfica sencilla donde podemos definir nuestros modelos de negocio. En esta carpeta se ubicaran los diferentes modelos de negocio que hayamos “dibujado” utilizando Talend. La herramienta contiene los elementos gráficos mas habituales.
- Job Designs: un proyecto de transformación o integración de datos se compone de multiples procesos o jobs que podemos definir y clasificar en una estructura de carpetas para organizarlos y clasificarlos. En esta sección vemos los diferentes jobs que hemos definido y la forma en la que los hemos clasificado.
- Contexts: son los contextos de ejecución de los procesos. En ellos podemos definir constantes o parametros que se nos piden al ejecutar un proceso y que podemos utilizar en los diferentes componentes de un job. Los contextos también se pueden cargar en tiempo de ejecución provenientes de ficheros.
- Rutinas: es el lugar donde podemos ver las rutinas de código desarrolladas por Talend(que luego podremos utilizar en las transformaciones) y donde nosotros podremos añadir nuestras propias rutinas para realizar operaciones, cálculos o transformaciones para las que no dispongamos de un método estandar. Las rutinas se programan en Java (o en Perl en el caso de haber seleccionado ese lenguaje).
- SQL Template: son templates de sentencias SQL predefinidas que podremos utilizar o personalizar.
- Metadata: es el lugar donde vamos a definir los metadatos del proyecto. Son definiciones de componentes que luego vamos a poder reutilizar en todos los procesos de diseño de las transformaciones. Por ejemplo, en el metadatos podremos definir conexiones a bases de datos, recuperar los esquemas de una base de datos y tenerlos documentados (con sus tablas, vistas, etc), definir sentencias Sql, definir patrones de diferentes tipos de ficheros, etc. Esto nos permite tener los elementos definidos en un único sitio y reutilizarlos a lo largo de los procesos. El Repositorio de metadatos centraliza la información de todos los proyectos y garantiza la coherencia en todos los procesos de integración. Los metadatos relacionados con los sistemas origen y destino de los procesos de integración se cargan fácilmente en el Repositorio de metadatos a través de utilidades avanzadas de analisis de las bases de datos o archivos, facilitada por diversos asistentes. Las características definidas en el Metadata son heredadas por los procesos que hacen uso de ellas.
- Documentacion: podemos cargar en el proyecto los ficheros de documentacion de nuestros análisis y desarrollos, clasificandolos por carpetas. La vinculación se puede hacer con un link o cargando directamente el fichero en el repositorio. Esta utilidad nos permite tener centralizado en un único lugar todos los elementos de un proyecto de integración de datos.
- Papelera de reciclaje: los objetos que borramos va a la papelera de reciclaje y de ahi los podremos recuperar en el caso de ser necesario.
Job Designer: es la herramienta desde la que manipulamos los diferentes componentes que conforman un job, estableciendo relaciones entre los diferentes elementos.
Job Designer
Cuando estamos trabajando con un job, en la parte inferior disponemos de un conjunto de pestañas desde donde podemos realizar varias acciones, tales como definir un contexto para el job, configurar las propiedades, ejecutar el job y establecer la forma de ejecución, modificar las propiedades de los componentes de los jobs, programar los jobs, establecer jerarquias en los jobs, etc.
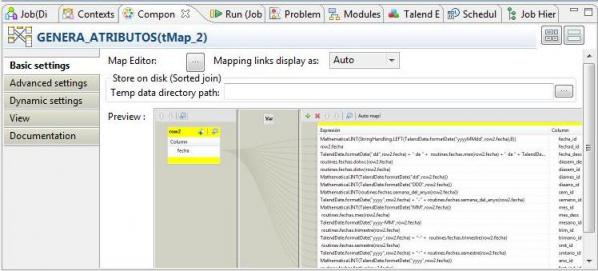
Finalmente, en la parte derecha de la aplicación tenemos la Paleta de Componentes, que son los diferentes controles que nos proporciona Talend para utilizar en nuestros jobs. Se encuentran clasificados según su función.
Paleta de Componentes
Algunos de los componentes disponibles en Talend son los siguientes:
- Business Intelligence: grupo de conectores que cubre las necesidades de lectura o escritua en bases de datos multidimensionales u olap, salidas hacia reports Jasper, gestión de cambios en la base de datos para las dimensiones lentamente cambiantes, etc (todos ellos relacionados con Business Intelligence).
- Business: conectores para leer y escribir de sistemas tipo CRM (Centric, Microsoft CRM, Salesforce, Sugar, Vtiger) o para leer y escribir desde sistemas Sap. También permiten trabajar con el gestor documental Alfresco.
- Custom Code: componentes para definir nuestro propio código personalizado y poder utilizarlo integrado con el resto de componentes Talend. Podemos escribir componentes en Java y Perl, así como cargar librerias o personalizar comandos Groovy.
- Data Quality: componentes para la gestión de calidad de datos, como filtrados, calculos CRC, busquedas por lógica difusa, reemplazo de valores, validación de esquemas contra el metadata, limpieza de duplicados, etc.
- Databases: conectores de conexión, entrada o salida de las bases de datos mas populares ( AS400, Access, DB2, Firebird, Greenplum, HSQLdb, Informix, Ingres, Interbase, JavaDB, LDAP, MSSQL Server, MaxDB, MySql, Netezza, Oracle, Paraccel, PostreSQL, SQLite, Sas, Sybase, Teradaba, Vertica).
- ELT: componentes para trabajar con las bases de datos en modo ELT (con las tipicas transformaciones y procesos de este tipo de sistemas).
- Fichero: controles para la gestión de ficheros (verificacion existencia, copia, borrado, lista, propiedades), para lectura de ficheros de diferentes formatos (texto, excel, delimitados, XML, mail, etc) y para escritura en ellos.
- Internet: componentes para acceder a contenidos almacenados en internet, como servicios Web, flujos RSS, SCP, Mom, Email, servidores FTP y similares.
- Logs & Errors: controles para la gestión de errores y logs en la definición de procesos.
- Miscelanea: componentes varios, como ventanas de mensajes, verificación de funcionamiento de servidores, generador de registros, gestión de contextos de variables, etc.
- Orchestration: componentes para generar las secuencias y la tareas de orquestación y procesamiento de los jobs y subjobs definidos en nuestras transformaciones (generación loops, ejecución de jobs previos o posteriores, procesos de espera para ficheros o datos, etc).
- Processing: componentes para procesamiento de los flujos de datos, como agregación, mapeos, transformaciones, filtrados, desnormalización, etc.
- System: componentes para interaccion con el sistema operativo (ejecución de comandos, variables de entorno, etc).
- XML: componentes para trabajo con estructuras de datos XML, con operaciones de parsing, validación o creación de estructuras.
Para haceros una idea de la forma de trabajar con Talend, es interesante ver una demo de 5 minutos en la Web de Talend (acceder desde este link). También podeis ver el siguiente video de demostración de como generar datos de test en una tabla Mysql.
Igualmente, podeís descargaros para profundizar más el Manual de Usuario de la herramienta y la Guia de Referencia de Componentes (ambos en inglés) en este link.
Job en Talend para el llenado de la Dimensión Tiempo
Ahora que ya conocemos un poco en que consiste Talend, vamos a profundizar viendo un ejemplo práctico. Necesitamos generar un flujo de fechas que comenzando en 01.01.2000, llegue hasta el dia 31.12.2020 (con eso cargamos las fechas de 20 años en la dimensión).
Para hacer el proceso vamos a definir los siguientes pasos:
1) Loop que se ejecuta 10.000 veces, con un contador que vas desde 0 a 9999 (utilizando el componente tLoop del grupo Orchestration).
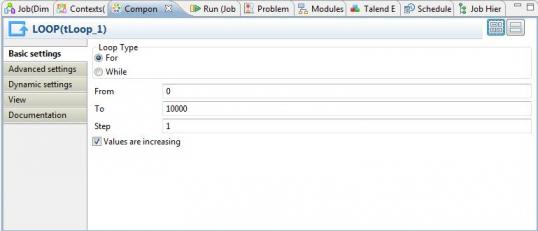
2) El loop llama al control Generador de Registros, que genera un registro con la fecha 01.01.2000 (utilizando el componente tRowGenerator del grupo Miscelaneous).
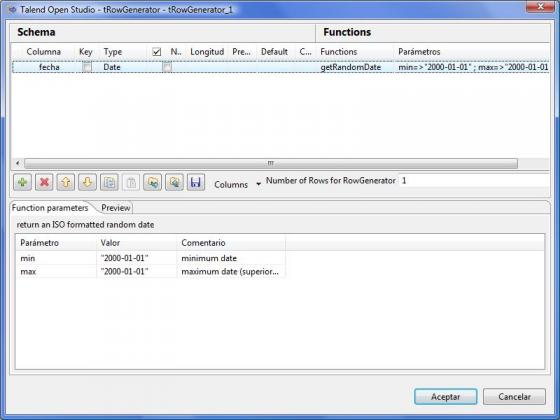
3) el RowGenerator pasa la fecha a un transformación (MAP), que le suma a la fecha el contador del paso 1 (con eso vamos incrementando la fecha de partida dia a dia y generando todas las fechas necesarias). Utilizamos el componente tMap del grupo Processing.
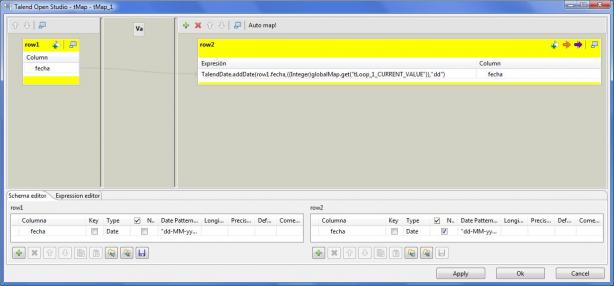
4) las fechas generadas las pasamos a otra transformación (MAP), donde para cada fecha, generamos todos los atributos de la dimensión tiempo según la tabla de transformación que hemos indicado anteriormente (mes, año, dia, dia de la semana, trimestre, semestre, etc). Utilizamos el componente tMap del grupo Processing.
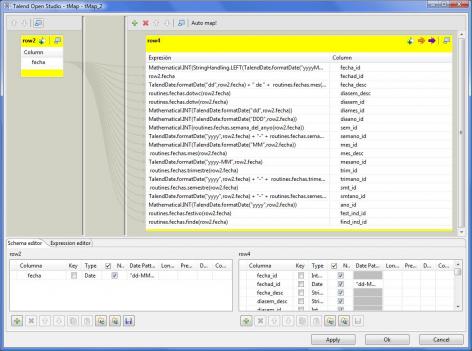
Hemos tenido que definir unas rutinas en java para la generación correcta del número de semana en el año de cada fecha, así como para la generación de los datos de trimestres, semestres, dia festivo y fin de semana. Por ejemplo, para la generación de las semanas hemos escrito el siguiente código en Java:
// template routine Java
package routines;
import java.util.Calendar;
import java.util.Date;
public class fechas {
public static String semana_del_anyo(Date date1) {Calendar c1 = Calendar.getInstance();
c1.set(Calendar.DAY_OF_WEEK,Calendar.MONDAY);
c1.setMinimalDaysInFirstWeek(1);
c1.setTime(date1);
int semana = c1.get(Calendar.WEEK_OF_YEAR);
if (semana < 10) {return ( 0 + Integer.toString(semana));
} else {return (Integer.toString(semana));
}}
5) Filtramos los registros para desechar los que son mayores de 31.12.2020, pues esos nos los queremos cargar en la base de datos. Utilizamos el componente tFilterRow del grupo Processing.
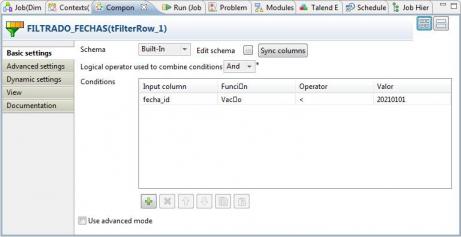
6) Insertamos los registros en la base de datos Enobi, en la tabla DWD_TIEMPO, utilizando el componente tMySqlOutput, del grupo Databases, MySql. Si los registros ya existen en la base de datos, se actualizan.
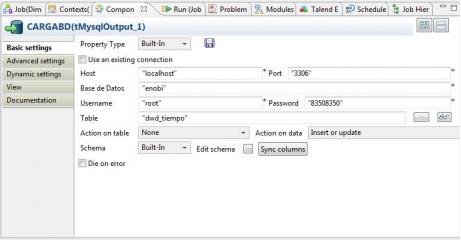
El esquema completo del Job sería el siguiente:
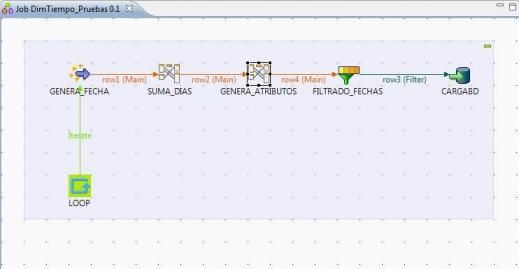
Job llenado Dimensión Tiempo
Esta ha sido nuestro primera toma de contacto con una herramienta ETL. Sin programar (o casi, pues hemos tenido que preparar una rutina en java para el tratamiento de las semanas y otros atributos de las fechas), hemos llenado con datos reales la primera tabla/dimensión de nuestro modelo.
Bases de Datos OpenSource. ¿Porque elegimos Mysql para nuestro proyecto?.
Bases de Datos OpenSource. ¿Porque elegimos Mysql para nuestro proyecto?. respinosamilla 25 February, 2010 - 09:50Antes de continuar con la construccion de los procesos ETL para el resto de las dimensiones del proyecto, vamos a hacer una pausa para explicar el motivo de elegir MySql como gestor de base de datos para el proyecto ENOBI.
En primer lugar, el económico. Estamos realizando un proyecto utilizando productos OpenSource o productos licenciados libremente por los fabricantes (como Microstrategy Reporting Suite). Seguramente si estuviesemos en un gran proyecto, elegiriamos una opción de base de datos propietaria, como Oracle ( que es para muchos la mejor opción por estudios, prácticas o consenso). Podeis ver el estudio comparativo de bases de datos realizado por Forrester ( gracias a todobi.com ).
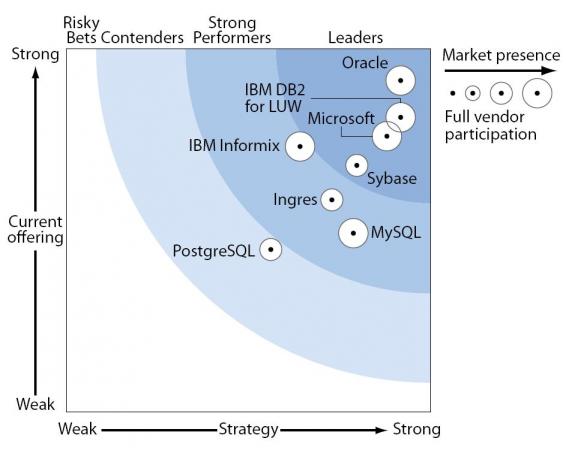
Estudio Forrester 2009 sobre Gestores de Base de Datos
En segundo lugar, estamos buscando productos con reconocido prestigio, fiabilidad, velocidad, rendimiento, facilidad de administración y conexión con otros productos, bien documentados, con una buena evolución y soporte. Productos de los que sea fácil obtener información, con buenas herramientas, y para los que incluso podamos recibir cursos de formación si fuese necesario. Productos que esten siendo utilizados en muchos entornos productivos y que nos den la suficiente confianza.
Ademas, los gestores de bases de datos OpenSource hace tiempo que dejaron de ser un experimiento y ya son una alternativa real para las empresas (incluso aparecen en los cuadrantes Gartner). Son productos cada vez mas evolucionados, con mas funcionalidades y las empresas que los desarrollan tienen también cada vez más volumen de negocio (cuestión importante para continuar la evolución de los productos).
Los productos OpenSource mas conocidos son:
MySQL, PostgreSQL, MaxDB, Firebird, Ingres , MonetDB, LuciDb.
Podeis echar un vistazo al directorio EOS de productos OpenSource para ver otras bases de datos Open, así como valoraciones de estas y casos reales de uso.
Existen multitud de comparativas sobre las bases de datos OpenSource, incluso estudios comparándolas con productos propietarios (ver comparativa Oracle/Mysql). La elección de una u otra dependerá del tipo de proyecto, el uso que vayamos a dar a la base de datos (Servidor Web, desarrollo aplicaciones, Dw), posibilidades de integración con otros productos, plataformas hardware o sistema operativo a utilizar, etc.
En nuestro caso, hemos decidido trabajar con MySql o PostgreSql, y vamos a centrarnos en analizar cual de los dos productos nos quedamos.
Existen multitud de comparativas, aunque algunas de las mas interesantes son:
Comparativa MySql vs PostGreSql.
Comparativa MySql vs PostGreSql: ¿cuando emplear cada una de ellas?
PostgreSQL Vs MySQL: Comparative Review: es una comparativa mas reciente donde se tiene en cuenta la evolución de los dos productos en los ultimos años.
Si analizamos las bases de datos centrandonos en el ámbito de los Datawarehouse, también existen estudios que analizan las diferentes opciones existentes ( otra vez gracias a todobi.com ). El estudio original, realizado por Jos van Dongen, lo tenemos aquí.
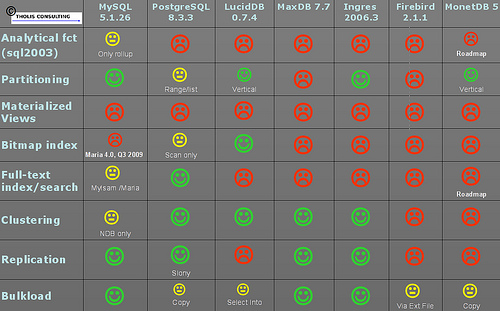
Comparativa BD-DW (estudio Jos van Dongen)
Incluso, tenemos en la Wikipedia un estudio comparativo de las bases de datos relacionales mas importantes, al que podemos acceder desde aquí.
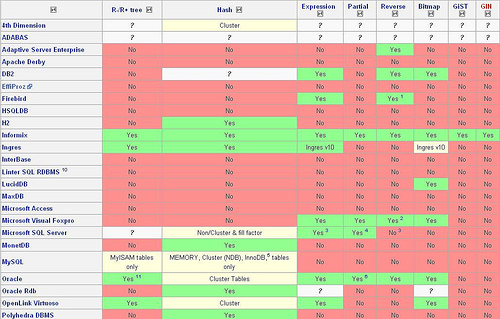
Comparativa BD Wikipedia
Tenemos mucha información, pero es el momento de las conclusiones y de elegir el producto que utilizaremos en nuestro proyecto, teniendo en cuenta las siguientes consideraciones:
1) Vamos a construir un DataWarehouse, por lo que tendrá prioridad para nosotros la velocidad de acceso a los datos (habrá cargas de datos regulares cuando estemos alimentando el DW a partir de los sistemas operacionales, y la mayoria de accesos serán para consultar dichos datos).
2) Para mejorar el rendimiento de la base de datos, en la tabla de hechos (que recordemos es la que tendra millones de registros, pues en ella se guardan todas las transacciones de ventas), realizaremos particionado. Eso significa que para la misma tabla lógica, habrá diferentes tablas físicas y toda la gestión de dicho particionado recaera sobre el motor de base de datos, siendo el proceso totalmente transparente para el usuario (también habría cabido la opción de gestionarlo nosotros en los procesos de carga ETL separando los datos en tablas distintas según un criterio determinado (por ejemplo, el año), teniendo en cuenta que esto es soportado, por ejemplo, por las herramientas de Microstrategy, que son capaces de generar las sentencias SQL apropiadas para leer información de las diferentes tablas donde la información está repartida).
3) Es la primera vez que trabajamos con ambas bases de datos, y en ambos casos buscaremos la facilidad de trabajo, la existencia de herramientas gráficas y de administración, la documentación, etc.
Teniendo en cuenta estas consideraciones y los estudios y comparativas que hemos descrito anteriormente, decidimos trabajar con MySql por los siguiente motivos:
1)Velocidad: aunque en algunos estudios PostgreSql es mejor para entornos donde la integridad de datos es fundamental (como en el desarrollo de aplicaciones), a nivel de rendimiento MySql es mejor. En concreto, cuando utilizamos el tipo de motor MyIsam, el rendimiento de MySql es mucho mejor. Este será el tipo de Engine con el que definiremos todas nuestras tablas en el DW. El motor InnoDb es mas lento y esta orientado a aplicaciones donde la actualización e integridad es mas importante.
2)Particionado: aunque ambas plataformas permiten particionado, la gestión utilizando Mysql es mas sencilla.
3)Herramientas gráficas, documentación, plataformas: Mysql proporciona una amplia documentación (muy completa) y multitud de herramientas gráficas de gestión y de conectividad. PostgreSql también cumpliría los requisitos en el tema de documentación y plataformas soportadas. También es importante para nosotros poder disponer en Mysql de una herramienta de Diseño de Bases de datos, como es MySql Workbench, que nos permite definir nuestros modelos relacionales, generar las sentencias SQL y construir la base de datos, así como realizar ingenieria inversa (construir el módelo de datos a partir de una base de datos existente) o comparar el modelo definido en la herramienta con el existente en la base de datos.
Algunos de los usuarios mas destacados de Mysql son los siguientes:
- Amazon.com
- Cox Communications – La cuarta televisión por cable más importante de EEUU, tienen más de 3.600 tablas y aproximadamente dos millones de inserciones cada hora.
- Craigslist
- CNET Networks
- Digg – Sitio de noticias.
- flickr, usa MySQL para gestionar millones de fotos y usuarios.
- Google – Para el motor de búsqueda de la aplicación AdWords.
- Joomla!, con millones de usuarios.
- phpBB, Uno de los más famosos sitios de foros, con miles de instalaciones y con millones de usuarios.
- LiveJournal – Cerca de 300 millones de páginas servidas cada día.[2]
- NASA
- NetQOS, usa MySQL para la gestión de algunas de las redes más grandes del mundo como las de Chevron, American Express y Boeing.
- Nokia, usa un cluster MySQL para mantener información en tiempo real sobre usuarios de redes de móviles.
- Omniture
- Sabre, y su sistema de reserva de viajes Travelocity
- Slashdot – con cerca de 50 millones de páginas servidas cada día.
- Wikipedia, sirve más de 200 millones de consultas y 1,2 millones de actualizaciones cada día, con picos de 11.000 consultas por segundo.
- WordPress, con cientos de blogs alojados en él.
- Yahoo! – para muchas aplicaciones críticas.
Si quereis ampliar la información sobre MySql, la entrada en la wikipedia es bastante completa.
Resto de procesos ETL para la carga del DW
Resto de procesos ETL para la carga del DW respinosamilla 25 February, 2010 - 09:50Mas ejemplos de Talend. Ejecución de sentencias SQL construidas en tiempo ejecución.
Mas ejemplos de Talend. Ejecución de sentencias SQL construidas en tiempo ejecución. respinosamilla 25 February, 2010 - 09:50Después de llenar la dimensión Tiempo con los procesos ETL utilizando Talend, al revisar los registros de la tabla DWD_TIEMPO, comprobamos que para algunos años, la ultima semana del año se ha llenado con el valor 1. La explicación es que Java utiliza la normalización ISO para el número de semana, y esta nunca puede ser superior a 52. Por tanto, para algunos años, la ultima semana del año ha quedado registrada con el valor 1.
Este problema nos sirve de base para desarrollar nuestro seguiente proceso ETL, que ira encandenado a la generación de los registros de la dimensión tiempo, y que tendrá el objetivo de arreglar los registros que han quedado erróneos en la base de datos.
El proceso tendría los siguientes pasos:
1) Recuperación para cada año, del mayor número de semana registrado en la tabla: para ello, ejecutamos una sentencia SQL , utilizando el componente TMySqlInput del grupo Databases, Mysql).
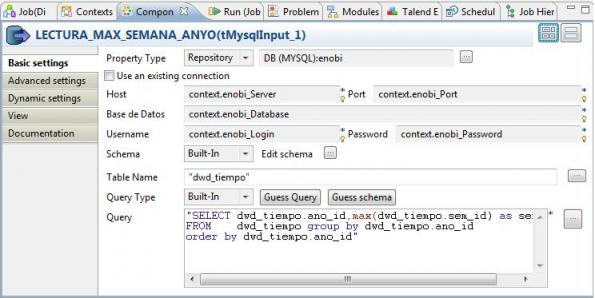
La sentencia ejecutada es la siguiente:
"SELECT dwd_tiempo.ano_id,max(dwd_tiempo.sem_id) as semana FROM dwd_tiempo group by dwd_tiempo.ano_id order by dwd_tiempo.ano_id"
Este control nos genera un flujo con todos los registros devueltos por la sentencia SQL y para cada registro realizaremos las acciones siguientes:
2) Para cada año, ejecutamos una sentencia SQL construida en tiempo de ejecución con los datos pasados por el control anterior,para arreglar el número de semana erronea (utilizando el mayor número de semana + 1). Para ello, utilizamos el control tMySqlRow. Este control nos permite ejecutar una sentencia SQL para cada registro del flujo y transmitir dicho flujo al paso siguiente del job.
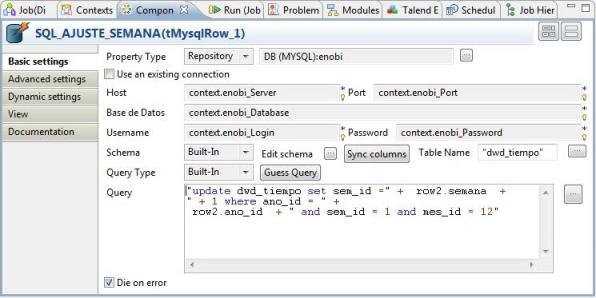
La sentencia ejecutada es la siguiente (observad como vamos construyendo la sentencia SQL concatenando trozos de texto fijo con los valores de la variable row, que seran pasados por el componente anterior de la secuencia):
"update dwd_tiempo set sem_id =" + row2.semana + " + 1 where ano_id = " + row2.ano_id + " and sem_id = 1 and mes_id = 12"
3) Terminamos el proceso de arreglo corrigiendo el campo compuesto semano_id, que también quedo erróneo y que corresponde a la Semana del año en la notacion AAAA-SS, donde AAAA es el año y SS es la semana. Para ello, utilizamos también el control tMySqlRow.
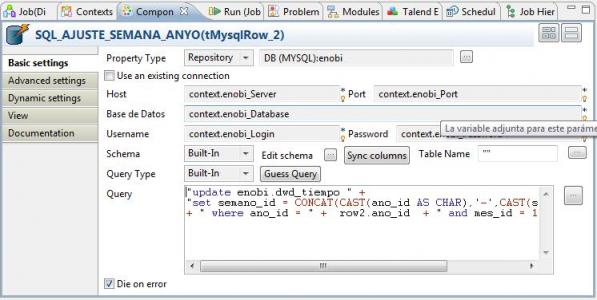
La sentencia ejecutada es la siguiente (construida igualmente concatenando trozos de texto fijo con los valores de la variable row, que seran pasados por el componente anterior de la secuencia). En este caso, también estamos utilizando funciones de Mysql (CONCAT y CAST), para hacernos una idea de la potencia del lenguaje SQL en combinación con la utilización de variables de Talend:
"update enobi.dwd_tiempo " + "set semano_id = CONCAT(CAST(ano_id AS CHAR),'-',CAST(sem_id AS CHAR))" + " where ano_id = " + row2.ano_id + " and mes_id = 12"
Los pasos 2 y 3 los podríamos haber realizado en una única sentencia SQL, pero los hemos separado para mayor claridad.
El proceso completo sería el siguiente:
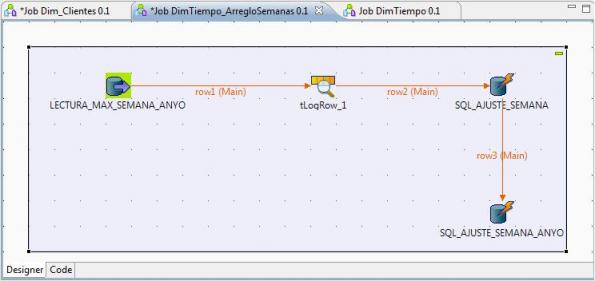
Esquema Completo del Job en Talend para el arreglo de las semanas
Seguimos avanzando en nuestro proyecto y una de las cosas que va quedando clara es que los conocimientos del consultor de BI han de cubrir muchas areas: bases de datos, sql, algo de lenguajes de programación (Java en el caso de Talend), herramientas de modelado, herramientas ETL, teoria de modelado de datos multidimensional con sus variantes, algo de estadística para el datamining, nociones de erp´s,crm´s, etc. Eso sin contar los conocimientos de las empresas, indicadores de negocio y la visión diferente que habrá que aportar a la empresa donde se realize el proyecto. Volvemos a acordarnos de lo que decía Jorge Fernández en su blog ( “El consultor de BI, ese bicho raro“).
A continuación, vamos a realizar el proceso ETL para la dimensión Producto.
ETL para carga Dimension Producto. Mas ejemplos de Talend. Uso de logs, metricas y estadisticas.
ETL para carga Dimension Producto. Mas ejemplos de Talend. Uso de logs, metricas y estadisticas. respinosamilla 25 February, 2010 - 09:50El siguiente proceso ETL que vamos a abordar es el de la carga de la Dimensión Producto. En esta dimensión se ubicarán, como ya vimos, los diferentes atributos relacionados con el producto que utilizaremos en nuestro sistema BI. Después de la revisión de la estructura física, teniendo en cuenta los origenes de datos, la estructura física de la tabla es la siguiente:
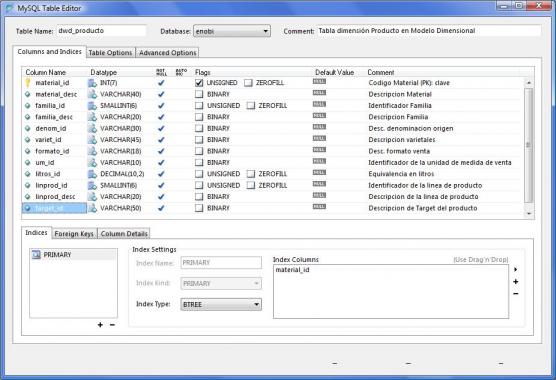
Diseño Fisico Tabla Dimensión Producto en MySql
Los procesos que tendremos que implementar utilizando Talend serán los siguientes (tal y como vimos en una entrada anterior del Blog):
.jpg)
Transformaciones para la creación de la Dimensión Producto
Para el desarrollo del proceso con Talend, vamos a ir un paso mas alla, definiendo información de logs, registro de estadísticas y métricas. Esto nos permitira conocer otra funcionalidad de Talend, y orquestar la ejecución de los jobs (para permitir, por ejemplo, la recuperación de la fecha de ultima ejecución del job para poder buscar los cambios en el maestro de materiales desde la ultima ejecución del proceso de traspaso), controlar los errores de ejecución y notificar por email en el caso de que se produzca algún problema.
El esquema completo del job con todos los pasos sería el siguiente (a continuación veremos de forma detallada cada uno de los pasos incluidos):
Proceso ETL en Talend completo para la dimensión Producto
Los pasos del proceso ETL para llenar la Dimensión Producto serán los siguientes:
1) Ejecución de un prejob que recuperará la fecha de ultima ejecución del proceso y registrara en el log el inicio de la ejecución del job. Además, se lanzará un logCatcher (para recoger las excepciones Java o errores en el proceso), que generará el envio de un email de aviso en el caso de que se produzca algún problema en cualquier paso del job.
2) A partir de la fecha de ultima ejecución, recuperamos del maestro de materiales en el ERP, todas las modificaciones o altas de productos realizadas en la tabla desde dicha fecha.
3) Realizamos una sustitución de valores erroneos o en blanco en los registros seleccionados según los criterios establecidos.
4) Completamos el mapeo de dimensión Producto, llenando el resto de campos que provienen de otras tablas en la base de datos (los campos de lookup), con sus correspondientes consultas SQL.
5) En el mapeo se podrán generar materiales erróneos que habrá que verificar y corregir en el sistema origen (por tener valores incorrectos). La lista de materiales se introduciran en un fichero excel. Igualmente, contaremos el número de registros leidos desde el sistema origen correctos para guardarlos en las tablas de metricas.
6) Verificamos que realmente haya modificaciones con los datos existentes en la base de datos del DW, y para los registros que si tienen modificaciones (o si son nuevos registros), realizamos la actualización. En principio, no vamos a realizar gestión de Dimensiones Lentamente Cambiantes, sino que siempre tendremos la foto de los datos tal y como están los ficheros maestros en el momento actual (mas adelante si gestionaremos una dimensión con esta casuistica para conocer los componentes de los que dispone Talend para este cometido).
7) Concluimos el proceso guardandonos en el log el correspondiente mensaje de finalización correcta del proceso.
Antes de profundizar y ver en detalle cada unos de los pasos, vamos a ver la forma de activar en Talend la gestión de logs, estadisticas y metricas. El significado de cada uno de estos elementos es el siguiente:
- Logs: sería el registro de los mensajes de error generados por los procesos, las excepciones Java al ejecutar o los mensajes generados por nosotros utilizando los componentes tDie o tWarn (para generar diferentes tipos de mensajes).
- Stats (estadísticas): es el registro de la información estadística de los diferentes pasos y componentes que forman un job. Para cada paso, se puede activar el registro de estadísticas seleccionando la opción tStatCatcher Statistics. Se guarda información de cada paso, cuando empieza, cuando termina, su status de ejecución, duración, etc.
- Meter, volumetrics (métricas): es el registro de metricas (numero de registros de un flujo) que podemos intercalar en los procesos utilizando el control tFlowMeter.
Talend nos permite trabajar de dos maneras con todos estos registros (se pueden combinar): una sería gestionando nosotros mismos los logs, stats y meters que se generan (recolectandolas en tiempo de ejecución con los componentes tLogCatcher, tStatcatcher o tFlowMeterCatcher en cada job y dandoles el tratamiento oportuno) o bien activar la gestión automática a nivel de cada proyecto o job, seleccionando en que lugar queremos guardar los registros generados(con tres opciones: visualización en consola, registro en ficheros de texto planos o registro en base de datos). Con esta ultima opción, toda la información que se genere quedara registrada en tablas y será mas fácil explotarla para revisión de procesos realizados, orquestación de procesos, verificación de cuellos de botella, corrección de errores, etc.
Para activar la gestión a nivel de proyecto seleccionaremos la opción de menú Archivo –> Edit Project Properties, opción Job Settings, Stats & Logs (tal y como vemos en la imagen):
Opciones de estadísticas y logs a nivel de Proyecto
Estas propiedades quedan habilitadas para todos los jobs del proyecto, aunque luego se pueden ajustar en cada job según nos interese (puede haber jobs para los que no queremos guardar nada de información). Esto lo modificaremos en las propiedades de cada job, en la pestaña Stats & Logs. En principio, mandan las propiedades establecidas en el proyecto, pero se pueden generar excepciones (llevar los logs a un sitio diferente o no generar) para un job en concreto:
Opciones de estadísticas y logs a nivel de Job
Una vez realizada esta aclaración, veamos en detalle cada uno de los pasos del ETL:
1) Ejecución de un prejob que recuperará la fecha de ultima ejecución del proceso y registrara en el log el inicio de la ejecución del job. Además, se lanzará un logCatcher (para recoger las excepciones Java o errores en el proceso), que generará el envio de un email de aviso en el caso de que se produzca algún problema en cualquier paso del job. Los componentes utilizados en este paso inicial son los siguientes:

- Lanzador Prejob (componente tPrejob): sirve para realizar el lanzamiento de un pretrabajo, anterior al proceso principal.
- Ultima Fecha Ejecución (componente tMySqlInput): recuperamos de la tabla de registro de logs, la ultima fecha de ejecución correcta del job. Esta fecha nos servira de fecha de referencia para buscar las altas/modificaciones de productos en el ERP desde la ultima ejecución. Sino hay una ejecución anterior del job, construimos una fecha de referencia para lo que sería la carga inicial de la dimensión producto.
- Mensaje Log Inicio (componente tWarn): genera un mensaje de log indicando que se comienza la ejecución del job.
- Set Variable Fecha (componente tSetGlobalVar): la fecha de ultima ejecución recuperada en el paso anterior se registra en una variable global que se podrá utilizar posteriormente en cualquier paso del job.
- Control Errores (componente tLogCatcher): activamos el componente que “escuchara” durante toda la ejecución del job, esperando que se produzca algún tipo de error. En ese momento se activara para recuperar el error y pasarlo al componente siguiente para el envio de un email de notificación.
- tFlowtoIterate: convertimos el flujo de registros de log a una iteración para poder realizar el envio del correo electrónico.
- Envio Email Notif (componente tSendMail): generamos el envio de un email de notificación de errores, incluyendo el paso donde se paro el proceso, y el mesaje de error generado. Es una forma de avisar que ha fallado algo en el proceso.
Para ver en detalle como hemos definido cada componente, podeis pulsar en el link de cada componente o para ver la documentación HTML completa generada por Talend pulsando aquí.
2) A partir de la fecha de ultima ejecución, recuperamos del maestro de materiales en el ERP, todas las modificaciones o altas de productos realizadas en la tabla desde dicha fecha.
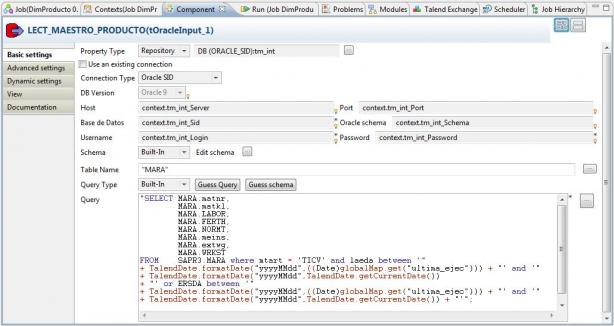
Job DimProducto - Lectura Maestro Productos Sap
Para ello, utilizamos el componente LECT_MAESTRO_PRODUC TO del tipo tOracleInput (ver detalle aqui ), que nos permite acceder a la base de datos de Sap, que en este caso es Oracle. También podiamos haber realizado la lectura de Sap utilizando los componentes tSAPConnectiony tSAPInput). Observar la sentencia SQL ejecutada en el componente, y ver como combinamos el texto escrito con el uso de una variable global y el uso de funciones de Taled (que también podrían ser Java).
3) Realizamos una sustitución de valores erroneos o en blanco en los registros seleccionados según los criterios establecidos. Utilizando el componente AJUSTE_CAMPOS, del tipo tReplace (ver detalle aqui), con el que podemos buscar valores existentes en los registros recuperados (utilizando cadena regulares) e indicar una cadena de sustitución. Puede ser util para cualquier transformación que haya que realizar para determinados valores, para normalizar, para corregir registros erróneos, etc. En nuestro caso, la vamos a utilizar para sustituir registros sin valor (se podría haber optado también por rechazar dichos registros).
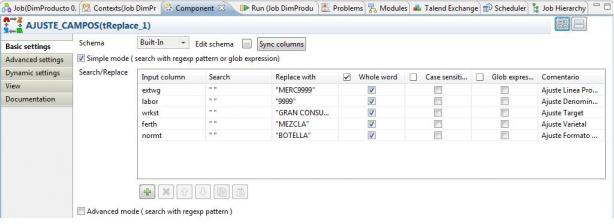
Job DimProducto - Ajuste Campos
4) Completamos el mapeo de dimensión Producto, llenando el resto de campos que provienen de otras tablas en la base de datos (los campos de lookup), con sus correspondientes consultas SQL. Para ello utilizamos el componente MAPEO_PRODUCTO del tipo tMap (ver detalle aqui ).
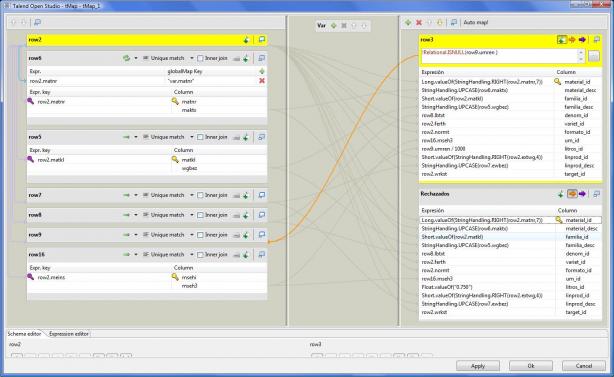
Job DimProducto - Mapeo Producto
Con este componente, juntamos en un paso los registros leidos del maestro de materiales, y los valores adicionales que estan en otras tablas del ERP que nos permiten completar cada registro (como son los valores de descripciones, unidades de medida, calculo de equivalencia de unidades de medida, etc).
En este mapeo, utilizamos una funcionalidad de Talend que no habiamos visto, que es realizar un filtrado selectivo de los registros. Esto nos permite generar en el paso dos flujos de datos, uno con los registros correctos, y otro con los registros que no cumplan unas determinadas condiciones. En nuestro caso, los registros que tengan un valor NULL en el campo umren, serán rechazados y pasados a un paso posterior donde serán grabados en un fichero excel para su revisión.
5) En el mapeo se podrán generar materiales erróneos que habrá que verificar por parte de algún usuario y corregir en el sistema origen (por tener valores incorrectos). La lista de materiales se introducira en un fichero excel a través del control REGISTROS_ERRONEOS del tipo tFileOutputExcel (ver aqui) . Igualmente, utilizando el componente CUENTA_LEIDOS_SAP del tipo tFlowMeter (ver aqui ),contaremos el número de registros correctos leidos desde el sistema origen para guardarlos en las tablas de metricas (para luego poder otener información estadística de los procesos realizados).
6) Verificamos que realmente haya modificaciones con los datos existentes en la base de datos del DW , y para los registros que si tienen modificaciones (o si son nuevos registros), realizamos la actualización. Para ello, utilizamos el componente VERIF_MODIFICACIONES del tipo tMap (ver aqui ) que recibira como flujo principal los registros que hemos leido desde Sap totalmente completados. Por otro lado, recibira como flujo de lookup (ver aqui) los registros que ya tenemos cargados en Myql en la tabla DWD_PRODUCTO (la tabla de la dimensión Producto). Con esta información, podremos realizar la comparación en el mapeo, realizarando un filtrado selectivo de los registros, pasando al siguiente componente solo aquellos que tienen modificaciones (hay alguna diferencia en alguno de los campos).
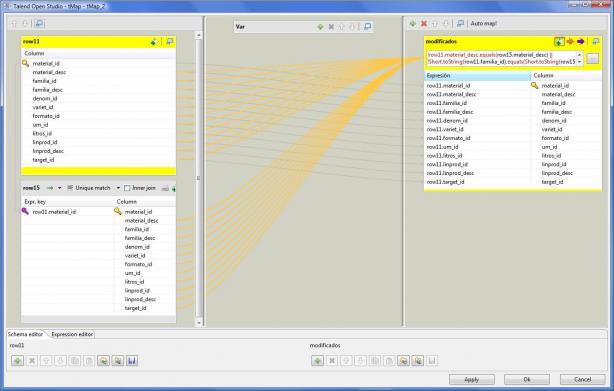
Job DimProducto - Verificacion Modificaciones
El código utilizado en el expression filter, que es la condición de filtrado, es el siguiente:
!row11.material_desc.equals(row15.material_desc) || row11.familia_id!=row15.familia_id|| !row11.familia_desc.equals(row15.familia_desc)|| !row11.denom_id.equals(row15.denom_id)|| !row11.variet_id.equals(row15.variet_id)|| !row11.formato_id.equals(row15.formato_id)|| !row11.um_id.equals(row15.um_id)|| row11.litros_id!=row15.litros_id|| row11.linprod_id!=row15.linprod_id|| !row11.linprod_desc.equals(row15.linprod_desc)|| !row11.target_id.equals(row15.target_id)
Observar como vamos realizando la comparación campo a campo de los dos flujos, para determinar si hay algún cambio entre los datos ya cargados y los provenientes del ERP.
En principio, no vamos a realizar gestión de Dimensiones Lentamente Cambiantes, sino que siempre tendremos la foto de los datos tal y como están los ficheros maestros en el momento actual (mas adelante si gestionaremos una dimensión con esta casuistica para conocer los componentes de los que dispone Talend para este cometido). Los registros que superan el mapeo, son registrados en la base de datos Mysql utilizando el control ACTUALIZA_DWD_PRODUCTO, del tipo tMySqlOutput (ver detalle aqui ), grabandose como ya hemos dicho en la tabla DWD_PRODUCTO.
Con el componente tFlowMeter, en el paso CUENTA_MODIFICADOS (ver detalle aquí ), registramos en las tablas de metricas el número de registros que van a generar actualización.
7) Concluimos el proceso guardándonos en el log el correspondiente mensaje de finalización correcta del proceso, con el componente MENSAJE_LOG_FIN del tipo tWarn (ver detalle aqui).
Para ver en detalle como hemos definido cada componente, podeís acceder a la documentación HTML completa generada por Talend aquí. Podeis descargaros el fichero zip que contiene dicha documentación aquí.
Conclusiones
Hemos realizado nuestro primer trabajo ETL complejo utilizando Talend. Ha sido un poco complicado entender como funciona la herramienta, como se vinculan y encadenan los diferentes componentes, la forma de pasar la información y los registros entre ellos, como se gestionan los errores, etc. Pero una vez comprendidos los conceptos básicos, se observa el gran potencial que tiene Talend (que ademas puede ser completado con el uso del lenguaje Java por todas partes). Os recomiendo si quereis ampliar el conocimiento de la herramienta, la lectura del Manual de Usuario de la herramienta y la Guia de Referencia de Componentes (ambos en inglés) en este link y visitar la web del proyecto Open TalendForge, donde podeis encontrar Tutoriales, Foros, gestión de bugs, etc.
También he visto lo importante que es el proceso de análisis de los origenes de información y el detallado de todas las transformaciones que hay que realizar, las excepciones, que criterio se sigue para ellas, que sustituciones realizamos, etc. Quizas deberiamos de haber realizado ese paso mas en profundidad, pues luego al realizar los procesos ETL han aparecido situaciones que no habiamos previsto. Lo tenemos en cuenta para nuestro próximo proyecto.
Igualmente hemos visto que es importante establecer un mecanismo para la gestión de todos los logs de la ejecución de procesos, estadísticas y metricas, pues luego nos serán de utilidad para montar los procesos de automatización, seguimiento y depuración de errores necesarios para la puesta en productivo del proyecto y para su mantenimiento a lo largo del tiempo.
Y como no, la documentación. El hecho de ir documentando y explicando cada componente que utilizamos en Talend (nombrado de los pasos, texto explicativo en cada componente, comentarios en los metadatos, etc), ha permitido que utilizando una funcionalidad estandar de Talend, la generación de documentación HTML, disponer de un repositorio donde poder consultar como estan construidos los procesos, de una forma muy completa y detallada, de cara a la comprensión de como están montados los procesos por parte de terceras personas, para su posterior modificación o mantenimiento en el futuro.
En la siguiente entrada del Blog, detallaremos los procesos ETL para la carga del resto de dimensiones de nuestro proyecto. Posteriormente, abordaremos el proceso ETL para la carga de la tabla de Hechos, que será la mas compleja y para la que habrá que establecer un mecanismo de orquestación para su automatización. En dicha entrada incluiremos igualmente el estudio del particionado de tablas utilizando Mysql, que veremos en profundidad.
Comparativa ETL´s OpenSource vs ETL´s Propietarias
Comparativa ETL´s OpenSource vs ETL´s Propietarias respinosamilla 25 February, 2010 - 09:50La elección de una herramienta ETL puede ser una tarea compleja que va a tener mucha repercusión en el desarrollo posterior de un proyecto. Podeis ver la comparativa de ETL´s OpenSource vs ETL´s Propietarias a continuación ( gracias a https://www.jonathanlevin.co.uk/). Aqui se habla de que las herramientas OpenSource ya estan empezando a ser una alternativa real a los productos existentes y se estan desarrollando con rapidez.
[slideshare id=1497055&doc=etl-124344719247-phpapp01]
Igualmente, os dejo el link a un documento donde se habla de todo lo que tendremos que tener en cuenta a la hora de realizar la selección de una herramienta ETL (características que habrán de tener, criterios para la evaluación, etc). Acceder al documento aquí.
Comparativa Talend / Pentaho
Si finalmente os decidis por utilizar herramientas ETL Open, la empresa francesa ATOL ha realizado una comparativa entre Pentaho y Talend con varios casos de ejemplo, comparativa de características, etc. (acceder al informe aquí , esta escrita en Frances pero es bastante completa).
Tambien os puede resultar interesante para comparar ambos productos la entrada del blog Wiki Wednesday, donde Vincent McBurney nos habla de los pros y contras de cada una de las herramientas, de una forma bastante completa (ademas hace referencia a varios sitios donde se estan analizando ambos productos).
ETL Talend Dimension Cliente.Tipos de Mapeo para lookup. Gestión de SCD (Dimensiones lentamente cambiantes).
ETL Talend Dimension Cliente.Tipos de Mapeo para lookup. Gestión de SCD (Dimensiones lentamente cambiantes). respinosamilla 25 February, 2010 - 09:50El proyecto ENOBI sigue avanzando en la parte mas compleja y que seguramente mas recursos consumira, los procesos ETL. Como ya indicamos, en algunos proyectos puede suponer hasta el 80% del tiempo de implantación. Y no solo eso, el que los procesos esten desarrollados con la suficiente consistencia, rigor, calidad, etc. va a determinar el exito posterior del proyecto y que la explotación del sistema de Business Intelligence sea una realidad. Seguramente si los procesos de extraccion, transformación y carga no esta bien desarrollados, eso pueda acabar afectando al uso correcto del sistema
Para concluir los procesos ETL de las Dimensiones del proyecto, vamos a abordar la carga de la Dimensión Cliente, que incluye todos los atributos por los que analizaremos a nuestros clientes. Vamos a obviar la publicación de los proceso de carga de la Dimensión Logistica y Promoción, pues son muy sencillos y no aportan nada nuevo.
Al detallar los procesos de la carga de la Dimension Cliente, entraremos en detalle en las diferente formas que tiene Talend de realizar los mapeos de tablas de lookup. Es decir, cuando tenemos un valor para el que tenemos que recuperar un valor adicional en otra tabla de la base de datos (por ejemplo, para un código de cliente recuperar su nombre; para la familia de producto, introducida en el maestro de materiales, recuperar de la tabla de parametrización su descripción, etc ), ver de que maneras Talend nos permite realizar dicha consulta.
Igualmente, veremos mas ejemplos de utilización de Java dentro de los componentes, y la potencia que ello nos proporciona (aunque nos obliga a tener conocimientos amplios de este lenguaje).
Para completar el ejemplo, aunque en realidad en nuestra dimensión no vamos a gestionar las dimensiones lentamente cambiantes (SCD Slowly Change Dimension), vamos a incluir un ejemplo de tratamiento de este tipo de dimensiones, utilizando el componente que tiene Talend para ese cometido, que implementa el algoritmo correspondiente para su procesamiento (elemento tMySQLSCD).
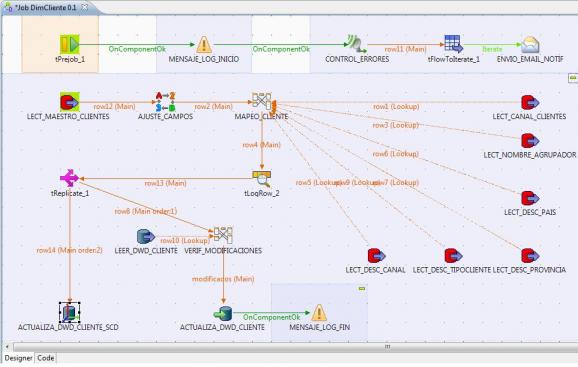
Proceso ETL en Talend completo para la dimensión Cliente
Tal y como vemos en la imagen anterior, los pasos del proceso ETL para llenar la Dimensión Cliente serán los siguientes:
1) Ejecución de un prejob que lanzará un generara en el log un mensaje de inicio del proceso y un logCatcher (para recoger las excepciones Java o errores en el proceso). Este generará el envio de un email de aviso en el caso de que se produzca algún problema en cualquier paso del job.
- Lanzador Prejob (componente tPrejob): sirve para realizar el lanzamiento de un pretrabajo, anterior al proceso principal.
- Mensaje Log Inicio (componente tWarn): genera un mensaje de log indicando que se comienza la ejecución del job.
- Control Errores (componente tLogCatcher): activamos el componente que “escuchara” durante toda la ejecución del job, esperando que se produzca algún tipo de error. En ese momento se activara para recuperar el error y pasarlo al componente siguiente para el envio de un email de notificación.
- tFlowtoIterate: convertimos el flujo de registros de log a una iteración para poder realizar el envio del correo electrónico.
- Envio Email Notif (componente tSendMail): generamos el envio de un email de notificación de errores, incluyendo el paso donde se paro el proceso, y el mesaje de error generado. Es una forma de avisar que ha fallado algo en el proceso. En la siguiente imagen tenéis un ejemplo de un email de notificación de error enviado a una cuenta de gmail.
Ejemplo envio Email de notificacion de error
2) Recuperamos del maestro de cliente en el ERP, todos los clientes existentes en el fichero maestro (con el componente tOracleInput).
Job DimCliente - Lectura Maestro Clientes Sap
3) Realizamos una sustitución de valores erroneos o en blanco en los registros seleccionados según los criterios establecidos (con el componente tReplace), como ya vimos en los procesos ETL de la Dimensión Producto.
4) Completamos el mapeo de dimensión Cliente, llenando el resto de campos que provienen de otras tablas en la base de datos (los campos de lookup), con sus correspondientes consultas SQL (utilizando el componente tMap).
Job DimCliente - Mapeo Cliente
Podeis observar como al realizar el mapeo del maestro de clientes con las correspondientes tablas de lookup (donde estan el resto de campos y descripciones), hemos estado utilizado sintaxis del lenguaje Java. Esto nos da mayor potencia a las transformaciones y nos permitirán hacer casi de todo, aunque tendremos que conocer bien Java, sus tipos de datos, la forma de convertirlos. Algunos ejemplos son:
- Relational.ISNULL(row2.psofg)?”SIN ASIGNAR”:row2.psofg : el operador Java que nos permite asignar un valor u otro a un resultado segun si se cumple una condición o no. En este caso, si row2.psofg es nulo, al resultado se le dara el valor “SIN ASIGNAR”. En caso contrario, se le dara el valor del campo row.psofg.
- StringHandling.UPCASE(row2.ort01 ) : es un metodo de la clase StringHandling, que nos permite pasar una cadena a mayúsculas.
- Long.valueOf(StringHandling.RIGHT(row2.konzs,10)) : utilizamos el metodo RIGHT de la clase StringHandling para obtener una subcadena, y el resultado lo convertimos al tipo de datos numérico Long con el metodo de este valueOf.
Tipos de Mapeo en el componente tMap
Cuando utilizamos el componente tMap para completar los datos de nuestro flujo con valores proveniente de otras tablas (u otros ficheros u origenes de datos), vemos que siempre tenemos un flujo Main (en nuestro caso con los datos que llegan del fichero maestro de Sap) y uno o varios flujos lookup (lo podeis observar en la imagen anterior). Estos flujos de lookup nos permiten “rellenar” valores que residen en otro lugar, buscandolos por una clave determinada. La clave puede venir del propio flujo Main o de otros flujos de lookup (de forma anidada). Pensar por elemplo el caso de recuperar, a partir del código de cliente, un dato asociado (como el comercial asignado). Posteriormente, para el código de comercial, busco en otro lookup, utilizando ese código, el nombre de dicho comercial.
Los flujos de lookup pueden ser de tres tipos, como vemos en la imagen. Veamos en que consiste cada uno de ellos:
- Load Once: la rama de lookup del componente tMap se ejecuta una unica vez y siempre antes de la ejecución del componente tMap. En este caso, la ejecución unica de la rama de lookup ha de generar todos los registros para poder buscar valores en ellos (será una carga de todo un fichero maestro, por ejemplo). Si los datos para el lookup tuvieran muchos registros, podría ser un cuello de botella para el proceso, e igual convendría utilizar el tipo Reload at each row.
- Reload at each row: la rama del lookup se ejecuta para cada registro que llegan del flujo Main. Este tipo de mapeo nos permite ejecutar la consulta de lookup para un valor concreto (podremos pasar un valor unico que sera el que realmente busquemos. Ver ejemplo posterior de este tipo de lookup). Puede tener sentido utilizarlo con tablas de lookup muy grandes que no tiene sentido gestionar en una consulta de atributos (pensar en una tabla maestro de clientes de millones de registros).
- Reload at each row (cache): idem al anterior, pero los registros que se van recuperando se guardan en la cache. En las siguientes consultas, se mira primero en la cache, y si ya existe, no se lanza el proceso. En el caso de que no exista, entonces si se relanza la ejecución para buscar los valores que faltan.
En este caso, en todos los flujos de lookup hemos utilizado el tipo Load Once (mas adelante veremos un ejemplo de uso Reload at each row).
5) Verificamos que realmente haya modificaciones con los datos existentes en la base de datos del DW (también con el componente tMap), y para los registros que si tienen modificaciones (o son nuevos registros), realizamos la actualización. En principio, no vamos a realizar gestión de Dimensiones Lentamente Cambiantes, sino que siempre tendremos la foto de los datos tal y como están los ficheros maestros en el momento actual.
Job DimCliente - Verificacion Modificaciones
Para discriminar el paso de registros al paso siguiente de actualización en la base de datos del DW, se ejecuta la siguiente expresión condicional (vemos que es 100% lenguaje Java). La expresión va comparando campo por campo entre los valores recuperados de nuestro ERP y los existentes en la tabla de la dimensión cliente DWD_CLIENTE.
!row8.cliente_desc.equals(row10.cliente_desc) || row8.agrupador_id!=row10.agrupador_id|| !row8.agrupador_desc.equals(row10.agrupador_desc)|| !row8.comercial_id.equals(row10.comercial_id)|| row8.canal_id!=row10.canal_id|| !row8.canal_desc.equals(row10.canal_desc)|| row8.tipocl_id!=row10.tipocl_id|| !row8.tipocl_desc.equals(row10.tipocl_desc)|| !row8.pais_id.equals(row10.pais_id)|| !row8.region_id.equals(row10.region_id)|| !row8.provincia_id.equals(row10.provincia_id)|| !row8.cpostal_id.equals(row10.cpostal_id)|| !row8.poblacion_id.equals(row10.poblacion_id)|| !row8.nielsen_id.equals(row10.nielsen_id)|| row8.clubvinos_id!=row10.clubvinos_id
Cuando el lookup lo ejecutamos para cada registro que llega al control tMap (en este caso utilizamos el tipo Reload at each row), la sentencia SQL que se ejecuta en el flujo de lookup es la siguiente (observa que en la condición del where utilizamos una variable que hemos generado en el control tMap, y será la que contiene el código de cada cliente que queremos verificar). En este caso, el paso asociado al flujo lookup se ejecuta una vez para cada registro que llegue al componente tMap y siempre posteriormente:
"SELECT dwd_cliente.cliente_id,
dwd_cliente.cliente_desc,
dwd_cliente.agrupador_id,
dwd_cliente.agrupador_desc,
dwd_cliente.comercial_id,
dwd_cliente.canal_id,
dwd_cliente.canal_desc,
dwd_cliente.tipocl_id,
dwd_cliente.tipocl_desc,
dwd_cliente.pais_id,
dwd_cliente.region_id,
dwd_cliente.provincia_id,
dwd_cliente.cpostal_id,
dwd_cliente.poblacion_id,
dwd_cliente.nielsen_id,
dwd_cliente.clubvinos_id
FROM dwd_cliente
WHERE cliente_id = " + (globalMap.get("var.cliente_id"))
En este caso, la sentecia SQL (y el correspondiente componente que la contiene), se ejecutara una vez por cada registro que llega por el flujo Main al componente tMap. Y la sentencia SQL solo recuperara un registro de la base de datos, aunque se estará ejecutando continuamente (le hemos pasado con la variable var.cliente_id el valor a buscar).
6) Concluimos el proceso guardándonos en el log el correspondiente mensaje de finalización correcta del proceso, con el componente MENSAJE_LOG_FIN del tipo tWarn.
TRATAMIENTO DE LAS DIMENSIONES LENTAMENTE CAMBIANTES
Como ejemplo y para estudiar su funcionamiento, incluimos un paso para la gestión de las dimensiones lentamente cambiantes (que se grabaran en una tabla paralela a la de la dimensión cliente). El tipo de componente en Talend para realizar esto será el tMySqlSCD.
Para entender que son exactamente las dimensiones lentamente cambiantes, os recomiendo un poco de literatura. En el blog Business Intelligence Facil, se explican de una forma muy clara que son y como gestionarlas ( ver aquí ), así como de las claves subrogadas. Tambien Jopep Curto nos da muy buenas definiciones en su blog.
Una vez tengamos clara la teoria, vamos a ver como aplicarlo a la practica utilizando los componentes de Talend.
Componente para gestion dimensión lentamente cambiante
El algoritmo de la dimensión SCD se gestiona con el correspondiente editor, tal y como vemos en la imagen siguiente:
Editor Componente SCD
Para utilizar el editor, se indica un nombre de tabla existente en la base de datos, que sera la tabla para la cual vamos a gestionar la SCD (ha de incluir los campos necesarios para la gestión de versiones según lo indicado en el editor SCD). El control recibirá un flujo con los registros a procesar contra la tabla indicada. En el editor SCD indicamos como se va a comportar la actualización contra la tabla según los diferentes tipos de atributos.
Los controles que forman el editor de dimensiones SCD son los siguientes:
- Unused: aquí apareceran todos los campos disponibles para utilizar en el editor SCD. Desde este sitio iremos arastrando los campos al resto de sitios.
- Source keys: son las claves principales de los datos (la clave en el sistema original). Para un maestro de clientes, aquí indicaremos la clave que identifica a este en el sistema origen.
- Surrogate keys: es el nombre que le damos a la clave subrogada. Es decir, aquella clave inventada que nos va a permitir gestionar versiones de nuestros datos en el DW.
- Type 0 fields: aqui indicaremos los campos que son irrelevantes para los cambios. Si aqui metemos, por ejemplo, el campo nombre, cualquier cambio en el sistema origen con respecto a los datos existentes en el DW no se va a tener en cuenta (se ignorará).
- Type 1 fields: aquí indicaremos los campos para los que, cuando haya un cambio, se machacará el valor existente con el valor recibido, pero sin gestionar versionado.
- Type 2 fields: aquí indicaremos los campos para los que queremos que, cuando haya un cambio, se produzca un nuevo registro en la tabla (con una nueva subrogated key). Es decir, aquí pondremos los campos que son dimensiones lentamente cambiantes y para los que queremos gestionar un versionado completo.
- Versioning: aqui indicamos los valores para el versionado (fecha de inicio y fecha de fin), y si queremos llevar un control de numero de versión o flags de registro activo (requeriran campos adicionales en la tabla para este cometido).
- Type 3 fields: aquí indicaremos los campos para los que queremos guardarnos una versión anterior del valor (es decir, cuando haya un cambio, siempre tendremos dos versiones, la ultima y la anterior).
Para concluir la explicación de las dimensiones SCD, observar las diferencias de catalogo entre el flujo de entrada y el flujo de salida (en el de salida se han incluido atributos propios para la gestión de la dimension lentamente cambiante, gestión de versiones, fechas de validez, etc):
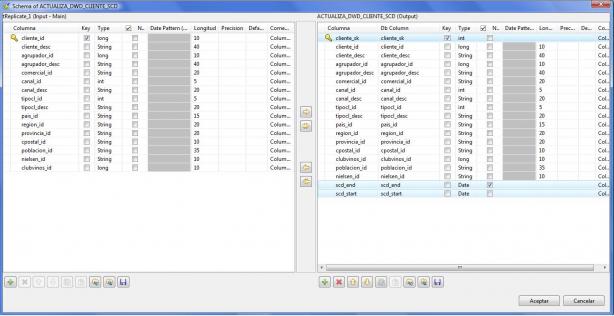
Esquema de traspaso de Datos en Dimensiones SCD
Para entender mejor el ejemplo, observar las entradas en MySql de la tabla DWD_CLIENTE_SCD. Observar como el cliente tuvo un cambio en su nombre y se generó un nuevo registro en la tabla con una nueva clave subrogada. Todo se ha realizado de una forma automatica por el componente de Talend, sin tener que gestionar nosotros nada.
Registros para el mismo cliente en MySql con Subrogated key
Finalmente, observar que hemos utilizado un componente nuevo para duplicar un flujo de datos (el componente tReplicate). Este componente nos permite a partir de un unico flujo, generar tantos flujos como sea necesarios (todos serán iguales y procesarán los mismos registros).
Duplicacion de flujos de datos con el componente tReplicate
Para ver en detalle como hemos definido cada componente del Job, podeís acceder a la documentación HTML completa generada por Talend. Podeis descargaros el fichero zip que contiene dicha documentación aquí.
Ejemplo Talend para conectarnos a Sap
Ejemplo Talend para conectarnos a Sap respinosamilla 25 February, 2010 - 09:50Antes de continuar con el proceso ETL para la carga de la tabla de Hechos de ventas, vamos a hacer una pausa para ver como utilizar Talend para conectarnos a Sap utilizando los componentes tSapConnection, tSapInput y tSapOutput. En nuestro proyecto, podriamos haber utilizado estos componentes para hacer la lectura de datos desde el ERP (pero hemos utilizado el componente tOracleInput para leer directamente de la base de datos).
Aunque el componente Sap de Talend es libre, para poder utilizarlo hace falta una librería Java proporcionada por Sap (sapjco.jar), que tendremos que tener instalada en nuestro sistema. Esta libreria solo se puede descargar de Sap si somos usuarios registrados (https://service.sap.com/connectors). La versión del sapjco que hemos instalado es la 2.1.8 (hay una posterior, la 3.0.4, pero con esa no funciona Talend).
La forma de instalar la libreria sapjco.jar es la siguiente:
- Una vez descargado el correspondiente fichero (según la versión de sistema operativo que estemos utilizando), lo descomprimimos en un directorio de nuestra elección. La prueba, en nuestro caso, la hemos realizado utilizando Windows Vista.
- Si tenemos una versión mas antigua de la dll librfc32.dll en el directorio de windows system32, la sustituimos con la que viene de Sap.
- Incluimos el directorio de instalación en la variable de entorno PATH (en nuestro caso c:\sapjco ).
- Finalmente, añadimos a la variable de entorno CLASSPATH el fichero sapjco.jar con su ruta completa (por ejemplo, CLASSPATH=c:\sapjco\sapjco.jar ).
A continuación, instalamos la libreria en el directorio de clases de Talend y comprobamos que este correctamente instalada. Para ello, dejamos caer el fichero sapjco.jar en el directorio <directorio_instalacion_talend>\lib\java. A continuación abrimos Talend, y en la pestaña Modules, comprobamos que aparezca el modulo sapjco.jar correctamente instalado (tal y como vemos en la imagen).
Finalmente, vamos a ver un ejemplos práctico de conexión a Sap para recuperar información, utilizando modulos de función (RFC) implementados en Sap y a las que podremos acceder desde Talend (esto es realmente lo que nos permite hacer el componente, acceder a Sap a traves de sus RFC´s y BAPIS).
Las RFC´s (Remote Function Call) son la base para la comunicación entre Sap y cualquier sistema externo. Son componentes de programación (un programa Abap, por ejemplo), encapsulado en una función, con su correspondiente interfaz de entrada y salida de datos, que ademas puede ser llamado desde dentro del propio Sap, o de forma remota si esta habilitada la opción “Modulo Acceso Remoto” (tal y como vemos en la imagen inferior). En este caso, es cuando podremos llamarlas, por ejemplo, desde Talend.
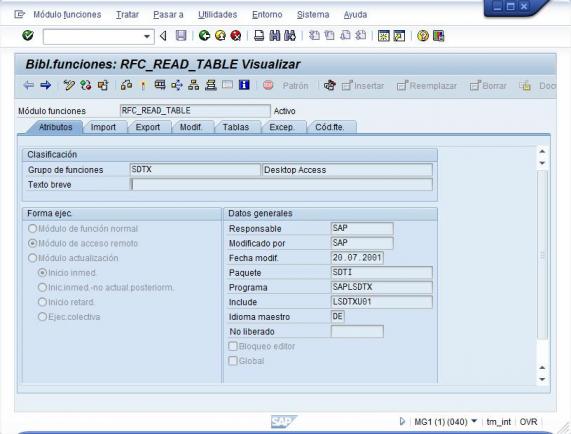
Definicion de la RFC "RFC_READ_TABLE" en Sap
Sap tiene programadas multitud de RFC´s de forma estandar, y ademas nosotros podremos construir las nuestras con codigo que realize las tareas que deseemos. Ademas, existe otro tipo de RFC´s dentro de sap, las llamadas BAPIS, que incluyen reglas adicionales integradas con el funcionamiento de la aplicación Sap (por ejemplo, la BAPI BAPI_SALESORDER_CREATEFROMDAT2 nos permite la creación de un pedido de ventas a partir de los datos que pasamos a la función en la interfaz).
Ejemplo: Lectura del contenido de una tabla utilizando la RFC “RFC_READ_TABLE”.
Vamos a realizar un Job en Talend para leer el contenido de una tabla de Sap, en concreto, vamos a recuperar todos los materiales que son de un determinado tipo. El Job completo tendrá la siguiente estructura:
En Talend utilizaremos el componente tSapInput para hacer la llamada a la RFC de Sap. Para poder hacer esto, tendremos que conocer cual es la interfaz que tiene definida esta en Sap para saber que parametros le podemos pasar y que resultados y en que tipos de estructuras de datos podemos recibir. En la transacción SE37 de Sap podemos ver como estan definidos los modulos de función, y ver como se va a realizar la comunicación con dicho componente.
Por ejemplo, en modulo de función RFC_READ_TABLE (como vemos en la imagen inferior), tiene 5 parametros de entrada, definidos en la pestaña IMPORT. Los que vamos a utilizar en nuestro ejemplo serán: QUERY_TABLE (la tabla de la que queremos obtener información), DELIMITER (delimitador para los datos obtenidos).
Definicion RFC en Sap - Import (parametros Entrada)
Existe tambien la pestaña EXPORT, en la que podriamos ver que parametros de salida tenemos (para el caso de variables o estructuras simples). En el caso de trabajar con tablas, estas aparecerán en la pestaña TABLAS. Las tablas son estructuras complejas de Sap (como una matriz de datos). Las tablas se pueden utilizar tanto para recibir datos de la RFC como para pasarselos. En nuestro ejemplo, utilizaremos la tabla DATA para recibir los registros recuperados de la base de datos.
Definicion RFC en Sap - Tables (parametros Entrada/Salida)
A continuación, volveremos a Talend y completaremos los diferentes campos del componente:
- Cliente: mandante de Sap del cual recuperaremos los datos.
- Userid: usuario para la conexión. Habrá de tener permisos para ejecutar la RFC y para acceder a los datos deseados.
- Password: contraseña.
- Language: lenguaje de conexión.
- Host Name: Host donde esta ubicado el servidor Sap.
- System Number: numero de instancia Sap del servidor (normalmente la 00 donde solo hay un servidor).
- Function name: Nombre de la RFC a la cual vamos a invocar.
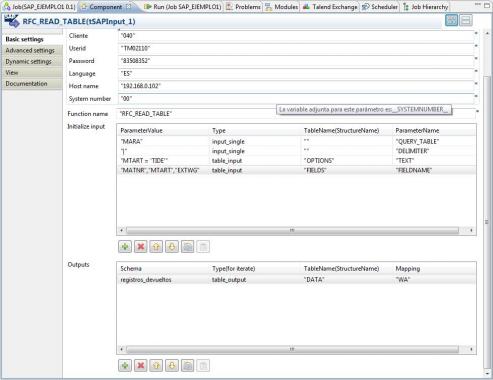
Ejemplo de Uso de componente tSapInput
- Initialize input: inicializacion de los parametros de entrada. Son los valores que vamos a pasar al módulo de función. En nuestro caso, observar que hemos pasado valores simples (variables) y también hemos pasado valores a algunas de las tablas.
- Input single: los parametros “QUERY_TABLE” y “DELIMITER” son del tipo input_single (entrada sencilla) y los inicializamos pasandoles un valor, en concreto el nombre de la tabla que queremos leer y el delimitador a utilizar.
- Table input: introducimos valores en dos tablas. En la tabla OPTIONS, en el campo TEXT, indicamos una condición para restringir la lectura de datos (como si fuera una condición del where). En la tabla FIELDS, en el campo FIELDNAME, le indicamos a Sap que campos de la tabla son los que queremos recuperar (en este caso el código del material, su tipo y su linea de producto). De esta forma, limitamos tanto el número de registros devueltos, como los campos obtenidos (no queremos ver todos los campos de cada registro de esta tabla). Observar como para indicar varios valores para el campo FIELDNAME de la tabla FIELDS, hemos puesto varias entradas separadas por coma.
- Outputs: definición de las estructuras donde vamos a gestionar los datos devueltos por Sap. Aquí indicaremos el tipo de valor recuperado (table_output para cuando el resultado sea una tabla), el nombre de la tabla en Sap (en el campo TableName (Structure Name) y el nombre del Schema (será un nombre para el flujo de datos, podemos ponerle cualquiera). En nuestro ejemplo, estamos leyendo de la tabla de Sap DATA, que es una tabla de registros, y cada registro tiene un unico campo que se llama WA. Los pasos a seguir en esta sección para una correcta definición de intercambio de datos son los siguientes:
- Creamos en primer lugar el flujo de salida pulsado el boton del signo “+”. Pulsado en Schema le daremos un nombre a este flujo (registros_devueltos en nuestro ejemplo) e indicaremos los campos que componen la estructura de salida del componente tSapInput. En este caso, solo tendremos un campo, llamado WA (tal y como vemos en la imagen), que corresponde con el campo de la tabla DATA de Sap.
Definicion de la estructura de salida "registros_devueltos"
- A continuación, habrá que asociar esta columna a la componente de Sap donde se recuperan los datos. Para ello pulsaremos en el campo Mapping,y se nos abrira una nueva ventana. Aquí nos aparecera el flujo de datos definido en el paso anterior mas el campo Schema XPatchQuerys, que es el que nos permite Mapear el campo de Talend con el campo del diccionario de datos de Sap, y así poder recibir los datos de Sap correctamente (los valores introducidos en XPatchQuerys deberán ir entre comillas dobles, utilizando el simbolo “).
- Mapeo entre la estructura de salida en Talend y la de Sap
Con este ejemplo, hemos podido de una forma relativamente sencilla recuperar datos de Sap en un único control. Conociendo los diferentes RFC´s existentes en Sap y las Bapis, seguramente podremos realizar tareas mucho mas complejas y aprovechar funcionalidades que ya estan definidas en Sap. Incluso puede ser una forma de realizar interfases con Sap utilizando estos componentes ya definidos y paquetizados.
Tabla Hechos Venta. Particionado en MySql.
Tabla Hechos Venta. Particionado en MySql. respinosamilla 25 February, 2010 - 09:50Antes de comenzar la implementación del proceso ETL para la carga de la tabla de Hechos de Ventas, vamos a realizar alguna consideración sobre el particionado de tablas.
Cuando estamos costruyendo un sistema de business intelligence con su correspondiente datawarehouse, uno de los objetivos (aparte de todas las ventajas de sistemas de este tipo: información homogenea, elaborada pensando en el analisis, dimensional, centralizada, estatica, historica, etc., etc.) es la velocidad a la hora de obtener información. Es decir, que las consultas se realicen con la suficiente rapidez y no tengamos los mismos problemas de rendimiento que suelen producirse en los sistemas operacionales (los informes incluso pueden tardar horas en elaborarse).
Para evitar este problema, hay diferentes técnicas que podemos aplicar a la hora de realizar el diseño fisico del DW. Una de las técnicas es el particionado.Pensar que estamos en un dw con millones de registros en una unica tabla y el gestor de la base de datos ha de mover toda la tabla. Ademas, seguramente habrá datos antiguos a los que ya no accederemos casi nunca (datos de varios años atras). Si somos capaces de tener la tabla “troceada” en segmentos mas pequeños seguramente aumentaremos el rendimiento y la velocidad del sistema.
El particionado nos permite distribuir porciones de una tabla individual en diferentes segmentos conforme a unas reglas establecidas por el usuario. Según quien realize la gestión del particionado, podemos distinguir dos tipos de particionado:
Manual: El particionado lo podriamos realizar nosotros en nuestra lógica de procesos de carga ETL (creando tablas para separar los datos, por ejemplo, tabla de ventas por año o por mes/año). Luego nuestro sistema de Business Intelligence tendrá que ser capaz de gestionar este particionado para saber de que tabla tiene que leer según los datos que le estemos pidiendo (tendra que tener un motor de generación de querys que sea capaz de construir las sentencias para leer de las diferentes tablas que incluyen los datos). Puede resultar complejo gestionar esto.
Automatico: Las diferentes porciones de la tabla podrán ser almacenadas en diferentes ubicaciones del sistema de forma automatica según nos permita el SGBDR que estemos utilizando.La gestión del particionado es automática y totalmente transparente para el usuario, que solo ve una tabla entera (la tabla “lógica” que estaria realmente partida en varias tablas “fisicas”). La gestión la realiza de forma automática el motor de base de datos tanto a la hora de insertar registros como a la hora de leerlos.
La partición de tablas se hace normalmente por razones de mantenimiento, rendimiento o gestión.
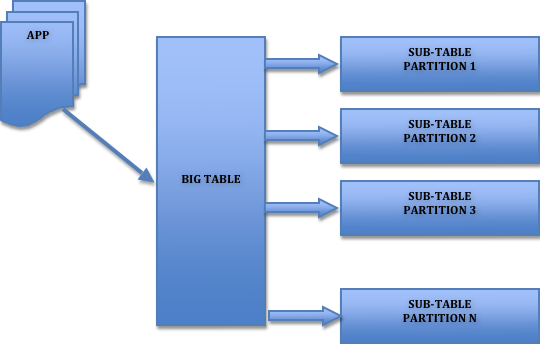
Lógica Particionado de tablas
Según la forma de realizar el particionado, podriamos distinguir:
Partición horizontal (por fila): consiste en repartir las filas de una tabla en diferentes particiones. Por ejemplo, los clientes de un pais estan incluidos en una determinada partición y el resto de clientes en otra. En cada partición se incluyen los registros completos de cada cliente.
Partición vertical( por columna): consiste en repartir determinadas columnas de un registro en una partición y otras columnas en otra (partimos la tabla verticalmente,). Por ejemplo, en una partición tenemos las columnas de datos de direcciones de los clientes, y en otra partición las columnas de datos bancarios.
Cada motor de base de datos implementa el particionado de forma diferente. Nosotros nos vamos a centrar en la forma de implementarlo utilizando Mysql, que es la base de datos que estamos utilizando para nuestro proyecto.
Particionado de tablas en MySql
MySql implementa el particionado horizontal. Basicamente, se pueden realizar cuatro tipos de particionado, que son:
- RANGE: la asignación de los registros de la tabla a las diferentes particiones se realiza según un rango de valores definido sobre una determinada columna de la tabla o expresión. Es decir, nosotros indicaremos el numero de particiones a crear, y para cada partición, el rango de valores que seran la condicion para insertar en ella, de forma que cuando un registro que se va a introducir en la base de datos tenga un valor del rango en la columna/expresion indicada, el registro se insertara en dicha partición.
- LIST: la asignación de los registros de la tabla a las diferentes particiones se realiza según una lista de valores definida sobre una determinada columna de la tabla o expresión. Es decir, nosotros indicaremos el numero de particiones a crear, y para cada partición, la lista de valores que seran la condicion para insertar en ella, de forma que cuando un registro que se va a introducir en la base de datos tenga un valor incluido en la lista de valores, el registro se insertara en dicha partición.
- HASH: este tipo de partición esta pensado para repartir de forma equitativa los registros de la tabla entre las diferentes particiones. Mientras en los dos particionados anteriores eramos nosotros los que teniamos que decidir, según los valores indicados, a que partición llevamos los registros, en la partición HASH es MySql quien hace ese trabajo. Para definir este tipo de particionado, deberemos de indicarle una columna del tipo integer o una función de usuario que devuelva un integer. En este caso, aplicamos una función sobre un determinado campo que devolvera un valor entero. Según el valor, MySql insertará el registro en una partición distinta.
- KEY: similar al HASH, pero la función para el particionado la proporciona MySql automáticamente (con la función MD5). Se pueden indicar los campos para el particionado, pero siempre han de ser de la clave primaria de la tabla o de un indice único.
- SUBPARTITIONS: Mysql permite ademas realizar subparticionado. Permite la división de cada partición en multiples subparticiones.
Ademas, hemos de tener en cuenta que la definición de particiones no es estática. Es decir, MySql tiene herramientas para poder cambiar la configuración del particionado a posteriori, para añadir o suprimir particiones existentes, fusionar particiones en otras, dividir una particion en varias, etc. (ver aquí ).
El particionado tiene sus limitaciones y sus restricciones, pues no se puede realizar sobre cualquier tipo de columna o expresión (ver restricciones al particionado aquí), tenemos un limite de particiones a definir y habrá que tener en cuenta algunas cosas para mejorar el rendimiento de las consultas y evitar que estas se recorran todas las particiones de una tabla ( el artículo MySql Partitions in Practice, se nos explica con un ejemplo trabajando sobre una base de datos muy grande, como realizar particionado y que cosas tener en cuenta para optimizar los accesos a las consultas). Para entender como funciona el particionado, hemos replicado los ejemplos definidos en este articulo con una tabla de pruebas de 1 millón de registros (llenada, por cierto,con datos de prueba generados con Talend y el componente tRowGenerator).
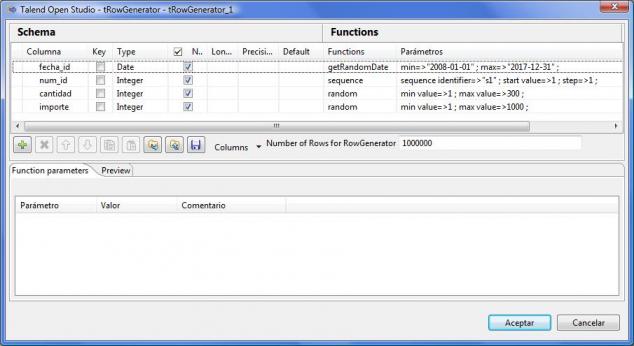
Ejemplo componente tRowGenerator para producir datos de test
En concreto, hemos creado dos tablas iguales (con la misma estructura). Una con particionado por año en un campo de la clave del tipo fecha, y la segunda con la misma estructura sin particionado. En ambas tablas tenemos un millon de registros repartidos entre los años 2008 y 2017. Una vez creadas las tablas, utilizamos la sentencia de MySql explain y explain partitions para analizar como se ejecutaran las sentencias sql (analisis de indices). Ademas, comprobamos tiempos de ejecución con diferentes tipos de sentencia SQL. Los resultados son mas que obvios:

Analisis tiempos ejecucion
En las mayoria de los casos se obtiene un mejor tiempo de respuesta de la tabla particionada, y en los casos en los que no, el tiempo de ejecución es practicamente igual al de la tabla no particionada (diferencias de milesimas de segundo). Observar cuando indicamos condiciones fuera del indice (ultima sentencia SQL), como los tiempos de respuesta son aun mas relevantes. Y siempre conforme vamos leyendo de mas particiones (por incluir mas años en la condición), el tiempo de respuesta de la consulta entre una y otra tabla se va acercando.
Particionado de la tabla de hechos de Ventas en nuestro DW
Para nuestro DW, hemos decidir implementar un particionado del tipo LIST. Como os habreis podido dar cuenta, seguramente los particionados por RANGE o por LIST son los mas adecuados para un sistema de Business Intelligence pues nos van a permitir de una forma facil reducir el tamaño de las casi siempre monstruosas tablas de hechos, de una forma fácil y automática.
Vamos a crear 10 particiones y repartiremos los diferentes años en cada una de las particiones, empezando por 2005 –> Particion 1, 2006 –> Particion 2, 2007 –> Particion 3, …, 2013 –> Particion 9, 2014 –> Partición 10. A partir de 2015, volvemos a asignar cada año a las particiones y así hasta el año 2024 (tiempo de sobra para lo que seguramente será la vida de nuestro DW).
Como el campo año no lo tenemos en el diseño físico de la tabla de hechos, aplicaremos sobre la columna fecha la funcion YEAR para realizar el particionado. La sentencia para la creación de la tabla de hechos quedaría algo parecido a esto:
CREATE TABLE IF NOT EXISTS `enobi`.`dwh_ventas` ( `fecha_id` DATE NOT NULL , `material_id` INT(11) NOT NULL , `cliente_id` INT(11) NOT NULL , `centro_id` INT(11) NOT NULL , `promocion_id` INT(11) NOT NULL , `pedido_id` INT(11) NOT NULL , `unidades` FLOAT NULL DEFAULT NULL COMMENT 'Unidades Vendidas' , `litros` FLOAT NULL DEFAULT NULL COMMENT 'Equivalencia en litros de las unidades vendidas' , `precio` FLOAT NULL DEFAULT NULL COMMENT 'Precio Unitario' , `coste_unit` FLOAT NULL DEFAULT NULL COMMENT 'Coste Unitario del Producto')
PARTITION BY LIST(YEAR(fecha_id)) (
PARTITION p1 VALUES IN (2005,2015),
PARTITION p2 VALUES IN (2006,2016),
..................................
PARTITION p9 VALUES IN (2013,2023),
PARTITION p10 VALUES IN (2014,2024)
);Con este forma de definir el particionado estamos sacando ademas partido de la optimización de lo que en MySql llaman “Partitioning Pruning”. El concepto es relativamente simple y puede describirse como “No recorras las particiones donde no puede haber valores que coincidan con lo que estamos buscando”. De esta forma, los procesos de lectura serán mucho mas rápidos.
A continuación, veremos en la siguiente entrada del Blog los ajustes de diseño de nuestro modelo físico en la tabla de hechos (teniendo en cuenta todo lo visto referente al particionado) y los procesos utilizando la ETL Talend para su llenado.
Tabla Hechos Venta. Ajuste diseño fisico y procesos carga ETL. Contextos en Talend.
Tabla Hechos Venta. Ajuste diseño fisico y procesos carga ETL. Contextos en Talend. respinosamilla 25 February, 2010 - 09:50Vamos a desarrollar los procesos de carga de la tabla de hechos de ventas de nuestro proyecto utilizando Talend. Antes de esto, vamos a hacer algunas consideraciones sobre la frecuencia de los procesos de carga que nos van a permitir introducir el uso de un nuevo elemento de Talend, los contextos.
En principio, vamos a tener varios tipos de carga de datos:
- Carga inicial: será la primera que se realice para la puesta en marcha del proyecto, e incluira el volcado de los datos de venta desde una fecha inicial (a seleccionar en el proceso) hasta una fecha final.
- Cargas semanales: es el tipo de carga mas inmediato. Se realiza para cada semana pasada (por ejemplo, el martes de cada semana se realiza la carga de la semana anterior), para tener un primer avance de información de la semana anterior (que posteriormente se refrescara para consolidar los datos finales de ese periodo). La carga de una semana en concreto también se podrá realizar a petición (fuera de los procesos batch automáticos).
- Recargas mensuales: una vez se cierra un periodo mensual (lo que implica que ya no puede haber modificaciones sobre ese periodo), se refresca por completo el mes en el DW para consolidar la información y darle el status de definitiva para ese periodo. La ejecución es a petición y se indicara el periodo de tiempo que se quiere procesar.
Teniendo en cuenta esto, definiremos un unico proceso de traspaso al cual se pasaran los parametros que indicaran el tipo de carga a realizar. Para ello utilizaremos los contextos de Talend. Cada tipo de carga tendra un contexto personalizado que definira como se va a comportar el proceso.
Contextos en Talend
Los contextos de Talend son grupos de variables contextuales que luego podemos reutilizar en los diferentes jobs de nuestras transformaciones. Nos pueden ser utiles para muchas cosas, como para tener definidas variables con los valores de paths de ficheros, valores para conexión a bases de datos (servidor, usuario, contraseña, puerto, base de datos por defecto, etc), valores a pasar a los procesos (constantes o definidos por el usuario en tiempo de ejecución). Los valores de los contextos se inicializan con un valor que puede ser cambiado por el usuario mediante un prompt (petición de valor). Un mismo contexto puede tener diferentes “grupos de valores”. Es decir, en el contexto “conexion a base de datos”, podemos tener un grupo de valores llamado “test”, que incluira los valores para conectarnos al sistema de pruebas y un grupo llamado “productivo”, que incluira los valores para la conexión a la base de datos real (tal y como vemos en el ejemplo).
Definición de Contextos en Talend
Dentro del contexto, definiremos que grupo de valores es el que se utilizara por defecto. Esto nos va a permitir trabajar con los jobs y sus componentes olvidandonos de contra que sistema estamos trabajando. Tendremos, por ejemplo, el contexto de test activo, y es el que utilizaremos para las pruebas. Y podremos cambiar en cualquier momento, al ejecutar un job, para decirle que utilice el contexto “productivo”. Igualmente, podremos preparar un fichero o una tabla de base de datos con los valores de las variables de contexto, que serán pasadas al job para su utilización en la ejecución de un proceso (utilizando el componente tContextLoad).
Definición del proceso de carga
El diseño físico definitivo de la tabla de hechos será el siguiente:
Una vez hechas todas las consideraciones, veamos el esquema de como quedaria nuestro proceso de transformación.
Job completo en Talend para la carga de la tabla de Hechos
Vamos a ver en detalle cada uno de los pasos que hemos definido para realizar la lectura de datos del sistema origen y su transformación y traspaso al sistema destino (y teniendo en cuenta varios procesos auxiliares y la carga del contexto de ejecución).
1) Ejecución de un prejob que lanzará un generara en el log un mensaje de inicio del proceso y un logCatcher (para recoger las excepciones Java o errores en el proceso). Este generará el envio de un email de aviso en el caso de que se produzca algún problema en cualquier paso del job (al igual que hemos incluido en todos los jobs de carga del DW vistos hasta ahora).
- Lanzador Prejob (componente tPrejob): sirve para realizar el lanzamiento de un pretrabajo, anterior al proceso principal.
- Mensaje Log Inicio (componente tWarn): genera un mensaje de log indicando que se comienza la ejecución del job.
- Control Errores (componente tLogCatcher): activamos el componente que “escuchara” durante toda la ejecución del job, esperando que se produzca algún tipo de error. En ese momento se activara para recuperar el error y pasarlo al componente siguiente para el envio de un email de notificación.
- tFlowtoIterate: convertimos el flujo de registros de log a una iteración para poder realizar el envio del correo electrónico.
- Envio Email Notif (componente tSendMail): generamos el envio de un email de notificación de errores, incluyendo el paso donde se paro el proceso, y el mesaje de error generado. Es una forma de avisar que ha fallado algo en el proceso.
2) Carga del contexto de ejecución: para que el proceso sepa que tipo de carga ha de realizar y para que periodo de fechas, es necesario proporcionarle la información. Esto lo haremos utilizando los contextos. En este caso, tal y como vemos en la imagen, el contexto tendrá 3 variables, donde indicaremos el tipo de carga y la fecha inicio y fin del periodo a procesar.
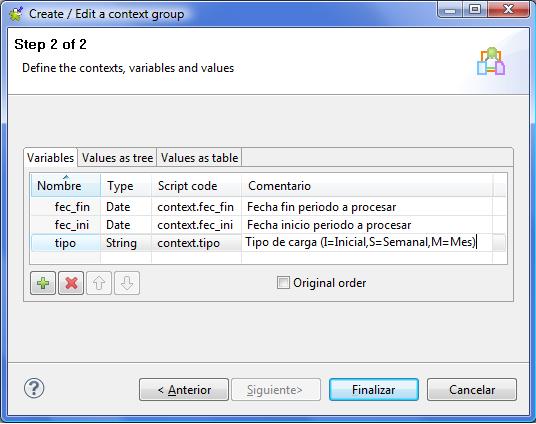
Contexto para la ejecución del Job
Los valores para llenar el contexto los recuperaremos de un fichero de texto (también lo podiamos haber recuperado de los valores existentes en una tabla de la base de datos). El fichero contendrá lineas con la estructura “clave=valor”, donde clave sera el nombre de la variable y valor su contenido.
Para abrir el fichero, utilizaremos el paso LEE_FICHERO_PARAMETROS (componente tFileInputProperties), que nos permite leer ficheros de parametros. A continuación cargaremos los valores recuperados en el contexto utilizando el paso CARGA_CONTEXTO, del tipo tContextLoad. A partir de este momento ya tenemos cargado en memoria el contexto con los valores que nos interesan y podemos continuar con el resto de pasos.
Podriamos haber dejado preparados los valores de contexto en una tabla de base de datos y utilizar un procedimiento parecido para recuperarlos y con el componente tContextLoad cargarlos en el job. Tened en cuenta que los ficheros que va a leer el job habrán sido previamente preparados utilizando alguna herramienta, donde se definira el tipo de carga a realizar y el periodo (y dichos valores se registraran en el fichero para su procesamiento).
3) Borrado previo a la recarga de los datos del periodo en la tabla de hechos (para hacer un traspaso desde cero): antes de cargar, vamos a hacer una limpieza en la tabla DWH_VENTAS para el periodo a tratar. De estar forma, evitamos inconsistencia en los datos, que podrían haber sido cargados con anterioridad y puede haber cambios para ellos. Con el borrado, nos aseguramos que se va a quedar la última foto completa de los datos. Para hacer esto, utilizamos el paso BORRAR_DATOS_PERIODO (del tipo tMySqlRow).
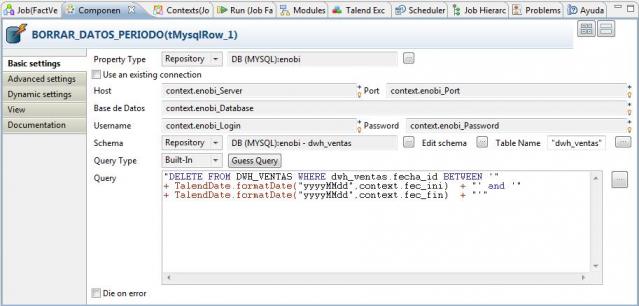
Observad como en el paso hemos incluido la ejecución de una sentencia sql de borrado (DELETE), y le hemos pasado como valores en las condiciones del where las fechas del periodo, utilizando las variables de contexto.
4) Lectura de datos desde los pedidos de venta (cabecera) y a partir de cada pedido, de las lineas (desde el ERP).
A continuación, procederemos a recuperar todos los pedidos de venta del periodo para obtener los datos con los que llenar la tabla de Hechos. Para ello, utilizamos el paso LEER_CABECERA_PEDIDO (del tipo tOracleInput), con el que accedemos a oracle y obtenemos la lista de pedidos que cumplen las condiciones (observar como también en la sentencia SQL ejecutada por este componente hemos utilizado las variables de contexto).
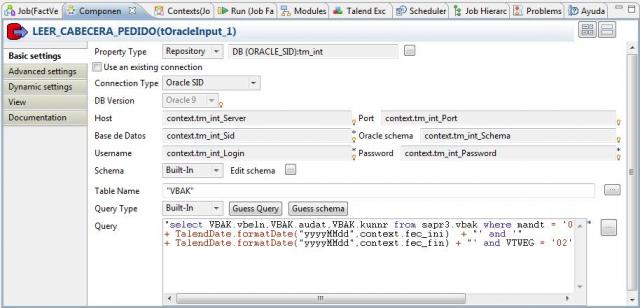
A continuación, para cada pedido, recuperamos todas las lineas que lo componen con el paso LEER_LINEAS_PEDIDO (también del tipo tOracleInput) y pasamos todos los datos al componente tMap para realizar las transformaciones, normalización y operaciones, antes de cargar en la base de datos.
5) Transformación de los campos, normalización, operaciones.
Los valores de los datos de cabeceras y lineas de pedido recuperados desde Sap los transformamos a continuación conforme a la especificaciones que hicimos en el correspondiente análisis (ver entrada blog). En este proceso realizamos conversión de tipos, llenado de campos vacios, cálculos, operaciones. Todo con el objetivo de dejar los datos preparados para la carga en la tabla de Hechos de la base de datos.
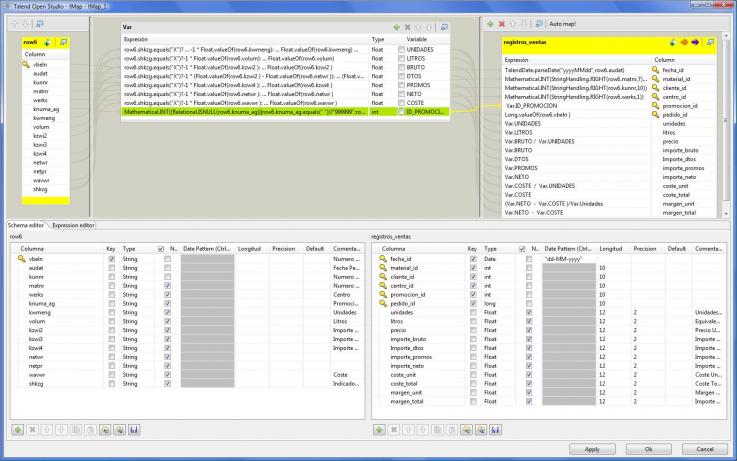
Transformaciones de los datos de pedidos antes de grabar en tabla Hechos
En este ejemplo, hemos utilizado un elemento nuevo del control tMap, que son las variables (ver la parte central superior). Las variables nos permiten trabajar de forma mas agil con los procesos de transformación, filtrado, conversión y luego se pueden utilizar para asignar a los valores de salida (o ser utilizadas en expresiones que las contengan).
Por ejemplo, observar que hemos creado la variable UNIDADES, y en ella hemos hecho un calculo utilizando elementos del lenguaje Java:
row6.shkzg.equals("X")?-1 * Float.valueOf(row6.kwmeng):Float.valueOf(row6.kwmeng)El campo SHKZG de los pedidos nos indica si un pedido es venta o abono. Por eso, si dicho campo tiene el valor X, hemos de convertir los importe a negativo. Observad también como luego utilizamos las variables definidas en la sección VAR en el mapeo de campos de salida.
Para los campos que son clave foranea de las correspondientes tablas de dimensiones (código de cliente, material, etc), hemos realizado las mismas transformaciones que realizamos cuando cargamos dichas tablas, para que todo quede de forma coherente y normalizada.
6) Inserción en la tabla de hechos y conclusión del proceso.
Como paso final, vamos realizando el insertado de los registros en la tabla DWH_VENTAS utilizando el componente tMysqlOutput (tal y como vemos en la imagen).
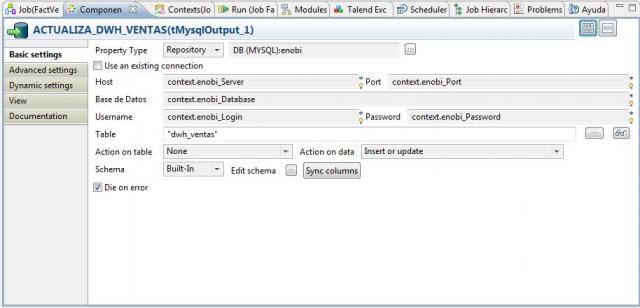
Una vez realizada toda la lectura de datos e inserción, concluiremos el proceso generando un mensaje de conclusión correcta del Job en la tabla de Logs con el paso MENSAJE_LOG_FIN (componente tipo tWarn).
Observad como hemos incluido, intercalados en los diferentes pasos del job, unos llamados VER_REGISTROS (del tipo tLogRow). Es un paso añadido para depuración y comprobación de los procesos (aparece en consola los valores de los registros que se van procesando). En el diseño definitivo del job estos pasos se podrían eliminar.
Para ver en detalle como hemos definido cada componente, podeís acceder a la documentación HTML completa generada por Talend aquí. Podeis descargaros el fichero zip que contiene dicha documentación aquí.
Conclusiones
Hemos terminado el desarrollo de todos los procesos de carga para llenar nuestro DW. Para cada una de las dimensiones y para la tabla de hechos, hemos construido un proceso con Talend para llenarlos. Como ultima actividad, nos quedaría combinar todos esos procesos para su ejecución conjunta y planificarlos para que la actualización del DW se produzca de forma regular y automatica.
Igualmente, veremos la forma de exportar los procesos en Talend para poder ejecutarlos independientemente de la herramienta gráfica (nos permitira llevar a cualquier sitio los procesos y ejecutarlos, pues al fin y al cabo es código java).
Todo esto lo veremos en la siguiente entrada del blog.
cuando los procesos utilizan
cuando los procesos utilizan cursores que elemento se deberia usar? estoy tratando de hacer un cursor que va generando variables que al final hacen un merge a la base. pero no he encontrado la manera de hacerlo desde el talend.
- Log in to post comments
Exportación jobs en Talend.Planificacion procesos ETL.
Exportación jobs en Talend.Planificacion procesos ETL. respinosamilla 25 February, 2010 - 09:50Una vez concluido el desarrollo de los procesos para la carga del DW, la siguiente tarea sera la planificación de estos para su ejecución regular, de forma que vayan reflejando en el DW todos los cambios que se vayan produciendo en el sistema operacional ( modificaciones en los datos maestros y nuevos hechos relacionados con los procesos de negocio de ventas).
Los jobs que hemos definido usando Talend se podrían ejecutar a petición desde la herramienta, o bien a nivel de sistema operativo, utilizando la correspondiente herramienta (CRON en Unix/Linux, AT en Windows). Para ello es necesario generar los ficheros de scripts a nivel de sistema operativo.
 Para hacer esto, hemos de exportar el Job, pulsando con el botón derecho sobre el. Nos aparecera el correspondiente menú contextual, donde podremos seleccionar la opción “Export Job Scripts“. Como ya comentamos, Talend puede trabajar a nivel de generación de código con los lenguajes Java y Perl. Cuando creamos un proyecto, seleccionamos con que lenguaje vamos a trabajar(en nuestro caso hemos seleccionado Java), lo que determina que internamente se trabaje a todos los niveles con Java, al igual que a la hora de definir expresiones en los diferentes procesos y transformacion. De la misma manera, cuando exportemos los correspondientes scripts de un Job, estos se generarán utilizando dicho lenguaje.
Para hacer esto, hemos de exportar el Job, pulsando con el botón derecho sobre el. Nos aparecera el correspondiente menú contextual, donde podremos seleccionar la opción “Export Job Scripts“. Como ya comentamos, Talend puede trabajar a nivel de generación de código con los lenguajes Java y Perl. Cuando creamos un proyecto, seleccionamos con que lenguaje vamos a trabajar(en nuestro caso hemos seleccionado Java), lo que determina que internamente se trabaje a todos los niveles con Java, al igual que a la hora de definir expresiones en los diferentes procesos y transformacion. De la misma manera, cuando exportemos los correspondientes scripts de un Job, estos se generarán utilizando dicho lenguaje.
 Al exportar el Job, nos aparece un cuadro de diálogo, como el que veis a la derecha, donde se nos pide un directorio para realizar la generación de todos los elementos necesarios, ademas de indicar una serie de opciones:
Al exportar el Job, nos aparece un cuadro de diálogo, como el que veis a la derecha, donde se nos pide un directorio para realizar la generación de todos los elementos necesarios, ademas de indicar una serie de opciones:
- Tipo de exportación: trabajo autonomo, Axis web service, JBoss ESB.
- Versión del job: podemos realizar una gestión de versiones de las modificaciones que vamos realizando sobre este y luego descargar una versión en concreto.
- Sistema operativo para generar el shell: indicamos para que tipo de sistema va a preparar los scripts para la posterior ejecución de los procesos.
- Incluir objetos dependientes: podemos hacer que en el directorio de exportación se incluyan todos los elementos necesarios para la ejecución independiente del trabajo (módulos talend, librerias java, rutinas del sistema). Esto nos permitirá llevarnos el job y ejecutarlo en cualquier sitio sin necesitar nada mas (solo la correspondiente maquina virtual java).
- Source files: podemos generar también el código fuente de nuestros jobs (para analizarlo o modificarlo directamente). Recordemos que Talend realmente es un generador de código, que utiliza la plataforma Eclipse.
- Contexto a utilizar: de todos los contextos que tenga definido el job, podemos indicar con cual se van a generar los scripts de ejecución (aunque luego podremos modificar el script para ejecutar con otro contexto, no es mas que un parametro de ejecución).
Una vez exportados los jobs, vemos que en la carpeta donde se ha exportado, aparecen los siguientes elementos:
- Directorio “NombreJob”: aparecen los scripts para ejecutar el job ( NombreJob_run.bat y NombreJob_run.sh), y la libreria NombreJob_version.jar, que es la que se llama desde el script para arrancar la ejecución del proceso. Es la libreria Java que se ha construido con todos los elementos y componentes que hemos utilizado para la definición de nuestro Job. Dento de estar carpeta cuelga otra donde se guardan los ficheros con los valores de las variables de contexto (en ficheros del tipo properties).
Script de ejecución de un job para Windows
En el script, observamos como se le pasa como parametro el contexto con el que queremos que se ejecute el Script. Es sencillo cambiarlo y teniendo preparados los juegos de variables correspondientes en diferentes ficheros de contexto, podremos trabajar con los mismos jobs trabajando sobre diferentes entornos o ejecutar los jobs con valores personalizados.
- Directorio “Lib”: aparecen todas las librerias java necesarias para la ejecución independiente del job. En nuestro caso, por ejemplo, que hemos utilizado controles para envio de mail (aparece la libreria mail.jar), conexión a mysql (aparece la libreria mysql-connector-java*.jar), conexión a oracle (libreria ojdbc14-9i.jar), rutinas de usuario (userRoutines.jar), etc.
Para realizar la planificación de los jobs, podriamos utilizar el CRON del sistema operativo Unix/Linux (preparando su correspondiente fichero crontab ), o bien a nivel de Windows utilizando AT o alguna herramienta similar como WinAT. Talend proporciona una herramienta para preparar los ficheros crontab. La herramienta es el OpenScheduler (tal y como vemos en la imagen).
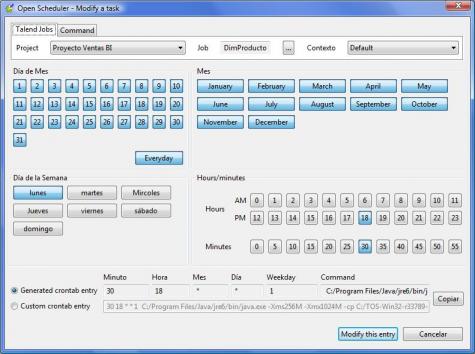
Talend Open Scheduler
De una forma visual, podemos elegir los diferentes parametros de ejecución del job (dia del mes, dia de la semana, mes, hora, minutos). A partir de las entradas grabadas en el OpenScheduler, podemos generar un fichero con los parametros necesarios para incorporar la programación de los jobs a las tablas crontab de nuestro sistema y asi planificar la ejecución de los procesos en los momento indicados.
Planificación de Jobs para el proyecto Enobi
Utilizando los scripts generados, planificaremos en nuestro sistema un lote de trabajos que ejecutará, en primer lugar, la carga de las dimensiones. Una vez concluida esta, se lanzara la carga de la tabla de hechos de venta (pues llevan incluidos datos que dependen de los existentes en las dimensiones).
La siguiente fase de nuestro proyecto será la explotación del DW utilizando la herramienta de Microstrategy 9. En primer lugar, teniendo en cuenta el diseño definitivo, configuraremos el modelo de datos dentro de el, para posteriormente abordar la explotación del sistema. Esta incluirá todos los ambitos del Business Intelligence. Veremos ejemplos de informes, cubos olap y navegación dimensional, cuadros de mando e indicadores kpi´s y también funciones de Data Mining.
Implementación del sistema BI utilizando Microstrategy.
Implementación del sistema BI utilizando Microstrategy. respinosamilla 25 February, 2010 - 09:50Aunque ya utilizamos la Microstrategy Reporting Suite para la construcción del prototipo de nuestro proyecto (ver entrada del blog ), antes de realizar la implementación completa del proyecto vamos a hablar un poco de Microstrategy.
Microstrategy es una compañia norteamericana, fundada en Virginia en 1989. Esta especializada en ambitos de Inteligencia de Negocio. Después del ultimo baile de adquisiciones (Cognos por parte de IBM, Business Objects por parte de Sap, etc.), se ha quedado como uno de los pocos grandes fabricantes de software BI independientes.

Parte de la fuerza de Microstrategy radica en su especialización, y en que su producto es realmente una plataforma integrada de herramientas de Inteligencia de negocio, y no diferentes productos agregados para formar una suite (como es el caso de otros fabricantes, conseguido en ocasiones a base de adquisiciones). Aparece en el cuadrante superior de los informes Gartner (tal y como vemos en la imagen) y cuenta con unos de los mayores porcentajes de fidelidad por parte de los clientes.
Su producto principal es la suite Microstrategy 9, que incluye todos los elementos para crear la estructura de business intelligence en una empresa.
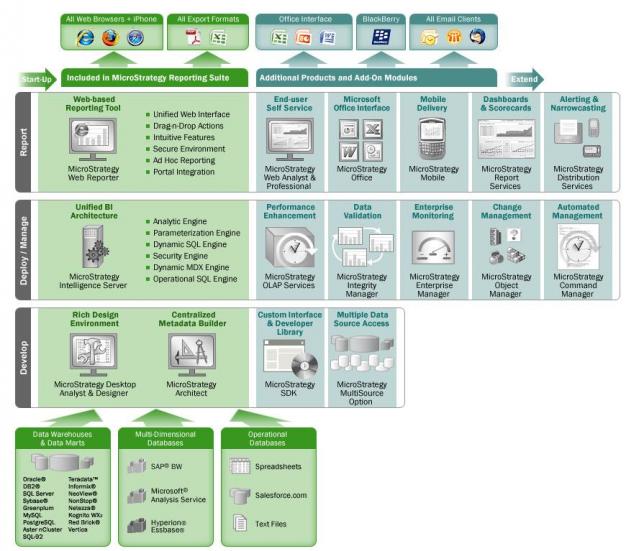
- Arquitectura de Microstrategy Reporting Suite
Algunas de las características mas importantes de la versión 9 son la siguientes (podeis ampliar información en la entrada del blog BI Facil ):
- Motor ROLAP Multi Origen: permite analisis a través de varios de origenes de datos. Podemos definir un modelo dimensional que trabaja sobre varias bases de datos diferentes.
- Tecnologia In-memory ROLAP: la tecnologia Intelligent Cube detecta las consultas mas frecuentes y que mas recursos consumen y las consolida en cubos en memoria. De forma que cuando los informes o cuadros de mando se ejecuten, utilizaran esos cubos siempre que sea posible.
- Mejoras de la interfaz Web.
- Mejoras de Dashboard y análisis.
- Distribución de servicios y automatización de procesos: herramienta para la distribución de los resultados de informes y cuadros de mando, utilizando multiples formatos (HTML, Excel, PDF, Flash, CSV, etc).
- Mejoras en el servicio de reporting.
- Generador de SQL de alto rendimiento: motor de generación de sentencias SQL mejorado de alto rendimiento, que permite mejorar los tiempos de respuesta en la ejecución de las consultas contra la base de datos.
Los elementos mas importantes que forman la herramienta de Microstrategy son los siguientes:
•MicroStrategy metadata: repositorio que almacena las definción de los objetos de MicroStrategyy la información sobre el data warehouse.
•MicroStrategy Intelligence Server: servidor analitico optimizado para el reporting empresarial y para el analisis Olap.
•MicroStrategy Desktop: aplicación en entorno windows que proporciona un completo abanico de funciones analíticas diseñadas para facilitar el desarrollo de informes.
•MicroStrategy Web and Web Universal: interfaz de usuario altamente interactivo para la ejecución de informes y análisis.
Componentes de Microstrategy
•MicroStrategy project: lugar donde definimos y almacenamos todos los objetos del esquema y la información que necesitamos para trabajar con nuestro sistema de reporting y analisis.
•MicroStrategy Architect,: herramienta para el diseño de los proyecots, que nos permite definir de forma gráfica todos los componentes requeridos para el proyecto desde una interfaz centralizada.
Los componentes de la plataforma de MicroStrategy trabajan de forma conjunta para proporcionar un entorno de analisis y reportig a la comunidad de usuarios de una organización, tal y como vemos en la imagen anterior:.
Como parte de su estrategia para captar clientes de medianas empresas, y también para plantar cara al gran desarrollo de las soluciones BI Open Source, Microstrategy ha liberado una parte de su producto en la Reporting Suite. Podemos ver en la imagen la parte que incluye la Reporting Suite, y la parte adicional de la que podriamos disponer si compramos la Suite Microstrategy 9. La MRS incluye licencia gratuita indefinida para 1 CPU y 25, 50 o 100 usuarios nominales y también 60 dias de soporte técnico via email. De la misma manera, tenemos acceso a su centro de recursos, donde se dispone de una amplia base de conocimiento, manuales completos de los productos, foros de discusión o recursos para desarrolladores (ver la guia rapida para empezar aquí ). Se supone que con este tipo de licencia, las empresas podrán cubrir una parte de sus necesidades en el ámbito del reporting y BI, conocer la herramienta y ampliar con la parte de pago las funcionalidades, según vayan surgiendo nuevas necesidades.
- Web del Centro de Recursos de Microstrategy
Para el proyecto ENOBI vamos a utilizar la versión de evaluación gratuita de Microstrategy 9,que podremos probar durante 30 dias. Para contruir nuestro sistema, nos valdrá todo lo que aprendimos montando el prototipo de evaluación inicial (pues la herramienta de modelado y desarrollo, el MicroStrategy Desktop y MicroStrategy Architect son comunes a ambas versiones, y nos valdrá todo lo que aprendimos en su momento).
Podriamos haber utilizado la Reporting Suite, pero tenemos el objetivo de comparar una versión Propietaria de software BI con una versión Open (que será Pentaho). Y para que ese análisis sea mas amplio, es preferible tener la versión completa. De esta forma podremos realizar un cuadro comparativo de la funcionalidad con cada herramienta ( y especificar de una forma clara las ventajas de una y otra, puntos fuerte y debiles, en que herramienta es mas facil hacer que tipo de cosas, para que cosas se necesita desarrollo adicional o conocimientos técnicos mas profundos, en que puntos cambiamos la facilidad de montaje por horas de consultoria pero menos precio de licencias, etc).
Esa comparativa entre Microstrategy y Pentaho será el pilar principal de nuestra investigación a partir de este momento, que nos va a permitir conseguir un amplio conocimiento de las herramientas, e igualmente llevar a la práctica y profundizar en mas conceptos de la teoria de la inteligencia de negocio (reporting, cuadros de mando, olap, data mining).
Igualmente, intentaremos comparar dos productos en el ámbito de las ETL Opensource, como son Talend Open Studio (del que ya hemos visto unas cuantas cosas ), y Pentaho Data Integration (Kettle), con el que intentaremos reproducir todos los procesos realizados hasta el momento para la carga del DW.

- Introducción.
- Get Started Now! Videos de Configuración:
- Set Up and Configure the Server: Instalación y configuración del servidor.
- Design Attributes and Hierarchies: Diseño de atributos y jerarquías.
- Design Metrics, Filters, and Prompts: Diseño de métricas, filtros y selecciones.
- Add Users: Gestión usuarios.
- Go Live on the Web.
- Business User Features Videos – Videos de Usuario:
- Explore the Data: Explorando por los datos.
- Visualize the Data: Visualizando los datos.
- Drill Through the Data: Navegando por los datos.
- Run Ad Hoc Reports: Ejecución de informes Ad Hoc.
- Technical Feature Videos – Videos Técnicos:
- Create a Report: Creación de Informes.
- Create a KPI or Metric: Creacion de KPI y Métricas.
- Create a Graph: Creación de Gráficos.
- Create Data Groups on the Fly: Creación de Grupos en tiempo de ejecución.
Como información adicional para empezar a trabajar con Microstrategy os dejo el link a unos cursos de la herramienta realizados por Anibal Goicoechea (gracias por su aportacion, podeis visitar su blog).
- Introducción a MicroStrategy, Sesión 1/4
- Introducción a MicroStrategy, Sesión 2/4
- Introducción a MicroStrategy, Sesión 3/4
Comparativas Microstrategy – Otros productos BI
Finalmente, os dejo unas comparativas de Microstrategy con los principales productos del mercado ( Sap Business Objects, IBM Cognos, Oracle OBIEE Plus, Microsoft y Qliktech ), que os pueden servir en el caso de que esteis realizando una selección del producto a utilizar (ver comparativa).
Comparativas con otros productos BI
Son muy interesantes, pues comparan el producto de Microstrategy con sus competidores a un gran nivel de detalle, remarcando que cosas se pueden hacer con MS y no con los competidores, ademas de incluir whitepapers independientes. No disponen de una comparativa con productos Open (intentaremos realizar nosotros al final de nuestro proyecto la nuestra con Pentaho).
excelente tutorial
excelente tutorial
- Log in to post comments
Instalación y configuración del servidor Microstrategy 9.
Instalación y configuración del servidor Microstrategy 9. respinosamilla 25 February, 2010 - 09:50Despues de descargarnos la versión de evaluación gratuita de Microstrategy 9 de su Web, procederemos al registro del producto. Para esto, utilizaremos el código de promocion que nos proporcionan y a la vuelta, nos enviarán el código de activación que sera el que nos permita utilizar la funcionalidad completa de la herramienta durante 30 dias (sino lo activamos solo se puede utilizar durante 7 dias).
Antes de instalar, vamos a tener en cuenta que requisitos de aplicaciones tiene la suite:
- Sistema Operativo: Windows 2003 SP2, Windows 2003 R2 SP2, Windows XP Professional Edition SP3 (on x86) or SP2 (on x64), Windows Vista Business Edition SP1, or Windows Vista Enterprise Edition SP1 (all Windows operating systems on x86 or x64). También se puede instalar la suite en Windows XP o Vista, pero solo para propositos de evaluación (como es nuestro caso).
- Servicios de Internet: Microsoft Internet Information Services (IIS) version 5.1, 6.0, or 7.0
- Explorador Web: Microsoft Internet Explorer version 6.0.2 or 7.0
- Lector Pdf: Adobe Reader version 7.0, 8.0, 8.1, or 9.0
- Adobe Flash Player version 9.0
- Para evaluar el MicroStrategy Office, cualquier de las versiones siguientes de Office:Microsoft Office 2002 (XP) SP3, Microsoft Office 2003 SP3 y Microsoft Office 2007 SP1.
A continuación lanzaremos el proceso de instalación, en el que se nos pedirá la ubicación de los ficheros y los elementos a instalar. Si alguna de las dependencias para instalar la suite no se cumple, se nos avisará de ello. Una vez concluido el proceso de instalación, continuaremos con la configuración. Como ayuda, os recomiendo el video Set Up and Configure the Server: Instalación y configuración del servidor. Una vez concluido el proceso, el sistema se reiniciara. Sería conveniente en este momento realizar el registro de las licencias utilizando el License Manager.
Bases de datos necesarias para utilizar Microstrategy 9
Para trabajar con Microstrategy, tendremos que tener disponibles varios esquemas de base de datos, cada uno con un cometido diferente:
- Datawarehouse: una o varias bases de datos de donde la herramienta leera la información (según el módelo que construyamos), para elaborar los informes, consultas, cuadros de mando, cubos, etc. Es la base de datos que hemos modelado y construido en la fase de analísis de nuestro proyecto y llenado con los procesos ETL utilizando Talend.
- Metadata: son las tablas internas de Microstrategy donde se guarda toda la información del modelo de datos que definamos y de todos los objetos que construyamos utilizando la herramienta (filtros, informes, indicadores, etc.). Es el corazon del sistema de BI.
- Historial: historial de las modificaciones que realizemos con los objetos.
- Estadisticas: tablas para mantener y controlar la actividad del sistema.
Microstrategy nos permite trabajar de forma directa con los principales motores de base de datos (DB2, Informix, MySql, Oracle, PostreSQL, Sybase o SQL Server). Igualmente, a través de ODBC podremos acceder a otras muchas bases de datos (comprobad las tablas de compatibilidad en la documentación).
Motores de bases de datos a utilizar con Microstrategy
En nuestro caso, utilizaremos ODBC, con el driver proporcionado por MySql. Y configuraremos las siguientes origenes de datos (podemos utilizar el Connectivity Configuration Wizard proporcionado por Microstrategy o el gestor de conexiones ODBC de Windows):
- ENOBI_DW: base de datos donde se ubicara el Datawarehouse (corresponde a la base de datos con esquema ENOBI en MySql).
- ENOBI_MD: base de datos donde se ubicara el Metadata de nuestro proyecto (corresponde a la base de datos con esquema METADATA en MySql).
- ENOBI_HS: base de datos donde se ubicara el Historial (esquema HISTORIAL en MySql).
- ENOBI_ES: base de datos donde estarán las estadísticas (esquema ESTADISTICAS en MySql).
Configuración Inicial del Sistema
Una vez definidos las conexiones ODBC e instalada correctamente la aplicación y su licencia, vamos a utilizar el asistente de configuración (Configuration Wizard) para dejar el sistema listo para empezar a trabajar con el.
El configuratión Wizard tiene 3 tareas a realizar, que son la siguientes:
Configuration Wizard
- Tablas de repositorio: en este paso creamos en las bases de datos los catalogos de tablas necesarios para los diferentes componentes (como hemos visto METADATA, ESTADISTICAS e HISTORIAL). El proceso se conecta a las bases de datos y crea en ellas todas las tablas necesarias para gestionar el metadatos de microstrategy, llenando ademas el contenido de las tablas con los objetos predefinidos.
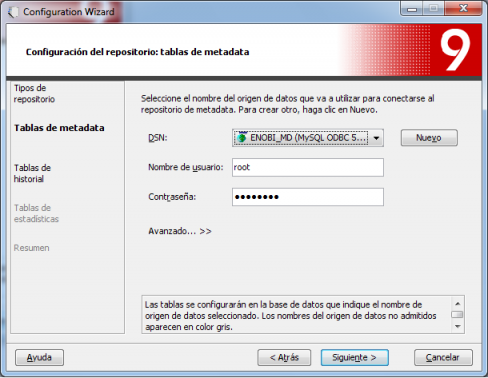
Creacion del repositorio de tablas del Metadata
- Definiciones de MicroStrategy Intelligence Server: el Microstrategy Intelligence Server es el motor de procesamiento y gestion de los trabajos de las aplicaciones de informes, análisis y monitorización. Utiliza una arquitectura orientada al servicio (SOA), y estandariza en una única plataforma todas las necesidades de analisis y reporting, a traves de varios canales de acceso:Web browsers, Microsoft® Office, Desktop clients,y email. En este paso de la configuración le asociamos al Intelligence Server el esquema de base de datos del METADATA (que habremos dejado preparado en el paso anterior), e indicamos parametros adicionales de configuración (como el puerto TCP o si queremos registrarlo como un servicio). Tendremos un unico Intelligence Server en nuestro sistema.
Configuracion Intelligence Server
- Orígenes de Proyecto: un origen de proyecto es la ubicación centralizada de los diferentes proyectos. Es un contenedor que luego nos permitira definir dentro de el los proyectos que tengamos en nuestra infraestructura de BI. Se pueden definir varios origenes de proyecto (no necesariamente solo uno). Al crear un origen de proyectos, le asociamos un tipo de origen y le indicamos el tipo de validación de usuarios que se va a realizar para el ( usuario de windows, usuario de Microstrategy, usuario LDAP, usuario de base de datos, etc). En nuestro caso creamos el origen de Proyecto ENOBI que va a incluir todos los elementos de nuestro proyecto.
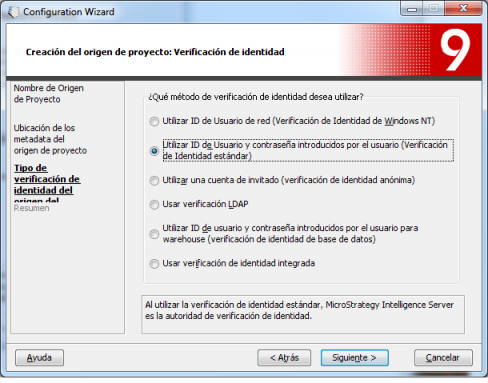
Definición de Origenes de Proyecto - Tipo de validación de usuarios
Los tipos de Origen de proyecto son los siguiente, segun el tipo de configuración:
- Directo o 2 niveles: pensado para instalaciones de test, formación o prototipos. En este caso, no pasamos a través del Intelligence Server, sino que accedemos directamente al Metadata cuando creemos un proyecto (por eso hay que indicar que origen de datos contiene el Metadata).
- Microstrategy Intelligence Server o 3 niveles: pensado para instalaciones en productivo. En este caso pasamos a través del Intelligence Server, y por tanto, utilizamos el origen de datos del Metadata que definimos anteriormente en él.
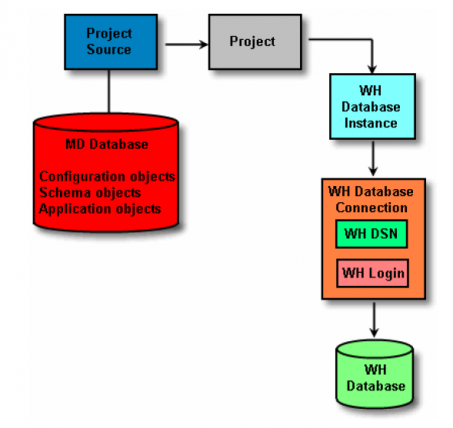
Esquema Arquitectura Microstrategy
En un origen de Proyectos podremos definir uno o varios proyectos utilizando el Project Builder o el Microstrategy Desktop (y su asistente para la creación de proyectos).
Hemos concluido con estos paso la configuración básica de nuestro servidor de Microstrategy 9. Ha sido relativamente sencillo dejar el sistema preparado para comenzar a trabajar con las herramientas de Microstrategy.
Creación del proyecto ENOBI
Es el último paso para poder empezar a trabajar con las herramientas de Microstrategy. Un proyecto ha de estar siempre ubicado en un origen de Proyectos, como hemos visto. Para la creación del proyecto, tenemos dos herramientas:
- Project Builder: es un asistente pensado para la creación de proyectos sencillos, demos y prototipos, por lo que tiene bastantes limitaciones. Para cualquier proyecto productivo, sera conveniente utilizar la herramienta Desktop. En la entrada 8 del blog, construimos un prototipo de nuestro proyecto utilizando esta herramienta (se explica allí de forma detallada todos los pasos seguidos).
- Desktop – Asistente para la creación del proyectos: es la herramienta principal de desarrollo para trabajar con Microstrategy. En la herramienta Desktop vemos los diferentes origenes de proyecto que tenemos definidos en nuestro sistema, y seleccionaremos uno de ellos para crear en él el nuevo proyecto. A continuación lanzaremos el asistente, tal y como vemos en pantalla. Tiene una serie de pasos donde configuraremos los diferentes elementos que conformaran el modelo Dimensional del proyecto. Con la herramienta Architect se completa la configuración jerárquica de los atributos que forman las dimensiones.
Podeis ver el video de Microstrategy donde se detallan todos los pasos a seguir para la creación de un proyecto y sus componentes.
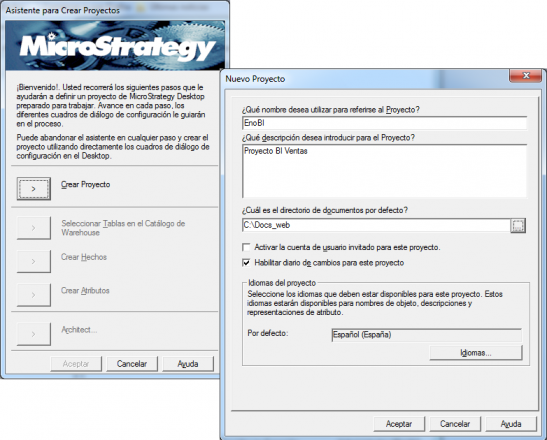
Asistente para la creación de Proyectos
Con la herramienta realizaremos una asociación entre las tablas de bases de datos del Data Warehouse (modelo físico), con los elementos lógicos de nuestro módelo (dimensiones y sus atributos; jerarquía entre los diferentes atributos que forman las dimensiones y finalmente, hechos e indicadores de negocio ). Detallaremos los pasos seguidos para realizar esto en la siguiente entrada del Blog.
Diseño de hechos, atributos y jerarquia de dimensiones en Microstrategy 9.
Diseño de hechos, atributos y jerarquia de dimensiones en Microstrategy 9. respinosamilla 25 February, 2010 - 09:50Una vez configurado el servidor y creado el proyecto (tal y como vimos en la entrada anterior del blog), vamos a proceder a implementar el modelo lógico de nuestro Data Warehouse dentro del esquema de metadatos de Microstrategy.
Esta tarea es fundamental para empezar a trabajar con nuestra herramienta de BI. Es el punto de partida para empezar a preparar los diferentes elementos que formaran nuestro sistema de Business Intelligence (informes, cuadros de mando, análisis, etc).
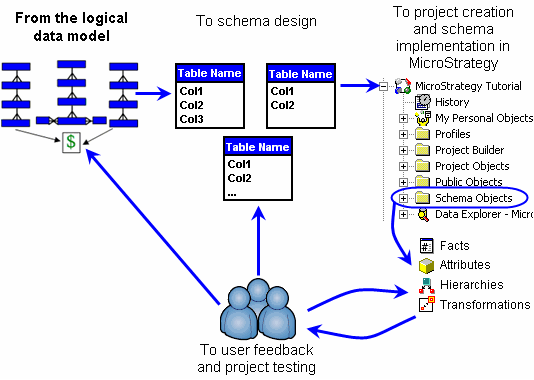
Del modelo lógico al metadata de Microstrategy
Las tareas que realizaremos en este paso será la definición de los atributos de las dimensiones, la relación entre ellos (organización jerarquica), asi como de los indicadores de negocio relevantes en nuestra organización. Aquí estableceremos la relación entre estos elementos lógicos y sus equivalentes a nivel físico (tablas y campos de la base de datos).
Os recomiendo visualizar el video elaborado por Microstrategy para ver un ejemplo real de la definición de estos elementos.
Haciendo memoria de la teoria del modelo dimensional que vimos anteriormente:
- Hechos / indicadores: son los valores de negocio por los que querremos analizar nuestra organización (importe ventas, margen, rentabilidad).
- Dimensiones: las perspectivas o diferentes ambitos por los que querremos analizar estos indicadores de negocio (son las que dan sentido al análisis de los indicadores de negocio, pues sin dimensiones no son mas que un valor mas). Permite contestar preguntas sobre los hechos y darles un contexto de análisis. En nuestro modelo, las dimensiones seran el tiempo (siempre suele haber una dimensión temporal), cliente, producto, promoción y logística.
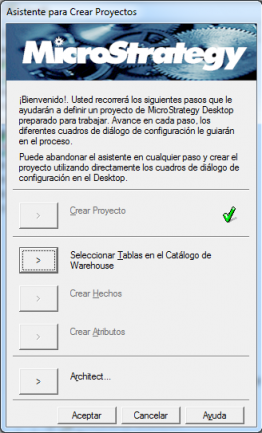
Para configurar esto dentro de Microstrategy, realizaremos tres tareas principales:
1) Selección de tablas del catalogo del Warehouse: de todas las tablas que tendremos en la base de datos del Data Warehouse, seleccionaremos con cuales de ellas vamos a trabajar. Las tablas seleccionadas y sus campos determinaran los elementos disponibles para el resto de pasos.
2) Creación de hechos: de las tablas seleccionadas en el paso anterior, indicaremos que campos son los que corresponden a los hechos. Estos campos nos serviran de base para la creación de las metricas, que seran las que utilizaremos en los informes, documentos y análisis. Estas métricas, partiendo de las base de los hechos, podran incluir operaciones, calculos de uno o mas campos, así como el uso de funciones complejas (Microstrategy incluye un gran número de funciones para realizar calculos complejos sobre los datos, incluyendo funciones estadísticas). Esto nos permitira disponer de valores que se calculan y que realmente no estan guardados en la base de datos.
3) Creación de atributos: en este paso, de la misma manera, seleccionaremos los campos que corresponden a los atributos y realizaremos la configuración básica de ellos, como descripciones, ordenación, asignación de descripciones a códigos (lookups), asi como la configuración de la estructura jerarquica de los diferentes componentes que forman una dimensión (a través de las relaciones padres e hijos).
Para realizar estas tareas, utilizaremos el Asistente para la creación de proyectos, que nos guiara de una forma ordenada, en todos los pasos a realizar para completar estas tareas. El asistente solo se utiliza cuando se crea el proyecto y los procesos de mantenimiento posteriores de las tablas, atributos y hechos los realizaremos desde la herramienta de desarrollo Microstrategy Architect o bien desde el Desktop.
Veamos un poco mas en profundidad cada uno de estos pasos:
Selección de tablas del catalogo del Warehouse
En este paso indicaremos la base de datos que corresponde al Data Warehouse, y del catalogo que indiquemos, nos apareceran todas las tablas definidas en el a nivel físico. De dichas tablas, seleccionaremos aquellas que sean relevantes para nuestro módelo (tal y como vemos en la imagen).
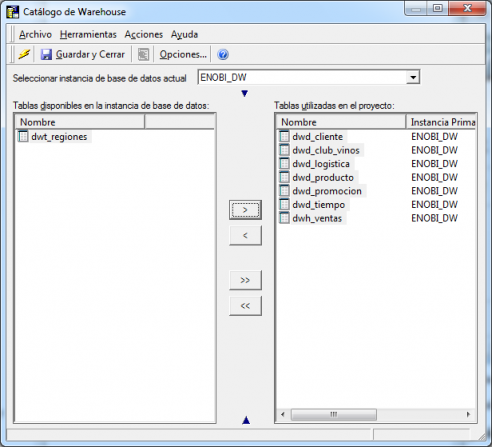
Selección de Tablas de DW
Microstrategy nos permite trabajar con la misma tabla varias veces a traves de los “alias” de tabla. Puede ser util cuando la misma dimensión fisica se utiliza de forma lógica en varios lugares(y no es necesario tener que tener una tabla física para cada una de las dimensiones). Igualmente, también nos permite trabajar con vistas.
Creación de Hechos
De los campos de las tablas indicadas en el punto anterior, en este paso seleccionaremos cuales de ellos son las que consideraremos Hechos. En principio, aunque se puede configurar, solo se toman para este cometido los campos que estan definidos como numéricos.
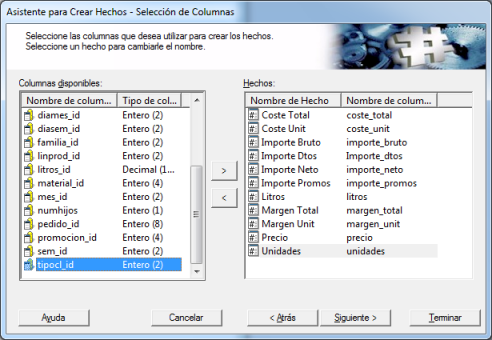
Selección de columnas de Hechos
Creación de Atributos
La creación de atributos es un poco mas compleja y lleva asociados varios pasos. En primer lugar, de todos los campos de las tablas, seleccionaremos cuales son los que corresponden a nuestros atributos. En el caso de que un atributo lleve asociado un campo identificador y un campo descripción, solo seleccionaremos el campo identificador (pues después se establecera la relación entre campos de código y campos de descripción o de lookup).
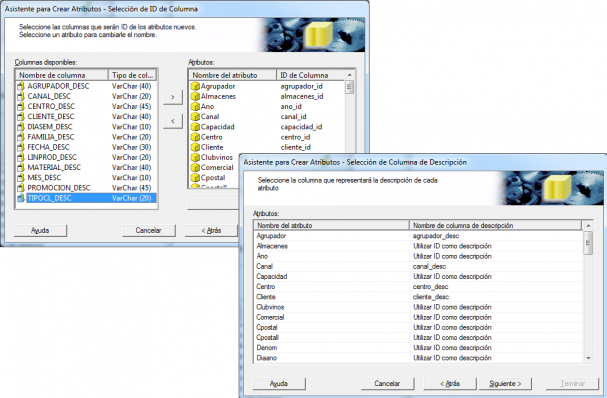
Creación de atributos
A continuación, para cada uno de los atributos, indicaremos su campo de lookup. Cuando un campo no dispone de este (como el campo Código Postal, que en si mismo se describe), indicaremos “Utilizar ID como descripción”.
Como ultimo paso en la creación de los atributos, para cada uno de ellos indicaremos que atributos son hijos de el (estan despues en la jerarquia de la dimension) o cuales son padre (estan arriba en el arbol). Este paso lo omiteremos, pues lo realizaremos a continuación con la herramienta gráfica Architect, que es mucho más agil para realizar esta definición.
Mantenimiento del módelo usando Microstrategy Architect
El Architect es, junto con el Desktop, la herramienta principal de desarrollo dentro de Microstrategy. Utilizando esta ultima herramienta podriamos igualmente haber realizado la definición de los hechos y atributos (el paso de selección de tablas habría que haberlo realizado igualmente como un paso previo).
El architect es una herramienta gráfica y con ella se realizan las tareas de mantenimiento dentro de MS. En nuestro caso, dejamos sin definir las jerarquías de atributos y las hemos completado utilizando esta herramienta. Esto es tan sencillo como seleccionar el atributo padre y arrastrar hacia el atributo hijo para que se cree la relación. Posteriormente, seleccionamos en el conector para modificar el tipo de relación entre los componentes ( 1 a n, 1 a 1, etc).
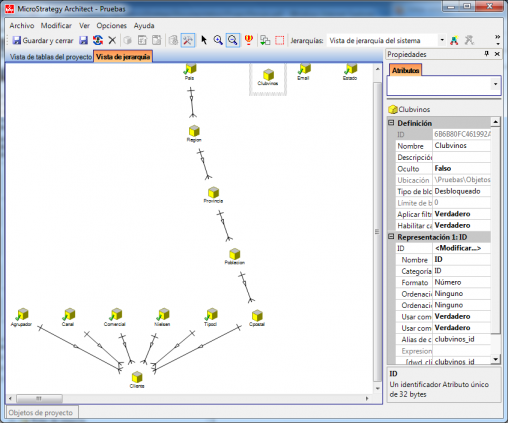
Definicion de jerarquias de atributos con Architect
En la imagen, podeis ver como hemos definido la estructura jerárquica dentro de la dimensión Cliente. Ademas, desde aquí podemos crear nuevos atributos, nuevos hechos o modificar las propiedades de estos (en la parte de la derecha tenemos la tabla de propiedades). Seleccionando el elemento, en esa sección nos aparece toda la información de como esta configurado.
Microstrategy Tutorial
Ademas del proyecto que hemos creado nosotros, al utilizar la herramienta Desktop observamos que hay creado un proyecto de ejemplo, llamado MicroStrategy Tutorial. Este proyecto trabaja con bases de datos de prueba en Access y contiene ejemplos de todos los elementos que podemos definir y utilizar en Microstrategy. Puede ser un punto de partida para aprender a trabajar con los diferentes componentes.
Igualmente, al realizar la instalación, se nos ha creado una carpeta de Documentación, donde disponemos de un lote de archivos en formato PDF con manuales completos de todas las herramientas de Microstrategy, como por ejemplo:
- Microstrategy Evaluation Guide
- Installation and Configuration Guide.
- System Administration Guide.
- Project Design Guide.
- Basic Reporting Guide.
- Advanced Reporting Guide.
- Report Service Document Creation Guide.
Conclusiones
Despues de realizar estas tareas, el módelo lógico de nuestro proyecto esta implementado y configurado dentro de Microstrategy 9, y podemos comenzar a utilizar la herramienta.
Uno de los puntos fuertes que hemos observado en la herramienta es que todo esta centralizado en las mismas aplicaciones, y desde ellas realizaremos todas las tareas de desarrollo, desde la configuración del sistema, creación del modelo, asi como la creación de los componentes que utilizaran los usuarios. El producto parece ser compacto y consistente, esta es la primera impresión que transmite.
Igualmente, Microstrategy proporciona gran cantidad de documentación, ejemplos, video tutoriales, etc, para que sea más fácil empezar a trabajar con la herramienta y buscar información sobre los diferentes elementos que la conforman. Hasta se incluye en la instalación un curso Web de la herramienta con examenes de evaluación.
Diseño de Indicadores, Filtros y Selecciones Dinámicas en Microstrategy 9.
Diseño de Indicadores, Filtros y Selecciones Dinámicas en Microstrategy 9. respinosamilla 25 February, 2010 - 09:50Antes de continuar con el diseño de indicadores, filtros y selecciones dinámicas, y ver la forma de preparar plantillas para nuestros informes, vamos a ver un poco mas en detalle elementos que tienen que ver con los atributos de las dimensiones (que vimos como se configuraban en la entrada anterior del blog), y que nos serán utiles en el desarrollo del proyecto.
Tipos de jerarquias de MicroStrategy
Las jerarquias nos permiten organizar y navegar por los atributos. En Microstrategy, disponemos de dos tipos de jerarquías:
- System hierarchy: Es la jerarquía del sistema, la que incluye las relaciones definidas entre los atributos del proyecto. Esta jerarquía no es necesario definirla, sino que se genera automaticamente en la herramienta Desktop al crear el proyecto (fue la que construimos utilizando el Architect).
Es la jerarquia por defecto, y contiene todos los atributos del proyecto, formando parte de la definición del esquema. Al terminar la creación del proyecto, es la única jerarquia que existe. La jerarquia de sistema no se edita, pero se actualiza cada vez que añadimos o quitamos atributos hijo o padre utilizando el editor de atributos o el architect, o añadimos nuevos atributos al proyecto.
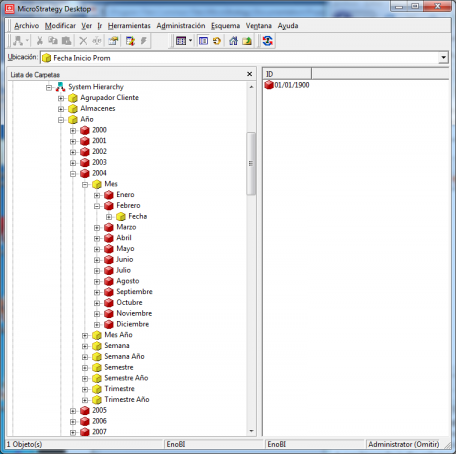
Jerarquia del Sistema del proyecto EnoBI
La jerarquia del sistema es util para determinar las relaciones existentes entre todos los objetos del proyecto (podemos navegar por ella viendo los valores de los atributos y como estan relacionados unos con otros). Los atributos definidos en la jerarquia del sistema no necesitan estan definidos en una jerarquia de usuario. Los atributos de la jerarquia de sistema que no utilizemos en las jerarquias de usuario seguiran estando disponibles para ser usados en los informes, filtros o consolidaciones.
- User hierarchy: las jerarquias de usuario son grupos de atributos y las relaciones entre ellos, juntados de manera que tenga significado en el contexto de análisis. No necesariamente tendrá que seguir el modelo de datos lógico. Ademas, a diferencia de la jerarquia de sistema, nos permite definir limitaciones al numero de valores visualizados, establecer filtros sobre los valores a visualizar o definir un punto de entrada, que sera el atributo donde nos posicionaremos al utilizar la jerarquia (por ejemplo, al navegar o al realizar filtrado).
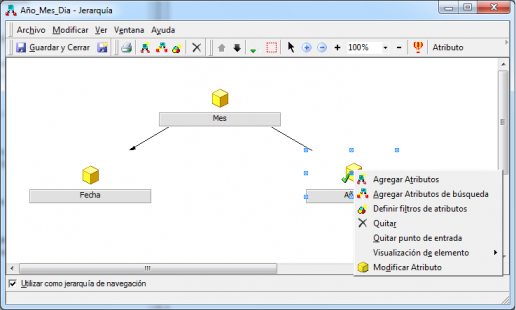
Editor de jerarquias
Por ejemplo, podremos crear una jerarquia que incluya los atributos Año, Trimestre, Mes y Dia. Cuando navegemos por los atributos con el Data Explorer, al hacer doble click en el año nos apareceran los trimestres, a continuación los meses y asi sucesivamente.
En nuestro proyecto vamos a crear todas las jerarquías necesarias para permitir la navegación por los diferentes atributos de las dimensiones.
Las jerarquias de usuario son las que tendremos disponibles cuando navegemos por los datos en los informes y documentos de Microstrategy, y nos permitiran disponer de la funcionalidad Drill Up y Drill Down entre los atributos que definamos dentro de ella. Por tanto, son un elemento indispensable en la configuración del sistema, pues son el punto de partida para sacarle todo el partido a la navegación dimensional. Por ejemplo, si en el ejemplo anterior estamos visualizando el atributo Trimestre, podremos navegar hacia arriba (drill up) por la jerarquia hasta el año, o navegar hacia abajo (drill down) hasta el mes, o cambiarnos a otra jeranquia y cambiar la navegación.
Son el unico tipo de jerarquia que se puede definir por el usuario y se podran crear todas las jerarquias que hagan falta dentro de un proyecto. Habra que pensar todas las jerarquias necesarias para que cubran todas las necesidades dentro del modelo de negocio de la compañia y del esquema del data warehouse.
Transformaciones de MicroStrategy
Son objetos del esquema que podemos definir utilizando los atributos. Se utilizan para ejecutar análisis de series de tiempo como periodo a fecha, periodo actual contra periodo anterior o análisis de periodos cambiantes. Las transformaciones las definimos sobre los atributos (como por ejemplo, en la imagen, en la que estamos utilizando una fecha, a la que restamos 14 dias). Esto nos configura un valor variable, que dependerá del valor del atributo con el que esta relacionado, y que luego utilizaremos al crear los indicadores.
Editor de transformaciones
Por ejemplo, tendremos un indicador llamado Ingresos Netos (calculado a partir del hecho ingresos netos), que nos mostrara las ventas netas actuales en el periodo que estemos analizando. Si creamos otro indicador llamado Ingresos Netos de hace 14 dias (y le asociamos la transformación definida en la imagen), cuando utilizemos el indicador en un informe nos mostrará los ingresos de 14 dias antes. Las transformaciones son un elemento muy potente y que nos permitira realizar de una forma sencilla el análisis de las series temporales.
Todos los objetos visto hasta ahora, los atributos, los hechos, las jerarquias de usuario y las transformaciones forman parte de los objetos de Esquema, y son el punto de partida para la construcción y el desarrollo de nuestro sistema de Business Intellingence. Veamos que elementos podemos construir con ellos
Diseño de Indicadores, Filtros y Selecciones de MicroStrategy
Antes de continuar, os recomiendo visualizar el video elaborado por Microstrategy donde se habla del diseño de indicadores, filtros y selecciones.
Indicadores
Los indicadores son objetos de MicroStrategy que representan medidas de negocio e indicadores de rendimiento clave. Desde un punto de vista práctico, los indicadores son los cálculos realizados en los datos almacenados en la base de datos y cuyos resultados se muestran en un informe. Son parecidos a las fórmulas de un programa de hoja de cálculo. No sería una exageración afirmar que el centro de prácticamente todos los informes son sus indicadores. La mayoría de las decisiones que se toman acerca del resto objetos que se deben incluir en un informe dependen de los indicadores que se utilicen en el informe.
En particular, los indicadores definen los cálculos analíticos que se realizan con los datos almacenados en el origen de datos. Un indicador se compone de hechos del origen de datos y de operaciones matemáticas que se van a realizar en tales hechos para, de este modo, poder efectuar un análisis de negocio con sentido en los resultados.
Editor de Indicadores
En los indicadores se pueden definir varias cosas, aunque el elemento fundamental es la formula que determina su valor.Una fórmula de indicador puede estar formada por hechos del origen de datos (como en el ejemplo anterior), atributos empresariales del origen de datos u otros indicadores que ya se hayan creado. Los siguientes ejemplos de indicadores muestran estas opciones distintas de fórmulas:
- Indicador formado por hechos: (Sum(Ingresos) -Sum(Coste)). La fórmula de este indicador suma todos los beneficios registrados en el origen de datos, suma todos los costes registrados en el origen de datos y, a continuación, resta el total de costes del total de beneficios.
- Indicador formado por atributos: Count(Clientes). La fórmula hace un recuento de los clientes de la empresa registrados en el origen de datos.
- Indicador formado por otros indicadores: [Beneficios de este mes] – [Beneficios del mes pasado] / [Beneficios del mes pasado]. La formula de este indicador resta los beneficios del mes pasado (un indicador) de los beneficios de este mes (otro indicador) y divide el resultado entre el resultado del mes pasado para determinar la diferencia porcentual en beneficios desde el mes pasado.
Las formulas pueden contener funciones matematicas y Microstrategy posee un amplia abanico de ellas para permitir realizar multiples tipos de cálculos:
Ademas de la fórmula, podemos indicar lo siguiente en las propiedades del indicador:
-
Nivel de cálculo del indicador: indicamos el nivel en la jerarquia de atributos en el que se realiza el cálculo del indicador. Por defecto, un indicador se calcula en el nivel de informe, es decir, en el nivel del atributo del informe en el que se encuentra el indicador. Pero puede haber ocasiones en las que el cálculo solo tenga sentido en un determinado nivel (no en todos los posibles según la estructura jerarquica de atributos de las dimensiones). Con este atributo condicionamos ese aspecto.
-
Condición:Es una condición que se incluye en los datos desde el origen de datos y aplica sólo a los datos relacionados con ese indicador en particular. El filtro entra a formar parte de la definición del indicador. La aplicación de la condicionalidad en un indicador hace que el cálculo de un indicador esté calificado por el filtro del indicador, independientemente de lo que se haya especificado en el filtro del informe, si lo hubiera. Nos permite definir indicadores con sus propias condiciones independientemente de las condiciones fijadas a nivel de informe.
-
Transformación: Las transformaciones se agregan normalmente a los indicadores diseñados para realizar análisis de series temporales, por ejemplo, para comparar los valores de momentos distintos, como este año frente al anterior o los del mes hasta la fecha. Las transformaciones son útiles para descubrir y analizar tendencias basadas en el tiempo en los datos.Las transformaciones se crean como objetos independientes (como hemos visto anteriormente) y se agregan a un indicador.
En el proyecto Tutorial que nos ofrece Microstrategy podemos ver ejemplos de como definir indicadores de todos los tipos posibles, desde funciones para manipular fechas, cadenas o numeros, funciones estadisticas, financieras, Olap o funciones para extraccion de datos para DataMining.
Filtros
Los filtros nos permiten establecer restricciones de valores a los diferentes elementos de nuestro sistema. Por ejemplo, podremos establecer un filtro sobre el atributo año y seleccionar un valor en concreto (por ejemplo 2009),y al ejecutar un informe con ese filtro, solo se recuperan los valores de ese año. Podriamos igualmente haber definido ese filtro de forma dinámica, de forma que al ejecutar el informe, nos aparecezca una lista de años y seleccionemos el que vamos a analizar (será un filtro de selección dinámica).
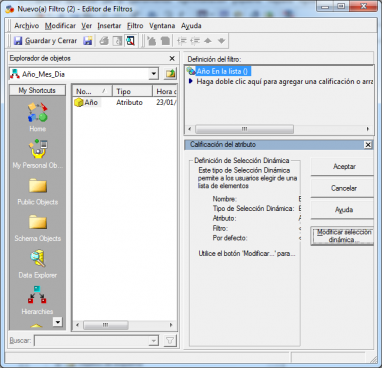
Editor de filtros
También se pueden definir los filtros sobre los indicadores, por ejemplo, para limitar que no nos aparezcan valores que sean inferiores a un valor u operaciones similares.
Selecciones dinámicas (Prompts)
Una selección dinámica es una pregunta que se hace al usuario que ejecuta un informe. Cualquier informe puede contener selecciones dinámicas. Este elemento nos permite dar un dinamismo a los informes y poder ejecutar el mismo report con diferentes criterios de ejecución. Las selecciones dinámicas pueden ser obligatorios (es imprescindible indicar un valor) u opcionales.
Las selecciones dinámicas se usan para seleccionar las condiciones de filtrado en el momento de ejecución del informe. Se puede condicionar de forma dinámica un atributo, una selección de elementos de atributo, métricas y otros objetos que se puedan incluir en un informe. Las selecciones dinámicas pueden utilizarse junto con otras selecciones estáticas, filtros, y se pueden añadir a un informe tantas como sean necesarias.
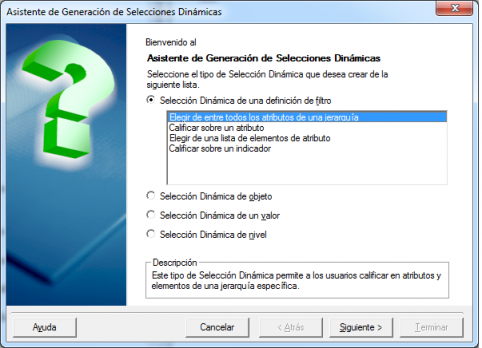
Creación de selecciones dinámicas
Tenemos los siguientes tipos de selecciones dinámicas:
- Selección dinámica de una definición de filtro: permiten a los usuarios establecer criterios de filtrado en la ejecución de informes, que se van a aplicar sobre los valores devueltos en la ejecucion de estos. Podremos establecer filtros sobre los siguientes objetos:
- Jerarquías: Es posible elegir dinámicamente la calificación de una jerarquía o entre cualquier atributo de cualquier jerarquía. Nos permite elegir entre todos los atributos que forman una jerarquía y seleccionar los valores de filtrado entre los valores mostrados para cada atributo.
- Atributos: Al igual que con las Jerarquías, es posible elegir dinámicamente un atributo concreto. Similar al caso anterior, pero solo se califica sobre un atributo en concreto (por ejemplo, el año).
- Lista de elementos de un Atributo. Esta opción permite elegir de una lista preestablecida de elementos de atributo, o bien se pueden mostrar todos los elementos. Podemos preseleccionar una lista de valores de los posibles de un atributo, y de esa lista previa, seleccionar los valores deseados.
- Calificar sobre un indicador. La calificación de una indicador se puede hacer también de forma dinámica cuando se ejecuta un informe. Nos permite establecer restricciones conforme a los valores del indicador.
- Selección dinámica de un objeto: permite al usuario seleccionar que objetos (tales como atributos, metricas, grupos personalizados, etc) incluir en el informe. Por ejemplo, podemos tener una lista con varios indicadores, y a la hora de ejecutar el informe, solo seleccionaremos los indicadores que nos interesen.
- Selección dinámica de un valor: Permite la selección dinámica de una fecha, de un valor numérico o de un texto. El valor devuelto lo podremos utilizar posteriormente en la definición de los filtros sobre una metrica o los valores de un atributo.
- Selección dinámica de nivel: Esta opción permite al usuario especificar el nivel de calculo de un indicador.
Plantillas de Informes
Las plantillas son objetos que nos sirven de base para construir los informes. Definen el layout que tendra el informe. Las plantillas especifican el conjunto de datos que el informe debe recuperar del origen de datos y también determinan la estructura en que se muestra la información en los resultados del informe.
Cuando se crea una plantilla, se colocan los diferentes objetos de Microstrategy en el, siendo los que podemos utilizar los siguientes: atributos, indicadores, filtros y selecciones dinámicas (ademas de los grupos personalizados y las consolidaciones).
Basicamente, tenemos dos tipos de layout:
- Tabla cruzada (cross-tab): util para analisis multidimensional.
- Tabular: util para listados simples de información.
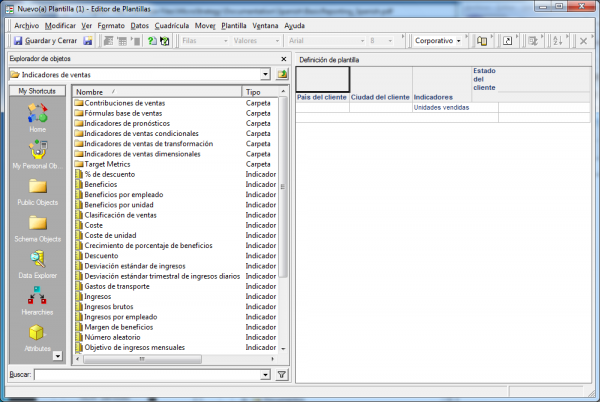
Editor de Plantillas
Las plantillas nos serviran de base para la construcción de informes.
Conclusiones
Hemos pasado por encima de los principales componentes que forman la base del sistema de BI Microstrategy. Son elementos mucho mas complejos de lo que hemos visto, con muchisimas opciones y funcionalidades, que nos van a dar muchisimas posibilidades de cara a cubrir nuestros requerimientos.
Os recomiendo una lectura profunda de la documentación proporcionada por Microstrategy para conocer cada uno de los elementos:
Estructura de Documentación de Microstrategy
De todo lo visto, podemos destacar:
- Jerarquías de usuario: nos permite personalizar la estructura de los atributos definidos en el modelo. Nos permite darle nuestro enfoque al análisis, pasando por encima del modelo jerárquica general. Ademas, el hecho de poder definir filtros sobre ellas nos podrían permitir crear las jerarquías personalizadas según la persona que va a analizar la información (como por ejemplo, por ámbito geográfico).
- Indicadores: van mucho mas allá de simples cálculos utilizando los valores que hemos generado en la tabla de hechos de nuestro modelo. El uso de las funciones de las que dispone MicroStrategy permite que podamos hacer casi de todo. Muy interesante el hecho de poder disponer de indicadores que calculan temas relacionados con los atributos (como contadores).
- Filtros y selecciones dinámicas: nos dan dinamismo en los informes a todos los niveles, no solo a la hora de filtrar la información la información a mostrar discriminando por los valores de los atributos o de los indicadores, sino también permitiéndonos seleccionar que elementos queremos que aparezcan en los informes de manera dinámica. El hecho de disponer de selecciones por los valores de los atributos de una dimensión, o de poder seleccionar entre los diferentes atributos de una jerarquía y de ahí, los valores, también nos da potencia de cara al filtrado.
Con lo visto, tenemos unas nociones básicas para empezar a trabajar con Microstrategy 9, definir los elementos básicos que luego utilizaremos (como son las jerarquías de usuario, los indicadores, filtros y selecciones dinámicas) y seguir profundizando en el resto de componentes de la herramienta.
Gestión de usuarios en Microstrategy 9. Configuración del portal Web.
Gestión de usuarios en Microstrategy 9. Configuración del portal Web. respinosamilla 25 February, 2010 - 09:50La gestión de usuarios se realiza en Microstrategy a nivel de proyecto, de forma que cada uno de ellos tiene sus propios usuarios y grupos de autorizaciones.
Antes de empezar, os recomiendo visualizar el video realizado por Microstrategy sobre la gestión de usuarios.
La gestión de usuarios se realiza desde la herramienta Desktop, en la sección de Administración. En Microstrategy se trabaja basicamente con tres conceptos: Roles de Seguridad,Usuarios y Grupos.
Gestión de usuarios en Microstrategy 9
Disponemos de un conjunto de privilegios, predefinidos y clasificados por areas temáticas, que son los siguientes:
- Web Reporter.
- Web Analyst.
- Web Professional.
- Opcion Web MMT.
- Privilegios comunes.
- Office.
- Mobile.
- Microstrategy Distribution Services.
- Opción de origen múltiple.
- Desktop analyst.
- Desktop designer.
- Architect.
- Object Manager.
- Integrity Manager.
- Administración.
Cada conjunto de privilegios dispone de una lista de posibles tareas a realizar que podemos habilitar o dejar desmarcadas, de forma que se dispondra de autorizacion para dicha actividad en el caso de que el usuario o grupo tenga marcado el correspondiente flag (o no la tendra en el caso de que no este seleccionado). Con la selección de las diferentes tareas autorizadas en los diferentes grupos de privilegios existentes en Microstrategy definimos el concepto de Rol (grupo de autorizaciones). Microstrategy dispone de un conjunto de roles predefinidos que podemos utilizar en nuestros usuarios o grupos.
Editor de Roles de Seguridad
Una vez tenemos definido un rol, podemos desde el mismo editor indicar los usuarios o grupos que lo poseen. Todas las autorizaciones indicadas en el rol pasaran automaticamente a formar parte del usuario o grupo. De la misma manera, cuando estamos creando un usuario o un grupo, podemos indicar, de cada privilegio, que tareas se autorizan o no al usuario (tal y como vemos en la imagen inferior). En el mismo editor de usuario o grupo podremos ver la autorizaciones que son heredadas por pertenecer a una entidad superior (el usuario pertenece a un grupo, por ejemplo, que ya tiene definidas sus propias autorizaciones, que el usuario también hereda o el usuario pertenece a un rol y también hereda todas las propiedades de este).
Mantenimiento de usuarios
Ademas de las autorizaciones, en el mantenimiento de usuarios se pueden indicar otros aspectos, como son:
- Gestión de contraseñas: criterios para vencimiento de contraseña, frecuencia de vencimiento, bloqueo de una cuenta.
- Filtros de seguridad: es un filtro de seguridad que se aplica a todas las consultas que ejecuta un usuario. Nos puede servir para limitar el acceso a los usuarios a determinados valores de atritubos (por ejemplo, creamos un filtro de seguridad para las diferentes regiones y los asignamos a los delegados de cada zona. De esta forma, solo podrán ver la información de su area, y no podrán ver nada del resto de zonas).
- Grupos: grupos a los que pertence un usuario. Hereda todas las propiedades del grupo (autorizaciones y filtros de seguridad).
- Verificación de identidad: si se va a verificar la c uenta cuentra un usuario de windows, de base de datos, servidor LDAP, etc.
- Microstrategy Distribution Services: datos para la gestión de la distribución de informes (por ejemplo, indicar una cuenta de correo para el usuario, para de esta forma poder enviarle los informes a los que este suscrito).
A nivel de mantenimiento de grupos, disponemos de los mismos elementos, excepto la gestión de contraseñas, verificación de identidad y la configuración de distribución de servicios (no tienen sentido en este ámbito).
Privilegios a nivel de objetos.
Finalmente, Microstrategy nos permite establecer permisos sobre los diferentes objetos (Atributos, indicadores, filtros, etc) a nivel de si este se puede ver, modificar o se tiene control total sobre el. Esto nos puede valer para que determinados objetos no sean modificados por nadie que no sea la persona encargada de su definición o mantenimiento.
Privilegios a nivel de objetos
Con toda la configuración de usuarios, privilegios y permisos, podremos montar (sobre todo pensando en entornos complejos con muchos usuarios), el esquema de autorizaciones apropiado para que cada usuario, según su rol dentro del sistema de BI, solo tenga acceso a las tareas y objetos necesarios para el desarrollo de su trabajo.
Configuración del Portal Web
Antes de continuar, os recomiendo un vistazo al video elaborado por Microstrategy referente a la configuración de Portal Web.
Una vez concluida la instalación del producto, el proceso habrá creado todos los elementos necesarios en el servidor de Internet Information Services (Servidor Web) para poder utilizar el portal Web. Igualmente, en el proceso de configuración visto en anteriores entradas del blog, habremos dejado configurado el Intelligence Server según los parámetros oportunos. El Intelligence server nos llevara a todos los origenes de proyecto (contenedor de proyectos), que tengamos definidos del tipo “3 Niveles” (que se gestionan a través de él). Todos los proyectos definidos en un origen de proyecto de este tipo estarán disponibles en la interfaz Web (en caso contrario, solo estarán disponibles a través de la herramienta Desktop).
Solo nos quedará el paso final de conectar el Intelligence Server con el Web Server, tarea que realizaremos desde las paginas de administración Web:
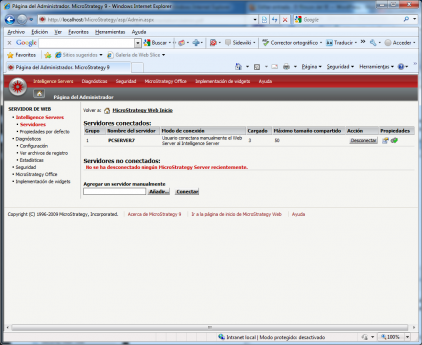
Conexion del servidor Web con el Intelligent Server
El proceso es tan sencillo como indicar el nombre del servidor donde esta el Intelligence Server, y de esta forma establecemos el vínculo entre los dos elementos.
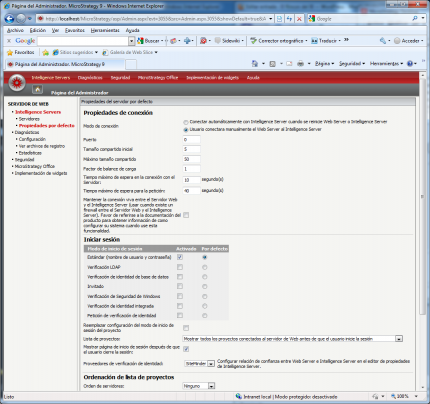
Configuracion parametros Web Server
Ademas podremos establecer otro tipo de propiedades, como la forma de autenticación de los usuarios, menú inicial, ordenación de los proyecto disponibles, etc. Una vez realizada la configuración, ya tenemos disponible también el entorno Web para trabajar con los diferentes elementos de Microstrategy (con el aspecto que vemos en la imagen siguiente):
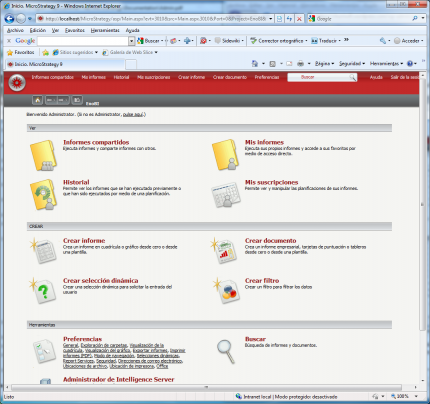
Entorno Web de Microstrategy
El entorno Web por defecto es el que aparece en la imagen. Se podrán personalizar muchisimos aspectos de el en las preferencias de usuario, para hacerlo mas ajustado a las necesidades de cada uno.
Conclusiones
Hemos concluido en esta entrada del blog la serie de artículos que hablan de como configurar los elementos base de nuestro sistema BI utilizando Microstrategy. Antes de proceder a entrar en profundidad a preparar el sistema de reporting para los usuarios con la elaboración de los informes mas comunes, en la próxima entrada del blog detallaremos la configuración de todos los elementos de nuestro proyecto. Veremos a fondo las jerarquías de sistema y de usuario creadas, los indicadores de análisis, los filtros, las selecciones dinámicas y las transformaciones.
Detalle de objetos definidos en el proyecto ENOBI. Atributos, Jerarquias, indicadores, filtros, transformaciones, etc.
Detalle de objetos definidos en el proyecto ENOBI. Atributos, Jerarquias, indicadores, filtros, transformaciones, etc. respinosamilla 25 February, 2010 - 09:50En esta entrada del Blog vamos a ver los elementos que hemos definido en el metadata de Microstrategy, que serán la representación de nuestro modelo lógico dentro del sistema de BI. Ademas, serán los elementos que nos van a permitir construir el resto de componentes que formaran nuestro sistema de análisis. Vamos a hacer un poco de recopilación de todo lo visto hasta ahora referente a nuestro modelo dimensional:
Modelo Lógico del Proyecto ENOBI
El modelo lógico del del proyecto, para que lo tengamos en mente ante toda la definición de elementos en Microstrategy, era el siguiente:
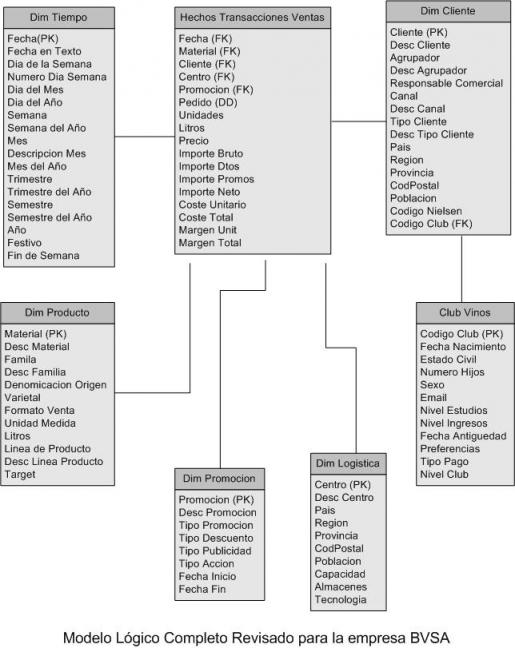
Modelo Físico del Proyecto ENOBI
El esquema físico definitivo del proyecto, con todos los ajustes realizados durante la fase de análisis y la creación de los procesos ETL era el siguiente:
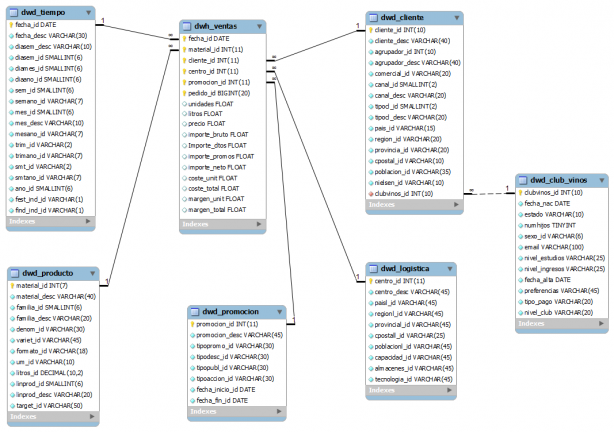
Diseño Fisico Final en MySql
Como ya indicamos, hemos utilizado MySql como motor de base de datos, en la versión 5.1 Community. Os dejo el link al fichero con las sentencias SQL de creación del Datawarehouse, así como al fichero de modelado (utilizando la herramienta de MySql Workbench).
Diseño de hechos, atributos y jerarquía de dimensiones en Microstrategy 9.
Conforme vimos en la correspondiente entrada del blog (14.2. Diseño de hechos, atributos y jerarquia de dimensiones en Microstrategy 9.), en esta fase de la configuración de nuestro BI seleccionabamos las tablas de la base de datos que iban a contener los elementos, y los formalizabamos, en forma de hechos (valores con los que construiremos los indicadores de negocio) y atributos (valores con los que construiremos las dimensiones de análisis y sus jerarquias). En nuestro proyecto, los elementos definidos son los siguientes:
Tablas
De todas las tablas existentes en la base de datos, seleccionamos las que van a contener nuestros hechos e indicadores (son las tablas que vemos en la imagen anterior).
- Hechos: DWH_VENTAS Tabla de Hechos de Venta.
- Dimensiones: DWD_TIEMPO Dimensión tiempo, DWD_PRODUCTO Dimensión Producto, DWD_PROMOCION Dimensión Promociones, DWD_LOGISTICA Dimensión Centros Logísticos, DWD_CLIENTE y DWD_CLUB_VINOS para la Dimensión Cliente (y los datos para análisis del Club de Vinos).
Atributos
La configuración de atributos que formara el módelo dimensional es la siguiente:
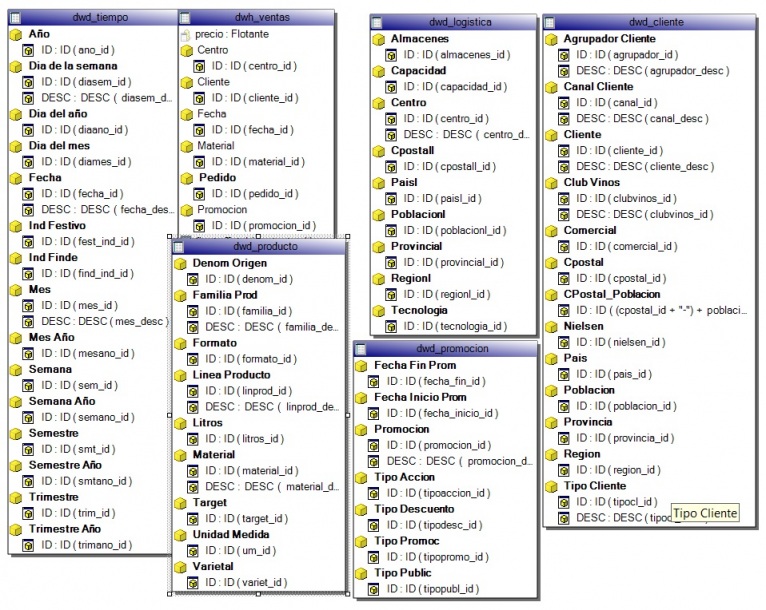
Atributos definidos en el proyecto EnoBI
En la imagen, obtenida, de la herramienta Architect, podeís observar la correlación que hay entre cada tabla de la base de datos, los atributos definidos en cada una de ellas, y los campos de la tabla a los que corresponden. De forma que, para cada atributo, indicamos los campos de la base de datos que le dan valor. Por ejemplo, en la dimensión tiempo tenemos creados los siguientes atributos:
- Año: año de la fecha. Corresponde al campo ano_id de la tabla dwd_tiempo.
- Dia de la semana: corresponde al campo diasem_id para el código numérico y diasem_desc para el campo descripcion (Lunes, Martes, etc), ambos de la tabla dwd_tiempo.
- Dia del año: corresponde al campo diaano_id de la tabla dwd_tiempo.
- Fecha: corresponde al campo fecha_id para el valor de la fecha y fecha_desc para el campo descripción (fecha en formato letra, p.e.: 12 de Enero de 2003).
- Ind Festivo: flag que indica si una fecha es festivo o no. Corresponde al campo fest_ind_id de la tabla dwd_tiempo.
- Ind Finde: flag que indica si una fecha es fin de semana o no. Corresponde al campo find_ind_id de la tabla dwd_tiempo.
- Mes: corresponde al campo mes_id par el código numérico y mes_desc para el campo descripción (Enero, Febrero, Marzo, etc).
- Mes Año: corresponde al campo mesano_id de la tabla dwd_tiempo. Indica el año en la notación AAAA-MM, donde AAAA es el año y MM el mes.
- Semana: corresponde al campo sem_id de la tabla dwd_tiempo. Indica el numero de semana en el año.
- Semana Año: corresponde al campo semano_id de la tabla dwd_tiempo. Indica el numero de semana en la notación AAAA-SS, donde AAAA es el año y SS y la semana.
- Semestre: corresponde al campo smt_id de la tabla dwd_tiempo. Indica el semestre del año, en la notación XS (1S Primer Semestre, 2S Segundo Semestre, etc).
- Semestre Año: corresponde al campo smtano_id de la tabla dwd_tiempo. Indica el semesre en la notación AAAA-SS, donde AAAA es el año y SS el semestre.
- Trimestre: corresponde al campo trim_id de la tabla dwd_tiempo. Indica el trimestre del año, en la notación XT (1T Primer Trimestre, 2T Segundo Trimestre, etc).
- Trimestre Año: corresponde al campo trimano_id de la tabla dwd_tiempo. Indica el trimestre en la notación AAAA-TT, donde AAAA es el año y TT el trimestre.
Para el resto de dimensiones, la correspondencia sería igual, conforme a la definido en la imagen anterior. Podeis observar como hay atributos que se asocian a dos campos (ID y DESC) y otros solo a uno (ID). Esto es debido a que hay atributos que se asocian con un identificador (por ejemplo,el código de cliente o el de un producto) y ese identificador lleva relacionada una descripción (como el nombre de un cliente o la descripción de una familia de producto), que es la que califica realmente al atributo. En cambio, otros atributos se califican directamente con el valor del atributo (por ejemplo, el año), y con ese campo unico ID también tenemos la descripción (DESC). Para otros atributos, como la provincia, región, tipo promoción, también hemos omitido los códigos numéricos y en el campo ID hemos metido las descripciones (esto es cuestión de diseño y seguramente tambíen podriamos haber utilizando una codificación estandar de las que hay definidas, y por tanto, la correspondiente tupla ID DESC).
Igualmente, observar en la dimensión cliente, el atributo compuesto CPostal_Poblacion. Este atributo se forma por la concatenación de dos campos de la tabla dwd_cliente, que son cpostal_id y población_id (cosa que permite Microstrategy ). Esto nos permite definir valores a partir de operaciones con campos de la base de datos.
Hechos
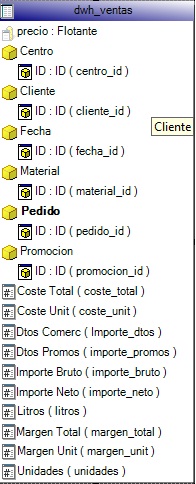
Diseño Hechos
De la misma manera, definimos que hechos vamos a tener en nuestro sistema y a partir de que columnas de la base de datos se van a calcular.
En nuestro caso, nos hemos limitado a crear hechos simples, vinculandolos a un unico campo de la base de datos. Los valores con calculos los definiremos cuando construyamos los indicadores de negocio (que son los valores de análisis que luego incluiremos en nuestros informes y análisis).
Los hechos definidos son los siguientes:
Coste Total: corresponde al campo coste_total de la tabla dwh_ventas. Es el importe total del coste de la mercancia.
Coste Unit: corresponde al campo coste_unit de la tabla dwh_ventas. Es el coste unitario de cada unidad vendida.
Dtos Comerc: corresponde al campo importe_dtos de la tabla dwh_ventas. Es el importe total de los descuentos comerciales aplicados en los pedidos.
Dtos Promos: corresponde al campo importe_promos de la tabla dwh_ventas. Es el importe total de los descuentos promocionales aplicados en los pedidos.
Importe Bruto: corresponde al campo importe_bruto de la tabla dwh_ventas. Es el importe bruto de las ventas de una posición de pedido (sin aplicar ni descuentos comerciales ni descuentos promocionales).
Importe Neto: corresponde al campo importe_neto de la tabla dwh_ventas. Es el importe neto de las ventas de una posición de pedido (después de aplicar todos los descuentos).
Litros: corresponde al campo litros de la tabla dwh_ventas. Es el total de litros vendidos en una posición de pedido.
Margen Total: corresponde al campo margen_total de la tabla dwh_ventas. Es el margen total de una posición de pedido ( ingresos totales – coste total).
Margen Unit: corresponde al campo margen_unit de la tabla dwh_ventas. Es el margen unitario de una posición de pedido.
Unidades: corresponde al campo unidades de la tabla dwh_ventas. Son las unidades de producto vendidas en una posición de pedido.
Observad que hay columnas en la tabla que podiamos haber calculado a partir de los valores de otras columnas (como el importe neto a partir del importe bruto menos los descuentos, el coste unitario y el margen unitario a partir de los costes totales y margen total dividido por el número de unidades, etc.). Hemos decidido en nuestro caso tener ya los calculos guardados en la base de datos para facilitar el análisis en determinados casos y a partir de ellos realizaremos muchos mas cálculos (como veremos cuando definamos los indicadores de nuestro proyecto). Es una elección de diseño esta consideración, aunque se podría haber elegido la de reducir al máximo el número de campos y luego realizar los calculos al ejecutar los corresondientes informes.
Igualmente, podiamos haber creados hechos compuestos, definidos con operaciones aritméticas o funciones sobre una o mas columnas de la tabla.
Jerarquia de atributos.
Las jerarquías, como ya vimos, determinan como se estructuran los diferentes atributos que forman las dimensiones. Tenemos dos jerarquías, la de Sistema, que se crea cuando construimos el módelo dimensional a partir de la información de relaciones padre-hijo entre los atributos y la de usuario, que determina la forma en que podremos realizar la navegación por los atributos cuando estemos ejecutando los informes. Veamos como hemos definido ambas en nuestro proyecto.
Jerarquia de Sistema.
Las jerarquias de Sistema quedarían definidas tal y como observamos en la presentación siguiente:
Jerarquias de Usuario.
En lo referente a las jerarquias de usuario, hemos definido las siguientes (iremos detallando para cada una de las dimensiones). Veremos que las jerarquias de usuario nos permiten saltarnos atributos en la jerarquia de una dimensión para personalizar la navegación según nuestras necesidades.
- Dimensión cliente:
- Agrupador_Cliente: Agrupador Cliente –> Cliente (con punto de entrada en Agrupador Cliente)
- Canal_Cliente: Canal Cliente –> Cliente (con punto de entrada en Canal Cliente).
- Comercial_Cliente: Representante Comercial –> Cliente (con punto de entrada en Representante).
- Nielsen_Cliente: Código Nielsen –> Cliente (con punto de entrada en Código Nielsen).
- Pais_Cliente: Pais –> Region–> Provincia –> Población –> Cliente (con punto de entrada en Pais).
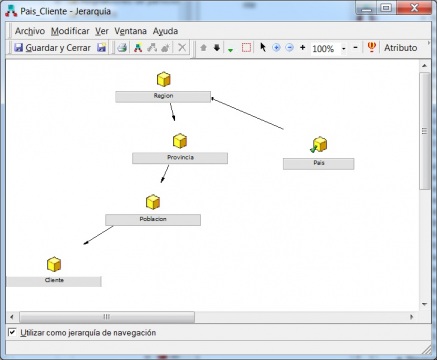
Jerarquia Pais --> Region --> Provincia --> Población --> Cliente
-
- Pais_Poblacion: Pais –> Region–> Provincia –> Población –>Codigo Postal (con punto de entrada en Pais).
- TipoCl_Cliente: Tipo de Cliente –> Cliente (con punto de entrada en Tipo de Cliente).
- Dimensión producto:
- Denominac_Material: Denominación de Origen –> Material.
- Familia_Material: Familia –> Material.
- Formato_Material: Formato de Venta –> Material.
- LinProd_Material: Linea de Producto –> Material.
- Litros_Material: Litros –> Material.
- Target_Material: Target de Destino del Producto –> Material.
- Unidad_Material: Unidad de Medida –> Material.
- Varietal_Material: Variedades de Uva –> Material.
- Dimensión tiempo:
- Año_Mes_Dia: Año –> Mes –> Dia.
- Año_Smt_Mes_Dia: Año –> Semestre del Año –> Mes Año –> Dia.
- Año_Smt_Trim_Mes_Dia: Año –> Semestre del Año –> Trimestre del Año –> Mes Año –> Dia.
- Año_Trim_Mes_Dia: Año –> Trimestre del Año –> Mes Año –> Dia.
Jerarquia Año --> Semestre --> Trimestre --> Mes --> Dia
- DiaSemana_Fecha: Dia de la Semana –> Dia (Fecha).
- Festivo_Dia: Indicador de Festivo –> Dia.
- Finde_Dia: Indicador de Fin de Semana –> Dia.
- Semana_Dia: Semana –> Dia.
- SemanaAño_Dia: Semana del Año –> Dia.
- Dimensión promoción:
- FecIni_Promocion: Fecha de Inicio de la Promoción –> Código de Promoción.
- FecFin_Promocion: Fecha de Fin de la Promoción –> Código de Promoción.
- TipoAccion_Promocion: Tipo de Acción Comercial –> Código de Promoción.
- TipoDto_Promocion: Tipo de Descuento –> Código de Promoción.
- TipoPromo_Promoción: Tipo de Promoción –> Código de Promoción.
- TIpoPublic_Promocion: Tipo de Publicidad –> Código de Promoción.
- Dimensión logística:
- Capacidad_Centro: Capacidad del Centro –> Centro Logístico.
- Pais_Centro: Pais –> Region –> Provincia –> Población –> Centro Logístico.
- Tecnologia_Centro: Tecnologia de Almacenaje –> Centro Logístico.
Igualmente, hemos creado Jerarquias filtradas. Estas jerarquias tienen aplicado un filtro que restringe los valores devueltos. Por ejemplo, dentro de la dimensión cliente, hemos creado una jerarquía con punto de entrada en Pais, que pasa por Region, Provincia, Población y Cliente. En el atributo de entrada (Pais), hemos indicado un filtro con un valor estático que restrige las entradas a solo aquellas del pais España. De esta forma, cuando utilizemos esta jerarquía en los informes o en la navegación, los valores ya van a estar restringidos por ese criterio (cuando un atributo de una jerarquia esta filtrado aparece el simbolo de los 3 circulos de colores en su icono).
Ejemplo de jerarquia Filtrada
En el Explorador de datos de la herramienta Desktop (que nos permite navegar por los atributos utilizando las jerarquias de sistema y las jerarquias de usuario), para esta jerarquía visualizariamos los siguientes valores:
Valores visualizados en jerarquia filtrada
Hemos creado otras jerarquias filtradas, como son:
- Linea Producto–> Material, eliminando los valores de linea de producto correspondientes a la gama alta (ciertos códigos de linea de producto).
- Tipo de Cliente –> Cliente, eliminando determinados tipos de cliente que no queremos considerar en nuestro análisis (ciertos códigos de tipo de cliente).
- Zona Levante –> Cliente, seleccionando el pais España y solo determinadas regiones (Cataluña y Comunidad Valenciana).
- …..
Vemos que tenemos infinitas posibilidades de dejar predefinidas jerarquias que podremos utilizar en cada tipo de análisis concreto que realizemos. Otro aspecto interesante de las jerarquias es que podremos definir uno o varios puntos de entrada (lugar desde el que se puede iniciar la navegación). El punto de entrada puede estar en cualquier nivel dentro de la jerarquía (en el ejemplo de la imagen, el punto de entrada esta en el atribuito Pais).
Diseño de transformaciones en Microstrategy 9.
Las transformaciones son una técnica definida por Microstrategy que nos permite realizar analisis de series temporales. Por ejemplo, la tipica comparación Año Actual / Año Anterior. Las transformaciones se definen sobre un atributo (por ejemplo la fecha, el año) y luego se utilizan a la hora de construir los indicadores. En nuestro ejemplo, hemos creado 3 transformaciones para los siguientes análisis temporales: 15 Dias Atras, Año Anterior, Mes Anterior y Misma Fecha Mes Anterior.
![]()
Transformación Año Anterior
Como podeis ver en el ejemplo, la transformación Año Anterior, en nuestro caso, se aplicaria sobre el Año (restandole 1 al año de los datos), y a la Fecha, restandole 12 meses para ir a la misma fecha del año anterior. Las transformaciones se pueden facilitar guardando en base de datos campos ya calculados en la dimensión tiempo que nos indiquen el periodo temporal de comparación (nos podiamos haber guardado el año anterior, el mes anterior, fecha de comparación del año anterior, etc), aunque tambien podemos calcular los valores, como en nuestro caso.
El uso de transformaciones esta limitado a los atributos por los que estemos analizando la información, pero para determinados informes nos proporciona una gran potencia de análisis.
Diseño de indicadores, Filtros y Selecciones Dinámicas.
Según vimos en la correspondiente entrada del blog (14.3. Diseño de Indicadores, Filtros y Selecciones Dinámicas en Microstrategy 9.), los indicadores, filtros y selecciones dinámicas son el resto de elementos que nos permitiran empezar a trabajar con nuestro sistema de Inteligencia de Negocio. Los elemenos que hemos definido en nuestro proyecto son los siguientes:
Diseño de indicadores.
Los indicadores de análisis que hemos construido en nuestro sistema para poder utilizar dentro de los informes y documentos son los siguientes:
- Coste_Total: coste total de las ventas. Se calcula con la funcion Sum sobre el hecho Coste_Total.
- Coste_Total%: porcentaje de coste de las ventas. Se calcula con la formula Coste_total * 100 / Importe_Neto, utilizando los indicadores correspondientes.
- Coste_Unit: es el coste unitario de las ventas. Se calcula con la formula Coste_Total / Unidades, utilizando los indicadores correspondientes.
- Dto_Comerc: importe de los descuentos comerciales aplicados en las ventas. Se calcula con la funcion Sum sobre el hecho Dtos_Comerc.
- Dto_Comerc%: porcentaje de descuento comercial aplicado. Se calcula con la formula Dto_Comerc * 100 / Importe Bruto, utilizando los indicadores correspondientes.
- Dto_Promos: importe de los descuentos promocionales aplicados en las ventas. Se calcula con la funcion Sum sobre el hecho Dtos_Promos.
- Dto_Promos%: porcentaje de descuento promocional aplicado. Se calcula con la formula Dto_Promos * 100 / Importe Bruto, utilizando los indicadores correspondientes.
- Dto_Total: suma total de descuentos aplicados (tanto comerciales como promocionales). Se calcula como la suma de los indicadores Dto_Comerc y Dto_Promos.
- Dto_Total%: porcentaje total de descuento aplicado. Formula ((Dto_Total * 100) / Importe Bruto), utilizando los correspondientes indicadores.
- Dto_Total_Unit: porcentaje de descuento total aplicado. Se calcula con la formula ([Dto_Total] / Unidades) sobre los correspondientes indicadores.
- Importe_Bruto: importe bruto de la venta. Se calcula con la funcion Sum sobre el hecho Importe_Bruto.
- Importe_Neto: importe neto de la venta. Se calcula con la funcion Sum sobre el hecho Importe_Neto.
- Litros: numero de litros vendidos. Se calcula con la funcion Sum sobre el hecho Litros.
- Margen_Total: margen total en la venta. Se calcula con la funcion Sum sobre el hecho Margen_Total.
- Margen_Total%: porcentaje de margen total sobre el importe de venta. Se calcula con los indicadores, utilizando la formula: (([Margen_Total] * 100) / [Importe Neto]).
- Margen_Unit: margen de cada unidad vendida. Se calcula con los indicadores, con la formula ([Margen_Total] / Unidades).
- Precio_Bruto: precio bruto de venta de cada unidad. Se calcula con los indicadores, con la formula ([Importe Bruto] / Unidades).
- Precio_Neto: precio neto de venta de cada unidad (despues de descuentos). Se calcula con los indicadores, con la formula ([Importe Neto] / Unidades).
- Unidades: numero de unidades vendidas. Se calcula con la funcion Sum sobre el hecho Unidades.
Editor Indicadores - Definicion del indicador Margen_Total%
Ademas, hemos creado los siguientes indicadores de recuento:
- Recuento Clientes: indicador que nos devuelve el numero de clientes de un análisis. Se calcula con la función Count sobre el atributo Cliente.
- Recuento Materiales: indicador que nos devuelve el numero de materiales de un análisis. Se calcula con la función Count sobre el atributo Material.
- Recuento Pedidos: indicador que nos devuelve el numero de pedidos de un analisis. Se calculo con la función Count sobre el atributo Pedido.
Y utilizando la transformación Año Anterior, los siguiente indicadores para utilizar en las series temporales:
- Importe Bruto AANT: similar al indicador Importe Bruto, pero aplicandole la transformación Año Anterior.
- Importe Neto AANT: similar al indicador Importe Neto, pero aplicandole la transformación Año Anterior.
- Margen Total AANT: similar al indicador Margen Total, pero aplicandole la transformación Año Anterior.
Este es un set de indicadores sencillos. Microstrategy nos permite, partiendo de los hechos definidos, los indicadores descritos aquí y multiples operadores y funciones realizar la definición de indicadores mucho mas complejos que nos permitirán cubrir los requerimientos de información (tales como valores máximos y mínimos, contadores, funciones estadísticas sobre un conjunto de valores como media, varianza, desviación estandar, etc, etc).
Diseño de Filtros.
Son los últimos elementos que nos faltan por definir, y son los que nos van a permitir establecer restricciones en los diferentes objetos de nuestro sistema, como son a nivel de jerarquías (jerarquias filtradas), indicadores o a la hora de ejecutar los informes y analisis (criterios de selección, selección de objetos a incluir en un informe, etc).
Algunos de los filtros estáticos (con valores fijos) creados en nuestro sistema son los siguientes:
- Año_2007, Año_2008: filtro sobre los valores del atributo Año, indicando un valor en concreto (2007, 2008, …).
- Pais_España: filtro sobre los valores del atributo Pais, seleccionando el valor España.
- LineaProducto_SinGamaAlta: filtro sobre los valores del atributo Linea Producto excluyendo determinados valores.
- TipoCl_SinVentaDirecta: filtro sobre los valores del atributo Tipo Cliente, excluyendo los clientes de venta directa.
- ES_TipoCL_No_VentaDirecta: filtro sobre el atributo pais con el valor España y a la vez sobre el atributo Tipo Cliente, excluyendo los de venta directa.
- ZONA_CENTRO, ZONA_ISLAS, ZONA_NORTE, ZONA_LEVANTE, ZONA_SUR: filtros sobre el atributo Región, seleccionando una lista de valores (las regiones que incluyen cada zona, tal y como vemos en la imagen posterior).
- …..
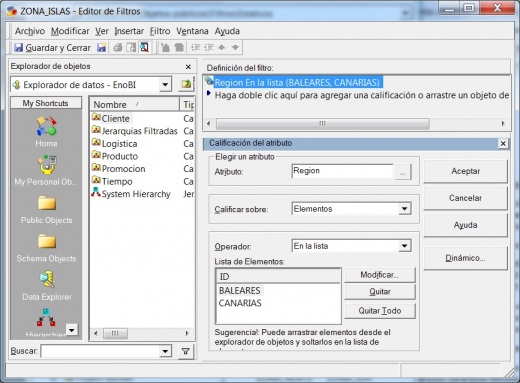
Filtro Estático ZONA_ISLAS
Algunos de los filtros dinámicos definidos (valores que se seleccionan o indican en tiempo de ejecución):
- Año: filtro dinamico sobre los valores del atributo Año, nos permite seleccionar entre la lista de años definidos en la dimensión tiempo.
- Periodo: filtro dinámico que nos permite definir un rango de fechas (fecha desde / fecha hasta), sobre el atributo fecha de la dimensión tiempo.
- Dim_Cliente: filtro dinámico que nos permite elegir sobre que atributo de la dimensión cliente definir el filtrado, y a continuación, para ese atributo, indicar los valores de restricción (pudiendo seleccionar de la lista de valores de dicho atributo).
- Dim_Tiempo: idem del anterior sobre todos los atributos de la dimensión tiempo.
- ……
Selecciones Dinámicas
Las selecciones dinámicas van intimamente ligadas a los filtros dinámicos (de hecho, utilizan características de estas). Ademas, se pueden definir selecciones dinámicas para otros cometidos, como son:
- Selección_Atributo_Tiempo: nos permite vincularla a un informe, de forma que al ejecutarlo podremos seleccionar que atributos queremos visualizar (y por los que queremos desglosar la información) en el informe, todo ello en tiempo de ejecución. El usuario se podrá construir su filas y columnas de forma dinámica.
- Selección_Indicadores_Informe: nos permite vincularla a un informe, de forma que al ejecutarlo podremos seleccionar de una lista los indicadores que queremos incluir en este (que serán los que se calculen y aparezcan en el informe), igualmente en tiempo de ejecución.
- Seleccion_Filtro_Zona: nos permite seleccionar de una lista de filtros predefinidos. Asociado a un informe, cuando lo ejecutemos nos aparecera la lista de filtros y el que seleccionemos se aplicara para la construcción de los datos (por ejemplo, para seleccionar la zona geográfica para la que queremos realizar el análisis). En el ejemplo, se seleccionan filtros estáticos que ya tienen los valores de las regiones a considerar, aunque también podrian ser filtros dinámicos que pedirian la lista de valores a considerar.
- Selección_Todas_Jerarquias: aplicada a un informe, nos permite seleccionar, de todas las jerarquias definidas en el sistema, los atributos correspondientes, y para cada uno de estos atributos, las correspondientes restricciones de filtrado de información (pudiendo seleccionar uno o varios atributos con los correspondientes valores para cada uno de ellos).
- ….
Editor Selecciones Dinamicas - Lista de Indicadores a elegir
Igualmente, podríamos haber definido todo tipo de selecciones dinámicas para filtrar el valor de un indicador o de un atributo, y luego utilizarlas indistintamente en la definición de filtros simples o compuestos, o bien directamente en los informes (una selección dinámica también se puede considerar en este caso un filtro).
Conclusiones
Con la explicación y enumeración de los elementos definidos en nuestro proyecto concluimos la fase de modelado y diseño. A partir de ahora, intentaremos explotar nuestro DW con las diferentes herramientas de las que dispone Microstrategy 9. Empezaremos con el diseño de informes y las amplias posibilidades que este ofrece.
Hemos pasado de la definición teórica de los elementos del sistema Microstrategy a la fase práctica de ver como los hemos utilizado y definido nosotros para nuestro proyecto, viendo de una manera sencilla (se puede profundizar muchisimo mas) las posibilidades y propiedades que nos ofrece cada uno, y la cantidad de cosas que podemos construir con ellos para las siguientes fases del proyecto.
Reporting en Microstrategy 9 (I).
Reporting en Microstrategy 9 (I). respinosamilla 25 February, 2010 - 09:50Durante los ultimos días he estado validando las funcionalidades de Microstrategy 9 en lo referente al reporting, intentando ir de los aspectos mas generales y sencillos hasta los mas especificos y complejos, intentando pasar por todos los componentes y desarrollando ejemplos de análisis basados en el módelo dimensional que hemos visto en las entradas anterior del blog.
Antes de empezar, os recomiendo el video publicado por Microstrategy para familiarizaros con el entorno de trabajo ( visualizar aquí ).
Como consideración inicial, indicar que el reporting en Microstrategy esta algo limitado a nivel de diseño, pues siempre trabajaremos con tablas tabuladas donde podremos ir colocando los diferentes elementos del informe (atributos, indicadores, filtros, selecciones dinamicas, grupos personalizados, etc). Ademas de los informes, podremos construir lo que en Microstrategy se llama Documento, el cual nos permitira incluir varios informes y objetos que diseñemos nosotros mismos (se utilizaran por ejemplo para construir los cuadros de mando, tableros interactivos, etc). Esta parte la veremos cuando veamos el diseño de cuadros de mando.
En la imagen podeis observar el editor de informes. Es el lugar donde se realiza el diseño de los informes. Podemos observar 5 secciones diferenciadas, que son:
Editor Informes en Microstrategy 9
- Objetos de informe: en la parte superior izquierda. En esa sección visualizaremos todos los elementos que hemos incluido en la tabla del informe. Nos apareceran los atributos, indicadores, campos calculados, etc., que hemos insertado en el diseño del informe. Desde aquí se pueden modificar sus características. Por ejemplo, podremos cambiar el nombre con el que aparece el elemento en el informe, su representación, si aparece en el informe o esta oculto, etc.
- Detalles de informes: en la parte superior derecha. Muestra información del informe en el momento de ejecutar.
- Filtro de informe: en la parte superior derecha. Es el lugar donde asociamos al informe los filtros o selecciones dinámicas que se van a utilizar para restringir la información devuelta.
- Explorador de objetos: en la parte inferior izquierda. Es el arbol desde el cual podemos navegar por los diferentes elementos definidos en el metadata de Microstrategy: Jerarquias de usuario, atributos, indicadores, etc. Desde esta ventana podemos arrastrar a la sección de filtros o a la plantilla del informe para incluir el elemento seleccionado en el informe. Es contextual y solo deja insertar en cada lugar los elementos que se pueden utilizar
- Vista de Informe: es el lugar donde diseñamos el layout del informe. Realmente estamos creando una plantilla que se asocia al informe. Es una tabla cruzada donde vamos incluyendo los elementos por los que se desglosara la información.
Construcción de Informes Simples
Vamos a empezar diseñando un informe sencillo. Queremos analizar los importes netos de venta y unidades por año y región. Ademas, queremos que se puede seleccionar el año/s de análisis. Para ello, abrimos el editor de informes y seleccionamos, en el explorador de objetos, los siguientes elementos:
- Filtro: navegamos por el explorador de objetos, en la carpeta objetos públicos, filtros y seleccionamos el que ya teniamos definido para seleccionar el año, arrastrandolo a la sección Filtro de informe.
Ventas por año y región
- Atributos e indicadores: a continuación, seleccionamos desde el explorador de objetos los atributos Año y Región y lo llevamos a las filas de la plantilla del informe. Finalmente, desde la carpeta de indicadores, realizamos la misma operación con los indicadores Importe Neto y Unidades, posicionandolos en las columnas de la tabla.
A continuación cambiamos el estilo del informe uno de los disponibles (en concreto el tema Pasteles). Veremos mas adelante que los estilos se pueden personalizar a todos los niveles (colores, tipos de letra, fuente, color de celda, color de subtotales, etc.). Con unos cuantos movimientos de ratón hemos construido nuestro primer informe de análisis. Lo ejecutamos y obtenemos el siguiente resultado:
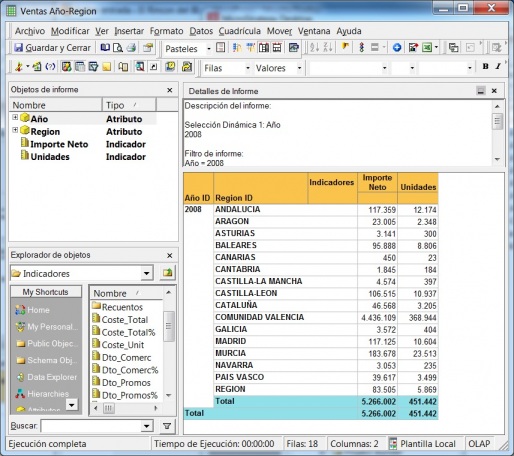
Ventas por Año-Region
Observar el resultado. Nos aparecen todas las ventas del año, desglosadas por región, con el detalle de importes y unidades. En la sección Detalles de informe, nos aparecen los criterios con los que se ha ejecutado el informe (filtros). En ese lugar tendremos la referencia de que restricciones se estan aplicando al informe. Las ventanas Objeto de informe y Explorador de objetos siguén apareciendo por si queremos ir realizando “sobre la marcha” modificaciones en el informe (añadiendo nuevos atributos o indicadores, cambiando descripciones, etc). Estas ventanas se pueden ocultar sin ningún problema (pues habrá usuarios que no tendrán que realizar este tipo de tareas).
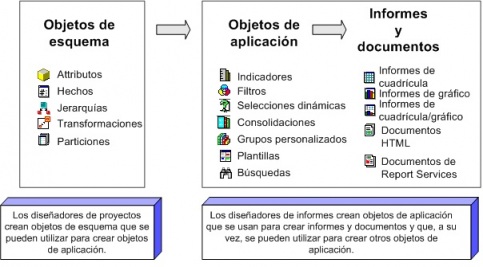
Objetos de Microstrategy
Partiendo de este informe simple, vamos a ir viendo las diferentes propiedades que podemos modificar para ir personalizando su aspecto y características conforme a nuestras necesidades.
Formateo de los Informes. Personalizar filas, columnas, titulos, fuentes, colores.

Microstrategy dispone de unos 20 estilos de informe predefinidos, tal y como observamos en la imagen.
Cada estilo tiene su propia configuración de colores, tipos de letra, tramas de las cuadriculas, etc. Ademas, las modificaciones que realizemos sobre el diseño las podemos guardar creando nuestros propios estilos personalizados.
Algunas de las cosas que podemos configurar en el formato de nuestros informes serán:
- Formato de los titulos de filas y columnas: fuente, tamaño de letra, efectos sobre la letra (negrita, cursiva, subrayado), color de la letra, color de la casilla, bordes, alineación.
- Formato de valores (indicadores): fuente, tamaño, efectos sobre la letra, formato de los números, color de la letra, color de la casilla, bordes, alineación.
- Visualización de los atributos: cuando en la casilla que estemos personalizando tengamos un atríbuto, podemos seleccionar que valor se mostrará de el (ID, DESC o ambos). Por ejemplo, si estamos con el atributo material, podemos ver solo el ID (será el código del material), o solo el DESC (será la descripción del material) o ambos y en el orden que deseemos.
- Formato de subtotales: de la misma manera, podremos cambiar las propiedades que hemos visto anteriormente para los subtotales de un atributo (tanto a nivel de encabezado como de valores).
Con esta parametrización a nivel de los elementos de un informe, le podremos dar el aspecto deseado para remarcar determinados valores o para hacerlos mas intuitivos al usuario. Para nuestro informe de ejemplo, hemos realizado varios cambios. Hemos incluido el indicador %Margen y le hemos cambiado el color de visualización y el formato a su valores (color de la letra azul y en negrita) para destacarlos sobre el resto de las columnas. Igualmente, hemos cambiado los colores de las celdas de subtotales y totales generales para diferenciarlos según el atributo al que corresponden. El informe modificado tendría el siguiente aspecto:
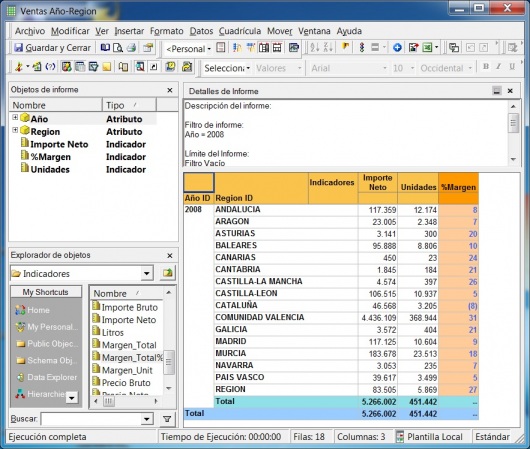
Informe basico con cambio formato
El cambio del formato es tan sencillo como seleccionar la casilla de cabecera del atributo o el indicador para el cual queremos cambiar el formato, y con el botón derecho nos aparecerá el menú contextual. El cambio de formato lo podemos realizar de la misma manera bien desde el diseño de informes o en tiempo de ejecución, interactuando con el informe que presenta la información. El menú contextual es el siguiente:
Menu contextual para cambio de formato
En el ejemplo, hemos seleccionado la casilla de cabecera del atributo Año. Podremos cambiar el formato del encabezado (Año encabezados), de los valores (Año valores), encabezado de los subtotales del atributo (casilla Total) y el formato de los valores de subtotales. Vemos que desde el mismo menú contextual podremos cambiar la Representación del Atributo, quitarlo de la cuadrícula o del informe, bloquear el objeto para que se quede fijo cuando tengamos informes con muchas filas o columnas o incluso acceder a la modificación de atributos, indicadores, etc desde este lugar (se requeriran los oportunos permisos. Los cambios en objetos del esquema desde esta opción no se resfrescarán hasta que no se vuelva a ejecutar el informe).
Para los indicadores, también podremos establecer formateo a nivel de categoría (Numero, Fracción, notación cientifica, porcentaje), número de decimales, separación de miles, formateo personalizado, etc (mas o menos las mismas opciones de formateo que en la tipica aplicación de Hoja de Cálculo).
Definición de Umbrales. Tipos de umbrales.
Observando el informe anterior, vemos que hemos remarcado los valores del indicador %Margen sobre el resto de indicadores del informe. En este informe nos interesa centrarnos en el análisis de este indicador de negocio. Para centrarlos en analizar los valores de una forma más ágil, vamos a utilizar otra característica de los informes de Microstrategy, que son los umbrales. Los umbrales nos permiten establecer un formato personalizado a los indicadores según los valores de estos. Con los umbrales podemos destacar determinados valores según nos interese, de forma que el usuario de los informes vaya al “grano” cuando este analizando la información visualizada, de forma que haya algo que le llame la atención directamente y le avise (valores de rentabilidad negativa, por ejemplo). Podría ser una forma de establecer alarmas en los datos.
Tenemos 4 tipos de umbrales, que son:
- Formato: modificamos el formato de los valores según las condiciones indicadas. Podemos cambiar el tipo de letra, el color, el resaltado, el fondo, etc, para remarcar los valores que cumplan unos determinados criterios.
- Remplazar texto: podemos cambiar el valor por un determinado texto que nos avise de algo (por ejemplo, el texto REVISAR para indicar que hay algo erróneo que convendría analizar o el texto EXCEDIDO para indicar que se han superado las ventas presupuestadas en un determinado nivel de análisis).
- Simbolo rápido: sustituimos los valores que cumplan las condiciones por un determinado simbolo, al que también podremos dar un color diferenciado.
- Imagen: sustituimos los valores que cumplan las condiciones por una imagen.
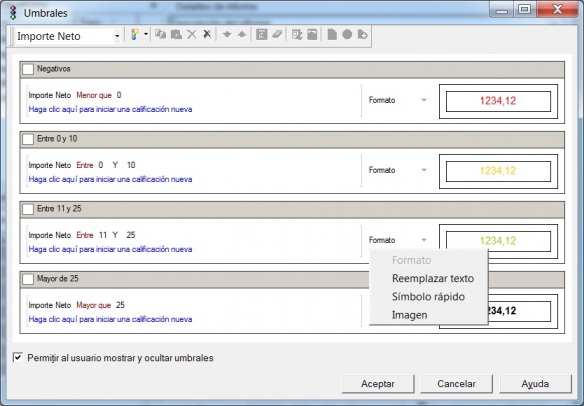
Editor de umbrales
Como veis en la imagen, una vez seleccionado un determinado indicador, seleccionando la opción Umbrales podremos establecer los criterios que determinan cada umbral. En el ejemplo, hemos creado 4 rangos de valores. Para cada rango de valores, hemos determinado un formato diferente para los valores, de forma que los importes negativos de rentabilidad los veremos resaltados en rojo, los importes con rentabilidades bajas (entre 0 y 10) los veremos en amarillo, y asi hasta los valores mayores de 25%, que sacaremos en color negro considerandolos los valores normales.
Aplicando estos valores de umbrales a nuestro informe ejemplo, obtendremos el siguiente resultado:
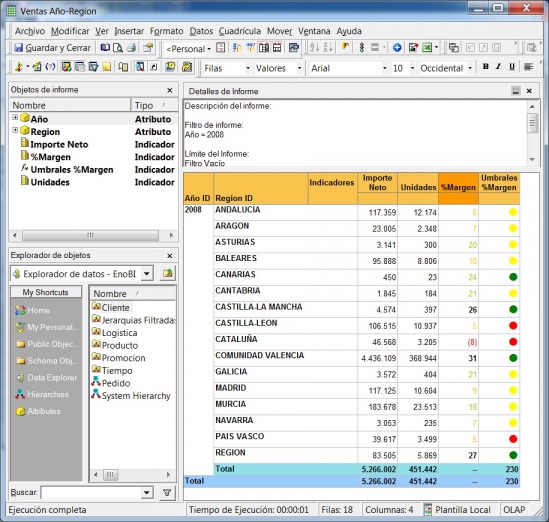
Informe con umbrales del tipo formato y del tipo simbolo
Observad como los valores en rojo nos indican una rentabilidad negativa y son elementos que habrá que estudiar. En el informe he incluido en una nueva columna un umbral utilizando simbolos. También puede ser una forma ágil de llamar la atención sobre un determinado valor.
Los umbrales se pueden establecer a nivel de indicadores, a nivel de indicadores y subtotales o solo a nivel de subtotales.
Ordenación avanzada.
Puede darse el caso que en los informes tengamos muchisima información y nos interese que este ordenada por determinados criterios (para solo analizar valores que consideremos relevantes). Por ejemplo, nos puede interesar analizar las ventas por importe de mayor a menor, o las rentabilidades de menor a mayor (para analizar las mas bajas).
Para esto, Microstrategy dispone del editor de Ordenación Avanzada, que nos permite establecer criterios de ordenación compleja sobre los datos. En nuestro ejemplo, queremos ordenar los datos por rentabilidad de menor a mayor, pero no en general para todos los datos del informe, sino dentro del analisis de cada año que aparezca en el informe.
Ordenación avanzada
Podeis ver como hemos indicado dos criterios de ordenación. En primer lugar, que se ordenen los datos por año de forma ascendente. En segundo lugar, para los datos de cada año, que se orden de forma ascendente según el valor del indicador %Margen. De esta forma, para cada año, tendremos al principio las regiones con margenes mas bajos, que son las que nos interesará analizar. El informe quedaría así:
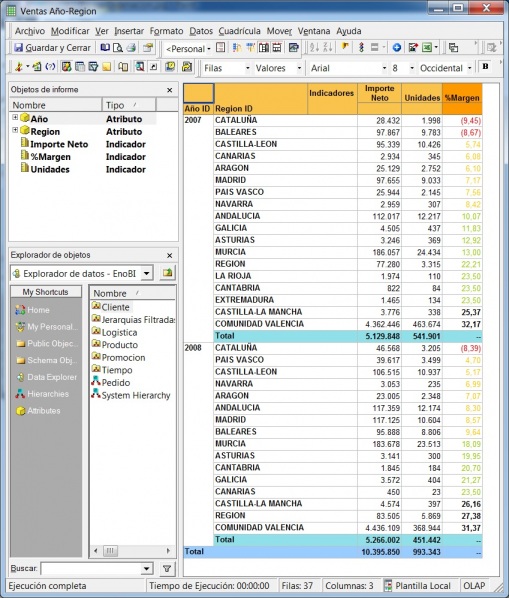
Informe con ordenación por Año y Margen
La ordenación avanzada se puede establecer tanto a nivel de filas (como en el ejemplo), a nivel de columnas, o a nivel de paginación. Veremos mas adelante en que consiste la paginación.
Filtros en indicadores. N Valores.
También puede darse el caso de que en los informes se nos presente gran cantidad de información irrelevante (por ejemplo, clientes con ventas muy bajas en un analisis detallado por cliente) y nos interese filtrar sobre los valores recuperados de la base de datos. Este filtrado sería a posteriori, y se produciria en el momento en el que el motor analítico va a mostrar la información.
Podremos tener dos tipos de filtrado sobre un indicador:
- N valores: donde podremos seleccionar, por ejemplo, los N primeros valores, los N ultimos valores, excluir los N primeros valores o excluir los N ultimos valores de la visualización. Tambien podremos indicar, dentro del ranking, los valores que estan o no estan en un determinado rango (por ejemplo, los valores entre la posición 10 y 30 del ranking), o un valor determinado del ranking (el doceavo en el ranking).
- Condición: igualmente, podremos establecer un filtrado indicando una condición que deberan de cumplir los valores del indicador (en el caso de que no la cumplan no se mostrarán).
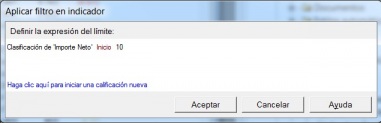
Filtro Indicador (10 primeros valores de ventas)
Para probar el filtro sobre un indicador, hemos modificado nuestro informe de ejemplo sustituyendo el atributo región por el de provincia. Igualmente, hemos ordenado los datos obtenidos de forma descendente por la columna Importe Neto de Ventas. En este informe nos aparecen muchos datos y queremos quedarnos solo con los 10 primero valores. Aplicando el filtro que hemos visto anteriormente, el informe resultante quedaría:
Informe de Ventas por Año y Provinca - 10 Primeros Importes
Hay que tener en cuenta que al establecer el filtrado, los valores de subtotales se alteran y reflejan solo la suma de los valores que se muestran en pantalla.
Paginación.
Para explicar el concepto de paginación, vamos a modificar nuestro informe ejemplo y vamos a sustituir el atributo Año por el atributo Región. Queremos analizar las ventas por Región, y dentro de cada región, ver el detalle de cada una de las provincias. El informe modificado quedaría así:
Informe de Ventas por Región y Provincia
Para poder facilitar el análisis, queremos ver solo una región en pantalla y poder ir moviendonos por las diferentes regiones. Para esto, Microstrategy nos proporciona la funcionalidad del paginado. Uno o varios de los atributos se sacan de la cuadricula y aparecen en la sección de Paginación. En esa seccion el atributo seleccionado aparece como un menú desplegable con los diferentes valores que tiene y que se aplicaran en el informe como un filtro dinámico que podremos ir cambiando para ver los diferentes valores. El mismo informe con paginación en el atributo Región sería el siguiente:
Ventas por Region y Provincia - con paginación
Se pueden incluir todos los atributos de paginado que queramos dentro de los informes. Es tan facil como arrastrarlos a la sección de paginado o bien desde el menu contextual, al pulsar sobre la casilla del atributo, seleccionar la opción Mover –> A Páginas.
Definición subtotales y totales. Tipos de totalizacion.
Vamos a crear un nuevo informe para explicar las posibilidades de totalización que proporciona Microstrategy. Construiremos un report donde veremos la información por el atributo Año, a continuación por Trimestre, y finalmente por el Comercial de Ventas asignado a los clientes. Como indicadores de negocio, analizaremos el importe neto de ventas, las unidades vendidas, el Margen y el número de pedidos de cada uno de ellos. El informe quedaría algo así:
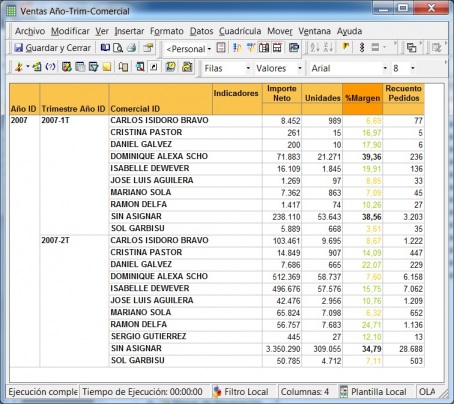
Ventas por Año, Trimestre y Comercial (sin Totales)
En un informe como este, donde no tenemos totalización, podremos añadir un total general al final del informe, así como subtotales para incluir en cada nivel de detalle de la información. Ademas del subtotal, que es una suma de valores, Microstrategy nos proporciona otras funciones de totalización como son Cantidad, Promedio, Minimo, Máximo, Producto, Mediana, Moda, Desviación Estandar, Varianza y Media Geométrica.
Para incluir un total general, seleccionaremos la opción Datos –> Totales Generales y nos aparecera un total general para el informe. Es importante tener en cuenta que podemos tenemos definidos los indicadores (cuando se crean) para que no se puedan realizar subtotales con ellos. Por ejemplo, en nuestro proyecto, el indicador %Margen esta configurado de esta manera, pues no tiene sentido la suma de valores individuales de porcentajes (es un dato que no nos dice nada, es mas, nos puede llevar a error).
Ademas, podemos incluir los subtotales indicando la opción de menú Datos –> Subtotales. Nos aparece el editor de subtotales donde podemos seleccionar que tipo de subtotal queremos utilizar,y el lugar dentro de la tabla donde mostraremos los subtotales por fila, columna o pagina. Observad el ejemplo donde hemos metido un subtotal al final de cada nivel y un total general. Ademas, hemos seleccionado el Minimo y Maximo de cada columna, que nos indicara los valores minimos y maximos de cada indicador en cada nivel. Puede resultar util para tener identificados determinados valores o cálculos de una forma rápida.
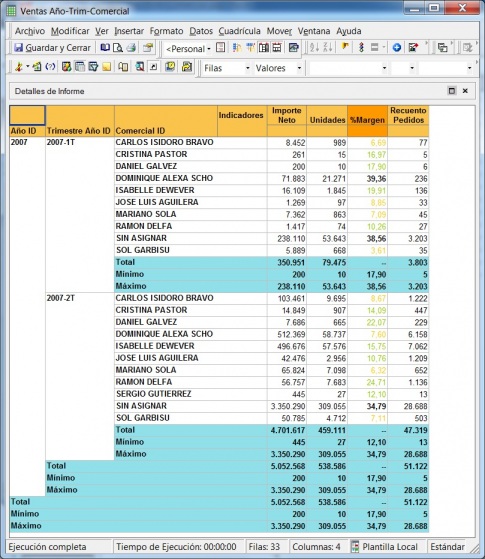
Ventas por Año, Trimestre y Comercial con Subtotales
Ademas, disponemos de unos subtotales avanzados que nos permiten realizar otro tipo de totalizaciones mas fuera de lo habitual. Por ejemplo, podemos indicar por que atributo queremos obtener un subtotal global y mostrarlo al final del informe. O establecer diferentes niveles de agrupación por atributos para los subtotales. En nuestro ejemplo, el subtotal global por el atributo comercial quedaría así:
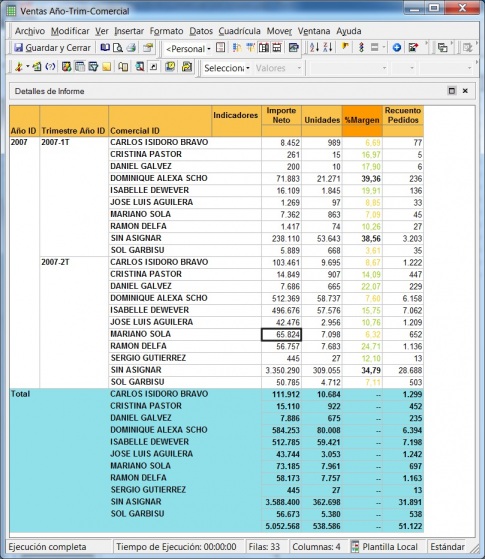
Ventas por Año, Trimestre y Comercial con Total por Comercial
Podremos definir tantos subtotales como deseemos para incluir la sumarización deseada por el atributo deseado y en el lugar deseado.
Visualización Jerarquica de Resultados.
Cuando tenemos mucha información en pantalla, con muchos niveles de desglose, Microstrategy nos permite organizar la visualización de la información de forma jerárquica (lo que llaman Mostrar resultados indentados). Es otra técnica diferente a la de la paginación que ya vimos anteriormente. Para verlo mas en detalle, vamos a construirnos un informe que incluye para cada año, las lineas de producto y el detalle de los materiales de cada linea de producto, con los indicadores de analisis vistos anteriormente. Al ejecutar el informe, vemos que tienes mas 400 lineas y es dificil moverse por la información.
Para cambiar la visualización jerárquica, seleccionamos la opción de menú Cuadrícula –> Mostrar resultados indentandos, y cambia el aspecto del informe al siguiente:
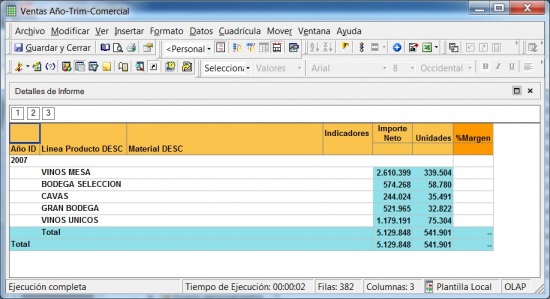
Informe con resultados indentados
Observar que en la parte superior de la cuadricula hay 3 cuadros (con los valores 1, 2 y 3). En nuestro caso, tenemos seleccionado el valor 2, y estamos viendo la información desglosada hasta el nivel de Linea de Producto. Si seleccionaramos el valor 3, veriamos ademas toda la información de los materiales. Y si estuvieramos en el nivel 1, solo veriamos la información desglosada por año.
Puede ser una forma util de presentar la información en un nivel no muy desglosado para ver los datos de forma mas clara y cambiar de nivel jerarquico en el caso de querer profundizar mas en determinados aspectos.
Reporting en Microstrategy 9 (II).
Reporting en Microstrategy 9 (II). respinosamilla 25 February, 2010 - 09:50Inserción de calculos. Porcentajes sobre Total y Transformaciones.
Microstrategy nos permite incluir en el informe cálculos que se realizan sobre los valores de las columnas devueltas al ejecutar el análisis. Es decir, se realizan después de la consulta sobre la base de datos, en el momento en el que el motor análitico va a visualizar los resultados. Esto nos puede ser util para incluir nuestros propios calculos que no tienen porque tener un indicador asociado y definido en el metadata.
Veamos un ejemplo:
Partiendo del informe de ventas por Año, Trimestre y Target (segmento destino del producto), en el cual se visualizan el importe neto de ventas, las unidades, el margen y el numero de pedidos contabilizados en el sistema, queremos obtener el numero de unidades medidas por pedido y el importe medio de cada pedido. El informe original es el siguiente:
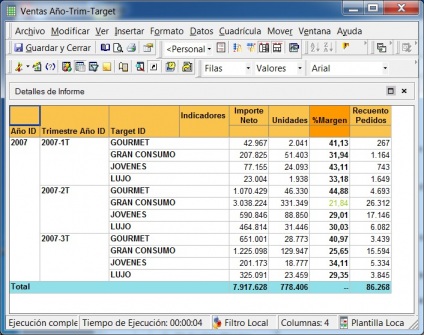
Ventas por Año, Trimestre y Target de Producto
Para añadir una columna calculada, seleccionaremos la opción Insertar –> Calculo. Nos aparecera el editor de indicadores donde podremos definir la formula de calculo de la nueva columna. En el editor nos aparecen unica y exclusivamente los indicadores del informe y los atributos (también los podremos utilizar en el calculo, por ejemplo, para obtener un recuento de sus valores).
Editor columnas calculadas
En nuestro ejemplo, añadimos tres nuevas columnas. Una de ellas, la Media de Unidades por Pedido fruto de la división del total de unidades y el numero de pedidos. La otra, la Media de Ingresos por Pedido, que se calcula dividiendo el Importe Neto por el número de pedidos. Finalmente, añadimos el calculo del Margen Porcentual, con el objetivo de ver como se comportan los totalizadores de las columnas calculadas (el indicador Margen% ya lo tenemos definido en nuestro catalogo de indicadores). El informe con los nuevos calculos sería el siguiente:
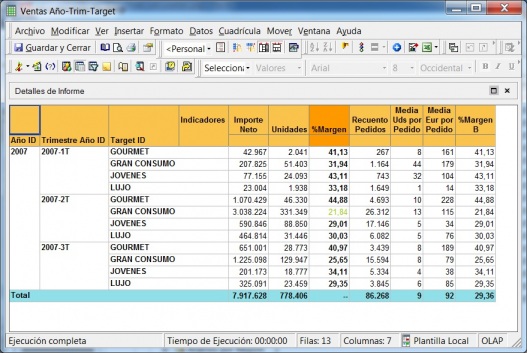
Ventas por Año, Trimestre y Target con columnas calculadas
Podemos ver como aparecen las nuevas columnas en el informe. A diferencia de los indicadores, los campos de totalización para estas columnas son calculados también en la sección de totales y subtotales. Por ejemplo, para la columna %MargenB, se va calculado su resultado en cada fila. A nivel de subtotal, no se suman las diferentes cantidades de cada linea, sino que se recalcula con los importes de los subtotales y totales de los campos implicados en el cálculo. Esto nos puede ser útil en determinados casos.
Ademas de los campos calculados, Microstrategy nos permite insertar otros campos con utilidad miscelanea, que pueden ser:
- Porcentaje sobre total: para un indicador determinado, podemos añadir un nuevo indicador calculado donde aparezca el peso de su valor con respecto al total general o con respecto a los totales en un determinado nivel de desglose del informe. En nuestro ejemplo, podriamos haber incluido el Porcentaje sobre Total a nivel de Trimestre (en ese caso, para cada Target, nos dara el peso del Importe Neto sobre el total de cada Trimestre).
- Transformaciones: podemos seleccionar cualquier indicador de los existentes en el informe y aplicarles una de las transformaciones que tengamos definidas, creando un nuevo indicador calculado. Por ejemplo, a la columna Importe Neto, le podriamos haber aplicado la transformación Año Anterior, y estamos creando un nuevo indicador que incluye los importes netos del año anterior al de analisis actual. Con esto, podemos realizar, como ya vimos, análisis de series temporales.
- Orden: nos permite definir una columna donde aparece el número de orden de un valor respecto al total o respecto a los diferentes niveles de desglose del informe. El orden se puede referir a nivel ascendente (de menor o mayor) o descendente (de mayor a menor). En nuestro ejemplo, podriamos haber añadido una columna de Orden a nivel de Trimestre, para que nos indique el ranking de mayor a menor importe de ventas o de rentabilidad.
Como ejemplo, vamos a añadir algún campo calculado de este tipo a nuestro informe de ejemplo:
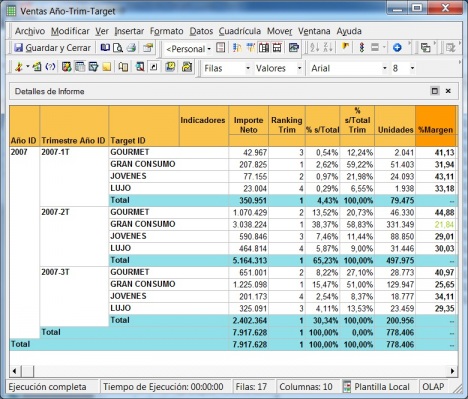
Informe con Indicadores % sobre Total y Orden
En nuestro informe ejemplo hemos añadido tres columnas mas:
- Ranking Trim: el valor que aparece en esta columna nos indica el lugar que ocupa el importe de ventas de cada Target de Producto a nivel de cada Trimestre, con ordenación descendente.
- %s/ Total: esta columna nos indica el porcentaje que representa el Importe Neto sobre el total general del informe.
- %s/ Total Trim: esta columna nos indica el porcentaje que representa el Importe Neto sobre el total general de cada Trimestre.
Vemos que estos campos calculados nos pueden ser utiles para añadir información estadística y ordenaciones que hagan mas claros y faciles de analizar los resultados.
Formatos de exportación de Informes: PDF, Excel, HTML, Word, Access, Texto. Envio por Email.
Una vez tenemos calculado un informe, podremos exportar sus resultados en diferentes formatos. Esto nos va a permitir, por ejemplo, pasar la información a terceras personas y en el formato preciso según el tipo de acción que se tenga que realizar sobre los datos. Para realizar la exportación, desde el menú Datos –> Exportar A, y a continuación seleccionaremos el tipo de formato de exportación.
Por ejemplo, podremos crear un documento estático del tipo PDF o HTML que contenga los resultados. Tambien podremos sacar los datos a un fichero de texto o a documentos modificables en formato Excel, Word, Access. Se pueden configurar parametros de la exportación (como si se abrirá la aplicación correspondiente despues de la exportación, si queremos guardarlo en un determinado archivo y carpeta, si queremos ejecutar macros en el documento antes o despues de la exportación, etc).
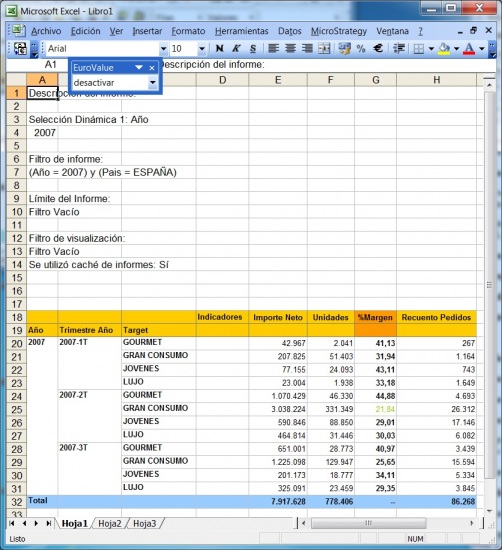
Exportacion a Excel de los resultados de un informe
Microstrategy tiene una gran integración con la suite Office y las exportaciones estan bastante conseguidas. Por ejemplo, al exportar el mismo resultado de informe del ejemplo a Word, me aparece un texto con las características de ejecución del informe y a continuación una tabla de Word con los resultados del informe (el crosstab del informe replicado en la tabla). Observad en el ejemplo como se han pasado todos los atributos del informe a Excel, incluyendo los formatos y umbrales.
Igualmente, Microstrategy nos permite enviar los resultados de un informe por Correo Electrónico, utilizando uno de los formatos indicados anteriormente. Se genera un correo electrónico que llevará anexo el correspondiente documento en el formato seleccionado (se requiere tener instalado el programa Outlook para que funcione correctamente).
Ejecución de Informes desde aplicaciones Office.
Microstrategy 9 incluye el componente Office que instala un complemento dentro la suite Microsoft Office. Este complemento nos permite interactuar directamente desde Word, Excel, Powerpoint, Access o incluso Outlook.El complemento se conecta a nuestro proyecto y nos muestra los diferentes informes a los que tenemos acceso.
Ejecucion de Informes desde Excel
Una vez seleccionado el informe que queremos ejecutar, apareceran los correspondientes filtros o selecciones dinámicas que lleve asociado el informe y se nos mostraran los resultados, una vez ejecutado el informe, dentro de la aplicación Office desde la que estemos trabajando. Desde Excel, podremos repetir la ejecución del informe con los mismos criterios de selección o repetir la selección para obtener otros rangos de información, todo de una forma integrada y automática.
En nuestra prueba hemos ejecutado un informe de Ventas por Año, Trimestre y Target desde Excel, y todos los formatos, colores, Umbrales, etc. se han mantenido y se han pasado exactamente igual en la hoja de calculo que se nos ha creado automáticamente.
Navegación en los informes. Opciones de navegación. Configuracion.
Aunque la navegación es una característica de los cubos OLAP, vamos a verla por encima pues es una característica muy util en el reporting, que nos va a permitir ir profundizando en el análisis de los datos que se obtienen en la ejecución de un informe o cambiar el ambito de análisis en tiempo de ejecución (cambiando la dimensión por la que estemos analizando la información).
La navegación se puede configurar a nivel de informe, de forma que podemos tener informes que sean estáticos y donde no este permitida la navegación (nos puede interesar por el perfil de usuario que lo utilice) o informes en donde se puede navegar, pero solo a nivel descendente. En la imagen, vemos algunas de las opciones de navegación.
Opciones de navegación en un informe
También se pueden configurar otros aspectos, como el mantener en la cuadricula el atributo padre desde el que estamos navegando, si mantenemos los umbrales y subtotales, etc. La navegación se puede realizar sobre todos los elementos de un atributo o sobre valores seleccionados. Para entender esto, vamos a ver un ejemplo. Tenemos un informe sencillo, donde se analizan las ventas por Año y Trimestre (tal y como vemos en la imagen).
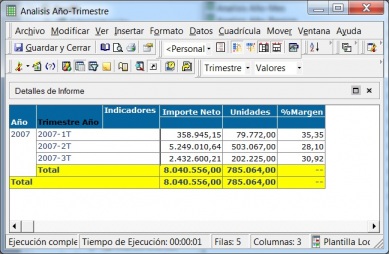
Analisis Ventas por Año y Trimestre
Podriamos profundizar mas en los datos de dos maneras:
- Total: seleccionamos en la cabecera del atributo que queremos desglosar (por ejemplo, el Trimestre Año), y con el botón derecho, desde el menú contextual seleccionamos Navegación –> Abajo –> Mes Año. El informe se recalculara y se mostrara toda la información desglosada al nuevo nivel.
- Según valores seleccionados: seleccionamos uno o varios trimestres (pulsando Control), y de la misma manera con el menú contextual, procederemos a la navegación. En este caso, solo estaremos desglosando al nivel inferior los trimestres seleccionados.
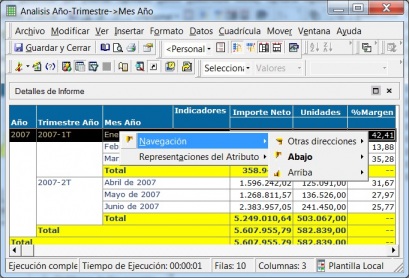
Analisis año-trimestre con navegacion
En la imagen podeis ver como hemos desglosado por mes el primer y segundo trimestre de 2007. Igualmente, podeis ver el aspecto del menú contextual que nos permite realizar la navegación. La opción Arriba y Abajo nos permite subir y bajar en la jerarquía actual. Con la opción Otras direcciones, podriamos cambiarnos de jerarquía y pasar a analizar los datos y a desglosarlos por otro atributo.
Movilidad en los componentes de un informe. Filas, columnas, indicadores.
La herramienta de reporting nos permite en tiempo de ejecución modificar el aspecto del informe, pudiendo intercambiar filas y columnas, cambiar el orden de los elementos en la visualización, ocultar un indicador (aunque sigue estando asociado al informe). Tambien podremos llevar una fila a columnas o viceversa o seleccionar un determinado atributo y llevarlo a la ventana de paginación (momento en el que pasara a formar parte del filtro de paginación). Veamos un ejemplo sencillo de un informe de analisis de ventas por Linea de Producto y Mes (en la filas estan las lineas de producto y en las columnas los meses):
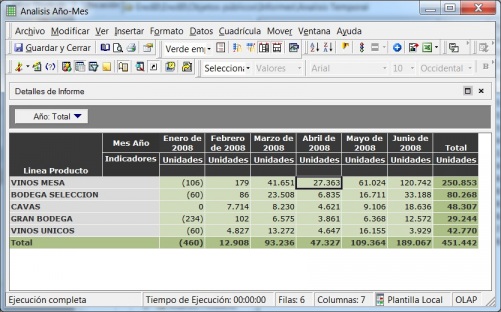
Ventas por Linea de Producto y Mes
En este informe queremos transponer las filas con las columnas. Sera tan facil como seleccionar la opción Mover –> Intercambiar filas y columnas, y el aspecto del informe pasará a ser el siguiente:
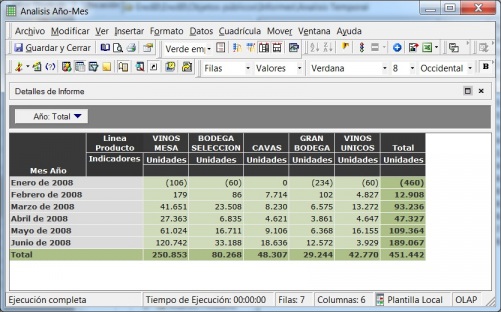
Ventas por Mes y Linea de Producto
En el caso de haber tenido mas indicadores, podriamos haber cambiado su posición simplemente seleccionandolos y arrastrandolos a la nueva ubicación. De la misma manera, en el caso de tener varios atributos en el mismo eje (por ejemplo Trimestre, Linea Producto), podriamos haberlos arrastrado cambiando su orden, orden que determinara la forma en que se hace el desglose de la información.
Limites a nivel de informe. Filtros de visualización.
Ademas de los filtros que vimos anteriormente que se pueden establecer a nivel del informe mediante los filtros y selecciones dinámicas, y también mediante el filtrado de valores de un indicador (que también vimos), Microstrategy nos permite dos filtrados adicionales de la información:
- Limites a nivel de informe: en las opciones de datos del informe, podemos indicar criterios adicionales de filtrado que produciran como resultado que no se visualicen los valores que no cumplan las condiciones. Por ejemplo, si en un informe de ventas indicamos la condición de la imagen (Importe Neto Mayor o Igual que 100), no se mostrara, cuando ejecutemos el informe, ninguna linea que no cumpla dicha condición. Pero una cosa importante, los valores filtrados si apareceran reflejados en totales y subtotales del informe. Es una forma útil de quitar información no relevante, aunque si siga considerandose para los analisis de importes totales.
- Filtro de visualización: este filtro se define en la sección del informe correspondiente y nos permite ir estableciendo filtros de visualización en caliente sobre los datos mostrados en pantalla. Conforme se van cambiando los filtros y aplicandose, dinamicamente cambian los valores visualizados, y también los importes de totales y subtotales. Puede ser util para trabajar dinamicamente sobre los datos y para ir mostrando diferentes escenarios de datos según se omite o no determinada información.
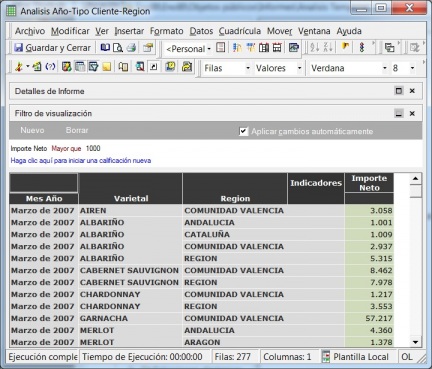
Filtro visualizacion
Cache de Informes.
Es una característica avanzada de Microstrategy, que permite que los informes que se ejecutan con mas frecuencia y en los que no cambian los criterios de ejecución, sean guardados en cache y recuperados en el momento en el que alguien vuelva a realizar la misma consulta. En este tipo de ejecución, cuando lanzamos un informe no se accede a la base de datos, sino que leemos los resultados del informe que quedaron guardados en un area de trabajo especial. Con esto, optimizamos los recursos del sistema y mejoramos los tiempos de respuesta y el rendimiento general del sistema. Puede tener algún inconveniente, como que los datos que se nos muestren no esten actualizados con los datos mas recientes, aunque todo esto es configurable.
Para saber si un informe se ha ejecutado recuperando o no la cache, en la sección Detalles de Informe aparecera si se ha recurrido a ella o no. En cualquier momento se puede limpiar la cache de un informe antes de volverlo a ejecutar, y así asegurarnos que se realizará el recálculo completo.
Las opciones de cache se establecen a nivel de proyecto (a nivel general), tal y como vemos en la imagen.
Configuración de cache a nivel de proyecto
A nivel de informe, se pueden establecer opciones de cache personalizadas, que solo afectarán al informe en cuestion. Incluso se puede inhabilitar la cache para un informe en concreto y darle una caducidad.
Cache a nivel de informe
Las caches se pueden limpiar de forma global en cualquier momento para que todo se recalcule.
Creación de informes al vuelo.
Ademas de construir informes desde cero utilizando el editor de informes o el correspondiente asistente, tenemos otra forma de construir informes al vuelo. Partiendo de la ejecución de cualquier informe, nos podemos pasar al modo Diseño, y realizar los cambios que estimemos oportunos (añadir indicadores, modificar atributos, quitar o poner filas y columnas, cambios en los formatos, umbrales, filtros, etc).
Una vez realizados todos los cambios, podremos guardar el informe con un nombre diferente y habremos creado de forma interactivo un nuevo informe. Esta característica nos permite reutilizar componentes ya definidos y personalizarlos según las diferentes necesidades que vayamos teniendo. Por eso, puede ser util cuando queramos construir un nuevo informe, buscar uno ya existente que tenga elementos en comun y sobre el realizar las modificaciones para dar lugar al nuevo informe.
Creación de grupos personalizados.
Los grupos personalizados son agrupaciones heterogeneas de atributos que nos permiten ver los resultados de los informes desde otro punto de vista. Es una característica avanzada de Microstrategy que yo no he visto en otras herramientas y que puede ser muy util para analizar la información por criterios que no estan registrados en el modelo de datos.
Antes de continuar, os recomiendo visualizar el video elaborado por Microstrategy que habla de la forma de crear los grupos personalizados (ver aquí ).
Para nuestro ejemplo, hemos creado un Grupo Personalizado que incluye varios grupos de atributos. El objetivo es realizar una clasificación de las regiones por Zonas. Por ejemplo, la zona Levante incluye la región de Valencia, Murcia y Cataluña. La region Sur incluye Andalucia, Extremadura, Ceuta y Melilla. Y así con el resto de las regiones. La definición del grupo personalizado sería la siguiente:
Creación de grupo personalizado Zonas Geográficas
Una vez definido un grupo personalizado, lo podemos utilizar en la creación de un informe como si fuera un atributo mas de una dimensión. En nuestro ejemplo, hemos definido un informe utilizando el Grupo personalizado en las filas y en las columnas los indicadores Importe Neto, Precio Neto y Unidades. El resultado de la ejecución del informe sería el siguiente:
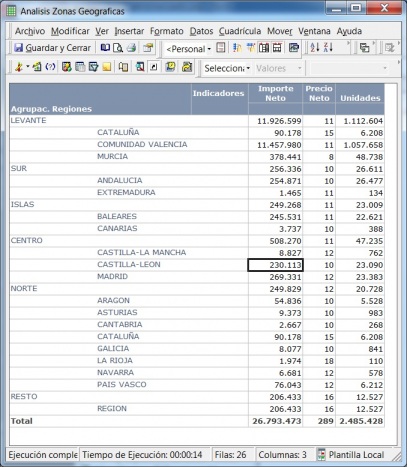
Informe con grupo personalizado
Podemos ver como se ha realizado la clasificación de la información y como aparece desglosado todo según la jerarquía definida al crear el grupo personalizado. Cuando se define el grupo personalizado, se puede predefinir como queremos que se vea la representación jerarquica, los subtotales, si el elemento padre aparecera en la parte superior o inferior de los hijos, etc.
Ademas del grupo personalizado indicando valores de atributos, podemos crear grupos personalizados que califican sobre valores (por ejemplo los 10 primeros clientes por importe, los 20 primeros clientes por rentabilidad, los clientes que representan el 40% de las unidades vendidas). Para este caso, la definición del grupo personalizado sería la siguiente:
Grupo Personalizado calificando Indicadores
Observad como se pueden añadir tantos subgrupos dentro de un grupo personalizado como se deseen. En este caso, hemos añadido 3. Cada uno califica sobre un indicador diferente y con un criterio de agrupación diferente (Clasificación, Porcentaje). El grupo personalizado lo hemos incluido en un informe, y el resultado de la ejecución sería el siguiente:
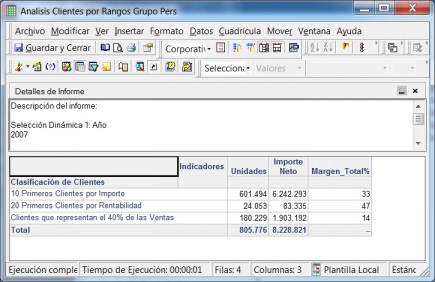
Informe con grupo Personalizado sobre indicadores
Hemos podido ver con estos dos ejemplos las amplias posibilidades que nos proporciona esta funcionalidad de Microstrategy. Podremos crear nuestro propios grupos e incluirlos en el mismo informe, incluso aunque no esten relacionados de una forma homogenea.
Graficos. Combinación tabla cruzada-gráfico.
Ademas de los informes en forma de crosstab o tabla cruzada que hemos visto hasta ahora, Microstrategy también nos permite incluir gráficos para la visualización de los resultados. Disponemos de un amplio abanico de posibilidades en lo que respecta a los gráficos: desde gráficos de área, de barras, de lineas, circular o de tarta, dispersión, polar, radial, burbuja, marcadores, diagramas de gant, gráficos combinados o gráficos personalizados.
Tipos de grafico en Microstrategy
A la hora de utilizar los gráficos, tendremos que tener los datos apropiados en la tabla cruzada para que su visualización en un gráfico tenga sentido (si tenemos 5 indicadores y la información desglosada por muchos atributos, no valdrá de nada construir un gráfico).
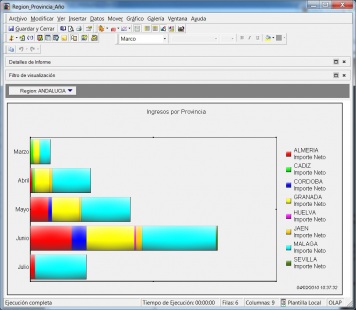
Ejemplo grafico de barras
Ademas, Microstrategy nos permite combinar en un mismo informe la tabla cruzada y su correspondiente informe. Por ejemplo, para el ejemplo que hemos visto, podriamos tener las ventas por mes y región-provincia. Conforme vayamos cambiando en la paginación la región, los valores en la tabla cruzada se irían actualizando, asi como los valores reflejados en el gráfico.
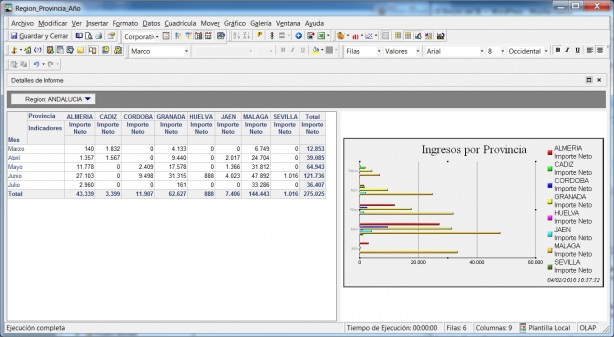
Ejemplo Tabla Cruzada con gráfico
Con los gráficos podremos complementar nuestro informes y darles un significado gráficos. También seran utiles para esquematizar información en los cuadros de mando. Cada tipo de informe tiene unos requisitos de atributos e indicadores (en la documentación hay una tabla donde se enumera cada gráfico y los requisitos mínimos para darle sentido).
Informes con selección de atributos y ratios en tiempo de ejecución.
Para terminar con el detalle de los elementos que podemos utilizar en nuestro sistema de reporting, vamos a ver la combinación de selecciones dinámicos que nos permiten seleccionar los atributos o indicadores de un informe, incluidos dentro de un crosstab. De esta forma, al ejecutar el informe, se ejecutaran también las selecciones, y estaremos construyendo, en tiempo de ejecución, lo que queremos que incluya nuestro informe.
En primer lugar, realizaremos la definición de las selecciones dinámicas. Definiremos esta como del tipo “Selección Dinámica de Objeto“, y crearemos una para los atributos, y otra para los indicadores (tal y como vemos en la imagen).
Seleccion dinamica de indicadores
A continuación, construiremos un informe. La seleccion dinámica de atributos la pondremos en las filas en nuestro ejemplo (como si fuera un atributo), y la selección dinámica de indicadores en las columnas(como si fuera un indicador). Al ejecutar el informe, nos aparecerá algo asi:
Selecciones de atributos e indicadores al ejecutar
Vemos como el informe nos muestra la lista de atributos e indicadores que hemos preconfigurado, y podremos elegir entre ellos para llevarlos al informe al lugar correspondiente donde se incluyeron en el diseño. Con la selecciónes realizadas, mas el filtrado propio de cada informe, estaremos dejando al criterio del usuario que información quiere ver en cada momento. Esto nos puede ser util para reducir el número de informes disponible o para que el mismo informe se utilice para funciones diferentes según nuestras necesidades.
Otros elementos
- Generación informes a partir de sentencias SQL personalizadas: podremos desde una sentecia SQL construida por nosotros, crear un informe. El el momento de crear un informe, seleccionamos el origen ODBC con el que vamos a trabajar. Utilizando el generador de consultas, podremos ir llevando las tablas que haya definidas en la base de datos seleccionada, al espacio de trabajo. De ahí, podremos ir seleccionando los campos, construyendo expresiones sobre ellos e indicando condiciones (como vemos en la imagen siguiente). Al grabar, volvemos al editor de informes con la información necesaria recuperada de la query. Con este procedimiento podremos construir informes sobre cualquier origen de datos y preparar consultas puntuales y no predefinidas sobre la información (podeis ver un video tutorial del proceso completo de creación de este tipo de informes aquí ).
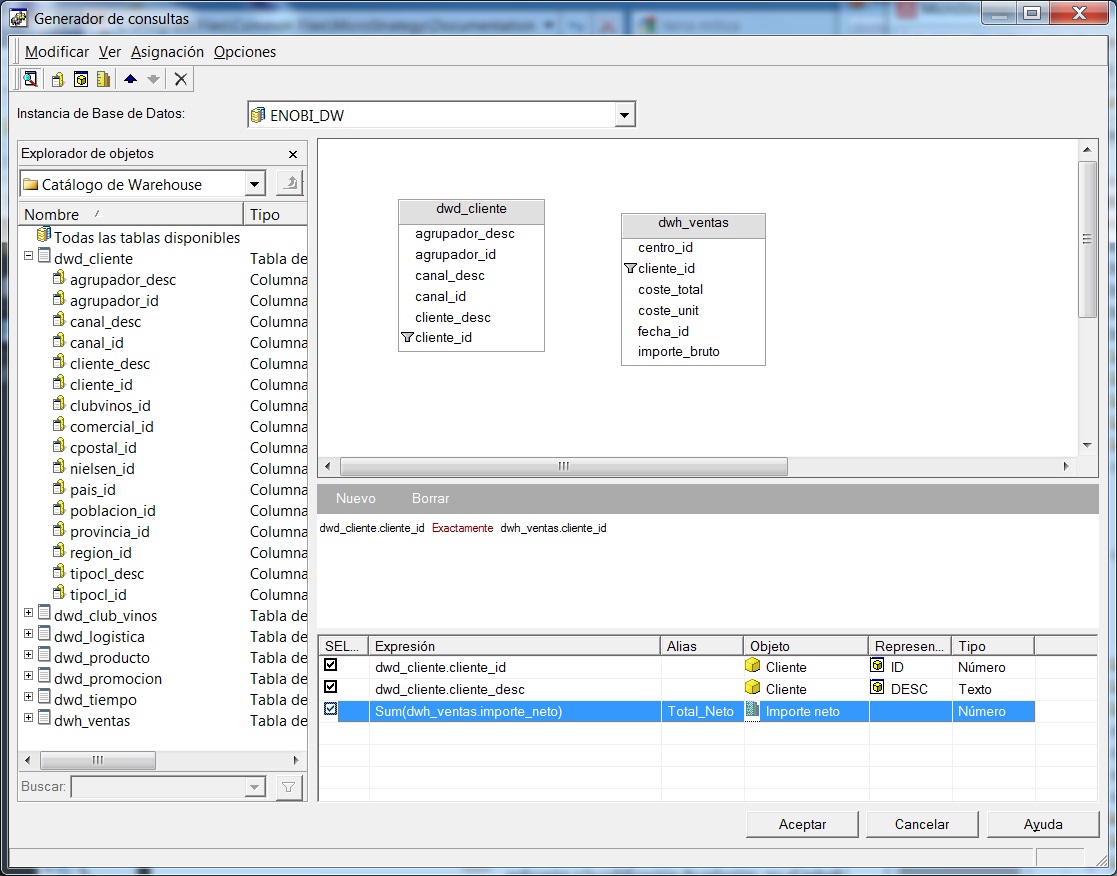
Generador consultas SQL para construir informes
- Mapas de navegación: nos permiten establecer los patrones de como será la navegación en los informes. Es decir, podremos indicadar que atributos estarán disponibles para la navegación hacia arriba, hacia abajo o hacia otra dimensión. Sino se crea ningún mapa de navegación, se utiliza el de proyecto que incluye todas las jerarquias de usuario. Si deseamos personalizarlo, podemos hacerlo a nivel de proyecto (general para todos elementos), o bien a nivel de atributos, jerarquias o consolidaciones. Cuando el objeto se utilice en un informe, se reemplazara el mapa de navegación general por el propio. También se pueden asociar mapas de navegación a un informe o una plantilla. En la imagen posterior, podeis ver un ejemplo de mapa de navegación, que asociariamos al atributo mes (en el estamos restringiendo la navegación hacia arriba a solo los atributos Año, Semestre y Trimestre, y a nivel inferior a Fecha, no permitiendo navegación transversal).
Editor de Mapas de navegacion
- Creación de plantillas de informes: cualquiera de los informes que hemos creado, lo podremos encapsular en forma de plantilla. Esta plantilla se podrán reutilizar luego en el diseño de otros informes.
- Consolidaciones: es un concepto similar al de los grupos personalizados. Las consolidaciones nos permiten crear atributos “ficticios”, que pueden ser agrupaciones de estos y para los que luego realizaremos operaciones aritmeticas. Las consolidaciones son mas eficientes a nivel de SQL y los calculos se realizan a nivel del Motor análitico (en lugar de en la consulta al DW, como es el caso de los grupos personalizados). En el ejemplo podeis ver el editor de consolidaciones. En los tres primeros grupos, hemos indicado los valores de las lineas de producto que queremos incluir en ellos, solo de un determinado atributo. En el ultimo grupo, Cavas Rueda, hemos indicado dos condiciones sobre atributos diferentes, la linea de Producto CAVAS y la denominación de origen RUEDA (Cavas fabricados en la denominación de origen Rueda). Las consolidaciones se utilizan luego en el editor de informes como si fueran un atributo.
Editor de consolidaciones
- Filtrado utilizando resultados de otro informe.
- Vinculos entre informes y documentos: llamada desde un informe a otro en un lugar determinado con paso de parametros de contexto.
- Creación de Datamarts: resultados de informes guardados en base de datos.
- Etc, etc.
Conclusiones.
Hemos intentado pasar con bastante detalle por todas las funcionalidades de reporting que nos proporciona Microstregy. Partiendo de los objetos de esquema que habiamos preconfigurado (atributos, indicadores, filtros, selecciones dinámicas) y los elementos que podemos utilizar para reporting como las tablas cruzadas, gráficos, grupos personalizados y consolidaciones, columnas calculadas, formatos, umbrales, totales y subtotales, etc, podremos seguramente cubrir todas las necesidades de reporting de cualquier organización. También seguramente habra funcionalidades complejas que nunca utilizaremos, pero que estan ahí disponibles.
El feeling con la herramienta es bueno, aunque la primera impresión es que técnicamente puede ser compleja la comprensión y utilización de todos los elementos que ofrece (sobre todo el tema de los niveles de cálculo de los indicadores), y para hacer determinadas cosas seguramente no bastará con un usuario de tipo medio, sino mas bien avanzado.
Por otro lado, conociendo otras herramientas de reporting, creo que Microstrategy es bastante completo y nos deja muchas puertas abiertas para personalizar los informes y para hacer cosas que no son estandar (como por ejemplo, lo de los grupos personalizados y las consolidaciones, o los indicadores de nivel) o el tema de las transformaciones para la series temporales.
Tras la revisión de la herramienta de reporting, hemos profundizado en su conocimiento y ademas hemos construido un set de ejemplos de informes que incluyen la mayoria de elementos disponibles y que nos permitiran preparar todo el lote de informes para reporting dentro de nuestro proyecto. En los ejemplos explicados no lo hemos visto, pero los filtros y selecciones dinamicas tienen muchisimas funcionalidades que nos van a permitir definir todo tipo de filtrados de todas las formas que necesitemos, como podriamos hacer en cualquier lenguaje de programación, y ademas con funciones avanzadas, para, por ejemplo, el tratamiento de fechas (nos permite definir patrones para crear, a partir de la fecha actual, periodos predefinidos, como el mes anterior hasta la misma fecha, desde principio de año hasta la fecha actual, el primer lunes del año y todas las variantes que podamos imaginar).
En la proxima entrada del blog veremos las funcionalidades OLAP que proporciona Microstrategy y como nos permite trabajar con los cubos inteligentes y origenes de datos MDX.
Hola Roberto, Quería hacerte
Hola Roberto,
Quería hacerte una pregunta, sobre temas de rendimiento en Microstrategy.
Tengo un par de tablas muy voluminosas en mi esquema de Oracle.
Me planteo la opción de particionar. ¿Qué es lo más recomendable
acudir a particiones de Microstrategy o utilizar las particiones propias
de BBDD?.
Gracias, un saludo,
- Log in to post comments
Hola Juan Si la base de datos
Hola Juan
Si la base de datos es una versión Enterprise y, por tanto, puedes utilizar la opción de particionamiento, yo sería más partidario de utilizar el particionamiento de Oracle, ya que la base de datos lo gestiona muy bien, y una optimización física como esta creo que es más adecuado dejarla a nivel de BD / ETL.
El particionamiento a nivel de MicroStrategy puede ser una solución muy buena cuando no dispones de esta opción en la base de datos, porque la versión de la misma sea una Standard Edition, por ejemplo.
- Log in to post comments
Gracias Roberto,
Gracias Roberto,
- Log in to post comments
Navegación Dimensional y cubos OLAP en Microstrategy 9.
Navegación Dimensional y cubos OLAP en Microstrategy 9. respinosamilla 25 February, 2010 - 09:50En la correspondiente entrada del Blog ( 2.2. Cubos OLAP (On-Line Analytic Processing)), vimos las características que deberían de tener las herramientas OLAP, diferenciando por un lado la plataforma OLAP y por otro lado los visores OLAP.
El termino OLAP fue introducido en 1993 por el Dr. E.F. Codd. OLAP son las siglas de On-line Analytical Processing. Es un software que nos permite la manipulación multidimensional de la información provenidente de varios origenes de datos y que ha sido almacenada en un data warehouse. El software nos permite crear varias vistas o representaciones de los datos, ademas de un acceso rapido, consistente e interactivo sobre los datos multidimensionales.
Os recomiendo revisar la entrada del Blog antes de continuar viendo como implementa Microstrategy los conceptos OLAP.
Plataforma OLAP de Microstrategy
La plataforma de Microstrategy es una plataforma ROLAP (Relational OLAP), que utiliza una base de datos relacional como soporte de datos. El Intelligence Server traduce nuestros análisis dimensionales a consultas SQL sobre esta base de datos, y construye unos cubos ROLAP virtuales que sera de donde se extraera la información con las consideraciones de Dimensiones e Indicadores seleccionados en las consultas de información. Estamos trabajando con una especie de cubos ROLAP virtuales. Ademas, el Intelligence server puede ser capaz de encontrar los cubos que se utilizan con mas frecuencia y guardarlos en memoria para la próxima vez, con lo que se mejora el rendimiento del sistema.
En la versión 9 esta presente la tecnología de Cubos Inteligentes. Estos cubos tienen una caracteristica MOLAP y funcionan de la siguiente manera. Se definen como si fuera un informe. En esta definición seleccionamos los atributos e indicadores que formaran nuestro cubo (esto será la definición del cubo, lo que determinara las dimensiones por las que podremos luego analizar la información).
Una vez el cubo esta definido, se ha de ejecutar (en ese momento se llena con información de la base de datos). La información almacenada en el cubo esta preagregada conforme a los atributos que hayamos seleccionado y por tanto preparada y preelaborada para el análisis. Y a partir de ese momento el cubo se publica y ya esta disponible para poder ser utilizado creando informes sobre él. El cubo se podrá ir actualizando automaticamente de forma planificada, por lo que nos olvidaremos de su mantenimiento o de si los datos estan actualizados o no (lo gestionará todo la plataforma).
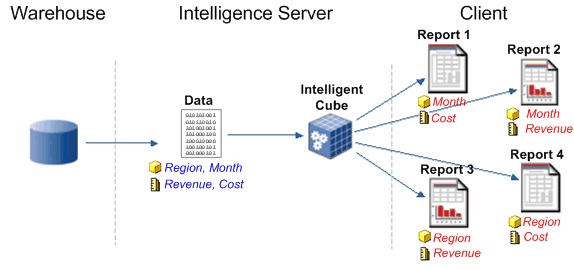
Funcionamiento de los cubos inteligentes
Los informes que creemos sobre el cubo intelligente solo podrán utilizar los elementos que definamos cuando construyamos el cubo. La información de los cubos esta guardada en el sistema en un sitio aparte y al ejecutar los informes, no se volvera a acceder al Data Warehouse, sino solo a la información almacenada en los cubos inteligentes (veremos mas adelante un ejemplo de construcción, planificación y explotación de un cubo inteligente). Cualquier cambio que vayamos realizando en el informe no necesita volver a acceder a la base de datos, siempre trabajara con los datos del cubo ( a no ser que nos vayamos fuera de las dimensiones establecidas, aspecto que se puede configurar para permitirlo o no). Los cubos se pueden compartir entre diferentes usuarios e informes.
Cliente OLAP de Microstrategy
A nivel de usuario, Microstrategy ofrece las características OLAP mas habituales. La mayoría de ellas ya las hemos visto al detallar los elementos de reporting de Microstrategy (en las dos entradas anteriores del Blog). En Microstrategy, los aspectos de reporting y olap estan mezclados y en un poco dificil saber cuando estamos utilizando características de reporting puro y duro y cuando características Olap. En teoría, cuando trabajamos con Desktop, en la parte inferior derecha nos aparecera el rótulo Estandar u Olap según si utilizamos o no las características Olap de Microstrategy. Realmente estariamos hablando de una distinción entre características Olap estandar y lo que llaman Olap Services.
En lo referente a la navegación multidimensional por los datos, Microstrategy incluye como hemos visto en los ejemplos las funcionalidades habituales:
- Rotar (Swap): alterar las filas por columnas (permutar dos dimensiones de análisis)
- Bajar (Down): bajar el nivel de visualización en las filas a una jerarquía inferior.
- Detallar (Drilldown): informar para una fila en concreto, de datos a un nivel inferior.
- Expandir (Expand): id. anterior sin perder la información a nivel superior para éste y el resto de los valores.
- Colapsar (Collapse): operación inversa de la anterior.
- Pivotación (Pivoting): movimiento de objetos de filas a columnas y de columnas a filas, asi como cambio del orden de los objetos tanto en filas como en columnas.
Cuando navegamos por los datos (y no estamos en los cubos inteligentes), las consultas se recalculan contra la base de datos. Solo puede haber algunos casos en los que se trabaja con el cubo que tenemos en memoría y no se haria un recalculo (por ejemplo, cuando quitamos un atributo del informe y nos quedamos en otro nivel de los que ya estan incluidos).
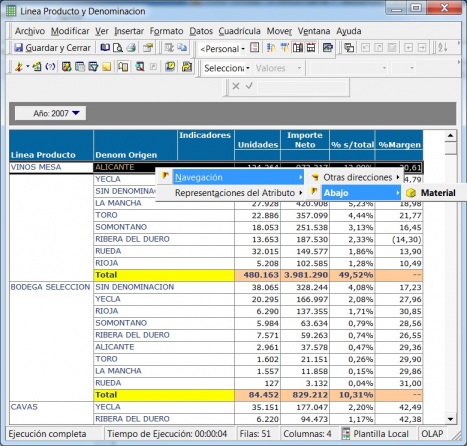
Navegacion - menu contextual
La gente de Microstrategy habla de las capacidades de Navegación llamandolas Drill-Anywhere. Se entiende que se permite la navegación en cualquier lugar y hacia cualquier dimensión del modelo de análisis (siempre que no lo hayamos limitado quitando la navegación en un informe o restringiendola a unos determinados atributos o dimensiones con los Mapas de Navegación personalizados).
Ademas de la navegación, podemos mencionar otras características, algunas de las cuales ya vimos (y que podeis revisar pulsando el correspondiente link de cada elemento):
- Grupos de datos: cuando queremos mostrar la información en una estructura de atributos que no esta definida dentro de nuestro modelo de negocio, Microstrategy nos proporciona los Grupos Personalizados y Consolidaciones.
- Paginación: como ya vimos, con esta funcionalidad podemos sacar un atributo de la cuadricula y crear paginas de datos para cada uno de los valores de dicho atributo (como veis en la imagen anterior, donde en la sección de paginación tenemos el atributo año).
- Subtotales: también pasamos por ellos cuando vimos las funcionalidades de reporting de Microstrategy. Es la funcionalidad que nos permite incluir totales de diferentes tipos en los niveles seleccionados de los informes.
- Aliasing: posibilidad de definir nombres de alias para cualquier elementro dentro los informes ( para los indicadores, atributos, grupos personalizados o consolidaciones).
- Banding: metodo para definir el aspecto de segmentos del informe aplicandos bandas de colores. Podemos aplicar las bandas de colores a filas y columnas según el numero de ellas.
- Ordenación avanzada: nos permite establecer criterios de ordenación compleja sobre los datos, con el correspondiente editor, indicando por niveles que tipo de ordenación deseamos, considerando tantos los valores de atributos como de indicadores.
- Visualización jerárquica: aunque en un informe tengamos varios niveles de detalle con la visualización jerarquica o resultados indentados, podemos con un simple click selección el nivel al que queremos ver la información.
- Umbrales: formatos personalizados sobre los valores de los indicadores para remarcar aquellos que cumplan unas determinadas condiciones (también se pueden sustituir los valores por simbolos, imagenes o texto).
A partir de los elementos siguientes es cuando Microstrategy considera que estamos utilizando funcionalidades Olap Services:
- Filtros de visualizacion: restricciones de visualización que se aplican al informe calculado y que nos van modificando los resultados en pantalla sin volver a reejecutar la consulta sobre la base de datos (trabaja con el cubo en memoria).
- Filtros de indicadores: filtrados sobre los valores de los indicadores que indicamos en los resultados del informe. Las condiciones podian ser sobre los valores del indicador o sobre valores de ranking. Igualmente, no se reejecuta la consulta sobre la base de datos al aplicar los filtrados.
- Columnas calculadas: vimos que en los resultados de ejecución del informe podiamos añadir nuestras propias columnas de indicadores que incluyesen diferentes tipos de calculos (con el editor de expresiones), o bien porcentajes sobre Total, campos de Ordenación (Ranking) y Transformaciones. De la misma forma, los calculos se realizan en memoria.
- Agregación dinámica: es la funcionalidad que nos permite cambiar de nivel de agregación en los resultados de un informe sin necesidad de volver a recalcular la consulta sobre la base de datos. La funcionalidad actua cuando estamos modificando un informe ejecutado ocultando atributos o indicadores, llevando atributos de la cuadricula a la sección de paginación, etc. Solo cuando los ocultamos, porque en el momento un objeto se borra del informe, entonces este siempre es recalculado.
- Cubos Intelligentes.
Como funcionalidades avanzadas Olap, y que solo estan disponibles en los informes sobre cubos inteligentes y en los documentos de Report Services, tenemos las siguientes:
- Definición de elementos derivados: es la definición de grupos de atributos creados al vuelo. Seria algo complementario a los grupos personalizados y las consolidaciones. El hecho de que se puedan construir sobre la marcha nos da posibilidades adicionales de formateo y de agrupación de la información para análisis. Se pueden definir de 3 maneras:
- Grupos de elementos: lista de elementos, de los que tenemos en pantalla, que forman cada grupo.
- Elementos que cumplan una condición de filtro: filtrado de los elementos de cada grupo por criterios de filtrado.
- Operaciones sobre elementos: calculos para combinar los valores de varios atributos.
Trabajando con cubos inteligentes.
Como hemos visto, los cubos inteligentes son un conjunto de datos, generados a partir de la información existente en nuestro DW, y que podremos analizar o explotar a traves de los informes. Los cubos solo almacenan información de los datos, y la gestión de su visualización y formateo quedaran en manos de los informes que construyamos sobre ellos.
Hay algunos elementos que no se pueden incluir en el informe de definición de los cubos inteligentes, que son:
- Grupos Personalizados y consolidaciones.
- Elementos olap (filtros de visualización, columnas calculadas y elementos derivados).
- Selecciones dinámicas o filtros que tengan asociados selecciones dinámicas.
Vamos a trabajar con un ejemplo de Cubo Inteligente para ver todos los pasos de su creación y explotación.
Creación de cubos inteligentes.
Para crear un cubo, crearemos un nuevo objeto en el lugar deseado del tipo Cubo Inteligente. En ese momento se nos abrira el editor de cubos (que es practicamente igual al editor de informes) y añadiremos en el los elementos deseados, siempre teniendo en cuenta las restricciones de elementos que no podemos utilizar.
Editor Cubos Inteligentes
Observad como hemos incluido en el informe un filtro estatico seleccionando la información de los años 2007 y 2008. En la cuadricula hemos seleccionado varios atributos de diferentes dimensiones y los indicadores: importe neto, unidades, margen total e importe de descuentos.
Una vez el cubo es correcto, lo guardamos y tendriamos creada su definición. Pero el cubo todavía no sería accesible, pues no esta ni calculado ni publicados sus resultados.
Publicación.
La publicación de un cubo es tan sencilla como realizar la ejecución de su definición. Cuando se realiza la ejecución, esta no tiene como resultado ningún resultado visible (no se ve una cuadricula como en el caso de los informes). Simplemente, nos aparecerá un log indicandonos que la ejecución ha sido completada.
Podemos ver las características del cubo con la opción del menú contextual Mostar información del cubo. Nos aparecera una pantalla con información general de este:
Propiedades del cubo creado
Ahí podremos ver cuando se creo el cubo, cuando se realizo la ultima actualización de sus datos, el numero de registros obtenidos de la base de datos para llenarlo. Incluso podriamos visualizar la sentencia SQL utilizada para su creación.
select a14.ano_id ano_id, a14.mes_id mes_id, max(a14.mes_desc) mes_desc, a11.fecha_id fecha_id, max(a14.fecha_desc) fecha_desc, a13.region_id region_id, a13.provincia_id provincia_id, a12.linprod_id linprod_id, max(a12.linprod_desc) linprod_desc, a12.denom_id denom_id, sum(a11.importe_neto) WJXBFS1, sum(a11.unidades) WJXBFS2, sum(a11.margen_total) WJXBFS3, (sum(a11.Importe_dtos) + sum(a11.importe_promos)) WJXBFS4 from dwh_ventas a11 join dwd_producto a12 on (a11.material_id = a12.material_id) join dwd_cliente a13 on (a11.cliente_id = a13.cliente_id) join dwd_tiempo a14 on (a11.fecha_id = a14.fecha_id) where a14.ano_id in (2007, 2008) group by a14.ano_id, a14.mes_id, a11.fecha_id, a13.region_id, a13.provincia_id, a12.linprod_id, a12.denom_id
El cubo esta calculado y ya podriamos crear informes sobre el. Tener en cuenta que sino planificamos o reejecutamos manualmente la actualización del cubo, este quedara como una foto de los datos en un momento puntual, totalmente desvinculada de las actualizaciones que se vayan realizando sobre el Data Warehouse.
Igualmente, tenemos la posibilidad de crear cubos inteligentes a partir de la definición de un informe. Es tan sencillo como, en la edición del informe, seleccionar la opción Datos –> Opciones de cubo inteligente –> Convertir a cubo inteligente. Siempre habrá que tener en mente las restricciones de los tipos de objetos que no podemos utilizar.
Creación de informes sobre cubos inteligentes.
Para crear un informe sobre un cubo inteligente, seleccionaremos el cubo sobre el que queremos trabajar, y desde el menú contextual, seleccionaremos la opción Crear Informe. Nos aparecerá el editor de informes, tal y como habiamos visto anteriormente, aunque con muchas opciones restringidas. No podremos seleccionar objetos de los definidos en nuestro proyecto (ni objetos del esquema, ni objetos publicos, ni atributos o indicadores). Solo podremos utilizar elementos de los definidos en la construcción del cubo (es decir, atributos e indicadores y calculos sobre ellos).
Por ejemplo, a nivel de atributos, solo podremos seleccionar por Año, Mes, Dia, Provincia, Región, Linea de Producto o Denominación de Origen. A nivel de indicadores, podemos utilizar los indicados o bien campos calculados sobre ellos (del tipo formula, porcentaje sobre el total u orden). En este caso no nos deja utilizar las transformaciones (lo cual es lógico, pues seguramente el ambito temporal de esta podría estar fuera de los datos del cubo).
Tampoco podremos añadir filtros de la forma usual ni selecciones dinámicas para filtrar la información (aunque si selecciones dinámicas del tipo objeto para permitir que se puedan seleccionar en tiempo de ejecución que atributos o indicadores se muestran en el informe). Tampoco podremos utilizar consolidaciones ni grupos personalizados en los informes que conectan con cubos inteligentes. Solo podremos establecer restricciones con el uso de los filtros de visualización. Otra forma de establecer restricciones será a traves de los filtros de seguridad. Podemos establecer limitaciones en los valores de atributos con los que puede trabajar un usuario con este tipo de filtros, que van asociados a la definición de usuario o grupo(pensar el tipico ejemplo de responsables de delegación que solo tienen que tener acceso a visualizar los datos de su ambito geográfico). Son filtros ocultos.
Creacion de informe sobre el cubo inteligente
Podeis ver en la imagen que en los objetos del informe estan todos los utilizados en la definición del cubo. También podeís ver que hemos añadido una columna calculada del tipo % sobre el total. Igualmente hemos añadido un filtro de visualización para restringir los datos a los del año 2007 (podiamos haber restringido por cualquier otro atributo o indicador). El informe esta listo para ejecutar.
Ejecucion de informes sobre cubos inteligentes.
La ejecución de los informes se realiza de la forma habitual. En este caso, no tenemos ningun filtro ni selección dinámica asociada en la ejecución (solo la selecciones dinámicas de objetos, como ya indicamos). Ejecutamos el informe y tenemos el siguiente resultado:
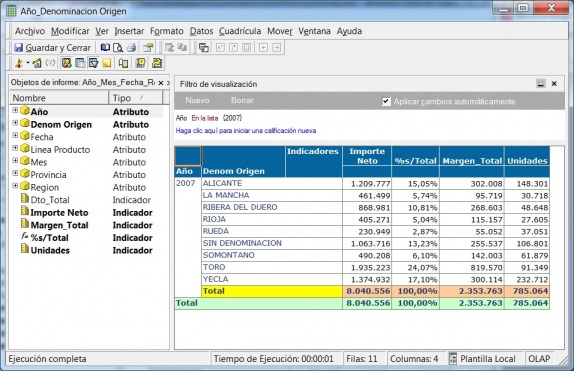
Ejecucion informe sobre el cubo
La ejecución del informe ha leido la información existente en el cubo sin realizar ninguna acción sobre la base de datos y los resultados se han mostrado de forma inmediata. En los resultados del informe podremos trabajar con los elementos habituales, tales como totales, umbrales, ordenación avanzada, insertar campos calculados, formato, aplicar filtros sobre indicadores, filtros de visualización, paginación, etc.
A nivel de la navegación, en principio podremos navegar solamente por los atributos que incluimos en el cubo. Existe la posiblidad de permitir la navegación fuera del cubo (es un parametro que se configura a nivel de proyecto y que también se puede establecer a nivel de cubo). En este caso, al realizar la navegación puede darse el caso que nos “salgamos” del cubo y haya que realizar un recalculo fuera de el, accediendo a datos del DW.
Una vez definido el informe, se podrá cambiar a posteriori el cubo al que esta asociado, aunque con restricciones (el nuevo cubo tendrá que tener todos los elementos necesarios para que el informe se pueda asociar a el).
Actualización de cubos inteligentes. Programacion de actualizaciones.
La actualización de un cubo es tan sencilla como volver a realizar la ejecución de este. En este momento, conforme a la definición del cubo, se vuelve a leer la información de la base de datos y se refresca su contenido. Lo habitual sería que la actualización de los cubos estuviese automatizada para no depender de ningún usuario. Para ello, hemos de tener configuradas las planificaciones, de forma que podamos asignar a una de ellas la actualización del cubo.
Asistente de planificacion
En nuestro ejemplo, hemos creado una planificación que se ejecuta una vez al dia, a las 10 de la mañana. Y la repetición de la ejecución es recursiva. El siguiente paso será cargar la actualización del cubo en la planificación. Para ello, con el menu contextual sobre el cubo, en la opción Planificar entrega a –> Actualizar Cubo.
Subscripcion a la actualizacion del cubo
En la subscripción al cubo podemos indicar una fecha de caducidad, a partir de la cual el cubo ya no se volvera a actualizar. Igualmente, seleccionamos a que planificación asociamos el proceso. Esto determinara la frecuencia de ejecución del proceso. También podremos hacer que se realice inmediante dicha actualización, a parte de la planificación establecida.
Trabajando con elementos derivados en cubos inteligentes.
Los elementos derivados son una funcionalidad exclusiva de los informes construidos sobre cubos intelligentes y de los documentos del report services. Son grupos de elementos que definimos al vuelo interactuando con los resultados de un informe. Para entender mejor los conceptos, vamos a ver un ejemplo.
Informe sencillo sobre cubo
El informe nos nuestra el total de ventas por región. Interactuando sobre los datos del informe, podremos crear los elementos derivados al vuelo. En los informes que trabajan sobre los cubos inteligentes, aparecen varias opciones de menú contextual nuevas, que son Elementos derivados, Crear grupo y Crear calculo.Vamos a ver un ejemplo de cada uno de los tipos.
- Grupos de elementos: lista de elementos, de los que tenemos en pantalla, que forman cada grupo. Podemos seleccionar en pantalla los atributos que queremos que formen un grupo y con la opción Crear Grupo creamos un grupo para ellos. Le asignamos un nombre, tal y como vemos en la imagen, y el grupo esta creado.
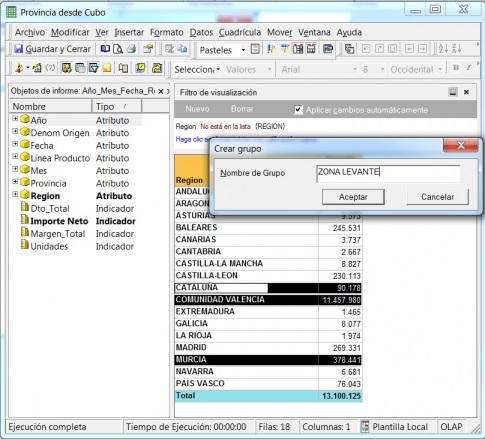
Creacion de grupo de elementos derivados
Repetimos el proceso para crear grupos para las diferentes Zonas Geográficas de España. Vamos seleccionando los diferentes valores de los grupos que queremos crear y hacemos la misma operativa. Tras crear todos los grupos, el informe quedará asi:
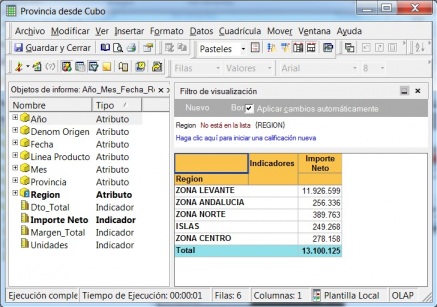
Informe con elementos derivado - grupo
Han ido despareciendo los valores individuales y se han sustituido por los nombres de los grupos. Todo de forma dinámica y sin recalcular nada, siempre trabajando en memoria. Podremos ver como ha quedado configurado el elemento derivado desde el editor, al que se accede desde el menú contextual.
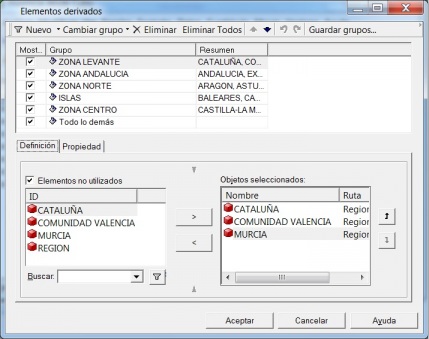
Editor elementos derivados
Podemos observar como aparecen los diferentes grupos que hemos ido creando y la lista de valores de cada atributo que hemos incluido en cada uno de los grupos. Aparece un grupo predefinido, llamado Todo lo demas, que siempre aparecerá y sobre el que no podemos realizar ninguna acción (siempre tiene que existir). Si quisieramos realizar algun cambio en los grupos, modificar el orden, la forma de visualizar o como afectan a los subtotales, lo hariamos desde este lugar.
- Elementos que cumplan una condición de filtro: filtrado de los elementos de cada grupo por criterios de filtrado. Sería similar al anterior. La definición de los grupos se realizaria desde el editor de Elementos derivados. Creariamos los grupos del tipo Filtro, y para cada grupo, estableceriamos las condiciones de filtrado que van a determinar los elementos que van a formar cada grupo.
- Operaciones sobre elementos: calculos para combinar los valores de un atributo. Un calculo es una operación sobre varios elementos de atributo o sobre los grupos creados anteriormente. En nuestro ejemplo, ademas de los grupos definidos, vamos a crear dos nuevos grupos, del tipo cálculo, que restan, a los importes de un grupo, los valores de una región (en el grupo ZONA LEVANTE restamos los valores de la región VALENCIA y en los de la ZONA CENTRO restamos los valores de MADRID). El editor de elementos tendrá el siguiente aspecto:
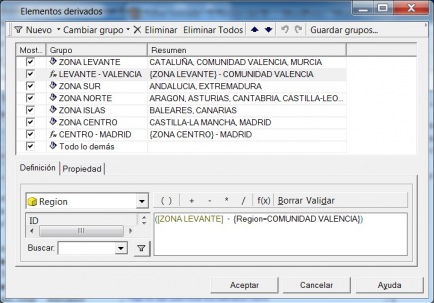
Elementos derivados - calculo
En este tipo de elemento derivado, se nos abre el editor de expresiones. Nos aparecen los diferentes valores de atributo del nivel seleccionado que tengamos en el informe y los grupos que hayamos definido. Y podemos hacer operaciones sobre ellos (suma, resta o funciones). Luego, en el informe, se realizara el mismo cálculo a nivel de los indicadores en cada fila del informe. Los dos nuevos grupos que hemos añadido, los hemos configurado en la pestaña propiedad para que no se tengan en cuenta en los subtotales. Podeis observar como al grupo ZONA LEVANTE le hemos restado los valores de una región en concreto. El informe resultante despues de aplicar los elementos derivados de grupo y de calculo sería el siguiente:
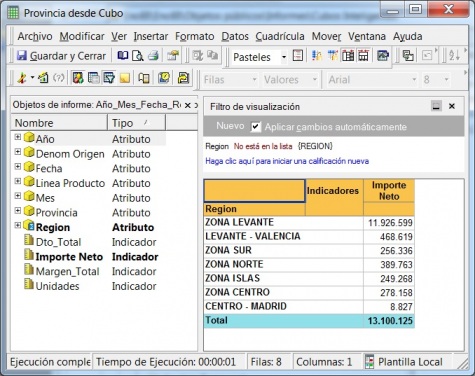
Informe con elementos derivado - calculo
Podemos ver los dos nuevos grupos que aparecen, y como no son tenidos en cuenta en el total general. Para ver como se estan haciendo los cálculos, desglosamos el informe a nivel de provincia, y el informe resultante es el siguiente:
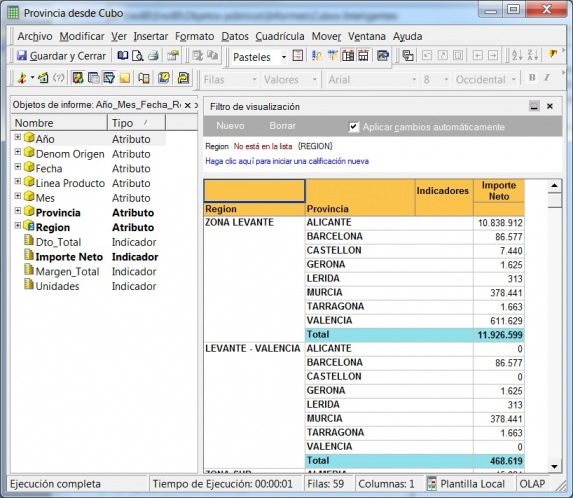
Informe con elementos derivado - calculo y desglose
Al desglosar la información, se mantiene en el nivel superior los grupos de elementos derivados. En el grupo donde a la zona de Levante restamos los datos de la region de Valencia, los valores de las provincias de dicha región presentan importes cero. Y el valor del elemento derivado de cálculo es la suma del resto de las provincias de las otras regiones.
Los elementos derivados se definen sobre cada atributo del informe y no se pueden combinar elementos de atributos diferentes (no puedo meter en los grupos de regiones operaciones o valores del atributo provincia, por ejemplo).
Conexión con otras bases de datos via MDX.
Microstrategy permite trabajar con cubos de otros sistemas que admitan MDX source tales como SAP BI, Hyperion Essbase y Microsoft Analysis Services. Por un lado, podemos realizar la integración de los cubos MDX en Microstrategy (importando los cubos, mapeandolos y realizando la creación de metricas a traves de los datos de el). Ademas, también podremos realizar reporting sobre ellos. No vamos a entrar en el análisis de esta funcionalidad.
Dynamic Sourcing
Como elemento destacable, el Dynamic Sourcing es una característica avanzada de la plataforma de Microstrategy que permite que los informes estandar accedan a los cubos inteligentes que puedan cubrir sus requerimientos de información (en lugar de hacerlo con la base de datos del DW). Con esta característica, se puede mejorar el rendimiento del sistema.
El Dynamic Sourcing esta deshabilitado por defecto y para habilitarlo se requiere configuración a nivel proyecto, cubos inteligentes, atributos, métricas e informes.
Conclusiones
Microstrategy cumple de sobra los requisitos de navegación dimensional y tipos de operaciones y elementos que podemos utilizar en el análisis dimensional. Muchos de los elementos OLAP han sido utilizados en las herramientas de reporting sin percatarnos de ello y viendolo como una funcionalidad mas de este. La funcionalidad de los cubos inteligentes es muy avanzada y presenta muchas ventajas, sobre todo en la rapidez de elaboración de los informes y en la facilidad para la creación y actualización de los cubos (aunque tiene algunas limitaciones respecto a los elementos que se pueden utilizar en ellos). El uso de la característica Dynamic Sourcing puede ser interesante para aumentar el rendimiento del sistema, aunque puede ser complicada su configuración y mantenimiento.
Finalmente, aunque esta funcionalidad no la hemos utilizado, puede ser interesante utilizar Microstrategy para atacar otras bases de datos a través de MDX.
Teoria de cuadros de mando. Tarjetas de puntuación y Dashboard.
Teoria de cuadros de mando. Tarjetas de puntuación y Dashboard. respinosamilla 25 February, 2010 - 09:50En la entrada anterior del Blog 'EIS (Executive information system). Cuadros de Mando Integral. DSS (Decission Support System)' hicimos una aproximación a la teoria de cuadros de mando y los sistemas de apoyo a la toma de decisiones (EIS/DSS).
Vamos a profundizar un poco más antes de ver la forma de construir estos elementos utilizando Microstrategy, a través de los Documentos de Report Services.
Teoría de cuadros de mando (Norton y Kaplan)
La teoria de cuadros de mando, impulsada por Robert S.Kaplan y David P.Norton surgio en los años 90 como respuesta ante la necesidad de analizar las organizaciones desde un punto de vista diferente al financiero, que se estaba quedando obsoleto. Se pretendia establecer un nuevo modelo de medidas dentro de las empresas para generar valor añadido en el futuro y también para conocer mejor las organizaciones.
Para ello, el instituto Nolan Norton, patrocinó un estudio de un año con la participación de varias compañias, de todos los sectores ( industria, servicios, alta tecnología, etc), con el objetivo de definir un “Corporate Scorecard” o cuandro de mando corporativo, que contuviese, ademas de los indicadores financieros tradicionales, medidas referentes a los tiempos de servicio a los clientes, calidad, tiempos de fabricación o desarrollo de nuevos productos. Durante el estudio, se fueron añadiendo otras medidas de productividad o calidad, que fueron ampliando los elementos a incluir en este cuadro de mando.
De ahi surgio el concepto “Balanced Scorecard”, que organizaba los indicadores o medidas en cuatro grandes grupos o perspectivas: financiera, cliente, interna e innovación y aprendizaje. El nombre de Balanced refleja que los indicadores tratan de ser un equilibrio entre los objetivos a corto y largo plazo, entre las medidas financieras y las no financieras, entro los indicadores de retraso o liderazgo y entre las perspectivas internas y externas.
Durante el estudio, varias compañias construyeron prototipos de un “Balanced Scorecard” dentro de sus compañias y fueron realimentando el estudio con las ventajas, oportunidades o incovenientes que fueron surgiendo durante su implantación. Una de las cosas mas importantes descritas fue el hecho que este sistema era algo mas que un sistemas de medidas, sino un alineamiento de las organizaciones con sus nuevas estrategias, partiendo de la información historica y de la compañia, con el objetivo de generar nuevas oportunidades de negocio o valor añadido. Los indicadores tenían ademas que estar alineados con el plan estrategico de la empresa, por lo que sería importante elegir los indicadores apropiados para cada organización.
Las experiencias demostraron que con 20 o 25 medidas a traves de las 4 perspectivas descritas se podría implementar una estrategia simple, aunque la elección de las medidas apropiadas podría ser algo complejo, así como el hecho de ver las relaciones causa-efecto entre los diferentes indicadores (por ejemplo, como determinar que el aumento de la formación de los empleados, la inversión en tecnología o la innovación en productos pueden producir un aumento de los ratios financieros de la compañia en el futuro).
Los resultados del estudio y las experiencias posteriores de los autores fueron publicadas en el libro “Traslating Strategy into Action: The Balanced Scorecard”, del que vamos a tratar de hacer un pequeño resumen.
Necesidad de los cuadros de mando en la edad de la información
Los autores abren el libro con una comparación entre un avión y una empresa, entre un piloto y un gestor de compañias. En un moderno avión, todos nos quedariamos sorprendidos si entrasemos en la cabina y viesemos un sencillo cuadro de mandos con un solo instrumental. Pensariamos, ¿que medira este instrumental?, ¿el nivel de gasolina o la velocidad del aire?, ¿es suficiente para el caso de problemas?¿y la altitud?. Esta claro que un moderno avión necesita muchos indicadores que un piloto preparado es capaz de analizar para manejar el avión correctamente. Para el caso de las empresas, un gestor necesitara los correspondientes instrumentos que le monitorizen desde la situación actual hacia la situación futura.
Este es lo que ha de proporcionar el cuadro de mando o Balanced Scorecard. Este ha de traducir la estrategia de la empresa en un conjunto comprensible de medidas de rendimiento que proporcionen el marco de medida estrategica y de sistema de gestión. Los cuadros de mando van a seguir incluyendo los objetivos financieros tradicionales, pero ademas van a incluir los elementos para conseguir esos objetivos financieros, en un equilibrio a través de las cuatro perspectivas indicadas.
A esto habría que añadir que las compañias necesitan un instrumento para ser competitivas en los entornos empresariales actuales, de gran competencia, donde se hace necesario la gestión de activos intangibles que son fundamentales para competir con exito. Alguno de estos activos pueden ser las relaciones de clientes, innovacion de servicios y productos en nichos de mercado diferenciados, productos de alta calidad y bajo coste con tiempos de desarrollo cortos, desarrollo de tecnologias de información, bases de datos o sistemas, movilización de las habilidades de los empleados y su motivación para una continua mejora de los procesos, calidad o tiempos de respueta, etc.
En el modelo de contabilidad financiera tradicional, todos los nuevos programas, iniciativas o procesos de gestión del cambio se implementaban en un entorno gobernado por los informes financieros trimestrales y anuales, anclados en un modelo contable definido hace siglos. Este modelo todavia se sigue utilizando en todas las compañias, pero seria ideal poder complementarlo incorporando la información de los activos no tangibles de los que hablabamos antes.
De la colisión entre estos dos elementos surge una nueva sintexis, el Balanced Scorecard. Pero las medidas financieras hablan de la historia, del pasado, pero no ven como algo crítico las relaciones con los clientes o la inversión en capacidades a largo plazo. Y esas medidas son inadecuadas para las transformaciones que ha de realizar la empresa con el objetivo de crear valor en el entorno de las relaciones con clientes y proveedores, empleados, procesos, tecnología e innovación.
The Balanced Scorecard complementa las medidas financieras del pasado con las medidas de los indicadores de rendimiento futuro, expandiendo los objetivos de negocio mas alla de las medidas financieras. Con un sistema como este, los ejecutivos podrán medir las unidades de negocio que crean valor para futuros y actuales clientes y como ellas deben mejorar su capacidades internas y la inversión en los empleados, sistemas o procedimientos, capturando las actividades críticas de creación de valor. Aunque retiene la visión financiera del corto plazo, incluye la visión de largo plazo que revela las posibilidades financieras y de competitividad a largo plazo.
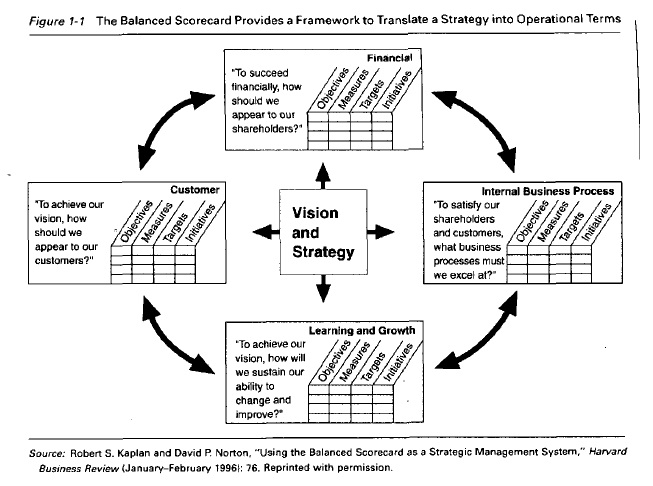
Ademas, ha de ser algo mas que un sistema de medición. Requiere a nivel de organización el establecimiento de unos objetivos estratégicos que incluyan los objetivos estratégicos de cada unidad de negocio. Con estos objetivos globales a nivel financiero y de cliente establecidos, la compañia identificara sus objetivos y medidas a nivel de procesos internos, que habrán de ser convenientemente comunicados a lo largo de la organización para involucrar a todos los participantes en los procesos internos. Finalmente, esos objetivos tendrán que ser traducidos a nivel operacional en cada ambito de la compañia. Podemos ver que podemos estar hablando de un cambio de rumbo dentro de la organización, partiendo del BS en un escenario habitual de 3 o 5 años.
Las 4 perspectivas del Balanced Scorecard.
Veamos un poco en que consiten las 4 perspectivas del Balanced Scorecard:
- La perspectiva financiera se sigue manteniendo porque es una forma de medir las consecuencias económicas de las acciones tomadas en las organizaciones. Incorpora la visión de los accionistas y mide la creación de valor de la empresa. Normalmente se referira a medidas como a la rentabilidad medida por los ingresos de explotación, rentabilidad sobre el capital empleado o sobre el valor económico añadido. Objetivos desde esta perspectiva podrían ser un aumento de las ventas o la generación de flujo de caja. Responde a la pregunta: ¿Qué indicadores tienen que ir bien para que los esfuerzos de la empresa realmente se transformen en valor? Esta perspectiva valora uno de los objetivos más relevantes de organizaciones con ánimo de lucro, que es, precisamente, crear valor para la sociedad.
- La perspectiva del cliente refleja el posicionamiento de la empresa en el mercado o, más concretamente, en los segmentos de mercado donde quiere competir. Aquí podremos tener medidas como son la satisfacción del cliente, retención y adquisición de nuevos clientes, rentabilidad, cuota de mercado en segmentos especificos, nivel de precios respecto a los competidores. Objetivos de este perspectiva podrían ser mejorar plazos de entregar, desarrollar nuevos productos o anticiparnos a las necesidades de los clientes. La perspectiva de cliente permitira a los gestores de las unidades articular las medidas a nivel de cliente y estrategias mercado para conseguir unos mejores resultados financerios en el futuro.
- La perspectiva interna pretende explicar las variables internas consideradas como críticas, así como, definir la cadena de valor generado por los procesos internos de la empresa. Será preciso llevar a cabo el análisis de la innovación de modo que partiendo de la identificación de las necesidades y demandas de los clientes, se desarrollen las soluciones idóneas para su satisfacción. Los procesos operativos, desde la recepción del pedido del cliente hasta la entrega del producto al mismo, vienen controlado por los indicadores de calidad, tiempo de ciclo, costos y análisis de desviaciones. Esta perspectiva finaliza con el servicio postventa que garantiza la adecuada atención y mantenimiento del cliente. La perspectiva interna también afecta a la perspectiva financiera, por su impacto sobre los conceptos de gasto.
- La perspectiva de aprendizaje y crecimiento identifica la infraestructura que la organización debe de construir para crear crecimiento y valor a largo plazo. La perspectiva de cliente e interna identifican los valores mas criticos para el exito actual y futuro. Pero no conseguiremos llevarlos a cabo si el uso de las tecnologías y capacidades adecuadas. Los recursos materiales y las personas serán la clave del éxito. Pero sin un modelo de negocio apropiado, muchas veces es difícil apreciar la importancia de invertir, y en épocas de crisis lo primero que se recorta es precisamente la fuente primaria de creación de valor: se recortan inversiones en la mejora y el desarrollo de los recursos.
Permite analizar la capacidad de los trabajadores para llevar a cabo los procesos de mejora continua, la actuación de los sistemas de la información y el clima organizacional que posibilite la motivación, la delegación de responsabilidades, la coordinación del proceso de toma de decisiones y la coherencia interna de los objetivos. La satisfacción de los trabajadores y su fidelización constituyen las premisas indispensables para el incremento de la productividad y la mejora continua del sistema. Las actividades y expectativas del personal han de estar alineadas con los objetivos generales de la empresa, de modo que el logro de las metas personales establecidas para los trabajadores vaya paralela al grado de consecución de la estrategia.
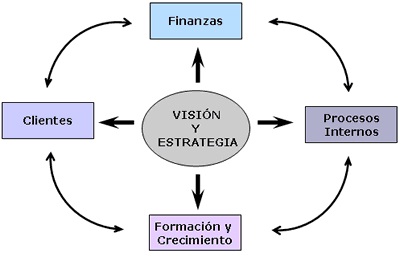
Perspectivas Cuadro Mando Integral
El Balanced Scorecard traslada la vision y estrategia a objetivos y medidas a traves de un conjunto equilibrado de perspectivas. Las cuatro perspectivas se ha demostrado que son suficientes para la mayoría de empresas e industrias. Pero solo hemos de considerar esto como un modelo, no como un patrón rígido. Puede haber compañias que no las utilicen todas u otras que añadan nuevas perspectivas según las características de su negocio u organización (por ejemplo, la perspectiva de los proveedores, de los empleados exclusivamente o de la comunidad, que puede en algunos casos ya estar incluida en las otras perspectivas).
Ademas de incluir una colección de indicadores críticos o factores clave de éxito, ha de ser también como un simulador de vuelo, incorporando el complejo conjunto de relaciones causa-efecto entre las variables más críticas. Pues, al fin y al cabo, una estrategia no es mas que un conjunto de hipotesis sobre causas y efectos. Y el sistema de medida debera establecer las relaciones e hipotesis entre los objetivos y medidas que pueden ser gestionadas y medidas. Esta cadena causa-efecto debera impregnar todos las perspectivas del Cuadro de Mando Integral.
Para permitirnos realizar un seguimiento del cumplimiento de los objetivos, el CMI deberá de incluir un conjunto de medidas e indicadores de rendimiento, que nos indicaran en que medida se esta cumpliendo la estrategia establecida. Ademas, habrá que tener en cuentaq que el CMI es principalmente un mecanismo para implementar o desarrollar estrategias, pero no para formulacion de ellas. Aunque si sera un magnifico mecanismo para traducir la estrategia en objetivos especificos, medidas y objetivos, y como elemento para monitorizar que se esta llevando a cabo correctamente en los periodos futuros. La comparación de los resultados que obtendremos de las medidas con respecto a los objetivos también nos permitirá establecer las acciones de mejora o corrección que habrá que realizar para reconducir o ajustar la situación.
La correcta selección de los indicadores reviste particular importancia, ya que estos han de explicar las razones del éxito o fracaso de la empresa, así como el impacto de las variables analizadas sobre los resultados. Además deben servir de alarma para poner en marcha acciones correctoras inmediatas ante determinados cambios detectados, para ello, los indicadores, han de ser asequibles y de fácil medida.
Medidas de las estrategias de negocio. Construccion del CMI
Las compañias que utilizan los CMI tendrán que realizar dos tareas para implantar un sistema de este tipo en sus organizaciones. Por un lado, habrá que construir el cuadro de mando. En segundo lugar, habrá que hacer uso de el, en lo que sería la fase de seguimiento y control. Las dos fases no son independientes, pues en el momento se comienze a utilizar, se empezara también su rediseño y ajuste, por ejemplo, en las medidas que no funcionen, en las que habrá que modificar o en las que habrá que añadir.
1. Diseño del Cuadro de Mando Integral. Diseño de los objetivos.
La elaboración del Cuadro de Mando Integral se inicia con la correcta planificación de los objetivos estratégicos y la adecuada definición de los factores claves que van a marcar la pauta de actuación y control a medio y largo plazo. Paralelamente debe existir y de hecho suele darse una alineación de los objetivos estratégicos planteados hacia aquel que representaría la máxima aspiración de la empresa. Así dicho objetivo primordial se despliega en abanico a través del planteamiento de otra serie de objetivos prioritarios de segundo rango y que a su vez se correlacionan con los objetivos parciales por departamentos o áreas específicas de actividad.
La elaboración de diagramas de causa-efecto permite en un primer momento enlazar el entramado de objetivos orientados a la meta última y posteriormente desarrollar el sistema de indicadores vinculados a aquellos. El sistema de objetivos debe mostrar en la medida en que sea factible esta vinculación causal de los mismos.
Los objetivos variaran según el estado en el que se encuentre una empresa, pues no es lo mismo una empresa en construcción con productos con gran capacidad de crecimiento (para las que se requeriran grandes inversiones iniciales) que una empresa consolidada en un sector maduro, donde habrá quizas el objetivo de mantener cuota de mercado o aumentarla (con el principal objetivo de la rentabilidad para los accionistas).
Los objetivos mas habituales según la perspectiva pueden ser:
- Perspectiva financiera: Crecimiento de los ingresos, reducción de costes / mejora de la productividad, Utilización de activos /retorno de inversión y Gestión de riesgos.
- Perspectiva cliente: Identificación de clientes y de segmentos de mercado, definición de productos y servicios, retención de clientes, captación o satisfación, beneficios del cliente. Imagen y reputación.
- Perspectiva interna: Identificación de procesos que son mas críticos para la captación de clientes y para cubrir los objetivos, mejoras en la cadena de valor interna (innovación, operaciones, servicio postventa)
- Perspectiva del aprendizaje y crecimiento: Identificación de inversiones para mejorar la capacidad del personal, sistemas y procesos de la organización, sin considerarlos desde el punto de vista financiero de gasto
2. Diseño del sistema de indicadores.
Una vez que se tienen claros los objetivos de cada perspectiva, es necesario definir los indicadores que se utilizan para realizar su seguimiento. Para ello, debemos tener en cuenta varios criterios: el primero es que el número de indicadores no supere los siete por perspectiva, y si son menos, mejor. La razón es que demasiados indicadores difuminan el mensaje que comunica el CMI y, como resultado, los esfuerzos se dispersan intentando perseguir demasiados objetivos al mismo tiempo. Puede ser recomendable durante el diseño empezar con una lista más extensa de indicadores. Pero es necesario un proceso de síntesis para disponer de toda la fuerza de esta herramienta.
La selección del conjunto de indicadores adoptados a los objetivos estratégicos previamente establecidos constituye un proceso laborioso, ya que el indicador ha de recoger con precisión el contenido del objetivo buscando la relación de causa-efecto entre ambos. Los indicadores, además de medir los resultados obtenidos deben facilitar la búsqueda de causas de ineficiencia y apuntar la orientación a seguir para la resolución de los problemas. Por otra parte, las fuentes de información requerida para su elaboración han de estar disponibles y ser de fácil accesibilidad.
A continuación relacionamos algunos de los indicadores más relevantes en relación con las perspectivas comentadas anteriormente. Los cuadros de mando han de adaptarse al nivel de decisión para el que se diseñan, siendo distinto, como cabe suponer, el de la dirección general de la empresa, que aquel que sirve de soporte decisional para un departamento o área concretos de la entidad. Cada departamento deberá prestar una atención especial a los indicadores que más relacionados están con su actividad. No se debe perder en ningún momento la visión global de la empresa, poniendo de manifiesto como los indicadores más importantes se alinean con la estrategia general de la misma.
Perspectiva Financiera
- Crecimiento de ventas: porcentajes de crecimiento de ventas o cuota de mercado por regiones, mercados o clientes. Crecimiento por segmentos de producto o por nuevos servicios/productos introducidos en un momento determinado. Porcentaje clientes no rentables.
- Reducción gastos / mejora de la productividad: ingresos por empleado, costes unitarios, comparación de costes con los competidores, porcentajes de reducción de costes, gastos indirectos, etc.
- Utilización de activos y capital: ratios de utilización de activos, ratios de generación de capital, retorno de inversión, etc.
- Tesoreria: ciclo de caja, cash flow, etc.
Perspectiva de los clientes.
- Cuota de mercado: proporcion de negocio en un mercado especifico (en termino de número de clientes, ingresos o unidades vendidas).
- Segmentación de mercados.
- Captación de clientes: medidas, en terminos absolutos o relativos, de los porcentajes de clientes ganados por una determinada unidad de negocio.
- Satisfacción de los clientes: medida de la satisfacción de los clientes de acuerdo con unos criterios especificos.
- Retención de los clientes: porcentajes, en terminos absolutos o relativos, de retencion o continuación de las relaciones con los clientes.
- Rentabilidad por cliente: indicadores de rentabilidad de los clientes (pueden estar referidos a mercados, a segmentos, a clasificación de estos, etc).
Asímismo son relevantes los indicadores relativos a:
- Los atributos de los productos y servicios: precios, tiempo de entrega, calidad.
- La relación de los clientes.
- La imagen y prestigio de la empresa.
- La creación de valor para el cliente.
Perspectiva de los procesos internos.
- Innovación e investigación básica o aplicada: porcentajes de ventas de nuevos productos o de productos propietarios, introducción de nuevos productos con respecto a los competidores, tiempo de desarrollo de nueva generación de productos, etc.
- Procesos operativos: costes, tiempos de servicio o producción, coste de inventarios, control de calidad (ratios de defectos, ratios de productos correctos en relación a los productos fabricados, devoluciones).
- Servicio postventa: costes de mantenimiento, porcentajes de averias.
Perspectiva Interna - Modelo de Cadena de Valor
Perspectiva de la formación y crecimiento.
Formación
- Nivel salarial/ salario medio
- Grado de calificación del personal
- Satisfacción de los trabajadores
- Nivel de ausentismo de los trabajadores
- Productividad de los trabajadores
- Nivel de seguridad e higiene en el trabajo (Numero de accidentes laborales)
- Estabilidad de los trabajadores
- Competencias de los trabajadores. Formación.
- Motivación: nivel de sugerencias y mejoras. Medidas de desarrollo de equipos.
Crecimiento
- Diseños de nuevos productos y mejora de productos
- Sistema de tratamiento de la información
- Sistemas de distribución de la información
- Inversiones en investigación y desarrollo
- Horas dedicadas a la investigación y desarrollo
- Resultados de la investigación y desarrollo
- Porcentaje de nuevos productos lanzados al mercado
- Acciones de protección al medio ambiente
Explotacion del CMI. El sistema de control (seguimiento).
Un buen sistema de control parte de la correcta definición de los presupuestos vinculados a cada una de las magnitudes previamente definidas como variable objeto de control especifico. La recogida de información ha de llevarse a cabo de forma rápida, sencilla y en tiempo oportuno, de modo que el análisis de las desviaciones y sus causas, así como las posibles acciones correctoras puedan desplegarse de forma eficaz. De igual modo, será preciso establecer un sistema de control de la efectividad de las modificaciones implantadas.
Un sistema integrado de control ha de tomar en consideración los siguientes aspectos:
- Definición de las variables objeto de análisis en cada área (factores clave e indicadores).
- Cuantificación de las variables.
- Comparación de los valores reales obtenidos con las previsiones y objetivos.
- Análisis de las causas de las desviaciones.
- Solución de las desviaciones.
El control integrado de gestión, mediante la utilización del cuadro de mando integral, facilita la búsqueda de productos con mayor valor añadido, la consecución de los objetivos de aumento de eficiencia, productividad y rentabilidad, la optimización del rendimiento de los factores y del proceso productivo en su conjunto, la obtención de la calidad total, particularmente en lo relativo a la atención a los clientes, así como la evaluación de la actuación de las personas.
Conclusiones
El cuadro de mando integral no es un documento único, se han de elaborar diferentes cuadros adaptados a cada uno de los departamentos o niveles de decisión de la empresa. El cuadro de mando integral no es un modelo estático, su carácter dinámico se evidencia, cuando al cuestionar la validez de la estrategia actual, surge otra, que puede responder más rápidamente ante las nuevas situaciones que se origina en su entorno. La adopción del CMI se debe apoyar en los sistemas de control de gestión (entre otros, contabilidad y presupuesto) porque por sí solo no podrá promover las modificaciones necesarias para su factibilidad.
La aportación que ha convertido al CMI en una de las herramientas más significativas de los últimos años es que se cimenta en un modelo de negocio. El éxito de su implantación radica en que el equipo de dirección se involucre y dedique tiempo al desarrollo de su propio modelo de negocio.
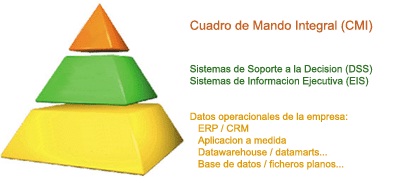
Cuadro Mando Integral
Beneficios de la implantación de un Cuadro de Mando Integral
- Define y clarifica la estrategia.
- Suministra una imagen del futuro mostrando el camino que conduce a él.
- Comunica la estrategia a toda la organización.
- Permite alinear los objetivos personales con los departamentales.
- Facilita la vinculación entre el corto y el largo plazo.
- Permite formular con claridad y sencillez las variables más importantes objeto de control.
- Constituye un instrumento de gestión.
- La fuerza de explicitar un modelo de negocio y traducirlo en indicadores facilita el consenso en toda la empresa.
- Una vez el CMI está en marcha, se puede utilizar para comunicar los planes de la empresa, aunar los esfuerzos en una sola dirección y evitar la dispersión. En este caso, el CMI actúa como un sistema de control por excepción.
- Permita detectar de forma automática desviaciones en el plan estratégico u operativo, e incluso indagar en los datos operativos de la compañía hasta descubrir la causa original que dió lugar a esas desviaciones.
Riesgos de la implantación de un Cuadro de Mando Integral:
- Un modelo poco elaborado y sin la colaboración de la dirección es papel mojado, y el esfuerzo será en vano.
- Si los indicadores no se escogen con cuidado, el CMI pierde una buena parte de sus virtudes, porque no comunica el mensaje que se quiere transmitir.
- Cuando la estrategia de la empresa está todavía en evolución, es contraproducente que el CMI se utilice como un sistema de control clásico y por excepción, en lugar de usarlo como una herramienta de aprendizaje.
- Existe el riesgo de que lo mejor sea enemigo de lo bueno, de que el CMI sea perfecto, pero desfasado e inútil.
Tarjetas de puntuación y Dashboard
Basándonos en el análisis de aspectos concretos de un area de actividad de la empresa o de un proceso de negocio concreto, podemos hablar de los Cuadros de Mando Operativo (CMO), es una herramienta de control enfocada al seguimiento de variables operativas, es decir, variables pertenecientes a áreas, actividades o departamentos específicos de la empresa. La periodicidad de los CMO puede ser diaria, semanal o mensual, y está centrada en indicadores que generalmente representan procesos, por lo que su implantación y puesta en marcha es más sencilla y rápida. Un CMO debería estar siempre ligado a un DSS (Sistema de Soporte a Decisiones) para indagar en profundidad sobre los datos.
Bajo esta consideración, y centrandonos en ambitos mas concretos, podemos hablar de los tableros de control o Dashboard como los documentos que muestran de una forma unificada los elementos clave de información que los componentes de una organización requieren para la realización de su trabajo de gestión, en un entorno grafico y altamente intuitivo e interactivo. Por ejemplo, un responsable comercial tendra uno o varios tableros de control donde se reflejara la información de ventas por diferentes criterios (geográfico, temporal, rentabilidad). Los tableros de control entran dentro del ambito de las tecnicas de sistemas de Business Intelligence.
Ejemplo de Tablero de Control (Dashboard)
Ademas, los cuadros de mando pueden sacar partido a otros elementos de los sistemas de Business Intelligence, como son los datawarehouse o las funcionalidades OLAP. Aunque los Dashboard los podriamos utilizar de forma autónoma, tienen más sentido en el ambito de una solución de BI. Igualmente, pueden formar parte de la estrategia de Cuadro de Mando Integral (como vimos anteriormente), como herramientas de control y seguimiento de la planificación, como herramienta de reporting o como herramienta de análisis, en el ambito de descubrir tendencias, oportunidades, etc.
Un cuadro de mando puede combinar indicadores de negocio, valores y componentes graficos para ayudar a la gestión o para mejorar el rendimiento de los empleados y encargados de la toma de decisión.
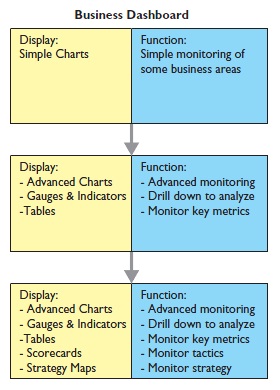
Evolucion de los tableros de control
Las ventajas de unos tableros de control bien construidos son evidentes y obvios, como por ejemplo:
- Mejora en la toma de decisiones y el rendimiento: facilidad para identificar y corregir tendencias negativas, posibilidad de llevar a cabo análisis no previstos, mejor toma de decisiones basado en la información recogida en un sistema de BI, etc.
- Mejora en la eficiencia de los empleados: incremento productividad, tiempos de analisis mas reducidos al fusionar varios informes en uno, reducción de tiempos de aprendizaje, reducción de la necesidad de crear nuevos informes.
- Motivación del empleado: el usuario puede generar nuevos informes siguiendo las nuevas tendencias, es mas agradable trabajar con graficos que con los viejos informes, el usuario utilizara mas tiempo en el analisis y menos en la elaboración de la información. Ademas, pueden ser una herramienta para compartir estrategias, tacticas y datos de los sistemas operacionales que permitan al empleado una mejor comprensión de objetivos y una mejor toma de decisiones.
El uso de los Dashboard se ha hecho cada vez mas popular en las organizaciones y actualmente incluye todos los ambitos de las empresas y organizaciones. Podemos distinguir principalmente tres tipos de dashboard, que serian:
- Estrategicos: soportan la alineacion organizacional con los objetivos estrategicos de una organización (como vimos en los CMI). Suelen ser informes de alto nivel de agregación que incluyen los indicadores de rendimiento alineados con los objetivos estrategicos de la empresa (por ejemplo, reducción de la devolución de produtos en un 2%, incremento de la retencionde empleados o mejora del flujo de tesoreria).
- Tacticos: soportan la medida del progreso de un proyecto o iniciativa en concreto. Nos permitiran realizar el seguimiento de estos proyectos o la validación de cumpliento de iniciativas en concreto con respecto a un objetivo. Los utilizaran normalmente los ejecutivos de nivel alto o medio (por ejemplo, seguimiento del proyecto de implantación de un nuevo sistema de control de calidad, incremento de las ventas en la zona X un 20% a traves de medidas promocionales, etc).
- Operacionales: soportan la monitorización de actividades de negocio especificas. Son normalmente los utilizados por los mandos intermedios o por los gestores departamentales. Se suelen usan con frecuencia para el trabajo diario y cotidiano dentro del ambito establecido (por ejemplo, ventas por departamento y mes con comparativa con el mes anterior, tablas de satisfacción de empleados, numero de llamadas gestionadas por el call center en el periodo, etc).
En la siguiente entrada del blog veremos la forma de construir nuestras tarjetas de puntuación o tableros de control (Dashboard) utilizando Microstrategy, en concreto utilizando los documentos de Report Services.
Cuadro de mando con Microstrategy
Bibliografía
The balance scorecard: translating strategy into action.
Kaplan, Robert S. Norton, David P.
ISBN: 978-0-87584-65 1-3
Monografia: El cuadro de mando integral como herramienta de Gestión.
Martinez Fernandez, Francisco (link a la publicación).
Business dashboards : a visual catalog for design and deployment.
Rasmussen, Nils Chen, Claire Bansal, Manish
ISBN 978-0-470-41347-0
Dashboard y Cuadros de Mando en Microstrategy 9. Utilizando documentos de Report Services (I).
Dashboard y Cuadros de Mando en Microstrategy 9. Utilizando documentos de Report Services (I). respinosamilla 25 February, 2010 - 09:50Como una componente avanzada para reporting y para la creación de cuadros de mando, tableros de control y tarjetas de puntuación, Microstrategy nos proporciona el producto Report Services.
Este producto también esta incluido en la Microstrategy Reporting Suite, aunque limitado el número de licencias a 2 usuarios. En el se trabaja con el concepto de Documento. Los documentos los utilizaremos para formatear la información proveniente de uno o varios informes en una interfaz simple con presentación de calidad. En un documento podremos incluir multiples elementos ademas de los que vimos al analizar el reporting (layout, imagenes, bordes, controles, pestañas, widgets). En un mismo documento podremos tener diferentes componentes relacionados entre si o no, a los que ademas podremos dar dinamismo con el uso de controles, listas de selección, botones, pestañas o permitiendo la navegación y el uso de las funcionalidades de reporting.
Los documentos introducen el concepto de conjunto de datos. Un documento podrá tener varios conjuntos de datos. El conjunto de datos lo define un informe estandar, que se asociara al documento y determinara el conjunto de información que recuperara el Intelligence Server y que podrá ser utilizada en el documento de diferentes maneras. Ademas de los conjuntos de datos, habrá otra mucha información referente al diseño del documento que quedara guardada en la definicion de este.
Para trabajar con los documentos es necesario conocer los informes de Microstrategy y todas las funcionalidades que vimos en las correspondientes entradas del blog ( Reporting en Microstrategy I, Reporting en Microstrategy II y Cubos Olap). El conocimiento avanzado del reporting nos permitira sacar más partido a los documentos.
Diseño de Documentos.
El diseño de documentos lo podemos realizar bien desde la interfaz Web, o desde el entorno Windows con la aplicación Desktop. En nuestro caso, vamos a trabajar con la aplicación Desktop para el diseño y los resultados los mostraremos en la interfaz Web.
Basicamente, podemos trabajar con dos tipos de documentos, los que se llaman General y los Tableros. Los documentos del tipo General esta orientados a la generación de formularios o documentos estáticos del tipo PDF, como por ejemplo, para generar facturas o informes, donde queramos tener una serie de secciones, con marcadores, titulo,encabezado, pie de pagina. Aunque se podrán utilizar para generar también documentos dinamicos, estan orientados a la impresión o a la exportación en otros formatos.En la imagen podeis ver el editor de Documentos, con un documento de este tipo. Mas adelante entremos un poco mas a fondo en este tipo de documentos.
Editor de Documentos - Tipo de Documento General
Por otro lado, tenemos los documentos del tipo Tablero, orientados a la creación de tableros, tarjetas de puntuación y cuadros de mando. Documentos que tratan de concentrar en un unico pantallazo (aunque pueda tener varias secciones o pestañas), toda la información. Con una presentación de calidad, gráfica e intuitiva para permitir el analisis de la información de una forma fácil. En la imagen posterior, podeis ver el diseño de un cuadro de mando para analizar la información por comercial. Es un informe dinámico, donde al seleccionar el agente comercial que queremos analizar, se actualizaran los otros 3 controles del tablero, uno donde se analizan las ventas por linea de producto, otro por region y en el gráfico la evolución mensual de ventas.
Editor Documentos - Tablero
Los documentos, una vez construidos y ejecutados, se pueden visualizar de varias maneras y exportar en varios formatos, y por eso habrá características de los documentos que serán especificas para cada uno de los formatos. Por ejemplo, podemos trabajar en modo PDF, en modo editable, en modo Html o en modo Flash. El formato PDF incluira propiedas para paginación, creación de secciones o marcadores, etc. Para el caso de la visualización Flash, tendremos controles o widgets que solo funcionaran en este modo. Es importante conocer esto para decidir que tipo de presentación utilizar para cada documento y realizar el diseño de forma adecuada.
Vamos a ver un poco mas en detalle la interfaz de usuario del editor de documentos antes de profundizar en los elementos de cada tipo de documento y construir finalmente varios ejemplos de Dashboard.
Editor de Documentos.
El editor de Documentos es el elemento central desde el cual vamos a realizar el diseño nuestro documentos y tableros. Como ya hemos indicado, podríamos realizar el diseño de los documentos desde el entorno Web, pero en nuestro caso nos vamos a centrar en el Desktop. Via Web la funcionalidad es muy similar y hay pequeñas diferencias.
Los componentes del editor de documentos son los siguientes:
- Menú: en la parte superior de la pantalla, nos ofrece las diferentes acciones y elementos con los que podemos trabajar al diseñar los documentos. Es un menú contextual, de forma que cambian las opciones según el elemento que tengamos seleccionado en el area de diseño. Por ejemplo, si en el area de diseño hemos incluido una cuadricula, cuando esta este seleccionada y estemos en modo edición dentro de ella, en el menú nos aparecerán las opciones tal y como si estuvieramos trabajando en el editor de informes (pues una cuadrícula no es, al fin y al cabo, mas que un informe embebido en el documento). Por ejemplo, en ese caso nos aparecerán las opciones para definir umbrales sobre los indicadores, formatear los valores o encabezados de filas y columnas, cambiar el estilo de la cuadricula, etc, etc. Esto nos recuerda, como ya hemos indicado, lo importante que es conocer al fondo todas las caracteristicas del reporting, pues al fin y al cabo seguimos utilizando por debajo los mismos elementos que ya vimos.
- Barras: tenemos varias barras de herramientas con las que podemos trabajar con los diferentes elementos de una forma rapida. Las barras son las siguientes: General (botones para guardar y guardar como), Modificar (botones para copiar, pegar, eliminar, deshacer y hacer zoom en el diseño), Ver (botones para cambiar el modo de visualización del documento y para seleccionar si vemos o no las diferenets secciones de la pantalla, Controles (botones para la inserción rapida de controles en el documento) y Formato (botones para el formateo de los elementos, como tipo de letra, estilo del documento, formato de numeros, etc).
Editor Documentos
- Area de Diseño: es la zona del editor donde realizamos la definición de como sera nuestro documento. Tenemos una cuadrícula donde iremos incluyendo los diferentes elementos. El Area de Diseño tiene varias secciones predefinidas que podemos visualizar o no (aparte de las secciones que podremos añadir nosotros). En la imagen, podemos ver el area de diseño en la parte inferior-central derecha.
- Conjutos de datos: los documentos no tienen sentido sin conjuntos de datos vinculados que podamos mostrar utilizando los diferentes componentes de los documentos. Como hemos indicado antes, un documento puede tener uno o varios conjuntos de datos. Los conjuntos de datos se asocian al documento a través de los informes que tendremos construidos en nuestro sistema y que añadiremos al documento. Al incluir un informe, aparecen todos sus atributos e indicadores en la sección Conjuntos de datos, tal y como vemos en la imagen, en la parte izquierda del editor de documentos. Todos los elementos definidos en el informe los podremos utilizar para crear, por ejemplo, cuadriculas, graficos, listas de elementos o para incluirlos en alguno de los widgets que nos proporciona Microstrategy.
- Listas de propiedades: podemos modificar las propiedades de cualquier elemento con el menú contextual del boton derecho, o seleccionado el elemento y visualizando la sección Lista de propiedades. La lista de propiedades es dinámica, pues cada objeto tiene unas propiedades diferentes y por tanto, diferentes características que se podran definir para cada uno de ellos.
Antes de empezar a trabajar con los diferentes tipos de documentos, vamos a ver los diferentes modos de trabajo y visualización que podemos utilizar con los documentos. Vamos a diferenciar cuando trabajamos con el Desktop y cuando trabajamos desde el portal Web (para ver que el portal Web es mas completo en este aspecto):
- Desktop:
- Vista Diseño: es el modo que utilizamos para realizar el diseño de los documentos. En este modo podremos insertar conjuntos de datos, controles como cuadriculas/graficos, campos de texto, lineas, formas y paneles. No podremos en este modo trabajar con los widgets de Flash.
- Vista PDF: se visualiza el documento como si fuera un pdf estatico. No podremos modificar o crear documentos, ni modificar las propiedades del que estemos visualizando.
- Visualización Html: visualización preeliminar de un documento en modo HTML. No se puede cambiar nada de el.
- Visualización Flash: visualización preeliminar de un documento en modo Flash. No se puede cambiar nada de el.
- Exportación: formato PDF, Excel, Html o Flash.
- Web:
- Modo Diseño: es el modo que utilizamos para realizar el diseño de los documentos. En este modo podremos insertar conjuntos de datos, controles como cuadriculas/graficos, campos de texto, lineas, formas y paneles. No podemos cambiar algunos aspectos de las cuadriculas/gráficos (como valores de indicador y encabezados de atributos), ni el formato a los widgets flash o paginacion para agrupar datos u ordenar informes de cuadricula.
- Modo Editable: es similar al modo anterior, pero incluyendo la visualización de datos reales. Permite todas las operaciones sobre los controles, excepto aplicar formato a propiedades flash de los widgets. Al incluir datos, el rendimiento es peor.
- Modo Interactivo: modo interactivo, de ejecución de los informes. No permite crear documentos nuevos, pero si editar el formato de cuadriculas/graficos, ordenar los informes y mover los objetos de estos, agregar totales, cambiar tamaño de filas y columnas o crear indicadores calculados. No se puede aplicar formato al diseño ni a los controles widgets.
- Modo Flash: similar al interactivo, pero ademas permite interactuar con los widgets de Flash, y modificar su formato.
- Modo Vista: se visualiza el documento como si fuera un pdf estatico. El documento no es interactivo. No podremos modificar o crear documentos, ni modificar las propiedades del que estemos visualizando (similar a la vista PDF del Desktop).
- Exportación: formato PDF, Excel, Html o Flash.
Propiedades básicas de los documentos
Los documentos tienen un conjunto de propiedades básicas, que estan agrupadas por secciones, en las que podemos indicar:
- Configurar página: se define el tamaño del papel, orientación, escalas, margenes, etc.
- Propiedades de Diseño: colores y bordes del documento, secciones que forman el documento, etc.
- Propiedades del documento: estilo por defecto para las cuadriculas que se incluyan en el, modos de visualización disponibles (podremos hacer que un documento solo se pueda ver, por ejemplo, en modo Flash), formatos de exportación permitidos, modo de ejecución por defecto del documento, propiedades de exportación (por ejemplo, si al exportar a PDF se incluiran marcadores o se mejorara la resolución de gráficos).
Propiedades de un documento
Los objetos mas importantes que podemos utilizar en los documentos son:
- Texto: casillas con texto que podremos formatear de la forma deseada.
- Imagen: imagenes en los formatos bmp, jpg o gif.
- Lineas: lineas graficas para mejorar nuestro diseños.
- Formas: rectangulos o rectangulos redondeados que podremos formatear.
- Informe: incluir un informe dentro del documento (al incluirlo, se añade en el conjunto de datos los atributos e indicadores que forman este informe).
- Cuadricula: incluimos una cuadricula similar a la que utilizamos al crear un informe. Una vez creada la cuadricula, se le incorporan los atributos e indicadores deseados de los disponibles en el conjunto de datos.
Objeto del tipo cuadricula
- Grafico: gráficos de todos los tipos disponibles en los informes.
- Pila de paneles: paneles para crear areas de objetos diferenciadas dentro del documento.
- Contenedor HTML: objeto que contendra código HTML personalizado.
- Selector: objetos que nos permiten establecer criterios de seleccion dinámicos dentro de los documentos ( listas desplegables, casillas de verificacion, botones de opcion, cuadros de lista de valores, selección de fecha, barra de vinculos).
Selector del tipo Cuadro de lista de valores
- Texto automatico: campos de texto automatico (numero de pagina, identificador de usuario, fecha/hora actual, nombre del documento, valores de las selecciones dinamicas utilizadas o de los filtros, etc.).
- Widgets Flash: solo se pueden añadir editando los documentos desde el portal Web. Incluye elementos como los siguientes: Cuadricula de burbujas, cilindro, nube de datos, selector de fechas, ojo de pez, embudo, indicador, matriz de graficos, mapa de calor, grafico de burbujas, grafico apilado interactivo, medio, micrograficos, lector de rss, termometro, barra de desplazamiento de serie temporal, cascada o visor de lista ponderada.
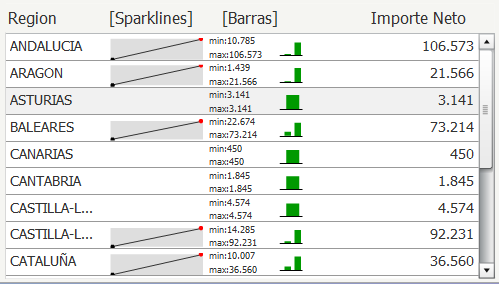
Widget Flash - Micrograficos
Asignación de conjuntos de datos a documento. Construcción de tablas y graficos a partir de informes o conjuntos de datos.
Cuando vinculamos un informe a un documento, todos los filtros y selecciones dinamicas de este se asocian tambien al documento,y en el caso de ser dinamicas, se ejecutaran cuando lanzemos el documento. Si vinculamos varios informes al documento y comparten el mismo filtro o selección dinámica, solo se ejecutará una vez. En el caso de que haya varias diferentes, podremos definir el orden en que seran ejecutadas.
Desde el panel de conjunto de datos podremos crear nuevos indicadores calculados utilizando los indicadores existentes en cada conjunto de datos (informe). Desde este mismo lugar podremos acceder a la modificación del informe original desde el cual se extraen los datos (puede ser util para agilizar el proceso de diseño).
Cuando en un documento añadamos cuadriculas o graficos, los podremos llenar arrastrando a filas y columnas los elementos que deseemos incluir en él (atributos, indicadores o indicadores calculados), formando un nuevo informe dentro del documento (que extrae su información del conjunto de datos ). De esta forma, utilizando el mismo origen de datos se pueden construir multiples cuadriculas/graficos con diferente información mostrada (que cogen la información del mismo sitio, del conjunto de datos que define el informe). En una cuadricula no se podrán combinar atributos o indicadores que provengan de conjuntos de datos diferentes.
Vinculación entre objetos.
Cuando en un documento disponemos de varios objetos del tipo tabla o grafico, podemos hacer que los datos que se visualizan dependan del valor de otro componente del documento (por ejemplo, una casilla de selección o una lista de valores). Esto se consigue a traves de la propiedad avanzada “Dirigido por”. Por un lado, en el objeto destino indicaremos que atributo es el que modifica la información mostrada en el (tal y como vemos en la imagen).
Atributo de dirige un control
Además, en el objeto Selector del tipo lista de valores (en que determinara el comportamiento de los otros objetos), indicaremos los destinos seleccionados. Son los objetos cuyo contenido se modifica al seleccionar un determinado valor de atributo en el selector (y por tanto, varia la información que se muestra en ellos).
Destinos que controla un objeto del tipo selector
Por ejemplo, imaginar una lista de valores con las diferentes regiones de un pais. Al seleccionar una región, podremos hacer que las cuadriculas o gráficos del documento solo muestren los valores de ella. O al seleccionar el valor Total, se muestren los importes de todas las regiones.
Una vez realizada la introducción de los componentes de un documento y despues de ver de forma general la forma de vincular los objetos que hay en él, vamos a diseñar un lote de ejemplos para hacernos una idea de las posibilidades de la herramienta Microstrategy.
Ejemplo de Documento General. Informes de ventas enviado a las delegaciones en PDF.
Para ver un ejemplo de un documento del tipo general, vamos a construir un informe de Evolución de Ventas por Region y Provincia trimestral. Será un informe estático que sera enviado por correo a las delegaciones en formato PDF. Se trata de darle una presentación atractiva pues será un documento corporativo.
Al crear el documento, seleccionamos que sea del tipo General. En ese momento, nos aparece la cuadrícula de diseño, donde podemos ver las diferentes secciones del documento ( Encabezado de página, encabezado de documento, detalle, pie de detalles, pie de documento y pie de página). Se puede controlar facilmente que secciones se visualizan y cuales no, desde las propiedades del documento, tal y como vemos en la imagen:
Secciones de un documento
En cada sección podremos ir incluyendo los diferentes objetos de diseño de los vistos anteriormente, asi como ir cambiando las propiedades de cada sección (tamaño, color, formato). En nuestro caso, insertarmos en encabezado de documento una portada para nuestro documento, con un texto y una imagen. En encabezado de página pondremos un titulo que se mostrará en todas las páginas del documento, de la misma manera que en pie de página mostraremos el número de página actual del documento.
Como queremos ir sacando la información de cada región detallada, vamos a asociar el documento a un informe que ya teniamos realizado, llamado ventas por Región, Provincia y Trimestre. Asociamos el informe con la opción Datos –> Agregar conjunto de datos, seleccionando el informe del repertorio definido en nuestro sistema. Podemos ver en la imagen siguiente como aparece, en la parte izquierda del documento, el nombre del informe y los indicadores y atributos de este en la sección Conjuntos de Datos.
Llevamos el atributo Región a la zona de paginación del documento (zona superior del documento, justo encima de la barra de cuadricula ). Al añadirla, aparecen en el documento dos nuevas secciones, llamadas Encabezado de Región y Pie de Región. Esto significa que vamos a realizar paginación sobre el valor de este atributo (aunque podremos configurar el comportamiento de la sección, para decir por ejemplo, si queremos que se cree una pagina nueva o no u otros aspectos). Incluimos en la primera de ellas el texto Región y un campo variable a continuación para que se muestre el nombre de cada región.
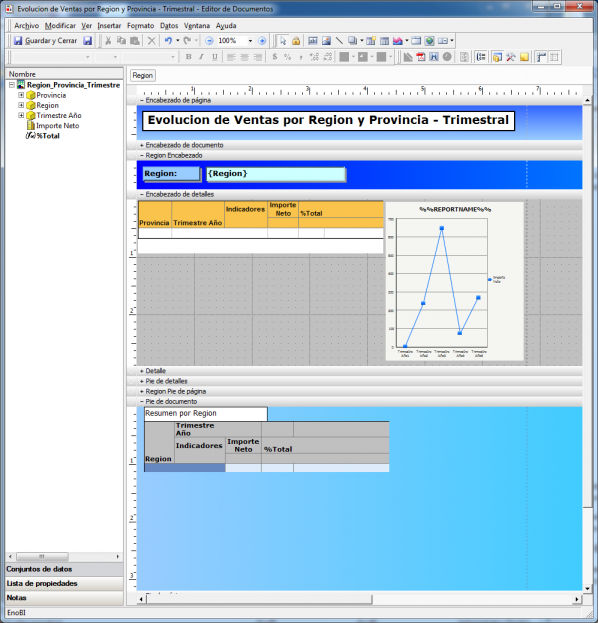
Ejemplo documento general
A continuación, construimos, en la sección Encabezado detalles una cuadricula y un gráfico. Para ello, insertamos primero el control y a continuación le añadimos los atributos e indicadores deseados arrastrandolos y dejandolos caer sobre el control. Cuando se hace doble click en el control del tipo cuadricula, se puede editar ademas la disposición de filas y columnas, así como realizar ajustes en el formato, añadir umbrales, totalización o crear indicadores calculados. En la cuadricula veremos una evolución de las ventas por provincias y trimestre del año, añadiendo un porcentaje de ventas sobre el total (solo se veran las ventas de las provincias de cada región). En el gráfico, veremos solo el total de ventas de cada región, desglosado por trimestre para ver de una forma gráfica la evolución.
En la sección Pie de página insertaremos textos del tipo automatico para sacar la paginación de las diferentes páginas que se generen al construir el documento:
 Finalmente, para cerrar el documento, insertamos en la sección Pie de documento otra cuadricula que será un resumen general incluyendo los datos de todas las regiones por trimestre, incluyendo igualmente el porcentaje sobre el total para ir viendo el peso de las diferentes regiones a nivel trimestral y a nivel total. El documento, una vez ejecutado y generado el correspondiente PDF, quedará de la siguiente manera:
Finalmente, para cerrar el documento, insertamos en la sección Pie de documento otra cuadricula que será un resumen general incluyendo los datos de todas las regiones por trimestre, incluyendo igualmente el porcentaje sobre el total para ir viendo el peso de las diferentes regiones a nivel trimestral y a nivel total. El documento, una vez ejecutado y generado el correspondiente PDF, quedará de la siguiente manera:
En el documento PDF se han generado los marcadores para cada región, lo que nos permite de una forma ágil ir directamente al contenido deseado seleccionando la región en el panel. Los paneles se pueden obviar cuando se diseña el documento (indicando que cuando el documento se exporte a PDF no se generen estos).
.png)
Marcadores en el documento PDF generado
Podemos ver en el ejemplo que con un unico conjunto de datos (informe vinculado al documento), hemos podido mostrar la información en varios sitios y con diferentes estructuras y niveles de detalle. Por tanto, siempre tendremos que tener definidos de antemano el conjunto de informes consistentes que nos permitan construir los documentos con la información que queremos.
En la siguiente entrada del Blog realizaremos varios ejemplos de Documentos del tipo Tablero, para entrar de forma profunda en esta funcionalidad y poder analizar sus ventajas e inconvenientes.
Dashboard y Cuadros de Mando en Microstrategy 9. Utilizando documentos de Report Services (II).
Dashboard y Cuadros de Mando en Microstrategy 9. Utilizando documentos de Report Services (II). respinosamilla 25 February, 2010 - 09:50Ejemplo de Tablero. Analisis de Agentes Comerciales, Productos y Regiones.
En nuestro primer ejemplo de documento del tipo tablero, vamos a intentar construir un cuadro de mando donde se resuma la evolución de un año en concreto viendo la información desde diferentes ambitos, en concreto, a nivel de Agente Comercial por un lado, a nivel de Producto y a nivel Geografico finalmente. Para cada uno de estos ambitos, tendremos una pestaña (y un conjunto de informes y graficos en cada una de ellas).
Para poder hacer esto, hemos preparado un lote de informes que, anexados al documento como conjuntos de datos, nos permitiran mostrar la información de la forma deseada.
Pestaña Agentes
En esta sección tendremos 5 componentes, de los diferentes tipos que podemos utilizar en los documentos, que son:
- Selector (del tipo cuadro de lista): este control estará asociado a los valores del atributo Agente Comercial. En el control se mostrara la lista de todos los agentes que tienen ventas en el periodo y un atributo Total (para el total de todos ellos). Este valor aparecerá marcado por defecto. Los controles Evolución Mensual Ventas por Agente y Ventas Anuales por Región estarán vinculados al selector, de forma que al cambiar el valor seleccionado, la información de los otros controles variara dinamicamente.
.jpg)
Selector de Agente
- Gráfico Evolucion Mensual Ventas por Agente: grafico de tipo Linea Vertical donde veremos la evolución mensual de importe de ventas, unidades y margen para el agente seleccionado.
- Tabla Ventas Anuales por Región: tabla donde veremos, para el agente seleccionado, los volumenes de ventas, unidades y margen detallados por región.
Ademas, tendremos dos componentes mas que no van a depender del agente seleccionado:
- Tabla Ventas Anuales por Agente: incluye las ventas de todos los agentes, con el porcentaje sobre el total de ventas, el ranking. el porcentaje de margen y un indicador de umbrales para detectar rentabilidades bajas o negativas.
- Grafico Evolución Anual por Agente y Linea Producto: grafico de tipo Area Vertical para analizar comparativamente todos los agentes y el peso de las diferentes lineas de producto en sus ventas.
Los cinco controles descritos estan todos vinculados a dos conjuntos u origenes de datos (informe Comercial – Mes los cuatro primeros y para el ultimo gráfico el informe Comercial – Linea Producto).
El resultado final del diseño, incluyendo todos los elementos mencionados será el siguiente (podemos ver la ejecución en modo interactivo).
.jpg)
Ejemplo de Tablero - Información de Agentes Comerciales
Podeis observar que en el cuadro selector de agentes aparece marcado el valor Total. Al ir cambiando el valor seleccionado, se ira actualizando la evolución mensual por agente y la tabla de ventas por región, permaneciendo los otros dos controles fijos (pues muestran información global).
Pestaña Producto
En esta pestaña dispondremos de 4 componentes, con el objetivo de ver de forma rapida la evolución anual de ventas por atributos de la dimension Producto.
- Grafico/Tabla Evolución Ventas Mensual por Linea Producto: grafico de tipo Area Vertical para analizar la evolución mensual de las ventas por Linea de Producto. También se incluye la visualización de la tabla de datos para darle contexto al gráfico.
- Tabla Ingresos por Varietal: ingresos anuales por variedad de uva.
- Grafico/Tabla Ingresos por Target: ingresos anuales por Target de Mercado del producto. El grafico será del tipo Circular (tarta) para ver el peso de cada elemento dentro del total. Ademas se visualiza la información del gráfico en forma de tabla para darle contexto al gráfico.
La visualización de la pestaña al ejecutar es la siguiente:
.jpg)
Ejemplo de Tablero - Información de Productos
Todos los componentes de esta pestaña estan asociados al conjunto de datos Producto – Mes (es un informe que obtiene la información de ventas con los atributos linea de producto, mes, target y varietal). De esta forma, con un unico informe estamos viendo 3 visiones diferentes de la información en el tablero.
Pestaña Region
En esta sección del informe pretendemos analizar la información anual de ventas desde un punto de vista geográfico. Para ello, incluimos los siguientes componentes:
- Tablas ventas anuales por región: tabla donde visualizaremos los importes de ventas, unidades y margen detallados por región. Ademas, incluiremos el peso de cada región en cada indicador (porcentaje sobre el total). Como elemento nuevo, haremos que el valor del atributo región sea un selector, de forma que algunos de los componentes de la pestaña se actualicen según la región seleccionada.
- Tabla ventas anuales región – material: en esta tabla apareceran los 10 productos con mas ventas de la región seleccionada.
- Tabla ventas anuales por provincia: en tabla aparecera, para la región seleccionada, el detalle de ventas de cada provincia, incluyendo el porcentaje de ventas sobre el total general.
- Grafico ventas anuales por provincia: igual que el componente anterior, pero en forma de grafico circular (para ver los pesos de cada provincia), veremos los importes de ventas y unidades.
- Tabla ventas anuales región – cliente: en esta tabla apareceran los 10 clientes con mas ventas de la región seleccionada.
- Tabla resumen anual por Zonas Geográficas: en esta tabla apareceran los volumenes de ventas anuales con la clasificación de las regiones por Zonas (utilizando para ellos los elementos derivados).
La visualización de la pestaña Región al ejecutar es la siguiente:
.jpg)
Ejemplo de Tablero - Información de Regiones
Para la construcción de los controles de la pestaña hemos utilizado 3 informes (ventas por Región – Cliente para el top 10 de clientes, ventas por Región – Material para el top 10 de materiales y el resto con el de ventas por Región – Provincia). Conforme vayamos cambiando la selección de la región en el control principal, se iran modificando la información detallada por provincia y los top 10 de clientes y materiales de esa región.
Ejemplo de Tablero. Evolución de Ventas por Linea de Producto.
El siguiente ejemplo es un tablero de analisis de evolución de ventas, pero centrandonos en el analisis del atributo Linea de Producto dentro de la dimensión Producto. Ademas, en este tablero vamos a utilizar widgets Flash, que de paso nos servirá para ver algunos inconvenientes de la posibilidad de ver los documentos en varios formatos (problema en el uso de componentes y visualización de los formatos diferente). El periodo de analisis es un rango de fechas, que indicaremos al ejecutar el documento (en lugar de un periodo anual como en el informe anterior).
El tablero se gobierna por un control selector del tipo Barra de Botones, asociado a los valores del atributo Linea de Producto (lo podeis ver en la parte superior del tablero, debajo del título). Este control va a determinar la información que se visualiza en todos los demas controles del tablero, que son:
- Grafico Evolución mensual de ventas por Linea de Producto: para la linea de producto seleccionada, veremos la evolución de ventas por mes, tanto a nivel de ingresos como unidades vendidas, en un grafico de lineas vertical. Incluimos en el gráfico los valores de indicadores en cada punto de la linea.
- Grafico barra de desplazamiento de serie temporal: es un widget flash que nos permite desplazarnos por una serie temporal e ir viendo de forma gráfica los resultados. En nuestro caso, la serie temporal la determinara el atributo día, y para cada dia, veremos la evolución de importes y unidades vendidas. La información visualizada correspondera a la linea de producto seleccionada. Nos podremos ir moviendo por la serie temporal en el gráfico guia superior, de la misma manera que podremos ir haciendo mas grande o pequeño el periodo de analisis que se visualizara en el gráfico inferior).
- Conjunto de marcadores para analisis de target: utilizando widget flash del tipo indicador, vamos a contruir un conjunto de ellos para ver la evolución de ventas por Target de Mercado por un lado y por otro lado, la comparativa entre las ventas reales y las presupuestadas en el periodo (en los marcadores de la derecha). De la misma manera que en los controles anteriores, solo vemos la información de la linea de producto seleccionada.
- Tabla analisis de rentabilidad mensual: para la linea de producto seleccionada, veremos un analisis detallado de varios conceptos por mes. En concreto, veremos las ventas y su peso sobre el total global; el precio medio de venta, el margen absoluto, el porcentual y su peso sobre el total global y finalmente el numero de pedidos y el importe medio de cada pedido.
La ejecución en modo flash del documento sería la siguiente (es necesario para visualizar correctamente los widgets flash).
.jpg)
Ejemplo de Tablero - Analisis de Linea de Producto
En este caso, hemos utilizado tres origenes de información (Linea de Producto – Mes para la evolución de ventas mensual y el analisis de rentabilidad, Linea de Producto – Fecha para la serie temporal por día y Linea de Producto – Target para el conjunto de marcadores).
Podeis descargaros la exportación en Flash del tablero aqui. Podreis ver como funciona de forma dinamica el informe (como si lo estuvierais ejecutando, aunque con un conjunto de datos concreto). Es necesario descargar el fichero a disco y entonces abrirlo con el Internet Explorer (permitiendo la ejecución de los controles ActiveX que lleva incluidos el Flash).
Algunas consideraciones sobre el uso de documentos.
En nuestro caso, hemos utilizado la herramienta Desktop para el diseño inicial de los documentos. En este entorno de trabajo, construimos los documentos y realizamos una previsualización en modo PDF o en modo Flash para ir viendo como queda la presentación (con limitaciones respecto a los ajustes de formateo o de propiedades de los controles widgets, por ejemplo).
Cuando incluimos los objetos en el informe, siempre tenemos el menú contextual sobre ellos con el que podemos modificar las propiedades generales (tamaño, colores, relación con otros objetos, efectos, titulos, filtro sobre el elemento (solo a nivel de atributos), conjuntos de datos al que esta asociado el elemento, etc.). El menú contextual va variando según el elemento que tenemos seleccionado, mostrando opciones diferentes según el tipo de componente. Al incluir gráficos, tablas o controles widget, al hacer doble click en el elemento (o selecciónando la opción modificar en el menú contextual), entramos en modo edición sobre el y podremos cambiar aspectos particulares (por ejemplo, en una tabla podremos los atributos e indicadores incluimos en el, estilo de la tabla, indicadores calculados, subtotales, umbrales, formato de visualización (tamaño de fuente, colores, tipo de letra), elementos derivados, ordenación, tamaño de filas y columnas en la visualización, etc. En un gráfico en el modo de edición podremos seleccionar el tipo de gráfico, titulos y todos los atributos especificos del gráfico, según el tipo de este, etc). Cuando estamos en el modo edición de un objeto, en el menú general aparecen las opciones correspondientes al objeto (por ejemplo, para una cuadricula aparecen las opciones Insertar, Formato, Datos, Cuadricula, Mover, etc.).
.jpg)
Modo diseño en Entorno Web
Siempre que utilicemos un gráfico dentro de un documento (igual que cuando realizabamos informes) o al incluir un widget, nos pasaremos al modo tabla del objeto para añadir los atributos e indicadores necesarios (recordar que cada tipo de gráfico o widget tiene unos requerimientos de atributos e indicadores en filas y columnas para poder funcionar). Una vez ajustados estos elementos, volveremos a pasar la visualización al modo gráfico para ver como quedara el objeto en las previsualizaciones. Esto no será necesario para algunos widget que no estan asociados a datos (como, por ejemplo, el lector rss o el editor de seleccion de fechas).
Cuando tenemos los documentos bastante elaborados, es el momento de realizar los ajustes en el formato, y para ello es recomendable hacerlo desde el entorno Web. En este entorno, como ya vimos, tenemos varios tipos de visualización. Los tipos de visualización son los siguientes (ademas del modo diseño):
- Modo Editable: es similar al de diseño, pero los controles se muestran con información, de forma que nos podemos hacer una idea de como quedara el formato de los resultados. En este modo se pueden realizar todos los ajustes del modo diseño vistos. Los widgets flash no funcionan y no se pueden cambiar los atributos de visualización de este tipo de objeto. Por ejemplo, este modo es ideal para realizar ajustes en los tamaños de filas y columnas, pues estamos viendo los controles con información real (este ajuste también se hace en el modo diseño, pero a ciegas, pues no vemos el resultado con datos).
Modo Editable - Cambio tamaño filas y columnas
Tanto el modo diseño como el modo editable son modos orientados al diseñador de los documentos. Los modos siguientes son modos de ejecución:
- Modo Vista: es un modo estático, como si estuvieramos viendo el resultado de ejecución del informe en un Pdf. No se puede realizar ningún ajuste y los widgets flash no funcionan.
- Modo Interactivo: es un modo de ejecución y en el no podremos cambiar ningun aspecto del diseño del documento. Solo podremos cambiar aspectos relacionados con los componentes que forman el documento, de los modificables en tiempo de ejecución. Por ejemplo, en una tabla, tal y como vemos en la imagen, podremos navegar por los atributos en el caso de que lo hayamos permitido, realizar ordenación, totalización, ajustar los filtros de visualización, mover los elementos o quitarlos, formatear los campos, cambiar el nombre de representación, crear elementos derivados o cambiar tamaño de filas y columnas (sería similar a cuando ejecutabamos un informe en el módulo de reporting, pues tenemos casi las mismas opciones de ajuste de los resultados de un informe). Y ademas nos permite el uso de Elementos derivados, que en la parte de reporting era exclusivo de los informes sobre cubos inteligentes.
- Modo Flash: es igualmente un modo de ejecución. Las opciones de ajuste de los componentes estan muy limitadas (casi inexistentes). Como mucho se pueden ordenar o mover columnas a izquierda y derecha.En este modo si funcionan todos los widgets y se pueden configurar las propiedades de ellos. En el modo Flash no funciona la navegación dimensional ni se puede realizar actividad alguna sobre los datos (creación indicadores, creación elementos derivados, formato, totalización, etc). Pero si podremos darle interactividad a los informes, pues los Selectores si funcionan. Cuando exportamos un documento en modo flash, con el archivo generado se integran todos los datos presentes en la ejecución del documento (habra que tenerlo en cuenta, pues puede que veamos una pequeña parte de los datos en los controles, pero en los conjuntos de datos haya mucha información, que hara que el fichero flash sea muy grande). En la imagen, configuración de la barra de desplazamiento de serie temporal.
Modo Flash - Propiedades Widget Serie Temporal
El modo por defecto en el que se ejecuta un documento, así como los modos disponibles son propiedades que se indican a nivel de documento, tal y como vemos en la imagen siguiente. Por tanto, nosotros determinaremos que modo de visualización va a estar disponible. Si, por ejemplo, usamos controles widgets, lo lógico sería verlos en el modo Flash. De la misma forma, si utilizamos gráficos que no se van a visulizar en modo Flash, lo lógico sería utilizarlos en modo Interactivo.
Propiedades de documento - Modos de Visualizacion
En los ejemplos no hemos incluido navegación dentro de los informes o los gráficos, ni tampoco la llamada a otros informes a través de la vinculación de atributos. Pero la funcionalidad esta disponible y se podría haber sacado partido de ella para profundizar mas en los datos (sobre todo para analizar determinados aspectos que nos llamen la atención, como tendencias, valores negativos o por debajo de lo esperado, etc.).
Conclusiones
Durante la elaboración de los ejemplos, partiendo de nuestro proyecto Enobi (que recuerdo es una empresa ficitica y por tanto, inexistente), he constatado lo importante que es tener bien claro que se quiere analizar, definir bien el ambito de este análisis y los indicadores clave que queremos estudiar. Los ejemplos descritos son sencillos y no entran en profundidad en los requerimientos de análisis del area de ventas de cualquier empresa, pero intentan que veamos las posibilidades de lo que podemos construir utilizando la herramienta de Microstrategy,combinando los diferentes elementos, dandole dinamismo a los informes y reutilizando todas las funcionalidades de reporting y navegación Olap que ya vimos en entradas anteriores del Blog.
Despues de estar trabajando durante una semana la eleboración de documentos utilizando tableros puedo afirmar que no es el producto de la suite de Microstrategy mas logrado. Resulta complicado realizar los documentos de tablero, darles el formato deseado y entender de una forma sencilla el funcionamiento global de los documentos. Ademas la documentación no es muy clara y aunque hay ejemplos de diseño en el repositorio de ejemplo, no se pueden ejecutar.
Los principales inconvenientes detectados son los siguientes:
- Diferentes modos de ejecución del documento. En cada sitio se puede modificar una cosa y no todos los controles funcionan en todos los modos (los widgets no funcionan en el modo interactivo y no todos los graficos funcionan en el modo flash). Esto nos limita las posibilidades de diseño y ademas complica este proceso, pues habrá que estar teniendolo en cuenta todo el rato según el tipo de componente a utilizar y en que tipo de visualización se vaya a ejecutar el documento.
- Ajustes de formateo: Lo que se formatea bien en un modo no aparece igual en otro modo. Por ejemplo, a nivel de tipos de letra, gráficos, tablas, etc. Igualmente, al realizar la exportación de los documentos (por ejemplo a Excel), no siempre se consiguen resultados aceptables.
- Interfaz Web lenta en el modo diseño y editable. Es tedioso el posicionamiento de los componentes dentro de la cuadricula y el uso de los menus desplegables.
- No se pueden poner limites en indicadores a nivel de cuadricula o grafico (habrá que ponerlos en el informe original). Esto nos puede obligar en ocasiones a construir varios informes para sacar subconjuntos de datos.
En lo referente a ventajas, podríamos indicar:
- Conjuntos de datos: a partir de un unico conjunto de datos (incluido en el documento a través de un informe predefinido), podemos construir multiples visualizaciones de los datos, tal y como hemos visto en los ejemplos.
- Multiples elementos disponibles para utilizar en los diseños. Con ellos se pueden construir informes atractivos y visuales (incluso muy bonitos en el modo Flash, aunque con las limitaciones indicadas).
- Se saca partido a toda la funcionalidad de los informes y la navegación Olap, lo que nos permite ejecutar de forma conjunta varios informes y tambien reutilizar elementos predefinidos.
- Los documentos se pueden ejecutar desde el entorno Office, embebidos dentro de la suite de Microsoft. La exportación de los documentos vía Pdf, Excel, Html o Flash puede ser una forma de generar contenido estatíco para enviar o para una intranet (con las limitaciones de formato indicadas). Como ejemplo de esto, el flash generado en nuestro ejemplo de tablero. El documento Flash obtenido es de gran calidad y da muchas posibilidades de hacer cosas interesantes.
Como curiosidad final, durante la construcción de los documentos de Report Services, venció la licencia de evaluación de Microstrategy 9 de 30 días que me habia proporcionado Microstrategy. Volví a instalar la licencia de Microstrategy Reporting Suite y me lleve la agradable sorpresa de que siguen activas las funcionalidades vistas hasta ahora. Solo bajo el numero de licencias disponibles a 2 (excepto en los usuarios de reporting Web e Intelligence Server, que son 25), limitando el uso a 1 cpu (de las 4 que tiene mi servidor). Ademas, tuve que desinstalar los productos Command Manager, Enterprise Manager, Object Manager, SDK y Web MMT para poder completar el registro. Por lo evaluado del producto (todo incluido en la Reporting Suite), puede ser una opción muy interesante para las empresas que empiezan en el mundo BI.
Teoria de Data Mining.
Teoria de Data Mining. respinosamilla 1 March, 2010 - 13:42En una entrada anterior del Blog (2.4. DataMining o Mineria de Datos.) intentamos hacer una aproximación inicial a la teoria del Data Mining. Los procesos de data mining tratan de extraer información oculta en los datos mediante el uso de diferentes técnicas (la mayoría relacionadas con la estadística y los modelos matemáticos, en combinación con aplicaciones informáticas).
Dada la complejidad de estas técnicas, y no siendo el cometido de esta blog entrar en profundidad en esta materia (por cuestiones de tiempo y de conocimientos), nos limitaremos a ver un par de metodologias de datamining, enumerar las técnicas mas habituales y a recordar los conceptos de tres de estas técnicas mediante ejemplos prácticos. Esos mismos ejemplos nos permitirán la posterior utilización de las herramientas de DataMining que proporciona Microstrategy 9 (también incluidas en la Microstrategy Reporting Suite) y explicar que visión tiene el producto de las técnicas de Data Mining.
Antes de comenzar, os recomiendo ver la presentación Data Mining.Extracción de Conocimiento en Grandes Bases de Datos, realizada por José M. Gutiérrez, del Dpto. de Matemática Aplicada de la Universidad de Cantabria, Santander.
Para quien quiera o necesite profundizar en la teoria de data mining, sus técnicas y posibilidades, os dejo la lista de referencias a algunos de los libros mas importantes en este ámbito:
- Data mining: practical machine learning tools and techniques.
- Data Mining Techniques: For Marketing, Sales, and Customer Relationship.
Management, 2nd Edition - The elements of statistical learning : data mining, inference, and prediction.
- Advanced Data Mining Techniques.
- Data Mining: Concepts and Techniques.
- Data Preparation for Data Mining.
Pasos a seguir en un proyecto de Data Mining
Existen varias metodologias estandar para desarrollar los analisis DataMining de una forma sistematica. Algunas de las mas conocidas son el CRISP, que es un estandar de la industria que consiste en una secuencia de pasos que son habitualmente utilizados en un estudio de data mining. El otro metodo es el SEMMA, especifico de SAS. Este metodo enumera los pasos a seguir de una forma mas detallada. Veamos un poco en que consiste cada uno.
CRISP-DM (Cross-Industry Standard Process for Data Mining).
El modelo consiste en 6 fases relacionadas entre si de una forma cíclica (con retroalimentación). Podeis ampliar información de la metodologia en la sección de manuales de Dataprix.com. Igualmente, podeis acceder la web del proyecto Crisp aquí. Las fases son las siguientes:
- Business Understanding: comprensión del negocio incluyendo sus objetivos, evaluación de la situación actual, estableciendo unos objetivos que habran de cumplir los estudios de data mining y desarrollando un plan de proyecto. En esta fase definiremos cual es el objeto del estudio y porque se plantea. Por ejemplo, un portal de ventas de viajes via web quiere analizar sus clientes y habitos de compra para hacer segmentación de ellos y lanzar campañas de marketing especificas sobre cada target con el objetivo de aumentar las ventas. Ese sera el punto de partida de un proyecto de datamining. Información detallada de la fase en Dataprix.com.
- Data Understanding: una vez establecidos los objetivos del proyecto, es necesario la comprensión de los datos y la determinación de los requerimientos de información necesarios para poder llevar a cabo nuestro proyecto. En esta fase se pueden incluir la recogida de datos, descripción de ellos, exploración y la verificación de la calidad de estos. En esta fase podemos utilizar técnicas como resumen de estadísticas (con visualización de variables) o realizar analisis de cluster con la intención de identificar patrones o modelos dentro de los datos. Es importante en esta fase que este definido claramente lo que se quiere analizar, para poder identificar la información necesaria para describir el proceso y poder analizarlo. Luego habrá que ver que información es relavante para el analisis (pues hay aspectos que se podrán desestimar) y finalmente habrá que verificar que las variables identificadas son independientes entre si. Por ejemplo, estamos en un proyecto de data mining de analisis de clientes para segmentación. De toda la información disponible en nuestros sistemas o de fuentes externas, habrá que identificar cual esta relacionada con el problema (datos de clientes, edad, hijos, ingresos, zona de residencia), de toda esa información, cual es relevante (no nos interesan, para el ejemplo, las aficiones de los clientes) y finalmente, de las variables seleccionadas, verificar que no estan relacionadas entre si (el nivel de ingresos y la zona de residencia no son variables independientes, por ejemplo). La información normalmente se suele clasificar en Demografica (ingresos, educación, numero de hijos, edad), sociografica (hobbys, pertenencia a clubs o instituciones), transaccional (ventas, gastos en tarjeta de credito, cheques emitidos), etc. Ademas, los datos pueden ser del tipo Cuantitativo (datos medidos usando valores numericos) o Cualitativo (datos que determinan categorias, usando nominales u ordinales). Los datos Cuantitativos pueden ser representados normalmente por alguna clase de distribución de probabilidad (que nos determinara como los datos se dispersan y agrupan). Para los Cualitativos, habrá que previamente codificarlos a numeros que nos describiran las distribuciones de frecuencia. Información detallada de la fase en Dataprix.com.
- Data Preparation: una vez los recursos de datos estan identificados, es necesario que sean seleccionados, limpiados, tranformados a la forma deseada y formateados. En esta fase se llevara a cabo los procesos de Data Cleaning y Data Transformation, necesarios para el posterior modelado. En esta fase se puede realizar exploración por los datos a mayor profundidad para encontrar igualmente patrones dentro de los datos. En el caso de estar utilizando un Data Warehouse como origen de datos, ya se habran realizado estas tareas al cargar los datos en el. También puede darse el caso de que necesitemos información agregada (por ejemplo, acumulación de ventas de un periodo), información que podremos extraer de nuestro DW con las herramientas tipicas de un sistema BI. Otro tipo de transformaciónes pueden ser convertir rangos de valores a un valor identificativo (ingresos desde/hasta determinan la categoria de ingresos n), o relizar operaciones sobre los datos (para determinar la edad de un cliente utilizamos la fecha actual y su fecha de nacimiento), etc. Ademas, cada herramienta software de Data Mining puede tener unos requerimientos especificos que nos obliguen a preparar la información en un formato determinado (por ejemplo, Clementine o PolyAnalyst tienen diferentes tipos de datos). Información detallada de la fase en Dataprix.com.
Esquema del Metodo CRISP
- Modeling: en la fase de modelización, utilizaremos software especifico de data mining como herramientas de visualización (formateo de datos para establecer relaciones entre ellos) o analisis de cluster (para identificar que variables se combinan bien). Estas herramientas pueden ser utiles para un analisis inicial, que se podran complementar con reglas de inducción para desarrollar las reglas de asociación iniciales y profundizar en ellas. Una vez se profundiza en el conocimiento de los datos (a menudo a traves de patrones de reconocimiento obtenidos al visualizar la salida de un modelo), se pueden aplicar otros modelos apropiados de analisis sobre los datos (como por ejemplo arboles de decisión). En esta fase dividiremos los conjuntos de datos entre de aprendizaje y de test. Las herramientas utilizadas nos permitiran generar resultados para varias situaciones. Ademas, el uso interactivo de multiples modelos nos permitira profundizar en el descubrimiento de los datos. Información detallada de la fase en Dataprix.com.
- Evaluation: el modelo resultante debera de ser evaluado en el contexto de los objetivos de negocio establecidos en la primera fase. Esto nos puede llevar a la identificación de otras necesidades que pueden llevarnos a volver a fases anteriores para profundizar (si encontramos por ejemplo, una variable que afecta al analisis pero que no hemos tenido en cuenta al definir los datos). Esto sera un proceso interactivo, en el que ganaremos comprensión de los procesos de negocio como resultado de las tecnicas de visualización, tecnicas estadísticas y de inteligencia artificial, que mostraran al usuario nuevas relaciones entre los datos, y que permitiran conocer mas a fondo los procesos de la organización. Es la fase mas critica, pues estamos haciendo una interpretacion de los resultados. Información detallada de la fase en Dataprix.com.
- Deployment: la mineria de datos puede ser utilizada tanto para verificar hipotesis previamente definidas (pensamos que si hacemos un descuento de un 5% aumentaran las ventas, pero no lo hemos comprobado con un modelo antes de aplicar la medida), o para descubrir conocimiento (identificar relaciones utiles y no esperadas). Este conocimiento descubierto nos puede servir para aplicarlo a los diferentes procesos de negocio y aplicar cambios en la organización donde sea necesario. Por ejemplo, pensar en el tipico ejemplo de la compañia de telefonos moviles que detecta que hay fuga de clientes de larga duración por un mal servicio de atención al cliente. Ese aspecto detectado hará que se realicen cambios en la organización, para mejorar ese aspecto. Los cambios aplicados se podrán monitorizar, para verificar en un tiempo determinado su corrección o no, o si tienen que ser ajustados para incluir nuevas variables. Tambien será importante documentarlos para ser utilizados como base en futuros estudios. Información detallada de la fase en Dataprix.com.
El proceso de seis fases no es un modelo rígido, donde usualmente hay mucha retroalimentación y vuelta a fases anteriores. Ademas, los analistas experimentados no tendran la necesidad de aplicar cada fase en todos los estudios.
SEMMA (Sample, Explore, Modify, Model and Assess).
Con el objetivo de ser aplicadas correctamente, una solución de datamining debe de ser vista como un proceso mas que como un conjunto de herramientas o técnicas. Esto es lo que pretende la metodologia desarrollada por el instituto SAS, llamada SEMMA, que significa sample=muestreo, explore=explora, modify=modifica, model=modeliza y assess=evalua. Este metodo pretende hacer mas facil la realización de exploración estadistica y las tecnicas de visualización, seleccionar y transformar las variables predictivas mas significantes, modelizar las variables para predecir resultados y finalmente confirmar la fiabilidad de un modelo. Al igual que el modelo Crisp, es posible la retroalimentación y el volver a fases anteriores durante el proceso. La representación grafica es la siguiente:
 Las fases serían las siguientes:
Las fases serían las siguientes:
- Sample: de un gran volumen de información, extraemos una muestra lo suficientemente significativa y con el tamaño apropiado para poder manipularla con agilidad. Esta reducción del tamaño de los datos nos permite realizar los analisis de una forma mas rapida y conseguimos también obtener información crucial de los datos de una forma mas inmediata. Las muestras de datos las podemos clasificar en tres grupos, segun el objeto para el que se usan: Training (usadas para la construcción del modelo), Validation( usadas para la evaluación del modelo) y Test (usadas para confirmar como se generalizan los resultados de un modelo).
- Explore: en esta fase de exploración el usuario busca tendencias imprevistas o anomalias para obtener una mejor comprensión del conjunto de datos. En esta fase se explora visualmente y numericamente buscando tendencias o agrupaciones. Esta exploracion ayuda a refinar y a redirigir el proceso. En el caso de que los analisis visuales no den resultados, se exploraran los datos con tecnicas estadisticas como analisis de factor, analisis de correspondencia o clustering.
- Modify: aqui es donde el usuario, crea, selecciona y transforma las variables con el objetivo puesto en la construcción del modelo. Basandonos en los descubrimientos de la fase de exploración, modificaremos los datos para incluir información de las agrupaciones o para introducir nuevas variables que pueden ser relevantes, o eliminar aquellas que realmente no lo son.
- Model: cuando encontramos una combinación de variables que predice de forma fiable un resultado deseado. En este momento estamos preparados para construir un modelo que explique los patrones en los datos. Las tecnicas de modelado incluyen las redes neuronales, arboles de decision, modelos logisticos o modelos estadisticos como series de tiempo, razonamientos basados en memoria, etc.
- Assess: en esta fase el usuario evalua la utilidad y fiabilidad de los descubrimientos realizados en el proceso de datamining. Verificaremos aqui lo bien que funciona un modelo. Para ello, podremos aplicarlo sobre muestreos de datos diferentes (de test) o sobre otros datos conocidos, y asi confirmar su vaildez.
Tecnicas de DataMining
Análisis estadístico:
Utilizando las siguientes herramientas:
1.ANOVA: o Análisis de la Varianza, contrasta si existen diferencias significativas entre las medidas de una o más variables continuas en grupo de población distintos.
2.Regresión: define la relación entre una o más variables y un conjunto de variables predictoras de las primeras.
3.Ji cuadrado: contrasta la hipótesis de independencia entre variables. Componentes principales: permite reducir el número de variables observadas a un menor número de variables artificiales, conservando la mayor parte de la información sobre la varianza de las variables.
4.Análisis cluster: permite clasificar una población en un número determinado de grupos, en base a semejanzas y desemejanzas de perfiles existentes entre los diferentes componentes de dicha población.
5.Análisis discriminante: método de clasificación de individuos en grupos que previamente se han establecido, y que permite encontrar la regla de clasificación de los elementos de estos grupos, y por tanto identificar cuáles son las variables que mejor definan la pertenencia al grupo.
Métodos basados en árboles de decisión:
El método Chaid (Chi Squared Automatic Interaction Detector) es un análisis que genera un árbol de decisión para predecir el comportamiento de una variable, a partir de una o más variables predictoras, de forma que los conjuntos de una misma rama y un mismo nivel son disjuntos. Es útil en aquellas situaciones en las que el objetivo es dividir una población en distintos segmentos basándose en algún criterio de decisión.
El árbol de decisión se construye partiendo el conjunto de datos en dos o más subconjuntos de observaciones a partir de los valores que toman las variables predictoras. Cada uno de estos subconjuntos vuelve después a ser particionado utilizando el mismo algoritmo. Este proceso continúa hasta que no se encuentran diferencias significativas en la influencia de las variables de predicción de uno de estos grupos hacia el valor de la variable de respuesta.
La raíz del árbol es el conjunto de datos íntegro, los subconjuntos y los subsubconjuntos conforman las ramas del árbol. Un conjunto en el que se hace una partición se llama nodo.
El número de subconjuntos en una partición puede ir de dos hasta el número de valores distintos que puede tomar la variable usada para hacer la separación. La variable de predicción usada para crear una partición es aquella más significativamente relacionada con la variable de respuesta de acuerdo con test de independencia de la Chi cuadrado sobre una tabla de contingencia.
Algoritmos genéticos:
Son métodos numéricos de optimización, en los que aquella variable o variables que se pretenden optimizar junto con las variables de estudio constituyen un segmento de información. Aquellas configuraciones de las variables de análisis que obtengan mejores valores para la variable de respuesta, corresponderán a segmentos con mayor capacidad reproductiva. A través de la reproducción, los mejores segmentos perduran y su proporción crece de generación en generación. Se puede además introducir elementos aleatorios para la modificación de las variables (mutaciones). Al cabo de cierto número de iteraciones, la población estará constituida por buenas soluciones al problema de optimización.
Redes neuronales:
Genéricamente son métodos de proceso numérico en paralelo, en el que las variables interactúan mediante transformaciones lineales o no lineales, hasta obtener unas salidas. Estas salidas se contrastan con los que tenían que haber salido, basándose en unos datos de prueba, dando lugar a un proceso de retroalimentación mediante el cual la red se reconfigura, hasta obtener un modelo adecuado.
Red Neuronal en Microstrategy
Lógica difusa:
Es una generalización del concepto de estadística. La estadística clásica se basa en la teoría de probabilidades, a su vez ésta en la técnica conjuntista, en la que la relación de pertenencia a un conjunto es dicotómica (el 2 es par o no lo es). Si establecemos la noción de conjunto borroso como aquel en el que la pertenencia tiene una cierta graduación (¿un día a 20ºC es caluroso?), dispondremos de una estadística más amplia y con resultados más cercanos al modo de razonamiento humano.
Series temporales:
Es el conocimiento de una variable a través del tiempo para, a partir de ese conocimiento, y bajo el supuesto de que no van a producirse cambios estructurales, poder realizar predicciones. Suelen basarse en un estudio de la serie en ciclos, tendencias y estacionalidades, que se diferencian por el ámbito de tiempo abarcado, para por composición obtener la serie original. Se pueden aplicar enfoques híbridos con los métodos anteriores, en los que la serie se puede explicar no sólo en función del tiempo sino como combinación de otras variables de entorno más estables y, por lo tanto, más fácilmente predecibles.
Clasificación de las técnicas de Data Mining
Las tecnicas de Data Mining las podemos clasificar en Association, Classification, Clustering, Predictions y Series Temporales.
- Association (asociacion): la relacion entre un item de una transaccion y otro item en la misma transacción es utilizado para predecir patrones. Por ejemplo, un cliente compra un ordenador (X) y a la vez compra un raton(Y) en un 60% de los casos. Este patron ocurre en un 5,6% de las compras de ordenadores. La regla de asociación en esta situación es que “X implica Y, donde 60% es el factor de confianza y 5,6% el factor de soporte. Cuando el factor de confianza y al factor de soporte estan representados por las variables linguisticas alto y bajo, la regla de asociacion se puede escribir en forma de logica difusa, como: “cuando el factor de suporte es bajo, X implica Y es alto”. Este seria el tipico ejemplo de datamining de estudio realizado en supermercados con la asociación entre la venta de pañales de bebe y cerveza (ver entrada del blog Bifacil). Usan los algoritmos de reglas de asociación y arboles de decisión.
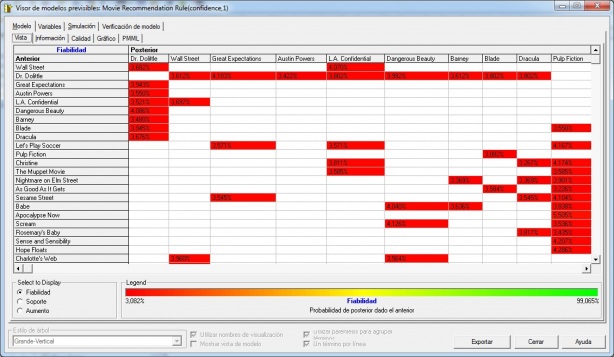
Modelo Asociacion en Microstrategy - Compra de Peliculas de DVD
- Classification (clasificacion): en la clasificación, los metodos tienen la intención de aprender diferentes funciones que clasifiquen los datos dentro de un conjunto predefinido de clases. Dado un nuevo de clases predefinidas, un numero de atributos y un conjunto de datos de aprendizaje o entrenamiento, los metodos de clasificación pueden automaticamente predecir la clase de los datos previamente no clasificados. Las claves mas problematicas relacionadas con la clasificación son las evaluacion de los errores de clasificación y la potencia de predicción. Las tecnicas matematicas mas usadas para la clasificación son los arboles de decisión binarios, las redes neuronales, programación lineal y estadistica. Utilizando un arbol de decisión binario, con un modelo de inducción de arbol en el formato Si-No, podremos posicionar los datos en las diferentes clases según el valor de sus atributos. Sin embargo, esta clasificación puede no ser optima si la potencia de predicción es baja. Con el uso de redes neuronales, se puede construir un modelo de inducción neuronal. En este modelo, los atributos son capas de entrada y las clases asociadas con los datos son las capas de salida. Entre las capas de entrada y de salida hay un gran numero de conexiones ocultas que aseguran la fiabilidad de la clasificación (como si fuesen las conexiones de una neurona con las de su alrededor).El modelo de induccion neuronal ofrece buenos resultados en muchos analisis de data mining, cuando hay un gran numero de relaciones se complica la implementación del metodo por el gran numero de atributos. Usando tecnicas de programación lineal, el problema de la clasificación es visto como un caso especial de programación lineal. La programación lineal optimiza la clasificación de los datos, pero puede dar lugar a modelos complejos que requieran gran tiempo de computación. Otros metodos estadisticos, como la regresión lineal, regresion discriminante o regresión logistica tambien son populares y usados con frecuencia en las procesos de clasificación.
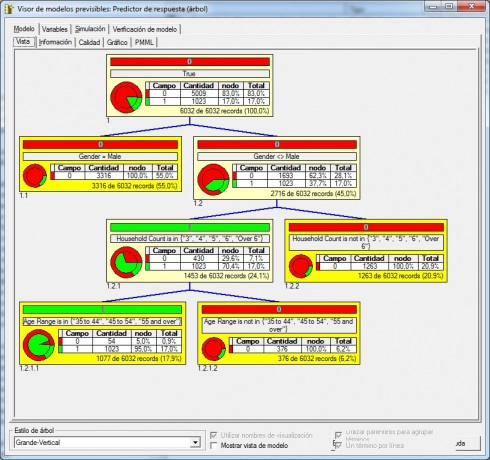
Arbol Decision en Microstrategy
- Clustering (segmentación): el analisis de cluster toma datos sin agrupar y mediante el uso de tecnicas automaticas realiza la agrupación de estos. El clustering no esta supevisado y no requiere un set de datos de aprendizaje. Comparte un conjunto de metodologias con la clasificación. Es decir, muchos de los modelos matematicos utilizados en la clasificación pueden ser aplicados al analisis cluster tambien. Usan los algoritmos de clustering y de sequence clustering.
- Prediction (predicción)/Estimación: el analisis de predicción esta relacionado con la tecnicas de regresión. La idea principal del analisis de predicción es descubrir las relaciones entre variables dependientes e independientes y las relaciones entre variables independientes. Por ejemplo, si las ventas es una variable independientes, el benefición puede ser una variable dependiente.
- Series Temporales (pronostico): utilizando datos historicos junto con tecnicas de regresión lineal o no lineal, podemos producir curvas de regresión que se utilizaran para establecer predicciones a futuro. Usan los algoritmos de series de tiempo.
Ejemplo 1. Analisis de cesta de la compra (Asociacion).
Es el tipico ejemplo que se utiliza para explicar los ambitos de utilización del datamining ( con la asociación entre la venta de pañales de bebe y cerveza ). En nuestro caso, utilizando los ejemplos que proporciona Microstrategy en su plataforma, en el proyecto de aprendizaje que llaman Microstrategy Tutorial, veremos un ejemplo de utilización de técnicas de analisis de asociacion.
En el ejemplo, se analizan las ventas de DVD´s de unos grandes almacenes y se trata de encontrar la asociación entre la venta de diferentes peliculas. Es decir, intentamos encontrar que títulos se venden conjuntamente con el objetivo de establecer posteriormente promociones comerciales de esas peliculas (por ejemplo, venta de packs, ubicación de las peliculas juntas en los pasillos, promoción de descuento por la compra de la segunda unidad, etc), con el objetivo de aumentar las ventas. Para este tipo de analisis utilizaremos analisis de reglas de asociación.
Ejemplo 2. Segmentación de clientes (Analisis de cluster).
Con este analisis pretendemos analizar nuestros clientes y utilizando información demográfica de ellos (edad, educación, numero de hijos, estado civil o tipo de hogar), realizar una segmentación de mercado para preparar el lanzamiento de determinados productos o la realización de ofertas promocionales.
En este caso, realizaremos un analisis de cluster, utilizando el algoritmo k-means, que es el que soporta Microstrategy.
Ejemplo 3. Predicción de ventas en una campaña (Arbol de decisión).
En este analisis utilizaremos un arbol de decisión para determinar la respuesta de un determinado grupo de clientes a rebajas en determinados productos en la epoca de vuelta al colegio. Para ello, utilizaremos arboles de decisión del tipo binario (recordemos que los arboles de decisión se pueden utilizar tanto para clasificación como para analisis de regresión, como en este caso). Intentaremos determinar como influyen factores como la edad, el sexo o el numero de hijos en la probabilidad de realizar compras en esa campaña de rebajas.
En la proxima entrada del blog detallaremos estos ejemplos utilizando las herramientas de Data Mining de Microstrategy.
DataMining en Microstrategy 9 (I).
DataMining en Microstrategy 9 (I). respinosamilla 3 March, 2010 - 00:17La orientación de Microstrategy 9 con el Data Mining es integrarlo totalmente en su plataforma de Business Intelligence y que no sea un producto aparte como en muchos otros fabricantes (lo que nos obliga a realizar los análisis en un sistema paralelo). Esta integración se realiza a traves de las métricas predictivas, que estaran disponibles en el sistema como un elemento mas del sistema de BI.
Ademas, soporta el estandar de la industria PMML (Predictive Model Markup Language), lo que nos permite importar modelos de data mining desde otras plataformas y crear de forma automatica en el repositorio de metadatos las metricas predictivas. Recordemos que PMML es un estandar de la industria en XML desarrollado por el Data Mining Group(DMG) para describir los modelos predictivos. En su desarrollo han participado los principales fabricantes de software de datamining, incluyendo Microstrategy. Este estandar soporta un gran numero de algoritmos de data mining, como son las Redes Neuronales, Clustering, Regresion, Arboles de Decision y Asociacion. PMML se puede generar en las principales aplicaciones de DM como son SAS®, SPSS®, Microsoft®, Oracle®, IBM®, KXEN™, ANGOSS y otros. Microstrategy es la primera plataforma BI que soporta el estandar, y su plataforma incluye, de forma integrada con el resto de elementos, la creación de modelos y la distribución de los resultados a los usuarios a traves del visor de modelos previsibles, que presenta unas características e información gráfica diferente según el tipo de análisis que estemos realizando. Los resultados de los estudios se pueden incluir como un elemento mas en los Dashboards de analisis.
Los tipos de algoritmos soportados por Microstrategy 9 son los siguientes: Regresión lineal , Regresión Exponencial, Regresión Logistica, Agrupación (Clustering), Arbol de Decisiones, Series Temporales y Asociacion.
Tipos de analisis de Datamining soportados por Microstrategy 9
Ademas de estas características DataMining puras, Microstategy va mas alla y enumera otros elementos de la plataforma BI que también son utiles y necesarios para un analisis avanzado (como parte incluida dentro de la preparación del modelado de DataMining o como analisis previos o especificos). Estas caracteristicas las hemos visto en diferentes entradas del Blog cuando hemos analizado las principales componentes de la Suite ( Reporting en Microstrategy 9 I y II, Navegación Dimensional y cubos OLAP en Microstrategy 9). Resumiendo, serían las siguientes:
Funcionalidad de Reporting Guiada por Parámetros.
Partiendo de los informes construidos, y mediante el uso de parametros, podemos construir analisis de una forma variable y sencilla. Esos parametros podrán interactuar contra los valores de los indicadores para hacer analisis interactivos, permitiendons crear informes sofisticados. Por ejemplo, podemos pedir un valor en tiempo de ejecución que se utilizara dinamicamente en la formula de calculo de un indicador, pudiendo realizar analisis de suposiciones y predictivos utilizando diferentes variables, algunas de las funciones proporcionadas por la suite y los valores de indicadores de nuestro modelo. Mediante las selecciones dinamicas de valor y la utilización de estos valores en las formulas de los indicadores dispondremos de una forma sencilla de esta funcionalidad.
Capacidades de Navegación Drill-Anywhere.
Mediante estas capacidades de navegación, los usuarios pueden visualizar tanto información sumarizada como detallada y tienen acceso a la totalidad de los datos contenidos en el data warehouse en cualquier lugar de estos. Esta navegación nos permite navegar en los detalles tal como aparecen en el modelo de negocio y detectar tendencias, desviaciones o aspectos que sera interesante analizar mas a fondo. No es necesario que los usuarios comprendan en profundidad la base de datos, las estructuras de las tablas, ni el lenguaje de las consultas. Simplemente deben saber dónde posicionarse y cómo hacer clic.
Análisis de Conjuntos y Segmentación de Datos
Los usuarios pueden potenciar los análisis de conjuntos que trae MicroStrategy para realizar una fácil segmentación de los datos. Los usuarios pueden manipular y combinar los sets de datos definidos para obtener un set de datos más refinado para llevar adelante análisis más profundos. Para ello podemos utilizar los filtros, las selecciones dinámicas, los filtros de visualización, los filtros sobre los indicadores, la navegación a través de grupos de atributos, etc. Las herramientas de reporting pueden ser el punto de partida para los analísis mas profundos utilizando todas las posibilidades que nos proporciona.
Grupos de Datos Definidos por Usuarios
Cuando construimos el data warehouse, definimos en el una estructura que refleja el modelo de negocio de la empresa, pero dicha estructura no siempre refleja los requerimientos de negocio de los departamentos individuales, ni de los equipos de trabajo ni de los decisores. Con los Grupos Personalizados y Consolidaciones, podemos cambiar el enfoque del modelo de negocio y construir nuevos atributos o agrupaciones mas acordes con el tipo de analisis que queremos realizar. No pueden ayudar a realizar analisis previos antes de la realización de estudios de data mining. Con ellos podemos perfeccionar el modelo de negocios hasta alcanzar los requerimientos departamentales o individuales, sin impactar en la estructura del modelo de datos de la empresa. Podemos realizar simulaciones de segmentación que luego analizaremos en profundidad utilizando las técnicas de Data Mining.
Tratamiento Analítico de los Datos
MicroStrategy nos proporciona un amplio conjunto de funciones analíticas para interactuar sobre los datos. MicroStrategy contiene una libreria de mas de 270 funciones, incluyendo las básicas, funciones Olap, funciones matematicas, financieras, estadísticas y de data mining, que pueden ser utilizadas para crear metricas e indicadores de rendimiento (pki).
Microstrategy - Funciones estadísticas
Las funciones disponibles, de forma resumida, son las siguientes:
- Funciones básicas: suma, promedio, media aritmetica, contadores, minimo, maximo, varianza, media geometrica, moda, desviación estandar, etc.
- Funciones de cadena: concatenacion, longitud de cadenas, tratamiento de subcadenas, paso a mayusculas o minusculas, eliminación espacios, etc.
- Funciones de fecha y hora: operaciones sobre fechas; hora, minuto, segundo, dia, mes, año, dia de la semana, dia del mes, dia del año de una fecha, etc.
- Funciones de orden y NTile: funciones ntile, percetiles o rankings.
- Funciones Olap: funciones relacionadas con el procesamiento Olap.
- Funciones de extraccion de datos: funciones para data mining como modelo asociacion, modelo regresion, arbol de decision, clustering, etc.
- Funciones estadisticas: distribucion beta, distribucion binomial, confianza, correlacion, covarianza, distribucion chi cuadrado, distribucion gamma, permutaciones, distribución de poisson, etc.
- Funciones financieras: funciones financieras para el calculo de interes, rentabilidad, prestamos, etc.
- Funciones matematicas: valor absoluto, seno, coseno, tangente, redondeo, truncate, logaritmos, raiz cuadrada, etc.
Ademas, como características avanzadas, y en las que no habiamos entrado todavia, podemos destacar las siguientes:
Plug-ins para Funciones a Medida
Microstrategy permite incorporar a la plataforma de BI nuestras propias funciones, desarrolladas mediante DLL´s. Por medio de un asistente plug-in para funciones a medida, los usuarios de MicroStrategy pueden incorporar dichas funciones para usarlas en la creación de informes. Una vez importadas, se ponen a disposición de todos los usuarios de manera automática para que se definan las métricas y las medidas.
Creación de Datamarts utilizando informes de Microstrategy.
Esta es una funcionalidad muy interesante, que nos puede servir tanto para la preparación de los datos sobre los que luego aplicar nuestros analisis de Data Mining o como para la construcción de Datamarts departamentales o de un area especifica (que incluyen solo un conjunto de datos de todos los que disponemos en nuestro sistema). Los datos extraidos son almacenados en una tabla de base de datos en el lugar que nosotros indiquemos. Los datos estaran en ese momento disponibles para analizarlos en el mismo Microstrategy o para utilizarlos con otras aplicaciones externas.
La idea es muy sencilla. Construimos un informe donde incluimos la información necesaria (el conjunto de atributos e indicadores que queremos “extraer” de nuestro sistema), con los correspondientes filtros o selecciones dinámicas para restringir o calificar el proceso de extracción a nuestras necesidades. Una vez definido el informe, en la seccion Datos –> Configurar Datamart indicamos el destino donde se guardarán los datos (tal y como vemos en la imagen):
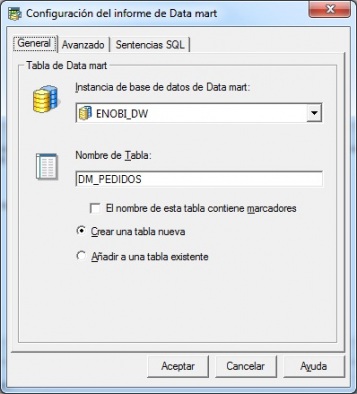
Microstrategy - Creación de Datamart
Indicaremos la instancia de la base de datos donde queremos guardar los datos (que podrá ser cualquier base de datos de las soportadas), la tabla, pudiendo además indicar una serie de opciones avanzadas, como número máximo de filas, sentencia sql a ejecutar antes y despues de crear la tabla o sentencia a ejecutar antes de insertar los datos. Además, en el nombre de la tabla podemos insertar calificadores que pueden ser utiles para crear tablas diferentes según algún criterio (usuario, fecha, nombre de informe). Para ello, marcamos la opción “El nombre de esta tabla contine marcadores” e indicamos alguno de los siguientes valores:
- !U – Nombre de usuario.
- !D – Fecha.
- !O – Nombre de informe.
Una vez indicados los parametros correctos en la sección, ejecutaremos el informe, momento en el cual se creara la tabla en el destino indicado y se llenara con los datos recuperados por el informe. La ejecución del informe no devuelve ningún resultado. Igualmente, podremos configurar la ejecución automatica de este tipo de informes para que se llene el Datamart de una forma desasistida (al igual que cuando vimos los cubos inteligentes).
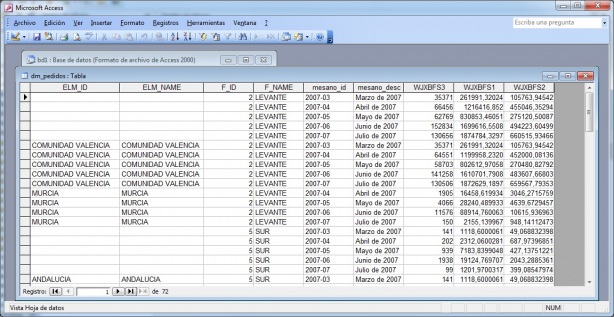
Microstrategy - Ejemplo de Datamart
En la imagen podeis ver la vinculación desde Access a una tabla del tipo Datamart creada con un informe. En el informe utilizamos los grupos personalizados de zonas geografícas (que agrupan los valores de varias regiones, por ejemplo, Zona Levante agrupa Murcia, Valencia y Cataluña) para extraer los datos de ingresos, unidades y margen por mes para cada zona geográfica. Podemos ver como, aunque los grupos personalizados no son algo que exista en nuestro modelo, al realizar la exportación de datos al Datamart si se ha creado su correspondiente columna en la tabla creada (campos F_ID y F_NAME en el ejemplo ). Los primeros registros del ejemplo tienen los datos totales de la zona geográfica LEVANTE por mes y los 9 registros siguiente el desglose de la zona por cada una de las regiones).
Con esta funcionalidad, junto con el uso de las multiples funciones que proporciona Microstrategy, podremos realizar la extracción de datos adaptada a nuestras necesidades para realizar los analisis de data mining sobre los datos o cualquier otro tipo de operativa.
Construcción de Analisis de DataMining en Microstrategy.
Para llevar a cabo la construcción del análisis, tendremos que determinar primero un objetivo. Es objetivo incluira los resultados deseados para mejorar un aspecto determinado en una organización. Por ejemplo, objetivos pueden ser mejorar la respuesta en una campaña de marketing, evitar la perdida de clientes, previsión de tendencias o segmentación de clientes. Este objetivo ha de ser especifico, pues a a ver determinar que analisis se puede utilizar y que datos nos haran falta.
Una vez definido el objetivo, comenzaremos a explorar en los datos para conocer mas de ellos y preparar el camino para el análisis. En nuestro caso, en Microstrategy, construiremos unos reports de ejemplo que nos permitiran ir observando los datos. Con el conjunto de datos que nos va a hacer falta para el analisis (dependeran del tipo de este), podemos construir un Datamart de la forma vista anteriormente (al que podremos atacar incluyendolo la definición de atributos e indicadores en el metadata) y a partir de el comenzar el análisis o continuar trabajando directamente con los datos mediante los informes. De ese conjunto de datos podremos ir eliminando componentes mediante filtrados (materiales que no son relevantes, clientes que no consideramos en el análisis, lineas de producto o zonas geograficas fuera del ambito, periodos de tiempo fuera de campaña, etc). Podremos igualmente ir navegando en los datos para observar comportamientos, variaciones, peculiaridades, patrones. Podremos crear nuevos indicadores que nos faciliten este analisis utilizando las funciones analiticas de Microstrategy (por ejemplo, funciones estadisticas, de ranking, de orden, etc). Todo este analisis previo nos permitira ir haciendo la depuración de datos y concretando los aspectos del análisis. Igualmente, podremos ir preparando para que solo se seleccione un conjunto determinado de los datos (un muestreo), utilizando igualmente funciones de las que disponemos en Microstrategy.
Una vez tenemos disponible el conjunto de datos, podremos seguir explorandolo para descubrir patrones o definir transformaciones que habra que realizar sobre ellos, con el objetivo final de identificar las variables con las que construiremos el modelo de análisis.
Pasos en un analisis de Datamining con Microstrategy
Con esas variables identificadas, construiremos el modelo previsible a traves de lo que en Microstrategy se llaman indicadores de formación. El indicador de formación es un tipo de indicador especial que va a contener información sobre el tipo de analisis que queremos realizar, que variables intervienen en el análisis y parametros concretos que determinaran la forma de realizar el analisis (que dependen del tipo de modelo a utilizar). Microstrategy dispone de un asistente de creación de indicadores de formación. En el caso de que vayamos a desarrollar un modelo que incluya el analisis de atributos (como por ejemplo número de pedido, material o datos de clientes), habrá que crear indicadores para estos atributos, pues en el indicador de formación solo se pueden utilizar indicadores. Los indicadores que se utilizan en la creación del indicador de formación se llaman indicadores de entrada previsibles.
Al crear el indicador de formación, seleccionamos en primer lugar el tipo de analisis, de los posibles en Microstrategy, que son, como ya vimos: Regresión lineal , Regresión Exponencial, Regresión Logistica, Agrupación (Clustering), Arbol de Decisiones, Series Temporales y Asociacion.
A continuación, el asistente nos pedira las variables implicadas en el análisis, según el tipo de este. Por ejemplo, para una analisis de asociación, las variables serán el indicador de transacción (el número de pedido, por ejemplo, que es el elemento para agrupar los elementos) y el indicador de elemento (los elementos que se van a analizar, en este caso, el material o producto). Ademas se nos pediran diferentes valores según el tipo de analisis a construir, valores que concretaran la forma en realizar en analisis.
Microstrategy - Definición de indicador de formación
El indicador de formación tiene el objetivo de construir los indicadores previsibles y de realizar al generación del modelo de análisis. Una vez definido el indicador de formación, crearemos un informe de Microstrategy donde tendremos las variables (atributos o indicadores) necesarias para el tipo de analisis y donde ademas incluiremos el indicador de formación. Al incluir este, cuando ejecutemos el informe, se crearan los indicadores previsibles. Los indicadores previsibles guardan los resultados del análisis y pueden ser analizados mediante el visor que proporciona Microstrategy.
El visor de modelos previsibles (según vemos en la imagen siguiente), tiene un aspecto diferente según el tipo de analisis que estemos realizando. Basicamente, nos proporciona información sobre el modelo ( incluyendo información grafica en algunos casos y los datos para exportar el modelo en el estandar PMML), las variables que intervienen en el, una pestaña de simulación donde podemos analizar como cambia el modelo si cambiamos el valor de las variables de entrada y la herramienta de verificación del modelo (una lista de registros de verificación del modelo con su puntuación).
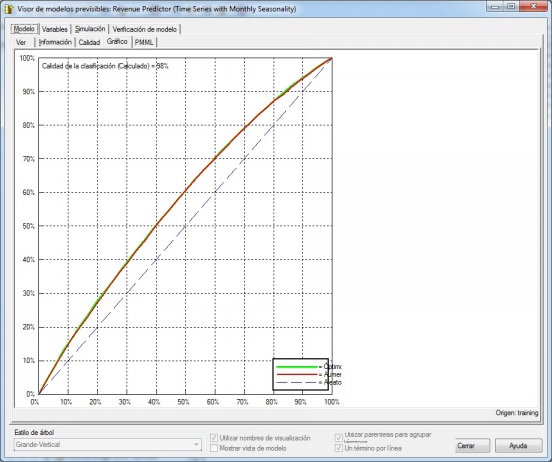
Microstrategy - Visor Modelos Previsibles en Analisis Serie Temporal
Podriamos ir modificando la muestra de datos sobre la que aplicamos el indicador de formación, y con los indicadores previsibles generados y el visor, ir validando y ajustando el modelo de análisis o ir realizando cambio en las variables, parametros del indicador de formación o en el conjunto de datos. Estos pasos los repetiremos hasta obtener los resultados deseados y concretar y validar el modelo de análisis.
Los indicadores previsibles se pueden, ademas de visualizar, utilizar como resultado en cualquier informe de Microstrategy. Esto puede ser util para validar los resultados, para analizar tendencias o para presentar los resultados del analisis.
Una vez concluido el análisis, podremos seguir utilizandolo para validar resultados a futuro o exportarlo en formato PMML para utilizarlo en otras herramientas de Data Mining que incluyan el trabajo con dichol estandar.
Para ver mas en detalle todos estos pasos seguidos, vamos a realizar un ejemplo práctico de analisis de Reglas de Asociación.
Ejemplo 1. Analisis de cesta de la compra (Asociacion).
Vamos a ver los pasos seguidos para la construcción de un modelo de analisis de la cesta de la compra, utilizando reglas de Asociación. Utilizamos para ello el proyecto Tutorial que se incluye en la instalación de Microstrategy (que muestra ejemplos de todas las funcionalidades incluidas en la suite, incluyendo el Data Mining).
Vamos a analizar una tabla que incluye los datos de ventas de peliculas de DVD. En primer lugar, construimos un informe para realizar un primer vistazo a los datos. En este informe podremos ir incluyendo restricciones sobre los datos, como excluir determinados materiales (o solo incluir una familia de producto determinada, como en este caso, las peliculas de DVD), seleccionar un periodo de tiempo o una zona geográfica concreta o realizar un muestreo aleatorio de datos utilizando indicadores de orden, para reducir el tamaño del conjunto de datos..
Como el tipo de analisis a realizar es el de asociación, que trata de ver como estan relacionadas las ventas de productos diferentes entre si en las mismas transacciones, nos vamos a centrar en los atributos Pedido y Articulo.
Informe inicial en analisis de asociacion
Una vez delimitado y acotado el conjunto de datos sobre el que realizaremos el analisis, realizamos la definición de los indicadores para los atributos Pedido y Articulo (aunque son indicadores normales, los llamamos Indicadores de Entrada Previsibles). Ellos nos van a permitir construir el indicador de formación, base del analisis. Veamos como definimos los indicadores para los atributos
Definicion de indicador de entrada previsible para atributo
A continuación, realizamos la creación del indicador de formación, seleccionando el tipo de analisis Asociación. Al crear un indicador de formación de este tipo, las especificaciones del modelo son las siguientes:
- Numero maximo de elementos por conjunto: este parametro determina el número máximo de artículos que pueden aparecer en el conjunto de elementos anterior o posterior. Por ejemplo, si se establece en tres, los articulos se agruparán en conjuntos de elementos que contendrán uno, dos o tres artículos. En nuestro ejemplo, indicamos 3.
- Confianza minima: probabilidad mínima que deben tener las reglas de calificación. Por ejemplo, si se establece en 10%, una regla de asociación debe tener una confianza del 10% o superior para que se incluya en el modelo. El valor por defecto es 10% y aumentar su valor puede llevar a generar menos reglas. En nuestro ejemplo indicamos un 0,1%.
- Soporte minimo: el número mínimo de transacciones en las que se debe producir un conjunto de elementos para que una regla de asociación lo tenga en cuenta. Por ejemplo, si se establece en 1%, los conjuntos de elementos deben aparecer, en promedio, en una transacción cada 100. En nuestro ejemplo indicamos un 0,1%.
A continuación indicamos las variables que intervienen en el análisis, por una lado el indicador de transacción (el indicador para los numeros de pedido que hemos definido) y el indicador de elemento (el indicador para el material). Finalmente, indicamos las opciones de los diferentes indicadores previsibles que se generaran cuando ejecutemos el indicador de formación dentro de un informe. En este caso, indicaremos que reglas de asociación se van a devolver en los indicadores previsibles que se creen. En nuestro ejemplo, devolveremos dos indicadores, la regla de asociación (la tupla grupo peliculas anterior –> grupo peliculas posterior) y la recomendación (grupo peliculas posterior). Y cada indicador lo devolveremos 3 veces, por cada una de las 3 reglas que mas porcentaje de confianza tenga:
Opciones de indicadores previsibles a generar
El modelo ya esta preparado para empezar a trabajar con el. A continuación, incluimos el indicador de formación en un informe, junto con los atributos necesarios para el analisis (cada fila será un pedido, material y el indicador). El informe sería algo asi:
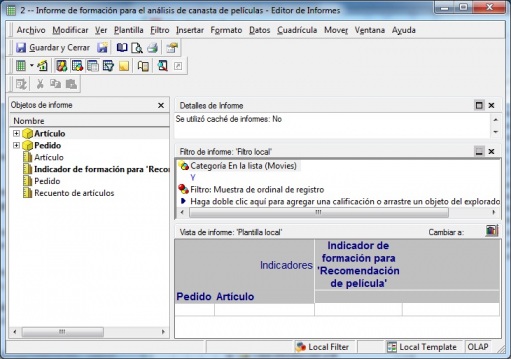
Asociacion - Informe Creacion Indicadores Previsibles
Podeis observar como hemos incluido en las filas los atributos pedido y articulo (al fin y al cabo, los indicadores se construyen sobre dichos atributos) y en las columnas el indicador de formación creado anteriormente. Cuando ejecutamos el informe, se realiza el proceso de analisis y se crean en el lugar indicado los indicadores previsibles (uno o varios según como hayamos definido el indicador de formación). En cada indicador previsible de los creados podremos visualizar el modelo que se ha creado con el visor de modelos previsibles (aunque hay varios indicadores previsibles, hay un unico modelo). El hecho de que haya varios indicadores previsibles es para tener información diferente que luego poder utilizar en un informe para presentar los resultados del análisis. Podremos ir realizando ajustes al modelo, cambiando el volumen del muestreo o las condiciones indicadas para la obtención de datos, o modificando los porcentajes de confianza y soporte del indicador de formación y generando diferentes indicadores previsibles que analizaremos con el visor correspondiente (tal y como vemos a continuación). También podremos validar el modelo aplicandolo sobre un conjunto de datos o muestreo diferente para confirmar los resultados que hemos obtenido en las diferentes tandas.
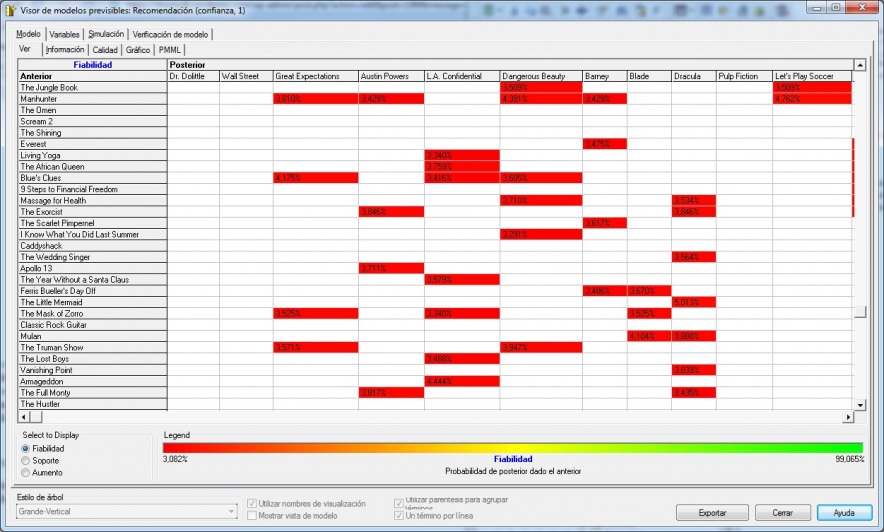
Visor de indicadores previsibles
En la imagen, podeis ver el visor de indicadores previsibles, donde tenemos la información del análisis realizado. Podemos ver la tabla de resultados (en otro tipo de analisis, la información que aparecerá será diferente). Podemos ver que Microstrategy ha construido la tabla de conjuntos, estando en las filas las reglas que representan a los grupos anteriores y en las columnas los grupos posteriores. El valor que aparece en cada casilla varia según el tipo de elemento elegido para visualizar ( casilla selección en la parte inferior izquierda):
- Confidence (confianza o fiabilidad): un estimacion de la probabilidad de que una transacción tenga el elemento posterior en el caso de que contenga el antecesor. La formula sería la siguiente:
- Confianza = Soporte (Anterior + Posterior en la misma transac ) / Soporte (Anterior)
- Support (soporte): frecuencia relativa de que una transaccion contenga el anterior y el posterior.
- Lift (aumento): Una relación que describe si la regla es más o menos significativa que el azar. Valores lift superiores a 1,0 indican que las transacciones con el anterior tienden a contener el posterior más a menudo que las transacciones que no contienen el antecedente.
La leyenda en la parte inferior de la tabla muestra el minimo y el maximo valor de la estadistica seleccionada para visualizar (con la correspondiente graduación de colores según los valores).
Despues de ajustar el modelo, realizar la verificación y las reejecuciones que se estime necesario, podemos comprobar los resultados incluyendo los indicadores previsibles en un informe estandar de Microstrategy. Para nuestro ejemplo, el informe final con los resultados podría ser algo así:
Modelo asociacion - Informe resultados con Indicadores Previsibles
A partir de los resultados, se podrían completar otro tipo de analisis que nos llevasen a establecer determinadas promociones con las peliculas, como colocarlas conjuntamente en los lugares de venta o en las zonas de paso, realizar packs que incluyan las dos, promociones de segunda unidad a un menor precio, etc. Las posibles acciones a realizar se podrian verificar a posteriori utilizando los grupos personalizados, de forma que podamos ver el historico de ventas anteriores de los materiales por separado y como han evolucionado las ventas despues de realizar las correspondientes acciones y venderlos conjuntamente. Incluso podriamos utilizar el indicador de formación que utilizamos en el estudio para verificar que los porcentajes de confianza han aumentado.
En la siguiente entrada del blog realizaremos el diseño completo de 2 ejemplos más de Data Mining con Microstrategy 9.
Hola amigos : Por favor,
Hola amigos : Por favor, necesito que me ayuden, tengo que generar un Data Mart en MicroStrategy pero el nombre de Tabla tiene que tener el formato similar al siguiente : "CLIENTES_YYYY_MM.txt" dónde YYYY_MM es año y mes actual -1, ¿ esto se puede hacer ? Gracias por la respuesta. Saludos.
- Log in to post comments
Hola Omar A nivel de base de
Hola Omar
A nivel de base de datos obviamente tu puedes denominar a las tablas como quieras, por lo que entiendo que estás preguntando si MicroStrategy puede utilizar como origen cada mes una tabla con nombre diferente.
Si es eso, directamente no, a menos que cada mes cambies el nombre en el modelo, pero lo que sí puedes hacer es utilizar el particionamiento de MicroStrategy, particionando por mes. En la ETL irías creando una tabla para cada mes, y en MicroStrategy creas un particionamiento para Clientes configurándolo por meses.
Espero haberte ayudado,
Nota: Este tema no tiene mucho que ver con el Datamining de MicroStrategy, para próximas consultas de este tipo mejor utiliza el foro de Dataprix sobre MicroStrategy.
- Log in to post comments
DataMining en Microstrategy 9 (II).
DataMining en Microstrategy 9 (II). respinosamilla 5 March, 2010 - 20:22Ejemplo 2. Segmentación de clientes (Analisis de cluster).
El analisis de clúster ofrece un método para agrupar valores de datos basado en similitudes dentro de estos. Esta técnica segmenta distintos elementos en grupos según el grado de asociación entre los elementos. El grado de asociación entre dos objetos es máximo si pertenecen al mismo grupo y mínimo si no pertenecen al mismo grupo. Se forma un número determinado o especificado de grupos, o clusteres, lo que permite clasificar matematicamente cada valor de los datos en el grupo adecuado.
El analisis de cluster se considera una técnica de aprendizaje sin guía debido a que no hay variable de destino o dependiente. Generalmente, hay características subyacentes (que habrá que descubrir) que determinan el motivo por el que determinadas cosas aparecen relacionadas y otras no lo estan. El análisis de cluster de elementos relacionados proporciona información significativa sobre cómo se relacionan entre sí los diversos elementos de un conjunto de datos.
Microstrategy emplea el algoritmo de promedio k para determinar los clusteres. Con esta técnica, los clústeres se definen por un centro en un espacio multidimensional. Las dimensiones de este espacio se determinan mediante las variables independientes que caracterizan cada elemento. Las variables continuas se normalizan en el rango de cero a uno (de modo que no haya una variable dominante). Las variables categóricas se reemplazan con una variable de indicador binario para cada categoría ( 1 = un elemento está en la categoria, 0 = un elemento no esta en la categoría). De esta manera, cada variable abarca un rango similar y representa una dimensión en este espacio.
El usuario especifica el número de clústeres, k y el algoritmo determina las coordinadas del centro de cada cluster. En Microstrategy, el usuario o el software de manera automática pueden determinar el número de agrupaciones que se generarán de un conjunto de datos. Si se determina mediante el software, el número de agrupaciones se basa en varias iteraciones para descubrir la agrupación óptima. El usuario establece un valor máximo para limitar el número de agrupaciones determinadas por el software.
La creación de un modelo de clústeres es el primer paso porque, aunque el algoritmo simpre generará los clústeres adecuados, el usuario debe comprender de qué manera difiere cada clúster de los demás. El analisis de cluster no genera ninguna conclusión en si mismo, y habrá que analizar los resultados para buscar esas relaciones ocultas entre los atributos que nos permitan determinan la segmentación, en este caso, de los clientes.
Vamos a ver un ejemplo de segmentación de clientes, en el que intentaremos formar grupos de forma que los miembros de cada uno de ellos se parezcan mas entre si que los miembros de los otros grupos. Vamos a crear cinco segmentos de clientes basandonos en criterios demográficos y psicográficos, que son:
- Rango de edades.
- Formación.
- Sexo.
- Tipo de vivienda.
- Estado civil.
La información reside en los datos de los clientes, y ha sido previamente elaborada para normalizarla según vemos en el informe siguiente (que es el informe de partida para el análisis):
Informe de Datos de clientes
Podemos observar que la información de edades ha sido clasificada en rangos de edad, al igual que la información de Nivel Educativo (formación), Sexo del cliente, Tipo de alojamiento (vivienda) y estado civil. Los valores de estos atributos del cliente ha sido codificados (valor 1, 2, 3, etc). Esta información puede haber sido generado en los procesos de carga del DW o bien definida por indicadores calculados, o por grupos personalizados. Para analizar los clientes, realizaremos un muestro de ellos extrayendo un porcentaje del total de clientes (en nuestro caso, vamos a analizar un 20%).
Para realizar el muestro de datos nos vamos a crear un indicador para luego poder filtrarlo y extraer exactamente el 20% de los clientes. Como vemos en la imagen, con la función Randbetween, que devuelve un numero aleatorio entre dos valores dados, creamos un valor, que luego filtraremos en el informe de creación de los indicadores previsibles a través de un filtro.
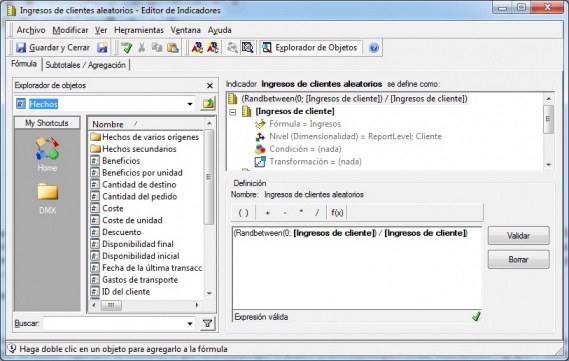
Cluster- Indicar de filtrado para muestreo
A continuación, al igual que en el ejemplo anterior, realizaremos la definición del indicador de formación. En este caso, selecciones el tipo de analisis Agrupación. Podremos realizar dos tipos de análisis. Indicar un número especifico de clusteres, lo que determinara que se analice la información para formar exactamente N grupos o bien la opción segunda, que es especificar un número máximo de clusters y un porcentaje de mejora. En este caso, el algoritmo crea dos clusteres y evaluará la calidad del modelo. A continuación, se crearán 3 clusteres y se comprobara si el modelo ha mejorado. Sino ha mejorado, nos quedamos con el modelo de 2 clusteres. Si mejora, se construira el de 4 clusters y se comparara con el de 3. El proceso continuará hasta que se alcance el número máximo de clusteres especificados o hasta que la mejora no supere el porcentaje indicado.
Indicador de formación en Analisis Cluster - Propiedades Análisis
En nuestro ejemplo, indicamos un número especifico de clusteres, en concreto 5.
A continuación, indicaremos los indicadores independientes que van a formar parte del modelo. Como ya indicamos, aunque estamos analizando atributos de los clientes, tendremos que crear indicadores para estos atributos, pues en el indicador de formación somo podemos incluir indicadores. Tendremos un indicador para cada atributo de los que queremos incluir en el análisis.
Finalmente, definiremos los indicadores previsibles que se generaran cuando ejecutemos un informe incluyendo el indicador de formación. Recordemos que en estos indicadores previsibles, cuando sean creados, podremos ver el modelo generado con el visor de Microstrategy. También podremos utilizarlos en informes para analizar los resultados de la segmentación y sacar conclusiones.
Analisis Cluster - Indicadores previsibles a generar con el modelo
El siguiente paso, una vez creado el indicador de formación, es incluirlo en un informe de Microstrategy junto con todos los atributos necesarios para el análisis. Ejecutaremos el informe, con el muestreo visto anteriormente (a traves de un filtro), y se generaran los indicadores previsibles que podremos analizar. A partir de los indicadores previsibles creados, con el visor de modelos, observamos los resultados del análisis:
Analisis de Cluster - Visor de Modelo Previsible
Aparece una tabla con los diferentes valores de los atributos de los clientes (edades, nivel educativo, sexo, tipo de vivienda y estado civil) y con los valores de peso de cada valor de cada atributo para pertenecer a cada unos de los clusteres. Vemos que los valores mas determinantes para determinar si un cliente entra en un cluster u en otro es el tipo de vivienda. El factor edad, educación o sexo es menos relevante (tiene menos peso). Por ejemplo, en el cluster 1, el tipo de vivienda “Dependiente” es condición para formar el cluster 1. Igualmente para el cluster 5, es condición el tipo de vivienda “Alquiler” y el estado civil soltero. La tabla nos puede hacer una idea de las relaciones entre los valores de los atributos y la pertenencia a un cluster u a otro.
El modelo previsible tiene en la pestaña Simulación una herramienta para ir jugando con las diferentes variables y ver la relación entre ellas. También nos puede ayudar para el análisis crear un informe que incluya todos los atributos y el indicador previsible creado (que devuelve al ejecutar el informe el cluster al que pertenece un cliente). Con el analisis de los datos, filtrado, conteo, ordenación podremos seguramente también descubrir relaciones entre los datos).
En nuestro ejemplo hemos limitado los atributos de clientes que utilizamos para el analisis, pero en una situación real, podriamos ir cambiando los atributos utilizados en el analisis por otros (o eliminando atributos no relevantes), hasta conseguir un modelo que satisfaga nuestra perspectiva de análisis.
Una funcionalidad interesante de Microstrategy es crear un grupo personalizado utilizando el indicador previsible creado, y utilizar este grupo personalizado dentro de los informes. La creación de los grupos personalizados es tan sencilla como vemos en la imagen:
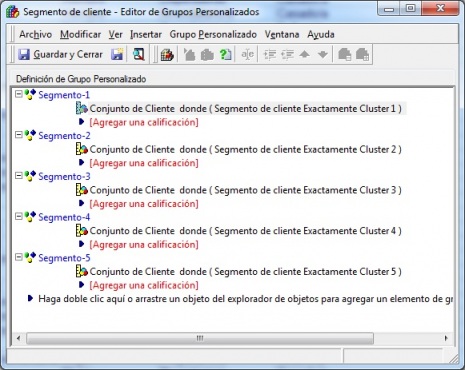
Grupos Personalizado utilizando el indicador previsible Segmento de cliente
Podemos incluir este objeto dentro de un informe para realizar analisis de las características de la segmentación o para analizar información de los clientes incluidos en cada grupo (por ejemplo, ventas, número de clientes, promedio por cliente). Esto nos puede ayudar a conocer mas características del grupo. Igualmente, podriamos realizar detalles y navegacion dentro de cada segmento por zona geográfica, tipo de material u otros aspectos que nos ayudaran a profundizar aun mas en características especificas de cada grupo.
Analisis de Segmento de Clientes usango Grupos Personalizados
El modelo descrito se puede validar en otro conjunto de datos para darle un contenido definitivo y presentar los resultados del análisis de cara a establecer las correspondientes medidas dentro del area de ventas o marketing.
Ejemplo 3. Predicción de ventas en una campaña (Arbol de decisión).
En este analisis utilizaremos un arbol de decisión para determinar la respuesta de un determinado grupo de clientes a rebajas en determinados productos en la epoca de vuelta al colegio. Para ello, utilizaremos arboles de decisión del tipo binario (recordemos que los arboles de decisión se pueden utilizar tanto para clasificación como para analisis de regresión, como en este caso). Intentaremos determinar como influyen factores como la edad, el sexo o el numero de hijos en la probabilidad de realizar compras en esa campaña de rebajas.
Los arboles de decisión son uno de los modelos de mineria de datos mas intuitivos, debido a que muestran una estructura “si-entonces-otro”, facil de comprender. Los arboles de decisión separan un conjunto de datos en distintos subconjuntos de datos. En lugar de utilizar un enfoque de aprendizaje sin guia (como en el análisis cluster), el arbol de decisión utiliza un algoritmo guiado, de forma que los subconjuntos de datos creados comparten una característica de destino determinada, que proporciona una variable dependiente. Las demas características las proporcionan las variables independientes, que se utilizan para dividir los conjuntos de datos originales en subconjuntos de datos. Normalmente, se utiliza la variable independiente con mayor poder previsible y asi sucesivamente. Microstrategy implementa el algoritmo de árbol de clasificación y regresión (CART).
Ejemplo de arbol de decision en Microstrategy
Cada nodo incluye la información siguiente:
- Puntuación (node´s score): el resultado más común (o dominante) de los registros de datos para el nodo.
- Predicado (predicate): una sentencia lógica que se usa para separar registros de datos del origen de un noto. Los registros pertenecen a un nodo si se evalua como verdadero (pueden incluir una o varias sentencias lógicas combinadas con los operadores AND, OR, XOR, etc).
- Gráfico de ojo (eye chart): representación gráfica de la distribución de puntuaciones.
- Distribución de puntuaciones (score distribution): tabla que muestra el desglose de registros de datos de formación asociados con el nodo. Sirve de leyenda para el gráfico de ojo. La distribución de puntuaciones contiene el conteo real de los registros de datos de formacion del nodo que se representa mediante cada clase de destino. La proporción de cada clase de registros de datos se muestra como porcentaje de los conteos totales de este nodo y como porcentaje de la población total.
- Resumen de nodo (node summary): porcentaje de todos los registros de datos de formación asociados con el nodo.
- ID de nodo (node id): identificador unico o referencia para cada nodo. Se usa un formato de profundidad en nivel (el id es una serie de numeros ).
Vamos a realizar un analisis de una campaña utilizando un arbol de decision. Como indicador dependiente utilizaremos el indicador “Respuesta a Rebajas vuelta al cole año X”. Como indicadores independientes, los valores sociodemográficos del cliente como rango de edades, número de mienbros de la familia, sexo o educación. Con estos valores, construiremos, de la forma habitual (e igual que en el resto de ejemplos), el indicador de formación, seleccionando el tipo de análisis Arbol de decisión:
Arbol Decision - Indicador Formacion
El indicador dependiente, cuya definición vemos en la imagen siguiente, es un numero cuyo valor indica un uno si una compra del cliente en el año X fue dentro de la campaña de rebajas y un 0 sino lo fue. Este va a ser el indicador dependiente dentro de nuestro modelo, y el resto los independientes.
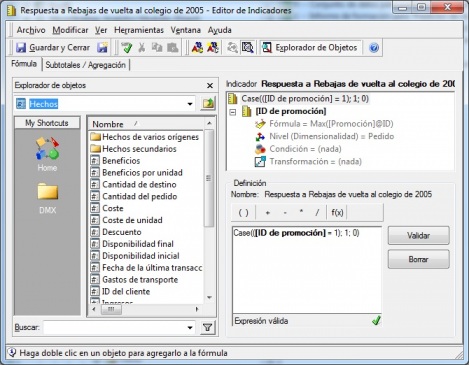
Arbol Decision - Indicador Dependiente
El siguiente paso, como en los ejemplos anteriores, es definir un informe de Microstrategy e incluir el indicador de formación para generar los indicadores previsibles en cuyo contenido podremos analizar los resultados del modelo con el visor de modelos previsibles. En nuestro ejemplo, construimos un informe que lee los datos de pedidos de un periodo de tiempo determinado, incluyendo la información del cliente y el indicador de formación (tal y como vemos en la imagen).
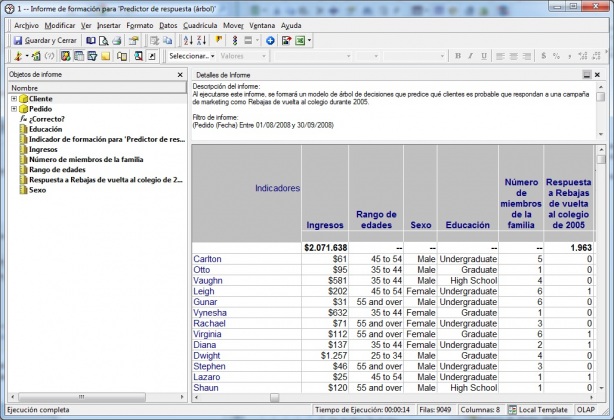
Arbol Decision - Informe creación modelo
Ejecutaremos el informe y se realizará la creación de los indicadores previsibles, donde podremos validar el modelo creado. Podremos ir jugando con las variables dependientes que incluimos en el modelo hasta dar con un arbol de decisión acorde con el objetivo de nuestro análisis. En nuestro caso, hemos obtenido el siguiente árbol de decisión:
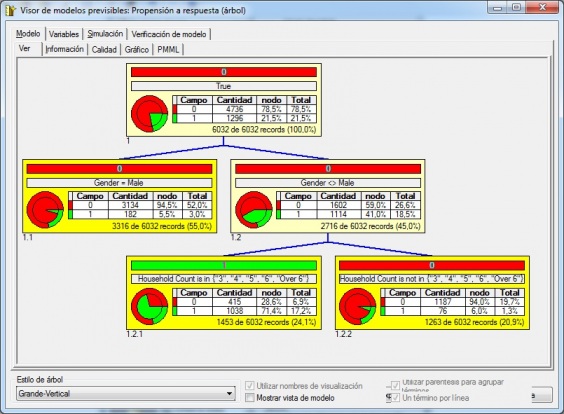
Arbol Decision - Resultados Ejemplo
Podemos observar los resultados del arbol. El sexo es una factor determinante para participar en la campaña (Gender <> Male). Los hombres no han comprado utilizando la rebaja en el 94,5% de los casos. Para las mujeres, si han comprado en el 41% de los casos. Ademas, para mujeres en familias numerosas (3, 4, 5, 6 hijos o mas), se utilizo la promoción en el 71,4% de los casos.
Una vez ajustado el modelo previsible, podremos realizar un analisis de previsión de ingresos de la campaña utilizando en informes (en forma de tabla o gráficos) los indicadores previsibles creados. Podremos de estar manera hacer una predicción de respuesta haciendo simulaciones con los datos de ventas anteriores, con estimaciónes según la predicción de respuesta o ver de forma gráfica el aumento de predictor de respuesta.
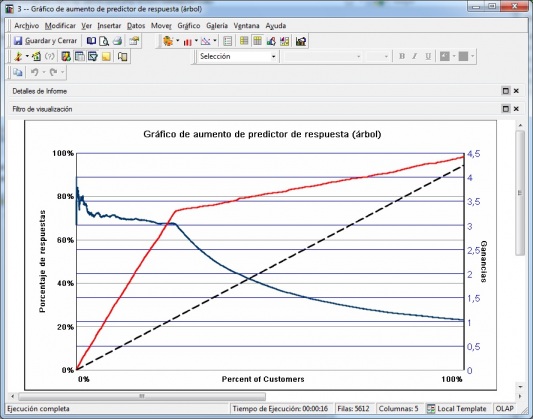
Arbol Decision - Grafico Aumento Respuesta
Los analisis nos permitiran realizar un analisis de los resultados de la campaña en un escenario basado en la respuesta prevista de un cliente a una campaña.
Conclusiones.
He intentado en estos ejemplos entender y transmitiros los conceptos básicos, la metodologia de aplicación y algunas técnicas de las que se utilizan en datamining con ejemplos prácticos que hacen mas fácil su comprensión. Como desconocedor del datamining y sus técnicas, siempre encontraba la carencia de no encontrar ejemplos prácticos que me hiciesen entender un poco mas a fondo y sin un enfoque técnico o estadístico, como es su aplicación, como se desarrollan las técnicas y como se sacan conclusiones de los resultados obtenidos. Espero haber conseguido con esta serie de ejemplos este objetivo.
Por otro lado, a nivel de Microstrategy 9, he constatado algunas ventajas e incovenientes, que os enumero:
Ventajas
- Total integración de los servicios de Data Mining con la plataforma. Se utilizan informes para generar los modelos predictivos a traves de los indicadores de formación. Los resultados obtenidos se analizan y ajustan con el visor de modelos y se pueden validar y explotar las conclusiones utilizando los indicadores previsibles como un elemento mas de los informes (o como parte de otros objetos, como filtros, grupos personalizados, nuevos indicadores, etc). Esto ultimo nos da gran potencia para realizar simulaciones o analisis de posibles resultados siempre trabajando en el entorno de nuestro DW o de los subconjutos de datos extraidos y preparados para el análisis (a través de la creación, por ejemplo, de los Datamarts).
- El uso del estandar XML para exportacion/importación de modelos (PMML), nos permite tanto exportar desde Microstrategy los analisis a otras herramientas de data mining que soporten el estandar para utilizar los modelos en ellas, o bien importar en nuestro sistema modelos desarrollados en otras herramientas (y poder validar los resultados de los análisis, pues al importar los modelos también creamos los indicadores previsibles, que podremos incluir en los informes para verificar resultados o previsiones).
Inconvenientes
- Microstrategy no es una herramienta especifica de Data Mining. Tiene limitaciones respecto al tipo de analisis que se pueden realizar y no es una herramienta diseñada especificamente para dicho proposito, con lo que en muchos aspectos no podrá competir con herramientas especificas.
Otras funcionalidades de Microstrategy 9. Distribución de resultados. Modelos de ejemplo (Analytics Modules).
Otras funcionalidades de Microstrategy 9. Distribución de resultados. Modelos de ejemplo (Analytics Modules). respinosamilla 8 March, 2010 - 09:57Analytic Modules
Como un add-on muy interesante dentro de la plataforma de Microstrategy, los Analytics Modules son un conjunto de componentes analíticos paquetizados construidos utilizando la plataforma de Microstrategy. Lo podemos considerar como una solución de Business Intelligence predefinida, enfocada en un area concreta de las mas comunes dentro de la empresa, y que incorpora todos los elementos necesarios para construir un sistema de inteligencia de negocio. Los modulos estan mapeados contra una base de datos de ejemplo (para que podamos empezar a trabajar con ellos y validarlos de una forma inmediata), aunque podriamos mapearlos contra nuestros propios DW o utilizarlos como un kit de iniciación para desarrollar aplicaciones o para tomar ideas de la forma de diseñar la base de datos, el modelo dimensional, o informes, gráficos, documentos y tableros.
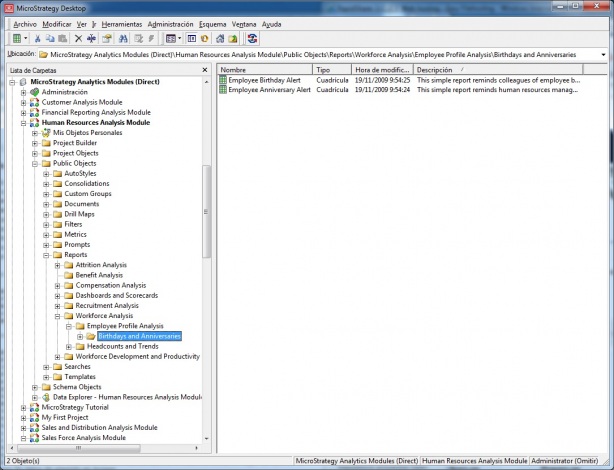
Analytic Modules - Arbol de Proyectos
Cada módulo esta relacionado con un ambito dentro de la empresa, teniendo disponibles los siguientes:
- Customer Analysis Module: análisis de clientes.
- Sales Force Analysis Module: análisis de fuerzas de venta.
- Financial Reporting Analysis Module: reporting financiero.
- Sales and Distribution Analysis Module: ventas y distribución.
- Human Resources Analysis Module: recursos humanos.
.jpg)
Analytic Modules - Cuadro Mando Recursos Humanos
Cada uno de estos módulos contiene los siguientes elementos:
- Project metadata: metadata de cada uno de los proyectos configurado para trabajar contra el DW de ejemplo. Estos proyectos estan preparados para trabajar contra los Access que contienen los datos de ejemplo, aunque utilizando la Guia de Instalación y de Portabilidad de los Analytic Modules podremos configurarlos para que accedan a otros almacenes de datos.
- Demo warehouses: base de datos de ejemplo en Access, como ya hemos indicado,que nos permite trabajar con los componentes del proyecto para evaluarlos o desarrollar nuevos componentes de test sin tener que construir nuestro propio DW.
- Reference Guide: guia completa para cada uno de los modulos en PDF. En esta guia se detallan cada informe, lista de metricas, atributos y otros objetos, como el modelo lógico de los datos y el diccionario de datos. Con esta guia podemos entender el modelo de datos que hay detras del sistema BI de ejemplo, para construir los procesos de llenado en el caso de que decidamos utilizarlo con su configuración original o para el caso de que queramos modificarlo para construir nuestro propio sistema personalizado (pero tomando este modelo como punto de partida). En la documentación proporcionada con los Analytic Modules se nos explica la forma de “migrar” los módulos para hacerlos atacar nuestro propio Data Warehouse. Sería la forma de hacer que el modelo lógico definido en cada uno de los módulos apunte a nuestros datos, en lugar de apuntar a las bases de datos de ejemplo en Access.
- Physical Data Model: modelo fisico de datos en el formato Erwin (Computer Associates). Con el podemos, utilizando la correspondiente herramienta, generar los scripts para la creación de las tablas de nuestro DW (replicariamos el DW de ejemplo del Access en la base de datos que vamos a utilizar para nuestro sistema de BI).
Cada uno de los módulos incluye ejemplos de todos los componentes de Microstrategy enfocados al ámbito de referencia de este, incluyendo ejemplos de atributos, indicadores, jerarquías, filtros, selecciones dinámicas, grupos personalizados, informes, gráficos y documentos. De la misma forma, también hay ejemplos de Data Mining, con la definición de los indicadores de formación y los informes necesarios para realizar el muestreo de datos y la verificación de los modelos de análisis con los indicadores previsibles.
Analytic Modules - Modelo Datos del Modulo HR
Tomando como referencia estos modulos, junto con el Proyecto Tutorial que también nos proporciona Microstrategy, tenemos un punto de partida consitente para profundizar en el conocimiento de la herramienta. Igualmente, estos proyectos predefinidos nos podrían ayudar a construir de forma rapida un proyecto piloto en el ambito seleccionado para mostrar las posibilidades de BI dentro de las organizaciones, con un esfuerzo limitado al estar utilizando componentes ya existentes y validados en muchas organizaciones (que pueden incluir los componentes mas habituales, por ejemplo, en gestión de personal, análisis de ventas o clientes, finanzas, etc).
Distribution Services
Es un componente integrado en la plataforma de Microstrategy 9 que permite la distribución automatizada de informes, cuadros de mando y alertas a través de diferentes canales, como pueden ser vía email, impresoras de sistema o carpetas de red. La distribución de los resultados puede ser activada por procesos planificados, eventos o excepciones. Deberan existir en el sistema procesos de planificación (con su configuración de horario de ejecución, por ejemplo, semanal, diario, cada hora, etc), para poder asociar a ellos las suscripciones y asi poderse llevar a cabo los procesos de distribución de información.
La distribución de los resultados de informes y documentos se puede realizar en los formatos habituales de Microstrategy, que pueden ser HTML, Excel, Pdf, Zip, Texto, CSV o Flash. A la hora de distribuir los resultados, se tendrán en cuenta los perfiles de autorización de los que disponga cada usuario, al igual que a la hora de realizar suscripciones.
En la imagen, podemos ver la forma de crear una suscripción de archivo. Seleccionamos el informe que queremos procesar con la suscripción, e indicamos los parámetros de Planificación (inmediata o a través de los Planificadores existentes en el sistema), tipo de fichero (Html,Pdf, Excel, Texto sin formato o csv), ubicación, propiedades adicionales (permisos, compresión del fichero, contraseña) y si queremos notificar la entrega.
Distribution services - Suscripción de archivo
Cuando se ejecute el proceso, se creara el correspondiente fichero en el formato indicado con los datos provenientes del informe seleccionado en la carpeta indicada. Puede ser una funcionalidad util para dejar preparados en un determinado lugar información que luego consultarán una serie de usuarios autorizados a entrar en esa ubicación. Además de la suscripción de archivo, podemos crear de los siguientes tipos:
- Historial: publicamos los resultados de la ejecución de los informes en la sección historial del sistema. Seria algo así como una ejecución guardada (una foto de los resultados), que podemos visualizar en cualquier momento sin necesidad de que los datos se vuelvan a leer del Data Warehouse. Al planificar, podremos seleccionar uno o varios usuarios. Todos esos usuarios podran ver en su sección Historial los resultados de la ejecución de la suscripción.
- Mobile: envio de resultados via móvil, utilizando el correspondiente producto de Microstrategy.
- Correo electrónico: creación de listas de distribución para enviar, via correo electrónico, los resultados de ejecución de los informes anexados dentro de los emails.
- Impresora: impresión de los resultados de informes en impresoras de sistema.
Distribution services - Tipos de Suscripción
A continuación, podeis ver un ejemplo de la creación de una suscripción de correo electrónico. Podeis ver como indicamos una planificación de la ejecución del envio, el formato de entrega de los resultados y la personalización del texto del correo electrónico (asunto, mensaje, etc).
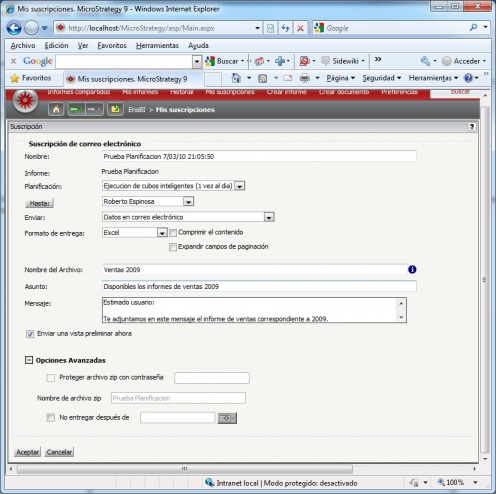
Distribution services - Suscripción de email
Las suscripciones las podrá parametrizar y gestionar el administrador del sistema, aunque los propios usuarios también podran crear o gestionar sus propias suscripciones, siempre que esten autorizados para ello (o autorizados a modificar los datos de suscripciones creadas por otros usuarios en las que ellos esten incluidos).
Este sistema puede ser util para realizar una distribución de la información en los diferentes ambitos de la organización conforme se vaya generando o actualizando el DW, de una forma desasistida y automática, y manteniendo siempre los requisitos de seguridad y control de acceso a la información que habremos configurado al establecer los diferentes permisos a los usuarios y las restricciones de visualización de información utilizando los filtros de seguridad (que también se tienen en cuenta a la hora de la generación de las suscripciones).
Los administradores del sistema tienen sus propias herramientas para gestionar todas las suscripciones que hay definidas en el sistema y poder realizar sus controles o ajustes (tal y como vemos en la imagen siguiente, donde vemos la gestión de suscripciones utilizando la herramienta Desktop).
Gestion de Suscripciónes del sistema usando Desktop
Antes de realizar las conclusiones de nuestro proyecto y el cuadro de evaluación final de los productos que hemos utilizado en él, vamos a desarrollar un mini proyecto de Business Intelligence utilizando datos públicos, en concreto, datos proporcionados por la autoridad de la ciudad de Londres. En este proyecto aplicaremos todo los visto hasta ahora para ver las posiblidades de aplicación del BI en el ambito público y asi cerrar las conclusiones del análisis de herramientas (Talend y Microstrategy).
Ejemplo de BI con Datos Públicos.
Ejemplo de BI con Datos Públicos. respinosamilla 10 March, 2010 - 14:13Al hilo de una interesante serie de artículos publicados en todobi.com (Business Intelligence con datos públicos, Obama usa los Dashboards y Datos Publicos para hacer demos), donde se habla de los datos públicos que ponen a disposición de todos diferentes organismos y como se utilizan estos por diferentes portales. Por ejemplo, Google utiliza los datos de la oficina de estadistica del equivalente al ministerio de trabajo de EEUU para mostrar estadísticas de desempleo en su Web. Otro ejemplo lo tenemos en la web del Banco Mundial, del cual hemos recogido un interesante ejemplo en la imagen siguiente (comparativa entre la esperanza de vida y la renta per capita por paises, en series anuales).
Web del Banco Mundial
Estos datos pueden ser interesantes para realizar demos de sistemas de business intelligence, para integrarlos con información gráfica o geográfica y ser un buen punto de partida para construir un prototipo y vender un producto (muy especialmente en el ámbito de las administraciones públicas). Incluso, estos datos podrían utilizarse para ver los resultados de determinadas políticas públicas o como elemento de toma de decisiones del lugar geográfico o ámbito social donde se deben de aplicar estas políticas. Igualmente, a nivel privado se podrían utilizar para complementar estudios de mercado (en decisiones como la ubicación de un supermercado, un centro de ocio o similares), para campañas de publicidad especificas o buzoneo, etc.
A nivel de la Comunidad Europea, el organismo Eurostat proporciona abudante información estadística en su portal. Incluso nos permite la descarga de los ficheros accediendo a sus directorios de datos (en lo que llaman Bulk Download) con actualizaciones continuas e información del diccionario de datos de cada estadística. Tambien dispone de un amplio abanico de informes estadísticos online que se pueden consultar en forma de tablas, gráficos o mapas y desde los cuales también se pueden descargar los datos en formato Xls, Html, Xml o Tsv.
Graficos Online en la web de Eurostat
A nivel de España, disponemos de un amplio repertorio de resultados de encuestas y estudios en la web del Instituto Nacional de Estadistica y en el Centro de Investigaciones Sociológicas (CIS). A nivel económico, el Banco de España también ofrece abundante información en su web, asi como la Oficina del Catastro para las viviendas, el Ministerio de Fomento sobre la construcción y el sector del transporte o el Ministerio de Trabajo y Asuntos Sociales. En las comunidades autonomas también hay accesibles datos (pues la mayoría de comunidades tienen su propio instituto), como es el caso el Portal Estadistico de la Generalitat Valenciana, el Instituto de Estadística de Cataluña, el Instituto de Estadística de la Junta de Andalucía, el Instituto de Estadística de la Comunidad de Madrid o del mismo Ayuntamiento de Madrid, Barcelona, Sevilla o Valencia. No en todos los sitios la información esta disponible para la descarga o el metodo de descarga es incomodo para poder procesar los datos de una forma automática (información repartida en hojas excel con diferentes pestañas o similares). Se echa de menos la utilización de un estandar para acceder a los datos disponibles de forma que se facilite su procesamiento.
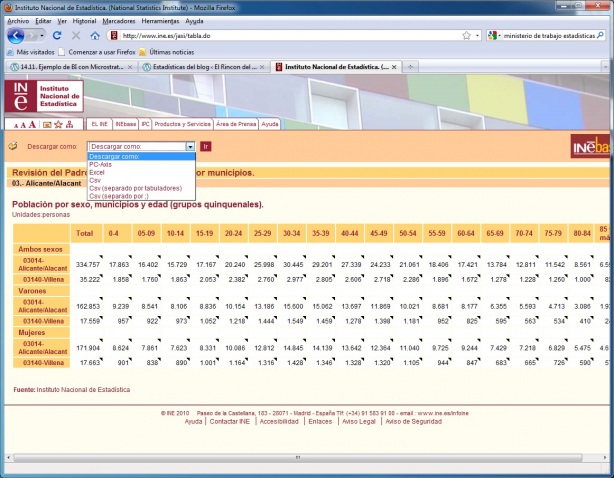
Web del Ine - Consulta de Datos del Padron de 2009 de Alicante
Como hemos indicado anteriormente, en la Web del Instituto Nacional de Estadística, que vemos en la imagen, hay una extensa información en el ambito nacional (Censo de Población, que se realiza cada 10 años y recoge una amplia recopilación de información de personas, estructura de hogares, edificios, etc.; Padrones municipales, que se actualizan todos los años por parte de los ayuntamientos; Encuesta de Población Activa, Indices de Precios al Consumo, Información de empresas y de administraciones públicas, Encuestas de ocupación hotelera, Estadísticas de Turismo y Establecimientos, etc, etc ). Dispone de herramientas online para ir seleccionando el tipo de información a visualizar, permitiendo finalmente la descarga de información en formato csv, excel o pc-axis. Este ultimo es un formato propio del Ine que se puede visualizar a través de una aplicación gratuita que también nos podemos descargar en su web.
Nuestro estudio lo vamos a realizar con datos de la ciudad de Londres (donde hay gran cantidad de datos disponibles en la web https://data.london.gov.uk/datasets, todos ellos en formato descargable, bien en csv, excel o xml). El procesamiento de los ficheros lo realizaremos con Talend y definiremos un miniproyecto en Microstrategy para explotar los datos.
La información que vamos a descargar de la Web para definir nuestro modelo de analisis público será la siguiente:
- Vehiculos abandonados: información anual de vehiculos abandonados por area en el periodo 2000-2008 (link aquí).
- Mortalidad relacionada con el alcohol (link aquí) y tratamientos de drogas (link aquí).
- Nacimientos y ratios de fertilidad (link aquí).
- Ratios de mortalidad (link aquí) y de suicidios (link aquí).
- Emisiones de dioxido de carbono (link aquí).
- Información del censo de población de 2001: población, estructura de edad, vivienda, estado civil, pais de nacimiento, grupos etnicos, religión, salud, actividad economica, ocupacion qualificaciones, vehiculos, composición de hogares, enfermos crónicos, etc.
- Información de impuestos (link aquí).
- Información de viviendas vacias (link aquí).
- Información histórica del censo (link aquí).
- Resultados de elecciones:
- Admisiones hospitalarias (link aquí).
- Viviendas: construccion (link aquí), venta (link aquí).
- Reciclado de basuras (link aquí).
- Ratios de aborto legal (link aquí) y de embarazos de menores (link aquí).
- Vehiculos por número (link aquí) y por tipo (link aquí).
- Espectativa de vida al nacimiento (link aquí).
- Uso de bibliotecas y museos (link aquí).
- Estimación de gasto de turistas (link aquí) y viajes previstos (link aquí).
Como veis, tenemos un amplio conjunto de información disponible para analizar temas muy interesantes, en todos los ambitos de lo publico. Desde analizar, a partir de los datos del censo, los grupos etnicos y religiosos por zonas, y como eso influye en otros aspectos (consumo de drogas, natalidad, etc). Nivel economico de las zonas según el pago de impuestos, los vehiculos o el uso de bibliotecas y museos. Como podeis ver, todo un abanico de posibilidades de análisis de la información.
Proyecto OpenStreet - Mapa de Londres
Como consideración aparte, hemos visto que la ciudad de Londres participa en OpenStreet, que es un proyecto global de colaboración, que ofrece mapas y datos geograficos en el ambito de licencia Open, con el objeto de su uso libre y su reutilización. Tenemos ejemplos de como utilizar los mapas via Apis o a través de código Java.
En la siguiente entrada del Blog mostraremos el modelo de datos para la carga de la información estadística y el diseño de procesos en Talend para cargar el DW. Posteriormente, mostraremos como vemos la información utilizando informes y documentos de Microstrategy.
Modelo de Datos y Procesos de Carga del DW de datos públicos de Londres.
Modelo de Datos y Procesos de Carga del DW de datos públicos de Londres. respinosamilla 29 March, 2010 - 10:35Durante estos días hemos estado analizando los diferentes ficheros de datos que proporciona la autoridad de Londres para preparar su “normalización” y procesamiento y definir también el modelo de datos del DW que vamos a construir. Tal y como nos recordaba la gente de BI Fácil, nos hemos encontrado con que la información estaba en unos “estándares muy poco estándares”. Cada fichero esta construido de una manera y no siguen una linea para construir de la misma forma los ficheros de datos. Eso nos ha complicado un poco el procesamiento de la información.
Para que entendamos mejor el ejemplo, anotar que los datos con los que hemos trabajado corresponden a la región de Londres (Greater London o Gran Londres), que incluye la Ciudad de Londres y Westminster, asi como otros 31 distritos. Es una de las nueve regiones de Inglaterra.Desde el año 2000, la región está administrada por la Autoridad del Gran Londres y tiene un alcalde controlado por la Asamblea de Londres. El estatus del Gran Londres es algo inusual. Es la única región de Inglaterra con un amplio poder, una asamblea regional electa y un alto cargo elegido también por elección directa.
Mapa de la Región de Londres
De todos los datos obtenidos de la web de la autoridad del Gran Londres, hemos procesado cada fichero utilizando Talend e integrado los datos en una tabla intermedia normalizada (sería el Datastage de nuestros procesos ETL). Desde esta tabla llenaremos posteriormente el DW.
Tabla Intermedia para Normalizar las estadísticas
Todas las estadísticas esta referidas a un area o distrito de Londres (el area_id) y corresponden a un año en particular. Ademas, hemos seguido una nomenclatura al nombrar las estadísticas y las variables, siendo la primera letra de sus nombres de la siguiente manera:
| Nomenclatura | |
| Estadistica | Variable |
| V Viviendas | N Numero |
| P Poblacion | P Porcentaje |
| O Ocio | |
| C Cultura | |
| S Salud | |
| E Economia | |
| A Automoviles | |
| T Politica |
Al concluir el procesamiento de todos los ficheros de datos, en esta tabla dispondremos de todos los datos de estadisticas que nos permitiran el llenado el DW con los datos definitivos y completos. Los datos de resultados de elecciones los hemos procesado e incorporado en una tabla diferente, pues no siguen el patrón del resto de estadísticas. Despues de realizar el procesado de alguno de los ficheros, disponemos de mas de 200 variables de análisis, que podeis consultar en el siguiente documento. Tenemos una información amplia de multiples variables que nos van a permitir analizar muchas cosas. Son las siguientes:
El modelo de datos conceptual para nuestro DW va a ser muy sencillo, pues basicamente esta compuesto de unas pocos atributos ( Año, Area ) y multiples hechos ( las variables de cada una de las estadísticas). Hemos creado dos dimensiones de análisis (Dimensión Tiempo: con los datos de año, decada y siglo y Dimensión Geografica, con los datos de las areas o distritos de londres y su correspondiente zona (circunscripciones)). Para facilitar el manejo del modelo, separamos los hechos (cada una de las variables de las estadisticas) agrupandolos por el tipo de estadística. Creamos para ellos 8 tablas de hechos, una para cada tipo de estadística.
El correspondiente modelo físico de nuestro DW sería el siguiente:

Esquema Fisico DW Londres
Los procesos de carga, como hemos indicado, han procesado en primer lugar cada uno de los ficheros de estadísticas, normalizando los resultados e insertandolos en la tabla intermedia que hemos descrito anteriormente (tabla ds_estadisticas). Una vez procesados todos los ficheros, hemos desarrollado los procesos finales en Talend que a partir de estos datos normalizados, han llenado y consolidado todos los datos de las estadísticas.

Talend - Procesamiento de tabla intermedia Estadisticas
Por si os interesa, os dejo el link al zip con la documentación generada de alguno de los procesos en Talend ( Procesos finales de llenado del DW, Tratamiento de ficheros de elecciones, Lectura de datos del censo correspondientes a grupos etnicos y Procesamiento estadistica de vehículos abandonados). Igualmente, podeís consultar online la documentación en los siguientes links:
- Procesos finales de llenado del DW: inicialización tabla de hechos, llenado de dimensión geográfica y dimensión tiempo y procesamiento final de tabla de estadísticas.
- Tratamiento de fichero de elecciones.
- Lectura de datos de grupos etnicos.
- Estadistica de vehiculos abandonados.
Ahora vamos a explotar toda esta completa información en una seríe de ejemplos utilizando Microstrategy para que veamos las posibilidades que nos ofrece el Business Intelligence con datos públicos.
Para terminar, vamos a hacer un poco de turismo. Os dejo una bonita presentación de fotos de la Ciudad de Londres.
| Attachment | Size |
|---|---|
| A_vehiculos_aband.zip | 162 bytes |
| ds_area.zip | 162 bytes |
| Llenado_DW.zip | 162 bytes |
| londres.xls | 162 bytes |
| P_grupo_etnico.zip | 162 bytes |
| T_elecciones.zip | 162 bytes |
Ejemplo BI con datos publicos
Intersantisimo articulo por no decir perfecto. Estoy realizando una practica con Pentaho y me gustaría saber como se ha cargado la tabla operacional ds_area ya que no encuentro la circunsncripcion o area para cada una de las localidades. O al menos el fichero plano donde estan lo tres campos para cargar la dimensión dwd_area.
Muchisimas gracias de antemano
- Log in to post comments
Te paso los ficheros Excel con los datos
Hola:
Los datos los saque de una de las estadísticas, donde estaban los códigos, los nombres y los circunscripciones.
Te he añadido en el post del blog los ficheros (estan el que se llama ds_area.zip).
Un saludo
- Log in to post comments
Muchas gracias. Me está
Muchas gracias. Me está sirviendo de gran utilidad.
Saludos
- Log in to post comments
Explotando los datos públicos de Londres con Microstrategy.
Explotando los datos públicos de Londres con Microstrategy. respinosamilla 1 April, 2010 - 10:41Con los datos de Londres recién sacados del horno y cargados en la base de datos, hemos construido un proyecto dentro de Microstrategy, dando de alta los atributos y sus jerarquias, todos los indicadores vistos, así como otros indicadores adicionales para el calculo de porcentajes o valores intermedios. El proyecto de analisis se ha simplificado lo máximo posible, pues no es nuestro objetivo considerar todas las posibles variantes y casuisticas que nos podriamos encontrar, pero si el plantear una serie de ejemplos reales que nos permitan ver las posibilidades de analisis que se presentan con los datos públicos y ver el partido que se podría sacar de ellos.
.jpg)
Definicion del modelo de datos en Microstrategy
Resultados de elecciones
Hemos procesado los ficheros de resultados de elecciones europeas de 2004 y 2009, así como las elecciones regionales de 2004. Para analizar los resultados, hemos creado un informe donde podemos seleccionar el año de la elección a visualizar, el tipo de elección de ese año, y el area de Londres de la que queremos ver el resultado. Para ello, añadimos los atributos Año, Tipo Elección y Area en la sección de paginación del informe, y los indicadores de análisis en las columnas (tenemos la opción en cada criterio de selección de indicar el valor Total para ver toda la información). Por ejemplo, en la imagen estamos viendo los resultados de las elecciones Europeas de 2004 para todas las areas de Londres.
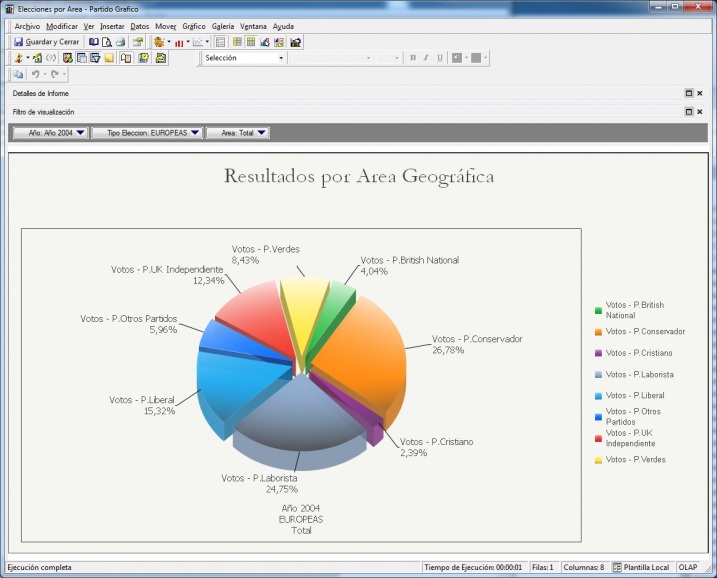
Resultados Electorales - Porcentaje por Partido Politico
Igualmente, hemos definido otro gráfico para poder ver de una forma rápida la evolución del voto en las tres elecciones que hemos analizado. En este informe, igualmente, permitimos ver el analisis del total de resultados o el análisis de un distrito en concreto. Así podemos ver que area es de voto Conservador o de Izquierdas, y como ha evolucionado el voto. Por ejemplo, en la imagen podeis ver los datos del distrito de Newham, que es mayoritario de voto Socialista (Partido Laborista), ademas con un aumento de este partido en las últimas elecciones.
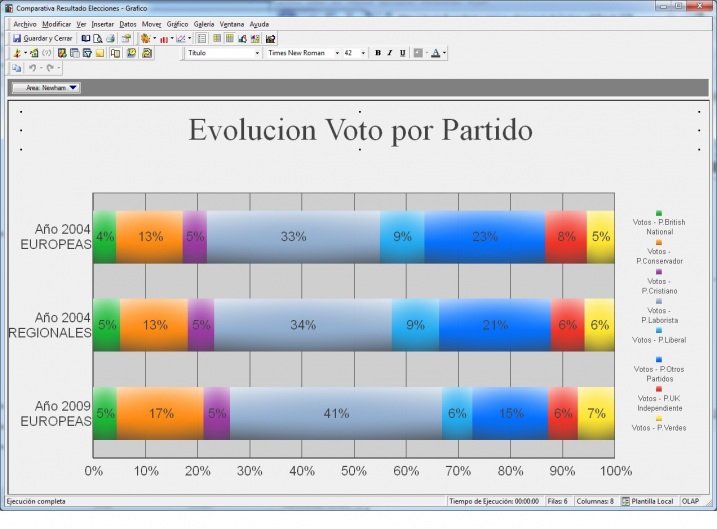
Comparativa Evolución Voto por Partido
Para cerrar el tema de los resultados electorales, hemos construido un informe resumen de resultados (con los valores númericos), incluyendo datos de participación, total de votos y porcentajes. Igualmente, podemos ver los resultados totales de la región o el detalle de cada distrito.
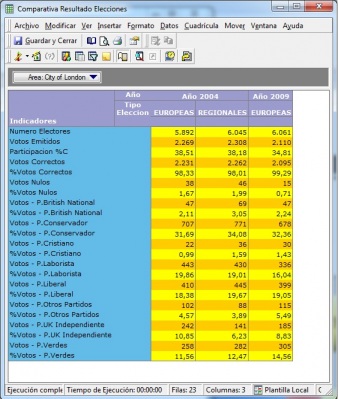 ,
,
Datos Completos de Resultados Electorales y Participacion
Evolución del precio de la vivienda.
De todas las estadísticas relacionadas con la vivienda, tenemos tres muy interesantes (además con una serie temporal amplia que incluye varios años). En concreto, son los valores de precio medio de venta de las viviendas, el número de ventas realizadas en el ejercicio y el total de viviendas construidas (inicio de construccion). Hemos juntado las tres variables de análisis en un informe grafico de ejes de lineas verticales con dos ejes. Ademas, hemos incluido para todas las variables un linea de tendencia lineal para ver hacia donde apuntan los valores futuros según los serie histórica. El resultado del informe es el siguiente:
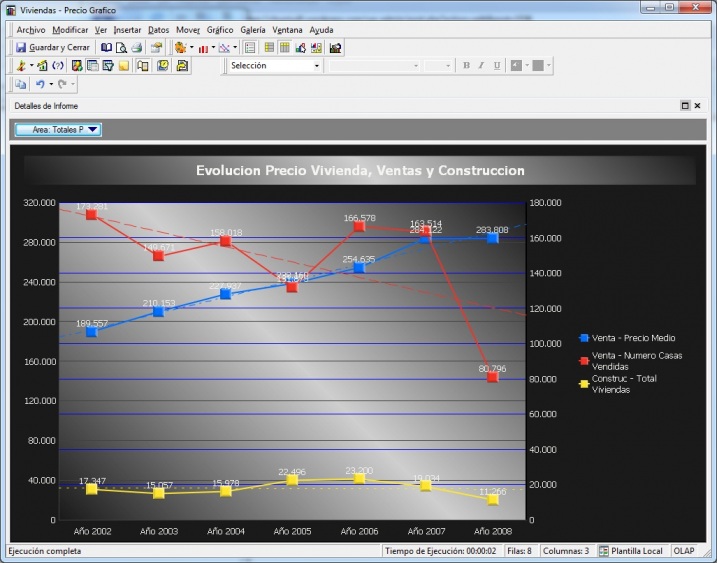
Evolucion Anual del Precio de la Vivienda, Ventas y Construccion
Como podeis ver, en Inglaterra también estan viviendo su propia crísis inmobiliaria con una bajada profunda de las ventas de casas, asi como una estabilización e incluso descenso moderado de los precios debido a la bajada de la demanda y a la crisis financiera. Sería interesante ver este mismo informe con los datos reales de nuestro pais.
Series Históricas de Poblacion.
Los datos de población histórica, incluidos en los datos públicos de Londres, abarcan desde el año 1801 al 2001. Estos datos pueden ser interesantes para ver series y poder ver como se ha modificado la población historicamente de forma general o en cada zona en particular. En el ejemplo siguiente, podeis ver la evolución por Zona (Circunscripción), desde el año 1901 al 2001.
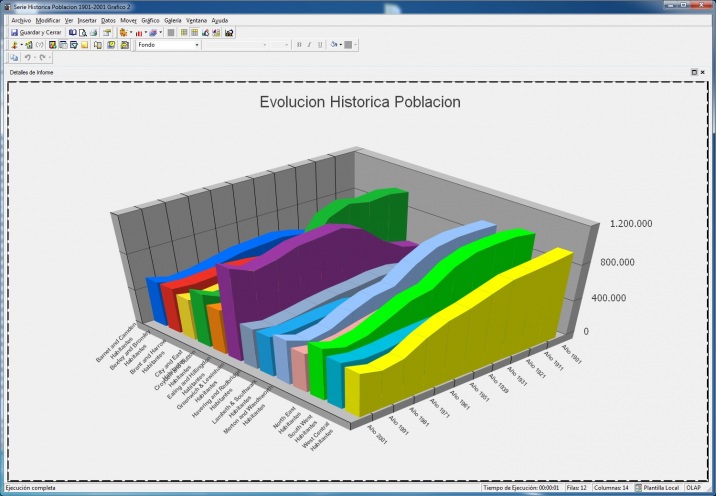
Evolucion Poblacion 1901-2001 por Zona (Circunscripcion)
Utilizando la misma información, hemos preparado un documento Pdf que muestra, para cada distrito o area, la evolución de la población desde 1901 hasta la actualidad, comparandola con la evolución de la población total. Hemos generado la información utilizando un documento que se ha exportado en formato Pdf para su distribución. Os dejo el acceso al documento para que lo veais:
Distribución de población por edad.
En todo análisis demográfico que se precie, es de gran interes el estudio de la distribución de la población por edades. Esto determina muchos aspectos, como pueden ser las necesidades de colegios en una zona (al tener gran cantidad de población infantil), los servicios sociales para atender población jubilada (si el numero de personas de determinadas edades es muy grande), o simplemente para ver como evoluciona la población en la llamada piramide poblacional.
Con los datos del censo de 2001 referente a edades, hemos elaborado dos interesantes gráficos. En el primero, vemos de forma conjunta la distribución de la población total y de cada uno de los distritos de Londres. Es muy gráfico pues se ve toda la información junta y es sencillo realizar comparaciones y ver pesos de cada rango de edades.
Distribucion de la poblacion por Edad - Comparativa de todos los distritos
Hemos incluido la misma información en otro gráfico para poder ver de forma mas clara la piramide poblacional para cada distrito de forma separada (o para el total de la población de Londres). El resultado es el siguiente:
Distribucion de la Poblacion por Edad - Total de la Region de Londres
Podemos observar que mas de la mitad de la población tiene una edad superior a 30 años. Esto puede adelantar problema de envejecimiento de la población en el horizonte de dentro de 20 años (como ocurre, por ejemplo, en España). Incluso, podemos ver en el primer gráfico como la población de la ciudad de Londres (area llamada City of London), esta especialmente envejecida, pues casi el 75% de la población tiene mas de 30 años.
Economia.
Un tema muy de moda en todos los paises es la economía sostenible. De los datos de Londres, referidos a este tema, hemos analizado los ratios de reciclado de basuras (evolución histórica entre los años 1999-2009). Para ello, hemos utilizado un informe tipo tabla, usando umbrales para procesar los porcentajes de una forma mas visual. Veamos los resultados:

Informe de Ratios de Reciclado de Basuras (Evolución)
De forma gráfica, se ve claramente el aumento de los ratios de reciclado, lo que indica la concienciación cada vez mayor de la gente. Se podría completar esta información con el número de contenedores instalados para poder establecer políticas que permitieran aumentar los valores.
Grafico Evolucion Reciclaje por Circunscripcion
Otro aspecto muy interesante de estudio dentro de la economia es la población activa e inactiva y su distribución. Veamos un ejemplo de análisis con la información del censo del año 2001. Para ello, hemos construido un documento de Microstrategy del tipo tablero, donde hemos incluido la información de la distribucion de la poblacion por actividad (activos y no activos), y dentro de cada grupo, su detalle. La información se presenta de forma global y también desglosada por Sexo. El tablero nos permite igualmente ver la información total de la región de Londres o ver de forma detallada cada uno de los distritos.
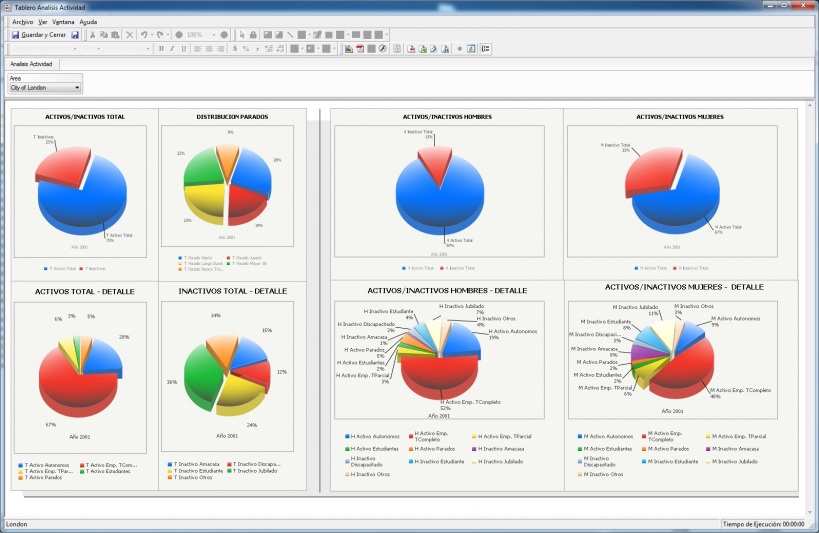
Analisis de Actividad de la Población
Del informe se obtienen bastantes conclusiones curiosas. El porcentaje de mujeres inactivas es claramente superior al de los hombres (40% frente al 18% de los hombres). Igualmente, las mujeres aceptan mas trabajos a tiempo parcial que los hombres, y hay mas hombres autonomos que mujeres. De las personas que se dedican a cuidar a los niños y el hogar, el porcentaje de hombres es infimo con respecto al de las mujeres (todo ello lógico, pues son más las mujeres que renuncian a trabajar o aceptan trabajos de menos horas para poder compaginar vida laboral y familiar).
Vehiculos
La información referente a los vehículos de una ciudad también puede resultar interesante. En nuestro ejemplo hemos combinado la siguiente información en un tablero: evolución del número de vehiculos en una serie temporal, evolución de la población para analizar el contexto del número de habitantes, distribución del numero de vehículos por hogar ( hogares sin vehiculo, hogares con 1 vehiculo, con 2, con 3 o con 4 o mas), distribución de vehículos por tipo y propietario (particulares o empresas/organismos), tipos de vivienda y evolución del precio de la vivienda. Con estos ultimos dos datos intentamos dar el contexto economico a la estadística (seguramente en zonas con viviendas con precios mas alto hay mas nivel adquisitivo y seguramente mas vehiculos o mas vehiculos por hogar). Igualmente, si la zona es residencial (tipo de viviendas bungalow o casas), también habrá mas vehiculos por hogar. El resultado del informe es el siguiente:
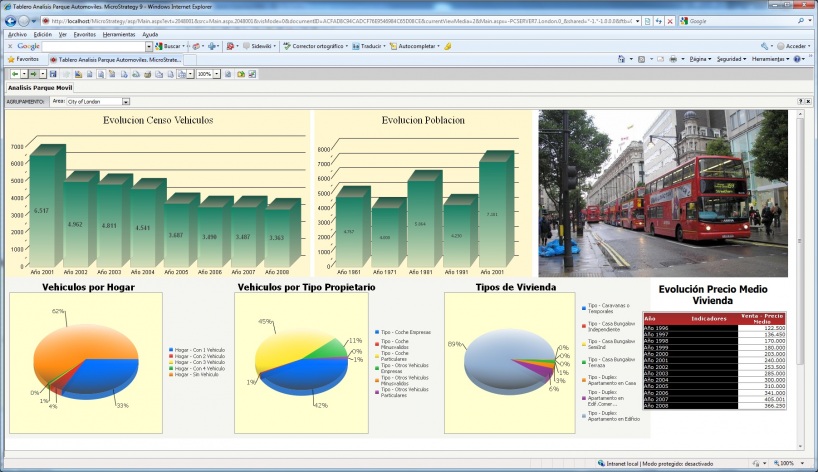
Tablero de Analisis de Parque Movil por Distrito
Hemos incluido la posibilidad de ver los datos totales o cada distrito por separado. Del analisis de un par de distritos, obtenemos conclusiones curiosas:
- Distrito London City: el censo de vehiculos disminuye año tras año, lo que adivina que seguramente es una zona donde se esta produciendo una salida de población hacia zonas perifericas con la vivienda mas barata y sin los problemas tipicos de las zonas más centricas. Ademas, vimos que era una de las zonas con la población mas envejecida. Tambien es curioso que el 62% de los hogares no tiene ningún vehículo (seguramente será también la zona mejor comunicada con trasporte público, tipo Metro o Autobus). De la misma manera, en la City predominan los coches cuyos propietarios son empresas u organismos (53%), a la vez que la mayoria de viviendas (un 89%), son apartamentos.
- Distrito Kingston-upon-Thames: el censo de vehiculos aumenta año tras año, y ademas, el 47% de los hogares tiene 1 coche y el 23% hasta 2 coches. Se podría explicar seguramente por la distribución de las viviendas, ya que el 64% de ellas son del tipo casa o bungalow. Seguramente estemos hablando de una zona residencial. Aquí el 95 por ciento de los coches son propiedad de particulares.
- Distrito de Chelsea: es una de las zonas con la vivienda mas cara,pero ello no implica mas vehiculos por hogar, como habiamos supuesto anteriormente.
Tablero de Analisis del Censo. Cuadro de Mando de Londres.
Para terminar, vamos a construir un tablero (nuestro cuadro de mando de Londres), donde vamos a incluir información variada de la región, referente principalmente al censo de 2001 (el censo es uno de los mayores estudios estadísticos que se realiza, como en España, que se realiza cada 10 años). Hemos construido tres pestañas diferentes en el tablero: Información Demografica, Actividad y Vivienda/Turismo.
En la pestaña Demografía, incluimos un lote de gráficos donde reflejamos: distribución de la población por Estado Civil, Nivel Estudios, Etnia, Religion, Pais Origen y Sexo. Ademas, hemos incluido los resultados electorales de la ultimas elecciones regionales, y una grafica dinámica para ver la evolución de la población desde 1801. Finalmente, se incluye otra gráfica para ver la distribución de la población por edades.
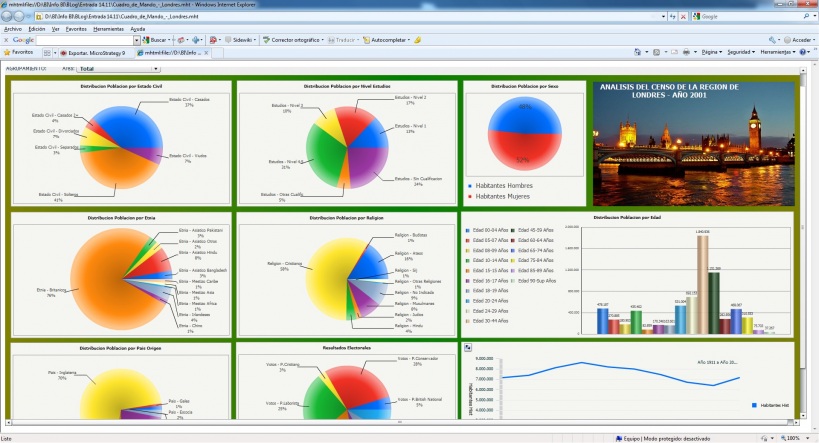
Cuadro de Mando - Londres (Informacion Demográfica)
En las pestaña Actividad, hemos incluido otro lote de gráficos con el objetivo de analizar la población desde un ambito sociolaboral, pudiendo ver la distribución total de profesiones, así como el detalle por sexo de estas, los porcentajes de personas activas e inactivas, y la distribución de dichos colectivos, para finalmente detallar esta información igualmente por sexo. Finalmente, en la pestaña Vivienda/Turismo hemos incluido una gráficas de evolución de los impuestos por vivienda y los ratios de reciclaje por un lado, y por otro lado el precio medio de venta de viviendas y el número de casas vendidas. Igualmente, hemos incluido un gráfico con la evolución de los ingresos por turismo, así como dos gráficos de area para detallar la distribución de los hogares y la tipologia de las viviendas.
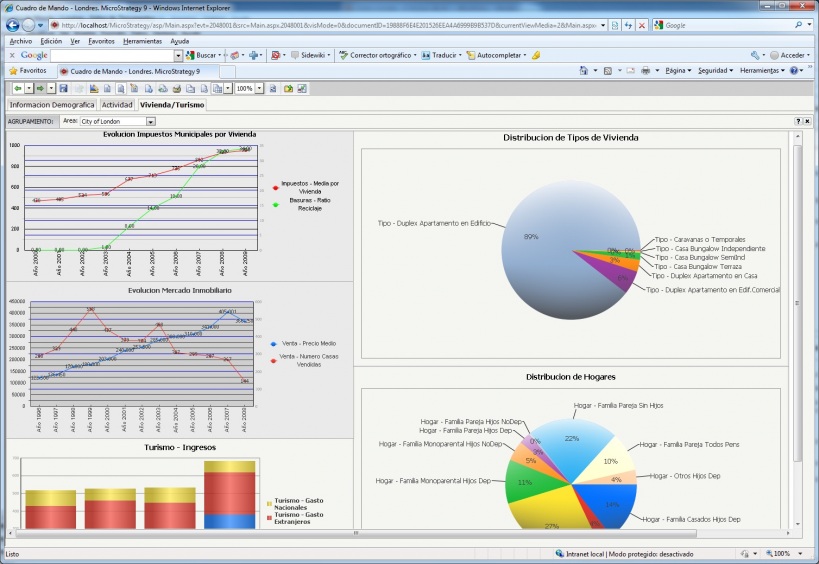
Cuadro de Mando - Londres (Informacion de Vivienda)
La información es abudante y se observan gran cantidad de cosas curiosas en los datos. Os enumero algunas:
- London City: el 60% de la población tiene nivel de estudios universitario, lo que se refleja en las profesiones ( el 77% son profesionales, manager o tecnicos, llegando al 81% en los hombres). Es una zona de voto conservador, con una poblacion en su mayoria mayor de 30 años y ateos (55%), y con un porcentaje alto de extranjeros (25%). Todo esto puede deberse a que en Londres tienen su sede muchos grandes bancos y entidades financieras.
- Barking: distrito con un 60% de la poblacion sin estudios o con estudios primarios. Eso se nota en las profesiones (donde el 34% de los hombres son operarios o empleos básicos, y las mujeres el 36% son administrativas). Hay una mayor población juvenil y el voto mayoritario es laborista (socialista). La etnia dominante es la britanica (90%), al igual que la nacionalidad (87%). Seguramente se trata de un barrio obrero. Es mas, si teneis en cuenta la información de la Wikipedia, donde se habla de este municipio, podeis observar que este fue un distrito de vivienda social entre 1921-31, donde se construyeron 27.000 casas que alojaron a mas de 100 mil personas. Igualmente, después de la 2ª Guerra Mundial se construyeron allí casas para alojar a gente que perdio su vivienda durante la guerra. Eso explicaria muchos de los datos que hemos observado.
- Wetmister: es una zona eminentemente turística, con unos ingresos por este concepto muy altos. Si leeis igualmente en la Wikipedia, podeis ver que este municipio o distrito es el que alberga la mayoria de instalaciones del gobierno de Gran Bretaña (el Palarmento, el Palacio de Buckingham o la Abadia de Wetmister). Igualmente incluye algunos de los puntos turísticos mas importantes de Londres, como son Trafalgar Square, Victoria Station, el Soho, Hyde Park, Piccadilly Circus o la National Gallery. Esto puede explicar que también sea una de las zonas con la vivienda mas cara.
- Tower Hamlets: es una zona donde hay una gran población de etnia asiatica (ver la Wikipedia). Esto fue debido a que hubo una gran necesidad de mano de obra para la industria textil, que se cubrió con habitantes asiaticos, sobre todo de Bangladesh. En esta zona, la religion musulmana constituye el 36% de la población y hay una población infantil y juvenil bastante alta con respecto a otras zonas de Londres.
Os dejo el enlace al flash generado para que vosotros mismos podais jugar con los datos reales (link aquí) y sacar vuestras propias conclusiones de análisis. Para poder trabajar con el flash, es necesario descargarse primero el fichero en local y luego utilizar Internet Explorer para abrirlo (primero abrimos el programa y luego desde él abrimos el fichero, con la opción Archivo–> Abrir), permitiendo la ejecución de los controles ActiveX que lleva incluidos. Según la resolución de pantalla, es posible que tengais utilizar el zoom del Explorer para poder ver los datos correctamente.
Como hemos podido ver con estos pocos ejemplos, con una información consolidada y correctamente normalizada, la cantidad de cosas que podemos analizar. Todo un mundo de posibilidades. Y quizas un nicho de mercado con mucho potencial para vender aplicaciones de Business Intelligence a las administraciones públicas. Espero que os haya resultado interesante el experimento.
Me gusta..
Enhorabuena Roberto, me parece un gran trabajo, habrá que traducirlo al inglés porque aunque sólo sea una demo seguro que más de uno le encontraría utilidad a la información que estás mostrando.
Habrá que investigar también a ver si en el INE podemos encontrar datos suficientes para hacer algo similar sobre una ciudad española.
Sobre Microstrategy, es sorprendente lo que nos dejan hacer con la versión gratuita de su software, los gráficos están muy bien, y las posibilidades para crear buenos cuadros de mando son muy amplias.
La duda que tengo es sobre la parte analítica de esta Reporting Suite. Aunque Microstrategy cuenta que tiene capacidades como drill-up, drill-down no sé si realmente puede utilizarse como herramienta de análisis OLAP, algo así como el Analysis Studio de Cognos, por ejemplo.
Sabes hasta donde llega la Microstrategy Reporting Suite en este sentido?
- Log in to post comments
Carlos, en la Reporting Suite
Carlos, en la Reporting Suite la funcionalidad de analisis OLAP es completa y esta totalmente activa. De hecho, cuando estuve haciendo las pruebas con mi proyecto de ejemplo, empeze a utilizar Microstrategy 9 (la version de evaluación de 30 dias). Cuando, se me acabaron los 30 dias, me pase a la Reporting Suite que ya tenia licenciada y no tuve ningun recorte de funcionalidad.
Asi que creo que es una buena opción para empresas que vaya a iniciarse en el mundo BI (luego siempre se puede ampliar lo que se quiera, previo paso por caja).
En los próximos días publicare las conclusiones de la evaluación de Microstrategy 9, con un cuadro de puntos fuertes y puntos debíles. Puede ser interesante para quien este evaluando entre las diferentes herramientas (o para quien haya pensado en un producto Open y haya visto que esta versión también es gratuita y con muchisimas funcionalidades).
No he tenido tiempo de profundizar en los datos del INE, pero creo que con los datos de los censos (del 2001 o anteriores), se podría hacer algo parecido. Igual utilizando Pentaho, por ejemplo. No estaria mal como ejemplo complementario.
- Log in to post comments
Conclusiones. Evaluación final de Microstrategy 9.
Conclusiones. Evaluación final de Microstrategy 9. respinosamilla 9 April, 2010 - 23:29Durante los ultimos dos meses hemos estado validando las funcionalidades que nos proporciona la suite Microstrategy 9 (gran parte de ellas incluidas, como ya vimos, en la versión gratuita Reporting Suite). Para hacer esto, definimos un proyecto sencillo ambientado en el análisis de ventas, con el que hemos podido desarrollar y explotar el sistema de BI, así como validar y profundizar en todas y cada una de las funcionalidades del producto de una forma detallada (y ampliar nuestros conocimientos en las diferentes técnicas asociadas con el Business Intelligence).
Ejemplo de Cuadro de Mando utilizando Microstrategy
Hemos intentado hacer mas didáctica la prueba incluyendo ejemplos reales de todo y ampliando los aspectos de teoria de Business Intelligence relacionados para ponernos en situación. Aquí os dejo los links a las diferentes entradas del Blog:
- Implementación del sistema BI utilizando Microstrategy.
- Instalación y configuración del servidor Microstrategy 9.
- Diseño de hechos, atributos y jerarquia de dimensiones en Microstrategy 9.
- Diseño de Indicadores, Filtros y Selecciones Dinámicas en Microstrategy 9.
- Gestión de usuarios en Microstrategy 9. Configuración del portal Web.
- Reporting en Microstrategy 9 (I).
- Reporting en Microstrategy 9 (II).
- Navegación Dimensional y cubos OLAP en Microstrategy 9.
- Dashboard y Cuadros de Mando en Microstrategy 9. Utilizando documentos de Report Services (I).
- Dashboard y Cuadros de Mando en Microstrategy 9. Utilizando documentos de Report Services (II).
- DataMining en Microstrategy 9 (I).
- DataMining en Microstrategy 9 (II).
- Otras funcionalidades de Microstrategy 9. Distribución de resultados. Modelos de ejemplo (Analytics Modules).
Llega el momento de las conclusiones y de hacer una recopilación de todo lo visto hasta ahora. Para ello, vamos a hacer un resumen de las funcionalidades mas importantes, y un cuadro donde describiremos lo que nosotros pensamos que son los puntos fuertes y los puntos débiles de Microstrategy.
Cuadro de funcionalidades
Reporting
Las funcionalidades mas destacables en lo referente al reporting son las siguientes:
- Utiliza crosstab o tablas cruzadas donde se pueden formatear y personalizar todos los componentes (filas, columnas, titulos, subtotales), a todos los niveles. Renombrado de indicadores en los informes. Se pueden crear estilos personalizados ( aparte de los estandar).
- Uso de umbrales de formato o con simbolos para destacar valores en rangos determinados (permiten configurar alertas, aviso de desviaciones o cumplimiento previsiones).
- Ordenación avanzada: ordenación a todos los niveles, utilizando tanto atributos como indicadores (de forma individual o combinada).
- Filtros en informes sobre indicadores. Selección de N valores: se pueden realizar filtrado de los indicadores, y limitación de N valores (N primeros, N ultimos, N valores entre el 10 y 15, etc).
- Paginación: creación de atributos de paginado para permitir analisis de información en conjuntos muy grandes de datos.
- Definicion de totales y subtotales totalmente personalizados (podemos crear los nuestro propios). Tipos de totalizacion multiple: total, maximo, minimo, mediana, moda. Selección de la posición de salida en el informe.
- Visualizacion jerarquica de resultados. Desglose automatico de la visualización de datos por niveles.
- Insercion de calculos entre indicadores. Porcentajes sobre el total y transformaciones: indicadores adicionales en los informes que reflejan calculo de otros indicadores o atributos, o bien reflejan información porcentual (a nivel de fila o columna o a nivel de atributo).
- Diferentes formatos de exportacion de los informes: excel, html, csv, pdf.
- Ejecucion de informes integrados en Office: con el componente Office podemos abrir informes y ejecutarlos desde Word, Excel o Powerpoint.
- Navegacion. Movilidad de componentes: navegación dimensional por los datos según las jerarquias de usuario. Mapas de navegacion personalizables (para permitir solo navegar por determinados atributos) o para prohibir la navegación.
- Filtros de visualizacion: filtros que se aplican sobre la visualización del informe una vez calculado. Limites a nivel de informes: definido en la creación de un informe.
- Uso de cache: guardado de resultados de ejecución en memoria para mejorar el rendimiento. Programación de actualizaciones de cache. Expiraciones.
- Grupos personalizados y consolidaciones: creación de grupos de atributos o valores de indicadores de grupos de atributos para reflejar estructuras al vuelo o no definidos en el modelo de datos. Creación de Datamarts para exportar subconjuntos de datos para otros análisis (como data mining) o para crear datamarts departamentales.
- Generacion de informes a partir de sentencias SQL.
- Definición avanzada de filtros: estaticos, dinamicos. Funciones avanzadas de definicion de filtros. Filtros para selección de objetos (por ejemplo, para seleccionar en tiempo de ejecución que indicadores o atributos se incluiran en el informe) . Filtros de seguridad: filtros para limitar el acceso a los valores de atributos a determinados usuarios.
- Multitud de tipos de gráficos disponibles: area, linea, barras, tarta o circular, dispersión, polar, radial, burbuja. Graficos avanzados como Cotizacion, Histograma, Indicador, Embudo, Pareto, Diagrama de Caja, Gant, etc.
- Resultado de informes como filtro de otros informes. Links desde atributos a la ejecución de otros informes.
- Amplitud de caracteristicas de analisis en la creación de indicadores con los diferentes tipos de funciones matemáticas, estadísticas, numéricas, etc.
Navegación Olap
En lo referente a la navegación Olap, podemos destacar lo siguiente:
- Plataforma Olap Relacional (ROLAP).
- Cliente Olap: navegación multidimensional, grupos (Grupos Personalizados y Consolidaciones), paginación, subtotales, ordenación avanzada, visualización jerarquica, umbrales, Filtros de visualización e indicadores, columnas calculadas, agregacion dinámica (todo ello integrado en el sistema de reporting, tal y como hemos visto anteriormente) .
- Elementos Derivados: grupos de atributos creados al vuelo. Seria algo complementario a los grupos personalizados y las consolidaciones.
- Cubos inteligentes: cubos MOLAP que se construyen mediante informes donde seleccionamos atributos, indicadores y filtros. Los cubos construidos almacenan los datos en un lugar diferente y son atacados por los informes sin necesidad de volver a consultar la base de datos.
- Conexion MDX para atacar a otros sistemas (Sap, Hyperion, Microsoft) a traves del lenguaje MDX.
- Dynamic Sourcing: característica avanzada que permite la creación automática de cubos inteligentes por parte del Integrity Server sobre los datos que son utilizados con mas frecuencia (requiere configuración adicional en el sistema).
Ejemplo de Tablero en Analisis de Datos Públicos
Documentos.Cuadros de Mando y Tableros. Report Services.
Con respecto a los Tableros y Cuadros de Mando, podemos considerar lo siguente:
- Diseño de documentos: informes del tipo documento para preparar presentaciones de información tipo pdf (con secciones, encabezados, pies de pagina, grupos) o para la construcción de formularios. En ellos se integran informes, gráficos, texto, imagenes. Multiples posibilidades de formato. Orientados a la impresión o a exportación de otros formatos.
- Diseño de tableros: documentos para construir tableros, tarjetas de puntuación y cuadros de mando. Permiten crear documentos de alta calidad combinando informes y gráficos, ademas de controles (selectores, botones, casillas de selección, etc).
- Conjunto de datos: los documentos del tipo tablero utilizan como origen de datos uno o varios informes, que determinan el conjunto de datos que se pueden utilizar en los componentes del tablero. A partir de un único origen de datos, podemos construir multiples presentaciones de la misma información en cuadriculas o gráficos (incluso con filtros de visualización especificos en cada uno), para visualizar la información con diferentes presentaciones o agrupaciones.
- Uso Widgets Flash, HTML. Los widgets nos permiten utilizar componentes flash de alto contenido visual para presentaciones vistosas. Uso de HTML propio para personalizar los tableros (quizas para publicar los resultados en una intranet corporativa).
- Otros elementos: Vinculacion de objetos (un control o los elementos seleccionados de una tabla pueden determinar los elementos a visualizar en otros controles). Multiples formatos de visualización (html, pdf, flash) y exportación (excel ademas de los anteriores).
DataMining.
- Importación / exportación de modelos de analisis previsible con el formato estandar de la industria PMML.
- Integración con el reporting, permitiendo desarrollar y analizar los resultados de los modelos en informes estandar.
- Visor de modelos previsibles grafico integrado donde construir, perfeccionar y validar los analisis de data mining.
- Tipos de analisis permitidos: Regresión lineal , Regresión Exponencial, Regresión Logistica, Agrupación (Clustering), Arbol de Decisiones, Series Temporales y Asociacion.
Data Mining en Microstrategy - Arbol Decision
Distribución de resultados.
- Distribución de resultados a través del sistema de ficheros, impresoras de sistema o via correo electrónico.
- Multiples formatos para la distribución de la información: pdf, excel, html, csv, texto.
- Procesos de distribución automaticos programados en el Integrity Server. Suscripciones gestionadas por el administrador o por los mismos usuarios.
Acceso Web / Otros
- Portal personalizable integrado con Integrity Server y con Microsoft IIS, desde el cual se pueden diseñar informes o documentos y realizar la ejecución de estos.
- Administración de servicios desde la consola Desktop.
Cuadro de Ventajas / Inconvenientes
Como ventajas o puntos fuertes y destacables de Microstrategy 9, podríamos enumerar las siguientes:
Ambito |
Descripción |
| Instalación | Instalación y configuración del sistema muy sencilla e intuitiva. |
| Configuración | Todo esta centralizado en un par de herramientas (Desktop/Architect) desde las que se realizan todas las tareas. El Architect es una herramienta gráfica muy fácil de utilizar, desde la cual implementamos el modelo lógico de DW a partír de las tablas físicas. Desde el Desktop configuramos el resto de objetos del metadatos (todo desde la misma herramienta), como son indicadores, filtros, selecciones, grupos personalizados, plantillas, informes, documentos, etc. |
| Documentación | Amplia documentación en pdf para todos los componentes (traducidos al castellano el Reporting Básico y Avanzado y la creación de Documentos). |
| Ejemplos | Proyectos de ejemplo (Tutorial) y proyectos tematicos (Analytic Modules) que nos permiten una profundización en el conocimiento del producto, viendo ejemplos reales de todos los componentes. |
| Arquitectura | Arquitectura SOA a través del Intelligent Server. En el se centralizan toda la ejecución de informes y consultas, así como los procesos de actualización desasistidos y la distribución de resultados. Producto consistente e integrado. Generador de querys optimizado. Soporta particionamiento. |
| Reporting | Herramienta de reporting muy avanzada, que deja puertas abiertas para hacer casi de todo. Multiples formatos de gráficos disponibles con gran capacidad de personalización. Interfaz de usuario unificada. |
|
Olap |
Navegación dimensional integrada con el reporting. Funcionalidades avanzadas, como el uso de Cubos Inteligentes, que permiten navegación en memoria. Conexión con otros sistemas a traves de MDX. |
| SDK | Creación de aplicaciones via Narrowcast Server. Integración de las funcionalidades de Microstrategy en otras aplicaciones a traves del SDK. |
| Tableros y cuadros de mando | Generación de documentos y tableros con multiples funcionalidades para realizar presentaciones vistosas, en los que se integran varios informes o gráficos. Exportación en Html o Flash para publicación. Uso de origenes de datos (informes) como fuentes que se pueden visualizar de multiples maneras con controles separados y cada uno con su filtro de visualización. |
| Distribucion de Resultados | Automatización de la distribución de resultados muy completa, via email, impresoras o ficheros y en diferentes formatos (Excel, Pdf, Html, Flash, Csv). |
| Datamining | Posibilidad de integración con herramientas especificas de Data Mining a traves del estandar PMML. La mineria de datos esta totalmente integrada con el reporting. Uso de Datamarts para crear subconjuntos de datos en BD. |
| Web | Acceso Web para el diseño y ejecución de informes/documentos con funcionalidades completas. |
| Conectividad | Cliente para Blackberrys, iPhone(Beta). Integracion con webs via SDK. |
| Licencias | Reporting Suite: funcionalidad completa de forma gratuita (con la limitación de licencias, productos y el uso de 1 Cpu). Paso a Microstrategy 9 ampliando licencias y funcionalidades con costes adicionales. |
Como inconvenientes o puntos débiles de Microstrategy 9, podríamos destacar los siguientes:
Ambito |
Descripción |
| Complejidad Técnica | Complejidad: hay elementos que tienen una complejidad alta (dimensionalidad atributos, diseño de documentos, data mining). Seguramente muchas funcionalidades avanzadas no se utilizaran en un entorno de empresa media. |
| Reporting | Limitaciones en el formato (aunque se pueden compensar en parte utilizando los documentos). |
| Cuadros de Mando/Tableros | Complejidad en el diseño de los documentos. No es el producto más logrado de la Suite. Diferentes resultados visuales según el tipo de presentación (es muy labioroso conseguir el formato deseado). Hay tipos de gráfico, por ejemplo, que no estan soportados en flash. |
| Data Mining | No es una herramienta especifica de Data Mining. Número de técnicas limitadas. |
| Licencias | Producto propietario. Costes altos en el momento salimos de la Reporting Suite. |
Si habeis trabajado con Microstrategy, quizas se os ocurra algo mas que se pueda incluir o rectificar. No estarían mal vuestros comentarios para completar la evaluación.
Bases de Datos Express. Una forma de empezar con las grandes.
Bases de Datos Express. Una forma de empezar con las grandes. respinosamilla 7 April, 2010 - 11:09En una entrada anterior del blog (Bases de Datos OpenSource. ¿Porque elegimos Mysql para nuestro proyecto?), hablamos de las bases de datos Open Source como opción interesante y fiable para el desarrollo de proyectos de Business Intelligence. Vimos diferentes productos y algunas comparativas entre ellos.
Pero hay otras alternativas (con limitaciones en la mayoria de casos), que nos permiten empezar a trabajar con “las grandes” de una forma gratuita. Son las llamadas versiones Express. Son versiones pensadas para pequeños sistemas, para labores de desarrollo o formación, para la preparación de prototipos o evaluaciones, que nos permiten una “iniciación” con los grandes gestores de bases de datos relacionales. En la mayoría de los casos, el producto se ofrece totalmente funcional, pero con limitaciones (en el tamaño máximo de la base de datos, uso de memoria Ram o procesadores de la máquina, etc). También puede haber funcionalidades que no esten activas en estas versiones (como el particionado en la versión Express de Oracle). Os dejo el link a las webs de los fabricantes donde os podeís descargar estas versiones:
- Oracle: Oracle ha apostado claramente por proyectos Open Source, como podeis ver en la web (proyecto Eclipse, PHP, Phyton, etc). A nivel de SGBDR, nos ofrece la Oracle Database 10g Express Edition, en las plataformas Windows y Linux. Se puede distribuir libremente y tiene las siguientes limitaciones: solo 1 instancia de Bd por servidor, tamaño maximo de esta de 4 Gb, utilización máxima de 1Gb de Ram y 1 procesador (aunque tengamos varios). Incluye las herramientas de administración. Mas información aquí.
- Microsoft SQL Server: SQL Server 2008 Express, tiene un limite de 16 instancias, con un máximo de 4 GB de tamaño, uso de 1 Gb de Ram y 1 procesador. Disponible en entorno Windows unicamente, se puede distribuir libremente también. Como opción interesante para el mundo BI, una de las versiones Express incluye los Reporting Services. Mas información sobre la versión en el blog Sqlserversi.com
- IBM DB2: IBM también ofrece su versión express de la archiconocida DB2. Nos ofrecen la DB2 Express-C, en las plataformas Linux y Windows (32 y 64 bits), Solaris y Mac, con la única limitación de uso de 2 Gb de Ram y 2 Procesadores. Podeis ampliar información aquí. También se puede distribuir libremente. Parece que IBM apuesta fuerte con esta versión de “entrada”. Incluso nos ofrecen un libro electrónico gratuito y una colección de videos de formación.
- Sybase: la versión Express de Sybase esta disponible para Linux (la llamada Adaptive Server Enterprise Linux x86 Express Edition). Nos permite trabajar con una unica instancia de base de datos, utilizando como máximo 2 Gb de Ram y 5 Gb de tamaño de la base de datos. Fue liberada para el mundo Linux alla por 1999, por lo que fueron uno de los pioneros en este tipo de versiones.
- IBM Informix: aunque es un producto de IBM al igual que DB2, siguen un estrategia diferente. Nos ofrecen el producto Informix Dynamic Server Developer Edition, en una evaluación sin periodo de expiración, pero solo con fines de desarrollo, y disponible en los sistemas siguientes: AIX, HP, Linux, Mac, Solaris y Windows. La versión Express propiamente dicha es la siguiente en la escala y ya es una versión de pago (pensada como un producto para Pequeña y Mediana Empresa). Los limites son de 1 Gb de Ram y un procesador, y un tamaño máximo de la base de datos de de 8 Gb. Podeís ver la comparativa de cada una de las versiones aquí.
- Adabas: es la base de datos Express menos generosa. En su Personal Edition Adabas 13, nos ofrecen 3 usuarios, limitados a una base de datos de 100Mb y 1 Cpu.
En todos los casos, si quereis pasar a las versiones completas, estan disponibles los correspondientes upgrades de pago. Antes de elegir una, podeís echar un vistazo a sus características en esta completa entrada de la wikipedia. Lo dicho, una opción interesante para formarnos, para validar productos o montar plataformas de desarrollo y prototipos. Y sin pasar por caja.
Aplicaciones para gestión de Incidencias y Bugs. Productos OpenSource.
Aplicaciones para gestión de Incidencias y Bugs. Productos OpenSource. respinosamilla 16 April, 2010 - 11:21En el desarrollo de cualquier proyecto o en la gestión del soporte en cualquier ambito de los sistemas de información (tanto si se trata de soporte interno o a clientes), se requiere el uso de software o herramientas apropiadas que nos permitan la gestión de dicho soporte, permitiendonos hacer un seguimiento de los procesos, realizar tareas de control o reporting, así como documentar adecuadamente las acciones realizadas.
[[ad]] En el mundo Open Source, existen multitud de herramientas orientadas a la gestión de incidencias, tickets o bugs. Herramientas que nos pueden servir para la gestión de un Help Desk, CAU o como soporte al desarrollo de nuevos proyectos o la gestión de los bugs y problemas detectados en un producto software.
Yo particularmente llevo 5 años trabajando con el software de gestión de incidencias open source Eventum, una solución desarrollada internamente en el proyecto de MySql y que posteriormente fue liberada al público para su uso. Es muy sencilla de utilizar y configurar (PHP+MySql) y puede ser valida para la gestión de soporte y documentación de incidencias en un departamento de Informática de una empresa pequeña o mediana. Podeis validarla en mi portal de pruebas (con el usuario supervisor@ejemplo.com, contraseña supervisor). Hay creados un lote de incidencias para que veais los informes, los estados y prioridades de cada una y las cosas que se pueden incluir en las incidencias (ficheros anexos, notas internas, imputación de tiempos consumidos, correos, etc). Podeis crear vuestras propias incidencias con el usuario indicado.
Interfaz de usuario del software de gestión de incidencias Eventum
Además, tenemos muchas más opciones Open source para el mismo cometido. Tenéis una interesante comparativa de herramientas de software libre para la gestión de incidencias en la Wikipedia. Igualmente, se ofrece una buena recopilación en Opensourcehelpdesklist.com, software-pointers.com y webresourcedepot.com. [[ad]] Hay proyectos muy curiosos, como el Bugzilla, desarrollado originariamente a nivel interno en el proyecto Mozilla( y utilizado por ejemplo, en el proyecto Eclipse); el mismo Trac, utilizado en la Nasa para el desarrollo de proyectos y por WordPress; o Jira, usado por la Apache Software Foundation y muchos otros proyectos de desarrollo Open Source, como Pentaho o JBoss (pues aunque es un producto propietario, se cede su uso para proyectos Open Source o para organizaciones sin animo de lucro). Como producto de pago, es usado en empresas tan importantes como BMW, Adobe, Yahoo o Boeing (ver lista completa aquí).
Otras iniciativas, como Google Code, proporcionan una serie de recursos para desarrolladores, así como hosting para proyectos Open Source (similar a Sourceforge ). En este hosting se incluyen el uso de herramientas para la gestión de proyectos, como Wiki o gestión de Issues (Bugs). Podeis ver un ejemplo con el proyecto Hypertable (ideado para la gestión de grandes volumenes de datos, tema del que precisamente estan hablando nuestros amigos de Dataprix.com).
Os dejo un pequeño resumen con los links a las páginas de alguno de los proyectos o fabricantes:
| Aplicacion | Creador | Licencia | Lenguaje/BD |
|---|---|---|---|
| BugTracker.NET | Corey Trager | GPL | ASP.NET/C# on Windows(SQL Server, SQL Server Express) |
| Bugzilla | Mozilla Foundation | MPL | Perl(MySQL, Oracle, PostgreSQL) |
| Debbugs | Debian | GPL | Perl (Flatfile, BDB indexes) |
| Eventum | Mysql | GPL | PHP (MySQL) |
| Flyspray | flyspray.org | LGPL | PHP (ADOdb) |
| Fossil | D. Richard Hipp | GPLv2 | C (Fossil) |
| Gemini | Countersoft | Proprietary, Free for non profit / open source | ASP.Net/C# (Microsoft SQL Server) |
| GNATS | Free Software Foundation | GPL | C (MySQL) |
| GLPI | INDEPNET | GPL | PHP (MySQL) |
| Google Code Hosting | Google Code | Proprietary, available for open source projects | Python (BigTable) |
| JIRA | Atlassian | Proprietary, Free for non-commercial use | Java (MySQL, PostgreSQL, Oracle, SQL Server) |
| Liberum Help Desk | Doug Luxem | GPL | ASP (SQL Server, Access) |
| Kayako SupportSuite | Kayako | Proprietary, some parts GPL | PHP (MySQL) |
| LibreSource | Artenum | GPLv2 | HTML/Java on all platforms (PostgreSQL) |
| MantisBT | Various (Open source contributors) | GPLv2 | PHP (ADOdb (MySQL, PostgreSQL, MS SQL, etc)) |
| OTRS | otrs.org | AGPL | Perl (MySQL, PostgreSQL, Oracle, SQL Server) |
| Redmine | Jean-Philippe Lang | GPL | Ruby on Rails (MySQL, PostgreSQL, SQLite) |
| Request Tracker | Best Practical Solutions, LLC | GPL | Perl (MySQL, PostgreSQL, Oracle) |
| Roundup | Ka-Ping Yee, Richard Jones | MIT license (ZPL v 2.0 for the template system) | Python (SQLite, MySQL, PostgreSQL, Berkeley DB) |
| Simpleticket | Spur | GPL | Ruby on Rails (MySQL, PostgreSQL) |
| Teamwork | Open Lab | Proprietary, some parts LGPL | Java (all relational (uses Hibernate)) |
| Trac | Edgewall Software | New BSD | Python (SQLite, PostgreSQL, MySQL) |
| OsTicket | OsTicket | GPL | PHP (MySQL) |
Como ejemplo del uso de estas herramientras en el ambito de las administraciones públicas, os dejo la interesante entrada del blog de Victor Fernández, donde nos explica un caso práctico de mejora de procesos Itil usando OpenSource, en concreto, usando OTRS (Open source Ticket Request System). Podéis acceder a una demo online del proyecto en este link.
[[ad]] Igualmente, os dejo el link al portal de pruebas para que jugueis con otra de las herramientas que se incluye en las listas, en concreto MantisBT(con el usuario supervisor, password supervisor) Al igual que Eventum, esta desarrollada en PHP y es muy fácil de configurar. Se puede utilizar con MySql, PostgreSQL o SQL Server, siendo un producto bastante completo, aunque no permite la imputación de tiempos o la integración con clientes como Eventum. Podeis ampliar información sobre el producto aquí. Es el proyecto Sourceforge del mes de abril.
Portal de bugs del proyecto Pentaho utilizando el software gestor de incidencias Jira
Para terminar, nada mejor que ver un ejemplo práctico de uso de la herramienta open source para gestión de incidencias Jira en el portal de tracking del proyecto Pentaho (en la imagen). Podeis acceder al portal en el siguiente link y realizar el seguimiento de los diferentes proyectos que estan realizando en Pentaho y como evolucionan los bugs y el desarrollo de mejoras, modificaciones o futuras versiones, a la vez que comprobáis las funcionalidades de Jira.
Particionado de tablas en Oracle
Particionado de tablas en Oracle respinosamilla 24 April, 2010 - 01:12
En una entrada anterior del blog vimos los conceptos básicos del particionado de tablas y como se podian llevar a la práctica utilizando MySql. Incluso hicimos una comparativa de tiempos de respuesta con una tabla de 1 millón de registros con y sin particionado.
Vamos a ver ahora como implementa Oracle el particionado y algunos ejemplos prácticos de creación de tablas particionadas. Como ya vimos, el particionado es una técnica de optimización que pretende mejorar los tiempos de respuesta de las consultas, y que puede ser especialmente útil en un sistema DW donde las tablas de hechos pueden ser muy grandes.
 Tipos de Particionado en Oracle
Tipos de Particionado en Oracle
El particionado fue introducido por primera vez en la versión 8 de Oracle, como una nueva característica DW para la gestión de grandes cantidades de información, y para facilitar la tarea de los administradores de bases de datos. Dependiendo de la versión de Oracle en la que estemos, tenemos diferentes tipos de particionado disponibles:
- Oracle 8.0: particionado Range.
- Oracle 8i: además del particionado Range se añaden los tipos Hash y Composite.
- Oracle 9iR2/10g: se amplian con el tipo List y se permiten nuevas combinaciones de tipos en el particionado Composite.
- Oracle 11g: se introducen las columnas virtuales para particionar(que no existen fisicamente en la tabla), así como el particionado de Sistema (donde podemos gestionar directamente en que partición de la tabla se insertan los registros) y el particionado por Intervalos.
Particionado de Tablas en Oracle
Basicamente, el particionado se realiza utilizando una clave de particionado (partitioning key), que determina en que partición de las existentes en la tabla van a residir los datos que se insertan. Oracle también permite realizar el particionado de indices y de tablas organizadas por indices. Cada partición ademas puede tener sus propias propiedades de almacenamiento. Las tablas particionadas aparecen en el sistema como una única tabla, realizando el sistema la gestión automatica de lectura y escritura en cada una de las particiones (excepto para el caso de la partición de Sistema introducida en la versión 11g). La definición de las particiones se indica en la sentencia de creación de las tablas, con la sintaxis oportuna para cada uno de los tipos.
- Particionado Range: la clave de particionado viene determinada por un rango de valores, que determina la partición donde se almacenara un valor.
- Particionado Hash: la clave de particionado es una función hash, aplicada sobre una columna, que tiene como objetivo realizar una distribución equitativa de los registros sobre las diferentes particiones. Es útil para particionar tablas donde no hay unos criterios de particionado claros, pero en la que se quiere mejor el rendimiento.
- Particionado List: la clave de particionado es una lista de valores, que determina cada una de las particiones.
- Particionado Composite: los particionados anteriores eran del tipo simples (single o one-level), pues utilizamos un unico método de particionado sobre una o mas columnas. Oracle nos permite utilizar metodos de particionado compuestos, utilizando un primer particionado de un tipo determinado, y luego para cada particion, realizar un segundo nivel de particionado utilizando otro metodo. Las combinaciones son las siguientes (se han ido ampliando conforme han ido avanzando las versiones): range-hash, range-list, range-range, list-range, list-list, list-hash y hash-hash (introducido en la versión 11g).
- Particionado Interval: tipo de particionado introducido igualmente en la versión 11g. En lugar de indicar los rangos de valores que van a determinar como se realiza el particionado, el sistema automáticamente creara las particiones cuando se inserte un nuevo registro en la b.d. Las técnicas de este tipo disponible son Interval, Interval List, Interval Range e Interval Hash (por lo que el particionado Interval es complementario a las técnicas de particionado vistas anteriormente).
- Particionado System: se define la tabla particionada indicando las particiones deseadas, pero no se indica una clave de particionamiento. En este tipo de particionado, se delega la gestión del particionado a las aplicaciones que utilicen la base de datos (por ejemplo, en las sentencias sql de inserción deberemos de indicar en que partición insertamos los datos).
Referente al particionado, y como característica interesante, Oracle nos permite definir sentencias SQL del tipo DML haciendo referencia a las particiones. Es lo que llaman nombres de tabla con extension de partición (partition-extended table names). Por ejemplo, podremos hacer un select sobre una tabla particionada indicando en la sintaxis la partición de la queremos que se haga lectura. Por ejemplo:
SELECT * FROM schema.table PARTITION(part_name);
Esto es igualmente válido para las sentencias INSERT, UPDATE, DELETE, LOCK TABLE. Esta sintaxis nos proporciona una forma simple de acceder a las particiones individuales como si fueran tablas, y utilizarlas, por ejemplo, para la creación de vistas (utilizando la vista en lugar de la tabla), lo que nos puede ser util en muchas situaciones.
Vamos a ver un ejemplo de construcción de cada uno de los tipos de particionado.
Particionado Range
Esta forma de particionamiento requiere que los registros estén identificado por un “partition key” relacionado por un predefinido rango de valores. El valor de las columnas “partition key” determina la partición a la cual pertenecerá el registro.
CREATE TABLE sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY RANGE (time_id)
( PARTITION sales_q1_2006 VALUES LESS THAN (TO_DATE('01-APR-2006','dd-MON-yyyy')) TABLESPACE tsa
, PARTITION sales_q2_2006 VALUES LESS THAN (TO_DATE('01-JUL-2006','dd-MON-yyyy')) TABLESPACE tsb
, PARTITION sales_q3_2006 VALUES LESS THAN (TO_DATE('01-OCT-2006','dd-MON-yyyy')) TABLESPACE tsc
, PARTITION sales_q4_2006 VALUES LESS THAN (TO_DATE('01-JAN-2007','dd-MON-yyyy')) TABLESPACE tsd
);Este tipo de particionamiento esta mejor situado cuando se tiene datos que tienen rango lógicos y que pueden ser distribuidos por este. Ej. Mes del Año o un valor numérico.
Particionado Hash
Los registros de la tabla tienen su localización física determinada aplicando un valor hash a la columna del partition key. La funcion hash devuelve un valor automatico que determina a que partición irá el registro. Es una forma automática de balancear el particionado. Hay varias formas de construir este particionado. En el ejemplo siguiente vemos una definición sin indicar los nombres de las particiones (solo el número de particiones):
CREATE TABLE dept (deptno NUMBER, deptname VARCHAR(32))
PARTITION BY HASH(deptno) PARTITIONS 16;
Igualmente, se pueden indicar los nombres de cada particion individual o los tablespaces donde se localizaran cada una de ellas:
CREATE TABLE dept (deptno NUMBER, deptname VARCHAR(32))
STORAGE (INITIAL 10K)
PARTITION BY HASH(deptno)
(PARTITION p1 TABLESPACE ts1, PARTITION p2 TABLESPACE ts2,
PARTITION p3 TABLESPACE ts1, PARTITION p4 TABLESPACE ts3);
Particionado List
Este tipo de particionado fue añadido por Oracle en la versión 9, permitiendo determinar el particionado según una lista de valores definidos sobre el valor de una columna especifica.
CREATE TABLE sales_list (salesman_id NUMBER(5), salesman_name VARCHAR2(30),
sales_state VARCHAR2(20),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY LIST(sales_state)
(
PARTITION sales_west VALUES('California', 'Hawaii'),
PARTITION sales_east VALUES ('New York', 'Virginia', 'Florida'),
PARTITION sales_central VALUES('Texas', 'Illinois')
PARTITION sales_other VALUES(DEFAULT)
);Este particionado tiene algunas limitaciones, como que no soporta múltiples columnas en la clave de particionado (como en los otros tipos), los valores literales deben ser únicos en la lista, permitiendo el uso del valor NULL (aunque no el valor MAXVALUE, que si puede ser utilizado en particiones del tipo Range). El valor DEFAULT sirve para definir la partición donde iran el resto de registros que no cumplen ninguna condición de las diferentes particiones.
Particionado Composite
Este tipo de particionado es compuesto, pues se conjuga el uso de dos particionados a la vez. Veamos un ejemplo utilizando el tipo RANGE y el HASH. En primer lugar, hace un particionado del tipo RANGE utilizando rangos de años. En segundo lugar, para cada partición definida por cada año, hacemos un segundo particionado (subparticion) del tipo aleatorio (HASH) por el valor de otra columna:
CREATE TABLE TAB2 (ord_id NUMBER(10), ord_day NUMBER(2), ord_month NUMBER(2), ord_year NUMBER(4) ) PARTITION BY RANGE(ord_year) SUBPARTITION BY HASH(ord_id) SUBPARTITIONS 8 ( PARTITION q1 VALUES LESS THAN(2001) ( SUBPARTITION q1_h1 TABLESPACE TBS1, SUBPARTITION q1_h2 TABLESPACE TBS2, SUBPARTITION q1_h3 TABLESPACE TBS3, SUBPARTITION q1_h4 TABLESPACE TBS4 ), PARTITION q2 VALUES LESS THAN(2002) ( SUBPARTITION q2_h5 TABLESPACE TBS5, SUBPARTITION q2_h6 TABLESPACE TBS6, SUBPARTITION q2_h7 TABLESPACE TBS7, SUBPARTITION q2_h8 TABLESPACE TBS8 ), PARTITION q3 VALUES LESS THAN(2003) ( SUBPARTITION q3_h1 TABLESPACE TBS1, SUBPARTITION q3_h2 TABLESPACE TBS2, SUBPARTITION q3_h3 TABLESPACE TBS3, SUBPARTITION q3_h4 TABLESPACE TBS4 ), PARTITION q4 VALUES LESS THAN(2004) ( SUBPARTITION q4_h5 TABLESPACE TBS5, SUBPARTITION q4_h6 TABLESPACE TBS6, SUBPARTITION q4_h7 TABLESPACE TBS7, SUBPARTITION q4_h8 TABLESPACE TBS8 ) )
Las combinaciones permitidas son las siguientes (se han ido ampliando conforme han ido avanzando las versiones de Oracle): range-hash, range-list, range-range, list-range, list-list, list-hash y hash-hash (introducido en la versión 11g).
Particionado Composite en Oracle
Particionado Interval
El particionado Interval ha sido introducido en la versión 11g para habilitar un mantenimiento de particiones desasistido. Normalmente, cuando realizamos un particionado sobre una tabla, indicamos una lista de valores o rangos para crear de antemano las particiones. Posteriormente, ajustamos la definición de las particiones para incluir nuevas para nuevos rangos o valores. Con las particiones Interval, preparamos para que Oracle cree las particiones de forma automática cuando lo necesite. Básicamente, se define un intervalo y una directiva para decirle a Oracle como se tiene que comportar. Veamos un ejemplo:
CREATE TABLE T_11G(C1 NUMBER(38,0),
C2 VARCHAR2(10),
C3 DATE)
PARTITION BY RANGE (C3) INTERVAL (NUMTOYMINTERVAL(1,'MONTH'))
(PARTITION P0902 VALUES LESS THAN (TO_DATE('2009-03-01 00:00:00','YYYY-MM-DD HH24:MI:SS')));
Hemos creado una partición base, y con lo especificado en Interval definimos como gestionar la creación automática de nuevas particiones. La posibilidad de definir un intevalo y que Oracle se encargue de crear las particiones a medida que se vayan necesitando resulta muy interesante para facilitar el mantenimiento y administración de particiones.
Particionado System
Una de las nuevas funcionalidades introducida en la version 11g es el denominado partitioning interno o de sistema. En este particionado Oracle no realiza la gestión del lugar donde se almacenaran los registros, sino que seremos nosotros los que tendremos que indicar en que partición se hacen las inserciones.
create table t (c1 int,
c2 varchar2(10),
c3 date)
partition by system
(partition p1,
partition p2,
partition p3);
Si hicieramos un insert sobre la tabla (por ejemplo, insert into t values (1,’A',sysdate);), daría error, siendo la instrucción a ejecutar correcta la siguiente:
insert into t partition (p3) values (1,’A',sysdate);
Puede ser util este particionado para aplicaciones donde nos interesa ser nosotros lo que gestionamos la forma en la que se realiza el particionado (lógica de aplicación).
Uso de columnas virtuales para particionar
En la versión 11g se pueden definir en las tablas columnas virtuales (no existen físicamente). Ademas estas columnas se pueden utilizar para realizar particionado sobre ellas. La forma de crear una tabla con columnas de este tipo sería la siguiente:
create table t (c1 int,
c2 varchar2(10),
c3 date,
c3_v char(1)
generated always as
(to_char(c3,'d')) virtual
)
partition by list (c3_v)
(partition p1 values ('1'),
partition p2 values ('2'),
partition p3 values ('3'),
partition p4 values ('4'),
partition p5 values ('5'),
partition p6 values ('6'),
partition p7 values ('7') );
Os recomiendo la lectura de la entrada del blog OraMDQ donde Pablo Rovedo habla en profundidad sobre las nuevas funcionalidades de particionado de la version 11g de Oracle, incluyendo unos completos ejemplos prácticos.
Gestión del particionado.
La gestión del particionado es totalmente dinámica, de forma que se podrán añadir particiones a una tabla particionada existente, juntar o borrar particiones, convertir una particion en una tabla no particionada, partir una partición en dos (Splitting), hacer un truncate (borra los datos de la partición pero deja la estructura). También podemos mover una partición de un tablespace a otro, renombrarla, etc. Os recomiendo la lectura de blog Bases de Datos y Tecnología donde se explican en detalle algunas de estas operaciones, así como el blog Database Design que también habla sobre el tema).
El particionado en Oracle tiene muchas mas funcionalidades de las que podeis ampliar información en la propia documentación online del fabricante (Oracle 10g y Oracle 11g)
Vistas Materializadas
Otra funcionalidad muy interesante de Oracle y que nos puede ser util cuando estemos construyendo un sistema de Business Intelligence son las Vistas Materializadas. Las vistas materializadas son un tipo de vistas especiales, en las que, ademas de guardarse la definición de esta (como es habitual en todos los sistemas de gestión de bases de datos), también se guardan los datos. También se determina en su definición cuando se va a realizar el refresco del contenido de la “vista”. Nos pueden ser muy utiles para la creación de tablas sumarizadas en un DW o para la creación de tablas intermedias. Os recomiendo la lectura de este artículo de dataprix.com donde se habla de este tema.
Muy buen post
Realmente te felicito por este post, muy interesante y completo.
Saludos
Mariano
- Log in to post comments
leo que se definen intervalos
leo que se definen intervalos en las tablas particionadas , pero cuando tienes ya un sistema en produccion andando utilizando una tabla con millones y millones de registros y se opta por particionar , es recomendable o habría que modificar algo en la programación? ya que las consultas que se utilizan de la tabla ya están definidas .
agradezco su ayuda
- Log in to post comments
Libros de Administración
Libros de Administración Oracle (DBA) y PL/SQL
¿Quieres profundizar más en PL/SQL de Oracle o en administración de bases de datos Oracle? Puedes hacerlo consultando alguno de estos libros de Oracle.
Los libros que ves a continuación son una selección de los que a mi me parecen más interesantes para aprender administración y desarrollo PL/SQL, teniendo en cuenta precio y temática, espero que te puedan ser de utilidad:
- eBooks de Oracle gratuítos para la versión Kindle, o muy baratos (menos de 4€):
- Libros recomendados de Oracle
- Log in to post comments
Ejemplo Kettle para conectarnos a Sap (con el plugin ProERPConn)
Ejemplo Kettle para conectarnos a Sap (con el plugin ProERPConn) respinosamilla 7 May, 2010 - 18:12En una entrada anterior del blog vimos que con Talend nos podiamos conectar a Sap sin necesidad de comprar ningún plugin o complemento adicional en la versión Open Studio. Tan solo habia que disponer del conector Java sapjco.jar, que Sap ofrece libremente a sus clientes, y utilizar los componentes de Talend tSapInput y tSapOutput. La comunicación con Sap era en ambas direcciones, permitiendo tanto la lectura como la escritura en el través de los módulos de función (las llamadas RFC). Ademas, en las versiones de pago de Talend, hay funciones adicionales que incluyen asistentes, la lectura directa del metadata de Sap (diccionario de datos, módulos de función y bapis, recuperación de la documentación de las RFC y su test online) y por tanto, una mayor facilidad de uso, ya que en la versión Open es muy dificil de configurar el componente y la documentación al respecto brilla por su ausencia.
Navegación por los modulos de función RFC de Sap desde Talend
Si nos vamos a Pentaho Data Integration (Kettle), no hay un conector disponible en la versión libre. Pero si tenemos una opción de pago a través del plugin ProERPConn, de la empresa Proratio, con un coste de 2.900 Euros por puesto. Tienen un versión de evaluación de 30 días, que es la que he utilizado para la elaboración de este ejemplo. Vamos a explicar la forma de configurarla y un ejemplo de su uso.
Configuración del Plugin (Windows).
Una vez nos registremos en la Web del fabricante, recibiremos un correo con la documentación y un fichero comprimido con los ficheros para añadir el nuevo “step” o componente a nuestra configuración de Kettle. Los pasos a seguir son los siguientes:
- Descomprimir el fichero recibido en el directorio [Kettle-Directory]\plugins\steps. Este será el lugar del cual leera la aplicación para tener disponible el plugin y poder utilizarlo como un step o paso mas dentro de las transformaciones.
- Instalar el conector sapjco de Sap: para ello dejaremos caer el fichero sapjco.jar en el mismo directorio de antes. Además, el fichero sapjcorfc.dll lo copiaremos al directorio [Kettle-Directory]\libswt\win32. Finalmente, si tenemos una versión anterior de la dll librfc32.dll en el directorio [Windows]\System32, la sustituiremos con la que nos hemos descargado de Sap (os recuerdo que para poder descargarnos el sapjco tenemos que ser clientes de Sap o tener usuario de su portal). Las versiones de Jco que podemos utilizar son la 2.1.6 o 2.1.8.
En este momento, ya podemos arrancar Kettle y al crear una nueva transformación,nos aparece en el grupo Input el paso ProERPconn – PRORATIO SAP Connector. Al colocarlo en la ventana de diseño, cuando hacemos doble click sobre el nos pedirá la clave de activación (que nos mandará el fabricante al enviarles el correspondiente Product Key).
Nuevo paso disponible en la seccion Input para el nuevo plugin
Una vez activado, esta disponible el componente para empezar a realizar lectura de tablas desde Sap, todo de una forma integrada con el diccionario de datos. Para entender mejor como funciona el plugin, hemos de saber que por detras esta utilizando la Remote Function Call de Sap llamada RFC_READ_TABLE, que nos permite realizar tanto la lectura del diccionario de datos de dichas tablas, así como de su contenido. La herramienta, en el caso de que la compremos, ofrece una RFC customizada adicional a la estandar que ofrece mejoras de rendimiento, controles de seguridad de acceso, permite el uso de campos de coma flotante y soluciona algunos problemas que existen con la version 4.7 de Sap. En nuestro caso, al estar con la demo, no disponemos de esa RFC mejorada, y como estamos en la versión 4.7, hemos detectado algunos problemas de funcionamiento incorrecto del plugin al realizar las lecturas desde Sap.
Vamos a ver un ejemplo completo de lectura de datos. Vamos a extraer el maestro de materiales de Sap haciendo un lookup contra tablas adicionales.
Uso del Plugin para recuperar datos del maestro de materiales.
En primer lugar, vamos a definir la conexión a base de datos que nos va a permitir conectarnos a Sap. Al crear una nueva, después de la instalación del Plugin, nos aparece una nuevo tipo llamado Sap R/3 System. En la definición de la conexión indicaremos el host donde esta instalado nuestro Sap (Host Name), el número de sistema (System Number. Normalmente el 00, a no ser que tengamos varios servidores), el mandante (Sap Client), el lenguaje (Language. Importante, pues determina el idioma en que se recuperan posteriormente las definiciones del diccionario de datos) y finalmente el usuario y la contraseña que se utilizaran (se utilizaran los permisos que tenga este usuario. Es importante que el usuario tenga las autorizaciones para ejecutar el módulo de función RFC_READ_TABLE y los permisos para leer en las diferentes tablas).
Plugin Sap - Definición Conexion
Una definida la conexión, ya podemos utilizar el paso para realizar la lectura de datos. En nuestro ejemplo, vamos a leer los registros del maestro de materiales (tabla MARA). Con los datos leidos, realizaremos un lookup para completar la descripción del material (tabla MAKT) y del Grupo de Material (Familia).
Plugin Sap - Configuración Step
En la imagen podemos ver los diferentes elementos que se pueden configurar en el paso. Vamos a ver un poco mas en detalle cada uno de ellos:
- Sap Connection: es la conexión a Sap que previamente habremos definido en las conexiones de base de datos.
- Tablename: nombre de la tabla donde queremos leer los datos. Con el boton Find Table disponemos de un asistente para buscar las tablas en el diccionario de datos de Sap. La busqueda la podemos hacer por el nombre de la tabla, por su descripción, por los campos incluidos en ella, por las claves principales o foraneas. En la busqueda podemos indicar el idioma con el que se recuperan las descripciones de los objetos.
Plugin Sap - Selección Tablas
- Selected Fields: una vez indicada la tabla, seleccionaremos los nombres de los campos que queremos recuperar. Disponemos de un asistente que nos recupera los campos existentes en la tabla con su descripción.
Plugin Sap - Selección Campos
- Where Clause: restricciones a la recuperación de la información. Al añadir los campos con el asistente en esta sección, se autollena una condición de referencia teniendo en cuenta el tipo de datos del campo. Aqui podemos indicar las condiciones para que se restringa la recuperación de información.
Estos son los parámetros básicos del Step. Ademas, podremos indicar otros valores, como el número de registros a recuperar o a ignorar, la conversión del tipo date a char, etc. Teniendo en cuenta esto, vamos a realizar nuestro ejemplo. El gráfico completo quedaría algo así:
![]()
Plugin Sap - Ejemplo Transformacion
Hemos realizado 3 lecturas de tablas desde Sap. En el step SAP – Materiales, leemos de la tabla MARA todos los registros que cumplen unas determinadas condiciones. A continuación, en el paso BUSCA_DESCRIP (del tipo Stream Lookup), realizamos la busqueda de la descripción del material en los registros leidos en el paso SAP – Descripción Material (que lee de la tabla de descripciones MATK). A continuación, el flujo de datos se pasa al paso SAP – Descripción Familia, donde hacemos un lookup, pero de una forma directa para cada uno de los valores del flujo. Podeis ver en la imagen siguiente como hemos añadido en las condiciones del Where para recuperar los valores de la tabla T023T (descripción de la familia del material), el campo del flujo, usando la notación [campo].
Plugin Sap - Lookup con campo del flujo en condición
Finalmente renombramos los nombres de los campos (en el paso RENOMBRA_CAMPOS del tipo Select/Rename Values) y pasamos los resultados a una hoja Excel (hubieramos podidos realizar mas transformaciones sobre los datos o guardarlos en una tabla destino de BD).
Conclusiones.
El plugin de Proratio solo permite la lectura de tablas, y siempre en sentido de salida (extracción), aunque como punto fuerte podemos destacar que esta completamente integrado con el diccionario de datos de Sap y es muy fácil bucear por las tablas y campos. Si lo comparamos con Talend y su componente Sap, este nos permite tanto la comunicación de entrada y de salida. Ademas, permite trabajar con cualquier RFC (no solo la RFC_READ_TABLE como Proratio), lo que nos da muchisimas posibilidades de una integración real de Sap con el exterior y de reutilización de componentes estandar diseñados para operaciones especificas (creación de pedidos de venta, realización de movimientos de material o procesos de contabilización). Incluso podriamos crear nuestras propias RFC en Abap para tareas especificas y llamarlas desde Talend, con todas las posibilidades que ello ofrece. La versión más basica de pago, la Talend Integration Suite, tiene un coste por puesto de 4000$, pero incluye soporte técnico, el acceso a los asistentes (como el de Sap) y funcionalidades avanzadas (como el repositorio compartido para trabajo en grupo).
Hola,lei tu comentario y
Submitted by Eduardo Montilla (not verified) on 22 October, 2014 - 16:29
Hola,lei tu comentario y estoy de acuerdo,te queria preguntar algo... imaginate que quiero estudiar algo referente a alguna aplicacion ibm que tenga demanda cuya curva de aprendizaje no sea tan compleja y alta, que tenga demanda en las empresas y que se pague bien,,, cual aconsejas?,,, yo soy desarrollador plataforma Visual Studio .Net pero quiero en dos años cambiar de perfil,lo que pasa es que no quiero perder dinero y tiempo buscando que especializarme.
que opinion me podrias dar?
gracias